一、random随机数模块
源码中的所有方法
_inst = Random()
seed = _inst.seed
random = _inst.random # 生成一个[0,1)范围内的随机浮点数
uniform = _inst.uniform # 生成一个[a,b]范围内的随机浮点数
triangular = _inst.triangular
randint = _inst.randint # 生成一个[a,b]范围内的随机整数
choice = _inst.choice # 从序列seq中随机选择一个元素,seq是自定义的序列(字符串、列表、元组),seq的长度不能小于1
randrange = _inst.randrange # 从range(stop) or range(start, stop[, step])中获取一个随机数
sample = _inst.sample
shuffle = _inst.shuffle # 随机打乱列表lst的元素顺序,并得到一个新的列表
choices = _inst.choices
normalvariate = _inst.normalvariate
lognormvariate = _inst.lognormvariate
expovariate = _inst.expovariate
vonmisesvariate = _inst.vonmisesvariate
gammavariate = _inst.gammavariate
gauss = _inst.gauss
betavariate = _inst.betavariate
paretovariate = _inst.paretovariate
weibullvariate = _inst.weibullvariate
getstate = _inst.getstate
setstate = _inst.setstate
getrandbits = _inst.getrandbits
randbytes = _inst.randbytes
案例:
import random
# 生成一个[0,1)范围内的随机浮点数
print(random.random())# 0.3065551007028968
# 生成一个[a,b]范围内的随机整数
print(random.randrange(1,3))
# 生成一个[a,b]范围内的随机浮点数
print(random.uniform(1,3)) # 2.122740269330794
# 从序列seq中随机选择一个元素,seq是自定义的序列(字符串、列表、元组),seq的长度不能小于1
# 字符串
s = "python"
result1 = random.choice(s)
print(result1)
# 列表
l = list(s)
result2 = random.choice(l)
print(result2)
# 元组
t = tuple(s)
result3 = random.choice(t)
print(result3)
# 从range(stop) or range(start, stop[, step])中获取一个随机数
print(random.randrange(1,10))
print(random.randrange(10))
# 随机打乱列表lst的元素顺序,并得到一个新的列表
number = [1,2,3,4,5]
random.shuffle(number)
print(number)
二、sys模块
sys是Python的内置标准模块,提供了访问与Python解释器系统相关的变量和函数的功能。它的主要用途是:
- 与系统交互
- 解释器配置
- 命令行参数处理
- 标准输入输出
- 异常处理等。
1、常用属性
-
sys.argv:获取命令行参数列表,包括脚本名称和传递为脚本的其他参数;
-
sys.version:获取当前Python解释器的版本信息–字符串形式;
-
sys.version_info:获取当前Python解释器的版本信息–元组形式;
-
sys.platform:获取当前运行的操作系统平台名称;
-
sys.modules:返回已导入的模块信息,返回一个字典;
-
sys.path:获取模块搜索路径列表,用于指定python解释器搜索模块的路径;
- 先到当前路径去找;
- 再到项目根目录去找;
- 再到Python安装目录去找;
- 再到Python解释器路径去找(虚拟环境);
- 再到安装的第三方库去找;
- 如果还是找不到,那就会报错没有这个模块;
import sys
# 获取命令行参数列表,包括脚本名称和传递为脚本的其他参数,终端执行命令:python .\sys_usage.py 127.0.0.1 8080
print(sys.argv) # ['.\\sys_usage.py', '127.0.0.1', '8080']
script_name = sys.argv[0]
arguments = sys.argv[1:]
print(f"脚本名称:{script_name}") # 脚本名称:.\sys_usage.py
print(f"命令行参数:{arguments}") # 命令行参数:['127.0.0.1', '8080']
# 获取当前Python解释器的版本信息--字符串形式
print(f"Python解释器版本号:{sys.version}") # Python解释器版本号:3.11.4 (tags/v3.11.4:d2340ef, Jun 7 2023, 05:45:37) [MSC v.1934 64 bit (AMD64)]
# 获取当前Python解释器的版本信息--元组形式
print(f"Python解释器版本号:{sys.version_info}") # Python解释器版本号:sys.version_info(major=3, minor=11, micro=4, releaselevel='final', serial=0)
print(f"大版本:{sys.version_info[0]}") # 大版本:3
print(f"小版本:{sys.version_info[1]}") # 小版本:11
print(f"子版本:{sys.version_info[2]}") # 子版本:4
# 获取当前运行的操作系统平台名称
print(f"当前操作系统:{sys.platform}") # 当前操作系统:win32
# 返回已导入的模块信息,返回一个字典
print(sys.modules)
for k,v in sys.modules.items():
print(f"导入的模块名:{k},模块对象{v}")
# 获取模块搜索路径列表,用于指定python解释器搜索模块的路径
"""
['E:\\hogwartscode\\built_in_module_Project\\sys_module',
'E:\\hogwartscode\\built_in_module_Project',
'D:\\ceshi\\Python\\python311.zip',
'D:\\ceshi\\Python\\DLLs',
'D:\\ceshi\\Python\\Lib',
'D:\\ceshi\\Python',
'E:\\hogwartscode\\built_in_module_Project\\InterfaceVenv',
'E:\\hogwartscode\\built_in_module_Project\\InterfaceVenv\\Lib\\site-packages']
"""
print(sys.path)
2、常用方法
- sys.getdefaultencoding():获取当前编码方式
- sys.exit():退出Python解释器,也就是停止运行,后面的代码不会运行
# 获取当前编码方式
print(sys.getdefaultencoding()) # utf-8
# 退出Python解释器,也就是停止运行,后面的代码不会运行
sys.exit()
print("这行代码不会运行") # pycharm编辑器都会飚黄
三、os模块
Python的内置库os(Operating System Interface)提供了与操作系统交互的函数,比如:
- 文件和目录操作;
- 环境变量访问;
- 进程管理等;
使用os库,可以编写跨平台的代码,因为它提供了对操作系统底层功能的抽象,而不用担心特定操作系统的细节。
1、路径操作
-
os.getcwd():获取当前文件的路径;
-
os.chdir(“path”):切换工作目录–工作目录是指当前正在执行的脚步所在的目录,通过这个方法,可以在脚本执行过程中动态切换到不同的目录;
- 说明:path必须存在,不然程序报错找不到路径;
path方法
-
os.path.abspath(path):返回绝对路径;
-
os.path.basename(path):返回文件名;
-
os.path.dirname(path):返回目录名-返回指定路径的父目录路径–通过连续获取父目录名可以找到项目的根目录;
-
os.path.split(path):路径分割-将一个路径拆分为目录名部分和文件名部分–得到一个元组;
-
os.path.join(path1,path2):拼接路径-用于连接多个路径部分,它将多个路径片段组合在一起,形成一个新的路径字符串;
- join方法会根据当前系统添加对应的路径连接符;类linux路径连接符
/,Windows路径连接符\;
- join方法会根据当前系统添加对应的路径连接符;类linux路径连接符
-
os.path.exists(path):判断路径是否存在;
-
os.path.isdir(path):判断是否是目录且存在;
-
os.path.isfile(path):判断是否是文件且存在;
-
os.path.getsize(path):获取文件大小,单位为字节;
# 获取当前文件的路径
print(f"当前路径:{os.getcwd()}") # 字符串形式--E:\hogwartscode\built_in_module_Project\os_module
print(f"当前路径:{os.getcwdb()}") # 二进制形式--b'E:\\hogwartscode\\built_in_module_Project\\os_module'
# 切换工作目录
os.chdir("../sys_module")
print(f"切换后的工作目录:{os.getcwd()}") # E:\hogwartscode\built_in_module_Project\sys_module
# 获取当前文件的绝对路径
print(f"当前文件绝对路径:{os.path.abspath(__file__)}") # E:\hogwartscode\built_in_module_Project\os_module\os_usage.py
# 当前文件名
print(f"当前文件名:{os.path.basename(__file__)}") # os_usage.py
# 当前文件路径
print(f"当前文件路径:{os.path.dirname(__file__)}") # E:\hogwartscode\built_in_module_Project\os_module
print(os.path.dirname(os.path.abspath(__file__))) # E:\hogwartscode\built_in_module_Project\os_module
# 通过连续获取父目录名可以找到项目的根目录
print(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) # E:\hogwartscode\built_in_module_Project
print(os.path.dirname(os.path.dirname(__file__))) # E:\hogwartscode\built_in_module_Project
# 路径拆分
path = os.path.split(__file__)
print(path) # ('E:\\hogwartscode\\built_in_module_Project\\os_module', 'os_usage.py')
print(f"目录名:{path[0]},文件名:{path[1]}") # E:\hogwartscode\built_in_module_Project\os_module,文件名:os_usage.py
# 路径拼接
path1 = "../data"
filename = "join.txt"
result = os.path.join(path1,filename)
print(f"拼接后的路径为:{result}") # ../data\join.txt
# 判断路径是否存在
path = "../data1"
print(f"路径是否存在:{os.path.exists(path)}") # True
# 判断是不是目录
print(f"判断是不是目录且存在:{os.path.isdir(path)}")
# 判断是不是文件
print(f"判断是不是文件:{os.path.isfile(result)}")
# 获取文件大小
print(f"文件大小:{os.path.getsize('../data/aaa.txt')}")
2、目录和文件操作
-
os.listdir(path):列出指定目录的内容,返回列表;
- 如果不给定path就是当前目录;
-
os.mkdir(path):创建一个单级新目录;
- 创建文件就用open方法以写的形式;
-
os.makedirs(path):递归创建多级目录;
-
os.rmdir(path):删除空目录;
- 只能删除非空目录;
- 不能递归删除,只会删除目录的最后一级空目录;
-
os.rename(old_dir_name,new_dir_name):目录或者文件重命名;
- 不管目录是否为空;
-
os.remove(filename):删除文件–只能删除文件,不能删除目录;
# 列出目录内容
# print(f"当前目录内容:{os.listdir()}") # ['sys_usage.py', '__init__.py']
# print(f"当前目录内容:{os.listdir('.')}") # ['sys_usage.py', '__init__.py']
# path = "../data"
# print(f"指定目录内容:{os.listdir(path)}") # ['aaa.txt']
# 创建一个新目录
# print(f"创建一个新目录返回:{os.mkdir('demo1')}") # None
# 递归创建多级目录
# os.makedirs("a/b/c")
# 删除空目录
# print(f"删除空目录:{os.rmdir('demo1')}") # None
# print(f"删除空目录:{os.rmdir('/demo/demo2/demo3/demo4')}") # None
# 目录重命名
# os.rename("../data","../data1")
# 文件重命名
# os.rename("../data1/aaa.txt","../data1/aaa1.txt")
# 删除文件
os.remove("../data1/aaa1.txt")
3、其他操作
-
os.name:获取系统名称,在Windows上值为
nt,在linux、macos值为posix; -
os.chmod(path,mode):更改文件权限模式,path为需要更改文件权限的路径,mode是权限模式,通常用八进制表示,如
0o755;- Windows系统这个方法没用;
-
os.sep:用于表示操作系统特定的路径分隔符;
- 得到的结果为字符串,此时可以使用字符串的join方法进行路径拼接;
# 获取系统名称
print(f"系统名称:{os.name}") # nt
# 获取系统路径分隔符
print(f"系统路径分隔符:{os.sep}") # \
root_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
dir_path = os.sep.join([root_path, "screenshot"])
print(dir_path) # E:\hogwartscode\built_in_module_Project\screenshot
四、datetime模块
在Python中,与时间处理有关的模块就包括:time,datetime以及calendar;
datetime是Python标准库中用于处理日期和时间的模块。它提供了多种类和函数,用于处理日期、时间、时间间隔等操作,使得日期和时间的处理更加方便和灵活。
注意:这个模块的模块名和类名同名,但是方法都是在类中,所以导包的时候要注意;
from datetime import datetime
获取当前日期时间的datetime对象
- datetime.now():获取当前日期时间,结果为datetime对象;
from datetime import datetime
# 获取当前日期和时间
print(f"当前日期和时间:{datetime.now()}") # 2023-12-19 14:20:20.583270
print(type(datetime.now())) # <class 'datetime.datetime'>
将datetime对象格式化输出为字符串
- strftime(self, format)::将datetime对象格式化为自定义的字符串日期时间格式
- format格式有固定要求;
- 年:%Y–大写;
- 月:%m–小写;
- 日:%d–小写;
- 时:%H–大写;
- 分:%M–大写;
- 秒:%S–大写;
- 说明:format的格式固定不变,其他的连接符号都可以变,比如:/、空格、_、:等等;
- format格式有固定要求;
from datetime import datetime
# 将datetime对象格式化为自定义的字符串日期时间格式
date = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"自定义日期时间格式:{date}") # 2023-12-19 14:23:44
print(type(date)) # <class 'str'>
print(datetime.now().strftime("%Y-%m-%d")) # 2023-12-19
print(datetime.now().strftime("%H:%M:%S")) # 14:23:44
print(datetime.now().strftime("%Y/%m/%d")) # 2023/12/19
print(datetime.now().strftime("%Y年%m月%d日")) # 2023年12月19日
将日期时间字符串解析为datetime对象
- strptime(cls, date_string, format):将日期时间字符串解析为datetime对象
from datetime import datetime
# 将日期时间字符串解析为datetime对象
date = "2023-12-19 14:23:44"
datetime_instance = datetime.strptime(date,"%Y-%m-%d %H:%M:%S")
print(type(datetime_instance)) # <class 'datetime.datetime'>
计算时间间隔
-
datetime对象可以进行减法运算,计算两个时间间隔,默认结果是
xx days, xx:xx:xx,可以用以下属性获取天和秒;- date_diff.days:间隔天;
- date_diff.seconds:间隔秒;
-
结合timedelta类进行加法运行,计算未来的某个时间;
from datetime import datetime, timedelta
# 初始化两个datetime对象
date1 = datetime(2023,11,1)
date2 = datetime(2023,11,30)
# 两个日期的时间间隔
date_diff = date2-date1
print(f"时间间隔:{date_diff}") # 时间间隔:29 days, 0:00:00
print(f"时间间隔多少天:{date_diff.days}") # 29
print(f"时间间隔多少秒:{date_diff.seconds}") # 0
print(f"时间间隔多少秒:{date_diff.microseconds}") # 0
# 计算未来日期
future_date = datetime.now() + timedelta(hours=360)
print(f"360小时后的日期:{future_date}") # 2024-01-03 21:32:33.668083
print(type(future_date)) # <class 'datetime.datetime'>
比较日期
- 通过比较datetime对象来判断日期的先后
# 通过比较datetime对象来判断日期的先后
date1 = datetime(2023,11,1)
date2 = datetime(2023,11,30)
if date1 > date2:
print("date2的日期先于date1")
elif date1 < date2:
print("date1的日期先于date2")
else:
print("date1和date2的日期一样")
获取日期和时间的部分
- 使用datetime的属性获取日期和实际的部分信息;
# 获取日期和时间的部分
print(f"当前年:{datetime.now().year}")
print(f"当前月:{datetime.now().month}")
print(f"当前日:{datetime.now().day}")
print(f"当前时:{datetime.now().hour}")
print(f"当前分:{datetime.now().minute}")
print(f"当前秒:{datetime.now().second}")
五、time模块
1、相关概念
- 在Python中,通常有这几种方式来表示时间:1)时间戳 2)格式化的时间字符串 3)元组(struct_time)共九个元素。由于Python的time模块实现主要调用C库,所以各个平台可能有所不同。
- UTC(Coordinated Universal Time,世界协调时)亦即格林威治天文时间,世界标准时间。在中国为UTC+8。DST(Daylight Saving Time)即夏令时。
- 时间戳(timestamp)的方式:通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。返回时间戳方式的函数主要有time(),clock()等。
- 元组(struct_time)方式:struct_time元组共有9个元素,返回struct_time的函数主要有gmtime(),localtime(),strptime()。下面列出这种方式元组中的几个元素:
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 61 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周日) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为-1 |
2、常用方法
1)time.localtime([secs]):将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
>>> time.localtime()
time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=14, tm_min=14, tm_sec=50, tm_wday=3, tm_yday=125, tm_isdst=0)
>>> time.localtime(1304575584.1361799)
time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=14, tm_min=6, tm_sec=24, tm_wday=3, tm_yday=125, tm_isdst=0)
2)time.gmtime([secs]):和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。
>>>time.gmtime()
time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=6, tm_min=19, tm_sec=48, tm_wday=3, tm_yday=125, tm_isdst=0)
注意:这里的tm_wday=3表示的是周几,但是要在这个返回值的基础上往后推一天,即表示的是周四,而不是周三。
3)time.time():返回当前时间的时间戳。
>>> time.time()
1304575584.1361799
4)time.mktime(t):将一个struct_time转化为时间戳。
>>> time.mktime(time.localtime())
1304576839.0
5)time.sleep(secs):线程推迟指定的时间运行。单位为秒。
6)time.clock():这个需要注意,在不同的系统上含义不同。在UNIX系统上,它返回的是“进程时间”,它是用秒表示的浮点数(时间戳)。而在WINDOWS中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用是自第一次调用以后到现在的运行时间。(实际上是以WIN32上QueryPerformanceCounter()为基础,它比毫秒表示更为精确)
import time
if __name__ == '__main__':
time.sleep(1)
print "clock1:%s" % time.clock()
time.sleep(1)
print "clock2:%s" % time.clock()
time.sleep(1)
print "clock3:%s" % time.clock()
---------------------------------------------------
运行结果:
clock1:3.35238137808e-006
clock2:1.00004944763
clock3:2.00012040636
其中第一个clock()输出的是程序运行时间
第二、三个clock()输出的都是与第一个clock的时间间隔
7)time.asctime([t]):把一个表示时间的元组或者struct_time表示为这种形式:‘Sun Jun 20 23:21:05 1993’。如果没有参数,将会将time.localtime()作为参数传入。
>>> time.asctime()
'Thu May 5 14:55:43 2011'
8)time.ctime([secs]):把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。
>>> time.ctime()
'Thu May 5 14:58:09 2011'
>>> time.ctime(time.time())
'Thu May 5 14:58:39 2011'
>>> time.ctime(1304579615)
'Thu May 5 15:13:35 2011'
9)time.strftime(format[, t]):把一个代表时间的元组或者struct_time(如由time.localtime()和time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。如果元组中任何一个元素越界,ValueError的错误将会被抛出。
| 格式 | 含义 | 备注 |
|---|---|---|
| %a | 本地(locale)简化星期名称 | |
| %A | 本地完整星期名称 | |
| %b | 本地简化月份名称 | |
| %B | 本地完整月份名称 | |
| %c | 本地相应的日期和时间表示 | |
| %d | 一个月中的第几天(01 - 31) | |
| %H | 一天中的第几个小时(24小时制,00 - 23) | |
| %I | 第几个小时(12小时制,01 - 12) | |
| %j | 一年中的第几天(001 - 366) | |
| %m | 月份(01 - 12) | |
| %M | 分钟数(00 - 59) | |
| %p | 本地am或者pm的相应符 | 一 |
| %S | 秒(01 - 61) | 二 |
| %U | 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。 | 三 |
| %w | 一个星期中的第几天(0 - 6,0是星期天) | 三 |
| %W | 和%U基本相同,不同的是%W以星期一为一个星期的开始。 | |
| %x | 本地相应日期 | |
| %X | 本地相应时间 | |
| %y | 去掉世纪的年份(00 - 99) | |
| %Y | 完整的年份 | |
| %Z | 时区的名字(如果不存在为空字符) | |
| %% | ‘%’字符 |
备注:
- “%p”只有与“%I”配合使用才有效果。
- 文档中强调确实是0 - 61,而不是59,闰年秒占两秒(汗一个)。
- 当使用strptime()函数时,只有当在这年中的周数和天数被确定的时候%U和%W才会被计算。
>>> time.strftime("%Y-%m-%d %X", time.localtime())
'2011-05-05 16:37:06'
10)time.strptime(string[, format]):把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
>>> time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X')
time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6, tm_wday=3, tm_yday=125, tm_isdst=-1)
说明:在这个函数中,format默认为:“%a %b %d %H:%M:%S %Y”。
3、时间戳、格式化时间字符串、元组struct_time三者直接的关系
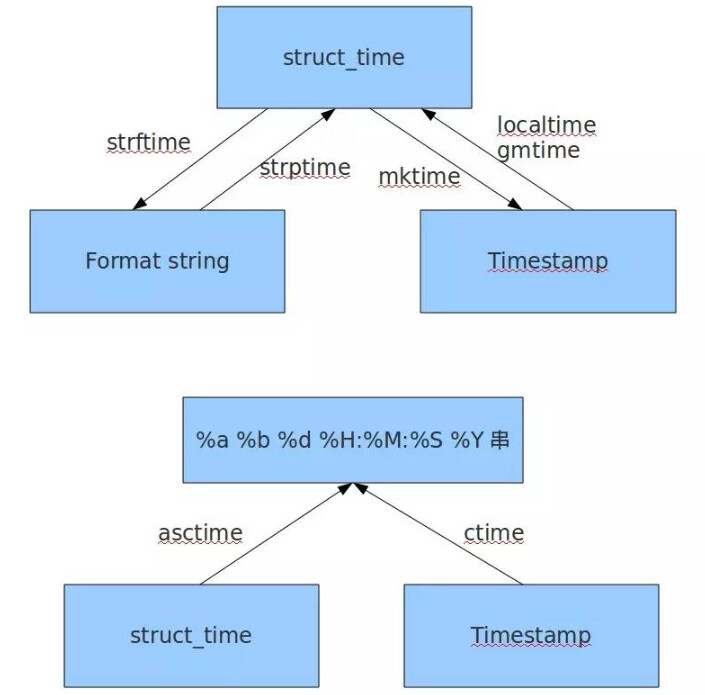
六、json模块
1、json数据结构
-
对象:用花括号
{}包裹,包含一系列键值对,每个键值对之间用逗号,分割; -
数组:用方括号
[]包裹,包含一系列值,每个值之间用逗号,分割; -
键值对:键和值之间使用冒号
:分割,键必须是字符串,值可以是字符串、数字、布尔值、对象、数组、或null; -
json数据的最外层只能是数组或对象;
-
json中的字符串,必须使用双引号包含;

2、Python与json数据类型对应关系
| Python | JSON |
|---|---|
| dict | object |
| list、tuple | array |
| str | string |
| int、float | number |
| True | true |
| False | false |
| None | null |
3、JSON序列化与反序列化
序列化: JSON的序列化指的是将Python对象转换为JSON格式的字符串;
反序列化: JSON的反序列化值将JSON格式字符串转成Python对象;
为什么要序列化?
1、存储
一个软件/程序的执行就在处理一系列状态的变化。
在编程语言中,“状态”会以各种各样有结构的数据类型(也可简单的理解为变量)的形式被保存在内存中。
内存无法永久保存数据,当程序运行一段时间,断电或者重启程序,内存中关于这个程序的一些数据就被清空了。
在断电或重启程序之前将程序当前内存中所有的数据都保存下来,以便于下次程序执行能够从文件中载入之前的数据就是序列化。
2、传输
因为TCP/IP协议只支持字节数组的传输,不能直接传对象。
对象序列化的结果一定是字节数组!
当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。
发送方需要把这个对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为对象。
如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互!
json.dumps():可以完成序列化操作,将Python对象转换为JSON字符串;
源码:
def dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, **kw):
参数说明:
-
obj:表示要序列化的对象。
-
skipkeys:默认为False。如果skipkeys是True则将跳过不是基本类型(str,int,float,bool,None)的dict键,不会引发TypeError。
-
ensure_ascii:默认值为True,能将所有传入的非ASCII字符转义输出。如果ensure_ascii为False,则这些字符将按原样输出。ensure_ascii=False,让文件中的中文可以直接显示!
-
check_circular:默认值为True。如果check_circular为False,则将跳过对容器类型的循环引用检查,循环引用将导致OverflowError。
-
allow_nan:默认值为True。如果allow_nan为True,则将使用它们的JavaScript等效项(NaN,Infinity,-Infinity)。如果allow_nan为False,则严格遵守JSON规范,序列化超出范围的浮点值(nan,inf,-inf)会引发ValueError。
-
indent:设置缩进格式,默认值为None,选择的是最紧凑的表示。如果indent是非负整数或字符串,那么JSON数组元素和对象成员将使用该缩进级别进行输入;indent为0,负数或“”仅插入换行符;indent使用正整数缩进多个空格;如果indent是一个字符串(例如“\t”),则该字符串用于缩进每个级别。
-
separators:去除分隔符后面的空格,默认值为None。如果指定,则分隔符应为(item_separator,key_separator)元组。如果缩进为None,则默认为(’,’,’:’);要获得最紧凑的JSON表示,可以指定(’,’,’:’)以消除空格。
-
default:默认值为None。如果指定,则default应该是为无法以其他方式序列化的对象调用的函数。它应返回对象的JSON可编码版本或引发TypeError。如果未指定,则引发TypeError。–为无法序列化的对象自定义序列化方式;
-
sort_keys:默认值为False。如果sort_keys为True,则字典的输出将按键值排序。
import json
# 定义一个字典
data = {
"code":200,
"msg":"ok",
"goods":[
{
"goods_id":"g0001",
"goods_name":"iphone13",
"goods_price":6999,
"isHot":False,
"isOpen":True
},
{
"goods_id":"g0002",
"goods_name":"iphone14",
"goods_price":7999,
"isHot":False,
"isOpen":True
},
{
"goods_id":"g0003",
"goods_name":"iphone15",
"goods_price":8999,
"isHot":True,
"isOpen":True
}
]
}
# 序列化操作:将Python对象转换为JSON字符串
result = json.dumps(data)
"""
{
"code": 200,
"msg": "ok",
"goods":
[{"goods_id": "g0001", "goods_name": "iphone13", "goods_price": 6999, "isHot": false, "isOpen": true},
{"goods_id": "g0002", "goods_name": "iphone14", "goods_price": 7999, "isHot": false, "isOpen": true},
{"goods_id": "g0003", "goods_name": "iphone15", "goods_price": 8999, "isHot": true, "isOpen": true}
]
}
"""
print(result)
print(type(result)) # <class 'str'>
json.loads():可以完成反序列化操作,将JSON格式字符串转换成Python对象;
源码:
def loads(s, *, cls=None, object_hook=None, parse_float=None,
parse_int=None, parse_constant=None, object_pairs_hook=None, **kw):
参数说明:
-
s:将s(包含JSON文档的str,bytes或bytearray实例)反序列化为Python对象。
-
encoding:指定一个编码的格式。
-
object_hook:默认值为None,object_hook是一个可选函数,此功能可用于实现自定义解码器。指定一个函数,该函数负责把反序列化后的基本类型对象转换成自定义类型的对象。
-
parse_float:默认值为None。如果指定了parse_float,用来对JSON float字符串进行解码,这可用于为JSON浮点数使用另一种数据类型或解析器。
-
parse_int:默认值为None。如果指定了parse_int,用来对JSON int字符串进行解码,这可以用于为JSON整数使用另一种数据类型或解析器。
-
parse_constant:默认值为None,如果指定了parse_constant,对-Infinity,Infinity,NaN字符串进行调用。如果遇到了无效的JSON符号,会引发异常。
如果进行反序列化(解码)的数据不是一个有效的JSON格式字符串,将会引发 JSONDecodeError异常。
import json
# 定义一个json格式字符串
date1 = '{"code": 200, "msg": "ok", "goods": [{"goods_id": "g0001", "goods_name": "iphone13", "goods_price": 6999, "isHot": false, "isOpen": true}, {"goods_id": "g0002", "goods_name": "iphone14", "goods_price": 7999, "isHot": false, "isOpen": true}, {"goods_id": "g0003", "goods_name": "iphone15", "goods_price": 8999, "isHot": true, "isOpen": true}]}'
result1 = json.loads(date1)
print(result1)
print(type(result1)) # <class 'dict'>
4、JSON文件的读写
将Python对象序列化为JSON格式并写入文件中
- json.dump():将Python对象序列化为JSON格式并写入文件中
源码:
def dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, **kw):
参数说明:
- obj:表示要序列化并存储到json文件的Python对象。
- fp:文件描述符 ,将序列化的str保存到文件中。
- 其他参数和dumps()方法一致;
import json
# 定义一个字典
data = {
"code":200,
"msg":"ok",
"goods":[
{
"goods_id":"g0001",
"goods_name":"iphone13",
"goods_price":6999,
"isHot":False,
"isOpen":True
},
{
"goods_id":"g0002",
"goods_name":"iphone14",
"goods_price":7999,
"isHot":False,
"isOpen":True
},
{
"goods_id":"g0003",
"goods_name":"iphone15",
"goods_price":8999,
"isHot":True,
"isOpen":True
}
]
}
# 将Python对象序列化为JSON格式并写入文件中
with open("jsondata1.json","w",encoding="utf-8") as f:
json.dump(data,f)
从JSON文件中读取数据为Python对象
- json.load():从JSON文件中读取数据为Python对象
源码:
def load(fp, *, cls=None, object_hook=None, parse_float=None,
parse_int=None, parse_constant=None, object_pairs_hook=None, **kw):
参数说明:
- fp:文件描述符 ,需要读取的JSON文件流。
- 其他参数和loads()方法一致;
import json
# 从JSON文件中读取数据为Python对象
with open("jsondata1.json","r",encoding="utf-8") as f:
result = json.load(f)
print(result)
print(type(result)) # <class 'dict'>
七、logging日志模块
1、logging日志模块的四大组件
- logger:日志器,提供程序可使用的接口;
- handler:处理器,用于写入日志文件并输出到指定位置,如文件、控制台、网络等;
- filter:过滤器,用于输出符合指定条件的日志记录;
- formatter:格式器,决定日志记录的输出格式;
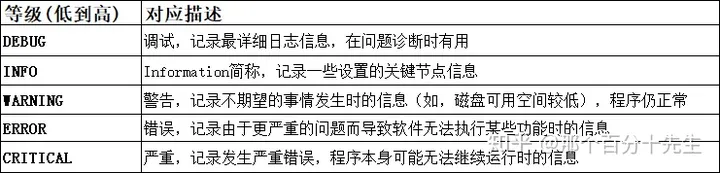
2、日志等级
日志等级是logging模块中的常量;
NOTSET = 0
DEBUG = 10
INFO = 20
WARNING = 30
ERROR = 40
CRITICAL = 50
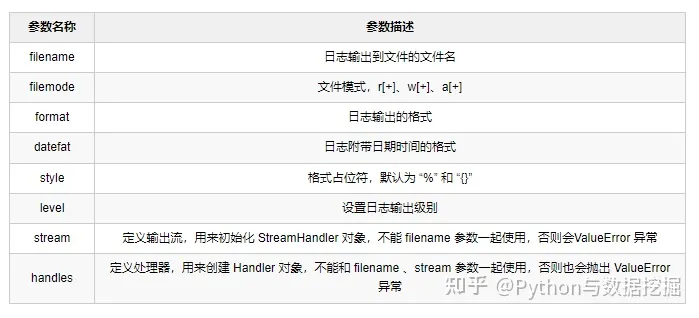
3、logging.basicConfig()配置日志
如果方法没有传入参数,会根据默认的配置创建Logger 对象,默认的日志级别被设置为 WARNING;
可选参数:
import logging
# 配置日志
logging.basicConfig(filename="test.log", filemode="a", format="%(asctime)s %(name)s:%(levelname)s:%(message)s", datefmt="%d-%M-%Y %H:%M:%S", level=logging.DEBUG)
# 调用日志触发器触发日志
logging.debug('This is a debug message')
logging.info('This is an info message')
logging.warning('This is a warning message')
logging.error('This is an error message')
logging.critical('This is a critical message')
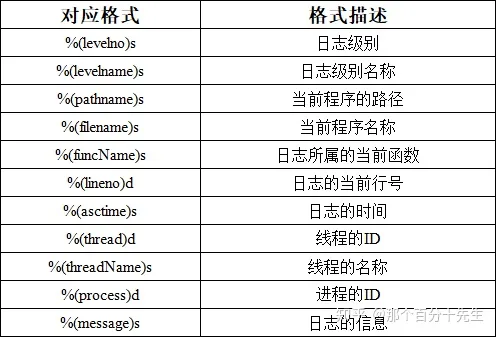
格式参数format的格式:
4、自定义日志
(1)自定义logger-logging.getLogger(name)
系统中 Logger 对象,不能被直接实例化,获取 Logger 对象的方法为 getLogger() ,并且这里运用了单例模式。
注意:这里的单例模式并不是说只有一个 Logger 对象,而是指整个系统只有一个 root Logger 对象,其他 Logger 对象在执行 info()、error() 等方法时实际上调用都是 root Logger 对象对应的 info()、error() 等方法。
我们可以创造多个 Logger 对象,但是真正输出日志的是root Logger 对象。每个 Logger 对象都可以设置一个名字,如果设置logger = logging.getLogger(__name__),name 是 Python 中的一个特殊内置变量,他代表当前模块的名称(默认为 main)。则 Logger 对象的 name 为建议使用使用以点号作为分隔符的命名空间等级制度。
Logger 对象可以设置多个 Handler 对象和 Filter 对象,Handler 对象又可以设置 Formatter 对象。Formatter 对象用来设置具体的输出格式。
(2)定义日志格式 logging.Formatter(format)
常用变量格式如下:
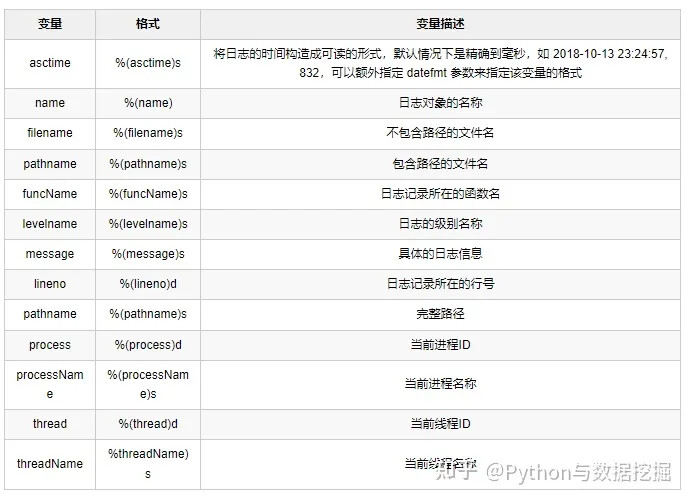
# 设置日志的格式
date_string = '%Y-%m-%d %H:%M:%S'
formatter = logging.Formatter(
'[%(asctime)s] [%(levelname)s] [%(filename)s]/[line: %(lineno)d]/[%(funcName)s] %(message)s ', date_string)
(3)将日志输出到文件RotatingFileHandler
# 创建日志记录器,指明日志保存路径,每个日志的大小,保存日志的上限
file_log_handler = RotatingFileHandler(os.sep.join([log_dir_path, 'log.log']), maxBytes=1024 * 1024, backupCount=10 , encoding="utf-8")
(4)将日志输出到控制台StreamHandler
# 日志输出到控制台的句柄
stream_handler = logging.StreamHandler()
# 绑定绑定句柄到logger对象
logger.addHandler(stream_handler)
(5)绑定日志输出句柄及输出格式和日志级别
# 日志输出到控制台的句柄
stream_handler = logging.StreamHandler()
# 将日志记录器指定日志的格式
file_log_handler.setFormatter(formatter)
stream_handler.setFormatter(formatter)
# 为全局的日志工具对象添加日志记录器
# 绑定绑定句柄到logger对象
logger.addHandler(stream_handler)
logger.addHandler(file_log_handler)
# 设置日志输出级别
logger.setLevel(level=logging.INFO)
(6)logutils
import logging
import os
from logging.handlers import RotatingFileHandler
# 绑定绑定句柄到logger对象
logger = logging.getLogger(__name__)
# 获取当前工具文件所在的路径
root_path = os.path.dirname(os.path.abspath(__file__))
# 拼接当前要输出日志的路径
log_dir_path = os.sep.join([root_path, f'../logs'])
if not os.path.isdir(log_dir_path):
os.mkdir(log_dir_path)
# 创建日志记录器,指明日志保存路径,每个日志的大小,保存日志的上限
file_log_handler = RotatingFileHandler(os.sep.join([log_dir_path, 'log.log']), maxBytes=1024 * 1024, backupCount=10 , encoding="utf-8")
# 设置日志的格式
date_string = '%Y-%m-%d %H:%M:%S'
formatter = logging.Formatter(
'[%(asctime)s] [%(levelname)s] [%(filename)s]/[line: %(lineno)d]/[%(funcName)s] %(message)s ', date_string)
# 日志输出到控制台的句柄
stream_handler = logging.StreamHandler()
# 将日志记录器指定日志的格式
file_log_handler.setFormatter(formatter)
stream_handler.setFormatter(formatter)
# 为全局的日志工具对象添加日志记录器
# 绑定绑定句柄到logger对象
logger.addHandler(stream_handler)
logger.addHandler(file_log_handler)
# 设置日志输出级别
logger.setLevel(level=logging.INFO)
