一、设计模式基本原则
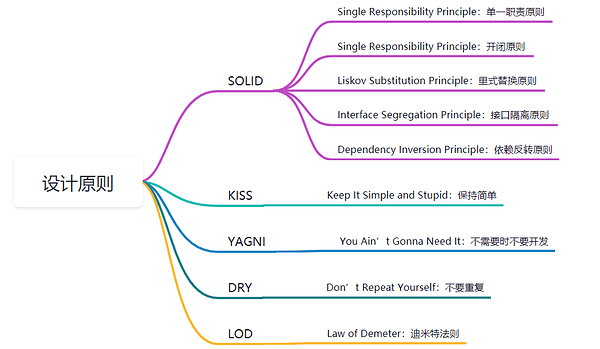
SOLID
| 英文名 | 中文 | 解释 |
|---|---|---|
| Single Responsibility Principle | 单一职责 | 一个类或者模块只负责完成一个职责(或者功能) |
| Open Closed Principle | 开闭原则 | 对扩展开放、对修改关闭 |
| Liskov Substitution Principle | 里式替换 | 子类对象能够替换程序中父类对象出现的任何地方,并且保证原来程序的逻辑行为不变及正确性不被破坏 |
| Interface Segregation Principle | 接口隔离原则 | 客户端不应该被强迫依赖它不需要的接口 |
| Dependency Inversion Principle | 依赖反转原则 | 高层模块不要依赖低层模块。高层模块和低层模块应该通过抽象来互相依赖。除此之外,抽象不要依赖具体实现细节,具体实现细节依赖抽象。 |
其它原则
| 简称 | 英文名 | 中文 | 解释 |
|---|---|---|---|
| KISS | Keep It Simple and Stupid | 尽量保持简单 | 保持简单 |
| YAGNI | You Ain’t Gonna Need It | 你不会需要它,不要做过度设计 | |
| DRY | Don’t Repeat Yourself | 不重复 | 不要编写重复的代码 |
| LOD | Law of Demeter | 迪米特法则 | 每个模块只应该了解那些与它关系密切的模块的有限知识 |
二、单例设计模式
1、 为什么要使用单例
普通的类就像生产机器,可以生产多个实例(动物糕点),就像下图:
单例设计模式(Singleton Design Pattern)对实例做限制,一个类只允许创建一个对象。

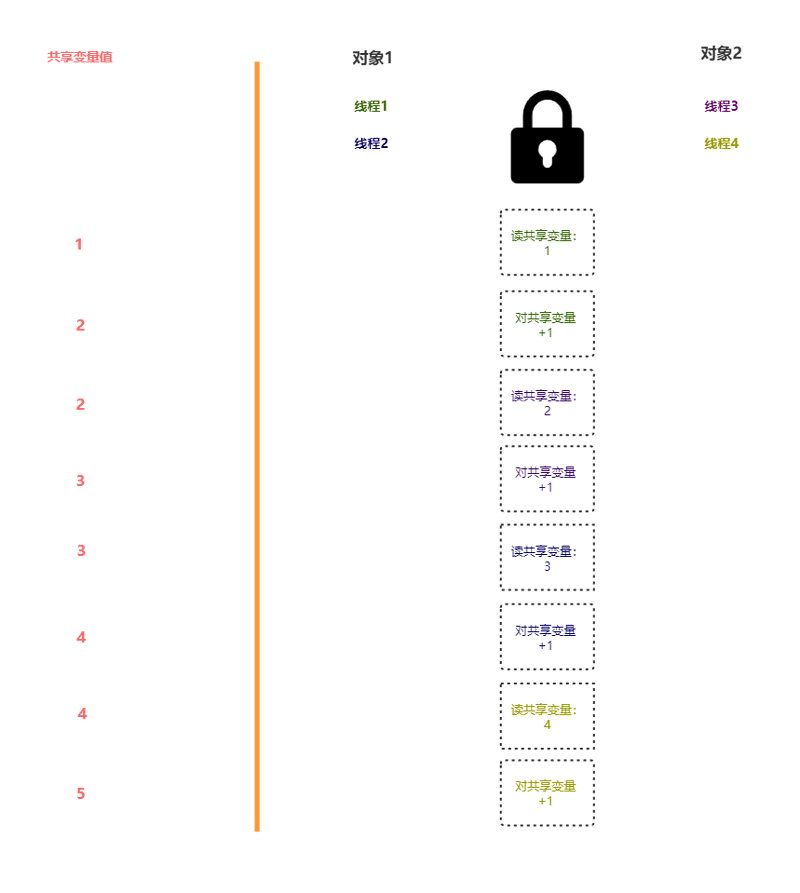
那么,对类进行限制有什么好处?假设对文件进行写入,同一个对的多个线程同时写入会造成资源竞争问题 ,比如两个线程同时给一个共享变量加 1 ,共享变量最后的结果可能只加了 1 。

如果是同一个对象,加入对象级别互斥锁 就能解决问题。
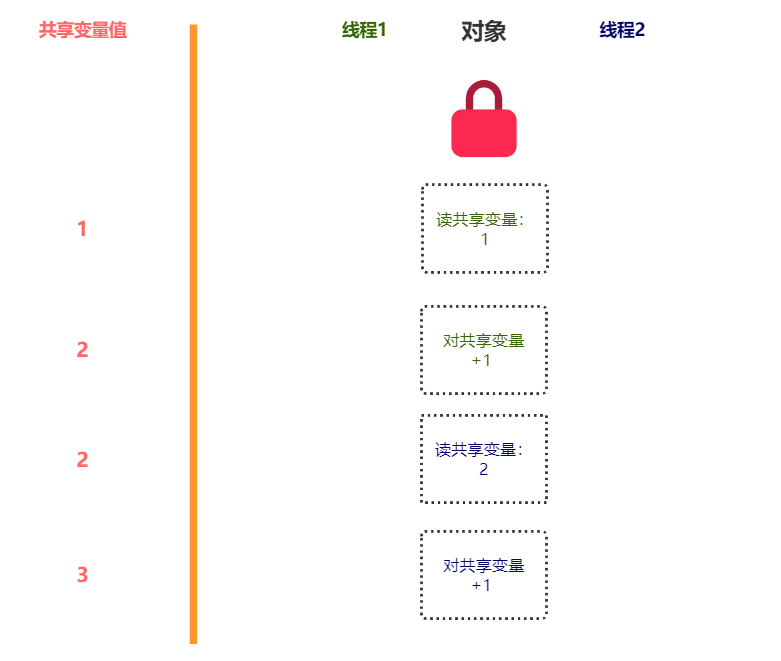
但是,对象锁,不同线程使用同一对象才有效,若使用不同对象,没有效(如果不理解,见下图)。
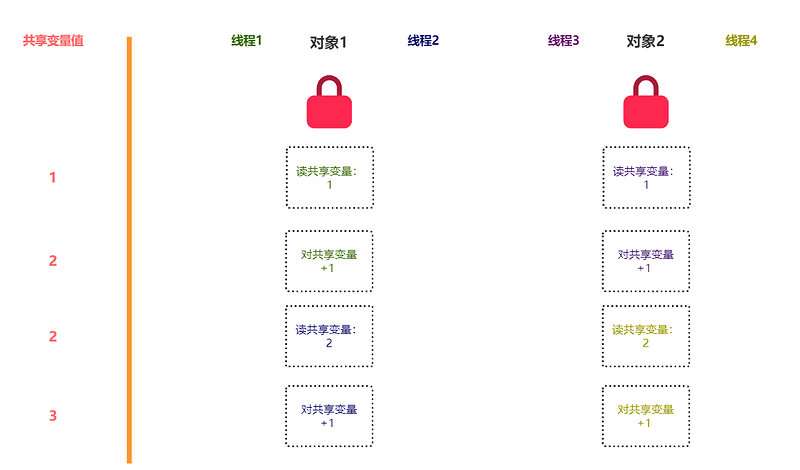
其实问题不难解决,把对象级别锁提升到类级别 即可:
其实还有很多方案,分布式锁,并发队列等等,但这些方案都比较复杂 ,而单例模式的思路简单清晰
2、 饿汉式单例
顾名思义,饥饿难忍,在类加载时就创建好实例。
很多语言都支持在类加载前就初始化变量的操作,比如 Java 的静态变量和 Python 的类变量,利用这个特性就能实现饿汉式单例。
class IdMaker:
# python 的类变量会被多个类实例共享
__instance = None
# __id 也是类变量,多个实例或类共享
__id = 0
# python 在类加载阶段,通过父类的 __new__ 创建实例,如果我们重写 __new__
# 就不会调用父类的 __new__ ,就会调用我们写的 __new__ 创建实例
# __new__ 需要返回一个实例,如果不返回,就不会实例化
def __new__(cls):
if cls.__instance is None:
# 父类的 __new__ 参数接收一个类名,会返回类的实例
cls.__instance = super().__new__(cls)
# 如果不用父类的__new__方法进行初始化,直接用类初始化,那在初始化的时候会调用自己的__new__方法,这样会形成递归报错
cls.__instance = IdMaker() # 这种方式会形成递归报错
return cls.__instance
# 计数器,在获取前,进行 + 1
def get_id(self):
# 类变量,所有实例共享
self.__id += 1
return self.__id
def test_id_maker():
# IdMaker 是单例类,只允许有一个实例,就算实例化多次,在内存中也只有一个实例
# 因为__instance是类属性,多个实例共享,当非第一次创建实例的时候,__instance不为None,直接就返回了原来的__instance
mark1 = IdMaker()
mark2 = IdMaker()
mark3 = IdMaker()
id1 = mark1.get_id()
id2 = mark2.get_id()
id3 = mark3.get_id()
print(id1, id2, id3) # 1 2 3--类变量,所有实例共享
print(mark1,mark2,mark3) # <__main__.IdMaker object at 0x000002EADA9AC590> <__main__.IdMaker object at 0x000002EADA9AC590> <__main__.IdMaker object at 0x000002EADA9AC590>
if __name__ == "__main__":
test_id_maker()
因为过于饥饿,该实现不支持延迟加载(用到的时候再初始化),如果实例占用资源多会造成初始化的慢,卡。其实,将占用资源多的方法提前(饿汉),有利有弊:
- 利:避免运行中卡顿,在初始化阶段就能发现错误
- 弊:提前初始化浪费资源
3、懒汉式单例
懒汉非常懒惰,在类使用阶段才会创建实例 。
懒汉式可以弥补饿汉式缺点,由于在使用实例时才创建,避免初始化阶段卡慢。
from threading import Lock
class IdMaker:
# 申请一个线程锁,虽然类是单例的,但是如果多个线程操作同一个实例的时候也会出问题,所以加个线程锁
__instance_lock = Lock()
# python 的类变量会被多个类,实例共享
__instance = None
# __id 也是类变量,多个实例或类共享
__id = 0
# 如果 __new__ 抛出异常,就不允许调用者进行实例化
def __new__(cls):
raise ImportError("Instantition not allowed")
# 类方法不用实例化也能调用,因为我们不允许进行实例化,所以要使用类方法
@classmethod
def get_instance(cls):
# 使用with上下文管理器管理线程锁
# with 会帮我们自动的上锁和释放,不用我们操心,如果这个实例被线程占用,其他线程则无法使用这个实例,防止多个线程操作同一个实例的情况
with cls.__instance_lock:
if cls.__instance is None:
# 在创建对象的时候如果直接用类进行实例化,会调用__new__方法,而此时__new__抛出异常,禁止进行实例化,所以要调用父类的__new__方法
cls.__instance = super().__new__(cls)
return cls.__instance
# 计数器,在获取前,进行 + 1
def get_id(self):
self.__id += 1
return self.__id
def test_id_maker():
# IdMaker 是单例类,只允许有一个实例,因为__instance是类变量,多个实例共享,非第一次创建对象的时候__instance不为None,会直接返回之前的__instance
mark1 = IdMaker.get_instance()
mark2 = IdMaker.get_instance()
mark3 = IdMaker.get_instance()
id1 = mark1.get_id()
id2 = mark2.get_id()
id3 = mark3.get_id()
print(id1, id2, id3) # 1 2 3
print(mark1, mark2, mark3) # <__main__.IdMaker object at 0x0000021CCED82450> <__main__.IdMaker object at 0x0000021CCED82450> <__main__.IdMaker object at 0x0000021CCED82450>
if __name__ == "__main__":
test_id_maker()
三、工厂方法设计模式
当创建对象的代码多而杂时,可以用工厂模式将对象的创建和使用分离,让代码更加清晰。
比如下面代码根据不同的 rule 创建不同的对象。
# Demo 用于加载不同的文件,对不同的文件作不同的处理
class Demo:
def load(self, rule):
parse = None
# 根据不同的 rule ,创建不同的对象
if "xml" == rule:
parse = XmlParse()
elif "json" == rule:
parse = JsonParse()
elif "excel" == rule:
parse = ExcelParse()
elif "csv" == rule:
parse = CsvParse()
else:
parse = OtherParse()
# 调用对象的方法进行操作
parse.parse()
# 相当于接口,用于规范各个解析类
# 每个解析类都要实现 parse 方法,否则在调用的时候就会报错
class IParse:
def parse(self):
raise ValueError()
class XmlParse(IParse):
def parse(self):
print("XmlParse中的parse方法执行")
class JsonParse(IParse):
def parse(self):
print("JsonParse中的parse方法执行")
class ExcelParse(IParse):
def parse(self):
print("ExcelParse中的parse方法执行")
class CsvParse(IParse):
def parse(self):
print("CsvParse中的parse方法执行")
class OtherParse(IParse):
def parse(self):
print("OtherParse中的parse方法执行")
if __name__ == "__main__":
Demo().load("json") # JsonParse中的parse方法执行
Demo().load("excel") # ExcelParse中的parse方法执行
1、简单工厂
把创建大量实例的代码放到工厂类中。
# Demo 用于加载不同的文件,对不同的文件作不同的处理
# 问题:如果创建对象的代码比较多,可能还会创建 text ,md,yml 等等
# 简单工厂解决:把对象的创建移动到其它类中, load 方法就会很简洁
class Demo:
def load(self, rule):
parse = ParseRuleFactory().create_parse(rule)
# 调用对象的方法进行操作
parse.parse()
# 简单工厂类:用于实例的创建,根据 rule 创建不同的实例。本质就是把 Demo 中原来创建实例的代码,给迁移过来
class ParseRuleFactory:
def create_parse(self, rule):
# 根据不同的 rule ,创建不同的对象
if "xml" == rule:
parse = XmlParse()
elif "json" == rule:
parse = JsonParse()
elif "excel" == rule:
parse = ExcelParse()
elif "csv" == rule:
parse = CsvParse()
else:
parse = OtherParse()
return parse
# 相当于接口,用于规范各个解析类
# 每个解析类都要实现 parse 方法,否则在调用的时候就会报错
class IParse:
def parse(self):
raise ValueError()
class XmlParse(IParse):
def parse(self):
print("XmlParse中的parse方法执行")
class JsonParse(IParse):
def parse(self):
print("JsonParse中的parse方法执行")
class ExcelParse(IParse):
def parse(self):
print("ExcelParse中的parse方法执行")
class CsvParse(IParse):
def parse(self):
print("CsvParse中的parse方法执行")
class OtherParse(IParse):
def parse(self):
print("OtherParse中的parse方法执行")
if __name__ == "__main__":
Demo().load("json")
Demo().load("excel")
2、工厂方法
问题:简单工厂不能解决创建实例的代码可能很复杂问题,即使迁移到了简单工厂中,复杂的创建过程依旧存在;
解决:使用工厂方法,把创建过程封装到工厂类;
# 问题:简单工厂不能解决创建实例的代码可能很复杂,即使迁移到了简单工厂中,复杂的创建过程依旧存在
# 解决:使用工厂方法,把创建过程封装到工厂类
class Demo:
def load(self, rule):
parse = None
if "xml" == rule:
# 未来可能会有1000行代码
parse = XmlParse()
elif "json" == rule:
# 未来可能会有1000行代码---将初始化的过程封装到工厂类,用工厂方法进行对象的实例化
parse = JsonParseRuleFactory().create_parse()
elif "excel" == rule:
# 未来可能会有1000行代码
parse = ExcelParse()
elif "csv" == rule:
# 未来可能会有1000行代码
parse = CsvParse()
else:
# 省略 1000 行代码
parse = OtherParse()
# 调用对象的方法进行操作
parse.parse()
# 相当于接口,用于规范各个工厂类,所有的工厂类都需要继承这个类并实现里面的方法
class IParseRuleFactory:
def create_parse(self):
raise ValueError()
# 工厂:把 Json 的解析放到此工厂下面
class JsonParseRuleFactory (IParseRuleFactory):
def create_parse(self):
# 未来可能会有1000行代码--全部写到这里,使得load方法创建对象的代码更简洁
return JsonParse()
# 相当于接口,用于规范各个解析类
# 每个解析类都要实现 parse 方法,否则在调用的时候就会报错
class IParse:
def parse(self):
raise ValueError()
class XmlParse(IParse):
def parse(self):
print("XmlParse中的parse方法执行")
class JsonParse(IParse):
def parse(self):
print("JsonParse中的parse方法执行")
class ExcelParse(IParse):
def parse(self):
print("ExcelParse中的parse方法执行")
class CsvParse(IParse):
def parse(self):
print("CsvParse中的parse方法执行")
class OtherParse(IParse):
def parse(self):
print("OtherParse中的parse方法执行")
if __name__ == "__main__":
Demo().load("json")
Demo().load("excel")
3、抽象工厂
假设有 A 公司, B 公司,C 公司… 都要有自己的解析方法,比如:A 公司有 AXmlParseFactory ,B 公司有 BXmlParseFactory ,C 公司有 CXmlParseFactory 。如果此时使用简单工厂和工厂方法,工作量非常大,因为要给每一个公司都创建所有的解析工厂。
此时可以用抽象工厂解决问题。解析工厂返回多个实例,比如,XmlParseFactory 可以返回 A ,B , C 的实例。
# 问题:如果多个公司都要封装工厂,比如 A, B, C ...公司都要封装自己的工厂,就要封装 n 个工厂类
# 解决:可以使用抽象工厂解决问题,每个工厂类可以创建多个实例,比如 JsonParseRuleFactory ,可以创建 A, B, C 公司的实例
# 一个工厂类,可以生成多个公司的解析方法
class IParseRuleFactory: # 相当于接口,用于规范所有的工厂类的必须实现的方法
def a_create_parse(self):
raise ValueError()
def b_create_parse(self):
raise ValueError()
def c_create_parse(self):
raise ValueError()
# 实现时候,一个工厂类就可以生成多个公司的实例
class JsonParseRuleFactory(IParseRuleFactory):
def a_create_parse(self):
pass
def b_create_parse(self):
pass
def c_create_parse(self):
pass
四、代理模式
-
定义:为其它对象提供一种代理以控制对这个对象的访问;
- 在某些情况下,一个对象不适合或者不能直接引用另一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用。
-
应用场景:
- 远程代理:在代码中加入 Web 引用
- 虚拟代理:存放实体化需要很久的对象,比如网页先看到文字,后看到图片
- 安全代理:控制真实对象的访问权限
- 智能指引:调用真实对象时,处理另外一些事,比如计算真实对象的引用次数
-
代理模式分类:
- 静态代理
- 动态代理
由下面三部分组成:
-
抽象角色:通过接口或抽象类声明真实角色实现的业务方法。 -
真实角色:实现抽象角色,定义真实角色所要实现的业务逻辑,供代理角色调用。 -
代理角色:实现抽象角色,是真实角色的代理,通过真实角色的业务逻辑方法来实现抽象方法,并可以附加自己的操作。
1、静态代理
在程序运行前,就已经确定代理类和委托类的关系的代理方式,被称为静态代理 。
案例: 小明请律师进行诉讼
import abc
# 诉讼流程可抽象为ILawsuit类,所有要进行诉讼的都需要实现这个类
class ILawsuit(abc.ABC):
@abc.abstractmethod
def submit(self): # 提交申请
pass
@abc.abstractmethod
def burden(self): # 进行举证
pass
@abc.abstractmethod
def defend(self): # 开始辩护
pass
@abc.abstractmethod
def finish(self): # 诉讼完成
pass
# 小明为具体诉讼人,可写为Litigant类
class Litigant(ILawsuit): # 继承于ILawsuit
def __init__(self, name):
self.name = name
def submit(self):
print(f'{self.name}申请仲裁!')
def burden(self):
print('证据如下:XXXXXX')
def defend(self):
print('辩护过程:XXXXXX')
def finish(self):
print('诉讼结果如下:XXXXXX')
# 律师可写为Lawyer类
class Lawyer(ILawsuit): # 继承于ILawsuit
# 律师代理谁就需要把谁传过来
def __init__(self, litigant):
# 具体诉讼人--委托人
self.litigant = litigant
def submit(self):
# 律师做的一切都是代理委托人做的
self.litigant.submit()
def burden(self):
# 律师做的一切都是代理委托人做的
self.litigant.burden()
def defend(self):
# 律师做的一切都是代理委托人做的
self.litigant.defend()
def finish(self):
# 律师做的一切都是代理委托人做的
self.litigant.finish()
if __name__ == '__main__':
# 诉讼过程
# 先有一个小明实体
xiaoming = Litigant("小明")
# 小明找律师代理
lawyer = Lawyer(xiaoming)
# 律师开始进行诉讼流程,但他都是代理的诉讼人去执行,因为底层是诉讼人
lawyer.submit() # 律师提交诉讼申请
lawyer.burden() # 律师进行举证
lawyer.defend() # 律师替小明辩护
lawyer.finish() # 完成诉讼
-----------------------------------------------
小明申请仲裁!
证据如下:XXXXXX
辩护过程:XXXXXX
诉讼结果如下:XXXXXX
静态代理的优缺点
优点:业务类只需要关注业务逻辑本身,保证了业务类的重用性。
缺点:代理对象的一个接口只服务于一种类型的对象,如果要代理的方法很多,势必要为每一种方法都进行代理,静态代理在程序规模稍大时就无法胜任了。
2、 动态代理
代理类在程序运行时创建的代理方式被称为 动态代理。
也就是说,这种情况下,代理类并不是在代码中定义的,而是在运行时根据我们在代码中的指示动态生成的。
案例:使用动态代理实现REST API的简洁调用
import json
from urllib import request
# 通常我们调用REST API通常可能是这样的
def fetch_resource(resource_id):
opener = request.urlopen('http://remote.server/api/resource/' + resource_id)
if opener.code != 200:
raise RuntimeError('invalid return code!')
content = opener.read()
try:
return json.loads(content)
except ValueError:
return content
"""
对于每一个REST操作,都会有以上类似的代码。差别仅在于API的地址和HTTP method(GET、POST、等)。
此时,可以引入一个GetProxy,可以代替我们实现这些繁杂的工作。
"""
class GetProxy(object):
def __getattr__(self, api_path):
print(f"api_path:{api_path}") # api_path:resource
def _rest_fetch(*paras):
print(paras) # ('switch', 456)
# 拼接url
base_url = 'http://remote.server/api/' + api_path
stitch_url = ""
for p in paras:
stitch_url += '/'+ str(p)
url = base_url + stitch_url
print(f"url:{url}") # url:http://remote.server/api/resource/switch/456
# 发送请求
opener = request.urlopen(url)
if opener.code != 200:
raise RuntimeError('invalid return code!')
content = opener.read()
try:
return json.loads(content)
except ValueError:
return content
return _rest_fetch
if __name__ == '__main__':
proxy = GetProxy()
# 调用API
proxy.resource('switch', 456) # http://remote.server/api/resource/switch/456
