一、DML表数据操作
1.1 简介
-
DML(Data Manipulation Language)是数据库操作语言的一种,主要用于对数据库中的数据进行操作。
-
DML包括了对数据的查询、插入、更新和删除等操作,是对数据进行操作的合计。
-
具体来说,DML允许用户查询数据库中的数据、添加新数据、修改现有数据,以及删除不再需要的数据。
1.2 使用场景
-
数据检索:这是DML最常见的使用场景。用户可以使用
SELECT语句,来查询数据库中的数据,根据特定的条件检索出需要的信息。 -
数据插入:当有新数据需要存储在数据库中时,可以使用
INSERT语句,将数据插入到表中。这包括添加新记录,或插入新的数据行。 -
数据更新:当表中的现有数据需要更改时,可以使用
UPDATE语句来更新数据。这通常用于修改现有数据的值。 -
数据删除:当表中的数据不再需要时,可以使用
DELETE语句来删除数据。这可以用于删除单个或多个记录。 -
事务处理:在数据库操作中,有时需要执行一系列的操作,并且这些操作要么全部成功,要么全部失败。DML支持事务处理,通过
BEGIN、TRANSACTION、COMMIT、ROLLBACK等语句来控制和管理事务。 -
视图操作:虽然DML主要用于对表中的数据进行操作,但它也可以用于对视图进行操作。视图是基于表的虚拟表,可以通过DML来查询、插入、更新和删除视图中的数据。
-
触发器操作:在某些情况下,需要执行某些DML操作之前、之后,或者在进行特定操作时,自动执行一些操作。触发器是与表相关联的特殊类型的存储过程,可以在DML操作触发时自动执行。
1.3 插入
1.3.1表数据插入语法
-
INSERT INTO数据表名:指定被操作的数据表; - (列名1, 列名2…):可选项,项数据表的指定列插入数据;
-
VALUES(值1, 值2…):需要插入的数据。
-- 插入数据
INSERT INTO 数据表名
(列名1, 列名2...)
VALUES(值1, 值2...);
1.3.2 插入完整参数
-- 选择数据库
USE db1;
-- 创建 user 表
CREATE TABLE user(
id INT,
name VARCHAR(20),
age INT,
sex CHAR(1),
address VARCHAR(40)
);
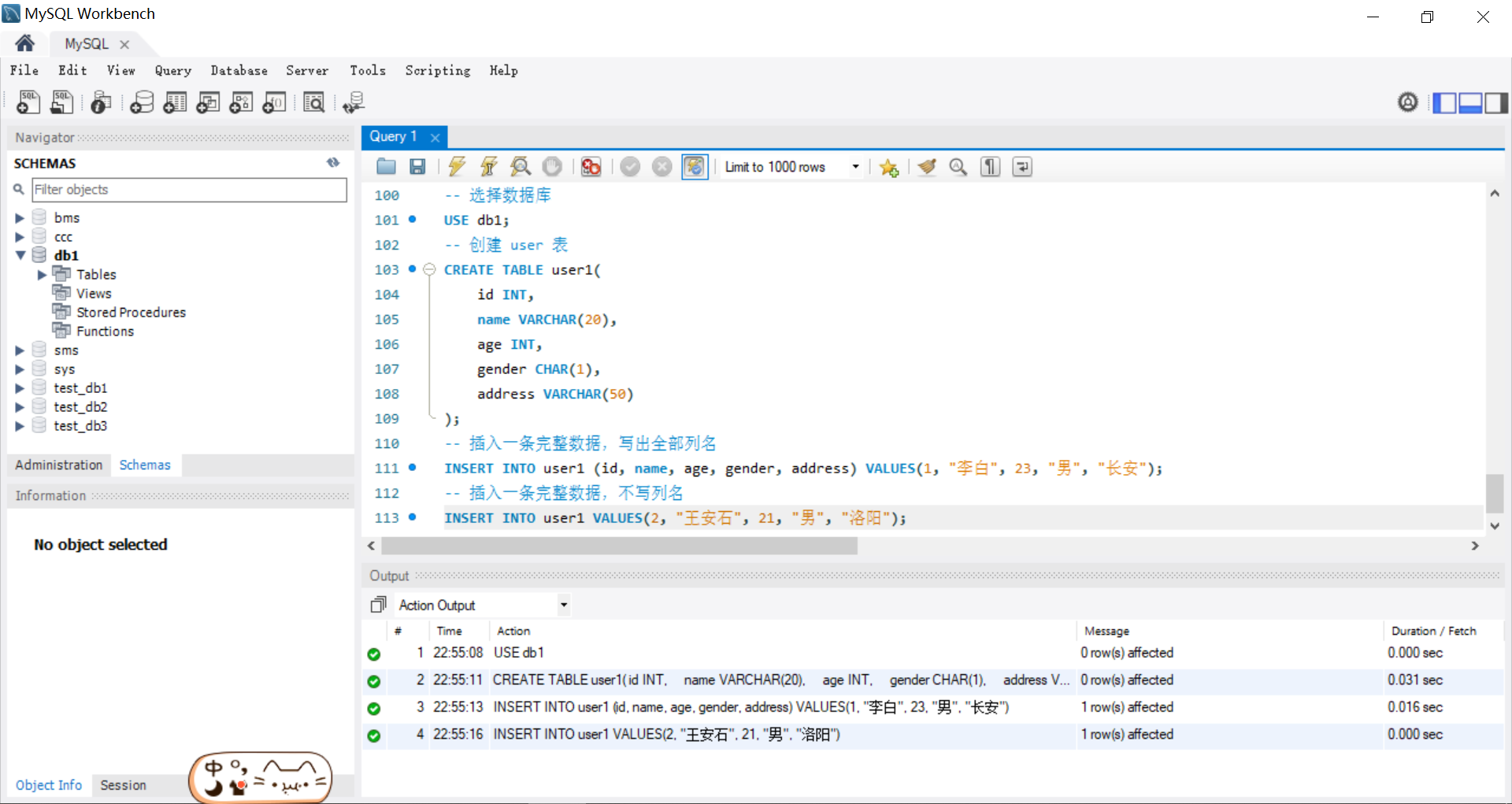
-- 插入一条完整数据,写出全部列名
INSERT INTO user (id,name,age,sex,address)
VALUES(1,'张三',20,'男','北京');
-- 插入一条完整数据,不写列名
INSERT INTO user
VALUES(2,'李四',22,'女','上海');
1.3.3 插入部分参数
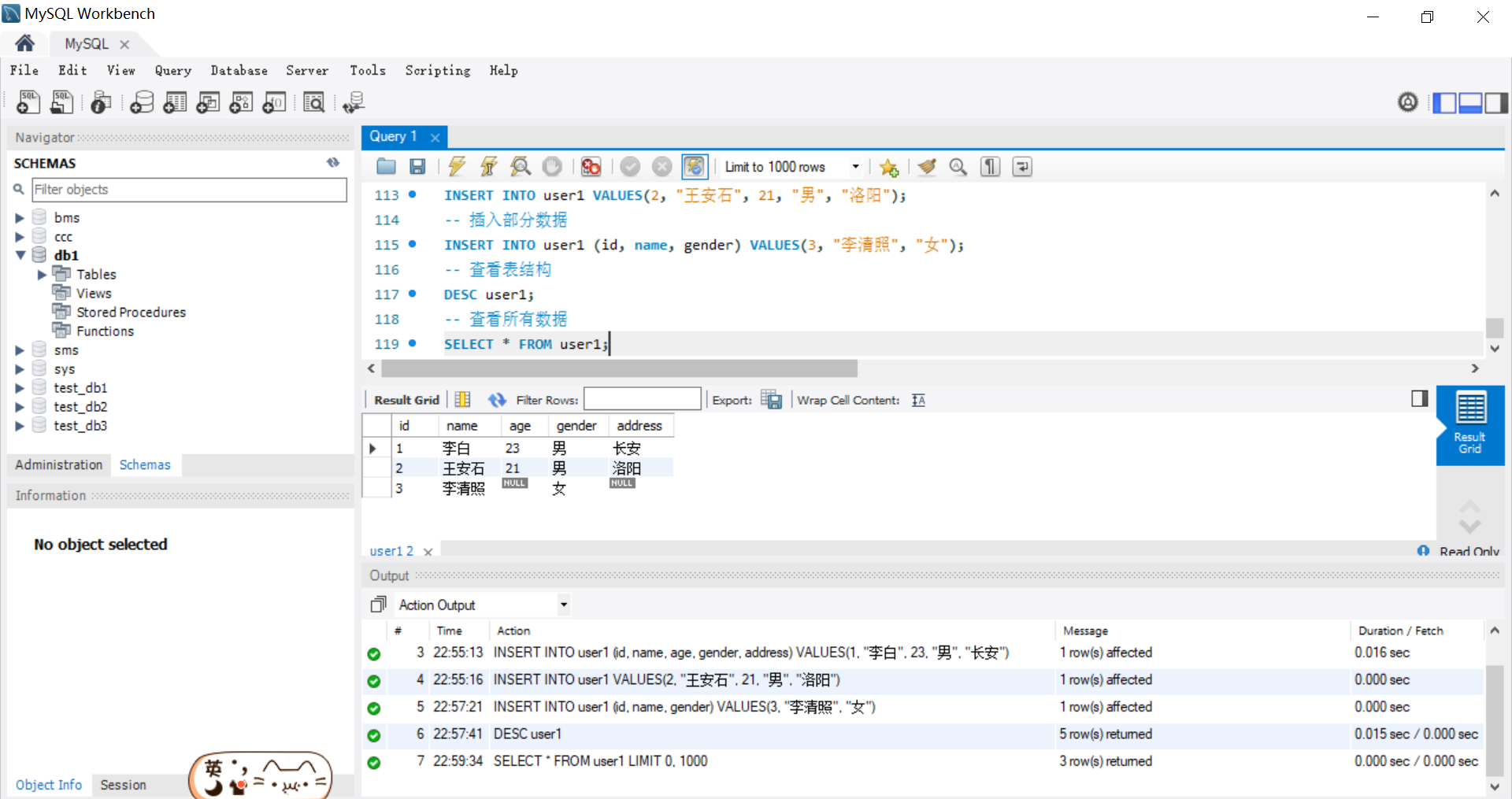
-- 插入表一行中的某几列的值
INSERT INTO user (id,name,address)
VALUES(3,'王五','深圳');

1.3.4 插入多条数据
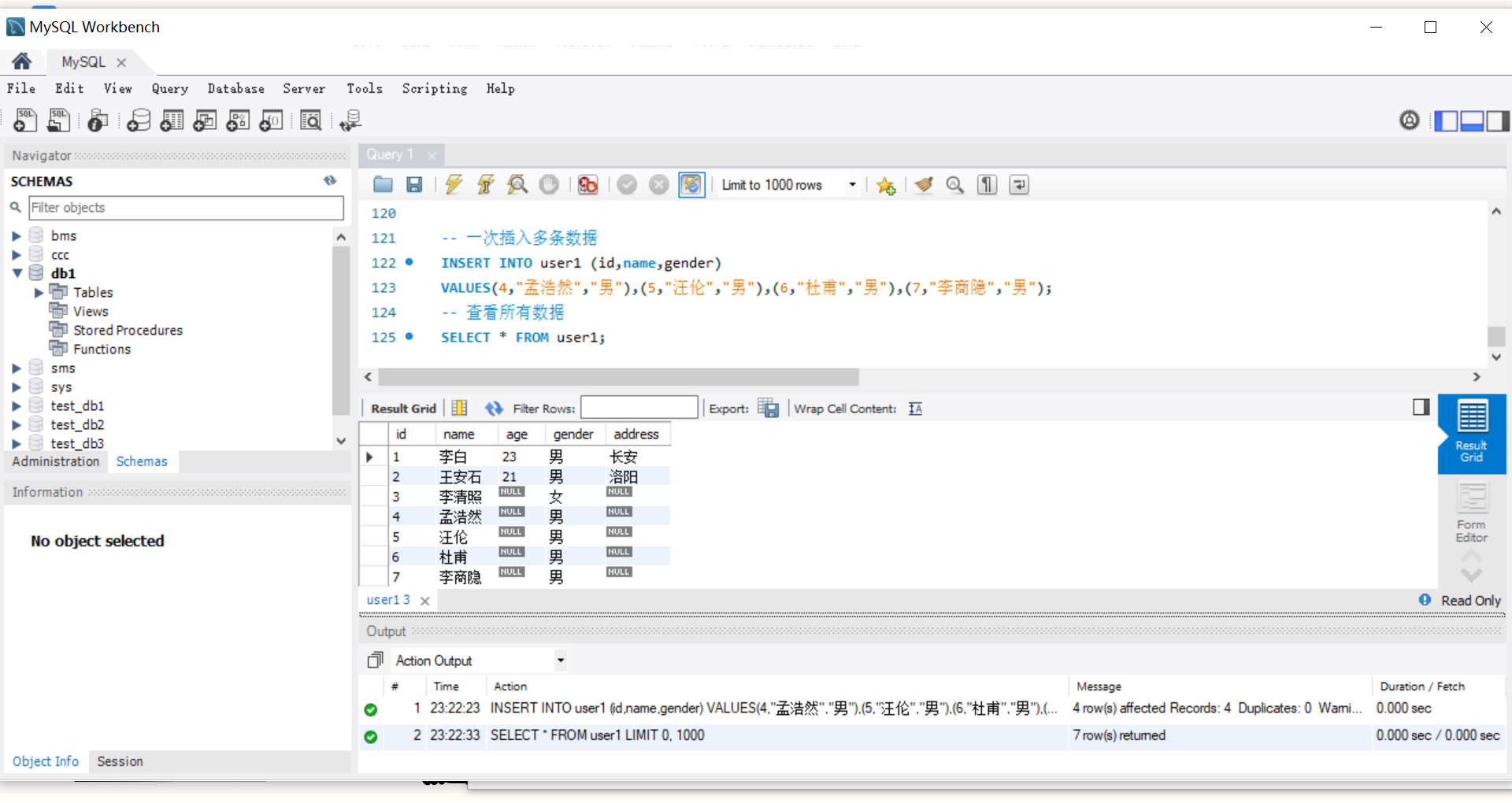
-- 一次插入多条数据
INSERT INTO user (id,name,address)
VALUES(4,'赵六','天津'),(5,'小红','成都'),(6,'小白','杭州');
1.3.5 注意事项
- 值与字段必须要对应,个数相同,且数据类型相同;
- 值的数据大小,必须在字段指定的长度范围内;
- varchar、char、date类型的值,必须使用单引号包裹;
- 如果要插入空值,可以忽略不写,或者插入null;
- 如果插入指定字段的值,必须要写上列名。
1.4 修改
1.4.1 表数据修改语法
-- 更新表中数据
UPDATE 数据表名
SET 字段1=值1 [, 字段2=值2...]
[WHERE 条件表达式]
-
SET子句:必选项,用于指定表中要修改的字段名及其字段值。- 其中的值可以是表达式,也可以是该字段所对应的默认值。
- 如果指定默认值,那么使用关键字
DEFAULT指定。
-
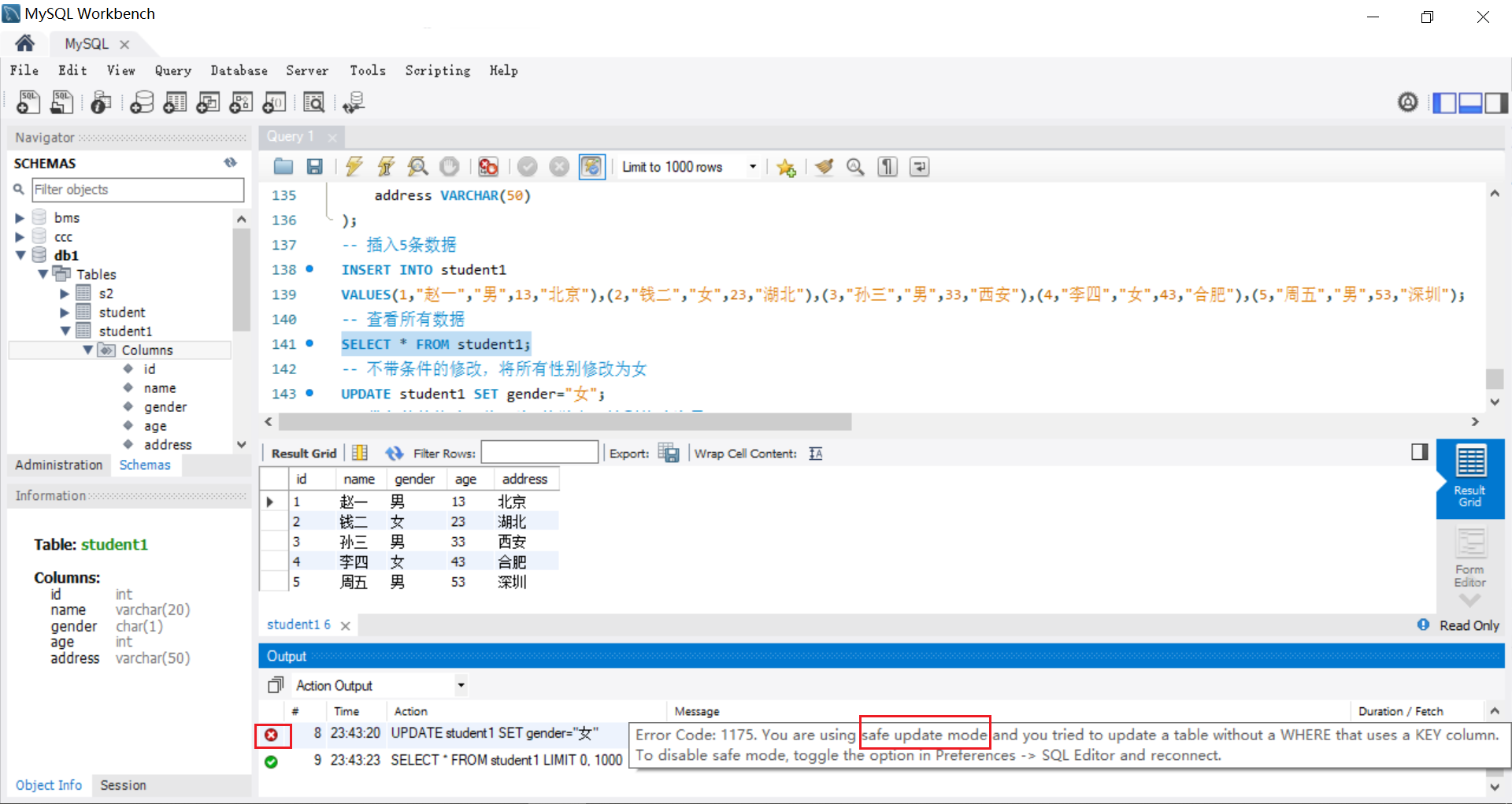
WHERE子句:可选项,用于限定表中要修改的行。- 如果不指定该子句,那么
UPDATE语句会更新表中的所有行。
- 如果不指定该子句,那么
1.4.2 不带条件的修改
-- 不带条件修改,将所有的性别改为女
UPDATE student SET sex = '女';
示例:
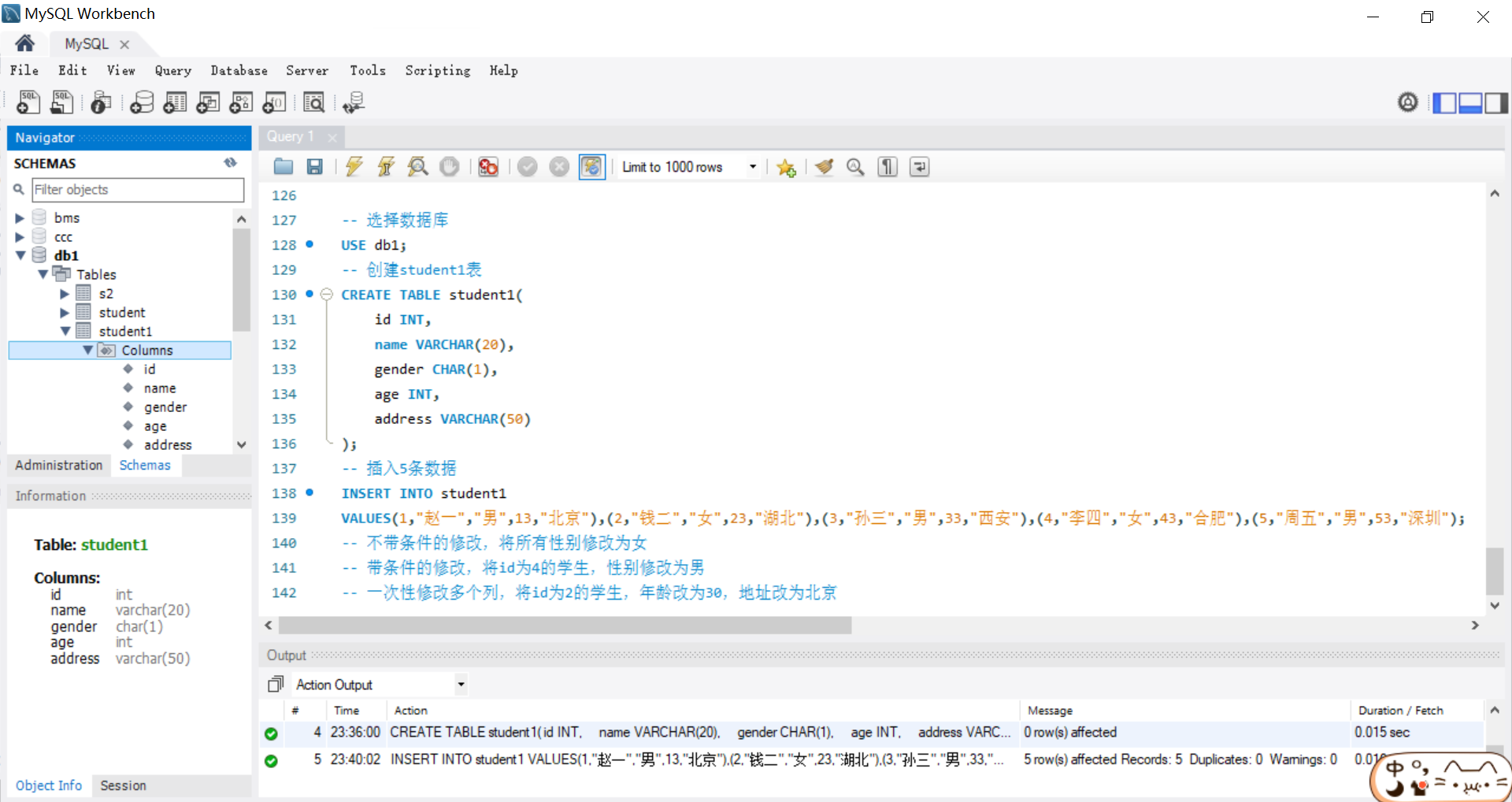
-- 选择 db1 为当前数据库
USE db1;
-- 创建 student 表
CREATE TABLE student(
id INT,
name VARCHAR(20),
sex CHAR(1),
age TINYINT,
city VARCHAR(50)
);
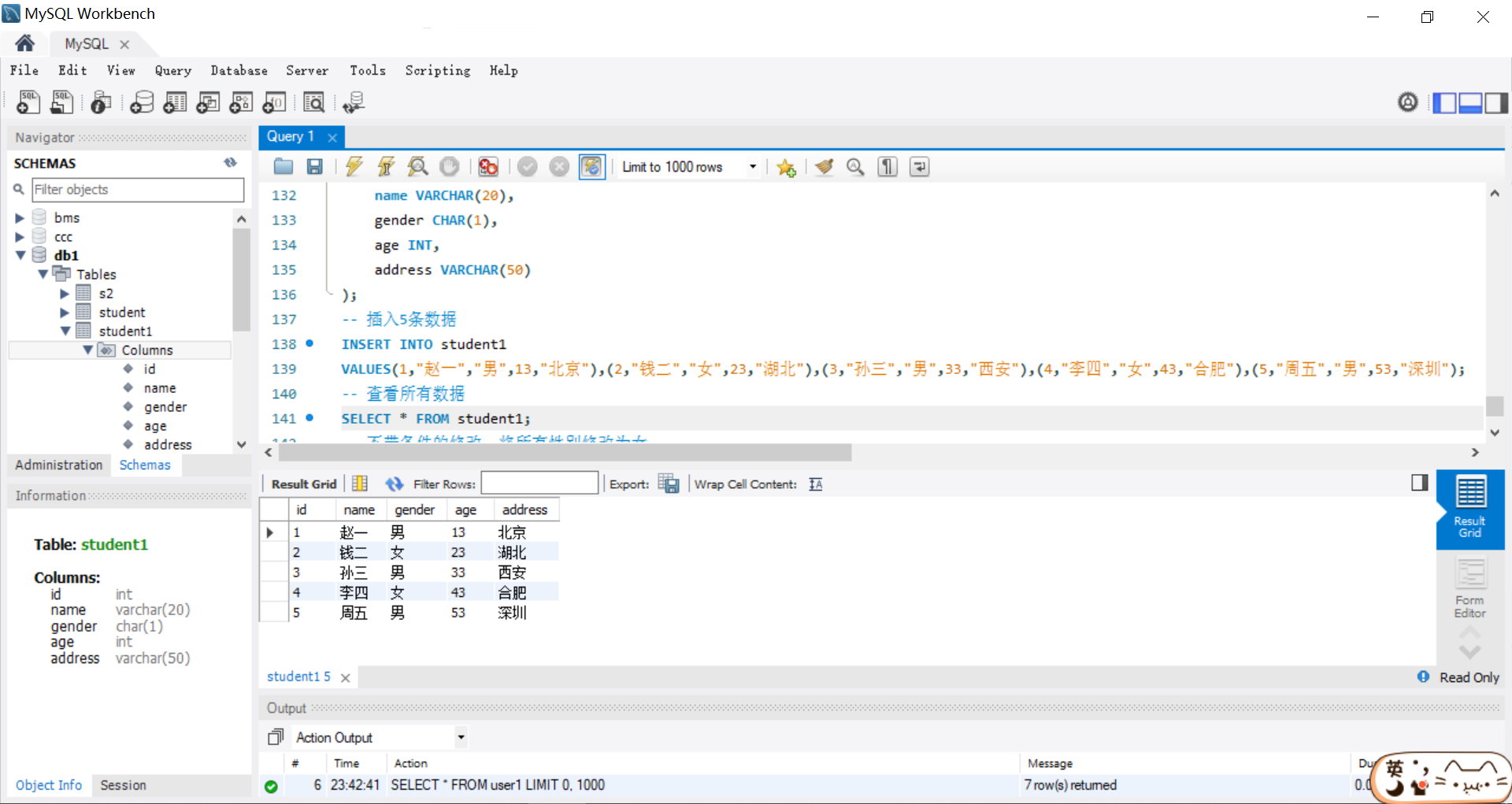
-- 插入 5 条数据
INSERT INTO student
VALUES(1,'小李','男', 18, '北京'),(2,'小白','女', 20, '成都'),(3,'小王','男', 23, '上海'),(4,'小赵','女', 21, '深圳'),(5,'小周','男', 25, '杭州');
-- 不带条件修改,将所有的性别改为女
UPDATE student SET sex = '女';
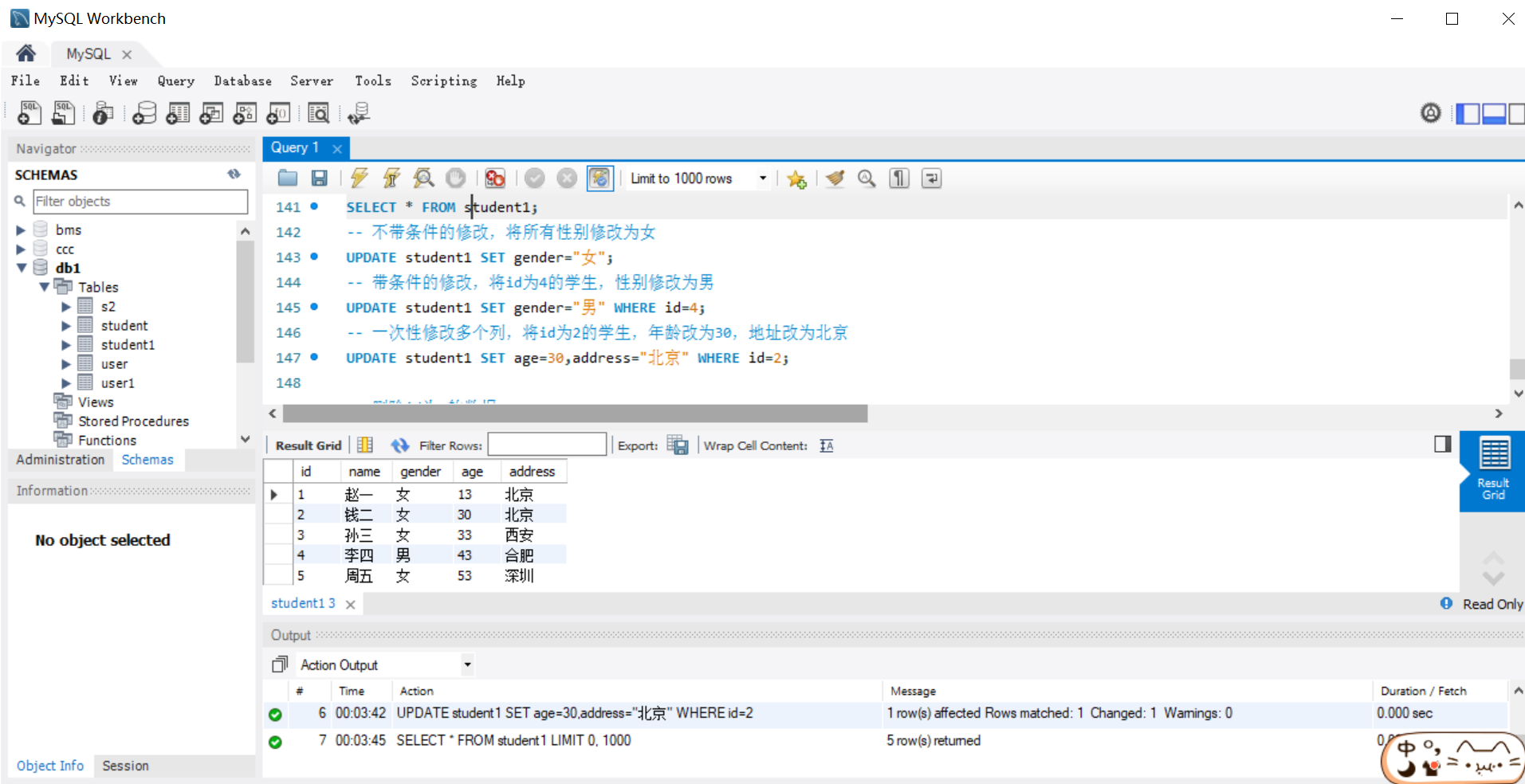
-- 带条件的修改,将 id 为 3 的学生,性别改为男
UPDATE student SET sex = '男' WHERE id = 3;
-- 一次修改多个列, 将 id 为 2 的学员,年龄改为 30,地址改为 北京
UPDATE student SET age = 30, city = '北京' WHERE id = 2;


1.5 删除
1.5.1 通过DELETE语句删除数据
DELETE FROM 数据表名
[WHERE 条件表达式]
-
数据表名:用于指定要删除的数据表的表名;
-
WHERE子句:可选项,用于限定表中要删除的行。- 如果不指定该子句,那么
DELETE语句会删除表中所有的行。
- 如果不指定该子句,那么
1.5.2 通过TRUNCATE TABLE语句删除数据
TRUNCATE TABLE 数据表名
示例:
-- 选择 db1 为当前数据库
USE db1;
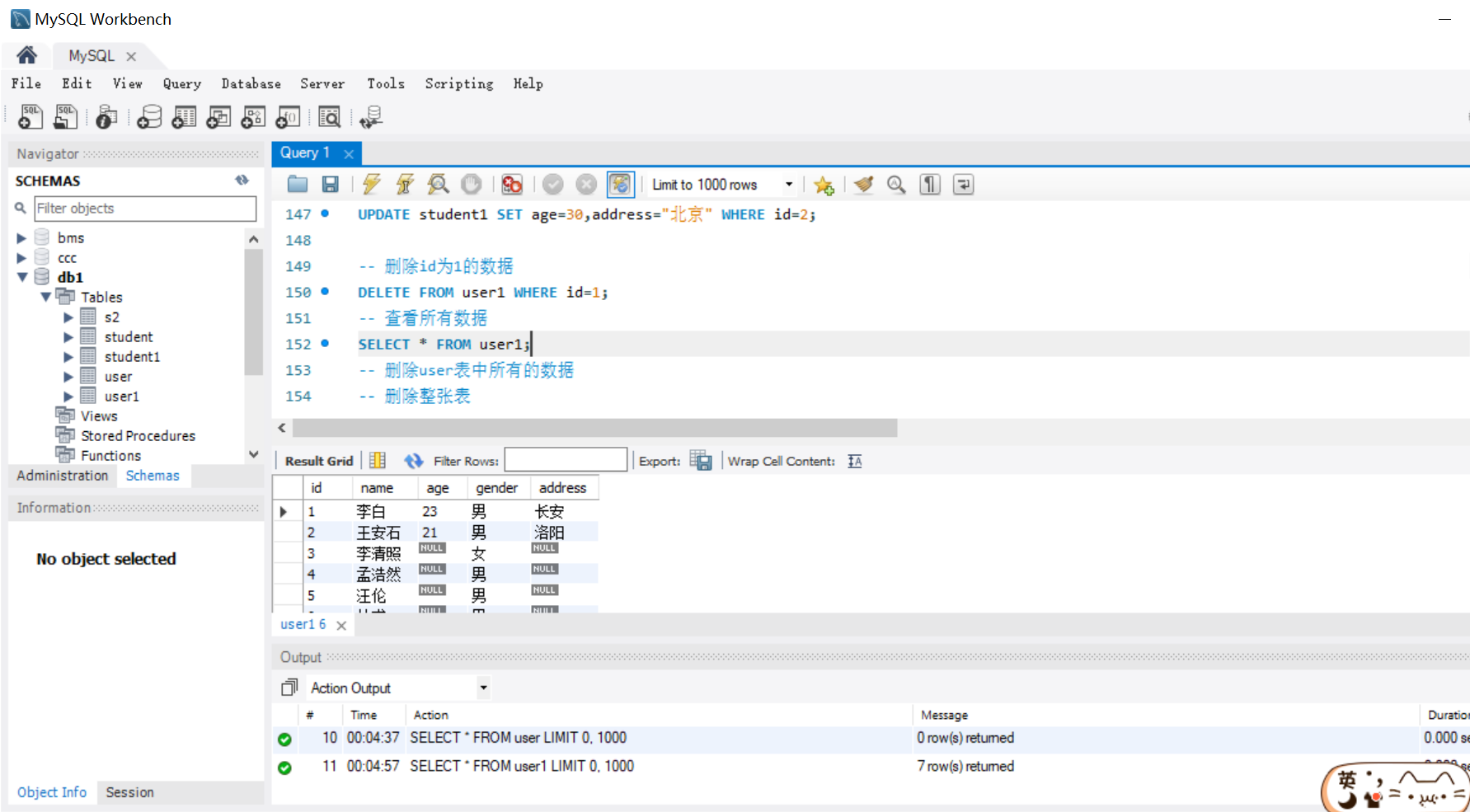
-- 删除 id 为 1 的数据
DELETE FROM student WHERE id = 1;
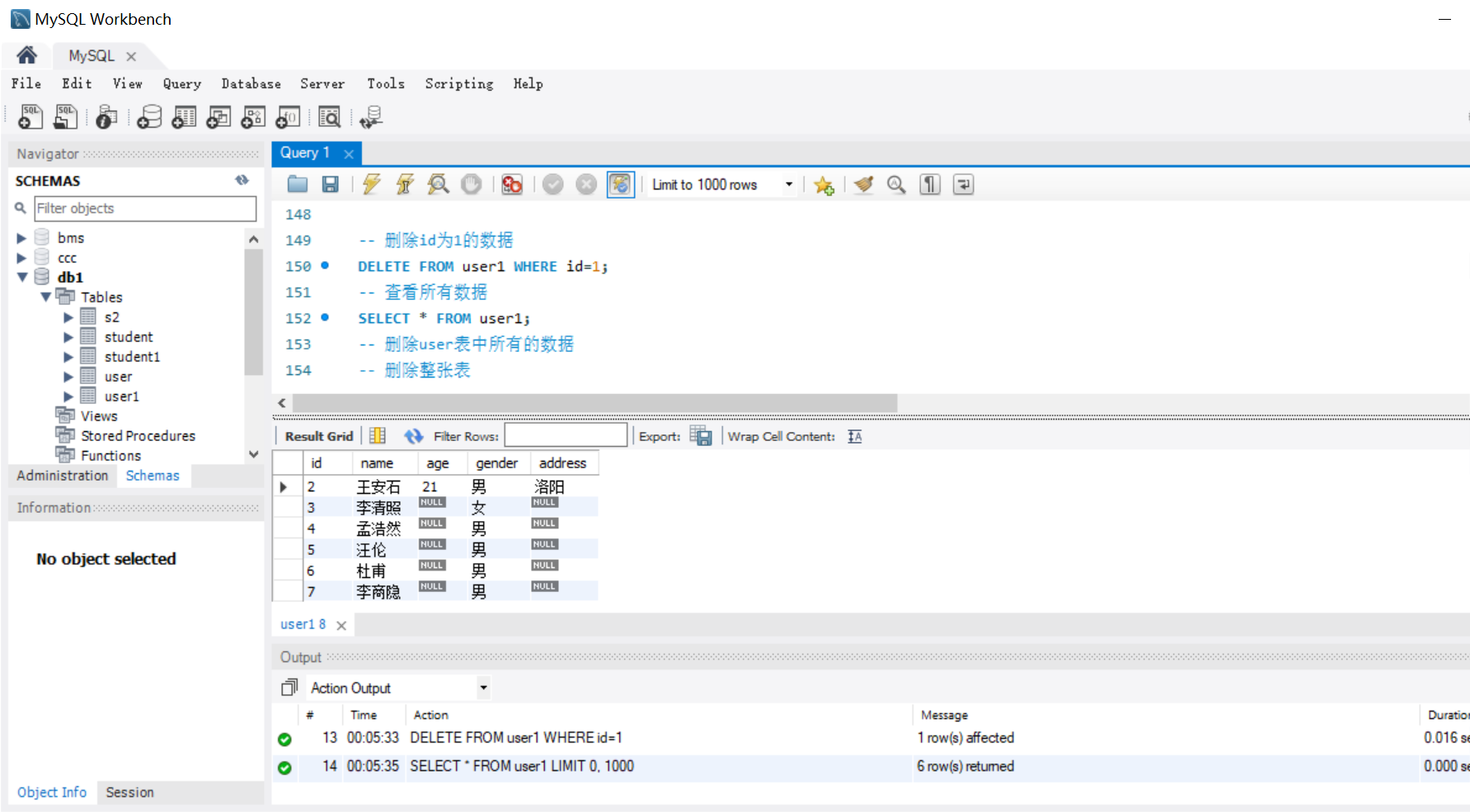
1.5.3 删除整张表的方法
- 方法一:
-- 删除 student 表中所有数据
DELETE FROM student;
注:该方法是将表里的每一条记录进行逐一删除,执行N次。

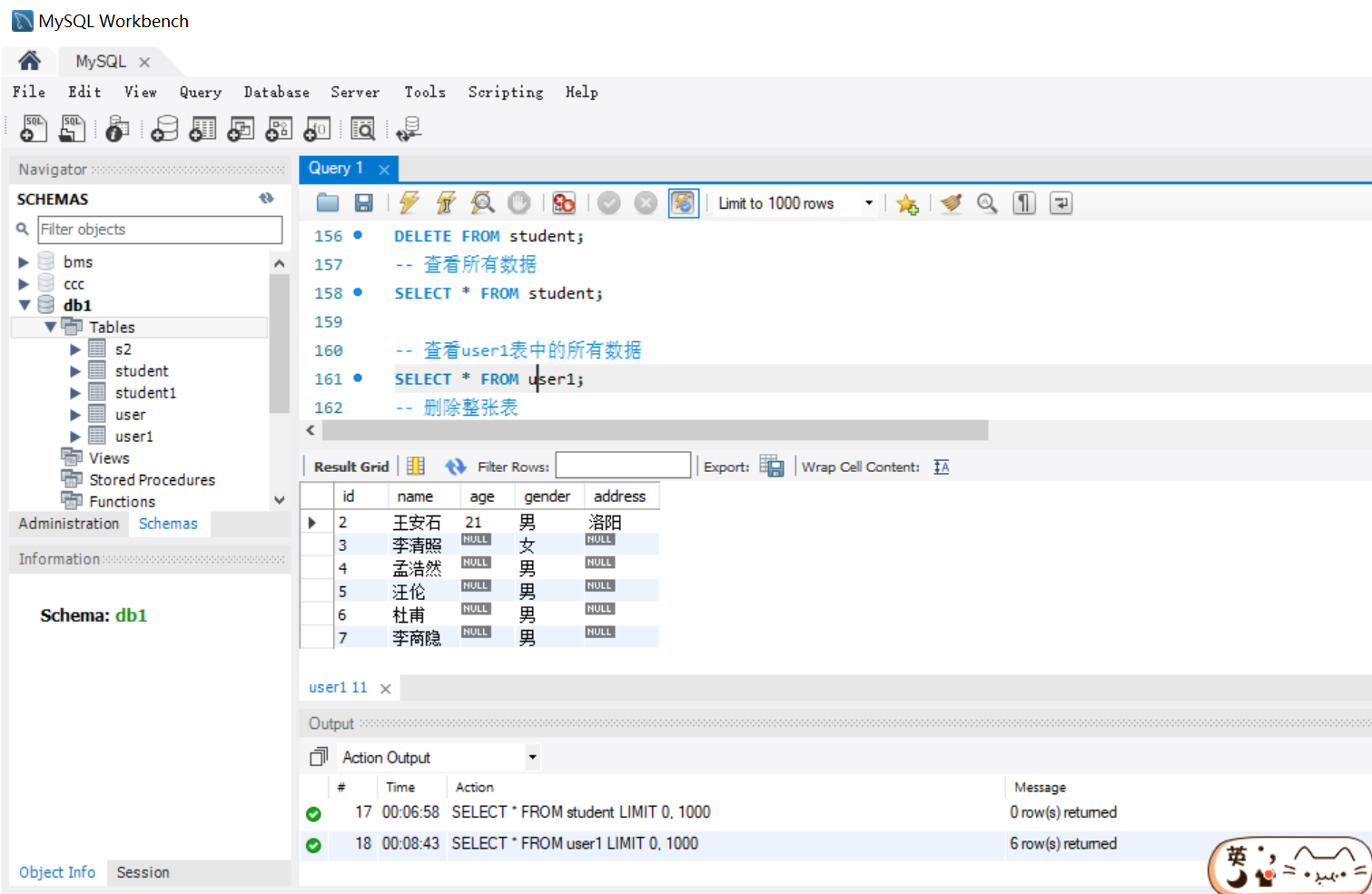
- 方法二:
# 数据准备
-- 创建 student 表
CREATE TABLE student(
id INT,
name VARCHAR(20),
sex CHAR(1),
age TINYINT,
city VARCHAR(50)
);
-- 插入 5 条数据
INSERT INTO student
VALUES(1,'小李','男', 18, '北京'),(2,'小白','女', 20, '成都'),(3,'小王','男', 23, '上海'),(4,'小赵','女', 21, '深圳'),(5,'小周','男', 25, '杭州');
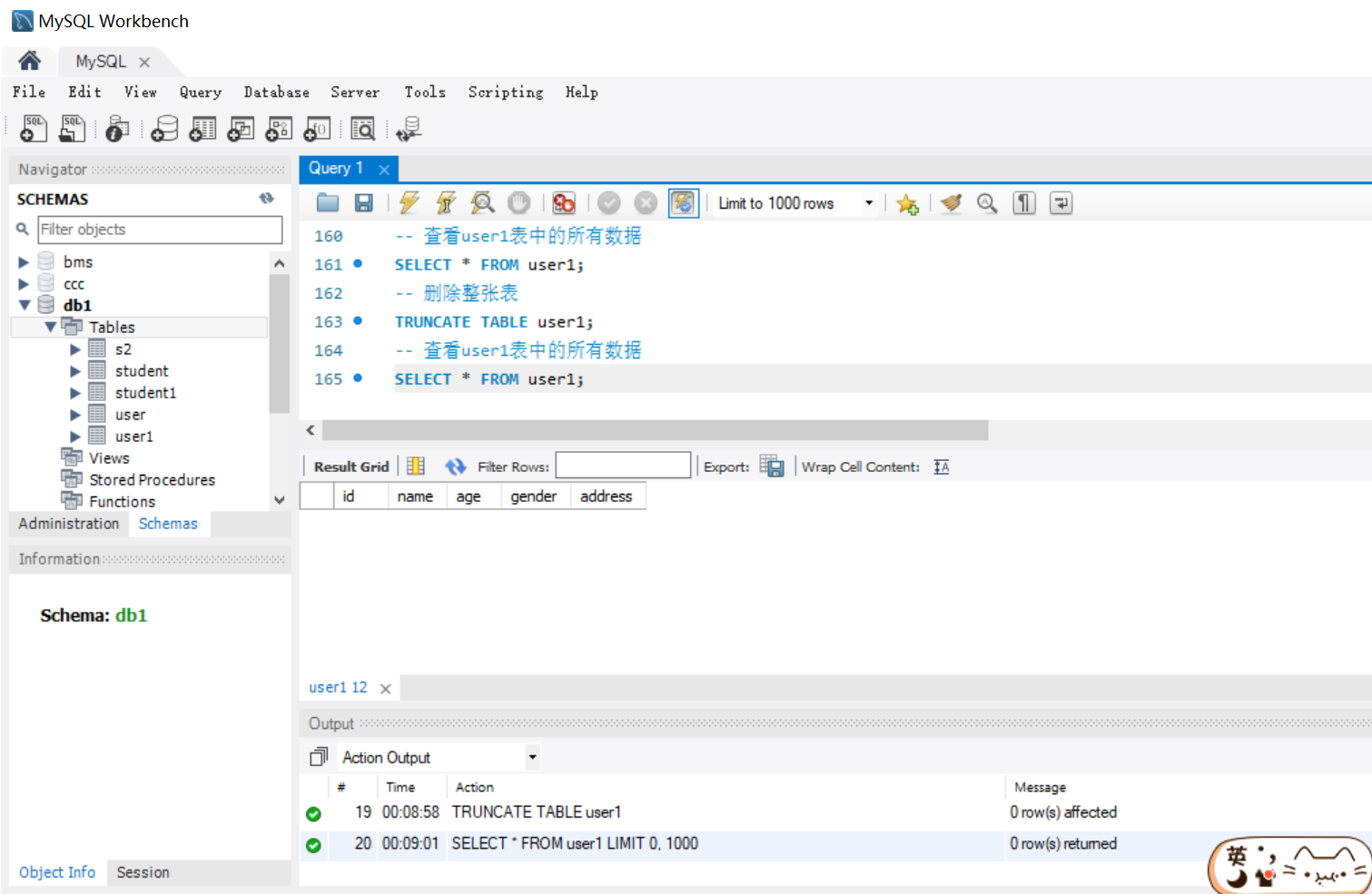
-- 删除 student 表中所有数据
TRUNCATE TABLE student;
注:该方法会先删除整张表,再重新创建一张一模一样的空白表。
二、事务处理
2.1 简介
- 事务处理:
-
事务处理是数据库管理系统(DBMS)中至关重要的功能,用于确保数据库操作的一致性、完整性和可靠性。
-
事务处理使得数据库能够在并发环境中,有效地处理多个用户的请求,同时维护数据的一致性。
-
- 事务:
-
一个事务(Transaction)是一个独立的工作单元,通常包含多个数据库操作(如插入、更新、删除)。
-
这些操作被视为一个整体,要么全部成功,要么全部失败。
-
事务可以保证数据库从一种一致性状态,变到另一种一致性状态。
-
2.2 事务的ACID特性
- 事务具备四个关键特性:
-
原子性(Atomicity):事务中的所有操作必须被视为一个原子单位。如果事务中的任何操作失败,则整个事务必须失败,所有已经执行的操作必须回滚,以保证数据库状态不变。
- 例子:银行转账中,扣款和存款操作必须同时成功或同时失败。
-
一致性(Consistency):事务在执行前后,数据库必须保持一致状态。事务在开始和结束时,数据库都必须满足所有的约束和规则。
- 例子:银行转账后,总金额应保持不变。
-
隔离性(Isolation):在事务执行期间,不同事务之间的操作互不干扰。并发事务在执行时互不影响,未提交的事务对其他事务是不可见的。
- 例子:在同一时期内,两个不同的用户对同一账户进行操作时,互不干扰。
-
持久性(Durability):一旦事务提交,其对数据库的改变将永久保存在数据库中,即使系统发生故障,这些改变也不会丢失。
- 例子:银行转账完成后,即使系统崩溃,转账结果也会保留。
2.3 事务的控制语句
-
BEGIN TRANSACTION或START TRANSACTION:开始一个新的事物;
-
COMMIT:提交当前事务,将所有更改永久保存到数据库中。
-
ROLLBACK:回滚当前事务,撤销自事务开始以来的所有更改。
-
SAVEPOINT:设置一个事务保存点,可以在需要时回滚到该保存点。
-
RELEASE SAVEPOINT:删除之前定义的保存点。
-
ROLLBACK TOSAVEPOINT:回滚到指定的保存点。
2.4 事务的隔离级别
-
数据库为了实现事务的隔离性,引入了不同的隔离级别。
-
不同的隔离级别允许不同程度的并发性和数据一致性。
常见的隔离级别:
-
读未提交(Read Uncommitted):最低的隔离级别。事务可以读取其他未提交事务的数据,可能导致“脏读”。
-
读已提交(Read Committed):事务只能读取已提交的数据,避免了脏读,但可能会出现“不可重复读”。
-
可重复度(Repeatable Read):在一个书屋内,多次读取同一数据,会得到相同的结果,避免了不可重复读,但可能会出现“幻读”。
-
串行化(Serializable):最高的隔离级别,通过完全锁定事务涉及的数据,确保事务之间完全隔离,避免了度脏、不可重复读和幻读。
2.5 事务中的常见问题
-
脏读(Dirty Read):一个事务读取了另一个未提交事务的数据。
-
不可重复读(Non-repeatable Read):一个事务在两次读取统一数据时,结果不同,原因是其他事务修改了该数据并提交。
-
幻读(Phantom Read):一个事务在两次查询过程中,另一个事务插入或删除了数据,使得两次查询结果不一致。
2.6 实例
- 一个经典的事务应用场景,是银行系统的转账操作:
BEGIN TRANSACTION;
UPDATE accounts SET balance = balance -100 WHERE account_id = 100011;
-- 假设在这里发生了某种错误
IF ERROR THEN
ROLLBACK;
RETURN;
END IF;
UPDATE accounts SET balance = balance + 100 WHERE account_id =100012;
COMMIT;
- 转账操作由两个更新操作完成,如果任何一个操作失败,整个事务将回滚,确保资金不会丢失或不一致。
或者用另一种方式:
# 开始一个事务,确保接下来的操作要么全部成功,要么全部失败。
BEGIN TRANSACTION;
# 从account_id为100011的账户中扣除100单位的金额。这表示用户1正在转出100单位的钱。
UPDATE accounts SET balance = balance -100 WHERE account_id = 100011;
-- 检查操作是否成功
IF @@ERROR <> 0
# 检查上一步操作是否成功。如果失败,事务回滚,并终止操作。@@ERROR是SQL Server中的一个系统函数,用于返回上一个Transact-SQL语句执行中的错误号。如果没有错误,则返回0。
ROLLBACK;
RETURN;
END IF;
# 向account_id为100012的账户中增加100单位的金额。这表示用户2正在接收100单位的钱。
UPDATE accounts SET balance = balance + 100 WHERE account_id =100012;
-- 检查操作是否成功
IF @@ERROR <> 0
# 再次检查操作是否成功。如果失败,事务回滚,并终止操作。
ROLLBACK;
RETURN;
END IF;
# 提交事务,将所有更改永久保存到数据库中。
COMMIT;
