目录
- xpath 基本概念
- xpath 使用场景
- xpath 语法与实战
xpath基本概念
- XPath 是一门在 XML 文档中查找信息的语言
- XPath 使用路径表达式在 XML 文档中进行导航
- XPath 的应用非常广泛
- XPath 可以应用在UI自动化测试
xpath 定位场景
- web自动化测试
- app自动化测试

xpath 相对定位的优点
- 可维护性更强
- 语法更加简洁
- 相比于css可以支持更多的方式
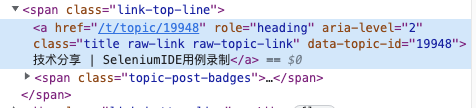
复制的绝对定位
$x(‘//*[@id=“ember75”]/td[1]/span/a’)
编写的相对行为
$x(“//*[text()=‘技术分享 | SeleniumIDE用例录制’]”)
xpath 定位的调试方法
- 浏览器-console
$x("xpath表达式")
- 浏览器-elements
- ctrl+f 输入xpath或者css
xpath 基础语法(包含关系)
| 表达式 | 结果 |
|---|---|
| / | 从该节点的子元素选取 |
| // | 从该节点的子孙元素选取 |
| * | 通配符 |
| nodename | 选取此节点的所有子节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
|  |
整个页面
$x(“/”)
页面中的所有的子元素
$x(“/*”)
整个页面中的所有元素
$x(“//*”)
查找页面上面所有的div标签节点
$x(“//div”)
查找id属性为site-logo的节点
$x(‘//*[@id=“site-logo”]’)
查找节点的父节点
$x(‘//*[@id=“site-logo”]/…’)
xpath 顺序关系(索引)
- xpath通过索引直接获取对应元素
获取此节点下的所有的li元素
$x(“//*[@id=‘ember21’]//li”)
获取此节点下【所有的节点的】第一个li元素
$x(“//*[@id=‘ember21’]//li[1]”)
xpath 高级用法
-
[last()]: 选取最后一个 -
[@属性名='属性值' and @属性名='属性值']: 与关系 -
[@属性名='属性值' or @属性名='属性值']: 或关系 -
[text()='文本信息']: 根据文本信息定位 -
[contains(text(),'文本信息')]: 根据文本信息包含定位 - 注意:所有的表达式需要和
[]结合
选取最后一个input标签
//input[last()]
选取属性name的值为passward并且属性pwd的值为123456的input标签
//input[@name=‘passward’ and @pwd=‘123456’]
选取属性name的值为passward或属性pwd的值为123456的input标签
//input[@name=‘passward’ or @pwd=‘123456’]
选取所有文本信息为’霍格沃兹测试开发’的元素
//*[text()=‘霍格沃兹测试开发’]
选取所有文本信息包’霍格沃兹’的元素
//*[contains(text(),‘霍格沃兹’)]
xpath 高级语法总结
- 基本语法
- 索引
- 高级用法
