性能测试流程:
- 1 分析现状
- 2 获取当前性能指标
- 3 定义用户场景
- 4 定义性能验收标准
- 5 测试计划/脚本
- 6 准备压力环境
- 7 执行压测
- 8 监控
- 9 搜集分析
- 10 测试报告
- 11 改进建议
- 12 持续测试
性能测试方法
- 并发模式(虚拟用户模式)
并发是指虚拟并发用户数,从业务角度,也可以理解未同时在线的用户数。如果需要从客户端的角度出发,摸底业务系统各节点能同时承载的在线用户数,可以使用该模式设置目标并发。 - RPS模式(吞吐量模式)
RPS(Requests Per Second)是指每秒请求数。RPS模式即“吞吐量模式”,通过设置每秒发出的请求数,从服务端的角度出发,直接衡量系统的吞吐能力,免去并发到RPS的繁琐转化,一步到位。
性能测试计划
-
需求分析与测试设计
-
环境设计与搭建
1.设计: 根据需求,结合线上机器部署情况,搭建线下测试环境,要求具有一定的参考价值,一般同比1/2,1/4
2.环境搭建:(1)起压环境:压测工具的安装与调试、机器参数记录;(2)被压环境:基础服务的搭建、web机代码部署及代码改造、机器参数记录
3.环境调试:查看接口是否正常 -
测试数据准备
-
性能指标预期设定
1.每秒请求数(QPS)
2.请求响应时间(最小、最大、平均)
3.错误率
4.机器性能: cpu idle 45%、memory无剧烈抖动或者飙升
5.压测过程中接口功能是否正常 -
发压工具配置及脚本编写
-
测试执行&监控
-
测试报告
性能测试报告
- 1、背景&方案
- 2、实际环境
- 3、压测过程
- 4、总结&建议
性能测试报告内容
性能测试场景
- 1、负载测试(Load Test): 负载测试是一种性能测试,指数据在超负荷环境中运行,程序是否能够承担。
- 2、压力测试(Stress Test): 压力测试(又叫强度测试)也是一种性能测试,它在系统资源特别低的场景下软件系统运行情况,目的是找到系统在哪里失效以及如何失效的地方。
- 3、极限测试(Extreme Testing): 在过量用户下的负载测试Hammer testing:连续执行所有能做的操作
- 4、容量测试(Volume Test):确定系统可处理同时在线的最大用户数。通常和数据库有关,容量和负载的区别在于: 容量关注的是大容量,而不需要关注使用中的实际表现。
性能测试概念
- 并发是指虚拟并发用户数,从业务角度,也可以理解为同时在线的用户数。并行技术上提升压力的方式:
1、多进程: 启动多个进程,每个进程虽然只有一个线程,但是多个进程可以一起执行多个任务
2、多线程: 启动一个进程,在一个进程的内部启动多个线程,这样多个线程也可以一起执行多个任务
3、多进程+多线程: 启动多个进程,每个进程再启动多个线程
| 维度 | 多进程 | 多线程 | 优劣 |
|---|---|---|---|
| 数据共享、同步 | 数据是分开的;共享复杂、需要用IPC;同步简单 | 多线程共享进程数据;共享简单;同步复杂 | 各有优势 |
| 内存、CPU | 占用内存多,切换复杂,CPU利用率低 | 占用内存少,切换简单,CPU利用率搞 | 线程占优 |
| 创建销毁、切换 | 创建销毁、切换复杂,速度慢 | 创建销毁、切换简单,速度快 | 线程占优 |
| 编程调试 | 编程简单,调试简单 | 编程复杂,调试复杂 | 进程占优 |
| 可靠性 | 进程间不会相互影响 | 一个线程挂掉将导致整个进程挂掉 | 进程占优 |
| 分布式 | 适应于多喝、多机分布;如果一台机器不够,拓展到多台机器比较简单 | 适应于多核分布 | 进程占优 |
- TPS(Transaction per Second): 系统每秒处理交易数,单位是笔/秒。
- QPS(Query per Second): 系统每秒处理查询次数,单位是次/秒。对于互联网业务中,如果某些业务有且仅有一个请求连接,那么TPS=QPS,一般情况下用TPS来衡量整个业务流程,用QPS来衡量接口查询次数。
==并发数=QPS*平均响应时间==
性能分析系统级别指标
- io指标及监控命令iostat: 监控系统设备的IO负载情况
- io指标监控命令df -h: 列出文件系统的整体磁盘空间使用情况
- cpu指标
- uptime → 用于显示系统总共运行了多长时间和系统的平均负载
- cat /proc/cpuinfo → 查看cpu配置信息
- mpstat -P ALL → 是一款常用的多核CPU性能分析工具,用来实时查询每个cpu的性能指标,以及所有cpu的平均指标
- sar -u 1 1 → 是一个Linux下的监控工具,可以用来监控cpu性能状况
- mem(内存)指标
- cat /proc/meminfo → 查看内存相关配置信息
- vmstat → 用来获得有关进程、内存、虚拟内存、页面交换空间及cpu活动的信息
- free, free -g → 显示系统使用和空闲内存情况,包括屋里内存、交互区内存(swap) 和内存缓冲区内存
- network指标
- ping → 向目标系统发送报文,检测网络连通性的工具
- ifconfig → 用于获取网卡配置与网络状态等信息
- hostname → 显示本机的hostname,修改本机的hostname
- netstat -altup → 用于显示各种网络相关信息,如网络连接,路由表,接口状态等
top 命令
- 命令描述: 实时的显示系统中各个进程的资源占用情况
- 统计信息: 前五行是系统的整体统计信息
- 进程信息: 统计信息下方类似表格的区域显示的是进程的详细信息,默认5秒刷新一次
ps 命令
- 命令描述: ps命令是Process Status的缩写,linux下最常用的进程查看命令;
- 可以配合管道命令 | 和查找命令 grep 同时执行来查看特定进程
- 可以配合管道命令 | 和文本分析命令 awk 同时执行来定位具体进程参数值
- 命令演示:
- ps
- ps -aux
- ps -ef
- ps ef |grep |awk
nmon命令
- 是一种可以在 AIX 与 Linux 操作系统上使用的性能监控与分析工具
- 下载位置:http://nmon.sourceforge.net , 从 Binaries 中下载可执行程序包
- 监控与结果分析:
- 启动nmon后台监控程序
- 命令: nmon -f -t -s 10 -c 10 -m <nmon 数据保存路径>
- -f 监控结果以文件形式输出, 默认: 机器名_日期_时间
- -F 指定输出文件名
- -t 显示资源占用率高的进程
- -s 采样频率,单位秒
- -c 采样次数
- -m nmon数据文件保存的目录
- 图形化分析工具下载位置: nmon and njmon | Site / Nmon-Analyser
- 用 Excel 打开,需要启用宏
- 在 Analyser 文件中打开性能监控数据文件 *.nmon 浏览图形化性能分析报告
基本性能监控系统使用
- 组成: Collectd + InfluxdDB + Grafana:
- Collectd 是一个守护(daemon)进程,用来定期收集系统和应用程序的性能指标,同时提供了以不同的方式来存储这些指标值的机制;
- InfluxDB 开源的、高性能的时序型数据库
- Grafana 一个非常酷的数据可视化平台,常常应用于显示监控数据,支持多种数据源
- 环境搭建
-
准备数据文件 types.db collectd.conf:
> docker create --name temporary mwaeckerlin/collectd > docker cp temporary:/usr/share/collectd/types.db types.db > docker cp temporary:/etc/collectd/collectd.conf collectd.conf > sudo mkdir -p /Users/chenqiang/docker/collectd > sudo mv -i types.db /Users/chenqiang/docker/collectd/types.db > sudo mv -i collectd.conf /Users/chenqiang/docker/collectd/collectd.conf > docker rm temporary -
启动 InfluxDB
docker run -d \ --name influxdb \ -p 8086:8086 \ -p 8083:8083 \ -e INFLUXDB_COLLECTD_ENABLED=true \ -e INFLUXDB_COLLECTD_DATABASE=_internal \ -e INFLUXDB_COLLECTD_TYPESDB=/usr/share/collectd/types.db \ -e INFLUXDB_COLLECTD_SECURITY_LEVEL=none \ -v /Users/chenqiang/docker/collectd/types.db:/usr/share/collectd/types.db \ influxdb:1.8 -
启动 grafana: 默认用户名/密码 → admin/admin
docker run -d \ --name=grafana \ -p 3000:3000 \ -v /Users/chenqiang/docker/grafana:/var/lib/grafana \ --link influxdb:influxdb grafana/grafana -
启动 collectd
docker run -d \ --name collectd \ --hostname localhost \ --link influxdb:influxdb \ -v /Users/chenqiang/docker/collectd/collectd.conf:/etc/collectd/collectd.conf \ mwaeckerlin/collectd -
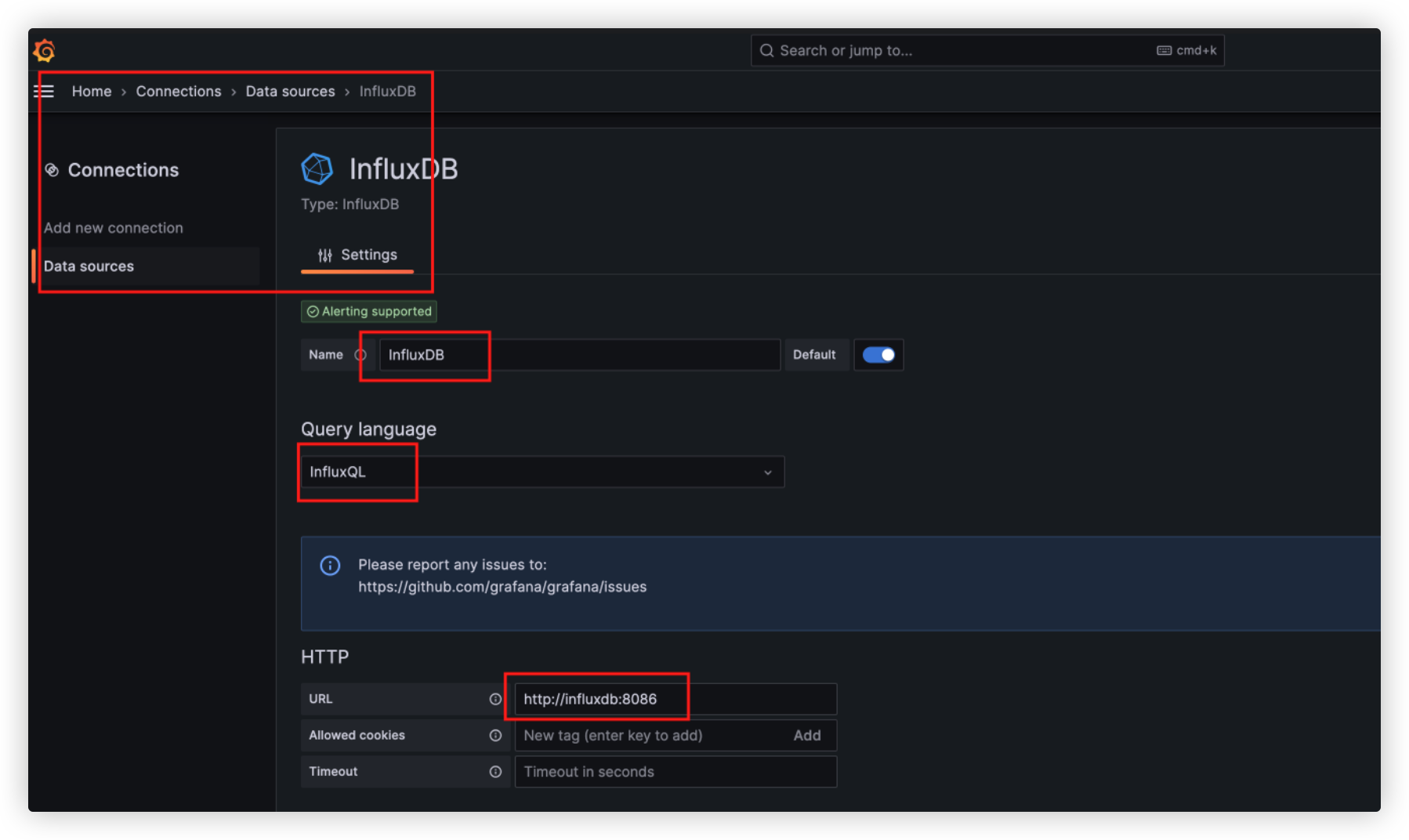
Grafana中配置数据源
- 打开URL :http://localhost:3000/
- 类型: InfluxDB
- URL: http://influxdb:8086
- DataBase: _internal
-
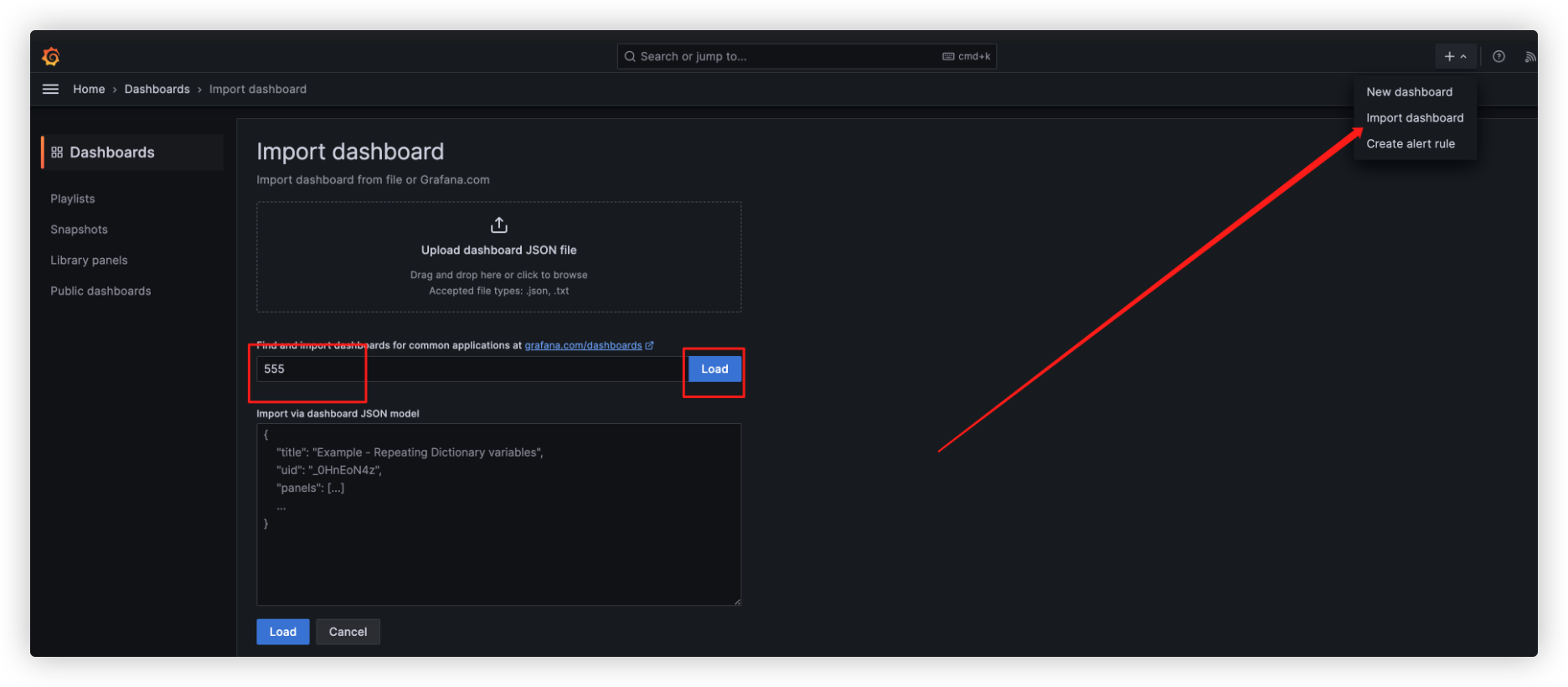
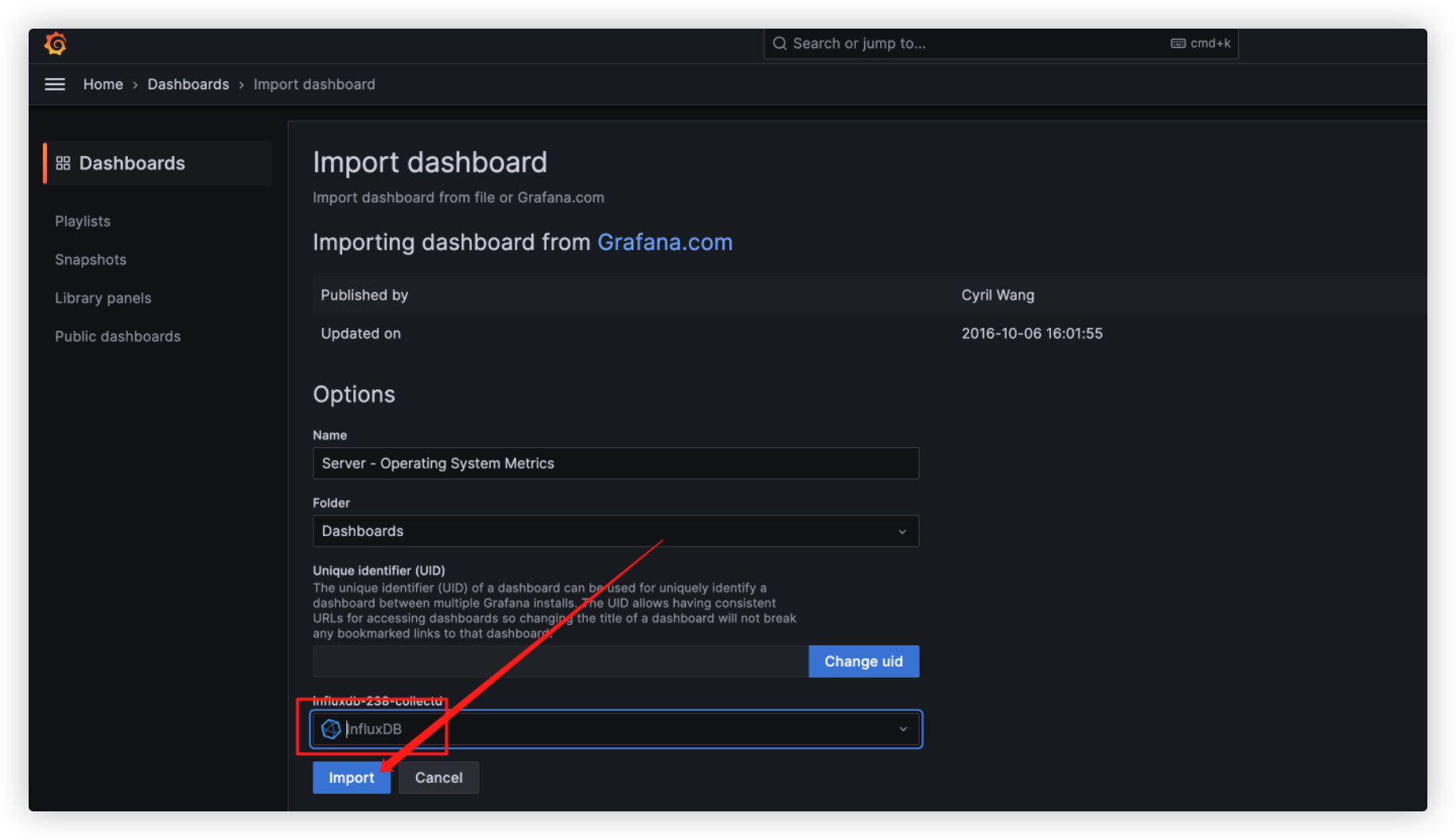
- Grafana 中配置Dashboard: Import id 555
- 系统使用
-
collectd编辑各项指标,获取指标对应的InfluxDB字段eg:uptime → uptime_value
-
vi collectd.conf: 搜索uptime 启用对应的监控选项
-
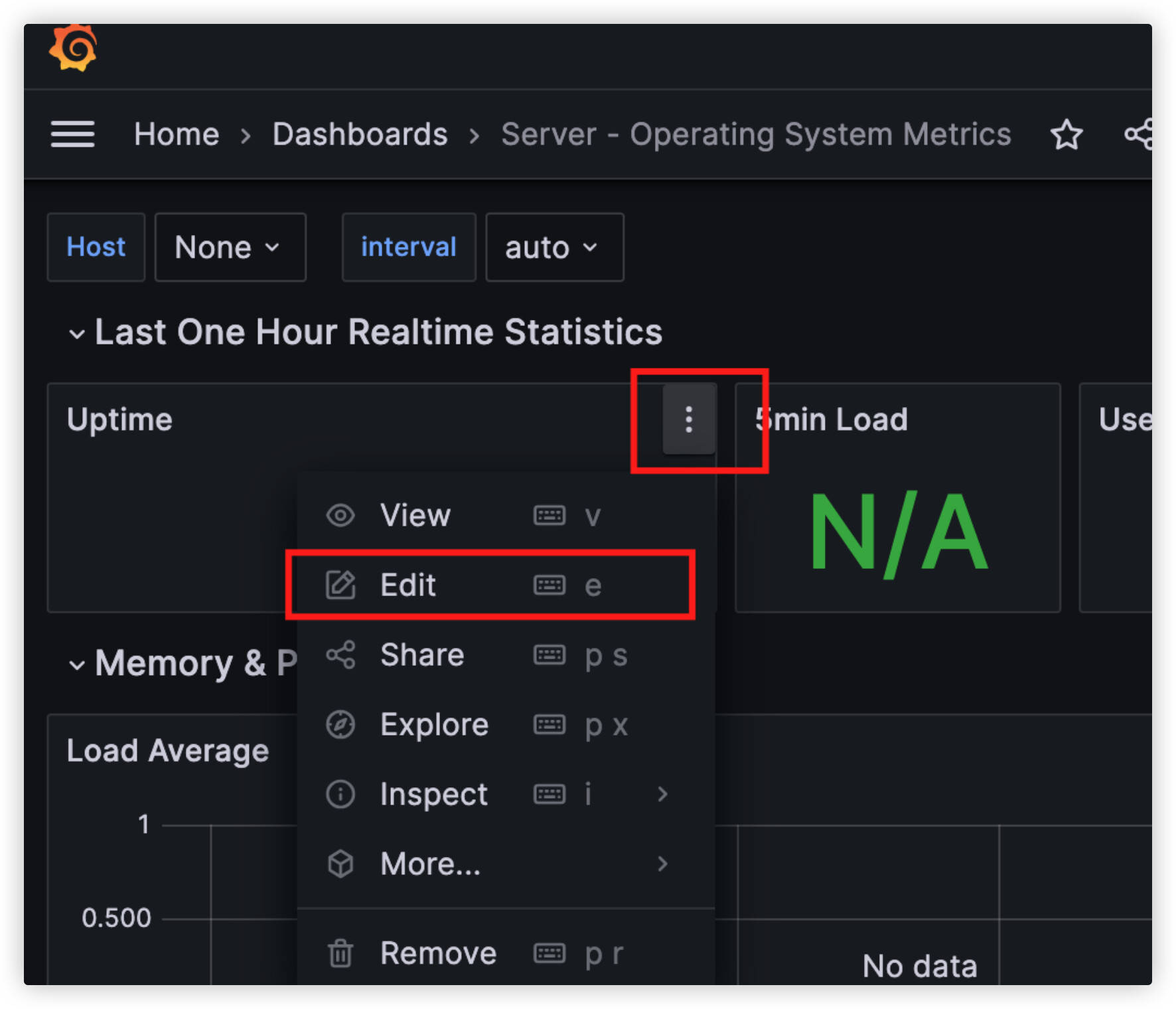
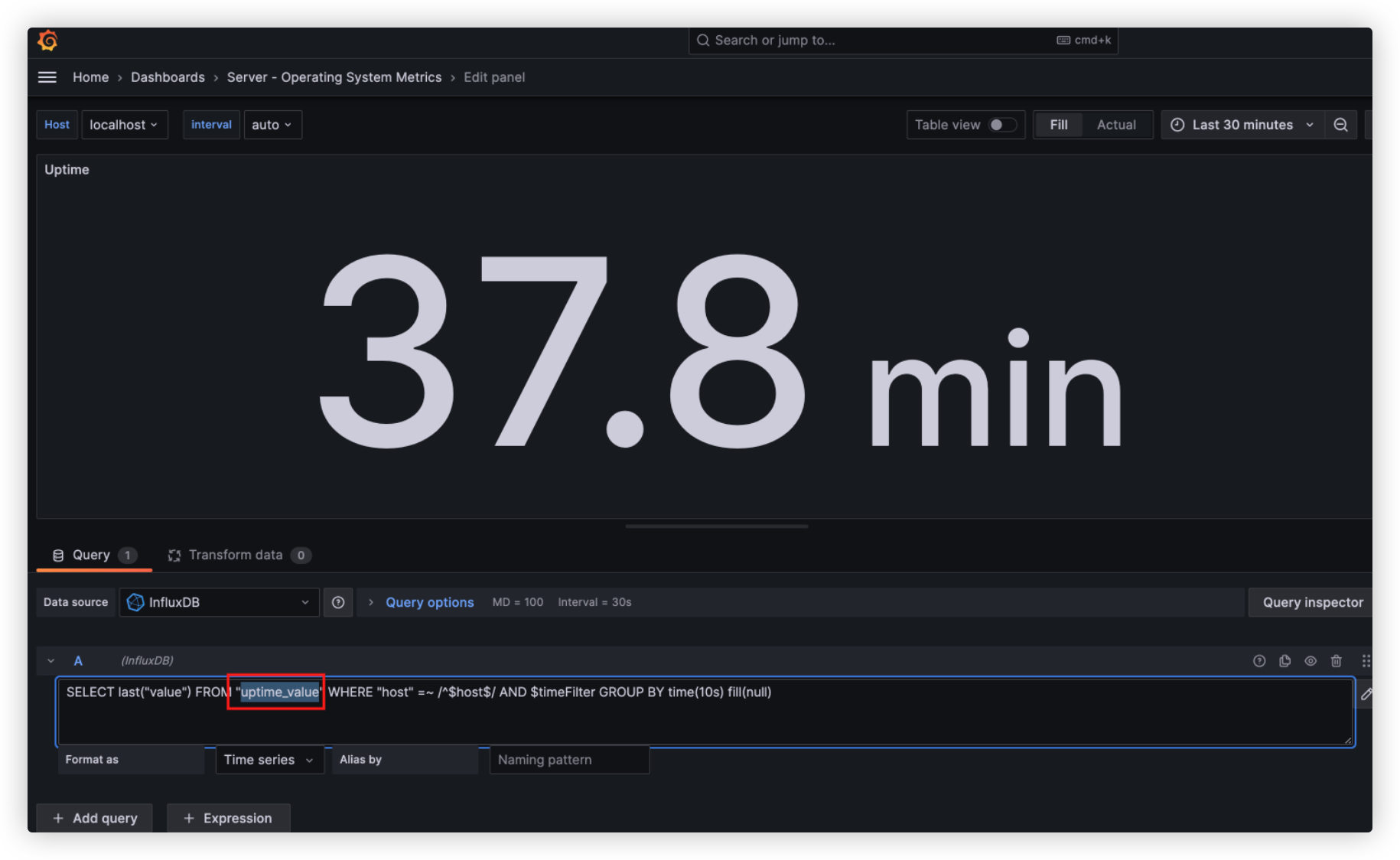
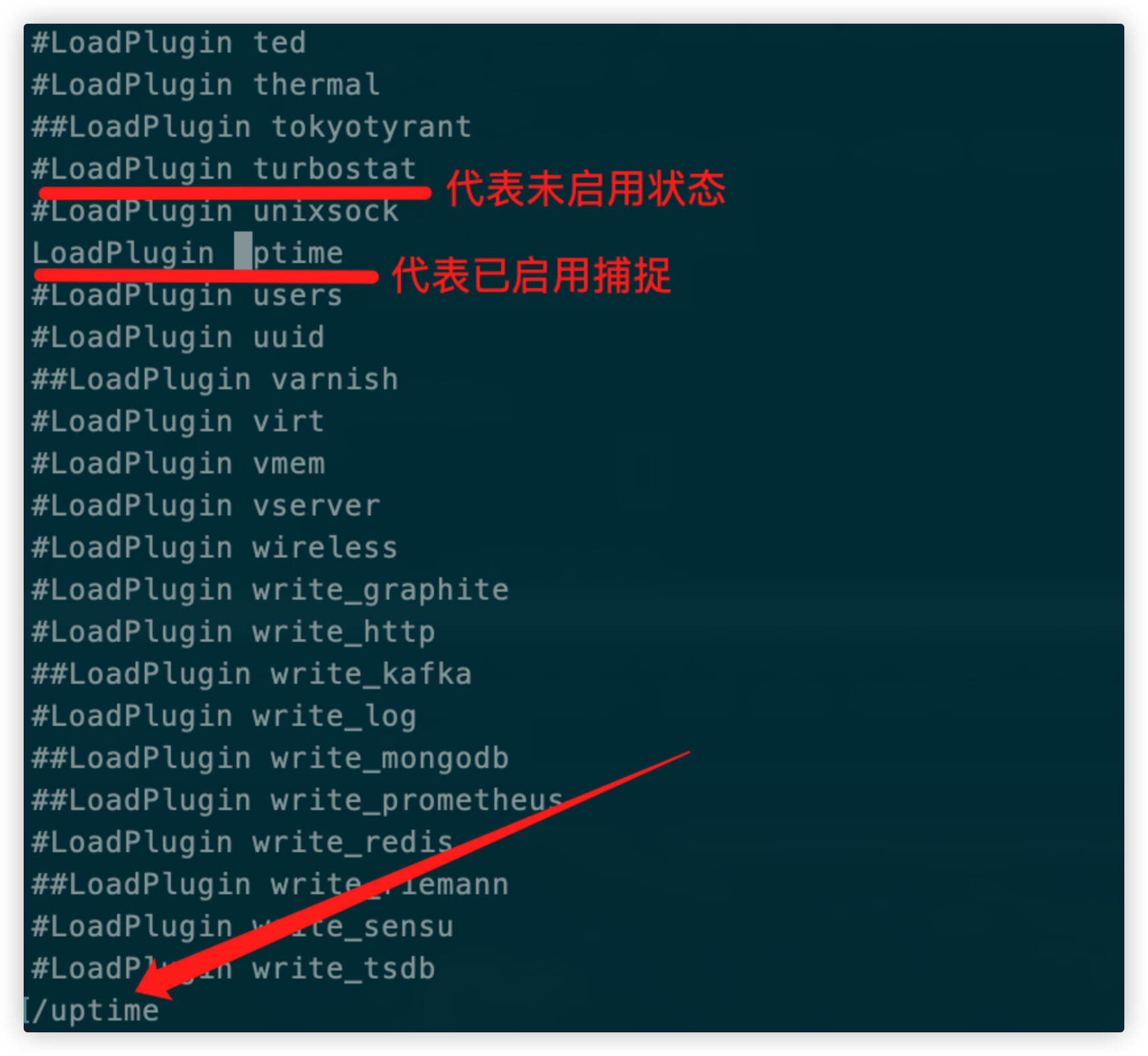
- 重启collectd: docker restart collectd
