一、 强制等待、隐式等待、显示等待
为什么需要使用等待: 避免页面未渲染完成后就进行查找或者操作元素导致的报错;
| 类型 | 使用方式 | 原理 | 适用场景 | 说明 |
|---|---|---|---|---|
| 直接等待 | time.sleep(等待时间)) | 强制线程等待 | 调试代码,临时性添加 | 实际工作中不建议使用 |
| 隐式等待 | driver.implicitly_wait(等待时间) | 在时间范围内,轮询查找元素 | 解决元素存不存在的问题,无法准确的判断元素是否展示,无法解决交互问题 | 一个设置全局有效,对该driver下的所有find方法都生效 |
| 显式等待 | WebDriverWait(driver实例, 最长等待时间, 轮询时间).until(结束条件) | 设定特定的等待条件,轮询操作 | 解决特定条件下的等待问题,比如点击等交互性行为 | 对指定元素的指定条件有效 |
(1)强制等待sleep
time.sleep(3)
- 原理:强制等待,线程休眠一定时间,简单说就是强制停止代码继续往下执行;
(2)隐式等待
driver.implicitly_wait(3)
- 问题:难以确定元素加载的具体等待时间。
- 解决方案:针对于寻找元素的这个动作,使用隐式等待添加配置。
- 原理:设置一个等待时间,轮询查找(默认0.5秒)元素是否出现,如果在设置时间元素加载显示到页面就继续往下执行,不管设置时间到没到,如果时间到了还没加载显示到页面就抛出异常
NoSuchElementException;
(3)显示等待
为什么还有显示等待: 因为有些问题隐式等待无法解决
-
比如: 元素可以找到,使用点击等操作,出现报错;
-
原因:
- 页面元素加载是异步加载过程,通常html会先加载完成,随后才加载js、css;
- 元素存在与否是由HTML是否加载显示决定,元素的交互是由css或者js加载完成决定;
- 隐式等待只关注元素能不能找到,不关注元素能否点击或者进行其他的交互;
-
解决方案:使用显式等待;
A、显示等待api基本使用
- 原理:在最长等待时间内,轮询,是否满足结束条件,满足条件就继续往下执行,不满足则抛出异常
TimeoutException; - 语法:
WebDriverWait(driver实例, 最长等待时间, 轮询时间-默认0.5秒).until(结束条件)
WebDriverWait参数:
from selenium.webdriver.support.wait import WebDriverWait
源码:
class WebDriverWait:
def __init__(
self,
driver: WebDriver,
timeout: float,
poll_frequency: float = POLL_FREQUENCY,
ignored_exceptions: typing.Optional[WaitExcTypes] = None,
):
- driver:webdriver驱动对象;
- timeout:超时时间(最大等待时间);
- poll_frequency:轮询间隔(默认0.5s);
- ignored_exceptions:忽略例外情况(None默认值,忽略NoSuchElementException);
.until(结束条件): WebDriverWait类中方法,等待某个条件为真(即条件满足);
- method参数:接收一个函数引用,这个函数就是显示等待需要等的内容,需要达到函数中实现的逻辑才轮询结束,通常使用
expected_conditions类中的方法,也可以自定义条件逻辑; - message:当抛出异常的时候的提示信息;
"""
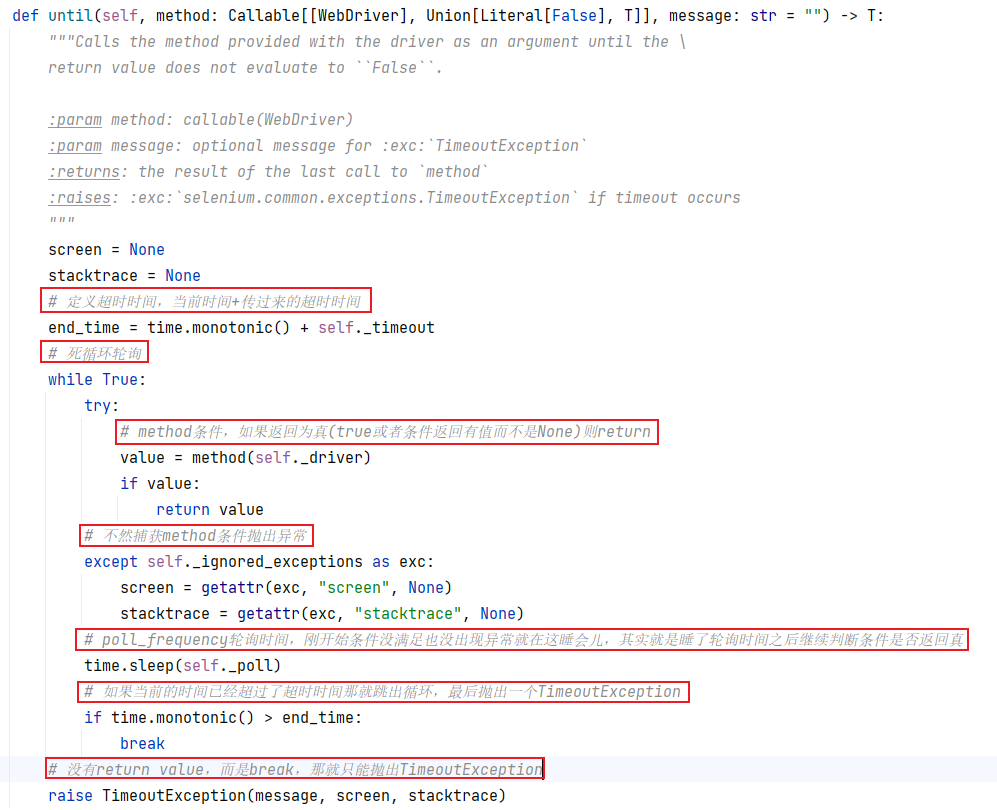
WebDriverWait.until()原理
"""
import time
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
if __name__ == '__main__':
# WebDriverWait的构造函数需要一个WebDriver对象
driver = webdriver.Edge()
#自定义一个条件方法,后面传给until用,从源码中发现这个条件方法需要一个ebDriver对象
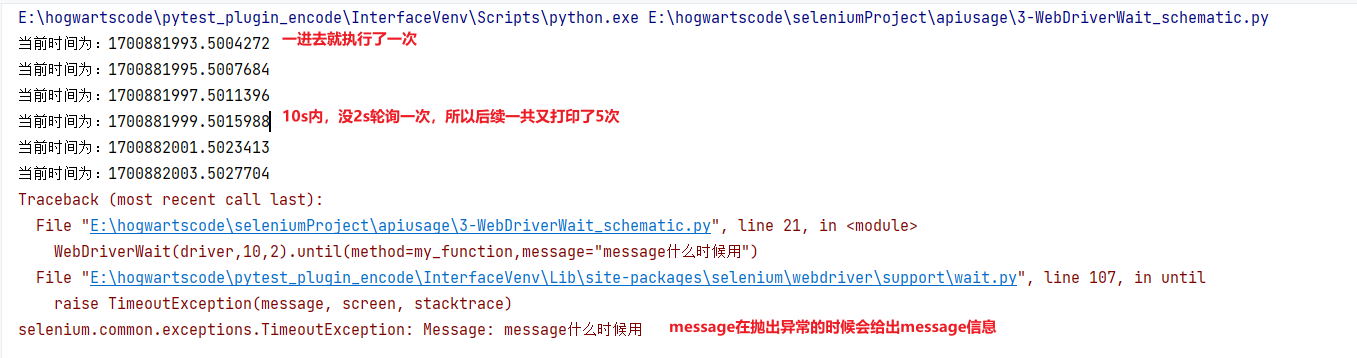
def my_function(driver):
print(f"当前时间为:{time.time()}")
# 初始化WebDriverWait等待10s,每2s轮询一次,然后调用until方法
# until方法接收两个参数,一个是条件方法的引用,另一个是错误信息
WebDriverWait(driver,10,2).until(method=my_function,message="message什么时候用")

.until_not(结束条件): WebDriverWait类中方法,等待某个条件为假(即条件不满足),它会反复检查条件是否为假,直到条件为假或超过指定的超时时间;
- 常配合以下方法使用,意思是等待某个元素不可见,也就是元素消失:
- visibility_of_any_elements_located:方法的原意是任意一个元素可见,配合until_not则是一个元素都不可见;
- visibility_of_element_located:方法的原意是某个元素可见,配合until_not则是元素不可见;
from selenium.webdriver.support import expected_conditions
常用方法: 这些方法都是返回了一个内部函数的引用,因为until的第一个参数需要是函数引用;
-
title_is(title: str): 判断当前页面的标题是否等于预期,返回布尔值; -
title_contains(title: str): 判断当前页面的标题是否包含预期字符串; -
presence_of_element_located(locator: Tuple[str, str]): 判断元素是否被加在DOM树里,并不代表该元素一定可见;- 传入的参数是tuple类型,第一个元素是定位方式,第二个元素是定位的具体值。如果元素存在则返回元素位置,不存在则抛出异常(NoSuchElementException);
-
url_contains(url: str): 判断当前url是否包含str内容; -
visibility_of_element_located(locator: Tuple[str, str]): 判断元素是否可见(可见代表元素非隐藏,并且元素的宽和高都不等于0),元素存在且可见,就返回元素本身,如果存在但不可见则返回false;- 传入的参数是tuple类型,第一个元素是定位方式,第二个元素是定位的具体值。
-
visibility_of(element: WebElement): 和visibility_of_element_located()作用一样,区别是传参不同,visibility_of()接收的参数是定位后的元素; -
text_to_be_present_in_element(locator: Tuple[str, str], text_: str): 判断某个元素中的text是否包含了预期的字符串;-
locator: Tuple[str, str]是定位器; -
text_: str是预期的字符串;
-
-
text_to_be_present_in_element_value(locator: Tuple[str, str], text_: str): 判断某个元素中的value属性是否包含了预期字符串; -
frame_to_be_available_and_switch_to_it(locator: Union[Tuple[str, str], str]): 判断该表单是否可以切换进去,如果可以,返回True并switch进去,否则返回False; -
invisibility_of_element_located(locator: Union[WebElement, Tuple[str, str]]): 判断某个元素是否不存在与DOM树中或不可见 -
element_to_be_clickable( mark: Union[WebElement, Tuple[str, str]]): 判断元素是否可见并是可以点击的,如果元素存在且可点击,则返回元素,如果元素存在但不可点击,则返回False; -
element_to_be_selected(element: WebElement): 判断某个元素是否被选中,一般用在下拉列表,传入element元素; -
element_selection_state_to_be(element: WebElement, is_selected: bool): 判断某个元素的选中状态是否符合预期,方法参数是element和 is_selected; -
element_located_selection_state_to_be(locator: Tuple[str, str], is_selected: bool): 与element_selection_state_to_be()作用一样,只是方法参数不同,方法参数是located和 is_selected -
alert_is_present(): 按断页面上是否存在alert警告;
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
driver = webdriver.Edge()
driver.get("https://www.baidu.com")
driver.maximize_window()
# 设置隐式等待--这是全局的,针对所有元素查找操作都有效
driver.implicitly_wait(3)
# 直到元素可点击
el = WebDriverWait(driver=driver,timeout=10,poll_frequency=1).until(EC.element_to_be_clickable((By.ID,"kw")))
print(type(el)) # <class 'selenium.webdriver.remote.webelement.WebElement'>
el.send_keys("hello")
query = driver.find_element(By.ID,"kw")
print(type(query)) # <class 'selenium.webdriver.remote.webelement.WebElement'>
isurl = WebDriverWait(driver,10,1).until(EC.url_contains("bai"))
print(isurl) # True
sleep(3)
driver.quit()
二、隐式等待与显示等待的区别和细节
1、区别
-
隐式等待(
driver.implicitly_wait(time_in_seconds))-
定义:设置一个全局的等待时间,在该时间范围内,Selenium 将等待页面的所有元素可见或可操作。
-
使用方式:通过
driver.implicitly_wait(time_in_seconds)来设置等待时间,time_in_seconds为等待的时间(以秒为单位)。 -
应用场景:适用于等待页面上的所有元素,在页面加载完成之前进行等待,并不需要为每个元素单独设置等待时间。
-
说明:
- 关注的是元素加载到DOM中,也就是元素存在于页面结构中,并且可以通过find_element方法来定位到元素。
- 隐式等待并不关注元素是否在页面上可见或者是否已经渲染出来,它的着重点在于等待元素的出现和可定位性。如果元素在指定的等待时间内成功被定位到,WebDriver会立即继续执行代码。但如果超过了设置的等待时间,仍未能找到元素,则会抛出 NoSuchElementException 异常。
- 隐式等待是一种全局设置,对于整个WebDriver的生命周期都起作用。在设置了隐式等待之后,WebDriver会在尝试在每个定位元素时等待一定的时间,直到找到符合定位条件的元素,或者等待时间超过了设置的等待时间。
-
-
显示等待(
WebDriverWait类)-
定义:显式等待是在特定条件满足之前停止代码执行的等待方法,可以根据具体需求等待元素可见、可点击等。
-
使用方式:通过
WebDriverWait类结合具体条件和等待时间来设置显示等待。 -
应用场景:适用于某个特定元素需要等待特定条件或时间后才能进行操作的情况。
-
说明:显示等待只会在特定的某次等待条件中起作用;
-
2、 如果每个元素定位的时候都是用显示等待会怎样
-
执行速度变慢:使用显示等待会在每个元素定位时都等待一定的时间或者条件满足才继续往下执行,这会增加整个测试脚本的执行时间,特别是在大规模的测试用例中。
-
等待时间的累加:当每个元素都使用显示等待进行定位时,每个定位都需要等待一定的时间或条件满足后再继续执行。这样逐个定位下来,等待时间就会累加起来,导致整体脚本执行时间变长。
-
等待条件的重复检查:在每个显示等待定位中,Selenium会不断地检查元素是否满足指定的条件。这种重复的检查会消耗一定的时间和资源,当脚本中频繁使用显示等待定位时,这种重复的检查会在总体上增加执行的时间。
-
-
代码复杂性增加:每个元素都需要编写显示等待的代码,这会导致测试脚本代码变得冗长且难以维护。如果同一个元素在多个地方使用到,就需要多次重复编写显示等待的代码。
-
可能导致超时或等待不足:如果设置的显示等待时间过短,可能会导致元素还未加载完成就进行操作,从而抛出找不到元素的异常;如果设置的显示等待时间过长,可能会导致测试脚本在等待期间一直处于等待状态,从而浪费时间。
3、隐式等待和显示等待同时设置的时间问题
- 两者的时间不会叠加,而是单独起作用;
- 找不到的情况:会根据两者中较长的等待时间来判断是否会抛出异常。
- 找到的情况:不管是显示等待还是隐式等待,只要找到了,代码会立即往下执行;
三、显示等待高级用法-自定义等待条件
1、为什么需要自定义等待条件
- 官方的 excepted_conditions 不可能覆盖所有场景;
- 定制封装条件会更加灵活、可控;
2、需要自定义等待条件的一个场景演示

-
网址:
https://vip.ceshiren.com/#/ui_study/frame; -
场景:这个网页中有个“点击两次响应”的按钮,需要点击这个按钮怎么处理;
-
初步解决方案:
- 1、能想到的第一解决方案就是使用显示等待然后给excepted_conditions 条件,直到按钮可点击,但是这是无法实现的,因为按钮可点击的条件可以实现,但是并不能实现双击;
- 2、调用两次click点击实现双击,这种方式虽然能解决问题,但是略显不高级!
初步解决方案代码如下:
"""
使用两次click实现点击两次
"""
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
driver = webdriver.Edge()
driver.maximize_window()
driver.get("https://vip.ceshiren.com/#/ui_study/frame")
driver.implicitly_wait(3)
# 使用显示等待,条件是这个按钮可点击,它会返回可点击的元素,然后进行点击试试
WebDriverWait(driver,10,2).until(expected_conditions.element_to_be_clickable((By.XPATH,"//*[@id='primary_btn']")),"按钮不可点击").click()
# 上面的点击事件确实触发了,在屏幕上确实可见,但是却没有达到要求点击两次,那就再来点击一次
WebDriverWait(driver,10,2).until(expected_conditions.element_to_be_clickable((By.XPATH,"//*[@id='primary_btn']")),"按钮不可点击").click()
time.sleep(10)
driver.quit()
3、私人定制等待条件
针对上面按钮的需求,自定义一个until的等待条件实现需要点击两次按钮的点击,甚至是需要点击多次才能点击成功的按钮的点击事件;
-
思路:
- 1、模仿expected_conditions中方法的定义模式,定义一个内函数和外函数;
- 2、外函数接收两个参数,第一个是需要点击的按钮定位器,第二个是下一个页面用于确认点击成功跳转过去的某个元素的定位器;
- 3、内函数接收一个参数,webdirver的对象,因为里面需要用到find_element方法,同时until源码中也传了一个参数(
value = method(self._driver)),所以需要webdirver对象; - 4、内函数返回定位到的下个页面用于确认点击成功并跳过去了的页面中的元素;
-
原理:仔细研究until方法和expected_conditions中的方法;
-
1、until方法的第一个参数需要的是一个函数引用,所以expected_conditions中的方法都返回了内函数的引用;
-
2、until中会通过死循环轮询去调用“内函数”,而自定义条件的内函数返回的是定位到的元素,在until中:
- 如果这个“内函数返回真”,也就是定位到了元素就会返回这个定位到的元素;
- 如果“内函数定位的时候抛出了异常”,until会捕获这个异常并且开始轮巡再次去调用“内函数”,直到”内函数找到元素“或者是超时时间达到最终抛出异常;
-
代码实现:
"""
对until中的等待条件做私人定制
"""
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
# 模仿expected_conditions自定义一个until的条件函数实现对某个按钮的多次点击操作
# 外函数,这是需要传给until的函数
def repeatedly_click(click_element_locator: tuple,next_page_element_locator:tuple):
# 内函数,这是until中真正用到的函数,里面是元素定位逻辑,需要一个webdirver对象作为参数
# 因为通过源码知道until中调用了内函数并且返回了一个value,我们这里value是个webelement对象,不是bool值
def inner(driver: webdriver):
# 直接定位元素并点击,但是可能会抛出异常,那就做异常处理
try:
# find_element需要两个参数,但传进来的是一个元组,所以使用自动解包方式(*click_element_locator)传参
driver.find_element(*click_element_locator).click()
except Exception as e:
# 出现了异常不要怕,直接返回这个异常,因为until中接收了异常并捕获处理,until中代码--try:value = method(self._driver)
# until捕获了异常会进入轮询
return e
# 内函数返回定位的下个页面的元素,因为是定位,必然可能会有异常,但是不要怕,这个异常until会处理
# 直到超时或者找到元素之后返回这个元素,until结束,代码继续往下执行
# until如果还抛出异常,那说明要么等待时间不够,要么定位器写错了,要么就是这个按钮压根就不可点击等等,需要具体问题具体分析
# until如果返回了真值,那说明下个页面的元素是找到了,说明多次点击成功
return driver.find_element(*next_page_element_locator)
# 外函数返回内函数的引用
return inner
def check_webdriverwait():
driver = webdriver.Edge()
driver.maximize_window()
driver.get("https://vip.ceshiren.com/#/ui_study/frame")
# 还是来个隐式等待吧
driver.implicitly_wait(3)
# 将自定义的until等待条件传给until
click_element_locator = (By.XPATH,"//*[text()='点击两次响应']") # 多练练xpath语法
next_page_element_locator = (By.XPATH,"//*[text()='该弹框点击两次后才会弹出']")
WebDriverWait(driver,10,2).until(method=repeatedly_click(click_element_locator,next_page_element_locator),message="自定义多次点击条件出没出问题")
# 睡上几秒查看效果
time.sleep(5)
driver.quit()
if __name__ == '__main__':
check_webdriverwait()
