一、多任务编程
(1)什么是多任务
-
多任务是一种同时执行多个任务或处理多个工作的能力,在日常生活和计算机编程中都是普遍存在的。通过合理的任务调度和多任务编程技术,可以提高效率、优化资源利用和提升系统性能。
-
多任务编程也面临一些挑战和问题,例如并发访问共享资源可能引发竞态条件和数据一致性问题,需要采取合适的同步机制来解决。此外,调度算法的设计和任务切换的开销也需要考虑。
(2)什么是多任务编程
-
多任务编程是指在编程中同时执行多个任务或线程。它可以提高程序的效率和响应能力,同时也可以利用多个处理器或核心的能力。在实际开发中,Python 多任务编程可以通过以下三种形式实现:
- 线程
- 进程
- 协程
-
多线程是最常见的一种多任务编程技术,它可以在同一个程序内同时运行多个线程,每个线程负责执行不同的任务。多线程编程能够充分利用多核心处理器的性能优势,提高程序的并发能力。然而,多线程编程需要注意线程安全问题,比如访问共享资源时需要使用锁来保证数据的一致性。
-
多进程编程可以在操作系统级别同时运行多个独立的进程。每个进程拥有独立的内存空间和资源,可以实现更高的隔离性。
-
协程也是一种轻量级的多任务编程技术,它可以在同一个线程中实现多个任务的切换和调度。协程通过yield语句和生成器函数实现任务的暂停和恢复,避免了线程切换的开销并减少了锁的使用。协程常用于异步编程场景,比如网络编程和IO密集型任务。
-
总结起来,多任务编程是一种提高程序并发能力和效率的编程技术,可以通过多线程、多进程或协程等方式实现。在选择多任务编程技术时,需要根据实际需求和情况综合考虑各种因素,比如性能、并发性、开发难度和可维护性等。
二、多任务“进程”编程
1、什么是进程
-
一个正在运行的程序或者软件就是一个进程,它是操作系统进行资源分配的基本单位,也就是说每启动一个进程,操作系统都会给其分配一定的运行资源(内存资源)保证进程的运行。比如:现实生活中的公司可以理解成是一个进程,公司提供办公资源(电脑、办公桌椅等),而公司下属的分公司,可以理解为子进程。
-
多个进程直接是交替运行的;
-
Python 中使用
multiprocessing模块实现进程多任务编程。
import multiprocessing
2、创建进程
-
multiprocessing模块使用Process类创建进程实例对象,实现进程任务的创建。
Process([group [, target [, name [, args [, kwargs]]]]])
参数说明:
-
group:指定进程组,目前只能使用None -
target:执行的目标任务名 -
name:进程名字 -
args:以元组方式给执行任务传参 -
kwargs:以字典方式给执行任务传参
3、启动进程
- 进程对象创建成功后,需要启动进程才会开始执行。
import multiprocessing
import time
# 跳舞任务
def task1():
for i in range(5):
print("跳舞中...")
time.sleep(0.2)
# 唱歌任务
def task2():
for i in range(5):
print("唱歌中...")
time.sleep(0.2)
if __name__ == '__main__':
# 创建进程
p1 = multiprocessing.Process(target=task1, name="myprocess1")
p2 = multiprocessing.Process(target=task2)
# 启动进程
p1.start()
p2.start()
4、获取当前进程
-
multiprocessing.current_process()可以获取当前进程。
import multiprocessing
def task1():
print(multiprocessing.current_process())
def task2():
print(multiprocessing.current_process())
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task1, name="myprocess-1")
p2 = multiprocessing.Process(target=task2)
p1.start()
p2.start()
----------------------------------------------------------------------------------------------
<Process name='myprocess-1' parent=1472 started>
<Process name='Process-2' parent=1472 started>
5 获取进程名
- 进程对象的
name属性可以获取进程的名称。
import multiprocessing
def task1():
print(multiprocessing.current_process().name)
def task2():
print(multiprocessing.current_process().name)
if __name__ == '__main__':
print(multiprocessing.current_process().name)# MainProcess
p1 = multiprocessing.Process(target=task1, name="myprocess-1")
p2 = multiprocessing.Process(target=task2)
p1.start()
p2.start()
---------------------------------------------------------------------------------
MainProcess
myprocess-1
Process-2
6 获取进程ID
-
每一个进程产生时,操作系统都分为进程分配一个ID编号,可以通过
os模块中的方法获取进程的ID。-
os.getpid()获取当前进程ID; -
os.getppid()获取当前进程的父进程的ID;
-
import multiprocessing
import os
def task1():
print(f"{multiprocessing.current_process().name}_ID", os.getpid())
print(f"{multiprocessing.current_process().name}_Parent_ID", os.getppid())
def task2():
print(f"{multiprocessing.current_process().name}_ID", os.getpid())
print(f"{multiprocessing.current_process().name}_Parent_ID", os.getppid())
if __name__ == '__main__':
print(f"{multiprocessing.current_process().name}_ID", os.getpid())
print(f"{multiprocessing.current_process().name}_Parent_ID", os.getppid())
p1 = multiprocessing.Process(target=task1, name="myprocess-1")
p2 = multiprocessing.Process(target=task2)
p1.start()
p2.start()
---------------------------------------------------------------------------------------------------------------
MainProcess_ID 17236
MainProcess_Parent_ID 5076
myprocess-1_ID 14488
myprocess-1_Parent_ID 17236
Process-2_ID 15340
Process-2_Parent_ID 17236
7 进程任务函数传参
-
在创建进程对象的时候,为进程任务函数传递参数,可以使用两种方式为任务函数传参。
-
args: 使用可变位置参数形式传参–传递元组; -
kwargs: 使用可变关键字参数形式传参–传递字典;
-
import multiprocessing
import time
def task(n, msg):
for i in range(n):
print(multiprocessing.current_process().name, f"打印第 {i+1} 次 {msg}")
time.sleep(0.2)
if __name__ == '__main__':
# 使用可变位置参数传参
p1 = multiprocessing.Process(target=task, args=(10, "Python"))
# 使用可变关键字参数传参
p2 = multiprocessing.Process(target=task, kwargs={"n": 10, "msg": "Hogwarts"})
p1.start()
p2.start()
8、进程同步
-
join()方法用来将子进程添加到当前进程之前执行,直到子进程执行结束后,当前进程才会继续向下执行。 -
多个进程间的代码在运行时是交替执行的,如果使用
join()方法后,当前进程会进入到阻塞状态,等待子进程结束后,解除阻塞状态,继续执行当前进程。 -
使用
join()方法后,可使多进程的异步执行变成同步执行, 过多使用会使程序效率变低。
import multiprocessing
import time
def task(n, msg):
for i in range(n):
print(multiprocessing.current_process().name, f"打印第 {i+1} 次 {msg}")
time.sleep(0.2)
if __name__ == '__main__':
# 使用可变位置参数传参
p1 = multiprocessing.Process(target=task, args=(10, "Python"))
# 使用可变关键字参数传参
p2 = multiprocessing.Process(target=task, kwargs={"n": 10, "msg": "Hogwarts"})
p1.start()
p1.join()
print("main run ...")
p2.start()
9、守护进程
-
多进程在执行时,父进程会等待子进程执行结束才会结束。
-
如果需要子进程在父进程执行结束后就结束执行,无论子进程是否执行完毕,可以将子进程设置为守护进程。 比如:只有开启企业微信后,才可以使用企业微信的会议功能,当企业微信退出时,会议也会随之退出。
-
设置守护进程方式有两种:
- 使用 子进程对象
.daemon = True在子进程启动前将子进程设置为守护进程。 - 使用 子进程对象
.terminate()在主进程退出前手动将子进程结束。设置子进程为守护进程
- 使用 子进程对象
-
1、 设置子进程为守护进程
import multiprocessing
import time
def task(n, msg):
for i in range(n):
print(multiprocessing.current_process().name, f"打印第 {i+1} 次 {msg}")
time.sleep(0.2)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task, args=(10, "Python"))
p2 = multiprocessing.Process(target=task, kwargs={"n": 10, "msg": "Hogwarts"})
# 在子进程启动前将子进程设置为守护进程,当主进程结束后,无论子进程是否执行完都要结束
p1.daemon = True
p1.start()
p2.start()
# 主进程睡1秒。。。
time.sleep(1)
print("main")
---------------------------------------------------------------------------------
Process-1 打印第 1 次 Python
Process-2 打印第 1 次 Hogwarts
Process-1 打印第 2 次 Python
Process-2 打印第 2 次 Hogwarts
Process-1 打印第 3 次 Python
Process-2 打印第 3 次 Hogwarts
Process-1 打印第 4 次 Python
Process-2 打印第 4 次 Hogwarts
Process-1 打印第 5 次 Python
Process-2 打印第 5 次 Hogwarts
main
Process-2 打印第 6 次 Hogwarts
Process-2 打印第 7 次 Hogwarts
Process-2 打印第 8 次 Hogwarts
Process-2 打印第 9 次 Hogwarts
Process-2 打印第 10 次 Hogwarts
Process finished with exit code 0
- 2、 手动杀死子进程
import multiprocessing
import time
def task(n, msg):
for i in range(n):
print(multiprocessing.current_process().name, f"打印第 {i+1} 次 {msg}")
time.sleep(0.2)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task, args=(10, "Python"))
p2 = multiprocessing.Process(target=task, kwargs={"n": 10, "msg": "Hogwarts"})
p1.start()
p2.start()
time.sleep(1)
# 手动杀死子进程2
p2.terminate()
print("main")
-------------------------------------------------------------------------------------
Process-1 打印第 1 次 Python
Process-2 打印第 1 次 Hogwarts
Process-1 打印第 2 次 Python
Process-2 打印第 2 次 Hogwarts
Process-1 打印第 3 次 Python
Process-2 打印第 3 次 Hogwarts
Process-1 打印第 4 次 Python
Process-2 打印第 4 次 Hogwarts
Process-1 打印第 5 次 Python
Process-2 打印第 5 次 Hogwarts
main
Process-1 打印第 6 次 Python
Process-1 打印第 7 次 Python
Process-1 打印第 8 次 Python
Process-1 打印第 9 次 Python
Process-1 打印第 10 次 Python
10、 进程间不共享全局变量
- 因为进程是程序执行的最小资源分配单位,当一个子进程被创建时,子进程会复制父进程的资源,形成一个独立的空间,所以多个进程之间的数据是独立不共享的。
import multiprocessing
import time
# 定义全局变量
g_list = list()
# 添加数据的任务
def add_data():
for i in range(5):
g_list.append(i)
print("add:", i)
time.sleep(0.2)
print("add_data:", g_list)
def read_data():
print("read_data", g_list)
if __name__ == '__main__':
add_data_process = multiprocessing.Process(target=add_data)
read_data_process = multiprocessing.Process(target=read_data)
add_data_process.start()
add_data_process.join()
read_data_process.start()
# 主进程
print("main:", g_list)
-------------------------------------------------------------------
add: 0
add: 1
add: 2
add: 3
add: 4
add_data: [0, 1, 2, 3, 4]
main: []
read_data []
三、多任务“线程”编程
1、什么是线程
-
线程是指在一个程序中执行的一段指令流。
-
在操作系统中,线程是调度执行的最小单位,它可以独立运行,并共享线程的资源,如内存空间、文件句柄等。
-
比如:现实生活中的公司可以理解成是一个线程,公司提供办公资源(电脑、办公桌椅等),真正干活的是员工,员工可以理解成线程。
2、线程的特点
- 轻量级:相对于进程来说,线程的创建、切换和销毁的开销较小。
- 共享资源:线程可以共享线程的资源,包括内存空间、文件句柄等。这使得线程之间可以方便地进行数据共享和通信。
- 并发执行:线程可以并发执行,即多个线程可以在同一时间内执行不同的任务。线程的并发执行可以提高程序的性能和响应性。
- 线程安全:线程安全是指多个线程同时访问共享数据时,不会出现数据不一致或异常的情况。在多线程编程中,需要采取一些措施(如锁、互斥量等)来保证线程安全性。
- 线程必须依附于进程中,线程不能单独存在。
3、多线程编程
- Python 中使用
threading模块实现线程多任务编程。
import threading
(1)创建线程
-
threading模块使用Thread类创建线程实例对象,实现线程任务的创建。
Thread([group [, target [, name [, args [, kwargs [, daemon]]]]]])
参数说明:
-
group:指定线程组,目前只能使用None -
target:执行的目标任务名 -
name:线程名字 -
args:以元组方式给执行任务传参 -
kwargs:以字典方式给执行任务传参 -
daemon:设置线程对象为守护线程
(2) 启动线程
- 线程对象创建成功后,需要启动线程才会开始执行。
import threading
import time
# 跳舞任务
def task1():
for i in range(5):
print("跳舞中...")
time.sleep(0.2)
# 唱歌任务
def task2():
for i in range(5):
print("唱歌中...")
time.sleep(0.2)
if __name__ == '__main__':
t1 = threading.Thread(target=task1, name="mythread-1")
t2 = threading.Thread(target=task2)
# 启动线程
t1.start()
t2.start()
--------------------------------------------------------------
跳舞中...
唱歌中...
唱歌中...跳舞中...
唱歌中...跳舞中...
唱歌中...
跳舞中...
跳舞中...唱歌中...
(3) 获取当前线程
-
threading.current_thread()可以获取当前线程。
import threading
def task1():
print(threading.current_thread())
def task2():
print(threading.current_thread())
if __name__ == '__main__':
t1 = threading.Thread(target=task1, name="myThread-1")
t2 = threading.Thread(target=task2)
t1.start()
t2.start()
------------------------------------------------------
<Thread(myThread-1, started 12776)>
<Thread(Thread-1 (task2), started 16220)>
(4) 获取线程名
- 线程对象的
name属性可以获取线程的名称。
import threading
def task1():
print(threading.current_thread().name)
def task2():
print(threading.current_thread().name)
if __name__ == '__main__':
print(threading.current_thread().name)# MainThread
t1 = threading.Thread(target=task1, name="myThread-1")
t2 = threading.Thread(target=task2)
t1.start()
t2.start()
---------------------------------------------------------------------------
MainThread
myThread-1
Thread-1 (task2)
(5) 线程无序性
- 线程执行时是无序的。它是由cpu调度决定的 ,cpu调度哪个线程,哪个线程就先执行,没有调度的线程不能执行。
import threading
import time
def task():
time.sleep(1)
print("当前线程:", threading.current_thread().name)
if __name__ == '__main__':
# Python中对于无需关注其实际含义的变量可以用_代替,这就和for i in range(5)一样,因为这里我们对i并不关心,只是要5次而已,所以用_代替仅获取值而已。
for _ in range(5,10):
t = threading.Thread(target=task)
t.start()
-------------------------------------------------------------------------------------------
当前线程:当前线程: Thread-1 (task)
Thread-2 (task)
当前线程: Thread-5 (task)
当前线程: 当前线程: Thread-3 (task)
Thread-4 (task)
(6) 线程任务函数传参
-
在创建线程对象的时候,为线程任务函数传递参数,可以使用两种方式为任务函数传参。
-
args: 使用可变位置参数形式传参 -
kwargs: 使用可变关键字参数形式传参
-
import threading
import time
def task(n, msg):
for i in range(n):
print(threading.current_thread().name, f"打印第 {i+1} 次 {msg}")
time.sleep(0.2)
if __name__ == '__main__':
# 使用可变位置参数传参
t1 = threading.Thread(target=task, args=(5, "Python"))
# 使用可变关键字参数传参
t2 = threading.Thread(target=task, kwargs={"n": 5, "msg": "Hogwarts"})
t1.start()
t2.start()
---------------------------------------------------------------------------------------------
Thread-1 (task) 打印第 1 次 Python
Thread-2 (task) 打印第 1 次 Hogwarts
Thread-1 (task)Thread-2 (task) 打印第 2 次 Python 打印第 2 次 Hogwarts
Thread-1 (task) 打印第 3 次 Python
Thread-2 (task) 打印第 3 次 Hogwarts
Thread-1 (task) 打印第 4 次 Python
Thread-2 (task) 打印第 4 次 Hogwarts
Thread-2 (task)Thread-1 (task) 打印第 5 次 Python
打印第 5 次 Hogwarts
(7) 线程同步
-
join()方法用来将子线程添加到当前线程之前执行,直到子线程执行结束后,当前线程才会继续向下执行。 -
多个线程间的代码在运行时是交替执行的,如果使用
join()方法后,当前线程会进入到阻塞状态,等待子线程结束后,解除阻塞状态,继续执行当前线程。 -
使用
join()方法后,可使多线程的异步执行变成同步执行, 过多使用会使程序效率变低。
import threading
import time
def task(n, msg):
for i in range(n):
print(threading.current_thread().name, f"打印第 {i+1} 次 {msg}")
time.sleep(0.2)
if __name__ == '__main__':
# 使用可变位置参数传参
t1 = threading.Thread(target=task, args=(5, "Python"))
# 使用可变关键字参数传参
t2 = threading.Thread(target=task, kwargs={"n": 5, "msg": "Hogwarts"})
t1.start()
# 线程同步,t1线程执行完之后才会执行其他线程
t1.join()
print("main run ...")
t2.start()
t2.join()
------------------------------------------------------------------------------------------
Thread-1 (task) 打印第 1 次 Python
Thread-1 (task) 打印第 2 次 Python
Thread-1 (task) 打印第 3 次 Python
Thread-1 (task) 打印第 4 次 Python
Thread-1 (task) 打印第 5 次 Python
main run ...
Thread-2 (task) 打印第 1 次 Hogwarts
Thread-2 (task) 打印第 2 次 Hogwarts
Thread-2 (task) 打印第 3 次 Hogwarts
Thread-2 (task) 打印第 4 次 Hogwarts
Thread-2 (task) 打印第 5 次 Hogwarts
(8) 守护线程
-
多线程在执行时,父线程会等待子线程执行结束才会结束。
-
如果需要子线程在父线程执行结束后就结束执行,无论子线程是否执行完毕,可以将子线程设置为守护线程。
-
比如:在使用下载软件进行下载多个视频时,每个下载任务都是一个线程,如果下载软件退出,则下载任务也会停止并退出。
-
设置守护线程方式有两种:
- 使用
daemon = True参数在子线程对象创建时将子线程设置为守护线程。 - 使用
子线程对象.daemon = True属性在子线程对象启动前将子线程对象设置为守护线程。
- 使用
设置子线程为守护线程
import threading
import time
import os
def task(n, msg):
print(f"{threading.current_thread().name}_id:{os.getpid()}")
print(f"{threading.current_thread().name}_pid:{os.getppid()}")
for i in range(n):
print(threading.current_thread().name, f"打印第 {i+1} 次 {msg}")
time.sleep(0.2)
if __name__ == '__main__':
print(f"{threading.current_thread().name}_id:{os.getpid()}")
print(f"{threading.current_thread().name}_pid:{os.getppid()}")
t1 = threading.Thread(target=task, args=(5, "Python"))
# t1 = threading.Thread(target=task, args=(5, "Python"),daemon=True)
t2 = threading.Thread(target=task, kwargs={"n": 5, "msg": "Hogwarts"})
t1.start()
t2.daemon = True
time.sleep(1)
t2.start()
print("main")
-------------------------------------------------------------------------------
MainThread_id:15704
MainThread_pid:5076
Thread-1 (task)_id:15704
Thread-1 (task)_pid:5076
Thread-1 (task) 打印第 1 次 Python
Thread-1 (task) 打印第 2 次 Python
Thread-1 (task) 打印第 3 次 Python
Thread-1 (task) 打印第 4 次 Python
Thread-1 (task) 打印第 5 次 Python
Thread-2 (task)_id:15704main
Thread-2 (task)_pid:5076
Thread-2 (task) 打印第 1 次 Hogwarts
(9)获取线程ID
-
每一个线程产生时,操作系统都分为进程分配一个ID编号,可以通过
os模块中的方法获取线程的ID。-
os.getpid()获取当前进程ID; -
os.getppid()获取当前进程的父进程的ID;
-
import threading
import os
def task1():
print(f"{threading.current_thread().name}_ID:{os.getpid()}")
print(f"{threading.current_thread().name}_PID:{os.getppid()}")
def task2():
print(f"{threading.current_thread().name}_ID:{os.getpid()}")
print(f"{threading.current_thread().name}_PID:{os.getppid()}")
if __name__ == '__main__':
print(f"{threading.current_thread().name}_ID:{os.getpid()}")
print(f"{threading.current_thread().name}_PID:{os.getppid()}")
t1 = threading.Thread(target=task1,name="mythread_1")
t2 = threading.Thread(target=task2)
t1.start()
t2.start()
-------------------------------------------------
MainThread_ID:4620
MainThread_PID:5076
mythread_1_ID:4620
mythread_1_PID:5076
Thread-1 (task2)_ID:4620
Thread-1 (task2)_PID:5076
(10) 线程间共享全局变量
- 因为线程是程序执行的最小执行单位,当一个子线程被创建时,子线程会使用父线程的资源,所以多个线程之间的数据是共享的。
import threading
import time
# 定义全局变量
g_list = list()
# 添加数据的任务
def add_data():
for i in range(5):
g_list.append(i)
print("add:", i)
time.sleep(0.2)
print("add_data:", g_list)
def read_data():
print("read_data", g_list)
if __name__ == '__main__':
add_data_Thread = threading.Thread(target=add_data)
read_data_Thread = threading.Thread(target=read_data)
add_data_Thread.start()
# 线程同步:add线程结束之后read线程才会开始
add_data_Thread.join()
read_data_Thread.start()
print("main:", g_list)
-----------------------------------------------------------------------
add: 0
add: 1
add: 2
add: 3
add: 4
add_data: [0, 1, 2, 3, 4]
read_data [0, 1, 2, 3, 4]
main: [0, 1, 2, 3, 4]
4、线程安全问题
-
线程间可以访问全局变量,在多个线程间进行数据传递时非常方便,但是随之也会产生很大的问题。
-
当多个线程同时对共享的全局变量进行操作时,可能会出现脏数据的问题。
注意:
- Python 3.9 版本解释器之前,线程安全问题非常明显
- Python 3.10 版本后,引入了新的 GIL2.0 版本的锁,有效的提升了线程安全问题,但某些时刻还需要使用互斥锁保证线程安全。
# 使用多个线程对象,分别对共享全局变量 sum 做一百万次加 1 操作,查看计算结果。
import time
import threading
# 定义全局变量
sum = 0
# 循环一次给全局变量加1
def add_one():
global sum
for i in range(1000000):
sum += 1
print(threading.current_thread().name , " : ", sum)
if __name__ == '__main__':
# 创建3个线程
t1 = threading.Thread(target=add_one)
t2 = threading.Thread(target=add_one)
t3 = threading.Thread(target=add_one)
# 启动线程
t1.start()
t2.start()
t3.start()
time.sleep(3)
print(threading.current_thread().name , " : ", sum)
-----------------------------------------------------------------------------
Thread-2 (add_one) : 2576819
Thread-1 (add_one) : 2704499
Thread-3 (add_one) : 3000000
MainThread : 3000000
错误分析:
多个线程线程对象 t1,t2,t3 都要对全局变量 sum (默认是0)进行加 1 运算,但是由于是多线程同时操作,有可能出现下面情况:
- 在
sum=0时,线程对象t1取得sum=0。 - 此时系统把线程对象
t1调度为sleeping状态 - 把线程对象
t2转换为running状态,t2也获得sum=0 - 然后线程对象
t2对得到的值进行加 1 并赋给sum,使得sum=1 - 然后系统又把线程对象
t2调度为sleeping - 再把线程对象
t1转为running状态 - 线程对象
t1又把它之前得到的 0 加 1 后赋值给sum,结果为sum=1 - 三个线程对象都会在执行过程中出现这种情况
- 这样导致虽然线程对象
t1,t2,t3都对sum加 1,但结果却是产生了无效的计算过程
5、 互斥锁
-
在 Python 中,可以使用互斥锁(Mutex)来保护共享资源,避免多个线程同时对共享资源进行写操作,从而避免竞争条件和数据不一致的问题。
-
使用
threading.Lock()获取互斥锁对象。
lock = threading.Lock()
-
互斥锁操作:
- 加锁操作:
lock.acquire(); - 解锁操作:
lock.release();
- 加锁操作:
使用互斥锁解决线程间数据安全问题。
import time
import threading
# 定义全局变量
sum = 0
# 定义互斥锁
lock = threading.Lock()
def add_one():
global sum
# 加锁
lock.acquire()
for i in range(1000000):
sum += 1
# 解锁
lock.release()
print(threading.current_thread().name , " : ", sum)
if __name__ == '__main__':
# 创建3个线程
t1 = threading.Thread(target=add_one)
t2 = threading.Thread(target=add_one)
t3 = threading.Thread(target=add_one)
# 启动线程
t1.start()
t2.start()
t3.start()
time.sleep(3)
print(threading.current_thread().name , " : ", sum)
-----------------------------------------------------------------------
Thread-1 (add_one) : 1000000
Thread-2 (add_one) : 2000000
Thread-3 (add_one) : 3000000
MainThread : 3000000
6、 死锁
-
虽然使用互斥锁可以解决线程间数据安全问题,但是,如果互斥锁使用不当,会出现死锁现象。
-
死锁是指一个线程获取锁权限后,并未释放锁,导致其它线程无法获取互斥锁的使用权,持续进行等待的过程。
import threading
import time
# 创建互斥锁
lock = threading.Lock()
numbers = [3, 6, 8, 1, 9]
# 根据下标去取值, 保证同一时刻只能有一个线程去取值
def get_value(index):
# 上锁
lock.acquire()
# 判断下标释放越界
if index >= len(numbers):
print(threading.current_thread().name, f"下标 {index} 越界")
# 如果角标越界就return不会往下执行,那么上的锁就没有释放,出现死锁,程序一直等待,知道电脑崩溃
return
value = numbers[index]
print(threading.current_thread().name, "取值为: ", value)
time.sleep(0.2)
# 释放锁
lock.release()
if __name__ == '__main__':
# 模拟大量线程去执行取值操作
for i in range(10):
sub_thread = threading.Thread(target=get_value, args=(i,))
sub_thread.start()
-----------------------------------------------------------------------------
Thread-1 (get_value) 取值为: 3
Thread-2 (get_value) 取值为: 6
Thread-3 (get_value) 取值为: 8
Thread-4 (get_value) 取值为: 1
Thread-5 (get_value) 取值为: 9
Thread-6 (get_value) 下标 5 越界
ps:如果角标越界就return不会往下执行,那么上的锁就没有释放,出现死锁,程序一直等待,直到电脑崩溃
7、 避免死锁
-
程序开发过程中,应该避免死锁的发生。
-
可以在程序的合适位置,将锁释放掉,让其它线程对象有能获取到互斥锁的机会。
import threading
import time
# 创建互斥锁
lock = threading.Lock()
numbers = [3, 6, 8, 1, 9]
# 根据下标去取值, 保证同一时刻只能有一个线程去取值
def get_value(index):
# 上锁
lock.acquire()
# 判断下标释放越界
if index >= len(numbers):
print(threading.current_thread().name, f"下标 {index} 越界")
# 如果角标越界就return不会往下执行,那么上的锁就没有释放,出现死锁,程序一直等待,直到电脑崩溃
# 所以当越界的线程来到这里需要把锁给释放掉,让其他线程可以拿到资源继续运行
lock.release()
return
value = numbers[index]
print(threading.current_thread().name, "取值为: ", value)
time.sleep(0.2)
# 释放锁
lock.release()
if __name__ == '__main__':
# 模拟大量线程去执行取值操作
for i in range(10):
sub_thread = threading.Thread(target=get_value, args=(i,))
sub_thread.start()
------------------------------------------------------------------------
Thread-1 (get_value) 取值为: 3
Thread-2 (get_value) 取值为: 6
Thread-3 (get_value) 取值为: 8
Thread-4 (get_value) 取值为: 1
Thread-5 (get_value) 取值为: 9
Thread-6 (get_value) 下标 5 越界
Thread-7 (get_value) 下标 6 越界
Thread-8 (get_value) 下标 7 越界
Thread-9 (get_value) 下标 8 越界
Thread-10 (get_value) 下标 9 越界
8、 进程与线程对比
(1)关系对比
- 线程是依附在进程里面的,没有进程就没有线程。
- 一个进程默认提供一条线程,进程可以创建多个线程。
(2) 区别对比
- 进程之间不共享全局变量
- 线程之间共享全局变量,但是要注意资源竞争的问题,解决办法: 互斥锁或者线程同步
- 创建进程的资源开销要比创建线程的资源开销要大
- 进程是操作系统资源分配的基本单位,线程是CPU调度的基本单位
- 线程不能够独立执行,必须依存在进程中
- 多进程开发比单进程多线程开发稳定性要强
(3)优缺点对比
- 进程优缺点:
- 优点:可以用多核
- 缺点:资源开销大
- 线程优缺点:
- 优点:资源开销小
- 缺点:不能使用多核(3.10版本后有改善)
四、多任务“协程”编程
1、什么是协程
-
协程,又称微线程,纤程。英文名Coroutine。
-
协程也是一种轻量级的多任务编程技术,它可以在同一个线程中实现多个任务的切换和调度。
-
协程通过任务的暂停和恢复,避免了线程切换的开销并减少了锁的使用。协程常用于异步编程场景,比如网络编程和IO密集型任务。
-
最大的优势就是协程极高的执行效率。因为函数切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,协程数量越多,协程的性能优势就越明显。
-
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
-
比如:一个人在打印资料的等待过程中,又去接听了客户的电话,在接听电话的等待过程中,又整理了桌面。
2、多任务协程编程
- Python 中可以使用第三方模块
gevent实现协程多任务编程。
# pip install gevent
import gevent
(1)、创建协程
-
gevent模块使用spawn类创建协程实例对象,实现协程任务的创建。
spawn(run [, args [, kwargs]])
参数说明:
-
run:执行的目标任务名 -
args:以元组方式给执行任务传参 -
kwargs:以字典方式给执行任务传参
(2) 启动进程
-
协程对象创建成功后,需要使用
join()方法启动协程才会开始执行。 -
该方法的作用是对当前线程进行阻塞,直到协程执行结束后,继续执行当前线程。
import gevent
import threading
import os
def task():
print(f"{threading.current_thread().name}_id:{os.getpid()}")
print(f"{threading.current_thread().name}_pid:{os.getppid()}")
for i in range(1,3):
print(i)
g1 = gevent.spawn(task)
g2 = gevent.spawn(task)
g3 = gevent.spawn(task)
g1.join()
g2.join()
g3.join()
print("main")
---------------------------------------------------
MainThread_id:15368
MainThread_pid:5076
1
2
MainThread_id:15368
MainThread_pid:5076
1
2
MainThread_id:15368
MainThread_pid:5076
1
2
main
(3) 获取当前协程对象
-
gevent.getcurrent()可以获取当前协程对象。
import gevent
import threading
import os
def task():
print(f"{threading.current_thread().name}_id:{os.getpid()}")
print(f"{threading.current_thread().name}_pid:{os.getppid()}")
for i in range(1,3):
print(gevent.getcurrent(),i)
g1 = gevent.spawn(task)
g2 = gevent.spawn(task)
g3 = gevent.spawn(task)
g1.join()
g2.join()
g3.join()
print("main")
--------------------------------------------------
MainThread_id:17116
MainThread_pid:5076
<Greenlet at 0x1ca59869ee0: task> 1
<Greenlet at 0x1ca59869ee0: task> 2
MainThread_id:17116
MainThread_pid:5076
<Greenlet at 0x1ca59e03380: task> 1
<Greenlet at 0x1ca59e03380: task> 2
MainThread_id:17116
MainThread_pid:5076
<Greenlet at 0x1ca5b7b1d00: task> 1
<Greenlet at 0x1ca5b7b1d00: task> 2
main
Process finished with exit code 0
(4)协程组
- 在创建多个协程对象后,可以将多个协程对象放入一个元组或列表中,然后使用
gevent.joinall()方法同时启动协程对象。
import gevent
def task():
for i in range(1,3):
print(gevent.getcurrent(), i)
# 使用列表推导式,生成一个有5个协程对象的列表
gs = [gevent.spawn(task) for i in range(5)]
gevent.joinall(gs)
-----------------------------------------------------------
<Greenlet at 0x1bd14f99ee0: task> 1
<Greenlet at 0x1bd14f99ee0: task> 2
<Greenlet at 0x1bd15558860: task> 1
<Greenlet at 0x1bd15558860: task> 2
<Greenlet at 0x1bd15558720: task> 1
<Greenlet at 0x1bd15558720: task> 2
<Greenlet at 0x1bd16ea9940: task> 1
<Greenlet at 0x1bd16ea9940: task> 2
<Greenlet at 0x1bd16ea99e0: task> 1
<Greenlet at 0x1bd16ea99e0: task> 2
(5) 协程切换
-
从前面的代码执行结果看,虽然可以执行多个协程任务,但是任务的执行过程依然是同步的。
-
可以通过在代码中添加
gevent.sleep()方法模拟耗时操作,实现协程任务的切换。
注意: sleep() 方法是 gevent 模块中的,不是 time 模块中的。
import gevent
def task():
for i in range(1,3):
print(gevent.getcurrent(), i)
gevent.sleep(0.001)
# 使用列表推导式,生成一个有5个协程对象的列表
gs = [gevent.spawn(task) for i in range(5)]
gevent.joinall(gs)
---------------------------------------------------------------
<Greenlet at 0x20c43879ee0: task> 1
<Greenlet at 0x20c43df8860: task> 1
<Greenlet at 0x20c43df8720: task> 1
<Greenlet at 0x20c45749940: task> 1
<Greenlet at 0x20c457499e0: task> 1
<Greenlet at 0x20c43879ee0: task> 2
<Greenlet at 0x20c43df8860: task> 2
<Greenlet at 0x20c43df8720: task> 2
<Greenlet at 0x20c45749940: task> 2
<Greenlet at 0x20c457499e0: task> 2
(6) 协程任务函数传参
-
在创建协程对象的时候,为协程任务函数传递参数,可以使用两种方式为任务函数传参。
-
协程的任务函数传参与进程和线程不同,协程可以和直接使用函数一样,在
spawn方法中为任务函数传参。
import gevent
def task(n, msg):
for i in range(1,n+1):
print(gevent.getcurrent(), f"第 {i} 次输出 {msg}")
gevent.sleep(0.001)
g1 = gevent.spawn(task,5, "Python")
g2 = gevent.spawn(task, msg="Hogwarts", n=5)
g1.join()
g2.join()
--------------------------------------------------------------------------
<Greenlet at 0x188ad8a04a0: task(5, 'Python')> 第 1 次输出 Python
<Greenlet at 0x188ae0487c0: task(msg='Hogwarts', n=5)> 第 1 次输出 Hogwarts
<Greenlet at 0x188ad8a04a0: task(5, 'Python')> 第 2 次输出 Python
<Greenlet at 0x188ae0487c0: task(msg='Hogwarts', n=5)> 第 2 次输出 Hogwarts
<Greenlet at 0x188ad8a04a0: task(5, 'Python')> 第 3 次输出 Python
<Greenlet at 0x188ae0487c0: task(msg='Hogwarts', n=5)> 第 3 次输出 Hogwarts
<Greenlet at 0x188ad8a04a0: task(5, 'Python')> 第 4 次输出 Python
<Greenlet at 0x188ae0487c0: task(msg='Hogwarts', n=5)> 第 4 次输出 Hogwarts
<Greenlet at 0x188ad8a04a0: task(5, 'Python')> 第 5 次输出 Python
<Greenlet at 0x188ae0487c0: task(msg='Hogwarts', n=5)> 第 5 次输出 Hogwarts
(7) 协程异步
-
在 Python 中,Gevent 的 monkey patch 是指使用 Gevent 的模块
gevent.monkey中的patch_all()等方法,来替换标准库中的一些阻塞式 I/O 操作,以实现非阻塞式的协程 I/O。 -
一般该方法写在程序的第一行。
from gevent import monkey
# 该方法一般写在第一行
monkey.patch_all()
import gevent
import random
import asyncio
def task(n, msg):
for i in range(1,n+1):
print(gevent.getcurrent(), f"第 {i} 次输出 {msg}")
gevent.sleep(random.random())
g1 = gevent.spawn(task,5, "Python")
g2 = gevent.spawn(task, msg="Hogwarts", n=5)
g3 = gevent.spawn(task, n=5, msg="Hello")
gevent.joinall((g1,g2,g3))
说明:
-
在 Python 3.10 版本中,Gevent 的 monkey patch 功能在某些情况下可能无效。这是因为在 Python 3.10 中引入了
asyncio的新的事件循环机制,与 Gevent 的事件循环有所不同,导致 monkey patch 在有些情况下失效。 -
Gevent 官方还没有正式发布兼容 Python 3.10 版本的版本,因此在 Python 3.10 中使用
monkey.patch_all()方法可能无法正常实现非阻塞的协程 I/O。 -
为了解决这个问题,你可以考虑使用 Python 3.10 引入的 asyncio 模块来进行异步编程。
-
asyncio 提供了原生的协程和事件循环,可以实现高效的异步操作。
五、网络编程
网络编程是指利用计算机网络进行数据传输和通信的编程技术。
在网络编程中,使用编程语言和相关的网络协议来建立连接、传输数据、处理请求和响应等。
常见的网络编程涉及以下几个方面:
- Socket编程:Socket是一种抽象的网络通信接口,可以用于在不同计算机之间建立通信连接。通过Socket编程,可以实现客户端和服务器之间的数据传输和通信。
- 网络协议:网络协议是用于规定计算机之间通信的规则和约定。例如,HTTP(超文本传输协议)用于在Web浏览器和Web服务器之间传输数据,TCP/IP(传输控制协议/互联网协议)用于在网络上传输数据包等。
- 客户端和服务器:在网络编程中,通常会涉及到客户端和服务器的概念。客户端是发起请求的一方,服务器是接收和处理请求的一方。客户端通过网络连接到服务器,发送请求并接收服务器的响应。
- 数据传输和通信:网络编程可以通过套接字(Socket)来实现数据的传输和通信。客户端可以向服务器发送请求,并接收服务器返回的响应数据。这可以包括发送和接收文本、图像、音频、视频等不同类型的数据。
- 并发与多线程:网络编程中,需要考虑多个客户端和服务器同时连接和通信的情况。使用多线程技术可以实现并发处理多个连接和请求,提高系统的性能和响应速度。
总的来说,网络编程是基于计算机网络进行数据传输和通信的编程技术。通过网络编程,可以实现客户端和服务器之间的连接和数据传输,实现各种网络应用程序。
1、前言-关于socket和websocket
Socket其实并不是一个协议,而是为了方便使用TCP或UDP而抽象出来的一层,是位于应用层和传输控制层之间的一组接口。
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
当两台主机通信时,必须通过Socket连接,Socket则利用TCP/IP协议建立TCP连接。TCP连接则更依靠于底层的IP协议,IP协议的连接则依赖于链路层等更低层次。
区别:Socket是传输控制层协议,WebSocket是应用层协议。
2、 IP地址与端口
IP地址
IP 地址用来标识网络中设备的一串数字编号。也就是说通过IP地址能够找到网络中某台设备。
IP 地址分为两类: IPv4 和 IPv6
- IPv4 是目前使用的ip地址,是由点分十进制组成。
- IPv6 是未来使用的ip地址,是由冒号十六进制组成
端口
端口是计算机网络中用于标识不同网络应用程序或服务的数字标识。每个网络应用程序或服务都会使用一个特定的端口号,以便其他设备通过网络与该应用程序或服务进行通信,当想要通过网络访问某个服务或应用程序时,需要指定目标设备的IP地址和端口号。
端口的分类
端口号是一个16位的数字,共有65536个可用端口,范围从0到65535。一般可划分为系统端口和动态端口。
- 系统端口是指范围从0到1023的端口号,常用于一些标准的服务和协议。
- 动态端口是指范围从1024到65535的端口号,用于自定义应用程序和临时连接。
但是,一些主流的第三方软件所使用的端口,默认在使用时,也应该避开,比如:MySQL 的3306端口,Reids 的6379端口等。
3、 通信协议
通信协议是用于在计算机网络上进行数据传输和交换的规则和约定。它定义了在通信过程中数据的格式、编码方式、传输速率、错误检测和纠正方法等。
通信协议可以分为多个层级,通常采用分层模型,最著名的是TCP/IP协议栈。每一层都有不同的功能和责任,通过交互和协调实现端到端的可靠通信。
例如,TCP/IP协议栈包括以下层级:
- 应用层:定义应用程序之间的通信规则,例如HTTP、FTP、SMTP等协议。
- 传输层:提供端到端的数据传输服务,包括TCP和UDP等协议,负责数据的分割、传输控制、错误检测和流量控制等。
- 网络层:处理网络间的数据传输和路由,例如IP协议。负责将数据包从源主机传输到目标主机,通过IP地址实现寻址和路由选择。
- 数据链路层:处理相邻节点之间的数据传输,负责定义数据的格式和封装,以太网协议就是其中的一种。
- 物理层:负责在物理媒介上传输比特流,例如通过电缆或无线信号传输数据。
TCP 协议
TCP 的英文全拼(Transmission Control Protocol)简称传输控制协议,它是一种面向连接的、可靠的、基于字节流的传输层通信协议。
TCP 协议特点
- 面向连接
- 通信双方必须先建立好连接才能进行数据的传输,数据传输完成后,双方必须断开此连接,以释放系统资源。
- 可靠传输
- TCP 采用发送应答机制
- 超时重传
- 错误校验
- 流量控制
- 阻塞管理
HTTP协议
HTTP(Hypertext Transfer Protocol)超文本传输协议,是一种用于在Web浏览器和Web服务器之间传输数据的协议。它是一个应用层协议,基于TCP/IP协议栈。
HTTP使用请求-响应模型,客户端(通常是Web浏览器)发送HTTP请求到Web服务器,服务器接收并处理请求,然后返回相应的HTTP响应给客户端。通过这种方式,HTTP实现了客户端和服务器之间的通信和数据交换。
HTTP报文格式
- 请求报文
| 组成 | 说明 |
|---|---|
| 请求行 | 请求方法 请求路径以及get请求参数 请求协议版本 |
| 请求头 | 以key-value形式描述,每行以\r\n结束 |
| 空行 | \r\n |
| 请求体 | 请求时携带的数据,GET请求方式没有此部分 |
- 响应报文
| 组成 | 说明 |
|---|---|
| 响应行 | 响应协议版本 响应状态码 响应状态描述短语 |
| 响应头 | 以key-value形式描述的请求信息,每行以\r\n结束 |
| 空行 | \r\n |
| 响应体 | 服务器返回给客户端的数据 |
4、socket编程
Socket编程是一种网络编程的技术,用于实现不同设备之间的数据通信。
它提供了一种基于TCP或UDP协议的接口,使得程序可以通过网络套接字(socket)进行数据的发送和接收。
通过Socket编程,可以在不同主机之间建立网络连接,进行双向的数据传输。Socket编程通常涉及两个角色:客户端和服务器。
在Socket编程中,服务器会创建一个监听套接字(listening socket),用于接收来自客户端的连接请求。一旦服务器接受了客户端的连接请求,它会创建一个新的套接字(socket)与客户端进行数据的交换。
客户端会创建一个套接字(socket),并向服务器发起连接请求。一旦服务器接受了该请求,客户端和服务器之间就可以进行数据的传输。
Socket编程提供了一组函数和方法,用于创建套接字、设置连接参数、发送和接收数据等操作。
常见的编程语言,如C、Python、Java等都提供了相应的Socket库和API,供开发者进行Socket编程。
通过Socket编程,可以实现各种类型的网络应用,包括像HTTP、FTP、SMTP等基于各种协议的应用。它也可以用于实现自定义的网络通信,例如实时通信、游戏服务器等。
需要注意的是,Socket编程是一种底层的网络编程技术,需要开发者有一定的网络编程基础和对网络通信原理的了解。
5、socket开发流程
Python 中使用 socket 模块完成网络编程,该模块是系统模块,直接导入即可使用。
Socket客户端及服务端开发流程如图所示:
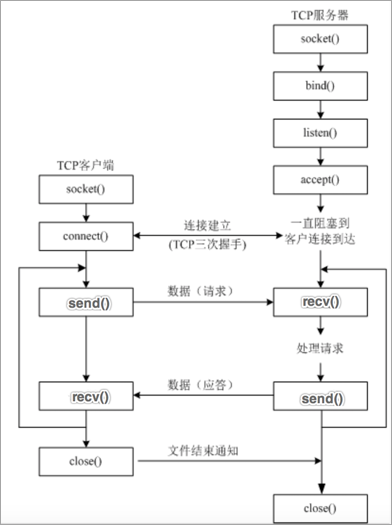
(1) Socket 客户端开发流程
- 创建客户端套接字对象
- 和服务端套接字建立连接
- 向服务端发送数据
- 从服务端接收数据
- 关闭客户端套接字
案例:
# 导入 socket 模块
import socket
# 创建tcp客户端套接字
# 1. AF_INET:表示ipv4
# 2. SOCK_STREAM: tcp传输协议
tcp_client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 和服务端应用程序建立连接
tcp_client_socket.connect(("192.168.5.65", 8888))
# 代码执行到此,说明连接建立成功
# 准备发送的数据
send_data = "你好,我是哈利波特!".encode("gbk")
# 向服务端发送数据
tcp_client_socket.send(send_data)
# 从服务端接收数据, 这次接收的数据最大字节数是1024
recv_data = tcp_client_socket.recv(1024)
# 返回的直接是服务端程序发送的二进制数据
print(recv_data)
# 对数据进行解码
recv_content = recv_data.decode("gbk")
print("接收服务端的数据为:", recv_content)
# 关闭套接字
tcp_client_socket.close()
代码调试
由于只编写了客户端,而没有服务端,此时的代码是无法自验证的,需要借助一个外部工具【网络调试助手】进行程序验证。(该软件需自行搜索下载安装,不同系统间软件界面有些许差异,功能基本一致)
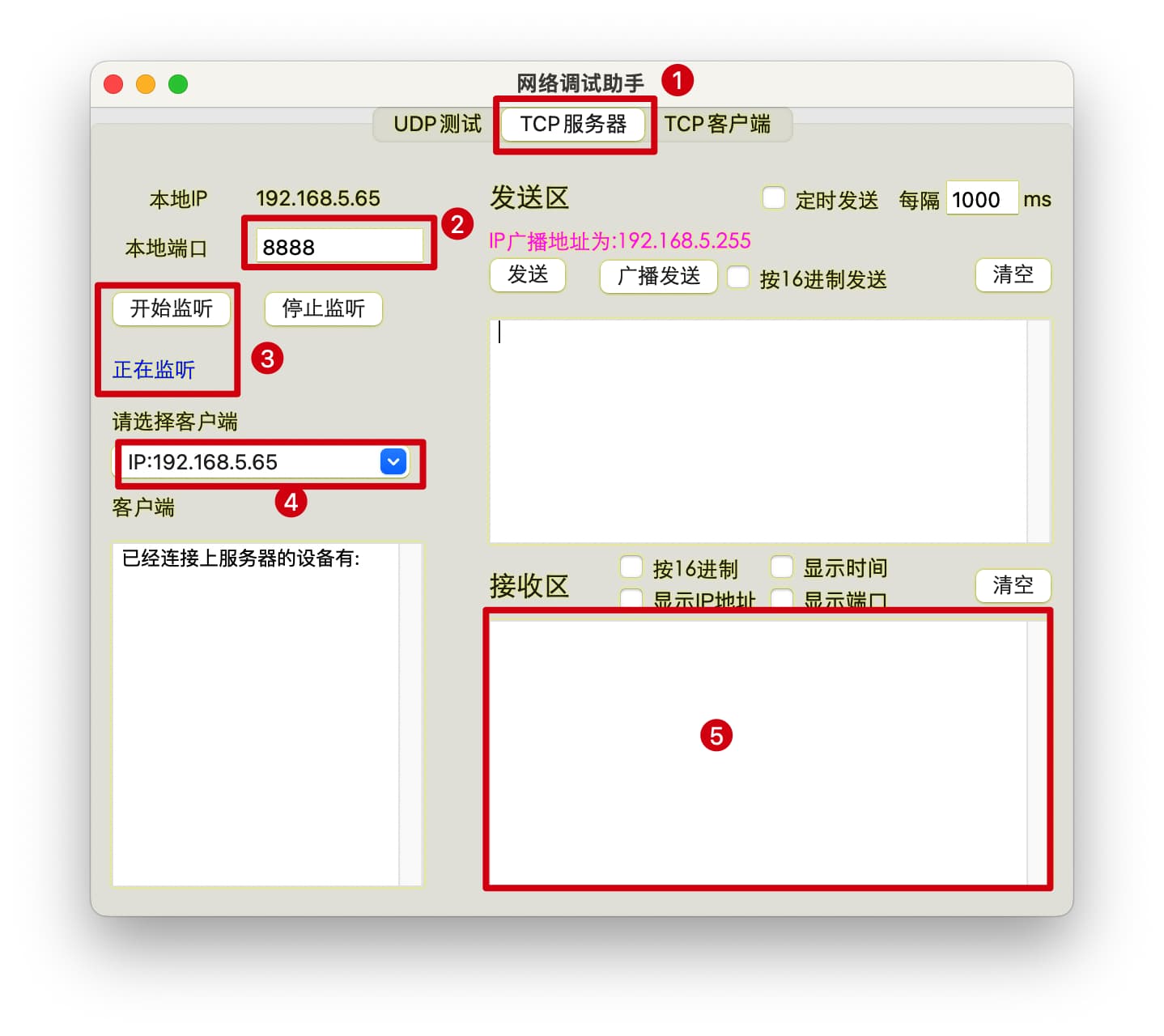
- 选择服务器类型为TCP服务器
- 设置服务器运行端口号
- 点击按钮开始监听,状态显示正在监听,等待客户端的连接请求
- 运行客户端程序后,服务助手会将正在连接的客户端IP地址显示在此
- 接收区显示客户端发送给服务端的数据
各阶段注意事项
-
创建客户端套接字对象
- 目前主流使用的IP分类还是IPv4
- 指定通信方式为TCP方式,此时数据传递使用的是二进制字节流
- socket方法的两个参数都可以省略,默认使用IPv4建立TCP方式的套接字
-
和服务端套接字建立连接
- 连接服务器时,需要指定服务器IP和端口号,需要向服务器确认,添入正确数据
- IP与端口需要使用元组形式传入
-
向服务端发送数据
- 程序中的默认字符串数据,都是str类型,不能直接进行传输。
- TCP方式传输数据必须是二进制数据。
- 需要将要传输的数据使用
encode()方法进行数据编码,转换成二进制数据
-
从服务端接收数据
- 服务端发送给客户端的数据,也是使用二进制方式进行传输的,所以需要使用
decode()方法对数据解码
- 服务端发送给客户端的数据,也是使用二进制方式进行传输的,所以需要使用
-
关闭客户端套接字
- 数据传输结束后,需要将连接进行关闭
(2) Socket 服务端开发流程
- 创建服务端端套接字对象
- 设置端口复用
- 绑定服务端口号
- 设置监听
- 等待接受客户端的连接请求
- 接收客户端发送数据
- 向客户端发送数据
- 关闭套接字
案例:
import socket
# 创建tcp服务端套接字
tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置端口号复用,让程序退出端口号立即释放
tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
# 给程序绑定端口号
tcp_server_socket.bind(("", 8888))
# 设置监听
tcp_server_socket.listen(128)
print("服务端启动成功,等待客户端连接。。。")
# 等待客户端建立连接的请求, 只有客户端和服务端建立连接成功代码才会解阻塞,代码才能继续往下执行
# 1. 专门和客户端通信的套接字: client_socket
# 2. 客户端的ip地址和端口号: ip_port
client_socket, ip_port = tcp_server_socket.accept()
# 代码执行到此说明连接建立成功
print("客户端的ip地址和端口号:", ip_port)
# 接收客户端发送的数据, 这次接收数据的最大字节数是1024
recv_data = client_socket.recv(1024)
# 获取数据的长度
recv_data_length = len(recv_data)
print("接收数据的长度为:", recv_data_length)
# 对二进制数据进行解码
recv_content = recv_data.decode("gbk")
print("接收客户端的数据为:", recv_content)
# 准备发送的数据
send_data = f"你好,{ip_port[0]}".encode("gbk")
# 发送数据给客户端
client_socket.send(send_data)
# 关闭服务与客户端的套接字, 终止和客户端通信的服务
client_socket.close()
# 关闭服务端的套接字, 终止和客户端提供建立连接请求的服务
tcp_server_socket.close()
代码调试
服务端代码调试时,可以使用之前编写的客户端代码,也可以使用网络调试助手。
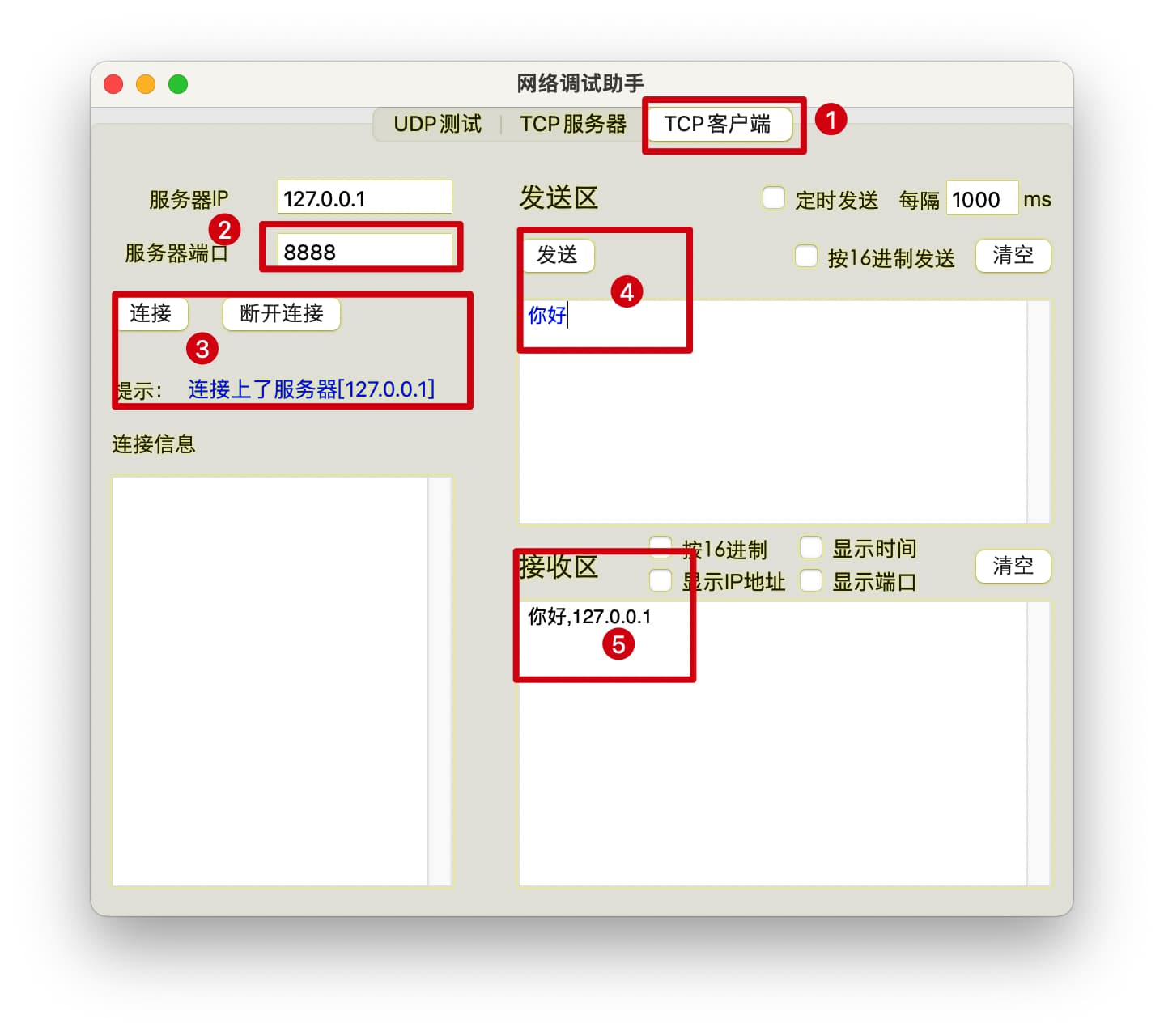
- 选择TCP客户端
- 设置端口号为服务器绑定的端口
- 点击连接按钮,连接状态显示连接成功
- 在发送区向服务器发送数据
- 在接收区显示服务器发送的数据
注意事项
- 创建服务端端套接字对象
- 同创建客户端一样,需要指定IP类型和服务器传输协议类型
- 设置端口复用
- 端口在停止使用后的一段时间内是不能重新启用的
- 为了方便调试程序,设置socket选项,可以立即启用端口
- 绑定服务端口号
- 服务器的端口号应该绑定一个固定端口号,方便客户端连接
- 设置监听
- 设置监听后,服务器socket变成被动模式,不能使用服务器socket收发消息
- 128:最大等待建立连接的个数
- 等待接受客户端的连接请求
- 服务器进入到阻塞状态,直到有客户端连接
- 接收到客户端请求连接后,返回客户端socket对象及客户端IP和端口
- 接收客户端发送数据
- 使用客户端socket对象接收客户端向服务端发送的数据
- 数据需要进行解码使用
- 向客户端发送数据
- 使用客户端socket对象向客户端发送数据
- 数据需要进行编码使用
- 关闭套接字
- 数据发送完毕后,服务器可以使用客户端socket对象将客户端连接断开
- 服务端socket视情况断开连接
6、 多任务服务端
结合多任务实现可以多个客户端同时访问的服务端。
案例:
import socket
import threading
class MultiTaskTCPServer(object):
# 在初始化方法中对服务端socket进行初始化操作
def __init__(self,ip="", port=8888):
# 创建tcp服务端套接字
self.server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 设置端口号复用,让程序退出端口号立即释放
self.server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
# 绑定端口号
self.server.bind((ip, port))
# 设置监听, listen后的套接字是被动套接字,只负责接收客户端的连接请求
self.server.listen(128)
# 启动服务器方法,实现多任务接受处理客户端连接请求
def run(self):
# 循环等待接收客户端的连接请求
while True:
# 等待接收客户端的连接请求
client_socket, ip_port = self.server.accept()
print("客户端连接成功:", ip_port)
# 当客户端和服务端建立连接成功以后,需要创建一个子线程,不同子线程负责接收不同客户端的消息
sub_thread = threading.Thread(target=self.handle_client_request, args=(client_socket, ip_port))
# 设置守护主线程
sub_thread.setDaemon(True)
# 启动子线程
sub_thread.start()
# tcp服务端套接字可以不需要关闭,因为服务端程序需要一直运行
tcp_server_socket.close()
# 处理客户端的请求操作
def handle_client_request(self, client, ip_port):
# 接收客户端发送的数据并解码
recv_data = client.recv(1024).decode("gbk")
# 如果接收的数据长度为0,说明客户端主动断开了连接
if len(recv_data) == 0:
print("客户端下线了:", ip_port)
return
print(recv_data, ip_port)
# 将客户端发送的数据转换成大写并编码后发送给客户端
send_data = recv_data.upper().encode("gbk")
client.send(send_data)
# 终止和客户端进行通信
client.close()
if __name__ == '__main__':
# 创建服务器对象
server = MultiTaskTCPServer(port=9999)
# 启动服务器
server.run()
7、使用socket手搓一个web服务
(1)案例一:实现服务器返回静态页面
(2)案例二:实现学生信息管理web服务
需求: 实现一个学生管理系统的简单 Web 服务器
项目简介
Web 服务器是一种比较常见的网络服务形式,所有的网站,应用等都会有服务器做为后台,向客户端提供数据。
通过本项目从零打造一个Web服务器,从中了解 Web 服务器的工作原理。
实现方式
以面向对象思想完成代码开发。
知识点
- 多任务编程
- 网络编程
- 网络基础理论
- JSON 数据
- Python面向对象、装饰器
项目要求
通过 Web 服务器,提供对学生数据的增删改查等功能接口
- 以面向对象方式实现
- 使用字典表示学生信息,不需要封装学生类
- 实现增删改查接口,返回 json 格式数据
- 请求方式:
- 数据需要使用文件 db.txt 进行持久化存储,并保证数据的有效性
功能拆解
- 定义 WebServer 类,用来实现 Web 服务器
- 实现实始化方法,定义socket服务器对象
- 实现 run 方法,使用多任务处理客户端请求
- 实现 handleClicentRequest 方法,用来做为子任务的响应方法,处理客户端请求
- 实现 parseRequest 方法,用来解析请求报文
- 参数:recv_data 接收请求报文
- 返回值:将解析后的数据以字典形式返回
- 实现 router 方法,用来实现路由功能
- 参数:解析后的请求报文 数据
- 返回值:调用接口方法后,完成的响应报文字符串
- 实现 addStudent 方法,用来处理添加数据请求
- 参数:解析后的请求报文数据
- 返回值:以 JSON 格式返回添加后的所有数据
- 实现 changeStudent 方法,用来处理修改数据请求
- 参数:解析后的请求报文数据
- 返回值:以 JSON 格式返回修改后的所有数据
- 实现 delStudent 方法,用来处理添加数据请求
- 参数:解析后的请求报文数据
- 返回值:以 JSON 格式返回删除后的所有数据
- 实现 queryStudent 方法,用来处理添加数据请求
- 参数:解析后的请求报文数据
- 返回值:以 JSON 格式返回查询到的数据
- 实现 save_data 方法,用来在每次改变数据的请求后,保存数据
- 实现 load_data 方法,用来在每次请求时,加载最新数据
相关知识点
- Socket 编程
- 多任务线程编程
- HTTP 协议
- python 面向对象
- 装饰器
- 接口函数
- 持久化存储
实战内容
- 优化 web 服务器为面向对象的方式。
- 完善路由表的维护。
- 使用学生信息管理系统实现。
- 实现数据的持久化存储。
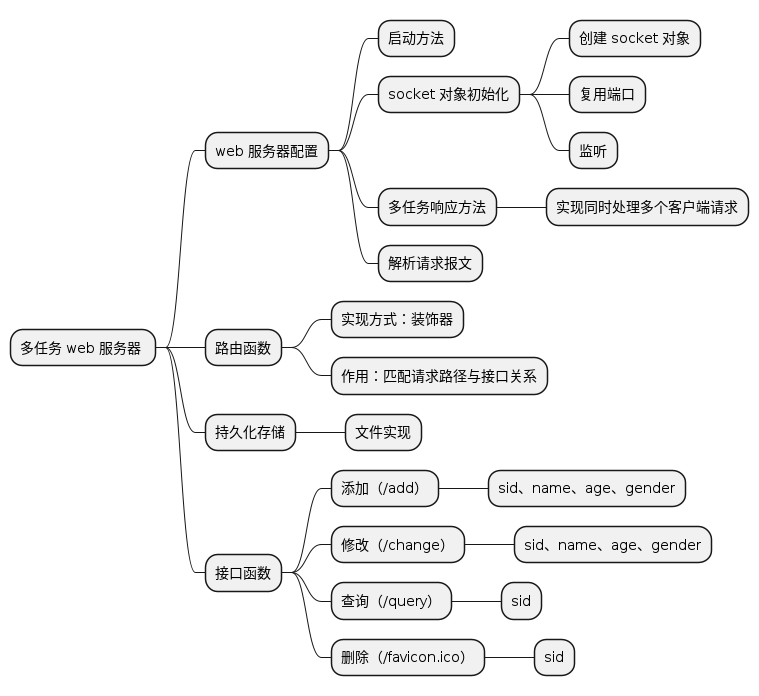
实现思路
实现代码
- 将课程中的代码优化为面向对象实现。
- 使用装饰器优化路由表的实现。
- 完善学生管理系统接口函数的优化。
- 使用文件实现持久化存储。
Web服务器实现
Web 服务器配置包含以下几部分:
- 初始化( _ init _ ):
- 初始化服务,监听socket,设置参数等
- 请求处理( _ _handleClientRequest):
- 接收请求、解析请求报文、提取请求信息。
- 并发处理:处理多个客户端的并发请求,通过多线程实现
- 生成响应( _ _parseRequest):
- 构造HTTP响应报文、将结果返回给客户端。
- 路由( _ _router):
- 根据请求的 URL 确定应该调用的处理函数,实现请求的路由。
- 启动(run):
- 配置多线程,实现多任务响应。
# 服务器类
class WebServer(object):
def __init__(self):
self.__data = []
# 1. 创建一个socket对象
self.__server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 2. 复用端口
self.__server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
# 3. 绑定端口
self.__server.bind(("", 8888))
# 4. 设置监听
self.__server.listen(128)
print("服务器使用 127.0.0.1:8888 启动成功... ")
# 启动方法
def run(self):
while True:
# 5. 接收客户端的请求
client, addr = self.__server.accept()
print(f"客户端 {addr[0]} 使用{addr[1]} 端口连接成功...")
# 创建一个子任务,用来去处理客户端的请求
t = threading.Thread(target=self.__handleClientRequest, args=(client,))
t.daemon = True
t.start()
# 多任务响应方法,用来处理客户端请求
def __handleClientRequest(self, client):
# 接收消息
recv_data = client.recv(4096).decode("utf-8")
# 判断客户端 是否主动断开连接
if len(recv_data) == 0:
client.close()
return
# 解析请求报文
request = self.__parseRequest(recv_data)
# 调用路由函数,获取响应数据
response = self.__router(request)
# 返回响应数据给客户端
client.send(response)
# 关闭连接
client.close()
# 解析请求报文的方法
def __parseRequest(self, recv_data):
# 用来保存请求报文的信息
request = {
"method": "",
"path": "",
"values": {}
}
# 解析请求报文中请求行的内容,格式如下
# GET /index?name=tom&age=12&gender=male HTTP/1.1
# 通过请求报文 ,获取请求路径,通过路径找到对应的接口处理函数
recv_data = recv_data.split()
# 提取请求方法
request["method"] = recv_data[0]
# 提取请求资源路径
path = recv_data[1]
# 判断是否有查询参数
if "?" in path:
tmp = path.split("?")
# 提取请求路径
path = tmp[0]
# 提取查询参数
params = tmp[1].split("&")
# 解析查询参数
for s in params:
# 分解参数并将数据保存到 request
k, v = s.split("=")
request["values"][k] = v
# 保存请求路径到 request
request["path"] = path
# 返回解析结果
return request
# 路由函数,用来匹配请求路径与接口关系
def __router(self, request):
# 从解析的请求报文中获取请求路径
path = request.get("path")
# 匹配路由
interface = router_table.get(path)
# 调用接口,接收响应数据
response_body = interface(self, request)
# 服务器要去做响应(给客户端发响应报文)
response = "HTTP/1.1 200 OK\r\n"
# 接口返回的都是json数据,所以响应数据类型使用 json 格式
response += "Content-Type: application/json\r\n"
response += "Server: MyServer V1.0\r\n"
response += "\r\n"
# 拼接响应报文
response += response_bod
return response.encode()
路由表实现
使用装饰器将路径与处理函数的实现绑定。
# 路由表
router_table = {}
# 装饰器维护路由表
def router(path):
def wrapper(func):
def inner(self, *args, **kwargs):
print("Run....")
return func(self, *args, **kwargs)
router_table[path] = inner
print(router_table)
return inner
return wrapper
持久化存储
# 向文件中写入数据,进行持久化存储
def __saveData(self):
with open("db.txt", "w") as file:
for s in self.__data:
s_str = f"{s['sid']}-{s['name']}-{s['age']}-{s['gender']}\n"
file.write(s_str)
# 从文件中读取数据,加载到内存
def __loadData(self):
# 清除之间的数据
self.__data.clear()
# 判断数据源文件是否存在
if os.path.exists("db.txt"):
with open("db.txt", "r") as file:
# 读取文件按行分割
content = file.read().split()
for s in content:
# 将每行按 - 分割,得到每个元素值
s = s.split("-")
# 组装成字典,因为此处需要使用 json,自定义类对象无法直接转josn,所以使用字典
stu = {"sid": s[0], "name": s[1], "age": s[2], "gender": s[3]}
self.__data.append(stu)
接口函数
实现学生管理系统需要包含四个处理函数,分别为:
- 添加( _ _addStudent)
- 修改( _ _changeStudent)
- 查询( _ _queryStudent)
- 删除( _ _delStudent)
此外,还额外增加了两个路由:根路由和处理谷歌浏览器标签请求的路由。
# 请求方式地址格式 /add?sid=s07&name=lucy&age=23&gender=male
@router('/add')
def __addStudent(self, request):
# 因为服务器永远不会退出,所以在每一次接口操作时,都去读取和写入文件,保证数据的有效性
self.__loadData()
# 读取请求参数
sid = request["values"]["sid"]
name = request["values"]["name"]
age = int(request["values"]["age"])
gender = request["values"]["gender"]
for s in self.__data:
# 存在不能添加新生
if s["sid"] == sid:
break
else:
# 不存在添加新生
obj = {"sid": sid, "name": name, "age": age, "gender": gender}
self.__data.append(obj)
# 持久化存储最新数据
self.__saveData()
# 将数据 json 化返回
return json.dumps(self.__data)
# 请求方式地址格式 /change?sid=s07&name=lucy&age=23&gender=male
@router('/change')
def __changeStudent(self, request):
self.__loadData()
sid = request["values"]["sid"]
for s in self.__data:
if s["sid"] == sid:
s["name"] = request["values"]["name"]
s["age"] = int(request["values"]["age"])
s["gender"] = request["values"]["gender"]
break
self.__saveData()
return json.dumps(self.__data)
# 请求方式地址格式 /query?sid=s01
@router('/query')
def __queryStudent(self, request):
# 查询只需要重新加载,不用写入,因为没有修改数据
self.__loadData()
sid = request["values"]["sid"]
for s in self.__data:
if s["sid"] == sid:
return json.dumps(s)
# 请求方式地址格式 /del?sid=s01
@router('/del')
def __delStudent(self, request):
self.__loadData()
sid = request["values"]["sid"]
for s in self.__data:
if s["sid"] == sid:
self.__data.remove(s)
break
self.__saveData()
return json.dumps(self.__data)
@router('/')
def __index(self, request):
return json.dumps(self.__data)
# 这个接口用来处理 谷歌浏览器的标签图标请求,可
@router("/favicon.ico")
def __favicon(self,request):
return ""
总结
- 通过装饰器,简化请求路径与处理函数之间的关联逻辑。
- 使用 socket 模块实现基本的网络通信,实现建立服务器和客户端之间的连接。
- 通过学生管理系统深入理解面向对象编程的思想。
