六、Datetime模块
-
datetime是Python标准库中用于处理日期和时间的模块。它提供了多种类和函数,用于处理日期、时间、时间间隔等操作,使得日期和时间的处理更加方便灵活。
应用场景:
- 作为日志信息的内容输出;
- 计算某个功能的执行时间;
- 用日期命名一个日志文件的名称;
- 生成随机数(时间是不会重复的)。
6.1 获取当前日期时间
-
datetime.now():获取当前日期和时间。
from datetime import datetime
current_datetime = datetime.now()
print("当前时间:", current_datetime)

6.2 格式化日期和时间
-
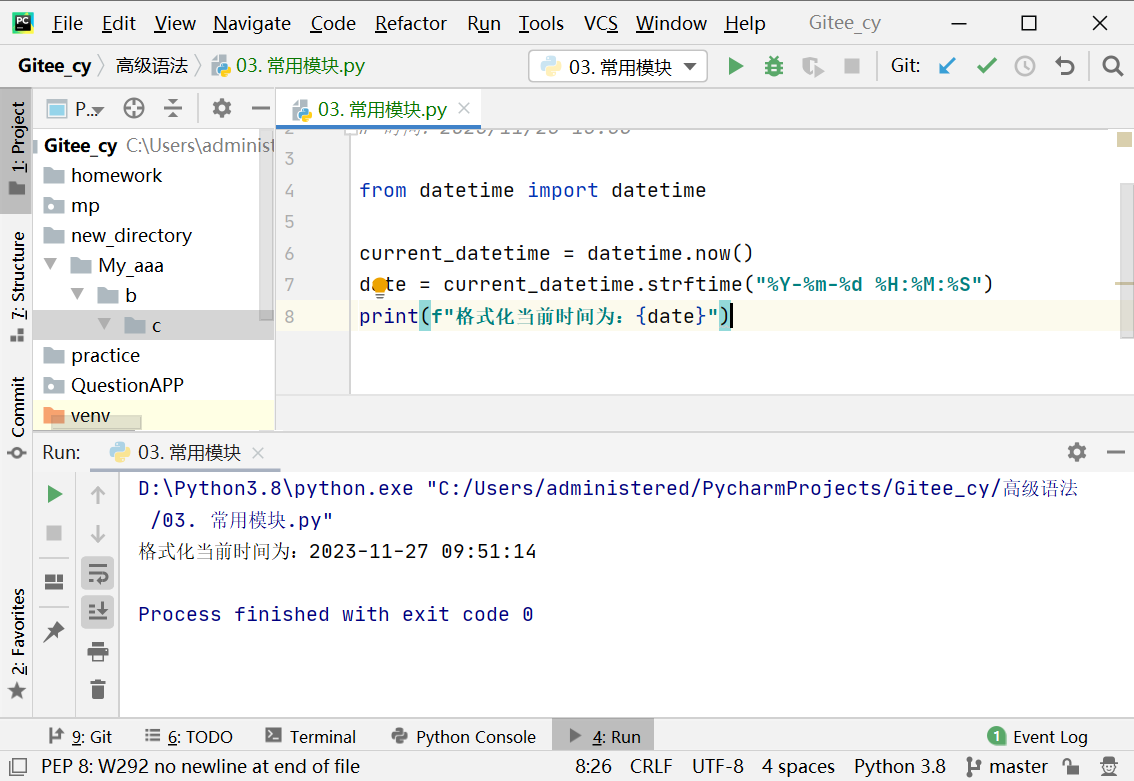
strftime()方法:将datetime对象格式化为字符串格式。
from datetime import datetime
current_datetime = datetime.now()
date = current_datetime.strftime("%Y-%m-%d %H:%M:%S")
print(f"格式化日期时间:{date}")
6.3 解析日期和时间
-
strptime()函数:将字符串解析为datetime对象。
from datetime import datetime
date = "2023-11-27 09:53:41"
print(type(date))
datetime = datetime.strptime(date, "%Y-%m-%d %H:%M:%S")
print(f"当前时间为:{datetime}")
print(type(datetime))

6.4 计算日期间隔
-
timedelta()类可以进行日期间隔的计算。
from datetime import timedelta, datetime
date1 = datetime(2023, 1, 1)
date2 = datetime(2023, 7, 7)
date_diff = date2 - date1
print("Date Difference:", date_diff)
current_datetime = datetime.now()
# 使用 timedelta 计算未来的日期
future_date = current_datetime + timedelta(days=30)
print("Future Date:", future_date)

6.5 比较日期
- 可以直接比较
datetime对象来判断日期的先后关系。
from datetime import datetime
date1 = datetime(2023, 1, 1)
date2 = datetime(2023, 8, 8)
if date1 < date2:
print("date1 is earlier than date2")
elif date1 > date2:
print("date1 is later than date2")
else:
print("date1 and date2 are the same")

6.6 获取日期和时间的部分信息
- 可以使用
year、month、day、hour、minute、second等属性来获取日期和时间的部分信息。
from datetime import datetime
current_datetime = datetime.now()
year = current_datetime.year
month = current_datetime.month
day = current_datetime.day
hour = current_datetime.hour
minute = current_datetime.minute
second = current_datetime.second
print(f"Year: {year}, Month: {month}, Day: {day}")
print(f"Hour: {hour}, Minute: {minute}, Second: {second}")

七、正则表达式
-
正则表达式是一种强大的文本处理工具,可以用于在字符串中进行模式匹配、搜索、替换等操作。
-
Python中内置
re模块,用于进行正则表达式操作,提供了一系列函数和方法,用于执行各种正则表达式操作。
7.1 常用正则表达式语法及含义
| 语法 | 含义 |
|---|---|
| 普通字符 | 大多数只会匹配字符本身 |
| ‘.’ | 匹配除换行符 \n 外的任意字符 |
| ‘[ ]’ | 匹配 [ ] 中列举的字符 |
| ‘*’ | 匹配前一个字符的零个或多个实例 |
| ‘+’ | 匹配前一个字符的一个或多个实例 |
| ‘?’ | 匹配前一个字符的零个或一个实例 |
| ‘{m}’ | 匹配前一个字符的 m 个实例 |
| ‘{m, n}’ | 匹配前一个字符的 m 到 n 个实例 |
| ‘^’ | 匹配字符串的开头 |
| ‘$’ | 匹配字符串的结尾 |
| ‘\d’ | 匹配任意数字字符,相当于 [0-9] |
| ‘\D’ | 匹配任意非数字字符,相当于除 [0-9]以外的字符 |
| ‘\w’ | 匹配任意字母、数字或下划线字符等非特殊字符,相当于 [a-zA-Z0-9_] |
| ‘\W’ | 匹配任意除字母、数字或下划线字符以外的特殊字符,相当于除 [a-zA-Z0-9_]以外的字符 |
| ‘\s’ | 匹配任意空白字符,如空格、制表符、换行等 |
| ‘\S’ | 匹配任意非空白字符 |
7.2 常用正则表达式处理函数
7.2.1 re.match
-
re.match:尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。 -
格式:
re.match(pattern, string, flags=0) -
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式 |
import re
# 使用 re.match 进行匹配
pattern = r"hello"
string = "hello world"
match = re.match(pattern, string)
if match:
print("匹配成功")
else:
print("匹配失败")

(1) group():获取匹配结果;
import re
# 使用 re.match 进行匹配
pattern = r"\d+"
string = "12345hello world"
match = re.match(pattern, string)
print(match.group())

(2)span():获取匹配结果在元字符中的范围;
import re
# 使用 re.match 进行匹配
pattern = r"hello"
string = "hello world"
match = re.match(pattern, string)
print(match.span())
(3)start():获取匹配结果在原字符串中起始下标位置;
(4)end():获取匹配结果在原字符串中结束下标位置。
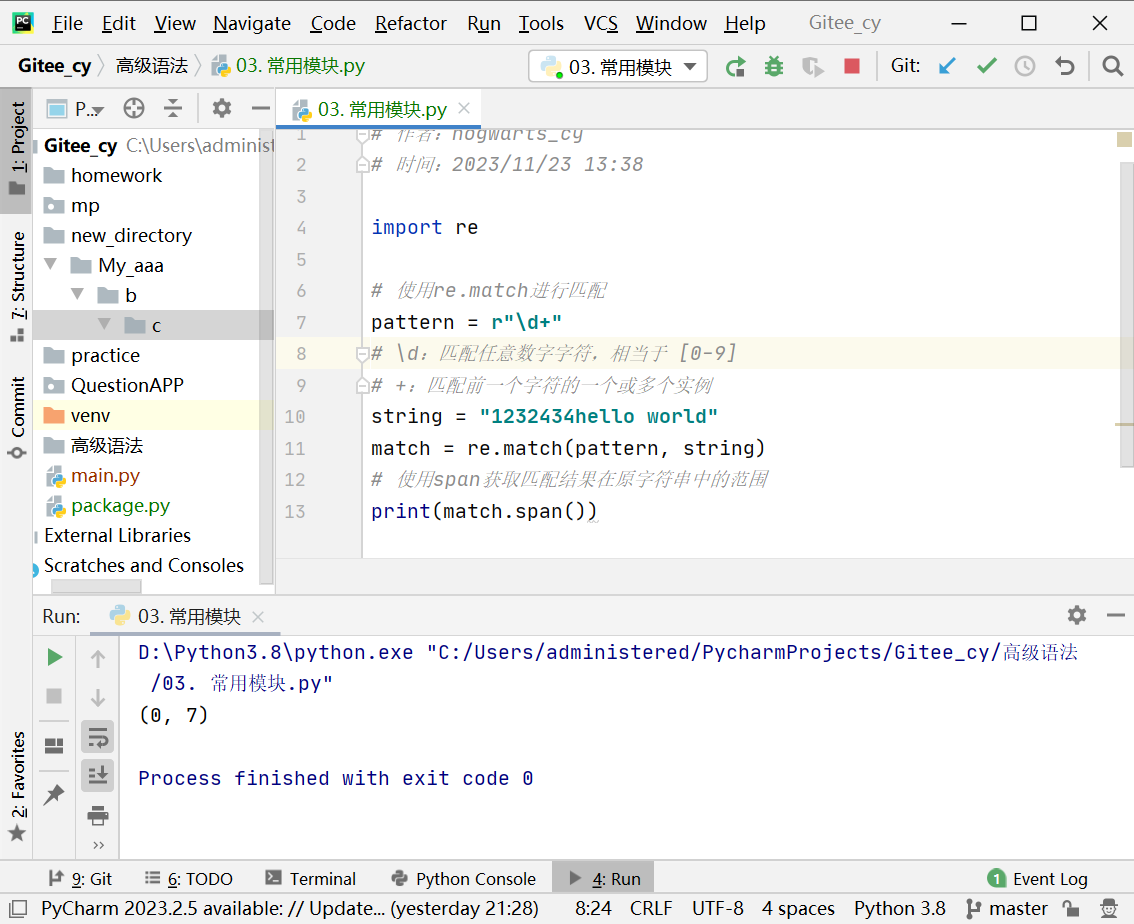
import re
# 使用re.match进行匹配
pattern = r"\d+"
# \d:匹配任意数字字符,相当于 [0-9]
# +:匹配前一个字符的一个或多个实例
string = "1232434hello world"
match = re.match(pattern, string)
# 使用start获取匹配结果在原字符串中的起始下标位置
print(match.start())
# 使用end获取匹配结果在原字符串中的结束下标位置
print(match.end())

7.2.2 re.search
-
re.search:在字符串中搜索匹配指定的模式,如果找到则返回匹配对象,否则返回None。 -
格式:
re.search(pattern, string, flags=0) -
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式 |
import re
# 使用 re.search 进行搜索
pattern = r"world"
string = "hello world"
search = re.search(pattern, string)
if search:
print("找到匹配")
else:
print("未找到匹配")

7.2.3 re.match与re.search的区别
-
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None; -
re.search匹配整个字符串,直到找到一个匹配。
7.2.4 re.findall
-
re.findall:在字符串中找到正则表达式所匹配的所有子串,并返回一个列表;如果有多个匹配模式,则返回元组列表;如果没有找到匹配的,则返回空列表。 -
格式:
re.findall(string[, pos[, endpos]]) -
函数格式说明:
| 参数 | 描述 |
|---|---|
| string | 待匹配的字符串 |
| pos | 可选参数,指定字符串的起始位置,默认为 0 |
| endpos | 可选参数,指定字符串的结束位置,默认为字符串的长度 |
import re
# 使用re.findall进行匹配
pattern = re.compile(r"\d+")
# \d:匹配任意数字字符,相当于 [0-9]
# +:匹配前一个字符的一个或多个实例
result1 = pattern.findall("hogwarts 123 python 456")
result2 = pattern.findall("hello123python456world", 0, 10)
print(result1)
print(result2)

- 多个匹配模式,返回元组列表。
import re
# 使用re.findall进行匹配
result = re.findall(r"(\w+)=(\d+)", "asd width=20 sdf height=10 python100")
# \d:匹配任意数字字符,相当于 [0-9]
# +:匹配前一个字符的一个或多个实例
# \w:匹配任意除字母、数字或下划线字符以外的特殊字符,相当于除 [a-zA-Z0-9_]以外的字符
print(result)

7.2.5 re.sub
-
re.sub:用于替换字符串中的匹配项。 -
格式:
re.sub(pattern, repl, string, count=0, flags=0) -
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| repl | 替换的字符串,也可为一个函数 |
| string | 要被查找替换的原始字符串 |
| count | 模式匹配后替换的最大次数,默认0 表示替换所有的匹配 |
import re
pattern = r"\d+"
# \d:匹配任意数字字符,相当于 [0-9]
# +:匹配前一个字符的一个或多个实例
string = "abc 234 def 567 gki"
# 将字符串中的数字替换为“NUM”
result = re.sub(pattern, "NUM", string)
print("替换后的字符串:", result)

7.2.6 re.split
-
re.split:按照能够匹配的子串,将字符串分割后返回列表。 -
格式:
re.split(pattern, string[, maxsplit=0, flags=0]) -
函数参数列表:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| maxsplit | 分隔次数,maxsplit=1 分隔一次,默认为0,不限制次数 |
| flags | 标志位,用于控制正则表达式的匹配方式 |
import re
pattern = r"\s+"
# \s:匹配任意空白字符,如空格、制表符、换行等
# +:匹配前一个字符的一个或多个实例
string = "Hello World Python"
# 使用正则表达式模式分割字符串
result = re.split(pattern, string)
print("分割后的字符串:", result)

7.3 匹配模式
- 在大多数正则表达式的方法中,都会有一个
flags的参数,该参数用于控制正则表达式的匹配方式。
7.3.1 re.IGNORECASE
-
re.IGNORECASE:用于在正则表达式中启用大小写不敏感的匹配,可简写为re.I。
import re
pattern = r"apple"
string = "Apple is a fruit. I like apple pie."
# 使用re.IGNORECASE标志进行匹配
matches = re.findall(pattern, string, re.IGNORECASE)
print("忽略大小写匹配的结果:", matches)

7.3.2 re.MULTILINE
-
re.MULTILINE:用于启用多行模式,使用^和$在每行的开头和结尾都能匹配,可简写为re.M。
import re
pattern = r"^\d+"
string = "123 apple\n456 banana\n789 cherry"
matches = re.findall(pattern, string)
print("单行匹配的结果:", matches)
# 使用re.MULTILINE标志进行匹配
matches = re.findall(pattern, string, re.MULTILINE)
print("多行匹配的结果:", matches)

7.4 匹配分组
| 模式 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式, \d+ |
| (xxx) | 将括号中字符作为一个分组 |
| \num | 引用分组 num 匹配到的字符串 |
| (?P) | 分组起别名 |
| (?P=name) | 引用别名为 name 分组匹配到的字符串 |
7.4.1 “ | ” 匹配多个规则
- 使用
|可以指定多个匹配表达式。
模式 功能
| 匹配左右任意一个表达式, \d+|\w+
(xxx) 将括号中字符作为一个分组
\num 引用分组 num 匹配到的字符串
(?P<name>) 分组起别名
(?P=name) 引用别名为 name 分组匹配到的字符串
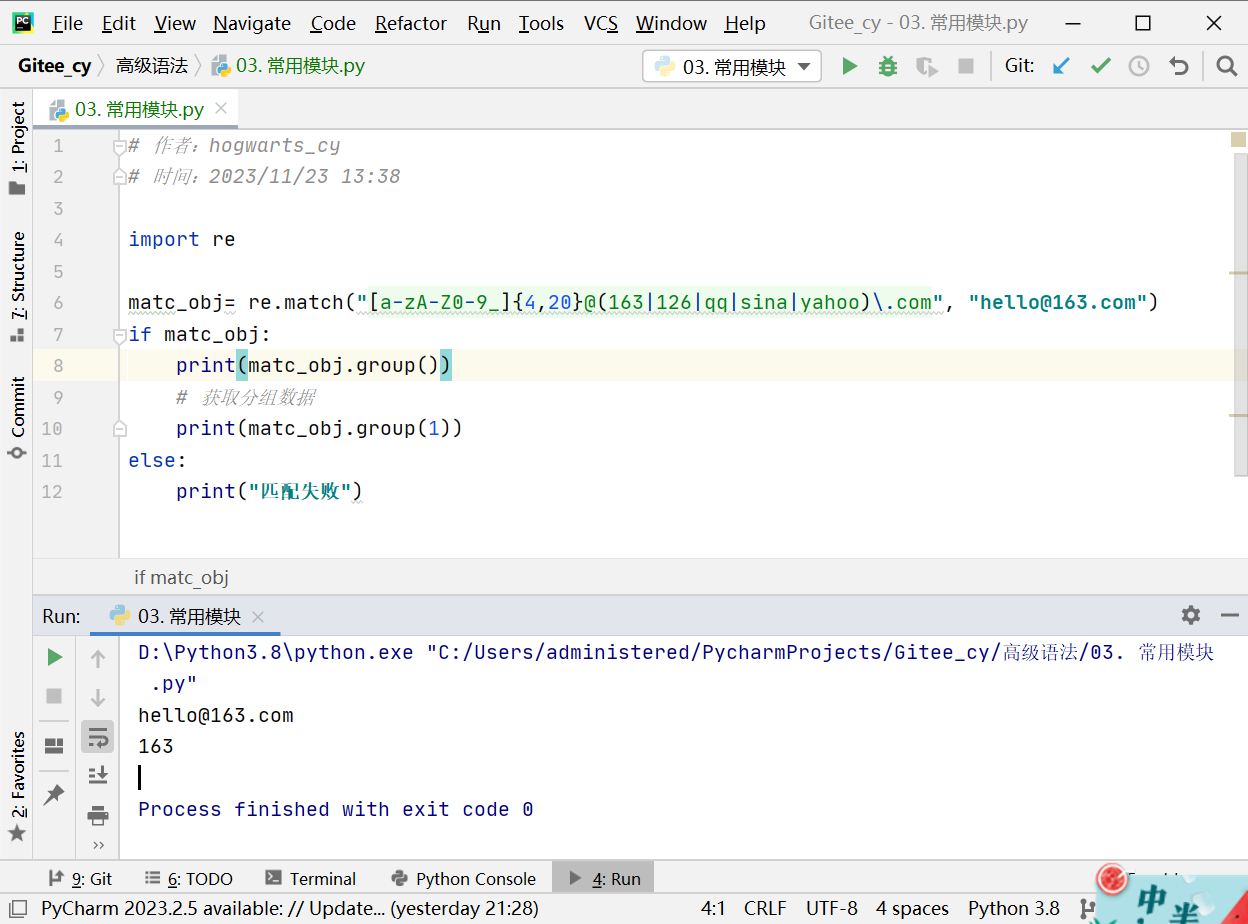
7.4.2 (xxx)分组
-
group()方法可以获取完整的匹配结果,如果想获取匹配结果中某一个分组规则匹配到的结果,可以使用数字参数形式。
import re
matc_obj= re.match("(\d{3,4})-(\d{4,10})", "010-888999")
if matc_obj:
print(matc_obj.group())
# 分组:默认是1一个分组,多个分组从左至右依次加1
print(matc_obj.group(1))
# 提取第二个分组数据
print(matc_obj.group(2))
else:
print("匹配失败")

7.4.3 “ \xxx”引用规则
- 在一个匹配模式中,如果一个规则出现多次,可以将规则进行分组,然后在分组后引用该规则,避免重复书写。
import re
match_obj = re.match("<[a-zA-Z1-6]+>.*</[a-zA-Z1-6]+>", "<html>hh</div>")
if match_obj:
print(match_obj.group())
else:
print("匹配失败")
match_obj = re.match("<([a-zA-Z1-6]+)>.*</\\1>", "<html>hh</html>")
if match_obj:
print(match_obj.group())
else:
print("匹配失败")

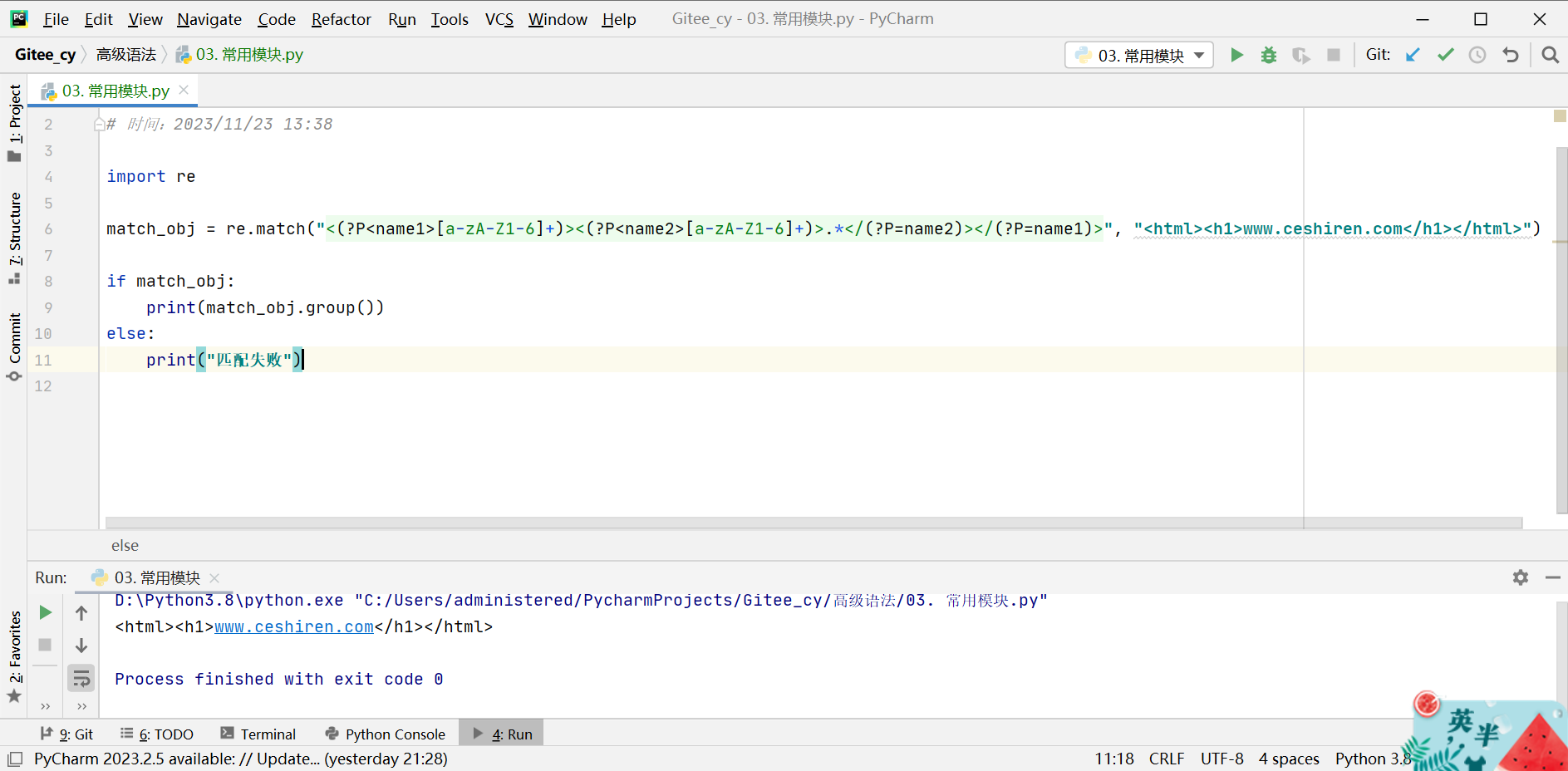
7.4.4 (?P)(?P=name)分组命名与引用
- 在使用分组时,可以给分组进行命名。在匹配规则中,可以通过分组命名引用某个分组中的规则。
import re
match_obj = re.match("<(?P<name1>[a-zA-Z1-6]+)><(?P<name2>[a-zA-Z1-6]+)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.ceshiren.com</h1></html>")
if match_obj:
print(match_obj.group())
else:
print("匹配失败")
八、JSON模块
8.1 JSON概念
-
JSON(JavaScript Object Notation,JS对象简谱)是一种轻量级的数据交换格式,用于在不同应用程序之间传输和存储数据。
-
它以文本形式表示结构化数据,易于理解和编写,同时也易于计算机解析和生成。
8.2 JSON的结构
- 对象:用花括号
{}包裹,包含一系列键值对,每个键值对之间用逗号,分隔; - 数组:用方括号
[ ]包裹,包含一系列值,每个键值之间用逗号,分隔; - 键值对:键和值之间使用冒号
:分隔,键必须是字符串,值可以是字符串、数字、布尔值、对象、数组或null; - JSON数据的最外层只能是数组或对象;
- JSON中的字符串,必须使用双引号包含。
{
"name": "John",
"age": 30,
"is_student": false,
"address": {
"city": "New York",
"zip": "10001"
},
"hobbies": ["reading", "swimming", "traveling"]
}
8.3 Python与JSON数据类型对应
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float | number |
| True | true |
| Flase | false |
| None | null |
8.4 JSON序列化与反序列化
-
JSON序列化指的是将Python对象转换为JSON格式的字符串。
-
通过序列化,Python对象可以被编码为符合JSON规范的字符串,从而可以在不同的应用程序、平台或语言之间进行数据交换。
(1)json.dumps():可以完成序列化的操作。这个函数将Python的数据结构转换成JSON格式的字符串。
import json
# 定义一个Python字典
data = {
"name": "Rose",
"age": 20,
"gender": "female"
}
# 将Python字典序列化为JSON格式的字符串
json_str = json.dumps(data)
print(json_str)

(2)json.loads():用于将JSON格式的字符串解码为Python对象。
import json
# 定义一个JSON格式的字符串
json_str = '{"name": "Rose", "age": 20, "gender": "female"}'
print(type(json_str))
# 将JSON格式的字符串解码为Python对象
Python_obj = json.loads(json_str)
print(Python_obj)
print(type(Python_obj))

8.5 JSON文件的写入和读取
with open(file_path, mode, encoding) as file
| 参数 | 描述 |
|---|---|
| file_path | 要打开为文件路径; |
| mode | 打开文件的模式,如r(只读)、w(写入)、a(追加)等; |
| encoding(可选) | 文件的编码方式,默认为None,表示使用相同默认编码。 |
(1)json.dump():将Python对象序列转化为JSON格式,并写入文件中;
import json
data = {
"name": "Rose",
"age": 20,
"gender": "female"
}
# 将数据写入JSON文件
with open("data.json", "w")as file:
json.dump(data, file)

(2)json.load():从文件中读取JSON格式的数据,并解码为Python对象。
import json
# 从JSON文件中读取数据
with open("data.json", "r")as file:
data = json.load(file)
print(data)
print(type(data))

九、日志模块
-
Python中的日志模块
logging是用于记录应用程序运行时的信息,帮助开发者诊断问题,跟踪应用程序的状态以及记录重要的时间。 -
logging模块提供了丰富的配置选项和灵活性,可以将日志信息输出到不同的位置,设置不同的日志级别等。
9.1 logging模块的四大组件
| 模块名称 | 作用 |
|---|---|
| logger | 日志器,提供程序可使用的接口; |
| handler | 处理器,用于写入 |
| filter | 过滤器,用于输出符合指定条件的日志记录 |
| formatter | 格式器,决定日志记录的输出格式 |
9.2 日志等级
| 级别 | 用法 |
|---|---|
| DEBUG | 最低级别的日志,用于调试和记录详细信息,通常用于开发和调试阶段; |
| INFO | 信息性信息,用于调试和记录详细信息,通常用于开发和调试阶段,确认程序按预期运行; |
| WARNING | 表示警告,用于指示应用程序已经或即将发生的意外(例如:磁盘空间不足)。程序仍按预期进行; |
| ERROR | 表示错误,由于严重的问题,程序的某些功能已经不能正常执行; |
| CRITICAL | 最高级别的日志,表示严重错误,表明程序已不能继续执行。 |
9.3 logging.basicConfig()函数
-
logging.basicConfig()是Python中提供一个用来配置日志管理的函数。 -
格式说明:
logging.basicConfig(filename, filemode, level) -
函数参数说明:
| 参数 | 描述 |
|---|---|
| fileneme | 指定将日志记录到文件中,如果不指定,则默认将日志输出到控制台; |
| filemode | 指定文件打开模式,默认为a(追加模式); |
| format | 指定日志记录的格式; |
| level | 指定日志记录的最低级别,默认为logging.WARING。 |
- format格式说明:
| 格式 | 描述 |
|---|---|
| %(asctime)s | 打印日志的时间 |
| %(filename)s | 打印当前模块名 |
| %(lineno)s | 打印日志当前的行号 |
| %(levelname)s | 打印日志级别名称 |
| %(message)s | 打印日志信息 |
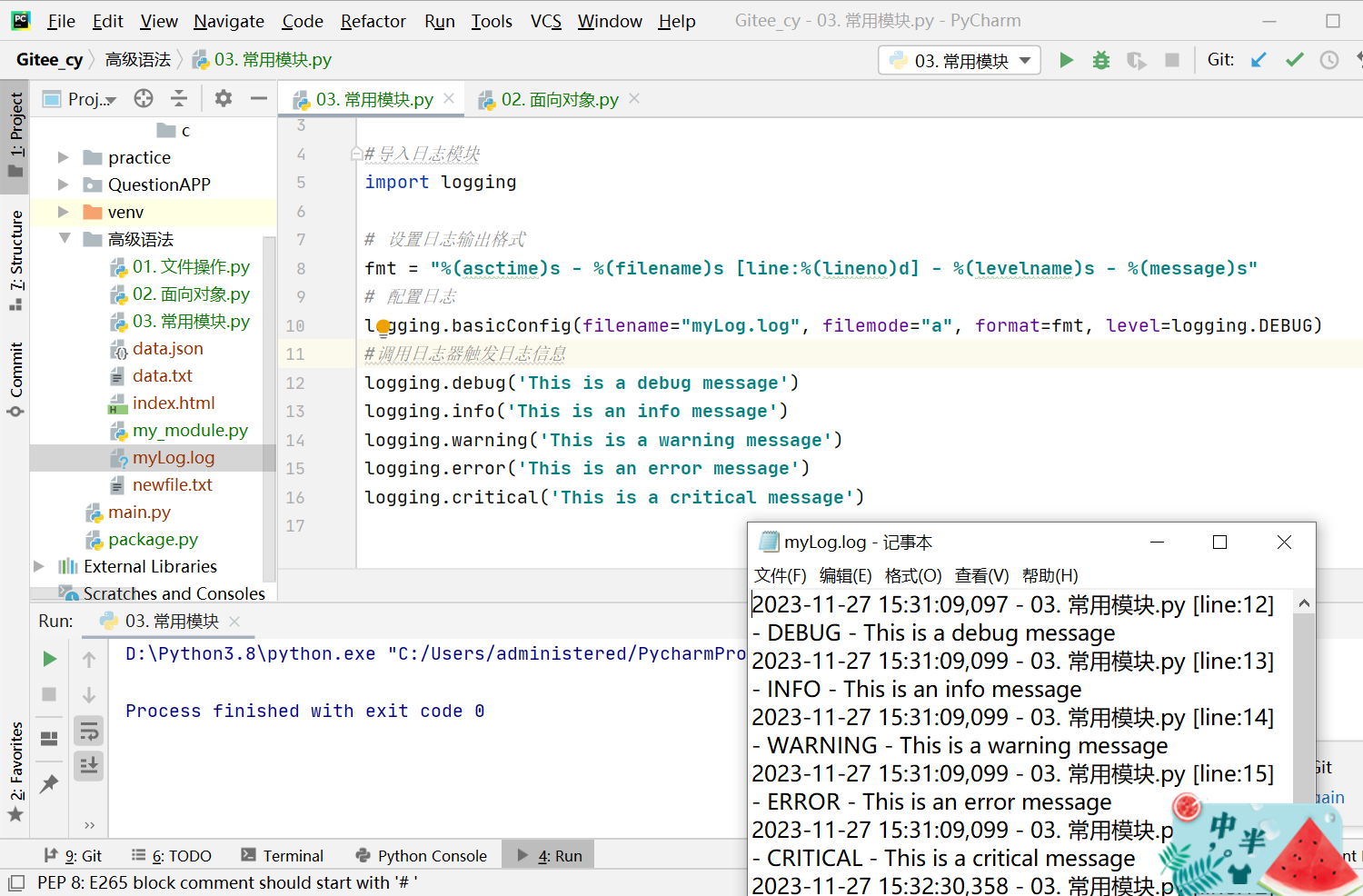
实例:
#导入日志模块
import logging
# 设置日志输出格式
fmt = "%(asctime)s - %(filename)s [line:%(lineno)d] - %(levelname)s - %(message)s"
# 配置日志
logging.basicConfig(filename="myLog.log", filemode="a", format=fmt, level=logging.DEBUG)
#调用日志器触发日志信息
logging.debug('This is a debug message')
logging.info('This is an info message')
logging.warning('This is a warning message')
logging.error('This is an error message')
logging.critical('This is a critical message')
十、虚拟环境管理
10.1 venv虚拟环境
-
虚拟环境是一个独立于系统全局环境的独立Python运行环境,用于隔离不同项目的依赖关系。
-
可以使每个项目都可以拥有独立的包依赖,从而避免包之间的冲突。
-
使用虚拟环境对于管理多个项目和维持干净的开发环境非常有帮助。
10.2 venv虚拟环境的特点和作用
-
隔离环境:每个虚拟环境都有自己的 Python 解释器和一组安装的库,这些都是独立于系统全局安装的 Python 和库的;
-
依赖管理:可以在虚拟环境中安装、升级和卸载库而不影响系统的其他部分或其他项目;
-
项目特定配置:允许为每个项目设置特定的Python版本和依赖,使得项目在不同机器和环境中具有更好的一致性和可移植性;
-
简单易用:使用
venv创建和管理虚拟环境相对简单,只需几个命令即可完成。
10.3 venv使用方法
-
创建虚拟环境:可以使用
python -m venv <env_name>命令创建一个新的虚拟环境,其中<env_name>是你为虚拟环境选择的名字; -
激活虚拟环境:在使用虚拟环境之前,需要先激活它。在 Windows 上,可以使用
<env_name>\Scripts\activate命令;在 Unix 或 MacOS 上,使用source <env_name>/bin/activate; -
使用虚拟环境:一旦虚拟环境被激活,就可以在其中安装、使用和管理库了。在虚拟环境中安装的库不会影响到系统中的其他部分;
-
退出虚拟环境:使用
deactivate命令可以退出当前的虚拟环境。
10.4 venv创建虚拟环境
- 在终端中,进入要创建虚拟环境的目录,执行以下指令;
Python3 -m venv myenv
10.5 激活虚拟环境
- 在macOS和Linux上:
source myenv/bin/activate
- 在Windows上:
myenv\Scripts\activate
- 虚拟环境被激活,在命令行提示符前看到环境名称(如
myenv),表示已经在虚拟环境中。
10.6 venv安装Python包
-
Python 版本选择
- 进入 Python2.7 环境:Python2
- 进入 Python3.x 环境: Python3
-
pip 安装 Python 包
- 安装 Python2.x 版本的包
- 安装 Python3.x 版本的包
# 进入 Python2.7 环境
Python2
# 进入 Python3.x 环境
Python3
# 安装 Python2.x 版本的包
pip install xxx
# 安装 Python3.x 版本的包
pip3 install xxx
10.7 venv退出和删除
- 退出虚拟环境:deactivate
- 删除虚拟环境:删除环境目录
# Windows和macOS通用的退出指令
deactivate
十一、Pip工具使用
- pip是Python中用于管理第三方包的工具,它可以帮助下载、安装、升级和管理各种Python包,能够轻松地引入外部库和模块到项目中。
11.1 pip 常用命令
| 功能 | 指令 |
|---|---|
| 查看 pip 版本 | pip -V |
| 查看帮助文档 | pip help |
| 查看包列表 | pip list |
| 安装 | pip install 包名 |
| 升级 | pip install --upgrade 包名 |
| 卸载 | pip uninstall 包名 |
11.2 pip 安装包
- 普通安装
# 默认安装最新版本
pip install pytest
- 指定版本安装
# 指定版本
pip install pytest==6.2.0
- 批量安装
# 从文件清单中批量安装
pip install -r requirments.txt
# 文件格式
pytest==6.2.0
Faker==9.3.1
selenium==3.14.1
11.3 升级pip
Python -m pip install --upgrade pip
11.4 指定安装源
pip install 包名 -i 镜像源
- 国内常用源
- 阿里源:
https://mirrors.aliyun.com/pypi/simple/ - 清华源:
https://pypi.tuna.tsinghua.edu.cn/simple/ - 豆瓣源:
http://pypi.douban.com/simple/
- 阿里源:
# 使用镜像
pip install pytest -i https://pypi.douban.com/simple
