前言
练习:
访问 Testerhome 的精华帖网址:https://testerhome.com/topics/excellent。
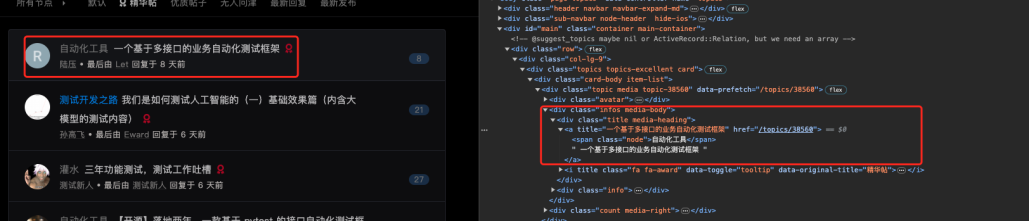
通过浏览器的开发者工具查看精华帖的元素信息如下:
要求:
根据a标签的中的 title 属性进行元素获取,实现获取到精华帖的帖子标题,并且逐步点击该页精华帖进入帖子详情并回退。
-
环境
- Java 8
- Maven
- Selenium 4.0
- Junit 5
尝试
通过开发者工具可以看到a标签的 title 属性的值其实就是帖子标题,即问题可以转化为获取到精华帖的标题。
根据 xpath 定位,即"//div[@class=‘title media-heading’]/a/text()",即可定位到帖子标题
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.time.Duration;
import java.util.List;
public class imoocTest {
private static WebDriver driver;
@BeforeAll
static void setUP() {
// 获取当前文件下所在的目录
String currentDirectory = System.getProperty("user.dir");
// 设置chromeDriver
System.setProperty("webdriver.chrome.driver", currentDirectory + "/src/test/resources/Driver/Chrome/chromedriver");
ChromeOptions options = new ChromeOptions();
//浏览器模拟手机模式
options.addArguments("--disable-web-security");
// 最大化窗口
options.addArguments("--start-maximized");
//解决报 403 问题
options.addArguments("--remote-allow-origins=*");
driver = new ChromeDriver(options);
// 隐式调用
driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(10));
}
@AfterAll
static void tearDown() {
//关闭浏览器
driver.quit();
}
@Test
public void test() throws InterruptedException {
// 打开testerhome的精华帖网站
driver.get("https://testerhome.com/topics/excellent");
// 获取帖子标题
List<WebElement> postTitleList = driver.findElements(By.xpath("//div[@class='title media-heading']/a/text()"));
for (int i = 0; i < postTitleList.size(); i++) {
String postTitle = postTitleList.get(i).getText();
Thread.sleep(1000);
System.out.println(i + ":" + postTitle);
Thread.sleep(1000);
// 点击帖子,进入帖子详情页面
driver.findElement(By.xpath("//a[@title='" + postTitle.trim() + "']")).click();
// 获取帖子详情页面的标题
String post = driver.findElement(By.xpath("//h1[@class='media-heading']/span[@class='title']")).getText().trim();
// 帖子列表的标题和帖子详情的标题进行对比
Assertions.assertEquals(postTitle, post, "帖子标题不一致");
}
}
}
执行代码,报错,报错信息
org.openqa.selenium.InvalidSelectorException: invalid selector: The result of the xpath expression "//div[@class='title media-heading']/a/text()" is: [object Text]. It should be an element.
(Session info: chrome=119.0.6045.199)
For documentation on this error, please visit: https://www.selenium.dev/documentation/webdriver/troubleshooting/errors#invalid-selector-exception
Build info: version: '4.15.0', revision: '1d14b5521b'
System info: os.name: 'Mac OS X', os.arch: 'x86_64', os.version: '13.6', java.version: '11.0.21'
Driver info: org.openqa.selenium.chrome.ChromeDriver
Command: [f7d4c506c9833333edcd2dc8f0c9451d, findElements {using=xpath, value=//div[@class='title media-heading']/a/text()}]
Capabilities {acceptInsecureCerts: false, browserName: chrome, browserVersion: 119.0.6045.199, chrome: {chromedriverVersion: 119.0.6045.105 (38c72552c5e..., userDataDir: /var/folders/9l/slrbyxhs46l...}, fedcm:accounts: true, goog:chromeOptions: {debuggerAddress: localhost:58406}, networkConnectionEnabled: false, pageLoadStrategy: normal, platformName: mac, proxy: Proxy(), se:cdp: ws://localhost:58406/devtoo..., se:cdpVersion: 119.0.6045.199, setWindowRect: true, strictFileInteractability: false, timeouts: {implicit: 0, pageLoad: 300000, script: 30000}, unhandledPromptBehavior: dismiss and notify, webauthn:extension:credBlob: true, webauthn:extension:largeBlob: true, webauthn:extension:minPinLength: true, webauthn:extension:prf: true, webauthn:virtualAuthenticators: true}
Session ID: f7d4c506c9833333edcd2dc8f0c9451d
at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at java.base/jdk.internal.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at java.base/jdk.internal.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.base/java.lang.reflect.Constructor.newInstance(Constructor.java:490)
at org.openqa.selenium.remote.codec.w3c.W3CHttpResponseCodec.createException(W3CHttpResponseCodec.java:200)
at org.openqa.selenium.remote.codec.w3c.W3CHttpResponseCodec.decode(W3CHttpResponseCodec.java:133)
at org.openqa.selenium.remote.codec.w3c.W3CHttpResponseCodec.decode(W3CHttpResponseCodec.java:52)
at org.openqa.selenium.remote.HttpCommandExecutor.execute(HttpCommandExecutor.java:191)
at org.openqa.selenium.remote.service.DriverCommandExecutor.invokeExecute(DriverCommandExecutor.java:200)
at org.openqa.selenium.remote.service.DriverCommandExecutor.execute(DriverCommandExecutor.java:175)
at org.openqa.selenium.remote.RemoteWebDriver.execute(RemoteWebDriver.java:607)
at org.openqa.selenium.remote.ElementLocation$ElementFinder$2.findElements(ElementLocation.java:182)
at org.openqa.selenium.remote.ElementLocation.findElements(ElementLocation.java:103)
at org.openqa.selenium.remote.RemoteWebDriver.findElements(RemoteWebDriver.java:377)
at org.openqa.selenium.remote.RemoteWebDriver.findElements(RemoteWebDriver.java:371)
at imoocTest.test(imoocTest.java:47)
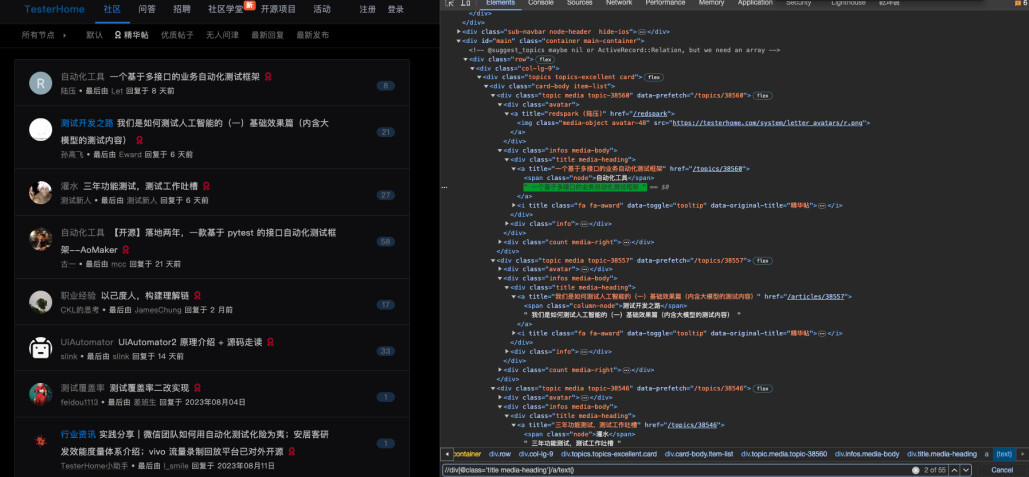
这个报错信息org.openqa.selenium.InvalidSelectorException: invalid selector: The result of the xpath expression “//div[@class=‘title media-heading’]/a/text()” is: [object Text]. It should be an element.是Selenium在尝试通过XPath表达式查找元素时抛出的异常。
当使用XPath表达式//div[@class=‘title media-heading’]/a/text()时,该表达式的结果指向了一个文本节点(Text Node),而不是一个元素节点(Element Node)。Selenium的findElement或findElements方法期望返回的是DOM中的元素。然而,在XPath语法中, /text()选择器用于获取元素内的纯文本内容,它不会返回元素本身,而是返回包含在该元素内的文本内容。
因此,当尝试用上述XPath表达式定位元素时,Selenium发现结果是一个文本节点而非元素节点,所以抛出了InvalidSelectorException,提示所选表达式的结果应该是元素类型,而实际上得到了文本类型。
解决
首先想到的方法是通过获取div下a标签内的文本内容,正确的做法是在找到a元素后,通过调用.getText()方法来获取其文本内容。获取到的文本信息如下:
自动化工具 一个基于多接口的业务自动化测试框架
在通过 String 的 split 方法,通过空格进行分割,获取到标题。
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.time.Duration;
import java.util.List;
public class imoocTest {
private static WebDriver driver;
@BeforeAll
static void setUP() {
// 获取当前文件下所在的目录
String currentDirectory = System.getProperty("user.dir");
// 设置chromeDriver
System.setProperty("webdriver.chrome.driver", currentDirectory + "/src/test/resources/Driver/Chrome/chromedriver");
ChromeOptions options = new ChromeOptions();
//浏览器模拟手机模式
options.addArguments("--disable-web-security");
// 最大化窗口
options.addArguments("--start-maximized");
//解决报 403 问题
options.addArguments("--remote-allow-origins=*");
driver = new ChromeDriver(options);
// 隐式调用
driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(10));
}
@AfterAll
static void tearDown() {
//关闭浏览器
driver.quit();
}
@Test
public void test() throws InterruptedException {
// 打开testerhome的精华帖网站
driver.get("https://testerhome.com/topics/excellent");
// 获取帖子标题
List<WebElement> postTitleList = driver.findElements(By.xpath("//div[@class='title media-heading']/a"));
for (int i = 0; i < postTitleList.size(); i++) {
String postTitle = postTitleList.get(i).getText().split(" ")[1];
Thread.sleep(1000);
System.out.println(i + ":" + postTitle);
Thread.sleep(1000);
// 点击帖子,进入帖子详情页面
driver.findElement(By.xpath("//a[@title='" + postTitle.trim() + "']")).click();
// 获取帖子详情页面的标题
String post = driver.findElement(By.xpath("//h1[@class='media-heading']/span[@class='title']")).getText().trim();
// 帖子列表的标题和帖子详情的标题进行对比
Assertions.assertEquals(postTitle, post, "帖子标题不一致");
}
}
}
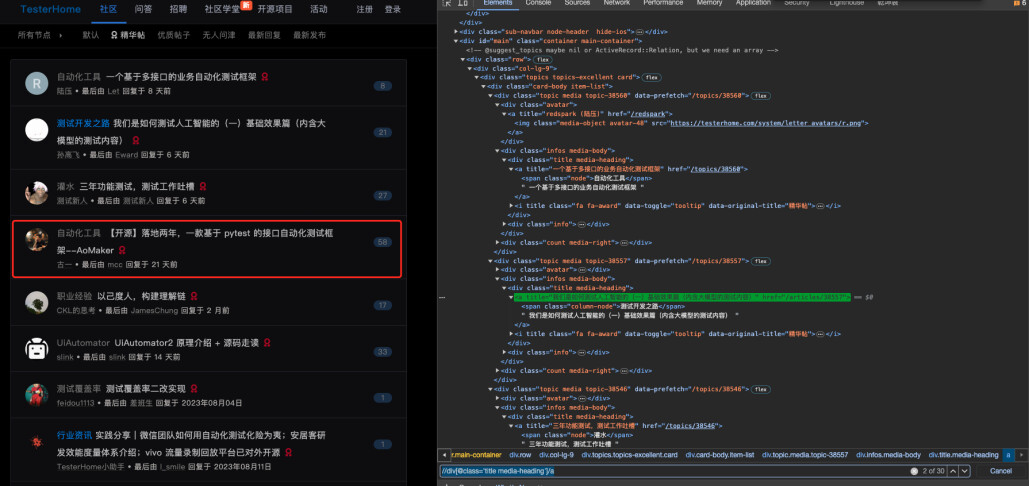
再次执行,发下执行几个之后,报错。其原因是如图中第四个帖子,有些帖子中有空格,导致用空格进行分割后获取到的帖子标题缺失,导致的元素定位失败。
那如何办呢? 这种时刻就需要动用万能的 Js 大法了。
之前已经用 xpath 定位,即"//div[@class=‘title media-heading’]/a/text()",即可定位到帖子标题。
但是此时有个问题,就是我对于 Js 只是了解个大概,不知道如何将 xpth 定位转为 Js 代码。
虽然我不知道如何去转化,但是可以活用工具,例如大模型就可以帮助我们快速的转化。
使用阿里的通义千问,询问它如何进行转化,提高自己的效率。


获取到代码之后,修改自己的代码
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.openqa.selenium.By;
import org.openqa.selenium.JavascriptExecutor;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
public class imoocTest {
private static WebDriver driver;
@BeforeAll
static void setUP() {
// 获取当前文件下所在的目录
String currentDirectory = System.getProperty("user.dir");
// 设置chromeDriver
System.setProperty("webdriver.chrome.driver", currentDirectory + "/src/test/resources/Driver/Chrome/chromedriver");
ChromeOptions options = new ChromeOptions();
//浏览器模拟手机模式
options.addArguments("--disable-web-security");
// 最大化窗口
options.addArguments("--start-maximized");
//解决报 403 问题
options.addArguments("--remote-allow-origins=*");
driver = new ChromeDriver(options);
// 隐式调用
driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(10));
}
@AfterAll
static void tearDown() {
//关闭浏览器
driver.quit();
}
@Test
public void test() throws InterruptedException {
// 打开testerhome的精华帖网站
driver.get("https://testerhome.com/topics/excellent");
// 创建一个JavaScriptExecutor对象
JavascriptExecutor jsExecutor = (JavascriptExecutor) driver;
String script = "var elements = document.querySelectorAll('.title.media-heading a');" +
"return Array.prototype.map.call(elements, function(e) { return e.textContent.trim(); });";
// 使用JavaScriptExecutor执行脚本并获取结果
Object result = jsExecutor.executeScript(script);
// 将结果转换为List<String>
List<String> postTitleList = new ArrayList<>();
if (result instanceof List<?>) {
for (Object text : (List<Object>) result) {
if (text != null) {
postTitleList.add((String) text);
}
}
}
for (int i = 0; i < postTitleList.size(); i++) {
String postTitle = postTitleList.get(i).split("\\n")[1].trim();
Thread.sleep(1000);
System.out.println(i + ":" + postTitle);
Thread.sleep(1000);
driver.findElement(By.xpath("//a[@title='" + postTitle.trim() + "']")).click();
String post = driver.findElement(By.xpath("//h1[@class='media-heading']/span[@class='title']")).getText().trim();
if (postTitle.equals(post)) {
System.out.println(i + ":相同_" + post);
driver.navigate().back();
Thread.sleep(1000);
} else {
System.out.println(i + ":不相同_" + post);
}
}
}
}
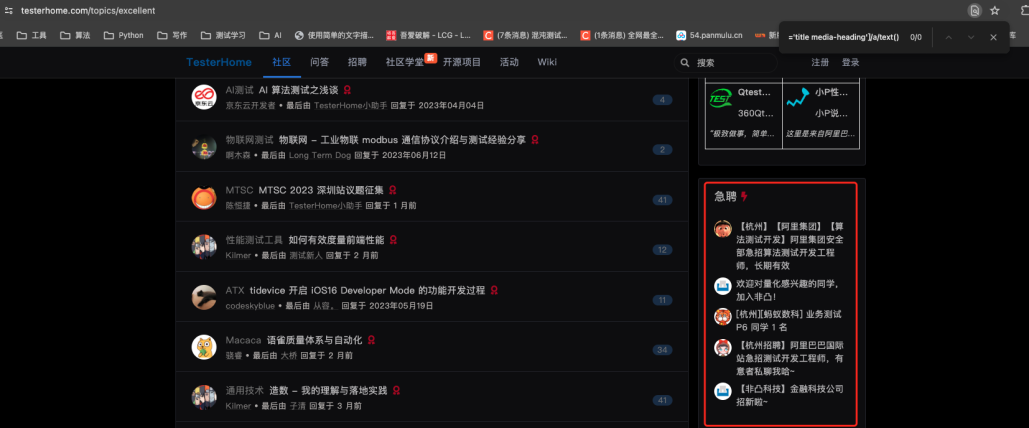
再次执行,在执行到第 25 个的时候报错。提示java.lang.ArrayIndexOutOfBoundsException: Index 1 out of bounds for length 1。第 67 行报错。在根据开发根据查看,发现在根据 xpath 定位,将急聘模块也获取到了,导致报错。
更新 xpath 定位,修改为://div[@class=‘col-lg-9’]//div[@class=‘title media-heading’]/a/text(),在利用阿里的通义千问转化为 Js 脚本。代码如下:
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.openqa.selenium.By;
import org.openqa.selenium.JavascriptExecutor;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
public class imoocTest {
private static WebDriver driver;
@BeforeAll
static void setUP() {
// 获取当前文件下所在的目录
String currentDirectory = System.getProperty("user.dir");
// 设置chromeDriver
System.setProperty("webdriver.chrome.driver", currentDirectory + "/src/test/resources/Driver/Chrome/chromedriver");
ChromeOptions options = new ChromeOptions();
//浏览器模拟手机模式
options.addArguments("--disable-web-security");
// 最大化窗口
options.addArguments("--start-maximized");
//解决报 403 问题
options.addArguments("--remote-allow-origins=*");
driver = new ChromeDriver(options);
// 隐式调用
driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(10));
}
@AfterAll
static void tearDown() {
//关闭浏览器
driver.quit();
}
@Test
public void test() throws InterruptedException {
// 打开testerhome的精华帖网站
driver.get("https://testerhome.com/topics/excellent");
// 创建一个JavaScriptExecutor对象
JavascriptExecutor jsExecutor = (JavascriptExecutor) driver;
String script = "var elements = document.querySelectorAll('div.col-lg-9 div.title.media-heading a');" +
"return Array.prototype.map.call(elements, function(e) { return e.textContent.trim(); });";
// 使用JavaScriptExecutor执行脚本并获取结果
Object result = jsExecutor.executeScript(script);
// 将结果转换为List<String>
List<String> postTitleList = new ArrayList<>();
if (result instanceof List<?>) {
for (Object text : (List<Object>) result) {
if (text != null) {
postTitleList.add((String) text);
}
}
}
for (int i = 0; i < postTitleList.size(); i++) {
String postTitle = postTitleList.get(i).split("\\n")[1].trim();
Thread.sleep(1000);
System.out.println(i + ":" + postTitle);
Thread.sleep(1000);
driver.findElement(By.xpath("//a[@title='" + postTitle.trim() + "']")).click();
String post = driver.findElement(By.xpath("//h1[@class='media-heading']/span[@class='title']")).getText().trim();
if (postTitle.equals(post)) {
System.out.println(i + ":相同_" + post);
driver.navigate().back();
Thread.sleep(1000);
} else {
System.out.println(i + ":不相同_" + post);
}
}
}
}
执行代码,顺利执行完成,无报错信息,亦也完成了要求。
