一、Playwright 介绍
- Playwright 是由微软的研发团队所开发的一款 Web&app 自动化测试框架。
- 跨平台,多语言支持。
- 支持 Chromium、Firefox、WebKit 等主流浏览器自动化操作。
- 除了基本的自动化测试能力之外,同时它还具备非常强大的录制功能、追踪功能。
1、Playwright 与 Selenium 的对比:
Playwright 不仅具备 Selenium 多语言、跨平台、多浏览器的优点。相较于 Selenium,Playwright 还有更加强大的优势。
| 对比项 | Playwright | Selenium |
|---|---|---|
| 是否需要驱动 | 否 | 需要对应浏览器 webdriver |
| 支持语言 | Java, Python, Javascript | Java, Python, Javascript, Ruby, C#等 |
| 支持浏览器 | Chrome、Firefox 等 | Chrome、Firefox 等 |
| 通讯方式 | websocket 双向通讯协议 | http 单向通讯协议 |
| 使用的测试框架 | 无限制(pytest,unittest) | 无限制(pytest,unittest) |
| 测试速度 | 快 | 慢 |
| 录制测试视频、快照 | 支持 | 支持 |
| 社区支持 | 微软 | thoughtworks 公司 |
2、 Playwright 有哪些优点
- 支持所有流行的浏览器。
- 速度更快,更可靠的执行。
- 更强大的自动化测试配置。
- 强大的工具库:
- Codegen:通过记录你的操作来生成测试。 将它们保存为任何语言。
- Playwright inspector: 检查页面、生成选择器、逐步执行测试、查看点击点、探索执行日志。
- Trace Viewer:捕获所有信息以调查测试失败,Playwright 跟踪包含测试执行截屏、实时 DOM 快照、动作资源管理器、测试源等等。
3、Playwright 原理
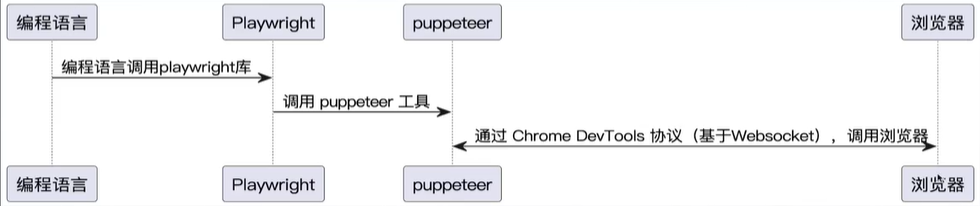
二、基本使用
1、Python技术栈环境安装
-
- 安装 playwright 插件:
pip install pytest-playwright
- 帮助文档:
playwright -v
- 安装 playwright 插件:
-
- 安装所需的浏览器:
playwright install
- 说明:使用这个命令会自动去安装所需所能用的浏览器,不需要手动下载浏览器的安装包安装到对应机器—这就很棒;
- 安装所需的浏览器:
2、Codegen 录制功能
Codegen 在启动录制的时候,可以针对于不同的场景,设定不同的参数。比如设置一个特殊的窗口分辨率、颜色主题、指定手机设备等操作。
(1)设定展示窗口大小
通过命令的--viewport-size参数可以指定录制时窗口展示的尺寸。用来测试当指定一个特殊的窗口展示尺寸时,界面显示是否还正常。
# 设定展示窗口大小
playwright codegen --viewport-size=800,600 地址

(2) 指定设备
通过命令的--device参数可以指定录制时手机的设备型号。用来测试在使用手机浏览时,界面展示是否正常。
# 指定设备
playwright codegen --device="iPhone 11" 地址

(3) 解决登录认证问题
-
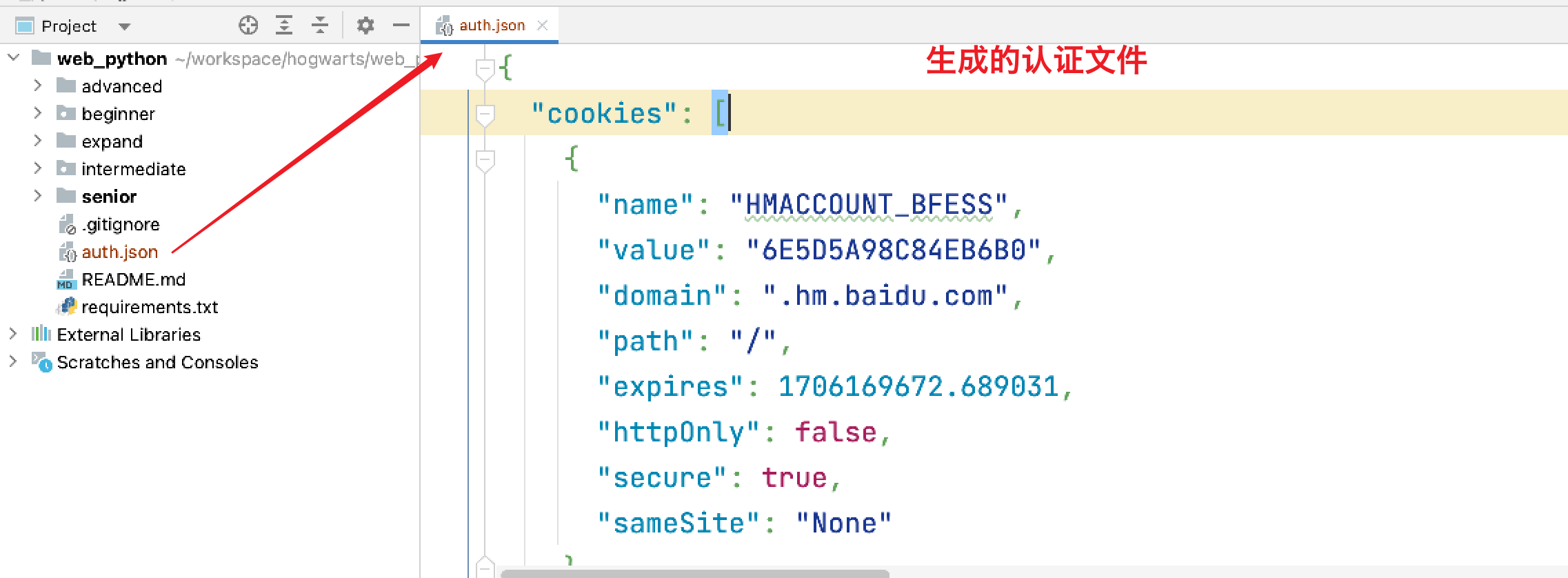
保存登录状态:通过参数
--save-storage可以将认证信息保存在一个文件中。在执行命令后,会自动启动窗口,登录账号之后,手动关闭窗口。即可将认证信息保存下来;
# 保存登录状态
playwright codegen --save-storage=auth.json
- 代码中就是用以下代码:
-
加载认证信息: 通过
--load-storage参数,可以再次启动浏览器,进入上次登录后的网站,发现已经登录成功;
# 加载认证信息
playwright codegen --load-storage=auth.json 地址
- 代码中就是用以下代码:
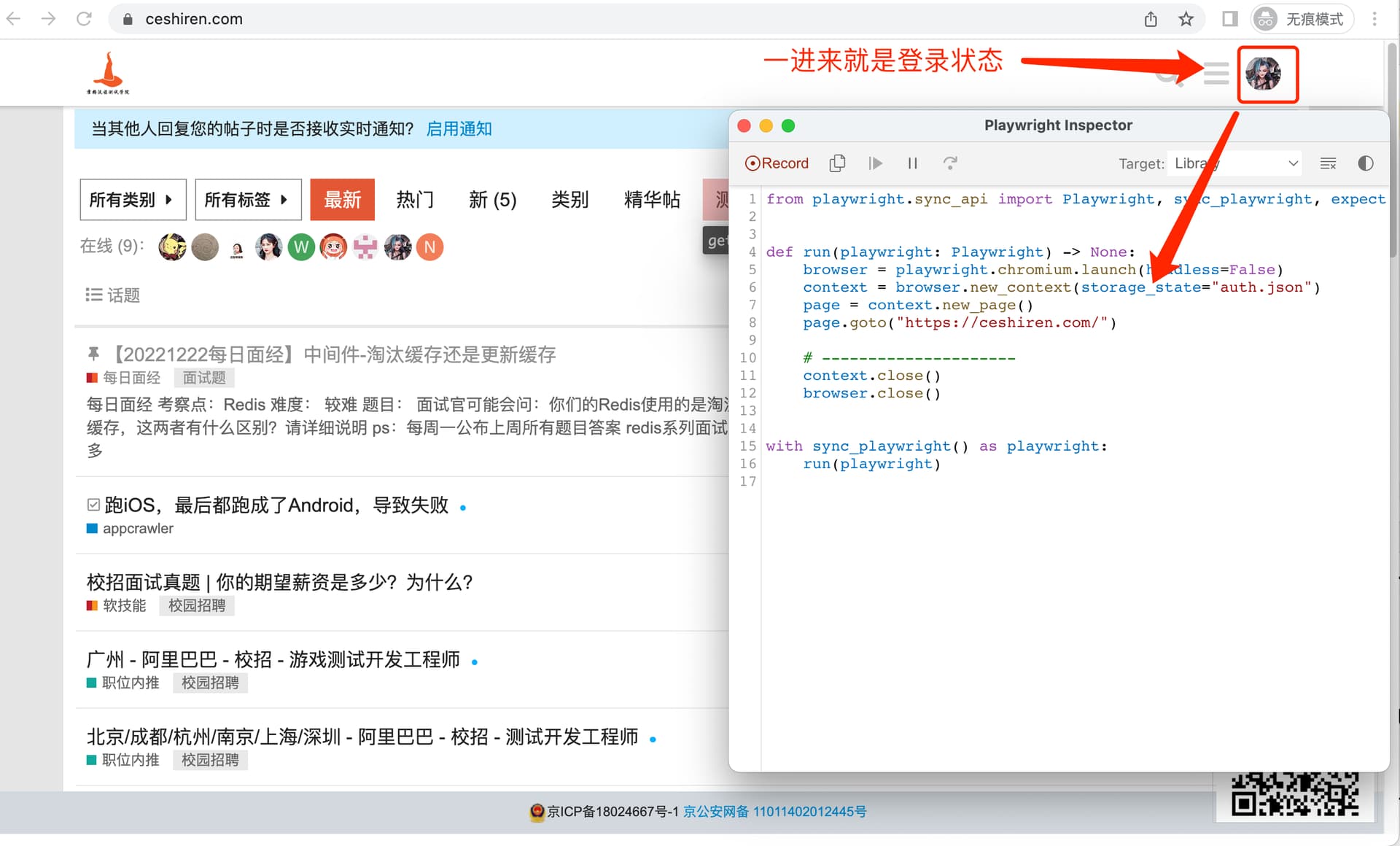
(4)使用代码解决认证问题
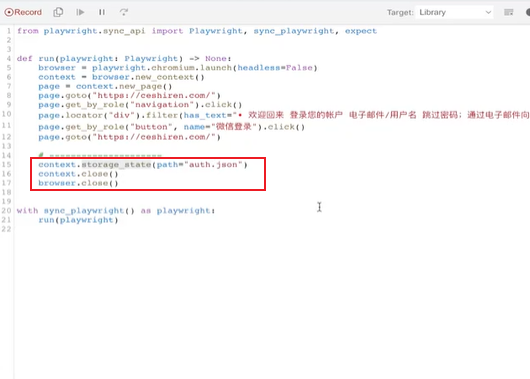
- 保存成功登录后的认证信息cookies到指定json文件:
context.storage_state(path="cookies.json") - 使用保存的认证信息cookies:
context = browser.new_context(storage_state="cookies.json")
import time
from playwright.sync_api import sync_playwright
class TestWework:
def test_get_cookies(self):
# 实例化playwright
wirght = sync_playwright().start()
# 使用非无头模式打开火狐浏览器--默认是无头模式
browser = wirght.firefox.launch(headless=False)
# 获取上下文
context = browser.new_context()
# 用上下文打开一个窗口页面
page = context.new_page()
# 在当前窗口页面中访问网址
page.goto("https://work.weixin.qq.com/wework_admin/loginpage_wx?from=myhome")
# 停止运行20s,扫描登录让服务器返回cookies
time.sleep(20)
# 保存cookies信息
context.storage_state(path="cookies.json")
def test_load_cookies(self):
# 实例化playwright
wirght = sync_playwright().start()
# 使用非无头模式打开火狐浏览器--默认是无头模式
browser = wirght.firefox.launch(headless=False)
# 获取上下文--将保存的cookies.json文件中保存的cookie添加进去
context = browser.new_context(storage_state="cookies.json")
# 用上下文打开一个窗口页面
page = context.new_page()
# 在当前窗口页面中访问网址
page.goto("https://work.weixin.qq.com/wework_admin/loginpage_wx?from=myhome")
# 睡上5s观察是否登录成功---牛皮,登录成功
time.sleep(5)
3、 编写测试用例脚本编写
(1)常用api
| 常用API | 含义 |
|---|---|
| start() | 实例化playwright |
| chromium().launch() | 打开chrome浏览器–默认使用无头模式 |
| new_page() | 打开一个窗口页面 |
| page.goto() | 跳转到某个地址 |
| page.locator(““) | 定位某个元素–默认使用css定位 |
| click() | 点击元素 |
| fill() | 输入内容 |
| keyboard().down() | 键盘事件 |
| screenshot() | 截图操作 |
(2)案例
- 打开测试人论坛https://ceshiren.com/。
- 点击搜索按钮。
- 输入搜索信息,按下回车键。
- 查看搜索的结果是否包含搜索的信息。
from playwright.sync_api import sync_playwright, expect
def test_playwright():
# 实例化playwright
playwright = sync_playwright().start()
# 打开chrome浏览器,headless默认是True,无头模式,这里设置为False方便查看效果
browser = playwright.chromium.launch(headless=False)
# 打开一个窗口页面
page = browser.new_page()
# 在当前窗口页面打开测试人网站
page.goto("https://ceshiren.com/")
# 定位搜索按钮并点击
page.locator("#search-button").click()
# 定位搜索框并输入web自动化
page.locator("#search-term").fill("web自动化")
# 使用keyboard.down模拟键盘的enter事件
page.keyboard.down("Enter")
# 断言搜索结果
result = page.locator(".list>li:nth-child(1) .topic-title>span")
expect(result).to_contain_text("自动化测试")
# 截图
page.screenshot(path='screenshot.png')
# 用例完成后先关闭浏览器
browser.close()
# 然后关闭playwright服务
playwright.stop()
4、 Trace Viewer 追踪功能
在做自动化测试过程中,常常会碰到的一个痛点问题:自动化测试明明发现了代码的 BUG,但是复现比较困难,研发又不认账。
碰到这种场景,Playwright 的 Trace 功能可以完美的解决。因为一旦设定了 Trace,代码执行过程中的每一个步骤,都有详细的截图,日志,时长的信息,比起功能测试的过程记录信息还要更加全面。
(1) Trace 的使用步骤
-
- 在代码中添加 Trace 配置。
-
- 通过 browser 实例生成一个 context 实例
-
- 通过 context 实例的 tracing 配置启动参数
-
- 通过 context 实例生成 page 实例对象。并且想要 trace 的操作,必须都使用这个 page 实例对象
-
- 在想要结束追踪的地方,添加 tracing 的结束配置。
-
- 打开 trace 记录文件,查看 trace 记录。
from playwright.sync_api import sync_playwright, expect
def test_ceshiren():
# 实例化一个playwright对象
playwright = sync_playwright().start()
# 启动谷歌浏览器,模式使用无头模式
browser = playwright.chromium.launch(headless=False)
# =========== trace 的配置
# 1. 生成 一个 context 实例
context = browser.new_context()
# 2. 添加 trace 的配置信息
context.tracing.start(screenshots=True, snapshots=True, sources=True)
# 3. 使用填加了trace 配置的 context 实例,去实例化一个page对象
page = context.new_page()
# 跳转到ceshiren页面
page.goto("https://ceshiren.com/")
# 点击搜索按钮, 输入css定位
page.locator("#search-button").click()
# 输入搜索的内容, 输入css定位
page.locator("#search-term").fill("Appium")
# 按下回车键
page.keyboard.down("Enter")
# time.sleep(3)
result = page.locator(".results .item:nth-child(1) .topic-title")
expect(result).to_contain_text("Appium")
# 4. 在关闭浏览器之前,一定要结束trace
context.tracing.stop(path="ceshiren.zip")
browser.close()
(2)查看 trace 的结果
在执行完成之后,查看项目根目录是否有生成对应的追踪文件夹。如果正常生成,即可使用以下命令查看 trace 的结果。

