一, CSS高级定位
1,css 定位场景
2,css 定位的调试方法
- 进入浏览器的console
- 输入:
$("css表达式")- 或者
$("css表达式")
3, css基础语法

//在console中的写法
// https://www.baidu.com/
//标签名
$('input')
//.类属性值
$('.s_ipt')
//#id属性值
$('#kw')
//[属性名='属性值']
$('[name="wd"]')
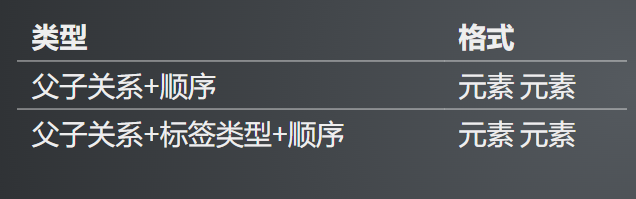
4, css关系定位

/在console中的写法
//元素,元素
$('.bg,.s_ipt_wr,.new-pmd,.quickdelete-wrap')
//元素>元素
$('#s_kw_wrap>input')
//元素 元素
$('#form input')
//元素+元素,了解即可
$('.soutu-btn+input')
//元素1~元素2,了解即可
$('.soutu-btn~i')
5,css 顺序关系
//:nth-child(n) - 它找的是ember15的第几个元素
$("#ember15>ul>li:nth-child(3)")
//:nth-of-type(n) - 当查询的元素有多个类型时,精确定位用这种
$('#form>input:nth-of-type(1)')
二, XPATH高级定位
1, xpath基本概念
- XPath 是一门在 XML 文档中查找信息的语言
- XPath 使用路径表达式在 XML 文档中进行导航
- XPath 的应用非常广泛
- XPath 可以应用在UI自动化测试
2,xpath 定位场景
3,xpath 定位的调试方法
4,xpath 基础语法(包含关系)
- nodename为标签名
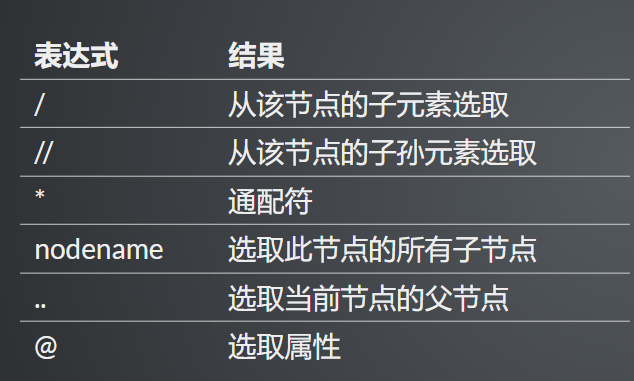
# 整个页面
$x("/")
# 页面中的所有的子元素
$x("/*")
# 整个页面中的所有元素
$x("//*")
# 查找页面上面所有的div标签节点
$x("//div")
# 查找id属性为site-logo的节点
$x('//*[@id="site-logo"]')
# 查找节点的父节点
$x('//*[@id="site-logo"]/..')
# 查找节点的父节点的父节点
$x('//*[@id="site-logo"]/../..')
5,xpath 顺序关系(索引)
# 获取此节点下的所有的li元素
$x("//*[@id='ember21']//li")
# 获取此节点下【所有的节点的】第一个li元素
$x("//*[@id='ember21']//li[1]")
6, xpath 高级用法

# 选取最后一个input标签
//input[last()]
#选取id='main-container下最后一个div标签
//$x("//*[@id='main-container']//div[last()]")
# 选取属性name的值为passward并且属性pwd的值为123456的input标签
//input[@name='passward' and @pwd='123456']
# 选取满足属性class和属性id值的标签
$x("//*[@class='topic-list-item category-studynotes ember-view' and @id='ember269']")
# 选取属性name的值为passward或属性pwd的值为123456的input标签
//input[@name='passward' or @pwd='123456']
# 选取满足属性class或者属性id值的标签
$x("//*[@class='topic-list-item category-studynotes ember-view' and @id='ember269']")
# 选取所有文本信息为'霍格沃兹测试开发'的元素
//*[text()='霍格沃兹测试开发']
# 选取所有文本信息为'每日一题0922】数字造型'的元素
$x("//*[text()='【每日一题0922】数字造型']")
# 选取所有文本信息包'霍格沃兹'的元素
//*[contains(text(),'霍格沃兹')]
# 选取所有文本信息包含'jck28 - 小柒'的元素
$x("//*[contains(text(),'jck28 - 小柒')]")
