一、 简介
- XML断言是针对XML格式的数据,用于验证XML文档的结构和内容是否符合预期,以确保系统在运行过程中输出的数据是正确的。
二、应用场景
- 当响应数据以XML类型返回时,需要先进行转换才能去断言。
三、XML解析方式
- 首先了解XML的三种解析方式:
-
DOM方式:它是文档对象模型,是W3C组织推荐的标准编程接口,它将XML数据在内存中解析成一棵树,通过对树进行操作。
-
SAX方式:它是一个用于处理XML事件驱动的模型,它逐行扫描文档,一遍扫描一遍解析。SAX方式对于大型文档的解析拥有很大优势,尽管不是W3C标准,但它却得到了广泛认可。
-
elementTree:它相对于DPM而言,拥有更好的性能,与SAX方式性能差不多,API使用也很方便。
-
四、实际操作
4.1 环境准备
- Python:
- 安装requests_xml
pip install requests_xml
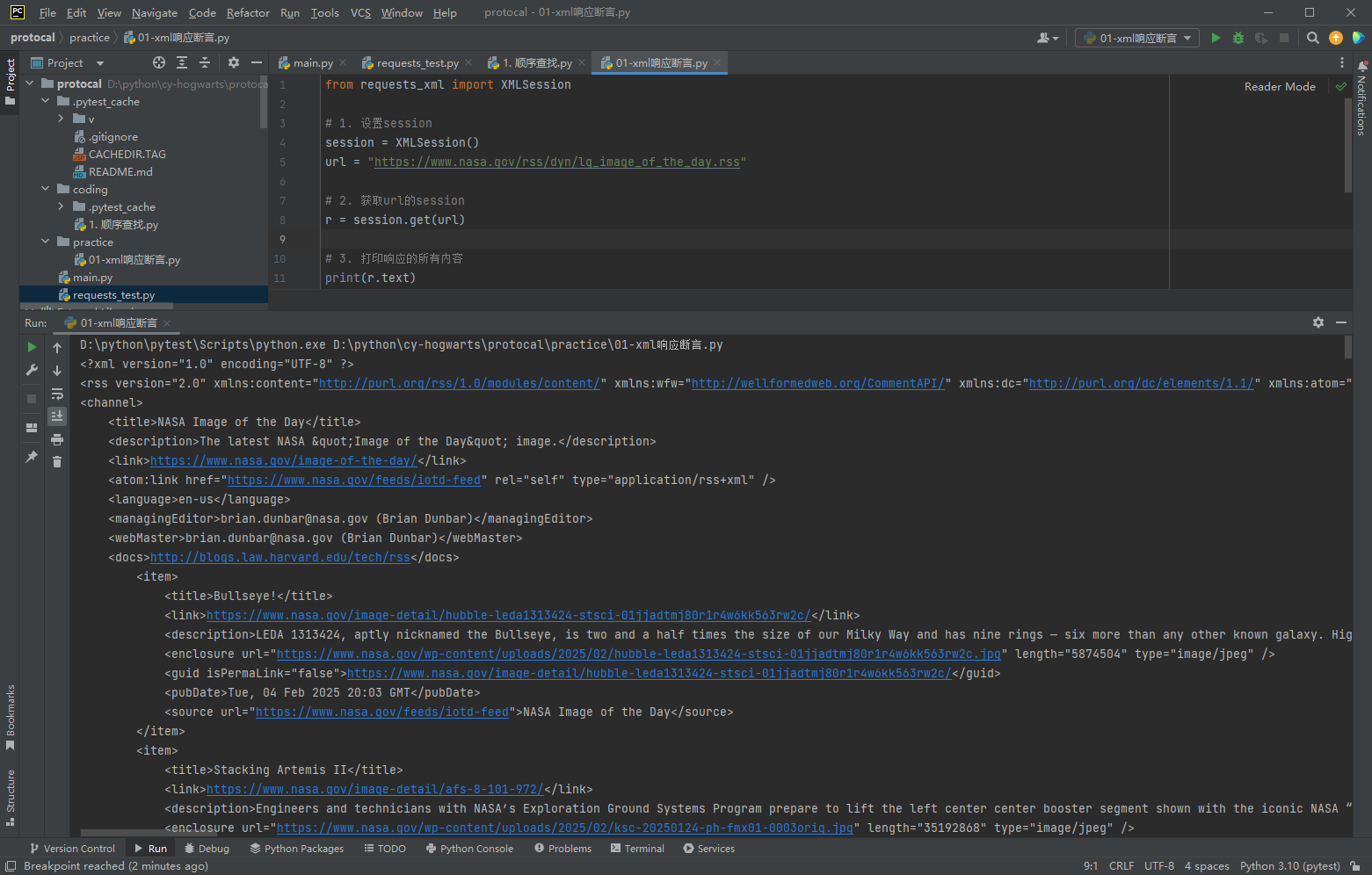
4.2 XML响应断言
from requests_xml import XMLSession
# 1. 设置session
session = XMLSession()
url = "https://www.nasa.gov/rss/dyn/lg_image_of_the_day.rss"
# 2. 获取url的session
r = session.get(url)
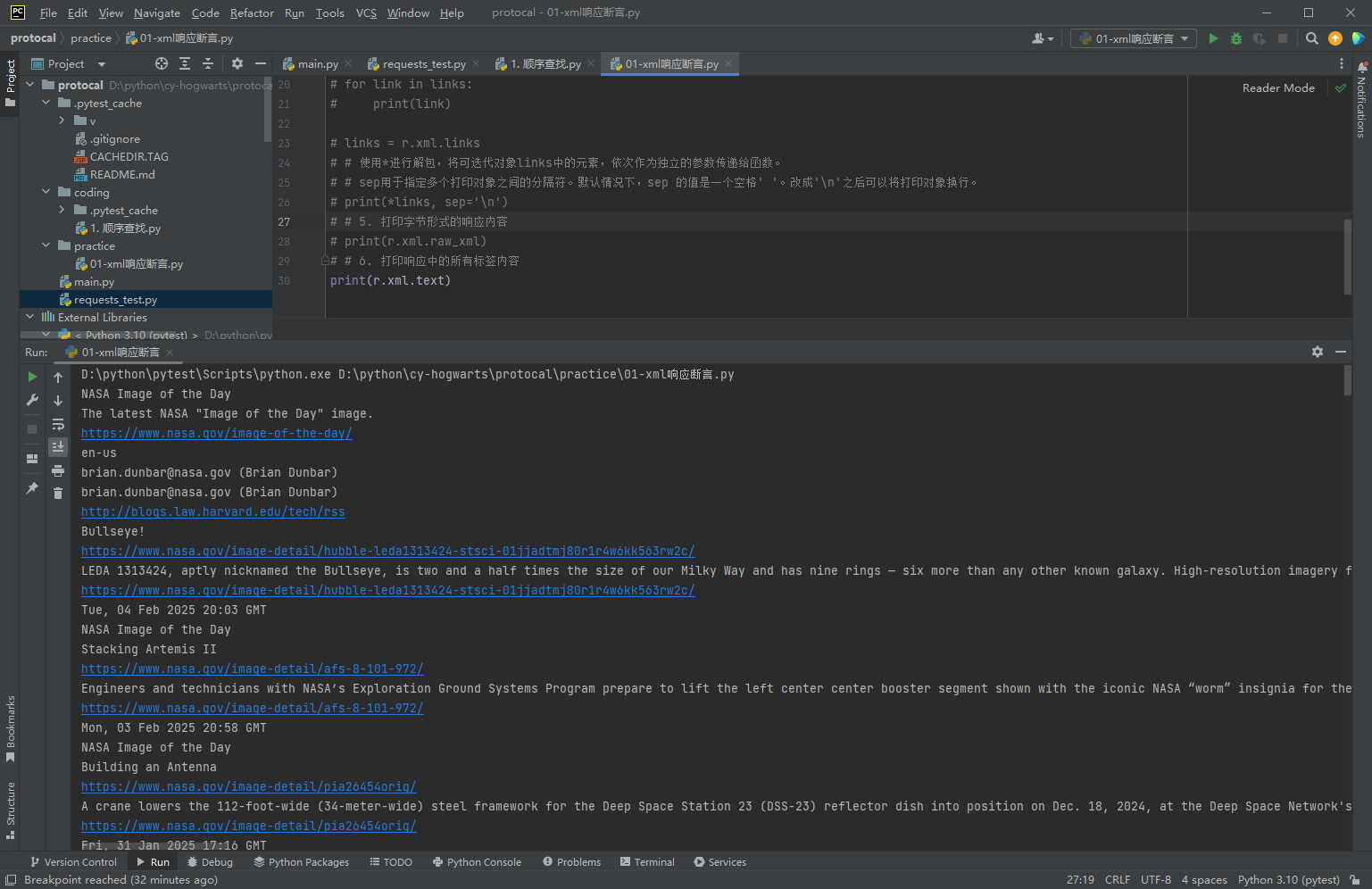
# 3. 打印响应的所有内容
print(r.text)
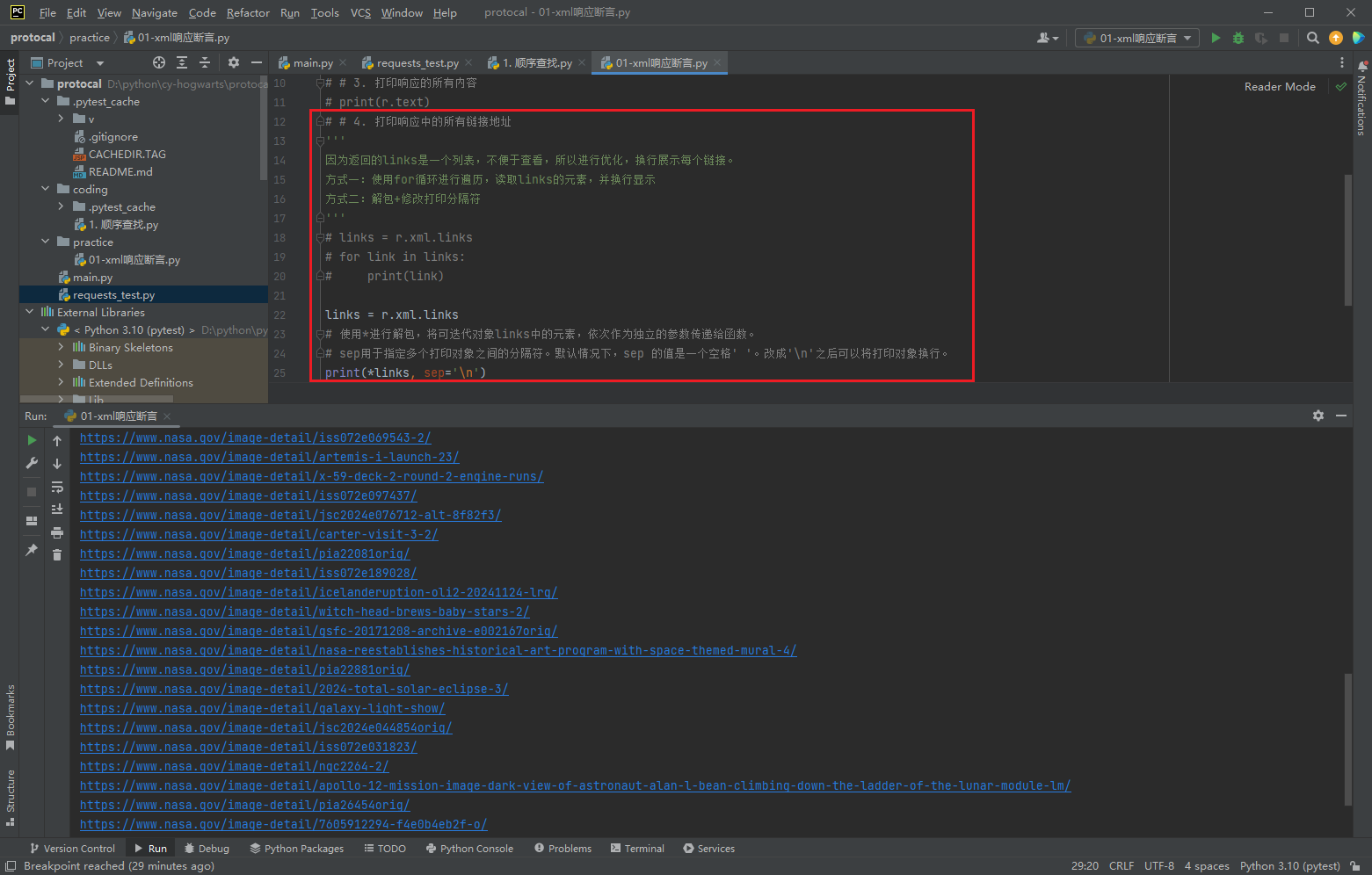
# # 4. 打印响应中的所有链接地址
print(r.xml.links)
'''
因为返回的links是一个列表,不便于查看,所以进行优化,换行展示每个链接。
方式一:使用for循环进行遍历,读取links的元素,并换行显示
方式二:解包+修改打印分隔符
'''
# links = r.xml.links
# for link in links:
# print(link)
links = r.xml.links
# 使用*进行解包,将可迭代对象links中的元素,依次作为独立的参数传递给函数。
# sep用于指定多个打印对象之间的分隔符。默认情况下,sep 的值是一个空格' '。改成'\n'之后可以将打印对象换行。
print(*links, sep='\n')
# # 5. 打印字节形式的响应内容
# print(r.xml.raw_xml)
# # 6. 打印响应中的所有标签内容
# print(r.xml.text)

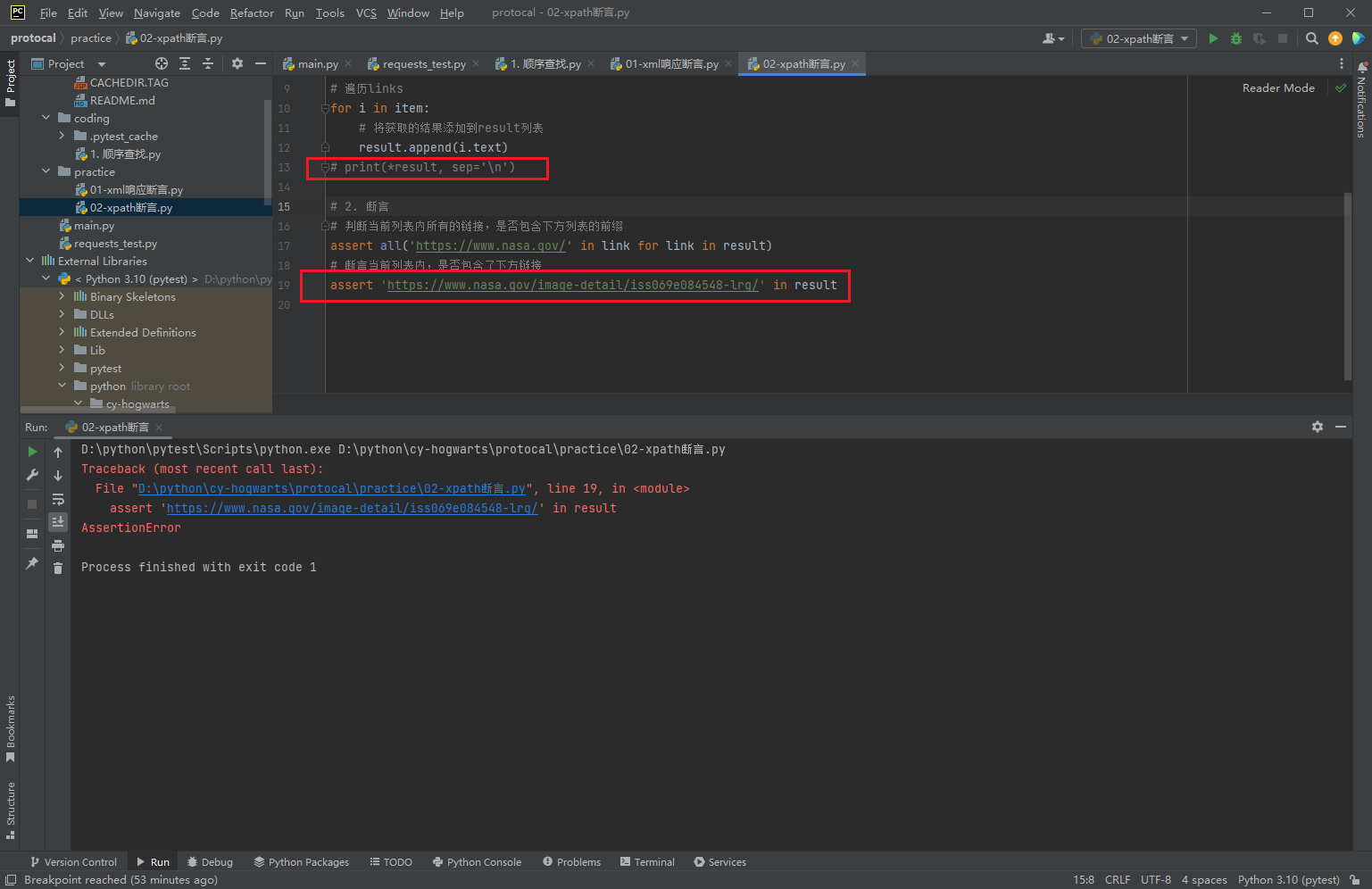
4.3 XPATH断言
-
说明:
- requests_xml库也支持XPath表达式。通过XPath表达式取出对应响应字段中的数据,再把取出的数据放在result列表中,方便用例断言。
-
xpath()用法
from requests_xml import XMLSession
session = XMLSession()
r = session.get("https://www.nasa.gov/rss/dyn/lg_image_of_the_day.rss")
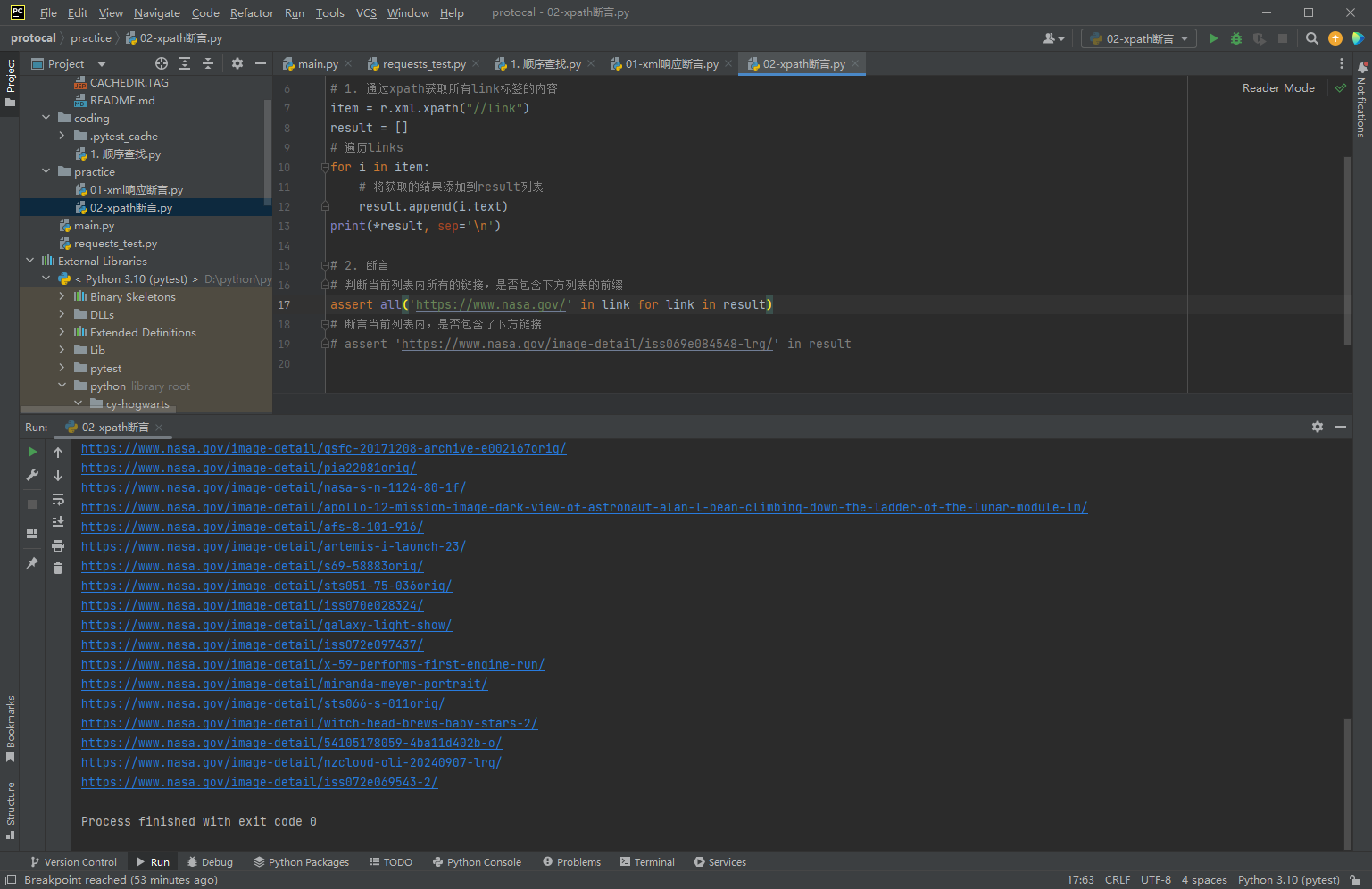
# 1. 通过xpath获取所有link标签的内容
item = r.xml.xpath("//link")
result = []
# 遍历links
for i in item:
# 将获取的结果添加到result列表
result.append(i.text)
print(*result, sep='\n')
# 2. 断言
# 判断当前列表内所有的链接,是否包含下方列表的前缀
assert all('https://www.nasa.gov/' in link for link in result)
# 断言当前列表内,是否包含了下方链接
# assert 'https://www.nasa.gov/image-detail/iss069e084548-lrg/' in result
- 断言成功:
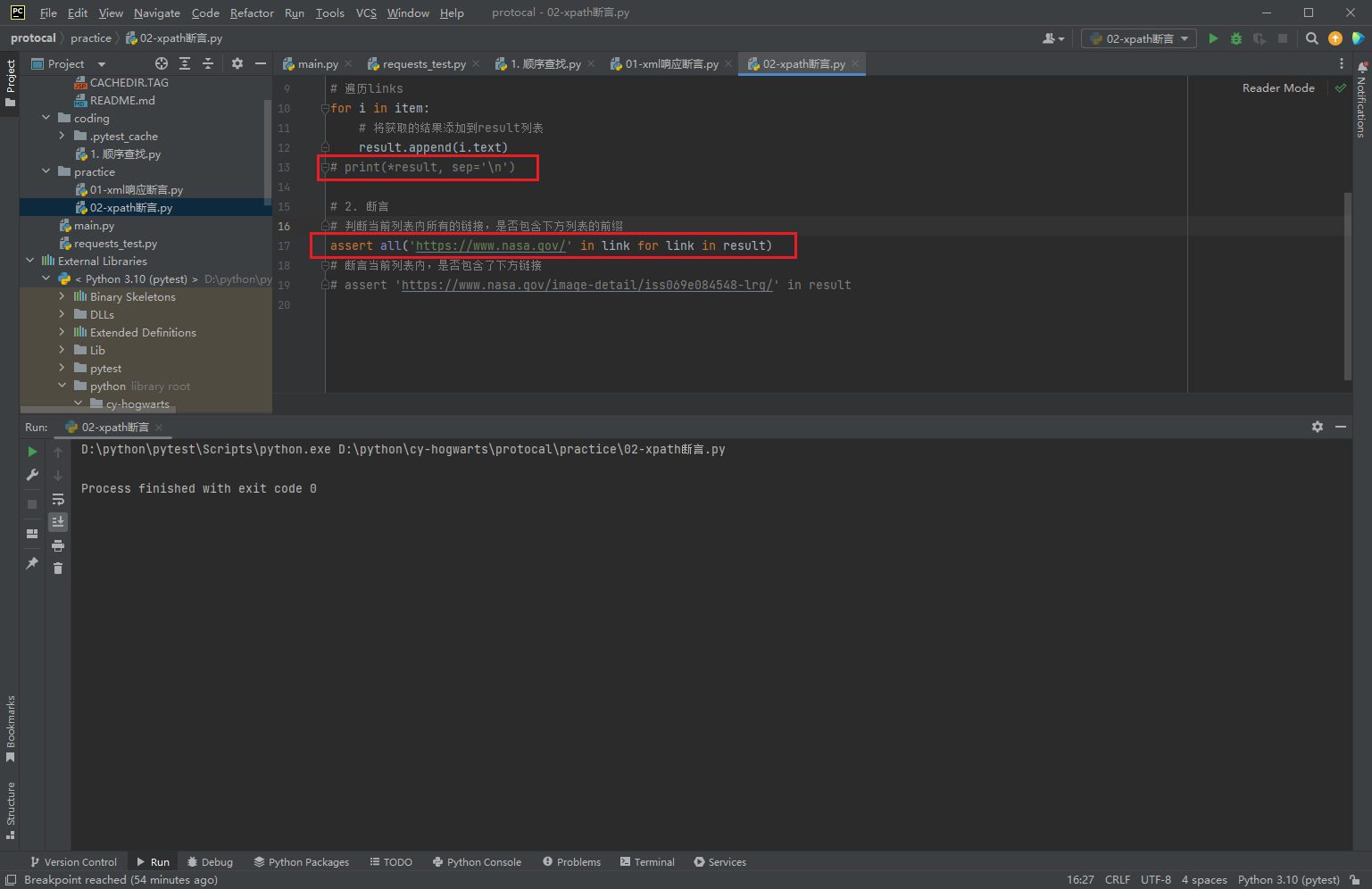
- 断言失败,抛出异常: