代码报错行数
最后的报错类型:
E selenium.common.exceptions.StaleElementReferenceException: Message: Cached elements ‘By.xpath: //android.widget.ListView/android.widget.RelativeLayout’ do not exist in DOM anymore
代码github 地址
https://github.com/archerckk/hogwarts/tree/master/appium_hw
求各位大佬支个招TAT
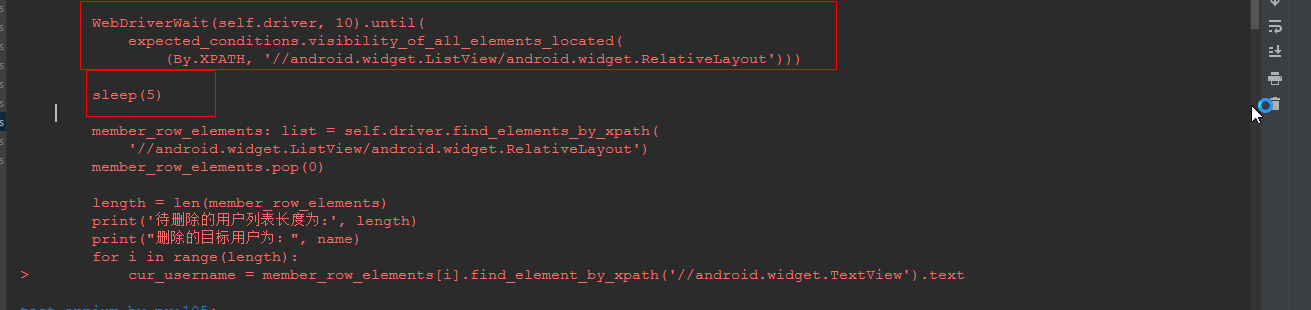
原来代码:
WebDriverWait(self.driver, 10).until(
expected_conditions.visibility_of_all_elements_located(
(By.XPATH, ‘//android.widget.ListView/android.widget.RelativeLayout’)))
sleep(5)
member_row_elements: list = self.driver.find_elements_by_xpath(
'//android.widget.ListView/android.widget.RelativeLayout')
member_row_elements.pop(0)
length = len(member_row_elements)
print('待删除的用户列表长度为:', length)
print("删除的目标用户为:", name)
for i in range(length):
cur_username = self.driver.find_elements_by_xpath(
'//android.widget.ListView/android.widget.RelativeLayout//android.widget.TextView')[i].text
print("获取到的用户名信息为:", cur_username)
if name == cur_username:
image_icon_element_list = member_row_elements[i].find_elements_by_xpath('//android.widget.ImageView')
print('icon列表', image_icon_element_list)
image_icon_element_list[1].click()
self.driver.find_element_by_xpath('//*[@text="删除成员"]').click()
self.driver.find_element_by_xpath('//*[@text="确定"]').click()
else:
continue
现在代码:
WebDriverWait(self.driver, 10).until(
expected_conditions.visibility_of_all_elements_located(
(By.XPATH, ‘//android.widget.ListView/android.widget.RelativeLayout’)))
print("删除的目标用户为:", name)
cur_username_list = self.driver.find_elements(By.XPATH,
f'//*[@text="{name}"]')
#在数据已被删除的情况,不进行删除操作
if len(cur_username_list) == 0:
print('目标用户不在当前用户列表当中')
else:
cur_username_list[0].click()
self.find((By.XPATH, '//*[@text="删除成员"]')).click()
self.find((By.XPATH, '//*[@text="确定"]')).click()
最后优化了点击逻辑跟判断名字是否在用户列表里面的逻辑,没有出现上面的错误了
初步猜想为:
在用XPATH层级定位的时候,我用先拿到了一个元素的列表,再用索引用这个元素拿出来再进行查找下级包含元素,这样的查找放在循环里面是不是会有查找的元素ID会有不一致的情况,层级虽然是一样的,但是它已经不在原来的页面里面了,不过这只是个猜想吧,不够能力去确认
个人收获:
第一点,可以一个比方来说吧,就好像我要找一个堆砖头里面的一块金砖,第一个代码就像当于拿起每一块砖来做一堆的程序校验再把砖扔掉,其实有更先进的方法就是先将砖都进行金属扫描,确定到具体的位置再直接到那个位置将金砖拿出来……这是思考实现的思路就有问题
第二点,自己下意识的觉得那个名字的编辑按钮才能点击,名字是不能点击,所以定位到那个编辑按钮的话就很费逻辑了,还得匹配上对应的名字,所以就有了上面那个特别复杂的循环还有索引,作为一个使用python的测试来说,这明显是不符合它“懒”的哲学的……自己还不够“懒”
第三点,尽量避免太复杂的遍历元素列表次索引再从里面进行层级定位的元素查找,这样很可能找着找着那个东西就变成叫一个名字的别的东西(避免的思想可以借鉴,结论有待考证)

