一、闭包与装饰器
1.1 函数引用
- Python中定义的函数,也可以像变量一样,将一个函数名,赋值给另一个变量名,赋值后,此变量名就可以作为该函数的一个别名使用,进行调用函数,此功能与列表操作的
sort()方法类似,sort()方法的key参数传入的就是一个函数名。
def show():
print("Show Run ...")
show()
a = show()
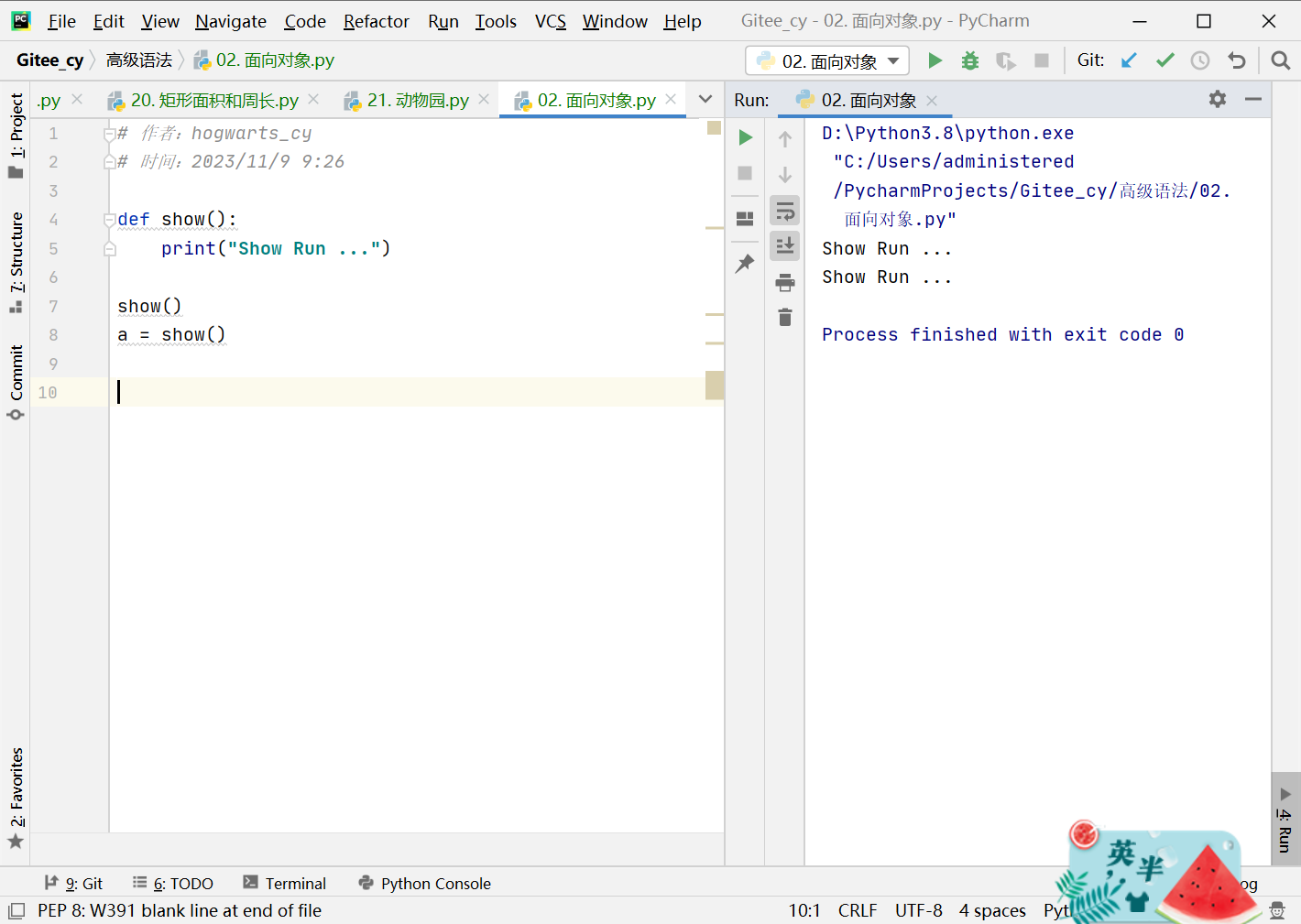
- 注意:在将一个函数名(函数引用)赋值给一个变量时,函数名后不能添加括号。
1.2 闭包
-
闭包(Closure)是指在一个嵌套的函数内部访问其外部函数中定义的变量或函数的能力。换句话说,闭包是一个函数对象,它可以记住并访问它创建时的上下文环境中的变量。
-
闭包通常由两个部分组成:内部函数和与其相关的环境变量。
-
内部函数是在外部函数中定义的函数,它可以访问外部函数中的局部变量和参数,以及外部函数所在的作用域中的变量。
-
环境变量是在外部函数中定义的变量或其他函数对象,它被内部函数引用并记住,即使外部函数执行完成后仍然存在。
-
-
闭包的特点:
-
内部函数可以访问外部函数中定义的变量和参数,即使外部函数已经执行完毕;
-
闭包可以在外部函数的作用域之外被调用和执行;
-
闭包可以访问并修改外部函数中的局部变量,使其具有持久性。
- 闭包的应用场景:
-
保护私有变量:可以使用闭包来创建私有变量和方法,通过内部函数的作用域和环境变量,可以实现对外部访问的限制;
-
延迟执行:可以使用闭包来延迟某个函数的执行,即在函数外部创建一个闭包,将需要执行的函数作为内部函数,通过调用闭包来触发函数的执行;
-
缓存数据:可以使用闭包来缓存一些昂贵的计算结果,以避免重复计算,提高程序的性能。
- 需要注意的是:在使用闭包时,要注意管理内存,避免产生不必要的内存泄露问题。
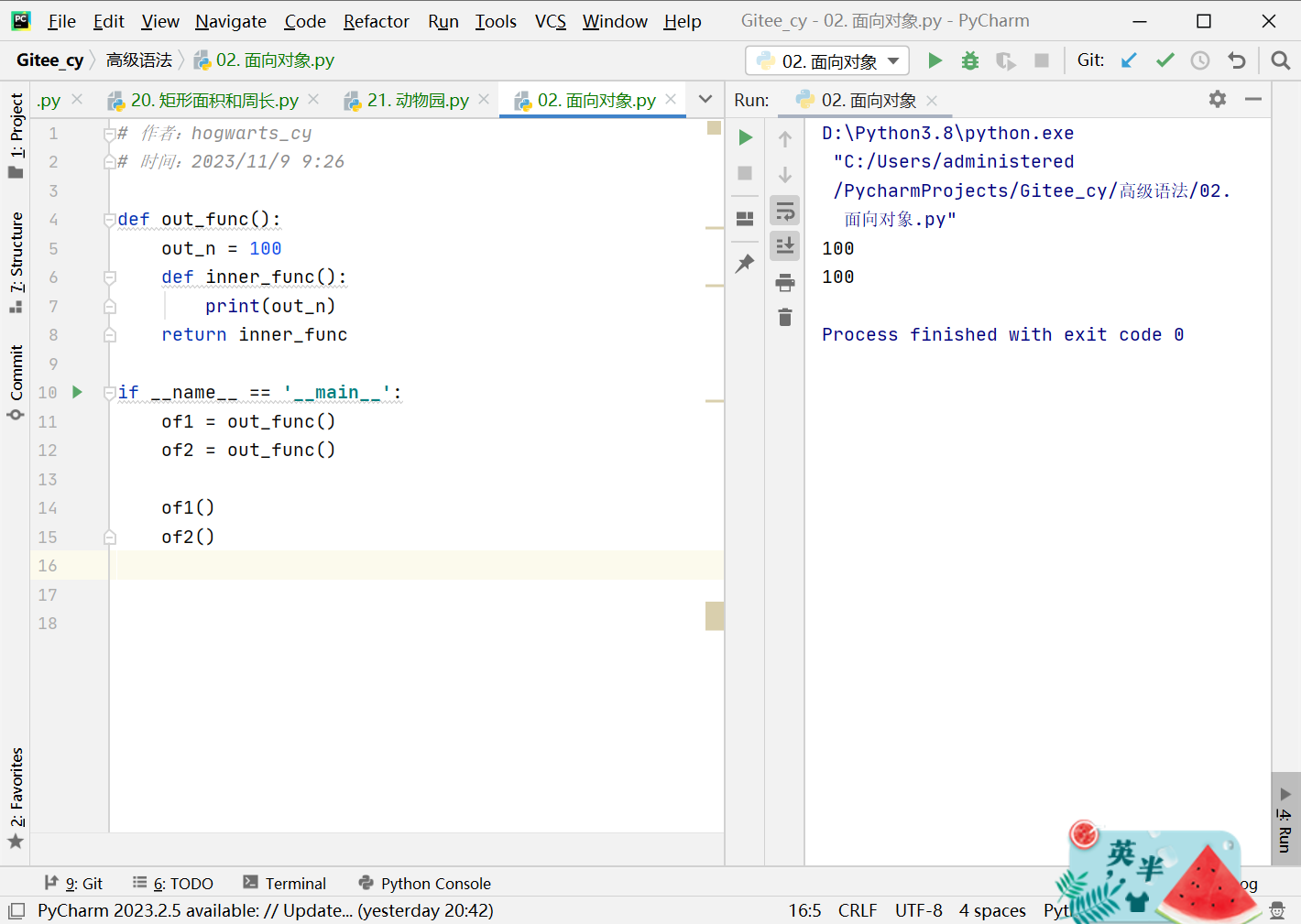
def out_func():
out_n = 100
def inner_func():
print(out_n)
return inner_func
if __name__ == '__main__':
of1 = out_func()
of2 = out_func()
of1()
of2()
nonlocal
- 和全局变量一样,在函数内是不能直接修改函数外的变量的,如果修改全局变量需要使用
global在函数内部声明变量为全局变量。闭包中要修改变量也是一样,内函数是不能直接修改外函数中定义的变量的,如果需要修改,要在内函数中使用nonlocal关键字声明该变量为外函数的变量。
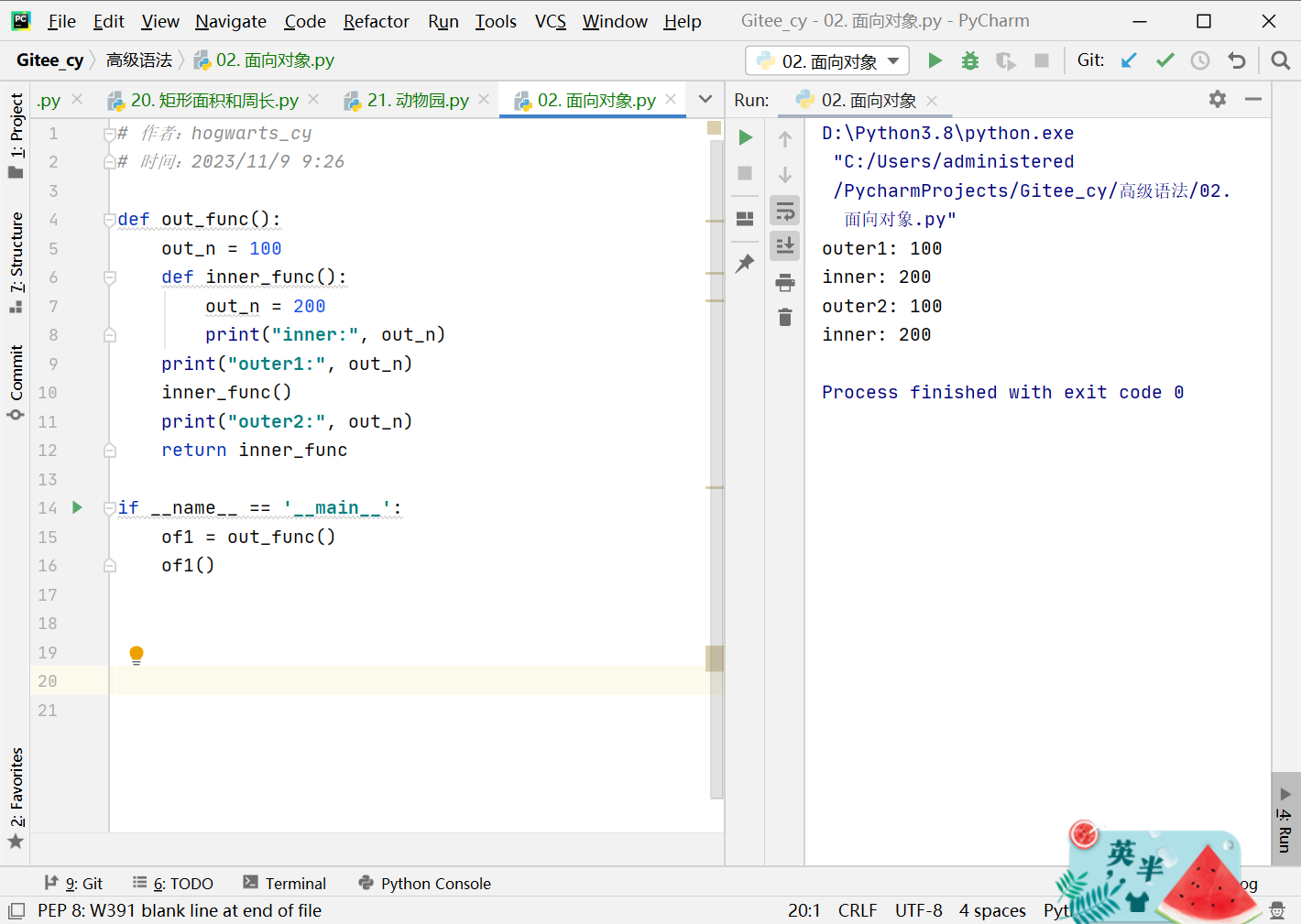
不使用nonlocal修饰
def out_func():
out_n = 100
def inner_func():
out_n = 200
print("inner:", out_n)
print("outer1:", out_n)
inner_func()
print("outer2:", out_n)
return inner_func
if __name__ == '__main__':
of1 = out_func()
of1()
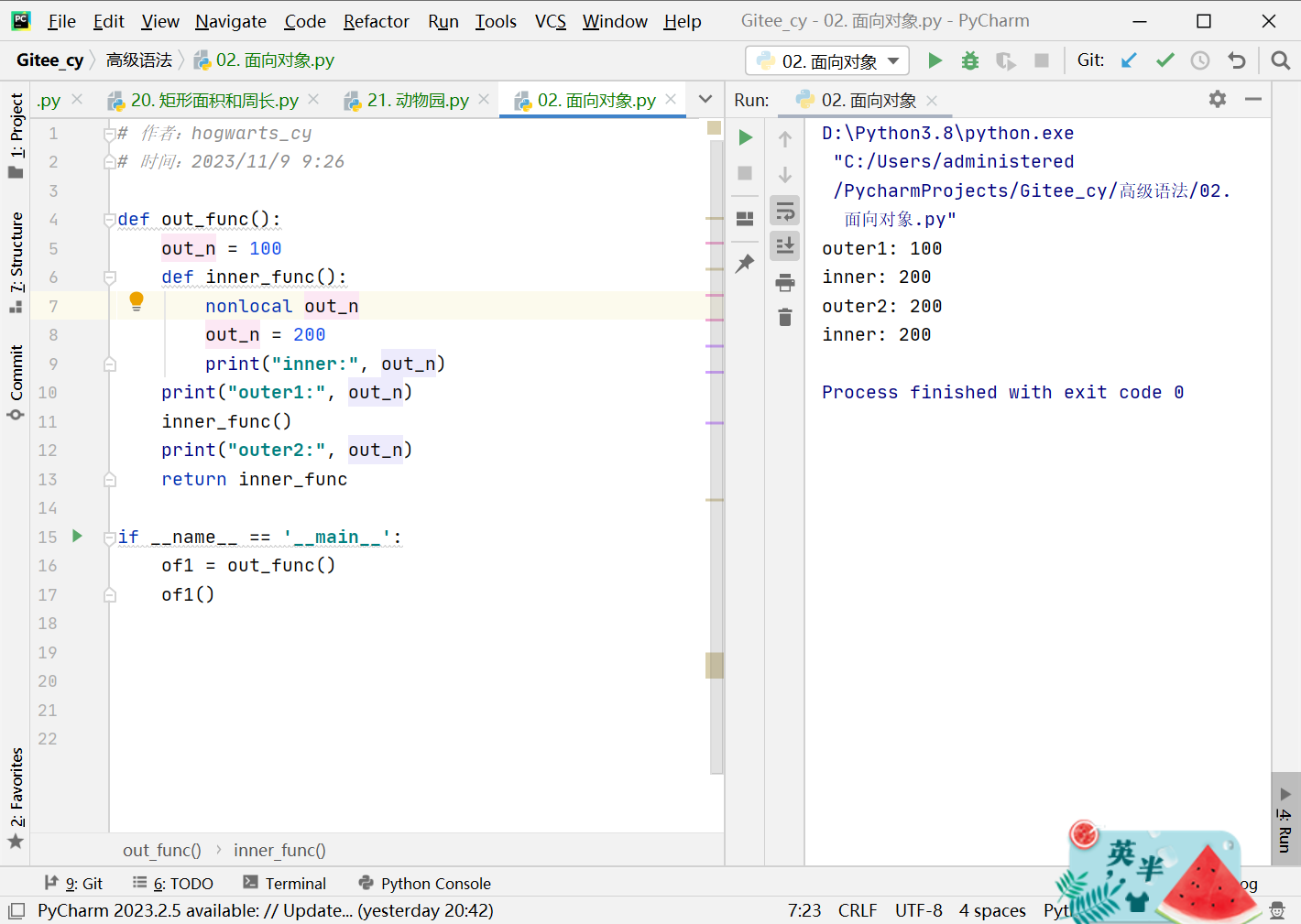
使用nonlocal修饰
def out_func():
out_n = 100
def inner_func():
nonlocal out_n
out_n = 200
print("inner:", out_n)
print("outer1:", out_n)
inner_func()
print("outer2:", out_n)
return inner_func
if __name__ == '__main__':
of1 = out_func()
of1()
1.3 装饰器
-
装饰器是Python提供的一种语法糖,装饰器使用
@符号加上装饰器名称,用于修改其他函数的行为,并且在不修改原始函数定义和调用的情况下,添加额外的功能。 -
装饰器提供一种简洁而优雅的方式,来扩展和修改函数或类的功能。它本质上就是一个闭包函数。
-
装饰器的功能:
-
不修改已有函数的源代码;
-
不修改已有函数的调用方式;
-
给已有函数增加额外的功能。
-
1.3.1 装饰器的使用
-
由于装饰器本质上就是一个闭包函数,所以在使用自定义装饰器之前,需要先定义一个用来作为装饰器的闭包。
-
而闭包的外部函数名,就作为装饰器名使用。
示例:使用闭包实现一个函数执行时间统计的功能。
import time
def count_time(func):
def inner():
start_time = time.time()
func()
stop_time = time.time()
print(f"函数执行时间为{stop_time - start_time}秒")
return inner
@count_time
def show():
for i in range(3):
print(f"第{i+1}次输出")
time.sleep(1)
if __name__ == '__main__':
show()
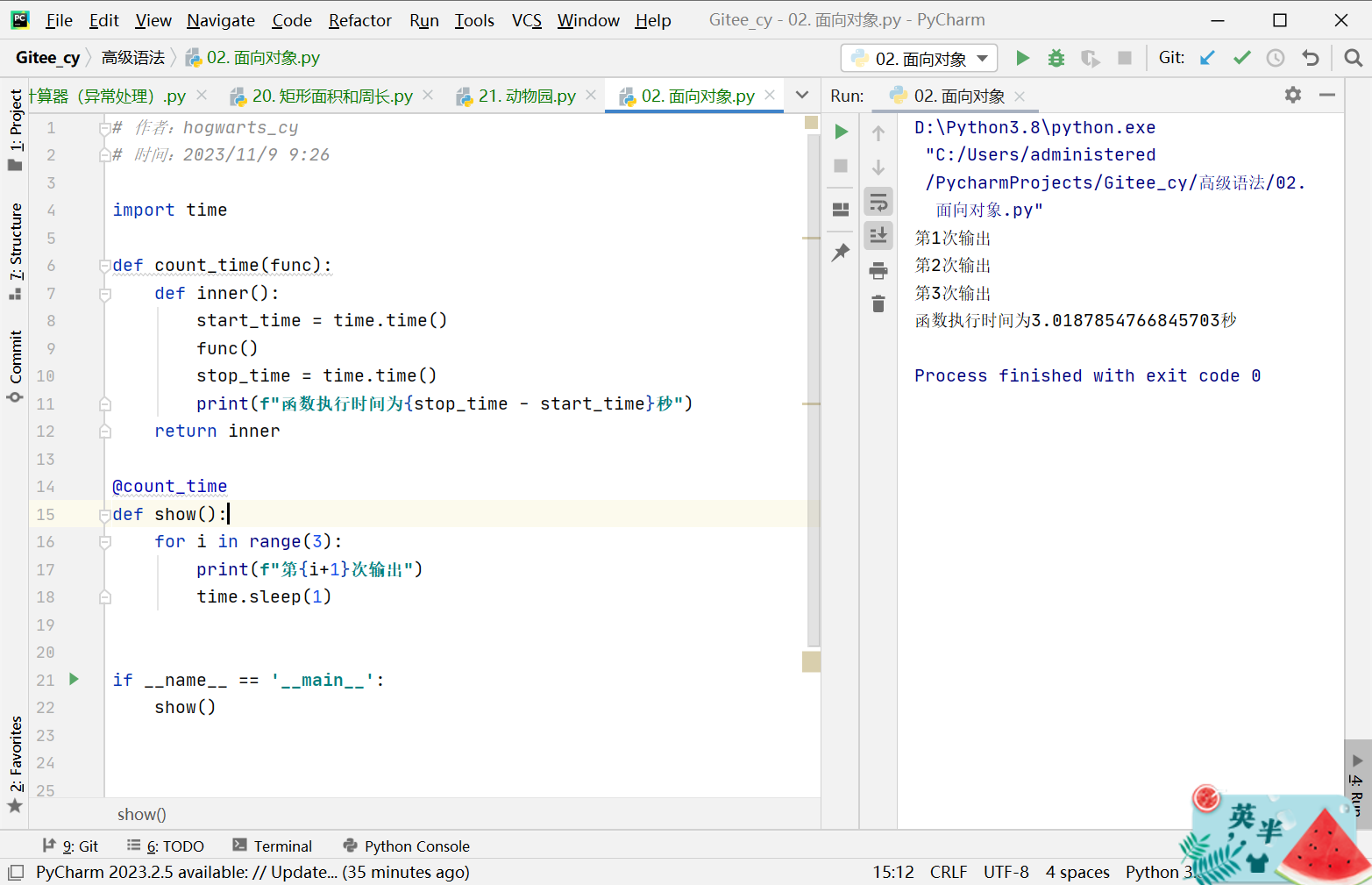
- 从示例中可以看出,在使用count_time函数作为装饰器时,既没有改变show函数的内部定义,也没有改变show函数的调用方式,但却为show函数额外扩展了运行时间统计的功能,这就是装饰器的作用。
1.3.2 装饰器的本质
- 装饰器提供了一种简洁而优雅的方式(语法糖)来扩展和修改函数或类的功能。其本质就是函数的使用。
语法糖:在计算器科学中,语法糖(Syntactic suger)是指一种语法上的扩展,它并不改变编程语言的功能,只是提供了更便捷、更易读的写法,使得代码更加简洁和可理解。
-
常见的语法糖:
- 推导式;
- 装饰器;
- 切片;
- 上下文管理器。
-
python解释器在遇到装饰器时,会将被装饰函数引用作为参数传递给闭包的外函数,外函数执行后,返回内函数的引用,此时,再将内函数引用赋值给被装饰器函数。
-
当python解释器执行完装饰过程后,被装饰函数的函数名就不再保存原函数的引用,而是保存的闭包函数inner的引用。
-
而当执行被装饰函数时,实际执行的是闭包函数inner,由inner间接调用被装饰函数,完成整个调用过程。
@count_time
def show():
pass
python解释器的过程:
show = count_time(show)
1.3.3 通用装饰器
-
理论上,一个装饰器可以装饰任何函数,但实际前面定义的作为装饰器的count_time函数却只能装饰特定的无参无返回值的函数。
-
如果需要装饰器可以装饰任何函数,那就需要解决被装饰函数的参数及返回值的问题。
-
可以通过可变参数和在内函数中返回被装饰函数执行结果的形式,解决此问题。
# 作为装饰器名的外函数,使用参数接收被装饰函数的引用
def decorator(func):
# 内函数的可变参数用来接收被装饰函数使用的参数
def inner(*args, **kwargs):
# 装饰器功能代码
# 调用被装饰函数,并将接收的参数传递给被装饰函数,保存被装饰函数的执行结果
result = func(*args, **kwargs)
# 返回被装饰函数的执行结果
return result
# 返回内函数引用
return inner
1.3.4 带参数装饰器
-
除了普通的装饰器使用方式之外,在使用装饰器时,还需要向装饰器传递一些参数,比如测试框架pytest实现数据驱动时,可以将测试数据以装饰器参数形式传入,此时,前面定义的作为装饰器的闭包形式就不满足需求了。
-
可以在通用装饰器外,再定义一层函数,用来接收装饰器的参数。
实现代码
def decorator_args(vars, datas):
def decorator(func):
def inner(*args, **kwargs):
return func(*args, **kwargs)
return inner
return decorator
data = [(1, 2, 3), (4, 5, 6), (7, 8, 9)]
# 装饰器传参
@decorator_args("a,b,c", data)
def show(a, b, c):
print(a, b, c)
装饰器传参原理
-
装饰器传参的本质就是链式语法的多次函数调用。
-
@decorator_args("a, b, c", data)解析:
- 将执行
@decorator_args("a, b, c", data)部分; - 得到结果
decorator_args与@结合变成装饰器形式@decorator; - 通过结果
@decorator装饰器正常装饰被装饰的函数。
使用装饰器传参,实现数据驱动过程
- 这里没有完整实现代码,只是讲解装饰器形式如何实现数据驱动过程,了解即可。
# 接收装饰器参数的函数
# 参数一:以字符串形式接收被装饰函数的参数列表,需要与被装饰函数的参数名保持一致
# 参数二:以[(),(),()]形式传入驱动数据
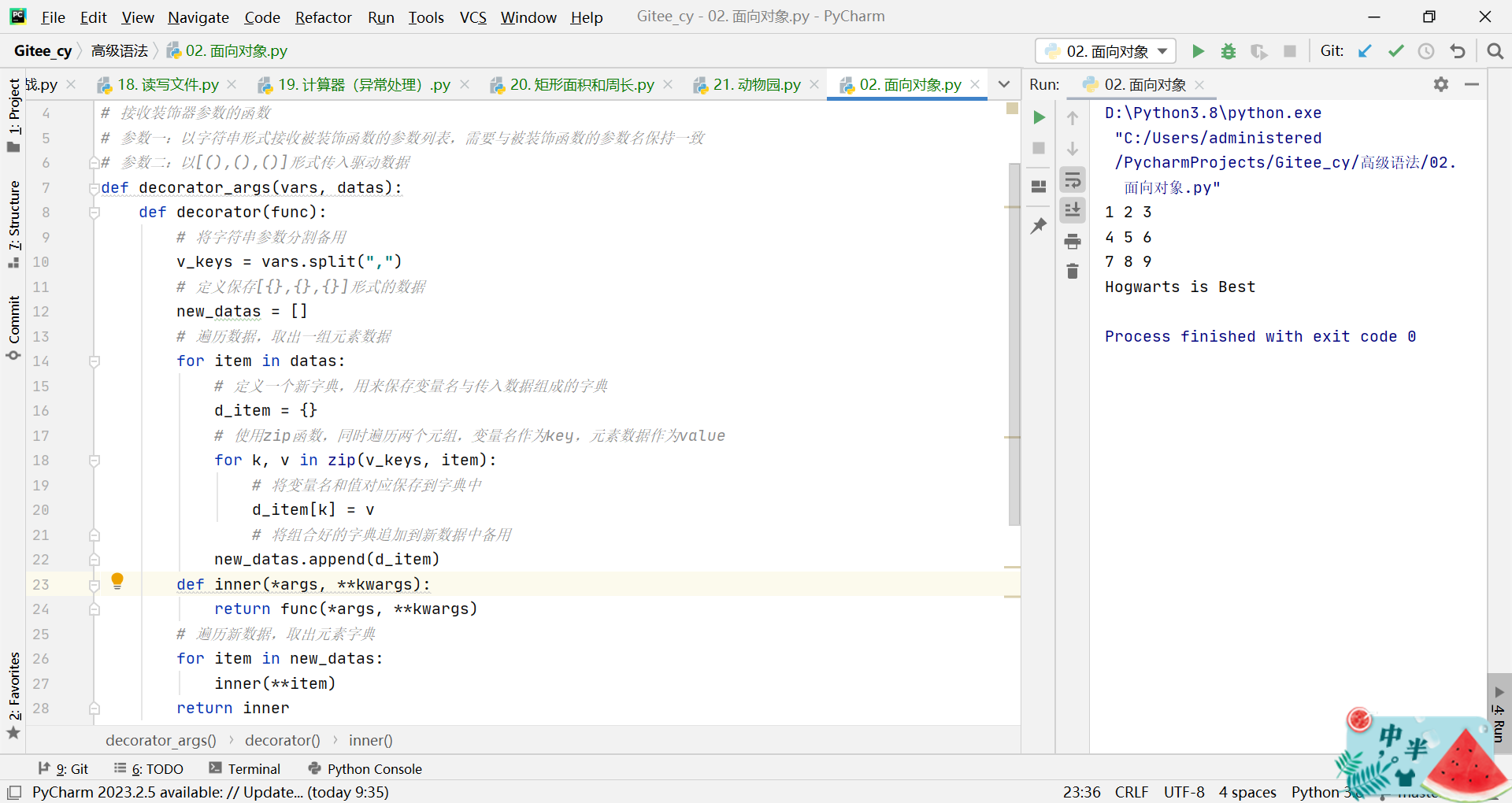
def decorator_args(vars, datas):
def decorator(func):
# 将字符串参数分割备用
v_keys = vars.split(",")
# 定义保存[{},{},{}]形式的数据
new_datas = []
# 遍历数据,取出一组元素数据
for item in datas:
# 定义一个新字典,用来保存变量名与传入数据组成的字典
d_item = {}
# 使用zip函数,同时遍历两个元组,变量名作为key,元素数据作为value
for k, v in zip(v_keys, item):
# 将变量名和值对应保存到字典中
d_item[k] = v
# 将组合好的字典追加到新数据中备用
new_datas.append(d_item)
def inner(*args, **kwargs):
return func(*args, **kwargs)
# 遍历新数据,取出元素字典
for item in new_datas:
inner(**item)
return inner
return decorator
# 传入驱动数据
data = [(1, 2, 3), (4, 5, 6), (7, 8, 9), ("Hogwarts", "is", "Best")]
# 装饰器传参
@decorator_args("a,b,c", data)
def show(a, b, c):
print(a, b, c)
二、文件操作
-
文件操作是每一门编程语言中都必不可少的一项语法,通过文件,可以实现数据持久化存储、测试数据驱动文件的处理、程序配置文件的处理等。
-
在程序中操作文件和使用图形界面操作文件的过程基本一致,都要进行找到文件、打开文件、读写文件、关闭文件等操作。
2.1 打开文件
-
python使用
open方法用于打开一个文件,并返回文件对象。在对文件进行处理的过程,都需要使用到这个函数,如果该文件无法被打开,会抛出OSError错误。 -
完整格式 :
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
- 简化格式:
open(file, mode='r', encoding=None)
- file:必需,指定打开文件的路径(相对或者绝对路径);
- mode:可选,文件打开模式,默认为
r只读模式; - encoding:一般使用
utf8。
mode常见参数:
| 字符 | 含意 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 以只写方式打开文件。如果该文件已存在则覆盖文件。如果该文件不存在则创建新文件。 |
| a | 以追加写入方式打开文件,如果文件存在则在末尾追加,文件不存在则创建新文件 |
| b | 二进制模式 |
| t | 文本模式(默认) |
# 以写入文件打开 index.html 文件
file = open("index.html", "w")
2.2 关闭文件
-
文件在操作完以后,需要将其关闭,
close()方法用于关闭一个已打开的文件。 -
关闭后的文件不能再进行读写操作,否则会触发
ValueError错误。 -
close()方法运行被调用多次。 -
使用
close()方法关闭文件是一个好习惯,需要保持。 -
格式:
fileObject.close()
# 以写入文件打开 index.html 文件
file = open("index.html", "w")
# 关闭文件
file.close()
2.3 写入文件
2.3.1 write()方法
-
write()方法用于向文件中写入指定字符串。如果文件打开模式为b,则要将字符串转换成bytes类型的二进制字符串,函数返回成功写入数据的长度。 -
格式:
fileObject.write( [str] )
# 以写入文件打开 index.html 文件
file = open("index.html", "w")
# 写入数据
file.write("<h1>文件写入标题</h1>")
file.write("\n")
file.write("<p>文件写入内容。。。。。。</p>")
# 关闭文件
file.close()
2.3.2 writelines()方法
-
writelines()方法用于向文件中写入一序列的字符串。 -
这一序列字符串可以是由迭代对象产生的,如一个字符串列表。
-
注意:不要被方法名所迷惑,如果每个元素独占一行,需要在数据后指定换行符
\n。 -
格式:
fileObject.writelines(seq)
datas = ["AAAAAAAAAAAA\n","BBBBBBBBBBBB\n","CCCCCCCCCCCC\n","DDDDDDDDDDDD\n"]
file = open('data.txt',"w")
file.writelines(datas)
file.close()
2.4 读取文件
2.4.1 read()方法
-
read()方法用于从文件读取指定的字节数,如果未给定或为负则读取所有。
*格式:fileObject.read([size=-1])
file = open('data.txt',"r")
# 读取10个字符
content = file.read(10)
print(content)
# 读取所有内容
content = file.read()
print(content)
file.close()
2.4.2 readline()方法
-
readline()方法用于从文件读取整行,包括\n字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括\n字符。 -
格式:
fileObject.readline(size=-1)
file = open('data.txt',"r")
# 读取10个字符
content = file.readline(10)
print(content)
# 读取文件指针所在行剩余所有内容
content = file.readline()
print(content)
file.close()
2.4.3 readlines()方法
-
readlines()方法用于读取所有行(直到结束符 EOF)并返回列表。 -
格式:
fileObject.readlines()
file = open('data.txt',"r")
# 以行为单位读取文件所有的内容
contents = file.readlines()
print(contents)
file.close()
三、错误分析与调试
3.1 调试与分析
-
程序出现错误把那个中断结束后,出现报错信息的错误都是不可怕的,大多是语法性的错误,通过错误提示信息,就可以快速定位和解决错误。
-
错误分析:
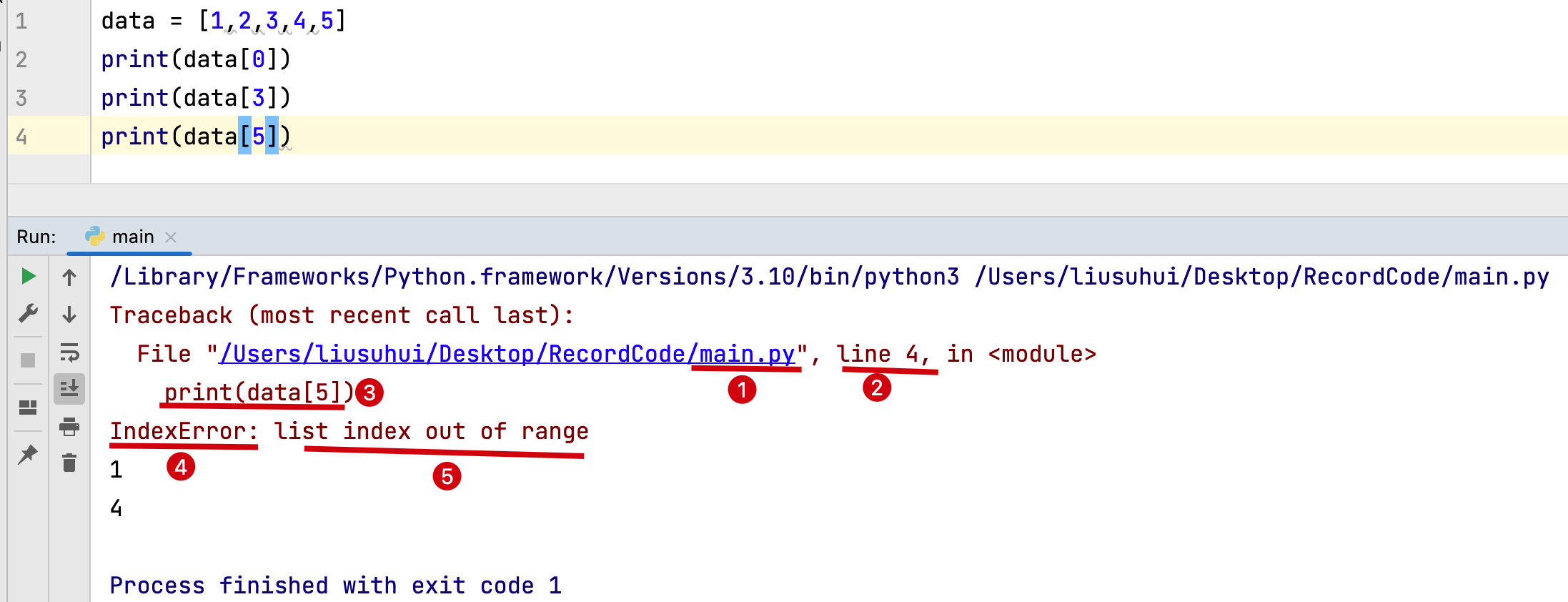
- 错误所在的文件;
- 错误所在的行;
- 错误出现的代码;
- 错误类型;
- 错误原因描述。
-
有时候通过报错信息,并不能直接定位出错误,要通过报错信息,及程序的上下文逻辑来分析真正的报错信息。
-
在上面的错误中,共提示了两处报错位置,分别是12行和7行,这是代码追踪提示。
-
但真正的错误并不在这里,通过错误原因描述发现,是在执行range()函数时,并不能将字符串类型的参数解释成一个数字。
-
从代码实现逻辑上看,
output函数并没有任何问题,结合上下文的代码逻辑发现,问题出在getInputData函数中的数据获取,从键盘输入的所有内容都是以字符串形式保存到程序变量中,程序要求获得一个数字,那么在键盘输入后,应该使用强制类型转换,将输入数据转换成数字。
n = input("请输入一个数字:")修改为n = int(input("请输入一个数字:"))
3.2 print信息调试
-
很多人由于英文不太好,在查看报错信息时很吃力,也可以通过
print()函数,自行输出信息来定位错误位置,虽然这种方式可以解决问题,但还是要慢慢学习,掌握如何查看报错提示。 -
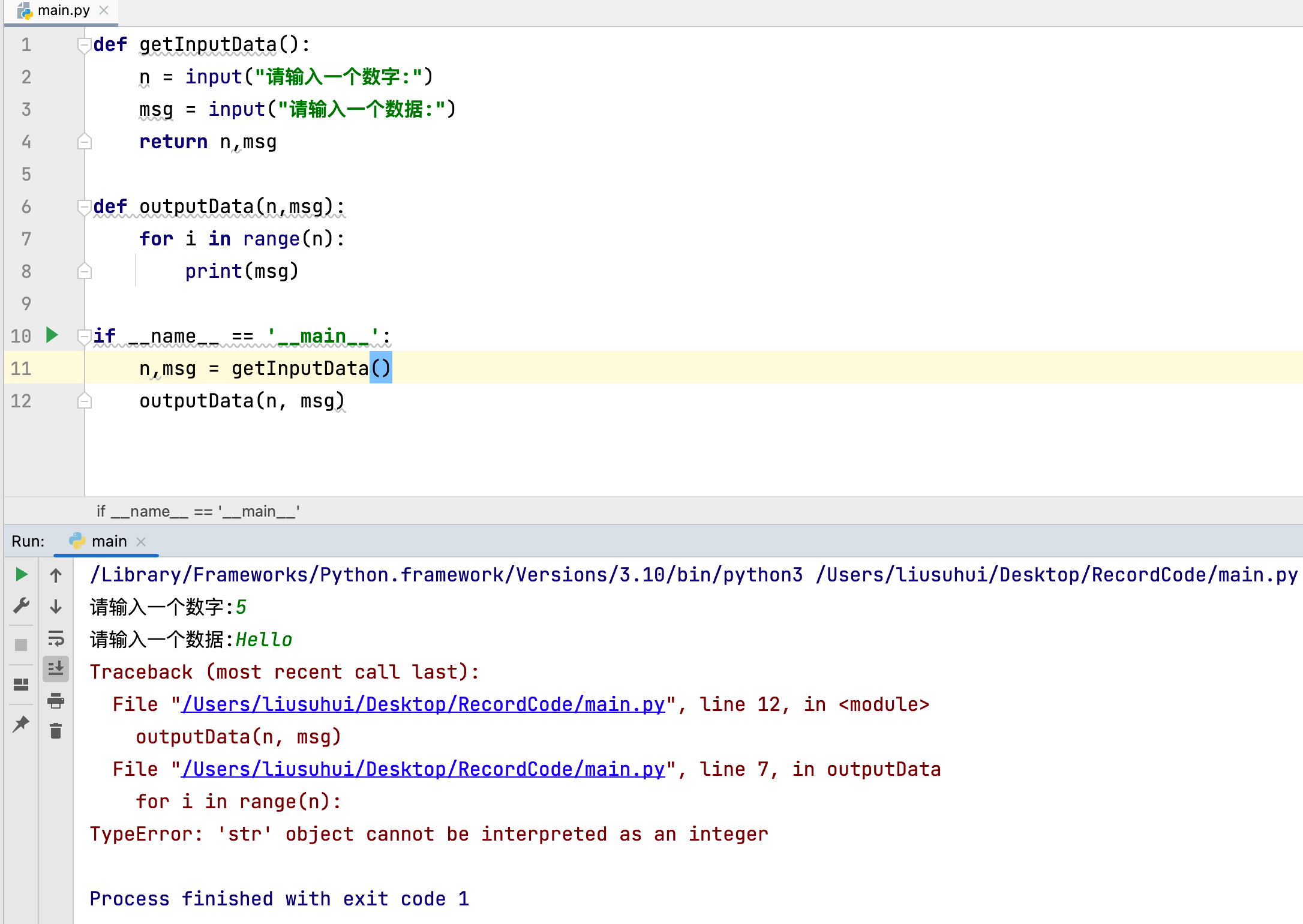
示例代码:
def getInputData():
print("input run")
n = input("请输入一个数字:")
msg = input("请输入一个数据:")
return n,msg
def outputData(n,msg):
print("output run")
for i in range(n):
print("output forin run")
print(msg)
if __name__ == '__main__':
n,msg = getInputData()
outputData(n, msg)
- 运行结果:
input run
请输入一个数字:1
请输入一个数据:1
output run
Traceback (most recent call last):
File "/Users/liusuhui/Desktop/RecordCode/main.py", line 15, in <module>
outputData(n, msg)
File "/Users/liusuhui/Desktop/RecordCode/main.py", line 9, in outputData
for i in range(n):
TypeError: 'str' object cannot be interpreted as an integer
Process finished with exit code 1
-
在示例代码中,加入了三条
print()语句,用来输出一些信息,通过运行结果可以看出,input run和output run都被正常输出,而output forin run没有输出,说明程序在输出该语句之前出现错误,此时就可以通过检查语法信息,上下文逻辑等来判断具体错误原因。 -
print()语句在调试代码时,两条语句之间包含多少代码,视具体情况而定。不是必须在每条语句前后都加print()输出,在错误调试完成后,需要把输出注释或删除掉。
3.3 debug调试
-
除了前面两种方式外,还可以通过 PyCharm 的
debug功能来调试程序,通过debug功能,还可以监控程序的执行过程。 -
在使用debug功能时,需要配合程序断点来进行调试。

3.3.1 程序断点
-
使用 PyCharm 编写代码时,可以在行号后通过点击添加删除断点。
-
断点的作用是在debug调试程序时,遇到断点程序就会暂停执行,通过点击控制按钮,控制程序向下执行。

3.3.2 调试控制
- 程序打好断点后,点击debug即可进入debug模式,程序遇到断点就会暂停执行,此时就需要通过控制按钮来控制程序的执行。

横向按钮
-
Step Over: 步过按钮,将函数做为一条语句执行,不进入函数内部执行。 -
Step Into: 单步执行,会进入到函数内部逐条执行代码。 -
Step Into My Code: 单步执行,只进入自定义函数内部,不会进入系统函数内部。 -
Step Out: 步出按钮,跳出当前函数体,返回到此函数调用位置 -
Run to Cursor: 运行到光标处,当调试程序时,如果某一行没有打断点,又想暂停,可以将光标移动到目标行,点击该按钮 -
Evaluate Expression: 评估表达式,高级用法,可以在调试过程中查看程序的中间过程,比如查看参数 n 的类型。
竖向按钮
-
Rerun main: 重新运行 debug 功能 -
Modify Run Configuration: 修改运行配置 -
Resume Program: 继续执行,运行到下一断点处,如果没有,程序运行结束 -
Stop main: 停止 Debug -
View Breakpoints: 显示程序中所有的断点。 -
Mute Breakpoints: 让所有断点失效,使用后所有断点为灰色,debug时,代码不会在断点处暂停。 -
Pin Tab: 钉住当前调试窗口标签,防止关闭。
四、异常处理
-
编写程序时,即使语句或表达式使用了正确的语法,执行时仍可能触发错误。执行时检测到的错误称为异常,大多数异常不会被程序处理,程序会中断运行,并抛出异常信息。
-
如果不想发生异常时,程序被中断执行,可以编写程序处理选定的异常。
4.1 try-except
-
Python 使用
try/except语句捕捉异常。 -
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。 -
如果你不想在异常发生时结束你的程序,只需在try里捕获它。
file = open("data.txt","r")
try:
# 写入数据时可能会有问题
file.write("写入的数据")
except IOError as err:
print("文件不能写入", err)
file.close()
4.2 捕捉多个异常
-
如果一段代码可能会发生多种异常,并想在程序中都想处理,可以使用多个
except分别捕捉异常。 -
可以捕捉
Exception异常类型来处理所有的异常,如果有多个时,必须放在最后捕捉该异常,否则无法处理到其它异常。
file = open("data.txt","r")
try:
# 写入数据时可能会有问题
# file.write("写入的数据")
# print(a)
# print(3 / 0)
# print([][10])
print("hello" + 100)
except IOError as err:
print("文件不能写入", err)
except NameError:
print("标识符没有定义")
except ZeroDivisionError:
print("除数不能为0")
except IndexError:
print("下标越界了")
except Exception:
print("程序运行出错,请检查代码")
file.close()
4.3 else 操作
- Python 使用
else在处理在代码无异常时的后续操作。
try:
n = input("请输入一个数字:")
num = int(n)
except Exception:
print("元素无法转换为数字")
else:
print("转换后成功",num)
4.4 finally 操作
- Python 使用
finally处理无论异常是否发异,都要执行的代码,一般用来完成清理工作。
try:
file = open("data.txt","r")
# file.write("A")
except Exception:
print("文件操作报错")
finally:
print("文件已关闭")
file.close()
