一、接口请求体-文件
1.1 简介
- 在计算机科学领域中,文件(File)是用于存储数据的一种常见形式。
- 文件通常被组织在存储设备(如硬盘、闪存驱动器、光盘等)上,它是可以包含文本、图像、视频、音频或其他类型的数据。
通过接口上传文件:
1.2 使用场景
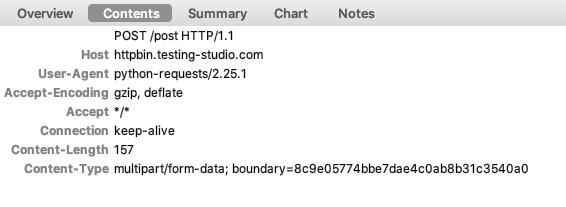
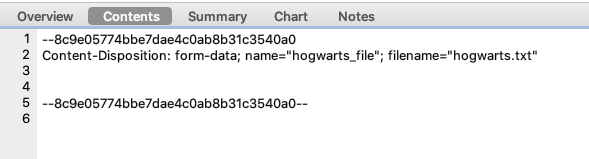
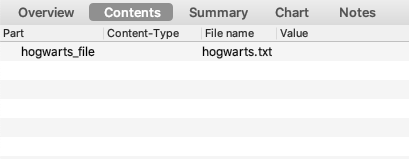
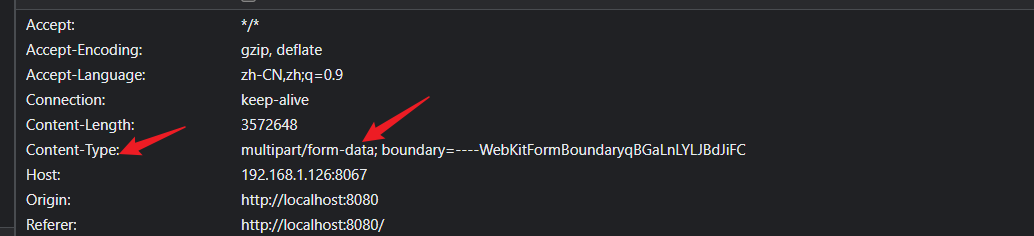
- 在进行自动化测试过程中,可能会碰到需要上传一个图片或者一个文件的接口,即头部的
content-type为multipart/form-data;boundary=...类型的接口,这时可以使用Python的Requests方法。
1.3 files参数
- files为字典类型数据,上传的文件为键值对的形式:
- 入参的参数名作为键,参数值是一个元组,内容为以下格式(文件名,打开并读取文件,文件的
content-type类型)。
- 入参的参数名作为键,参数值是一个元组,内容为以下格式(文件名,打开并读取文件,文件的
- 除了上传的文件,接口的其他参数不能放入files中,使用data进行传递即可。
# 上传图片
files ={
"file": ("攀登者.png", open("C:/Users/A/Desktop/攀登者.png", "rb"), "imags/png")
}
#上传表格文件
files = {
"file": ("test.xlsx", open("D:\\test.xlsx", "rb"), "application/octet-stream")
}
| 名称 | 类型 | 是否必须 | 描述 |
|---|---|---|---|
| file | File | 是 | 文件 |
| title | String | 是 | 文件名称 |
| fileType | String | 是 | 文件类型:doc, docx, txt, pdf, png, gif, jpg, jpeg, tiff, html, rtf, xls, txt |
1.4 实例
- 在python中使用files参数上传文件:
- files要求传递的参数内容为字典格式;
- key值为上传的文件名;
- value通常要求传递一个二进制模式的文件流。
import requests
import pprint
def req():
files = {
"file": ("攀登者.png", open("C:/Users/A/Desktop/攀登者.png", "rb"), "imags/png")
}
r = requests.post("https://httpbin.ceshiren.com/post",files=files)
assert r.status_code == 200
pprint.pprint(r.json())
req()
二、接口请求体-form表单
2.1 简介
- 在自动化测试过程中,form请求代表请求体为表单类型,其特点为:
- 数据量不大、数据层级不深的情况,使用键值对传递,form请求头中的
content-type通常对应为application/x-www-form-urlencoded。
- 数据量不大、数据层级不深的情况,使用键值对传递,form请求头中的
- 碰到这种类型的接口,使用Python的requests方法。
2.2 使用场景
- 在进行搜索、登录的时候,可以使用form表单进行填写数据。
- 在Python中,可以使用data参数传输表单,data参数以字典的形式,字典以键值对的形式出现。
import requests
import pprint
def req():
data = {
"school": "hogwarts"
}
r = requests.post("https://httpbin.ceshiren.com/post",data=data)
pprint.pprint(r.json())
req()
运行结果:
{
"args": {},
"data": "",
"files": {},
"form": {
"school": "hogwarts"
},
...省略...
"json": None,
"origin": "36.112.118.254, 182.92.156.22",
"url": "https://httpbin.ceshiren.com/post"
}
三、接口请求体-XML
3.1 简介
- 在做接口自动化时,可能会遇到一种接口,参数数据通过XML传递。
- post请求相当于get请求多一个body部分,body部分常见的数据类型有以下4种(注意是常见的,并不是只有4种):
- application/x-www-form-urlencoded
- application/json
- text/xml
- multipart/form-data
- 其中,XML是可扩展标记语言,是用于描述数据、存储数据、传输(交换)数据,与HTML类似,XML使用标签来标识数据的结构和内容,用户可以定义自己需要的标记。
3.2 应用场景
- 当进行数据交换、信息配置时,就可以使用XML来进行传输。
3.3 text/xml的数据类型
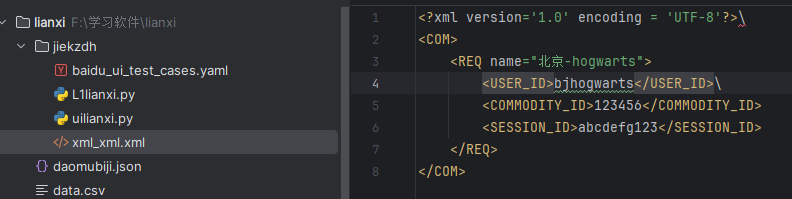
- 首先要确定post请求的body部分类型是XML格式:
<?xml version="1.0" encoding = "UTF-8"?>
<COM>
<REQ name="北京-hogwarts">
<USER_ID>bjhongge</USER_ID>
<COMMODITY_ID>123456</COMMODITY_ID>
<SESSION_ID>abcdefg123</SESSION_ID>
</REQ>
</COM>
3.4 XML请求
- 支持发送XML格式请求体。
import requests
import pprint
xml = """<?xml version=“1.0” encoding = “UTF-8”?>
<COM>
<REQ name="北京-hogwarts">
<USER_ID>bjhogwarts</USER_ID>
<COMMODITY_ID>123456</COMMODITY_ID>
<SESSION_ID>abcdefg123</SESSION_ID>
</REQ>
</COM>"""
headers = {'Content-Type': 'application/xml'}
# 遇到编码报错时候,对body进行encode
r = requests.post('https://httpbin.ceshiren.com/post', data=xml.encode('utf-8'), headers=headers)
pprint.pprint(r.json())
3.5 从文件中读取XML数据
- XML格式的数据写到代码里不直观,也不便于后期维护。可以把XML格式数据单独拿出来,写到一个.xml文件里,再用open函数去读取。
import requests
import pprint
# 用open函数读取xml文件中的内容
with open('xml_xml.xml', encoding='utf-8')as fp:
xml=fp.read()
headers = {'Content-Type': 'application/xml'}
# 遇到编码报错时候,对body进行encode
r = requests.post('https://httpbin.ceshiren.com/post', data=xml.encode('utf-8'), headers=headers)
pprint.pprint(r.json())
四、XML响应断言
4.1 简介
- XML断言是针对于XML格式的数据,用于验证XML文档的结构和内容是否符合预期,以确保系统在运行过程中输出的数据是正确的。
4.2 应用场景
- 当响应数据以XML类型返回时,需要进行转换才能断言。
4.3 XML解析方式
- 首先了解XML的三种解析方式:
- DOM方式:它是文档对象模型,是W3C组织推荐的标准编程接口,它将XML数据在内存中解析成一棵树,通过对树进行操作。
- SAX方式:它是一个用于处理XML事件驱动的模型,它逐行扫描文档,一边扫描一边解析。SAX方式对于大型文档的解析,拥有很大的优势,尽管不是W3C标准,但它却得到了广泛的认可。
- elementTree方式:它相对于DOM而言,拥有更好的性能,与SAX方式性能差不多,API使用也很方便。
4.4 环境准备
-
- 环境准备
- 安装requests_xml:pip install requests_xml
-
- XML响应断言
from requests_xml import XMLSession
# 设置session
session = XMLSession()
url = "https://www.nasa.gov/rss/dyn/lg_image_of_the_day.rss"
r = session.get(url)
# 打印所有的内容
print(r.text)
# links可以拿到响应中所有的链接地址
print(r.xml.links)
# raw_xml返回字节形式的响应内容
print(r.xml.raw_xml)
# text返回标签中的内容
print(r.xml.text)
-
- xpath()断言
- requests_xml库也支持XPath表达式。通过XPath表达式取出对应响应中字段的数据,把取出来的数据放在result列表中,方便用例断言。
def xpath():
session = XMLSession()
r = session.get("https://www.nasa.gov/rss/dyn/lg_image_of_the_day.rss")
# 通过xpath获取所有link标签的内容
item = r.xml.xpath("//link")
result = []
for i in item:
# 把获取的结果放进列表中
result.append(i.text)
# 断言
##判断当前列表内所有的链接是否包含下方列表的前缀
assert all('https://www.nasa.gov/' in link for link in result)
##断言当前列表内是否包含了下方的链接
assert 'https://www.nasa.gov/image-detail/iss069e084548-lrg/' in result
xpath()
五、cookie处理
5.1 简介
- cookie是服务器发送到用户浏览器,并保存到用户本地的一小块数据,会在浏览器再下次向同一服务器发起请求时,被携带并发送到服务器上。
- 通常用于告知服务端,两个请求是否来自同一浏览器,如保持用户的登录状态。
5.2 原理
- cookie技术会根据从服务器端发送的响应报文内,一个叫做Set-Cookie的首部字段信息,通知客户端保存cookie。
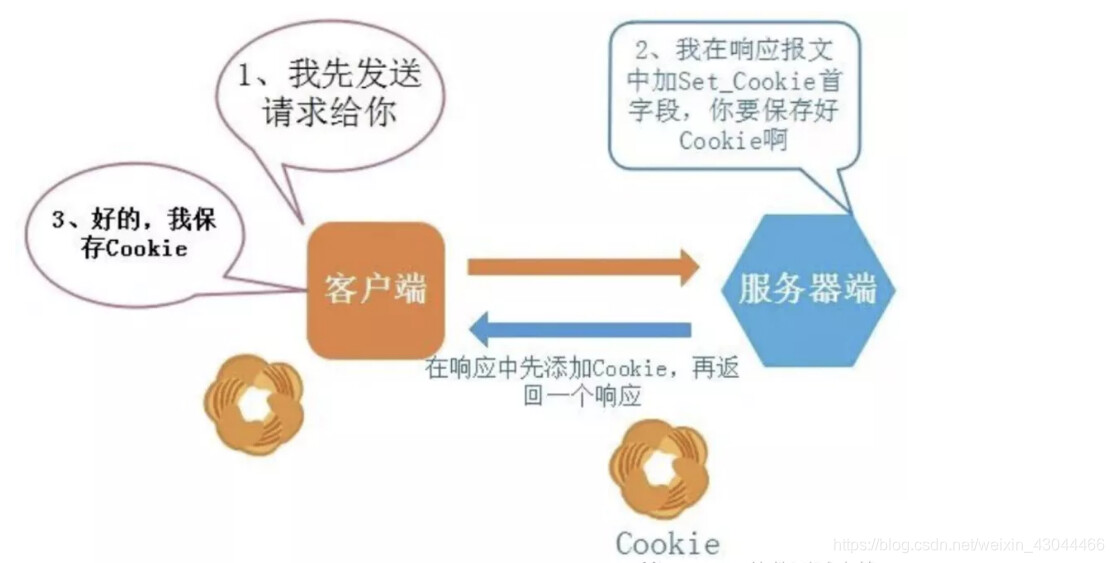
- 客户端再向服务器端发送请求时,客户端会在请求报文中加入cookie值后发送出去。
