一、数据库进阶
1.1 MySQL中SQL执行原理
1. SQL语句执行过程
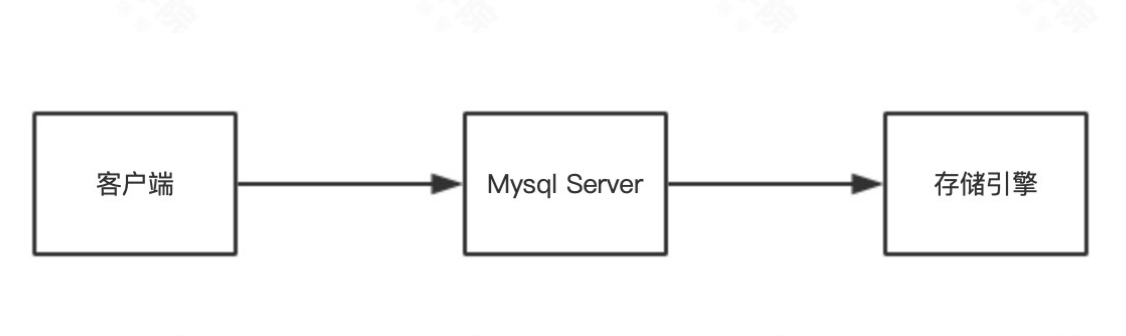
2. Server组件
- 连接器:连接管理,权限验证
- 查询缓存:命中直接返回结果
- 分析器:语法分析
- 优化器:生成执行计划,选择索引
- 执行器:操作引擎,返回结果
1.2 索引
1. 定义
- 索引是存储的表中,一个特定列的值数据结构;
- 索引包含一个表中列的值,并且这些值存储在一个数据结构中。
2. 分类
-
单列索引
- 普通索引
- 唯一索引:允许NULL值
- 主键索引:不允许NULL值
-
组合索引
-
全文索引
3. 优劣势 -
优势:
- 提高数据检索的效率,降低数据库的IO成本;
- 通过索引对数据进行排序,降低数据排序的成本,降低CPU的消耗。
-
劣势:
- 占用空间;
- 降低更新表的速度;
- 需要花时间研究建立最优秀的索引,或者优化。
4. 适用场景
- 主键自动建立唯一索引;
- 频繁作为查询条件的字段,应该创建索引;
- 查询中与其他表关联的字段,外键关系建立索引;
- 查询中排序的字段。
1.3 explain
1. 执行计划
- 模拟优化器执行SQL查询语句;
- 分析查询语句或是表结构的性能瓶颈。
2. 使用
-
explain的基本用法:
- explain命令用于展示SQL查询的执行计划。它可以帮助我们理解查询是如何被优化器处理的,包括使用的索引、表扫描方式等。
-
MySQL中的explain:
- 在MySQL中,可以已使用explain关键字来查询计划。
- 比如,有一个orders的表,并且想查询
SELECT * FROM orders WHERE order_date > '2023-01-01'的执行计划,可以写:
EXPLAIN SELECT * FROM orders WHERE order_date > '2023-01-01'
- 这会返回一系列的信息,每一行对应查询计划的一部分:
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------------+
| 1 | SIMPLE | orders| range | order_date | order_date| 5 | NULL | 1000| Using where |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------------+
- id :查询的顺序;
- select_type:选择类型;
- table:被查询的表名;
- type:访问类型(如 ALL, index, range 等);
- possible_keys :列出了可能使用的索引;
- key :显示了实际使用的索引;
- ref :显示了使用的引用列;
- rows :预计的行数;
- Extra :列提供了额外的信息。
3. 作用
- 表的读取顺序;
- 数据读取操作的操作类型;
- 哪些索引可以使用;
- 哪些索引被实际使用;
- 表之间的引用;
- 每张表有多少行被优化器查询。
4. 实例
假设有如下三个表:
-
employees表,包含员工信息,如employee_id,name,department_id。 -
departments表,包含部门信息,如department_id,department_name。 -
salaries表,包含员工薪资信息,如employee_id,salary,effective_date。
现在要找出所有在 sales 部门工作的员工的姓名和薪资。可以这样写 SQL 查询:
SELECT e.name, s.salary
FROM employees e
JOIN departments d ON e.department_id = d.department_id
JOIN salaries s ON e.employee_id = s.employee_id
WHERE d.department_name = 'sales';
使用 EXPLAIN,查看这个查询的执行计划:
EXPLAIN SELECT e.name, s.salary
FROM employees e
JOIN departments d ON e.department_id = d.department_id
JOIN salaries s ON e.employee_id = s.employee_id
WHERE d.department_name = 'sales';
1.4 事务
1. 概念
- 数据库事务(transaction)是一组SQL语句的集合,用来完成一个特定的业务逻辑。这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。
- 数据库事务是数据库操作的基本单位。
2. 特点 ACID
-
原子性(Atomicity):事务中的所有操作要么全部成功,要么全部失败,不能只执行一部分操作。
-
一致性(Consistency):事务开始前和结束后,数据库都必须处于一致性的状态。
-
隔离性(Isolation):并发执行的事务之间不能互相干扰,每个事务看起来就像是在独立的系统中运行一样。
3. 事务操作
- begin:事务开始
- rollback:事务回滚
- commit:事务提交
4. 实例
- 假设有一个简单的转账场景,从账户A向账户B转账100元。这个操作涉及到两个步骤:
-
- 从账户A扣除100元;
-
- 向账户B增加100元。
-
-- 开始事务
BEGIN TRANSACTION;
-- 执行转账操作
UPDATE accounts SET balance = balance - 100 WHERE account_id = 'A';
UPDATE accounts SET balance = balance + 100 WHERE account_id = 'B';
-- 提交事务
COMMIT;
-- 如果在转账过程中出现了任何问题(例如,账户A余额不足),则可以通过回滚事务来撤销所有的更改:
ROLLBACK;
在这个例子中,如果第一步成功执行了,但第二步出错,那么整个事务都会被回滚,不会让账户A的余额减少而账户B的余额不变,从而保证了一致性和完整性。
1.5 日志
- 查看数据库的日志对于监控和优化系统的性能至关重要。
1. 统计日志
- show log:慢查询日志,超出预设的 long_query_time 阈值的SQL记录;
- general log:全局查询日志,所有SQL查询的记录。
2. 查看慢查询日志
- 查看日志开关:
show variables like '%query%'; - 打开日志开关:
set global slow_query_log='ON'; - 设置阈值:
set long_query_time=0.01; - 执行SQL语句;
- 查看日志内容。
3. 在表中查看日志
- 修改日志存放方式:
set global log_output = 'table'; - 查看表中内容:
select * from mysql.slow_log;
4. 查看全局查询日志
- 查看变量信息:
show variables like '%general'; - 打开日志开关:
set global general_log = 'ON'; - 执行SQL语句;
- 查看表中日志内容:
select * from mysql.general_log;
二、Redis内存数据库
2.1 简介
- 是一款完全开源免费的高性能的 Key-value 键值存储数据库,广泛用于缓存、消息队列以及实时数据分析等多种应用场景。
- 支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载并使用;
- 不仅支持简单的 Key-value 类型的数据,还提供list、set、zset、hash等数据结构的存储;
- 支持数据的备份,即 master-slave 模式的数据备份;
- 性能极高,Redis能读的速度是110000次/s,写的速度是81000次/s;
- Redis的所有操作都是原子性的,要么全部执行成功,要么失败完全不执行。单个操作时原子性的,多个操作也支持事务,通过 MULTI 和EXEC 指令包起来;
- 支持 publish/subscribe 、通知、key过期等特性。
2.2 基本概念
- 键值存储:Redis存储数据的方式是键值对的形式,其中键Key通常是字符串,值value可以是多种数据类型。
- 内存存储:Redis将数据存储在内存中,这使得它的读写速度非常快。
- 持久化:尽管Redis主要在内存中工作,但它也支持将数据持久化到磁盘上,以防数据丢失。
- 网络服务:Redis作为一个网络服务运行,客户端可以通过TCP或Unix socket与其通信。
2.3 特性
- 高性能:由于数据存储在内存中,Redis 能够实现非常高的读写速度。
- 丰富的数据结构:除了简单的键值对之外,Redis 还支持多种复杂的数据结构。
- 主从复制:Redis 支持主从复制,可以实现数据的备份和读写分离。
- 事务支持:Redis 支持事务,可以保证一组操作的原子性。
- Lua 脚本支持:允许用户编写 Lua 脚本来执行复杂的操作。
- 发布/订阅模式:Redis 支持发布/订阅模式,可以实现消息传递功能。
- 持久化:支持两种持久化策略,RDB 快照和 AOF 日志。
2.4 数据类型
-
String(字符串):最简单的一种数据类型,可以存储任意类型的数据。是二进制安全的 , 意思是 redis 的 string 可以包含任何数据。比如 jpg 图片或者序列化的对象;最大能存储 512MB 。
-
Hash(哈希):类似于 Map,存储键值对的集合。一个 string 类型的 key 和 value 的映射表, hash 特别适合用于存储对象;存储 232 -1 键值对( 40 多亿)。
-
List(列表):链表结构,适合用于消息队列。按照插入顺序排序,你可以添加一个元素到列表的头部(左边)或者尾部(右边)。可存储 232 - 1 元素 ( 每个列表可存储 40 多亿 )。
-
Set(集合):存储没有重复元素的字符串集合。无序集合,通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1) 。
-
Sorted Set(有序集合):有序集合每个元素都会关联一个 double 类型的分数, redis 正是通过
分数来为集合中的成员进行从小到大的排序; zset 的成员是唯一的 , 但分数 (score)
却可以重复。

2.5 常用命令
- String
-
SET key value:设置键key的值为value。 -
GET key:获取键key的值。
- Hash
-
HSET key field value:设置哈希表key中的字段field的值为value。 -
HGET key field:获取哈希表key中字段field的值。
- List
-
LPUSH key value:将一个值value通过表头插入到列表key中。 -
LPOP key:移除并返回列表key的头部元素。
- Set
-
SADD key member:将成员member添加到集合key中。 -
SMEMBERS key:返回集合key中的所有成员。
- Sorted Set
-
ZADD key score member:将成员member添加到有序集合key中,并指定其分数score。 -
ZRANGE key start stop:返回有序集合key中指定范围内的成员。
2.6 下载安装
地址:Releases · microsoftarchive/redis · GitHub
-
将下载好的文件解压,将文件夹重命名为Redis,此文件只需解压无需安装;
-
打开一个cmd窗口,使用cd命令切换到步骤1里存放的路径
-
运行
redis-server.exe redis.windows.conf
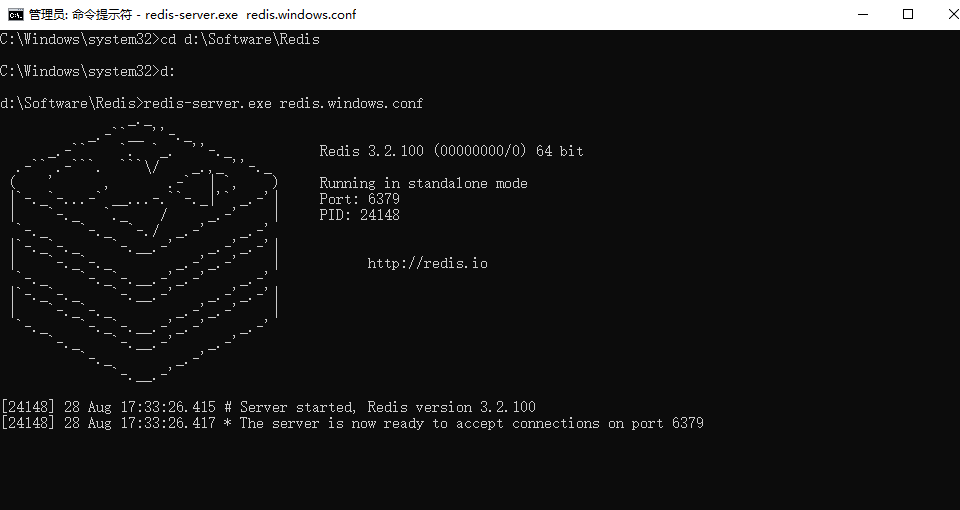
-
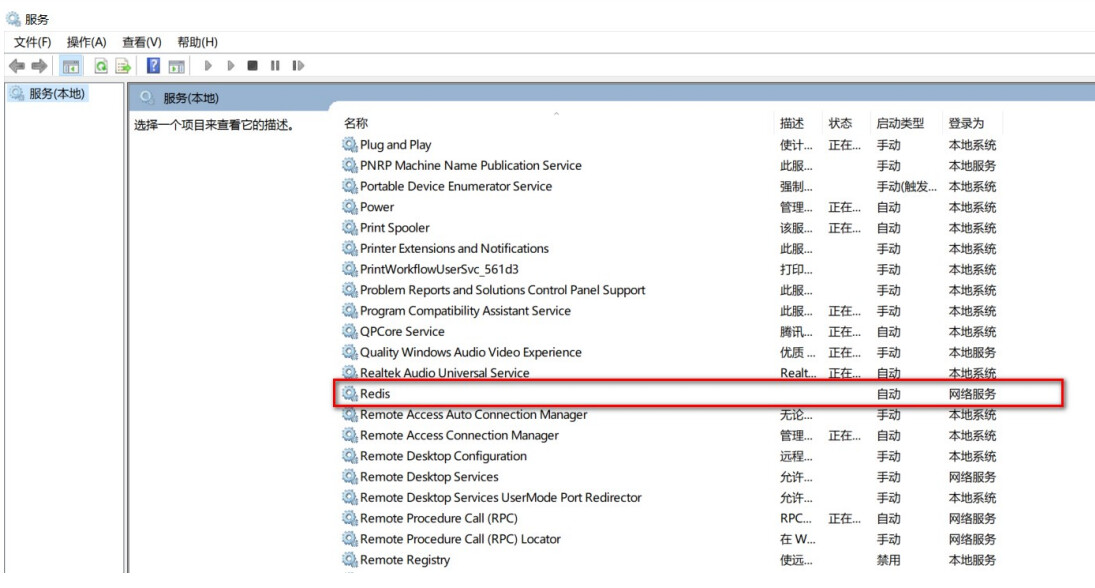
如果运行报错,可以使用解决方案:win+R 然后输入 services.msc ,调出 Windows 服务,然后
找到 Redis ,右键手动停止。
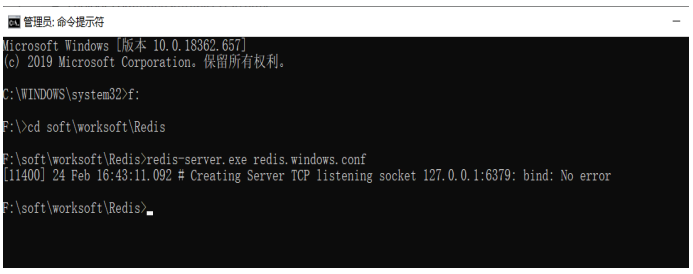
-
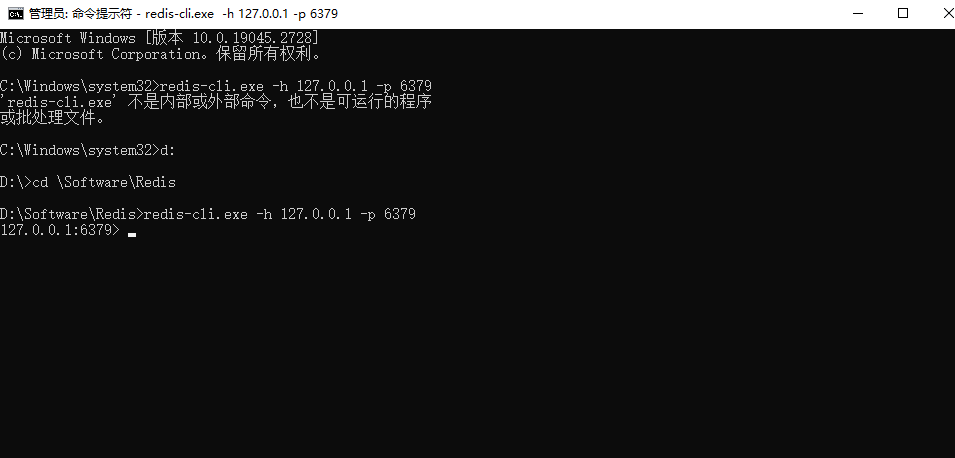
4.另起一个cmd窗口,原来的窗口不要关闭,都则无法访问服务器。再切换到redis目录下运行:
redis-cli.exe -h 127.0.0.1 -p 6379
2.7 使用
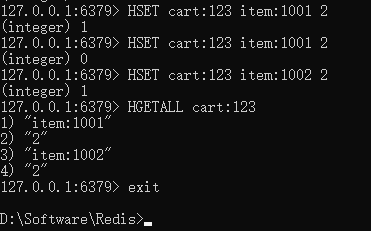
- 假设需要存储一个用户的购物车信息,其中包含商品 ID 和数量。可以使用 Hash 数据结构来存储这些信息:
HSET cart:123 item:1001 2 # 用户 123 的购物车中商品 1001 的数量为 2
HSET cart:123 item:1002 1 # 用户 123 的购物车中商品 1002 的数量为 1
- 然后可以使用
HGETALL命令来获取购物车中所有的商品和数量:
HGETALL cart:123
- 这将返回这样的结果:
1) "item:1001"
2) "2"
3) "item:1002"
4) "1"