awk
awk 是一种强大的文本处理工具,用于模式扫描和处理。它广泛用于 Unix 和类 Unix 操作系统中。awk 主要用于处理文本文件,尤其是格式化数据和生成报告。以下是 awk 的详细解释,包括其基本用法、主要功能和常见命令。awk 的基本结构
awk 的基本结构
awk 'pattern { action }' file
-
pattern:匹配模式,可以是正则表达式或条件表达式。 -
{ action }:当模式匹配成功时执行的操作。 -
file:要处理的文件。如果不指定文件,awk从标准输入读取数据。
awk 的主要功能
- 字段处理 :
-
awk将每行分为多个字段,默认以空格或制表符分隔。 -
$1,$2, …,$n代表第1个、第2个、…第n个字段。 -
$0代表整行。
- 内置变量 :
-
NR:当前记录(行)号。 -
NF:当前记录的字段数量。 -
FS:字段分隔符(默认为空格或制表符)。 -
OFS:输出字段分隔符(默认为空格)。 -
RS:记录分隔符(默认为换行符)。 -
ORS:输出记录分隔符(默认为换行符)。
- 常见命令和示例
1. 打印文件内容
awk '{ print }' filename
- 打印文件的每一行。
2. 打印指定字段
sh
复制代码
awk '{ print $1, $3 }' filename
- 打印文件每行的第1和第3个字段。
3. 使用分隔符
sh
复制代码
awk -F: '{ print $1 }' filename
- 使用冒号(
:)作为字段分隔符,打印每行的第1个字段。
4. 条件判断
sh
复制代码
awk '$3 > 50 { print $1, $3 }' filename
- 打印第3个字段值大于50的行的第1和第3个字段。
5. 字符串操作
sh
复制代码
awk '{ print substr($1, 1, 5) }' filename
- 打印第1个字段的前5个字符。
6. 统计和汇总
sh
复制代码
awk '{ sum += $2 } END { print "Total:", sum }' filename
- 计算第2个字段的总和,并在处理完所有记录后输出总和。
7. 正则表达式匹配
sh
复制代码
awk '/pattern/ { print }' filename
- 打印匹配“pattern”的行。
8. 行号和字段数
sh
复制代码
awk '{ print NR, NF }' filename
- 打印每行的行号和字段数。
9. 处理多个文件
sh
复制代码
awk '{ print FILENAME, $0 }' file1 file2
- 打印每行的文件名和内容。
10. 设置字段分隔符和输出字段分隔符
sh
复制代码
awk -F, -v OFS='\t' '{ print $1, $2 }' filename
- 使用逗号作为输入字段分隔符,制表符作为输出字段分隔符,打印第1和第2个字段。
脚本编写
awk 也可以用来编写复杂的脚本,以下是一个 awk 脚本的示例,保存为 script.awk 文件:
awk
复制代码
BEGIN {
FS = "," # 设置输入字段分隔符为逗号
OFS = "\t" # 设置输出字段分隔符为制表符
print "Name", "Score"
}
{
if ($2 > 50) {
print $1, $2
}
}
END {
print "End of report"
}
执行脚本:
sh
复制代码
awk -f script.awk filename
总结
awk 是一个功能强大的文本处理工具,通过其模式匹配和操作能力,可以处理和分析各种文本数据。掌握 awk 的基本命令和功能,可以大大提高文本处理的效率。
用法示例
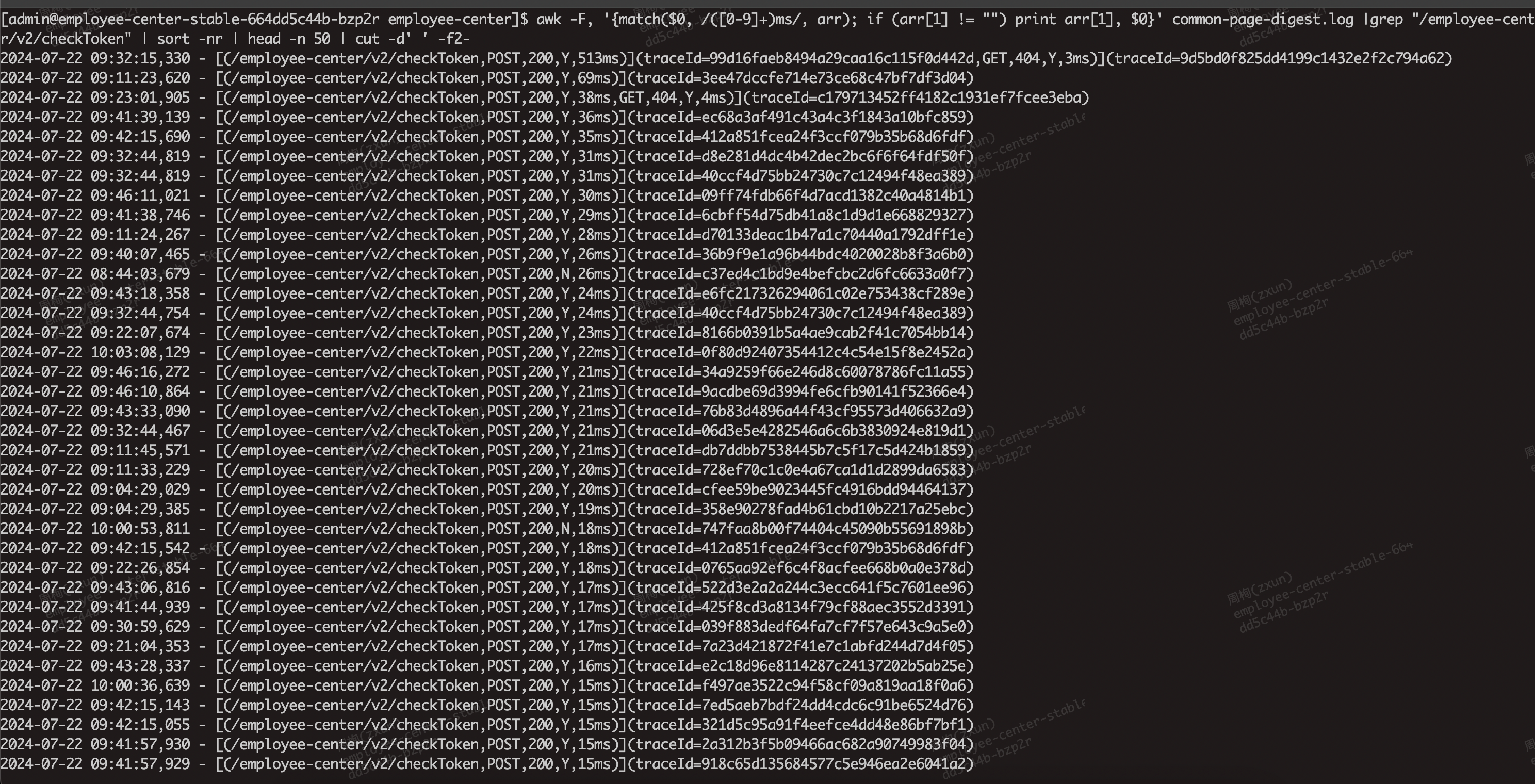
awk -F, '{match($0, /([0-9]+)ms/, arr); if (arr[1] != "") print arr[1], $0}' common-page-digest.log |grep "/employee-center/v2/checkToken" | sort -nr | head -n 50 | cut -d' ' -f2-
命令和解释
awk -F, '{match($0, /([0-9]+)ms/, arr); if (arr[1] != "") print arr[1], $0}' log.txt
-
-F,:- 指定字段分隔符为逗号(
,)。虽然在这个例子中不直接影响结果,但可以用来设置awk在处理某些数据时的分隔符。
- 指定字段分隔符为逗号(
-
{match($0, /([0-9]+)ms/, arr); if (arr[1] != "") print arr[1], $0}:-
match($0, /([0-9]+)ms/, arr):- 使用正则表达式
/([0-9]+)ms/在当前行($0)中查找数字和 “ms”。 -
arr数组存储匹配结果。arr[1]包含提取的耗时数字。
- 使用正则表达式
-
if (arr[1] != ""):- 确保
arr[1](提取的耗时数字)不为空,以避免处理未匹配的行。
- 确保
-
print arr[1], $0:- 输出提取的耗时数字和整行日志记录。
-
sort -nr
- 按照数字倒序排序(耗时从高到低)。
head -n 50
- 获取前 50 条记录。
cut -d' ' -f2-
- 去除最前面添加的耗时字段,只保留原始日志内容。
整体流程
- 使用
awk提取每行日志中的耗时数字,并将其与整行日志一起输出。 - 使用
sort对结果进行按耗时倒序排序。 - 使用
head获取前 50 条记录。 - 使用
cut去除排序过程中添加的耗时字段,只保留原始日志记录。
vi 是一个强大的文本编辑器,广泛用于 Unix 和类 Unix 操作系统。它有两种主要模式:命令模式和插入模式。下面是 vi 编辑器的详细命令说明和使用方法:
基本模式
- 命令模式 :
- 默认启动模式。
- 用于执行编辑命令,比如删除、复制、粘贴、搜索等。
- 插入模式 :
- 用于插入和编辑文本。
- 进入插入模式的方法是按
i(在光标前插入)、I(在行首插入)、a(在光标后插入)、A(在行尾插入)、o(在当前行下方插入新行)、O(在当前行上方插入新行)。
vi
基本命令
启动和退出
-
启动
vi编辑器 :
vi filename
如果文件存在,vi 将打开该文件;如果文件不存在,vi 会创建一个新文件。
-
退出
vi:-
:wq或:x:保存更改并退出。 -
:q:退出(如果没有更改,直接退出)。 -
:q!:强制退出,不保存更改。 -
:w:仅保存更改,不退出。
-
移动光标
-
基本移动 :
-
h:左移一个字符。 -
j:下移一个行。 -
k:上移一个行。 -
l:右移一个字符。
-
-
按单词移动 :
-
w:移动到下一个单词的开头。 -
b:移动到当前单词的开头。 -
e:移动到当前单词的末尾。
-
-
按行移动 :
-
0:移动到当前行的开头。 -
$:移动到当前行的末尾。 -
gg:移动到文件的开头。 -
G:移动到文件的末尾。
-
编辑文本
-
插入模式 :
-
i:在光标前插入。 -
I:在行首插入。 -
a:在光标后插入。 -
A:在行尾插入。 -
o:在当前行下方插入新行。 -
O:在当前行上方插入新行。
-
-
删除文本 :
-
x:删除光标所在位置的字符。 -
dd:删除当前行。 -
d+ 移动命令:删除指定范围的文本。例如d2j删除当前行及其下两行。
-
-
复制和粘贴 :
-
yy:复制当前行。 -
p:在光标后粘贴。 -
P:在光标前粘贴。
-
-
替换文本 :
-
r+ 字符:替换光标下的字符。 -
R:进入替换模式,替换光标下的字符直到按下Esc键。
-
搜索和替换
-
搜索文本 :
-
/pattern:向下搜索指定的模式(pattern)。 -
?pattern:向上搜索指定的模式。 -
n:重复上一次搜索。 -
N:重复上一次搜索(方向相反)。
-
-
替换文本 :
-
:s/old/new/:替换当前行第一个匹配的old为new。 -
:s/old/new/g:替换当前行所有匹配的old为new。 -
:n,m s/old/new/g:在第n行到第m行范围内替换所有匹配的old为new。 -
:%s/old/new/g:替换整个文件中所有匹配的old为new。
-
其他有用命令
-
撤销和重做 :
-
u:撤销上一个操作。 -
Ctrl + r:重做上一个撤销的操作。
-
-
保存文件 :
-
:w filename:将文件保存为filename。
-
-
设置行号 :
-
:set number:显示行号。 -
:set nonumber:隐藏行号。
-
vi 是一个功能强大的编辑器,掌握了这些基本命令后,可以进行高效的文本编辑。
sed
sed 是一种流编辑器(stream editor),用于对文本进行基本的编辑操作,如查找、替换、插入和删除。它广泛用于 Unix 和类 Unix 操作系统中。sed 以行作为基本操作单位,并且通常用于批量处理文件。以下是 sed 的详细解释和用法。
sed 的基本结构
sed 'script' file
-
script:sed命令的脚本或指令,用于指定要执行的编辑操作。 -
file:要处理的文件。如果不指定文件,sed将从标准输入读取数据。
sed 常用命令和示例
1. 替换
- 基本替换 :
sed 's/old/new/' file
-
替换每行第一个匹配到的
old为new。 -
全局替换 :
sed 's/old/new/g' file
-
替换每行所有匹配到的
old为new。 -
替换指定行 :
sed '3s/old/new/' file
-
仅在第3行中替换第一个匹配到的
old为new。 -
替换范围内的行 :
sed '2,4s/old/new/g' file
- 在第2行到第4行范围内替换所有匹配到的
old为new。
2. 删除
- 删除指定行 :
sed '3d' file
-
删除第3行。
-
删除匹配的行 :
sed '/pattern/d' file
-
删除匹配
pattern的所有行。 -
删除范围内的行 :
sed '2,4d' file
- 删除第2行到第4行。
3. 插入和追加
- 在指定行前插入 :
sed '2i\New line' file
-
在第2行前插入
New line。 -
在指定行后追加 :
sed '2a\Another new line' file
- 在第2行后追加
Another new line。
4. 替换与编辑结合
-
使用
-i选项直接修改文件 :
sed -i 's/old/new/g' file
-
直接在文件中进行替换,而不是输出到标准输出。
-
备份文件并修改 :
sed -i.bak 's/old/new/g' file
- 将修改应用到文件,并创建一个备份文件
file.bak。
5. 多条命令
- 在脚本中使用多条命令 :
sed -e 's/old/new/g' -e '2d' file
-
执行多个
sed命令:替换所有old为new,然后删除第2行。 -
在脚本文件中使用多条命令 :
sed -f script.sed file
- 从
script.sed文件中读取sed命令并应用到file。
sed 的高级用法
1. 正则表达式
- 使用正则表达式进行匹配和替换 :
sed 's/[0-9]\{3\}/XXX/g' file
-
替换所有3位数字为
XXX。 -
使用分组和反向引用 :
sed 's/\(abc\)123/\1XYZ/' file
- 使用反向引用
\1替换abc123为abcXYZ。
2. 处理复杂文本
- 替换多行文本 :
sed -e '/start/,/end/{s/old/new/g}' file
-
在从
start到end的多行范围内进行替换。 -
在行间插入文本 :
sed '/pattern/a\New line after pattern' file
- 在匹配
pattern的行后插入New line after pattern。
总结
sed 是一个功能强大的文本处理工具,能够进行复杂的文本编辑操作。掌握 sed 的基本命令和高级用法可以帮助你高效地处理和编辑文本数据。
grep
grep 是一个用于搜索文件中匹配指定模式的文本行的工具。它在 Unix 和类 Unix 操作系统中广泛使用。grep 的功能非常强大,支持正则表达式、文件搜索和多种选项。以下是 grep 的详细解释和用法。
grep 基本结构
grep [options] pattern [file...]
-
pattern:要匹配的模式,可以是普通字符串或正则表达式。 -
file:要搜索的文件。如果不指定文件,grep从标准输入读取数据。 -
options:用于控制grep的行为的选项。
常用选项
-
-i:忽略大小写。
grep -i 'pattern' file
-
-v:反向匹配,显示不包含模式的行。
grep -v 'pattern' file
-
-r或-R:递归搜索目录中的文件。
grep -r 'pattern' directory
-
-l:仅显示匹配模式的文件名。
grep -l 'pattern' file1 file2
-
-n:显示匹配行的行号。
grep -n 'pattern' file
-
-c:统计每个文件中匹配模式的行数。
grep -c 'pattern' file
-
-o:仅显示匹配到的文本,而不是整行。
grep -o 'pattern' file
-
-H:显示匹配行的文件名(即使只有一个文件)。
grep -H 'pattern' file
-
-A:显示匹配行及其后面指定行数的内容。
grep -A 3 'pattern' file
-
-B:显示匹配行及其前面指定行数的内容。
grep -B 3 'pattern' file
-
-C:显示匹配行及其前后指定行数的内容(即上下文)。
grep -C 3 'pattern' file
-
--color:高亮显示匹配的文本。
grep --color=auto 'pattern' file
使用示例
1. 基本字符串匹配
grep 'pattern' file
- 查找文件
file中包含pattern的所有行。
2. 使用正则表达式
grep 'patt[ern]' file
- 使用字符类匹配
patt后跟e、r或n。
3. 忽略大小写
grep -i 'pattern' file
- 忽略大小写进行搜索。
4. 递归搜索
grep -r 'pattern' directory
- 递归搜索目录
directory下的所有文件。
5. 统计匹配行数
grep -c 'pattern' file
- 统计
file中包含pattern的行数。
6. 显示匹配行号
grep -n 'pattern' file
- 显示匹配到的行及其行号。
7. 显示匹配上下文
grep -C 3 'pattern' file
- 显示匹配行及其前后3行的内容。
8. 反向匹配
grep -v 'pattern' file
- 显示不包含
pattern的所有行。
9. 仅显示匹配的文本
grep -o 'pattern' file
- 仅显示文件中匹配的
pattern。
10. 显示匹配行及其后3行
grep -A 3 'pattern' file
- 显示匹配行及其后面3行的内容。
结合使用
grep 可以与其他命令结合使用,通过管道操作进一步处理数据。例如:
- 查找进程并过滤包含特定名称的行 :
ps aux | grep 'process_name'
- 查找日志文件中的错误信息 :
cat logfile | grep 'error'
总结
grep 是一个非常有用的工具,用于在文件中查找和筛选文本行。掌握 grep 的基本用法和各种选项,可以帮助你高效地处理文本数据。
