关键数据
- 代码的执行日志
- 代码执行的截图
- page source(页面源代码)
作用
-
日志
1、记录代码的执行过程,方便复现
2、作为bug依据 -
截图
1、断言失败或成功截图
2、异常截图达到丰富报告的作用
3、作为bug依据 -
page source
1、协助排查报错时元素当时是否存在在页面上
行为日志记录
- 日志配置
class LogConfig:
def log_config(self):
"""
1、创建logger实例
2、设置日志级别
3、使用流处理器标准输出格式输出
4、设置日志打印格式
5、添加格式配置
6、添加日志配置
:return:
"""
# 1、创建logger实例
self.logger = logging.getLogger('simple_example')
# 2、设置日志级别
self.logger.setLevel(logging.DEBUG)
# 3、使用流处理器输出
ch = logging.StreamHandler() # StreamHandler() 用于将日志消息以标准输出流的格式(sys.stdout)输出
ch.setLevel(logging.DEBUG)
# 4、设置日志打印格式: 打印日志时间--当前模块名--日志级别--日志信息
formatter = logging.Formatter \
('%(asctime)s-%(name)s-%(levelname)s-%(message)s')
# 5、添加格式配置
ch.setFormatter(formatter)
# 6、添加日志配置
self.logger.addHandler(ch)
- 脚本日志级别(debug、info、warning、error、critical)
1、debug记录执行步骤信息
2、info记录关键信息,比如断言等
日志配置结合selenium定位操作,记录自动化关键数据实例:
class TestDataRecord:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.get("https://www.sogou.com")
self.driver.implicitly_wait(3)
def teardown_class(self):
self.driver.quit()
def test_log_data(self):
"""
1、进入搜狗首页
2、输入霍格沃茨测试开发,进行搜索操作
3、获取搜索结果(对应测试用例的实际结果)
:return:
"""
search_content = "霍格沃兹测试开发学社"
self.driver.find_element(By.ID, "query").send_keys(search_content)
logger.debug(f"搜索的信息为{search_content}")
self.driver.find_element(By.ID, "stb").click()
search_res = self.driver.find_element(By.CSS_SELECTOR, "em")
logger.info(f"实际结果为{search_res.text},预期结果为{search_content}")
assert search_res.text == search_content
步骤截图记录
- save_screenshot(截图路径+名称)
- 记录关键页面(不需要每个步骤都截图)
1、断言页面
2、重要的业务场景页面
3、容易出错的页面
# 调用save方法截图并保存在当前路径下的image文件夹下:
driver.save_screenshot("./images/search1.png")
实例:
def test_screen_data_record(self):
"""
# 截图记录
1、进入搜狗首页
2、输入霍格沃茨测试开发,进行搜索操作
3、获取搜索结果(对应测试用例的实际结果)
4、对断言结果截图记录
:return:
"""
search_content = "霍格沃兹测试开发学社"
self.driver.find_element(By.ID, "query").send_keys(search_content)
logger.debug(f"搜索的信息为{search_content}")
self.driver.find_element(By.ID, "stb").click()
search_res = self.driver.find_element(By.CSS_SELECTOR, "em")
logger.info(f"实际结果为{search_res.text},预期结果为{search_content}")
# 在断言前截图记录,双重保障
self.driver.save_screenshot("search_res.png")
assert search_res.text == search_content
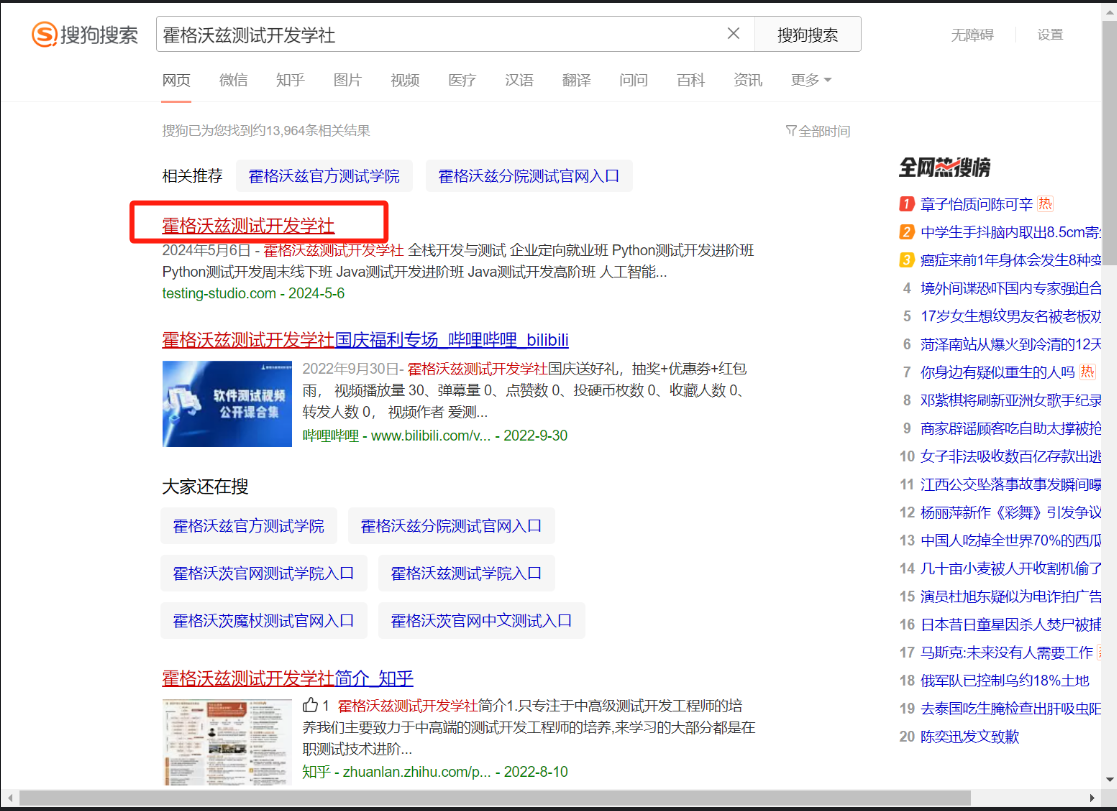
page_source记录(在代码报错处,获取网页源代码,进行错误原因定位)
- 使用page_source属性获取页面源码
- 在调试过程中,如果有找不到元素的错误可以保存当时的page_source调试代码
# 在报错行前面添加保存page_source的操作
with open("record.html","w", encoding="u8") as f:
f.write(self.driver.page_source)
实例:
def test_page_source_data_record(self):
search_content = "霍格沃兹测试开发学社"
self.driver.get("https://www.sogou.com/")
# 获取page_source
with open("page_source.html", "w", encoding="utf8") as f:
f.write(self.driver.page_source)
# 输入霍格沃茨测试开发,进行搜索操作,此处有错误,在报错前添加page_source,获取源码,帮助定位问题
self.driver.find_element(By.ID, "query1").send_keys(search_content)


