一、简介
1.1 grep命令
-
grep是一个全局查找正则表达式,并且打印结果行的命令。
-
grep的输入是一个文件或者一个标准输入(stdin),或者是一个“-”连字符,输出一般是打印在屏幕上。
-
grep家族还有egrep和fgrep这两个命令。
1.2 工作原理
-
grep命令在一个或多个文件中,查找某个字符模式。
-
如果这个模式中包含空格,就必须用引号把它括起来。
-
grep命令中,模式可以是一个被引号括起来的字符串,也可以是单个词,位于模式之后所有的单词都被视为文件名。
-
grep将输出发送到屏幕,不会对输入文件进行任何修改或变化。
-
命令格式:
grep [选项] 模式 [文件....]
示例:

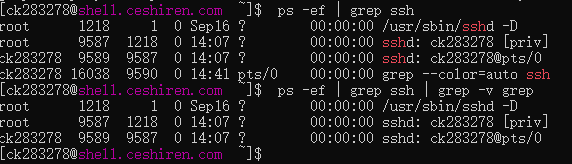
注:ps命令的输出被送到grep,然后所有包含root的行,都被打印出来。
二、内容检索
- 获取行:
grep pattern file - 获取内容:
grep -o pattern file - 获取上下文:
grep -A -B -C pattern file
三、文件检索
- 递归搜索:
grep pattern -r dir - 展示匹配文件名:
grep -H 111 /tmp/1 - 只展示匹配文件名:
grep -l 111 /tmp/1
四、范围约束
- 忽略大小写:
grep -i pattern file - 不显示匹配的行:
grep -v pattern file - 使用扩展正则表达式:
grep -E pattern file - 文件范围和目录范围约束:
grep 111 -r /tmp/demo/ --include "11*"
五、进程检索
- 进程过滤场景比较特殊,需要注意:因为grep本身会开启新进程,所以需要单独过滤掉grep进程。
六、基本正则表达式(BRE)和扩展正则表达式(ERE)
- grep命令支持两种常见的正则表达式语法,默认情况下使用基本正则表达式,而使用
grep -E或egrep则启用扩展正则表达式。
6.1 基本正则表达式(Basic Regular Expression)
| 元字符 | 含义 |
|---|---|
. |
匹配除换行符以外的任何单个字符。 |
\. |
匹配一个实际的点字符。 |
^ |
锚定到字符串的开始位置。 |
$ |
锚定到字符串的结束位置。 |
* |
前面的字符匹配零次或多次。 |
\+ |
前面的字符匹配一次或多次。 |
\{n\} |
前面的字符恰好匹配 n 次。 |
\{n,\} |
前面的字符至少匹配 n 次。 |
\{,m\} |
前面的字符最多匹配 m 次。 |
\{n,m\} |
前面的字符至少匹配 n 次,最多匹配 m 次。 |
\? |
前面的字符匹配零次或一次。 |
\{ |
匹配实际的大括号字符。 |
\( |
匹配实际的左圆括号字符。 |
\) |
匹配实际的右圆括号字符。 |
\ |
转义下一个字符,或者表示一个八进制数。 |
[] |
字符集合,匹配其中的任意一个字符。 |
[^] |
排除字符集合,匹配不在括号内的任意一个字符。 |
[0-9] |
匹配数字字符。 |
[^0-9] |
匹配非数字字符。 |
[ \t\n\r\f\v] |
匹配空白字符。 |
[^ \t\n\r\f\v] |
匹配非空白字符。 |
[a-zA-Z0-9_] |
匹配单词字符。 |
[^a-zA-Z0-9_] |
匹配非单词字符。 |
6.2 扩展正则表达式(Extended Regular Expression)
| 元字符 | 含义 |
|---|---|
. |
匹配除换行符以外的任何单个字符。 |
^ |
锚定到字符串的开始位置。 |
$ |
锚定到字符串的结束位置。 |
* |
前面的字符匹配零次或多次。 |
+ |
前面的字符匹配一次或多次。 |
{n} |
前面的字符恰好匹配 n 次。 |
{n,} |
前面的字符至少匹配 n 次。 |
{,m} |
前面的字符最多匹配 m 次。 |
{n,m} |
前面的字符至少匹配 n 次,最多匹配 m 次。 |
? |
前面的字符匹配零次或一次。 |
() |
分组,允许将多个字符或表达式组合。 |
\{ |
匹配实际的大括号字符。 |
\( |
匹配实际的左圆括号字符。 |
\) |
匹配实际的右圆括号字符。 |
\ |
转义下一个字符,或者表示一个八进制数。 |
[] |
字符集合,匹配其中的任意一个字符。 |
[^] |
排除字符集合,匹配不在括号内的任意一个字符。 |
\(...\) |
匹配括号内的子表达式,并且括号内的表达式可以作为一个整体进行重复。 |
[0-9] |
匹配数字字符。 |
[^0-9] |
匹配非数字字符。 |
[ \t\n\r\f\v] |
匹配空白字符。 |
[^ \t\n\r\f\v] |
匹配非空白字符。 |
[a-zA-Z0-9_] |
匹配单词字符。 |
[^a-zA-Z0-9_] |
匹配非单词字符。 |
6.3 区别
- 在基本正则表达式中,像
+、?、|等符号,需要通过\转义来使用; - 在扩展正则表达式中,
+、?、|、()等符号可以直接使用,无需转义。
1. 匹配多个字符的次数:+ 和 \+
-
基本正则表达式 (BRE):
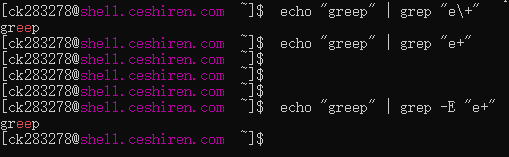
+在 BRE 中并不代表“一个或多个”的含义。如果你想匹配前面的字符一个或多个,需要使用\+来转义。示例:- 命令:
echo "greeep" | grep "e\+" - 结果: 匹配成功,因为
\+在 BRE 中表示“匹配一个或多个 e”。如果不转义+: - 命令:
echo "greeep" | grep "e+" - 结果: 不匹配,因为在 BRE 中,
+被视为普通字符。
- 命令:
-
扩展正则表达式 (ERE):
+直接表示“一个或多个”,无需转义。示例:- 命令:
echo "greeep" | grep -E "e+" - 结果: 匹配成功,因为 ERE 中
+直接表示匹配一个或多个e。
- 命令:
2. 选择符号:| 和 \|
-
基本正则表达式 (BRE):
|在 BRE 中也没有特殊意义。如果你想在 BRE 中使用“或”的语义,必须写成\|。示例:- 命令:
echo "grep or egrep" | grep "grep\|egrep" - 结果: 匹配成功,因为
\|在 BRE 中表示选择操作符(“或”)。
- 命令:
-
扩展正则表达式 (ERE):
|直接表示“或”,无需转义。示例:- 命令:
echo "grep or egrep" | grep -E "grep|egrep" - 结果: 匹配成功,
|在 ERE 中代表“或”操作。
- 命令:
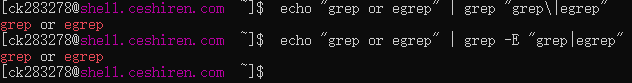
3. 匹配字符次数范围:{n,m} 和 \{n,m\}
-
基本正则表达式 (BRE):
{n,m}需要转义为\{n,m\}才能表示匹配前面的字符至少 n 次,最多 m 次。示例:- 命令:
echo "abc" | grep "a\{1,2\}" - 结果: 匹配成功,因为
a出现一次,\{1,2\}表示匹配a一次或两次。
- 命令:
-
扩展正则表达式 (ERE):
{n,m}在 ERE 中可以直接使用,无需转义。示例:- 命令:
echo "abc" | grep -E "a{1,2}" - 结果: 同样匹配成功。
- 命令:
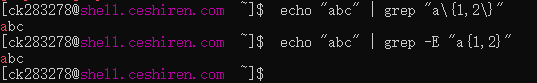
4. 分组:() 和 \(\)
-
基本正则表达式 (BRE): 在 BRE 中,如果你想要分组表达式,需要使用
\(和\)。示例:- 命令:
echo "grep123" | grep "\(grep\)[0-9]" - 结果: 匹配成功,
\(...\)用来捕获分组,后面可以是数字。
- 命令:
-
扩展正则表达式 (ERE): 在 ERE 中,
()直接表示分组,无需转义。示例:- 命令:
echo "grep123" | grep -E "(grep)[0-9]" - 结果: 同样匹配成功。
- 命令:

七、grep常用选项
| 选项 | 说明 |
|---|---|
| -i | 忽略大小写进行匹配。 |
| -v | 只显示不匹配模式的行(反向匹配)。 |
| -r/-R | 递归搜索目录中的文件。 |
| -n | 显示匹配行的行号。 |
| -H | 在输出匹配行时显示文件名。 |
| -l | 只显示包含匹配模式的文件名,不显示匹配的行。 |
| -c | 显示匹配到模式的行数。 |
| -A | 显示匹配行后面的 n 行。 |
| -B | 显示匹配行前面的 n 行。 |
| -C | 显示匹配行的前后 n 行。 |
| -E | 使用扩展正则表达式进行匹配。 |
| -F | 将模式作为固定字符串进行匹配,而不是正则表达式。 |
| -P | 使用 Perl 正则表达式进行匹配。 |
| -q | 静默模式,不输出匹配结果,只返回退出状态码。 |
| -w | 只匹配整个单词。 |
| -x | 只匹配整行。 |
--color |
为匹配的部分加上颜色。 |

八、grep实际运用
- grep是一个非常实用的工具,用于快速过滤、查找和分析日志文件、代码库和输出结果。
8.1 日志文件分析
-
grep可以快速定位错误、警告或特定的输出。
- INFO:表示信息性日志,通常用于记录程序的正常运行状态。
- WARN:警告信息,表示有潜在问题但不会立即导致程序中断。
- ERROR:错误日志,表示程序在运行过程中遇到了问题。
- DEBUG:调试信息,用于记录系统内部的运行状态,通常用于开发或调试阶段。
-
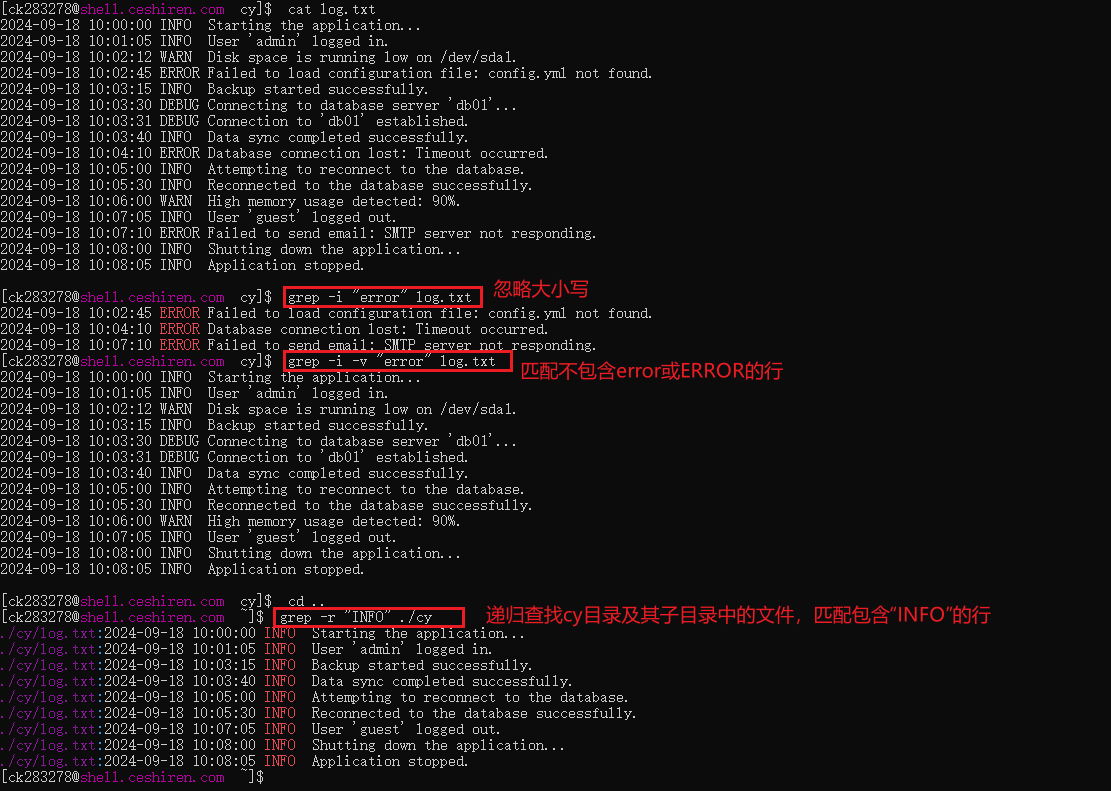
查找错误信息:
grep -i "error" log.txt -
查找多个错误或警告:
grep -E "error|warn" log.txt -
显示错误前后几行上下文:
grep -A 3 -B 3 -i "error" log.txt

8.2 代码库中的模式查找
- grep 可以帮助快速查找源代码中的函数、变量或注释,特别是当需要定位大规模代码库中特定的模式时。
-
查找函数定义:
grep -r "def my_function" . -
查找特定关键字的注释:
grep -r "// TODO" . -
查找特定的变量声明:
grep -r "int my_variable" src/
8.3 测试结果中的关键输出检查
-
grep可以用来过滤测试输出,检查测试是否通过、失败或抛出异常。 -
检查测试结果:
grep -i "test passed" test_output.log -
查找失败的测试:
grep -i "fail" test_output.log -
计数测试失败次数:
grep -i "fail" test_output.log | wc -l
8.4 日志监控和实时分析
-
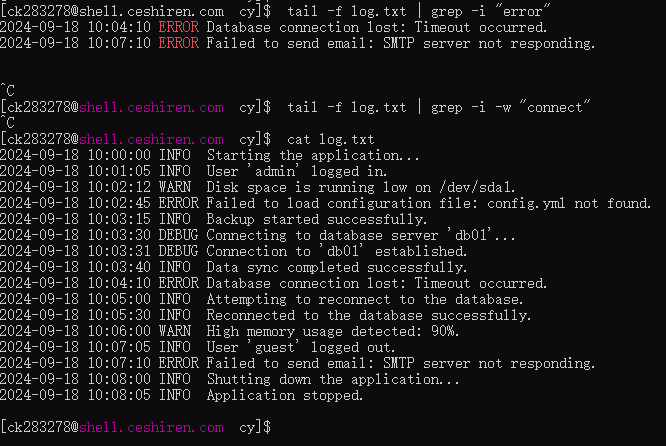
监控日志文件的实时变化:
tail -f log.txt | grep "error" -
监控特定服务启动情况:
tail -f log.txt | grep "started"
8.5 配置文件检查
-
在开发环境中,常常需要检查配置文件中的某些关键参数。
grep可以帮助快速定位配置项,避免手动查找的繁琐。 -
查找配置文件中的特定参数:
grep "db_host" config.yml -
查找未配置项或默认值:
grep -r "default" config/
8.6 文件内容批量替换
-
某些场景下,需要在多个文件中批量替换内容,
grep和sed常常组合使用以实现这一功能。 -
查找并确认要替换的文本:
grep -r "old_text" src/ -
在多个文件中替换文本:
grep -rl "old_text" src/ | xargs sed -i 's/old_text/new_text/g'
8.7 性能日志分析
-
在性能测试中,开发人员常需要查找性能日志中某些指标的数值,并进行统计分析。
-
查找请求响应时间超过特定阈值的记录:
grep "response_time" performance.log | awk '$3 > 1000' -
统计特定时间段的请求数:
grep "2024-09-18" access.log | wc -l
8.8 版本控制集成
-
在版本控制系统(如 Git)中,
grep也常被用来快速查找某些提交记录、变更等。 -
查找某个提交中涉及的变更:
git grep "function_name" -
查看特定文件的历史修改:
git log -p -- file_name | grep "pattern"
