一,数据处理 grep
1.1 基本语法
- grep [options] pattern [file…] ——[options]表示选项,具体的命令选项见下表。pattern表示要匹配的模式(包括目标字符串、变量或者正则表达式),file表示要查询的文件名,可以是一个或者多个
-c :只打印匹配的文本行的行数,不显示匹配的内容
-i :匹配时忽略字母的大小写
-h :当搜索多个文件时,不显示匹配文件名前缀
-n :列出所有的匹配的文本行,并显示行号
-l :只列出含有匹配的文本行的文件的文件名,而不显示具体的匹配内容
-s :不显示关于不存在或者无法读取文件的错误信息
-v :只显示不匹配的文本行
-w :匹配整个单词
-x :匹配整个文本行
-r :递归搜索,搜索当前目录和子目录
-q :禁止输出任何匹配结果,而是以退出码的形式表示搜索是否成功,其中0表示找到了匹配的文本行
-b :打印匹配的文本行到文件头的偏移量,以字节为单位
-E :支持扩展正则表达式
-P :支持Perl正则表达式
-F :不支持正则表达式,将模式按照字面意思匹配
1.2 内容检索
-
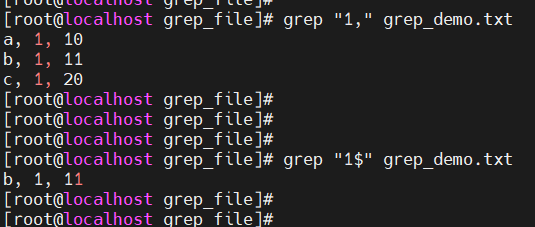
获取行
grep pattern file
-
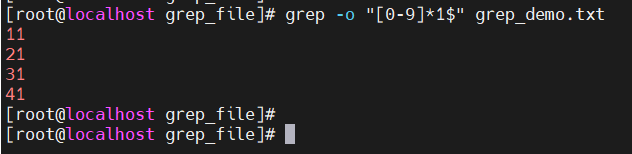
获取内容
grep -o pattern file
-
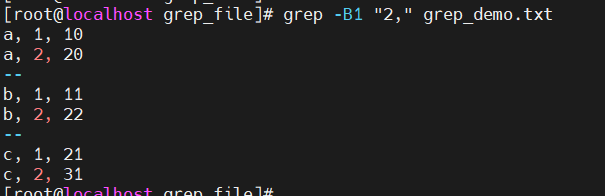
获取上下文
grep -A -B -C pattern file-
-A:after- 取后n行的数据 -
-B:before - 取前n行的数据 -
-C: 取前n行和后n行的数据
-
1.3 文件检索
-
递归搜索
grep pattern -r dir/

-
展示匹配文件名
grep -H 111 /tmp/1 -
不展示匹配文件名
grep -h 111 /tmp/1

-
只展示匹配文件名
grep -l 111 /tmp/1

1.4 范围约束
- 忽略大小写
grep -i pattern file - 不显示匹配的行
grep -v pattern file - 使用扩展正则表达式
grep -E pattern file - 文件范围和目录范围约束
grep 111 -r /tmp/demo/ --include "11*"
1.5 进程检索
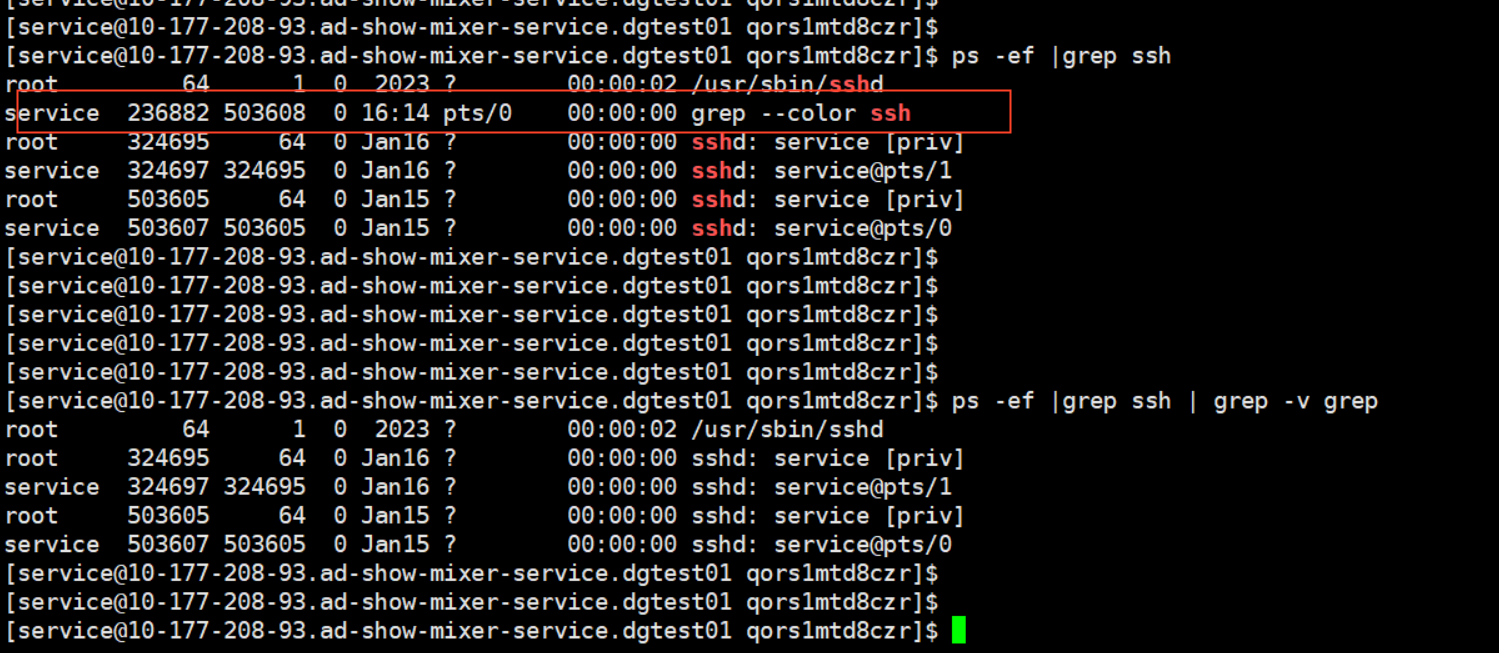
- 进程过滤场景比较特殊,需要注意
- grep 本身会开启新进程,所以需要单独过滤掉 grep 进程
- ps -ef |grep ssh | grep -v grep
- ps -ef |grep ssh | grep -v grep
二,数据处理 awk
参考文档: awk命令详解_51CTO博客_awk命令详解if
2.1 基本语法
- awk 是 linux 下的一个命令,同时也是一种语言解析引擎
- awk 具备完整的编程特性。比如执行命令,网络请求等
- 精通 awk,是一个 linux 工作者的必备技能
- 语法
awk 'pattern{action}'
2.2 awk上下文变量
- 开始 BEGIN 结束 END
- 行数 NR
- 字段与字段数 $1 $2 … $NF NF(代表1,2,n列,NF代表最后一列)
- 整行 $0
- 字段分隔符 FS
- 输出数据的字段分隔符 OFS
- 记录分隔符 RS
- 输出字段的行分隔符 ORS
2.3 字段变量用法
- -F 参数指定字段分隔符,可以用|指定多个- 多分隔符 -F ‘<|>’
- BEGIN{FS=“_”} 也可以表示分隔符
- $0 代表当前的记录
- $1 代表第一个字段
- $N 代表第 N 个字段
- $NF 代表最后一个字段
- $(NF-1) 代表倒数第二个字段
2.4 pattern 表达式案例
-
开始和结束:
awk 'BEGIN{}END{}' -
正则匹配 :
$1~/pattern//pattern/- 整行匹配:
awk '/Running/' - 字段匹配 :
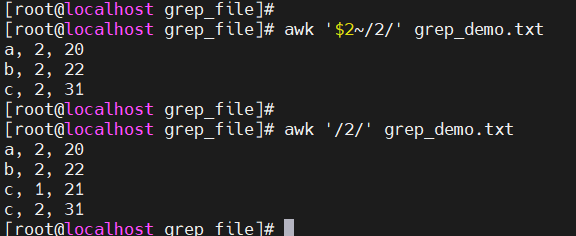
awk '$2~/xxx/'-
$2~/2/:表示第2列的数据中包含2数字的行所有的数据
-
- 整行匹配:
-
行数表达式
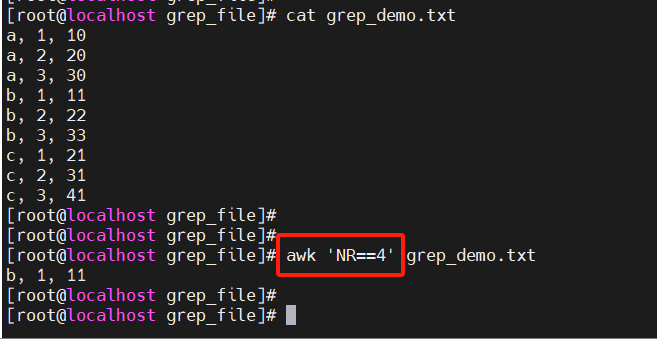
- 取第二行:
awk 'NR==2'
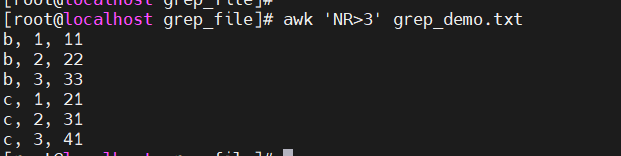
- 去掉第一行 :
awk 'NR>1'
- 取第二行:
-
区间选择
-
awk '/aa/,/bb/':取区间在20~30的行数据
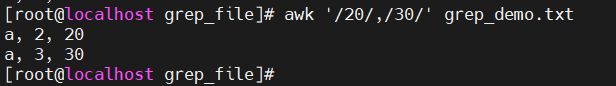
-
awk '/1/,NR==2'
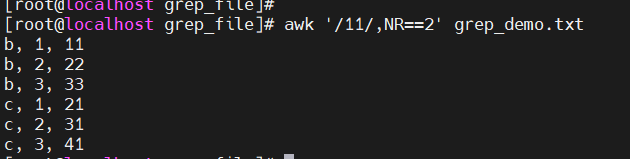
-
-
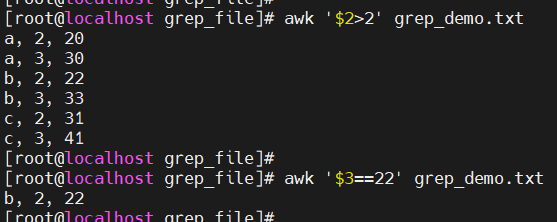
比较表达式 :
$2>2$1=="b"
2.5 行为表达式 {action}
- 打印
{print $0}{print $2} - 赋值
{$1="abc"} - 处理函数
- 原始内容 $0
- 更新后内容
{$1=$1;print $0} - 实例:
-
单行转多行:echo 1:2:3 | awk ‘BEGIN{RS=“:”}{print $0}’
-
多行变单行:awk ‘BEGIN{RS=“”;FS=“\n”;OFS=“:”}{$1=$1;print $0}’ / awk ‘BEGIN{ORS=“:”}{$1=$1;print $0}’
-
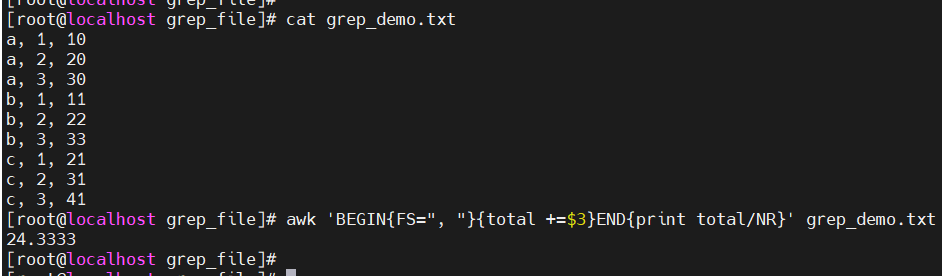
计算平均数:awk ‘BEGIN{total=0;FS=“,”}{total+=$2}END{print total/NR}’
-


2.6 awk 的词典结构 array
-
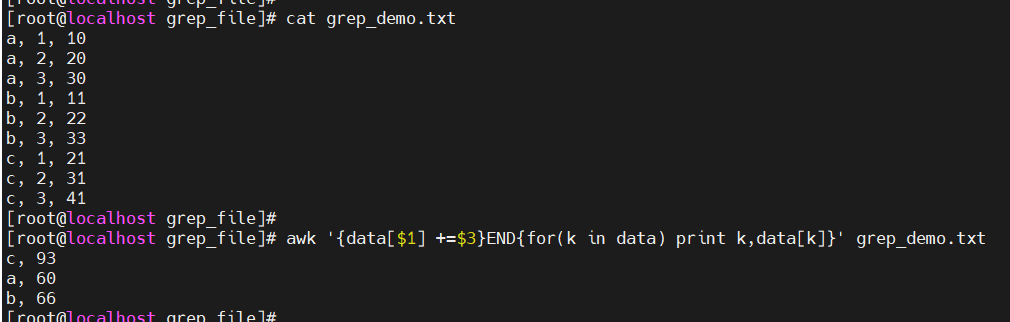
统计营业额:awk ‘{data[$1]+=$3}END{for(k in data) print k,data[k]}’
-
统计营业额平均值:awk ‘{data[$1]+=$3;count[$1]+=1;}END{for(k in data) print k,data[k]/count[k]}’

三,数据处理 sed(常用于定位)
3.1 基本语法与常用参数
- 语法结构 sed [addr]X[options]
- -e 表达式
- sed -n ‘2p’ 打印第二行
- sed ‘s#hello#world#’ 修改替换
- -i 直接修改源文件
- -E 扩展表达式
- –debug 调试
3.2 pattern 表达式
- 行数与行数范围 20 30,35
- 正则匹配 /pattern/
- 区间匹配 //,//

3.3 action 表达式
-
p 打印,通常结合-n 参数:sed -n ‘2p’
-
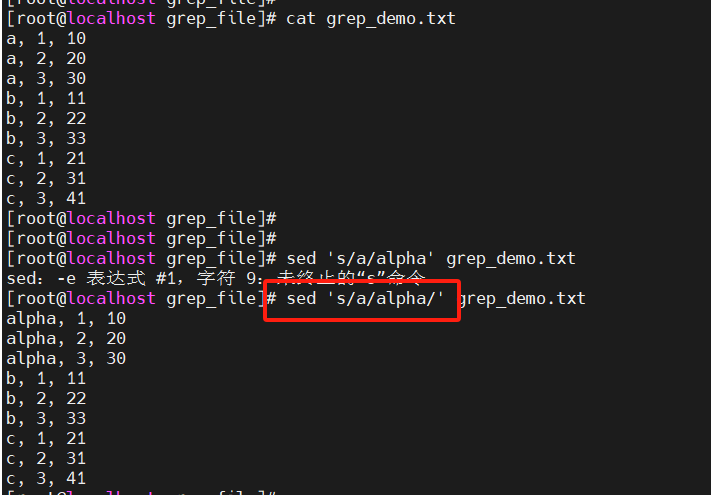
s 查找替换:s/REGEXP/REPLACEMENT/[FLAGS]
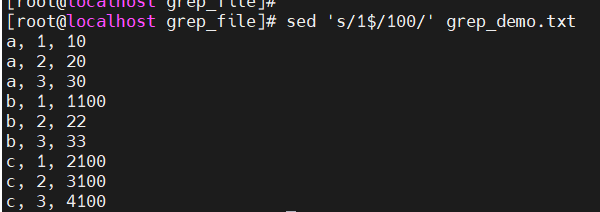
(以1结尾的数据都乘以100)
-
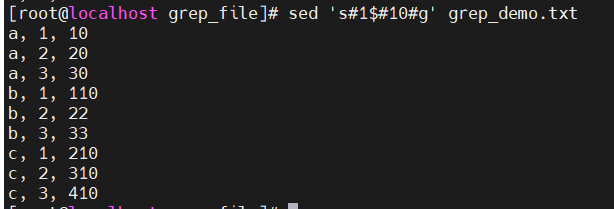
s 后面的追加字符可以为任意字符
-
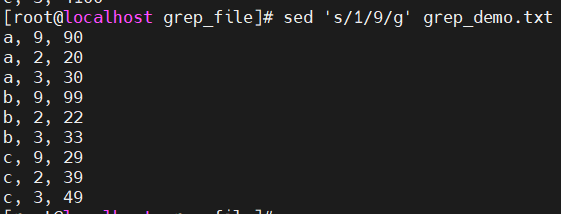
g 表示全局匹配
-
& 表示匹配内容(在匹配的规则前/后添加对应的内容)
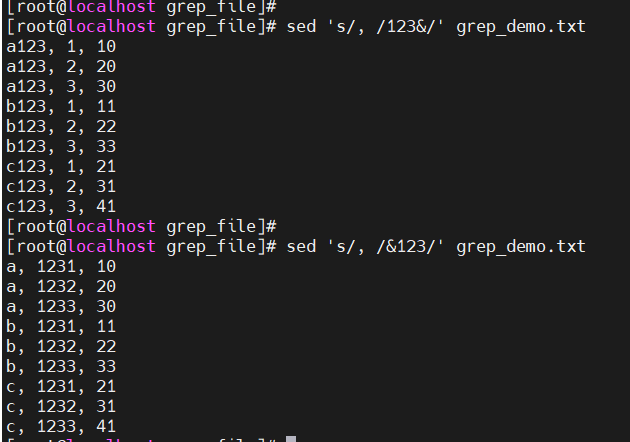
-
-
d 删除,删除前两行 sed ‘1,2d’;删除最后一行 sed ‘$d’
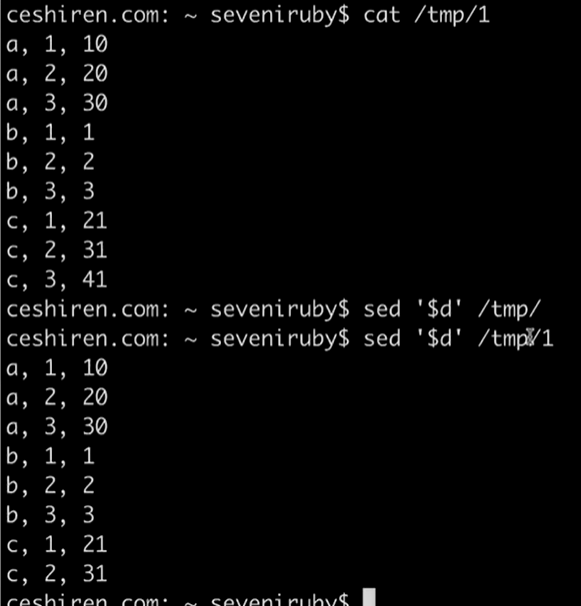
-
a 追加(匹配规则行后追加)
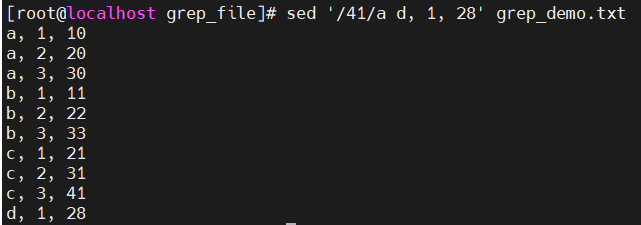
-
c 改变(!!! 改变整行的数据)
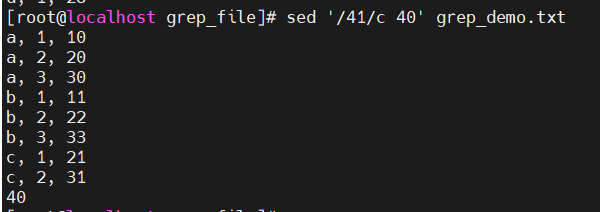
-
i 插入内容到匹配行之前
-
e 执行命令
-
分组匹配与字段提取:sed ‘s#([0-9])|([a-z])#\1 \2#’
3.4 反向引用
- 使用()对数据进行分组
- 使用\1 \2 反向引用分组
四,linux三剑客与管道使用
4.1 程序运行环境输入与输出
-
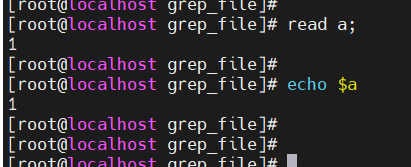
标准输入 0
read a;echo $a
-
标准输出 1
-
echo ceshiren.com
-
-
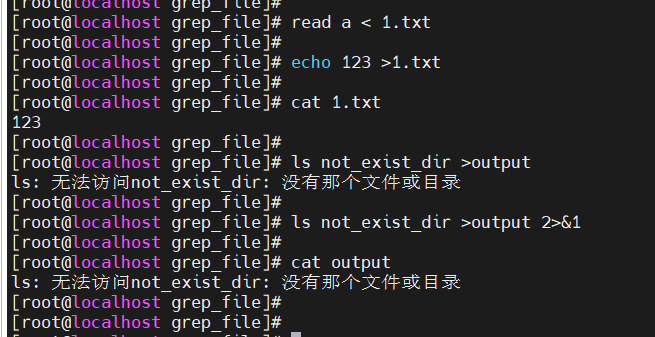
错误输出
ls not_exist_dir
4.2 管道重定向
- 管道与管道之间可以重定向
- 管道与文件之间可以重定向
4.3 管道连接符 |
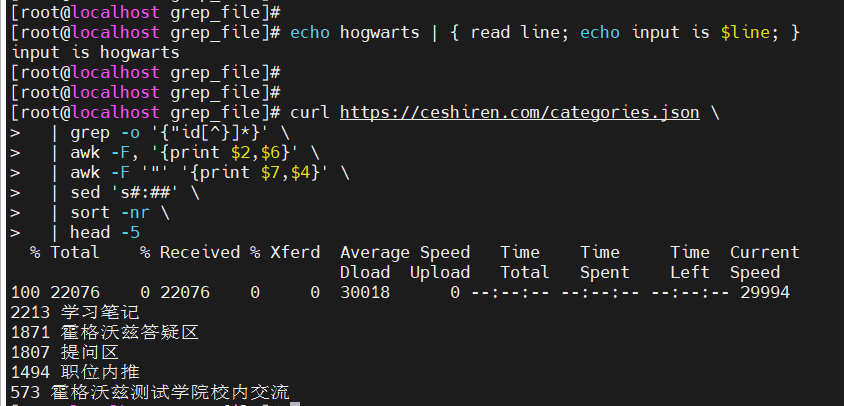
- 管道连接符
|可以连接多个程序的执行 - 管道连接是以子进程的方式启动的
4.4 管道执行的上下文控制
- 使用 { command; } 注意花括号与内部命令之间的空格与分号
- 使用控制逻辑 while read 组合
- 使用 $() ``
- 如下两个方式可以获得变量x

- 如下两个方式可以获得变量x
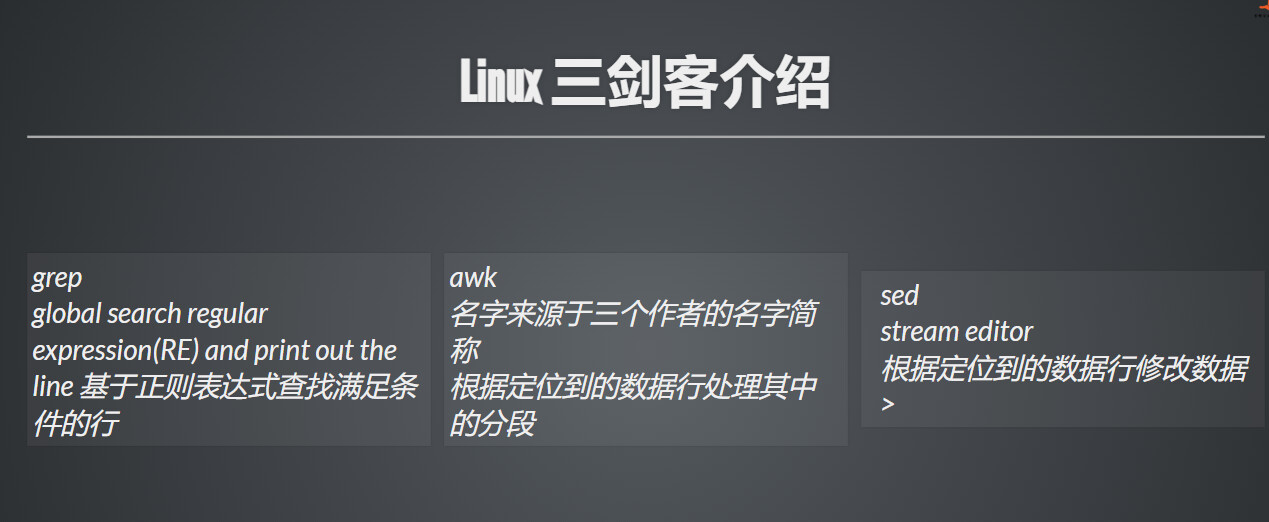
4.5 三剑客介绍
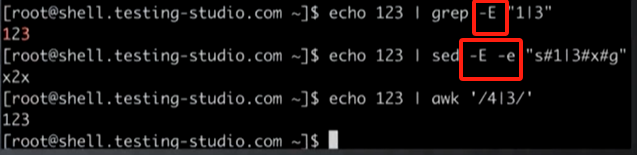
4.6 BRE 基本正则表达式
- ^ 开头 $结尾
-
[a-z][0-9]区间,如果开头带有^表示不能匹配区间内的元素 -
*0 个或多个 -
.表示任意字符
4.7 ERE 扩展正则表达式
- 基本正则表达式(BRE)基础上的扩展
-
?非贪婪匹配 -
+一个或者多个 -
()分组 -
{}范围约束 -
|匹配多个表达式的任何一个
五,Linux进阶命令
4.1 curl 命令
4.1.1 接口请求
- curl是一个发起请求数据给服务器的工具
- curl支持的协议FTP、FTPS、HTTP、HTTPS、TFTP、SFTP、Gopher、SCP、Telnet、DICT、FILE、LDAP、LDAPS、IMAP、POP3、SMTP和RTSP
- curl是一个非交互的工具
4.1.2 curl发起请求
- 发起get请求 :curl -G url
- 发起post请求 : curl -d “name=xxx” url / curl -X POST url
4.1.3 常用参数
- curl -o filename url 保存响应内容
- curl -i url 显示头信息
- curl -I url 仅显示头信息
- curl -s url 静默访问不输出错误和进度
- curl -v url 输出通信过程
- curl -H headers url 添加头信息
- curl -x “ip:port” url 为请求添加代理
4.2 jq工具
4.2.1 jq安装
- yum install jq
4.2.2 常用命令
-
jq格式化:echo ‘{“a”:1,“b”:2}’ | jq ‘.’
-
json 数据提取
- 提取指定key: echo ‘{“foo”:53,“bar”:“some datas”}’ | jq .foo
- 从数组中提取单个数据: echo ‘[{“a”:1,“b”:2},{“c”:3,“d”:4}]’ |jq .[0]
- 从数组中提取所有数据: echo ‘[{“a”:1,“b”:2},{“c”:3,“d”:4}]’ |jq .
- 从数组中提取多个值: echo ‘[{“a”:1,“b”:2},{“c”:3,“d”:4},{“e”:5,“f”:6}]’ |jq .[0,2]
-
json 数据重组
- 数据重组成数组:echo ‘{“a”:1,“b”:2,“c”:3,“d”:4}’| jq ‘[.a,.b]’
- 数据重组成对象:echo ‘{“a”:1,“b”:2,“c”:3,“d”:4}’| jq ‘{“tmp”:.b}’
