Python语言高级
Python的多进程/多线程/多协程:多任务编程(concurrent.futures这个库同时提供了:多线程池ThreadPoolExecutor,一个是多进程池:ProcessPoolExecutor。 Python广为使用的并发处理库futures使用入门与内部原理_concurrent库-CSDN博客)
-
进程与线程的概念:进程是操作系统分配的最小单元,线程时操作系统调度的最小单元;一个应用程序最少包含一个进程(开辟一块内存空间),一个进程可以包含多个线程(多个线程共享这个进程的内存空间,但是:一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存,这就是所说的线程安全问题,共享资源时,需要考虑线程安全)。 一文看懂Python多进程与多线程编程 | 大江狗的博客 (pythondjango.cn)
-
多进程、多线程、多协程
- 多线程是最常见的一种多任务编程技术,它可以在同一个程序内同时运行多个线程,每个线程负责执行不同的任务。多线程编程能够充分利用多核心处理器的性能优势,提高程序的并发能力。然而,多线程编程需要注意线程安全问题,比如访问共享资源时需要使用锁来保证数据的一致性。
- 另一种常见的多任务编程技术是多进程编程,它可以在操作系统级别同时运行多个独立的进程。每个进程拥有独立的内存空间和资源,可以实现更高的隔离性。
- 另外,协程也是一种轻量级的多任务编程技术,它可以在同一个线程中实现多个任务的切换和调度。协程通过yield语句和生成器函数实现任务的暂停积恢复,避免了线程切换的开销并减少了锁的使用。协程常用于异步编程场景,比如网络编程和I0密集型任务。
总结起来,多任务编程是一种提高程序并发能力和效率的编程技术,可以通过多线程、多进程或协程等方式实现。在选择多任务编程技术时,需要根据实际需求和情况综合考虑各种因素,比如性能、并发性、开发难度和可维护性等。(一个进程可以有多个线程,一个线程可以有多个协程)
-
多进程multiprocessing库:
- Process:用Process()来创建子进程。此方法接收2个参数:target,args,前置传递需要执行的函数名字,后者传函数需要传入的参数
- 用Process()创建子进程,多进程执行任务示例:
from multiprocessing import Process import time import os def long_time_task(): print('当前进程id: {}'.format(os.getpid())) time.sleep(2) print("结果: {}".format(8 ** 20)) if __name__ == '__main__': print(f"当前母进程{os.getpid()}") # 这是母进程 start = time.time() p1 = Process(target=long_time_task) # 这是子进程1 p2 = Process(target=long_time_task) # 这是子进程2 p1.start() p2.start() p1.join() # 让母进程阻塞,等待子进程执行完毕 p2.join() # 让母进程阻塞,等待子进程表执行完毕 end = time.time() print("用时{}秒".format((end - start))) - 用进程池创建进程Pool():
import os import time from multiprocessing import cpu_count,Queue,Manager,Pool, Process def long_time_task(): print('当前进程id: {}'.format(os.getpid())) time.sleep(2) print("结果: {}".format(8 ** 20)) if __name__ == '__main__': start = time.time() p = Pool(4) # 创建线程池容器,池子大小:4 for i in range(3): p.apply_async(long_time_task) # 添加执行的任务 p.close() # 调用join()之前必须先调用close()或terminate()方法,让其不再接受新的Process了。 p.join() # 对Pool对象调用join()方法会等待所有子进程执行完毕; end = time.time() print("总共用时{}秒".format((end - start))) - 多进程间的数据共享:进程之间是相互独立的,每个进程都有独立的内存。通过共享内存(nmap模块),进程之间可以共享对象,使多个进程可以访问同一个变量(地址相同,变量名可能不同)。多进程共享资源必然会导致进程间相互竞争,所以应该尽最大可能防止使用共享状态。还有一种方式就是使用队列queue来实现不同进程间的通信或数据共享,这一点和多线程编程类似。
- 大大
- Process:用Process()来创建子进程。此方法接收2个参数:target,args,前置传递需要执行的函数名字,后者传函数需要传入的参数
-
多线程threading库: 一文吃透python多线程(全面总结)_python 获取线程id_Ethan-running的博客-CSDN博客
- 多线程执行任务
from threading import Lock, Thread def long_time_task(): print('当前进程id: {}'.format(os.getpid())) print("当前线程id:{}".format(threading.current_thread().ident)) # 获取当前线程id time.sleep(2) print("结果: {}".format(8 ** 20)) if __name__ == '__main__': start = time.time() t1 = Thread(target=long_time_task) # 创建线程1 t2 = Thread(target=long_time_task) # 创建线程2 t1.start() t2.start() t1.join() t2.join() end = time.time() print("总共用时{}秒".format((end - start))) - 利用线程池管理线程的创建与销毁:concurrent.futures模块中的ThreadPoolExecutor创建线程池
python queue 线程池_mob64ca12e2f123的技术博客_51CTO博客 - 继承Thread类重写的run方法
class MyTheard(threading.Thread): def __init__(self): # 这里可以穿参数进来,比如需要执行的任务的名字,在run中调用执行 super().__init__() def run(self): # 调用start()的时候会自动调用run函数 print('当前进程id: {}'.format(os.getpid())) print("当前线程id:{}".format(threading.current_thread().ident)) # 获取当前线程id time.sleep(2) print("结果: {}".format(8 ** 20)) if __name__ == '__main__': start = time.time() t1 = MyTheard() t2 = MyTheard() t1.start() t2.start() t1.join() t2.join() end = time.time() print("总共用时{}秒".format((end - start))) - 线程守护
- Thread类中有deamon的属性,设置了这个属性执行,当主线程结束后,子线程无所谓结束不结束都会跟着主线程结束。(ps:这个属性需要在start()方法之前调用。否则会报错)此属性默认为False
- join():设置子线程join()后,主线程会阻塞等待子线程完成,再执行join后面的代码
- threading.enumerate():列表形式返回所有存活的Thread对象
- 线程锁:Lock、死锁、Rlock
- 为什么线程有线程锁的概念:
- 一个进程可以产生多个线程,多个线程可以对共享的数据操作,如果某个线程要更改共享数据时,别的线程也再操作共享数据,会导致共享数据同时被操作导致数据不对。锁的作用:在线程更改共享数据时,先将此线程的操作数据锁住,此时资源处于锁定状态,操作完毕后,将资源解锁,此资源处于非锁定状态,其他的资源才能再次锁定该资源。这就保证了每次只有一个线程对资源进行操作,从而保证了多线程数据情况下数据的正确性。(有点同步的意思)
- Lock锁:
def func1(): global n for i in range(1000000): # 那些资源共享,就给操作资源的地方上锁 lock.acquire() # 上锁 n += 1 lock.release() # 释放锁 def func2(): global n for i in range(1000000): lock.acquire() # 上锁 n -= 1 lock.release() # 释放锁 if __name__ == '__main__': start = time.time() t1 = Thread(target=func1) # 创建线程1 t2 = Thread(target=func2) # 创建线程2 t1.start() t2.start() t1.join() t2.join() end = time.time() print("操作n后的值:", n) print("总共用时{}秒".format((end - start))) - 死锁:
- Rlock锁:为了解决死锁的情况,就有了递归锁:Rlock
- 为什么线程有线程锁的概念:
- 线程间的数据共享,线程通信
- Condition:也可以认为是一把锁,比Lock和Rlock更高级。在其内部维护了一个锁对象,在创建Condigtion对象的时候把锁作为参数传入
- acquire(): 上线程锁、
- release(): 释放锁、
- wait(timeout): 线程挂起,直到收到一个notify通知或者超时(可选的,浮点数,单位是秒s)才会被唤醒继续运行。wait()必须在已获得Lock前提下才能调用,否则会触发RuntimeError
- notify(n=1): 通知其他线程,那些挂起的线程接到这个通知之后会开始运行,默认是通知一个正等待该condition的线程,最多则唤醒n个等待的线程。notify()必须在已获得Lock前提下才能调用,否则会触发RuntimeError。notify()不会主动释放Lock
- notifyAll(): 如果wait状态线程比较多,notifyAll的作用就是通知所有线程
- 示例
num = 0 # 生产着 def product(con: threading.Condition): global num con.acquire() print("工厂开始生产") while True: num += 1 print(f"已生产数量{num}") time.sleep(1) if num >= 5: print("仓库已满,停止生产") con.notify() con.wait() con.release() def consumer(con): con.acquire() global num print("开始消费") while True: num -= 1 print(f"仓库剩余{num}") time.sleep(2) if num <= 0: print("仓库变空,开始生产") con.notify() con.wait() con.release() if __name__ == '__main__': con = threading.Condition() t1 = Thread(target=product, args=(con,)) t2 = Thread(target=consumer, args=(con,)) t1.start() t2.start() t1.join() t2.join()
- Condition:也可以认为是一把锁,比Lock和Rlock更高级。在其内部维护了一个锁对象,在创建Condigtion对象的时候把锁作为参数传入
- 使用queue队列通信,进行数据共享通信
- 常用的方法:
- qsize():返回队列的规模
- empty():如果队列是空的,返回True,不是空的返回Flase
- full():如果队列满了,返回True,不满Flase
- get(block,timeout):获取队列,timeout等待时间
- get_nowait():取出不等待
- put(item,[,timeout]):放进队列,timeout等待时间,如果队列满了再调这个方法会阻塞线程
- put_nowait():放入不等待
- task_done():完成一项工作的时候,task_done()函数像任务已完成的队列发送一个信号
- join():等队列为空之后,再执行别的操作
- 用Queue队列实现生产者与消费者:
def product(con: threading.Condition, que: Queue): con.acquire() print("工厂开始生产") while True: que.put(1) print(f"生产了:{que.qsize()}") time.sleep(1) if que.qsize() == 10: con.notify() con.wait() con.release() def consumer(con: threading.Condition, que: Queue): con.acquire() print("开始消费") while True: que.get() time.sleep(2) print(f"消费剩余:{que.qsize()}") if que.qsize() == 2: con.notify() con.wait() con.release() if __name__ == '__main__': con = threading.Condition() que = queue.Queue() t1 = Thread(target=product, args=(con,que)) t2 = Thread(target=consumer, args=(con,que)) t1.start() t2.start() t1.join() t2.join()
- 常用的方法:
- 多线程执行任务
-
多协程gevent库:这是一个第三方库,需要pip安装
-
在3.10版本以后python提供了异步编程的库:asyncio
-
协程是单线程的,没法利用cpu的多核,想利用cpu的多核可以通过:进程+协程/进程+线程+协程的方式。进程和线程都是通过cpu的调度实现不同任务的有序执行,
而协程是由用户程序自己控制调度的,没有线程的切换开销,所以执行效率极高 -
实现方式:
- yield关键字实现协程(利用生产器来实现函数的挂起/恢复)
import time def producer(): while True: time.sleep(1) print("生产了1个包子", time.strftime("%X")) yield # 这里相当于阻塞住了 def consumer(): while True: next(prd) print("消费了1个包子", time.strftime("%X")) # 执行完这里之后回到producer函数里继续执行 if __name__ == '__main__': prd = producer() consumer()-
greenlet模块(需pip安装):如果有上百个任务之前需要切换,那用yield生成器的方式实现就太鸡肋,而greenlet模块可以轻松的实现很多个任务之前进行切换(需要人显性的去切换任务)
- 此模块中通过switch()可以切换到指定的协程,可以更简单的进行切换任务
from greenlet import greenlet def producer(): while True: time.sleep(1) print("生产了1个包子", time.strftime("%X")) g2.switch() def consumer(): while True: print("消费了1个包子", time.strftime("%X")) # 执行完这里之后回到producer函数里继续执行 g1.switch() if __name__ == '__main__': g1 = greenlet(producer) g2 = greenlet(consumer) g1.switch() -
gevent模块(需pip安装) 【Python 协程详解】_python 携程-CSDN博客
- greenlet模块实现了协程并且可以很方便的切换任务但是仍需要人工去切换,而不是自动的进行任务的切换,当一个任务执行时如果遇到IO就会阻塞,没有解决IO阻塞自动切换的问题。gevent模块是对greenlet的再次封装,不用程序员自己变成切换(注意:gevent只有遇到耗时的操作才会切换协程运行,没有耗时的操作不会主动切换)
- gevent模块识别耗时的两种方式:1、使用gevent模块中重写类:gevent.socket gevent.sleep 2、打补丁的方式,所有的代码from gevent import monkey 导入这个模块,moneky.patch_all()调用这个方法。(后者是给程序打补丁的方式,这样就可以不用改写源码)
-
import gevent import time from gevent import monkey monkey.patch_all() def work1(): for i in range(5): print("work1开始执行...", gevent.getcurrent()) time.sleep(0.5) def work2(): for i in range(5): print("work2开始执行...", gevent.getcurrent()) time.sleep(0.5) if __name__ == '__main__': g1 = gevent.spawn(work1) g2 = gevent.spawn(work2) g1.join() g2.join() - 当开启的协程很多的时候,一个个的调用join方法就有点麻烦,所以gevent提供了一个方法joinall(),可以一次join所有的协程。joinall() 方法传参一个列表,列表包含了所有的协程。gevent.joinall([gevent.spawn(producer, “zhangsan”), gevent.spawn(consumer, “lisi”)])
-
高版本的python内置了:asyncio库来实现异步协程。由于是内置的会比第三方库来实现性能更优
- 此库引入新的语法:async和await
- 其中async关键字用来声明一个函数为异步函数,异步函数的特点是能在函数执行过程中挂起,去执行其他的异步函数,等到挂起条件消失后再回来继续执行。
- await关键字用来实现异步挂起,。比如某一异步任务执行到某一步时需要较长时间的耗时操作,就将此挂起,去执行其他的异步程序。(注意:await后面只能跟异步程序或者__await__属性的对象)
- 示例:
- 此库引入新的语法:async和await
-
import asyncio
async def work1(): # 声明异步函数
for i in range(5):
print("work1开始执行...", gevent.getcurrent())
await asyncio.sleep(0.5) # 耗时操作,挂起
async def work2():
for i in range(5):
print("work2开始执行...", gevent.getcurrent())
await asyncio.sleep(0.5) # 耗时操作,挂起
if __name__ == '__main__':
loop = asyncio.get_event_loop() # 创建事件循环
task = [asyncio.ensure_future(work1()), asyncio.ensure_future(work2())] # 创建任务列表
loop.run_until_complete(asyncio.wait(task)) # 将你任务注册到事件中
loop.close()
Python的网络编程 【精选】Python – 网络编程_python网络编程-CSDN博客
- ip地址:用来找唯一主机的,用来指引数据包的收发方向
- 端口:端口只有整数,范围从0-65535.动态端口是:1024-65535.
- 端口的作用:IP地址+端口来区分不同的进程服务。
- socket概念:
- 所谓进程指的是:运行的程序以及运行时用到的资源这个整体称之为进程
- 所谓进程间通信指的是:运行的程序之间的数据共享
- 什么是socket:
- socket(简称:套接字):是进程间的一种通信方式。它与其他进程间通信的一个不同是:它能实现不同主机间的进程间通信,网络上各种各样的服务大多都是基于socket来完成通信的。
- Python中的socket模块的函数socket
- 创建socket:socket.socket(AddressFamily, Type):AddressFamily–可以选择AF_INET(用于Internet进程间通信)、AF_UNIX(用于同一台机器进程间通信);Type:套接字类型,可以是:SOCK_STREAM(流式套接字,主要用于TCP协议)、SOCK_DGRAM(数据报套接字,主要用于UDP协议)
-
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 这是创建了一个:Internet进程间通信,tcp协议 s_u = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 这是创建了一个:Internet进程间通信,udp协议 s.close() # 关闭套接字 - 套接字的使用流程和文件的使用流程类似:
- 1、创建套接字 2、使用套接字收/发数据 3、关闭套接字
- UDP:
import socket # s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 这是创建了一个:Internet进程间通信,tcp协议 s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 这是创建了一个:Internet进程间通信,udp协议 data = input("请输入内容:") # 输入内容 addr = ("127.0.0.1", 8011) # 发送数据的IP地址,与端口 s.sendto(data.encode("gbk"), addr) # 发送 recv_data = s.recvfrom(1024) # 接收发送的数据 print(recv_data) print(recv_data[0].decode("gbk")) # 第一个值数数据 print(recv_data[1]) # 第二个值是端口号 s.close() # 关闭套接字 - TCP:
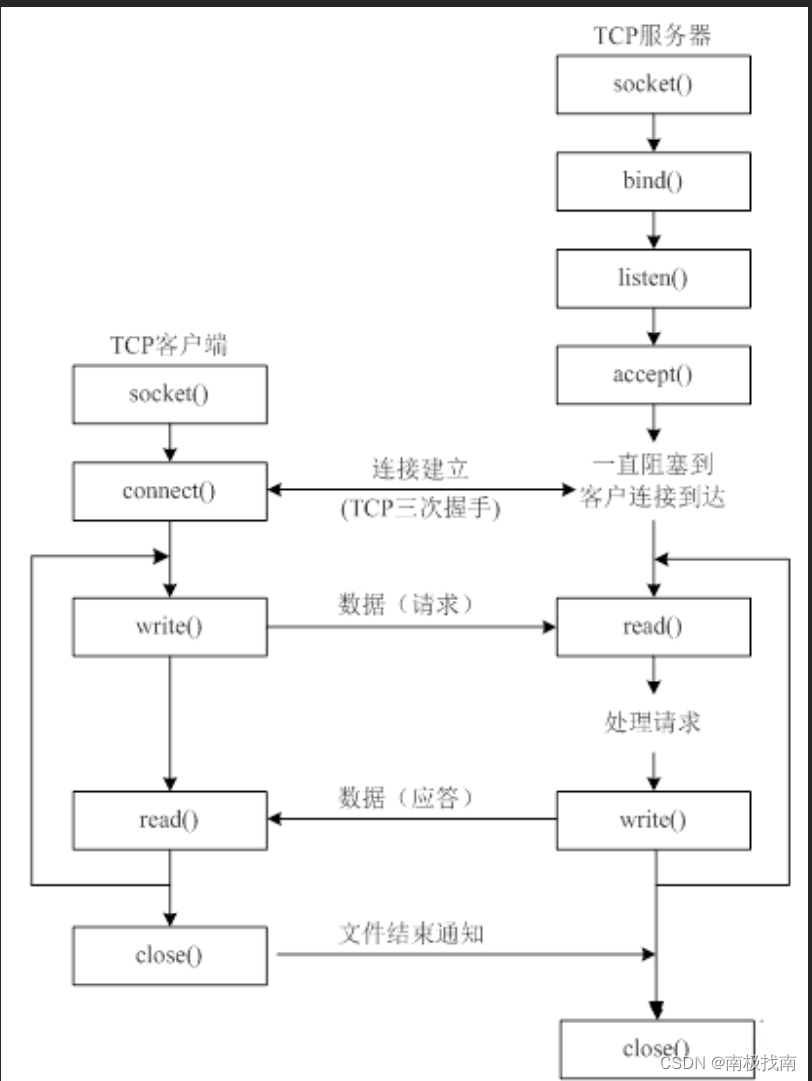
- TCP通信需要经过:创建连接、数据传送、终止连接。TCP通信之前需要先建立相关的链接。
- TCP通信模型:
- TCP完成一个客户端的功能
import socket # 模拟客户端 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 创建TCP套接字 IP = "127.0.0.1" PORT = 8080 s.connect((IP, PORT)) # 与服务端创建连接 send_data = input("请输入发送的数据:") s.send(send_data.encode('gbk')) # 发送数据 rescData = s.recv(1024) # 接收数据 print(rescData.decode('gbk')) s.close() - TCP完成一个服务器的功能
-1、创建套接字 2、bind绑定IP和port 3、listen使套接字变为被动链接 4、accept等待客户端的链接 5、recv/send接收发数据- Demo示例:
import socket # 模拟服务端 tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 创建TCP套接字 IP = "" PORT = 8080 tcp_server_socket.bind((IP, PORT)) # 服务端绑定地址信息 tcp_server_socket.listen(128) # 将主动套接字变成被动套接字 # 如果有客户端来链接服务器,那么就产生一个新的套接字专门为这个客户端服务 # client_socket就是用来为这个客户端服务的 # tcp_server_socket就可以省下来专门等待其他的新客户端链接 client_socket, clientAddr = tcp_server_socket.accept() print("已与客户端建立连接") data = client_socket.recv(1024) print("接收到的数据:",data.decode('gbk')) send_data = input("请输入返回数据:") send = client_socket.send(send_data.encode('gbk')) # 关闭为这个客户端服务的套接字,只要关闭了,就意味着为不能再为这个客户端服务了,如果还需要服务,只能再次重新连接 client_socket.close() - TCP连接的注意事项:
- tcp一般情况下都是需要绑定ip/port的,否则客户端找不到这个服务器
- tcp客户端一般不绑定,主动连接服务器不绑定。只要确定好服务器的ip/port,客户端随时可以链接
- tcp服务器通过listen可以将socket创建出来的主动套接字变成被动的,这是tcp作为服务器必须要做的
- 客户端连接服务器时,就需要使用connect连接,udp不需要连接直接发送就行。
- 当tcp客户端连接服务器时,服务器会产生1个先的套接字,这个新的套接字标记这个客户端后,单独为这个客户端服务
- listen后的套接字是被动套接字,用来接收新的客户端链接请求的,而accept返回的是新套接字标记的这个客户端
- 关闭listen后的套接字意味着被动套接字关闭,会导致新的客户端不能链接服务器,但是之前已经链接成功的客户端正常通信
- 关闭accept返回的套接字意味着这个客户端已经服务完毕
- 客户端的套接字调用close后,服务器的recv堵塞,并返回的长度是0,因为服务器可以根据返回数据的长度来区别客户端是否已经下线
Python进行数据库操作
- 常用的的库:pymysql、dbutils(下的PooledDB可以进行连接池设置)、sshtunnel(需要通过ssh通道连接,需要借助这个库)
- 不需要ssh连接的数据库操作
- Demo示例
class MysqlClient(object): """ Mysql客户端 """ def __init__(self, host=None, port=3306, user=None, password=None, db=None, charset='utf8'): """ 数据库工具类初始化方法 Args: host: 数据库地址 port: 数据库端口 user: 数据库用户名 password: 数据库密码 db: 数据库名 charset: 数据库编码 """ self.host = host self.port = port self.user = user self.password = password self.db = db self.charset = charset # self.db_pool = PooledDB(pymysql, mincached=1, maxcached=5, host=self.host, port=self.port, # user=self.user, passwd=self.password, db=self.db, charset=self.charset, # connect_timeout=60) self.c = pymysql.connect(host=self.host, port=self.port, user=self.user, passwd=self.password, db=self.db, charset=self.charset) - 需要ssh连接的数据库操作
- Demo示例
class MysqlClient(object): """ Mysql客户端 """ def __init__(self, host=None, port=3306, user=None, password=None, db=None, charset='utf8', ssh_host=None, ssh_username=None, ssh_password=None, use_ssh_tunnel=False): """ 数据库工具类初始化方法 Args: host: 数据库地址 port: 数据库端口 user: 数据库用户名 password: 数据库密码 db: 数据库名 charset: 数据库编码 ssh_host: ssh地址 ssh_username: ssh用户名 ssh_password: ssh密码 use_ssh_tunnel: 使用ssh隧道 """ self.host = host self.port = port self.user = user self.password = password self.db = db self.charset = charset self.ssh_host = ssh_host self.ssh_username = ssh_username self.ssh_password = ssh_password self.use_ssh_tunnel = use_ssh_tunnel self.tunnel = None try: if self.use_ssh_tunnel: self.tunnel = SSHTunnelForwarder( ssh_address_or_host=(self.ssh_host, 22), ssh_username=self.ssh_username, ssh_password=self.ssh_password, remote_bind_address=(self.host, self.port)) self.tunnel.start() self.db_pool = PooledDB(pymysql, mincached=1, maxcached=5, host='127.0.0.1', port=self.tunnel.local_bind_port, user=self.user, passwd=self.password, db=self.db, charset=self.charset) else: self.db_pool = PooledDB(pymysql, mincached=1, maxcached=5, host=self.host, port=self.port, user=self.user, passwd=self.password, db=self.db, charset=self.charset, connect_timeout=60) except Exception as e: if self.tunnel is not None: self.tunnel.close() logger.error('Mysql数据库工具初始化异常,原因:{}'.format(str(e)))
- Demo示例
Python的高级用法
- 3.10版本增加类似Java_switch case语句 结构化模式匹配:match() case(): 【Python】Python 3.10 新特性之 match case语句_python match case-CSDN博客
match (s): # 可以是单个,也可以是多个 case "a": # 配置条件 print("s:", s) case "b": print("s", s) case _: print("默认值") - Python内置魔术方法: Python魔术方法详解_彭阳的技术博客_51CTO博客(魔术方法不需要主动调用,存在的目的是给Python的解释器进行调用的,几乎每一个魔术方法都有一个对应的内置函数)
-
__init__():初始化-用于初始化对象的属性和状态。 -
__del__():当对象不在被使用时执行清理操作,此魔术方法用的不多,Python有自己的垃圾回收机制。 -
__hash__()内建函数hash():返回一个整数值,实现魔术方法的类可被hash。 -
__eq__():与==对象,判断两个对象是否相等 -
__bool__()内建函数bool():布尔 -
__repr__()内建函数repr():对一个对象获取字符串表达式,如果没有定义__str__也会调用此方法 -
__str__()内建函数str():返回对象的字符串表达式,没有定义调__repr__,也没有定义的话防护object的内存地址信息 - 运算符魔术方法(不常用):见学习连接
-
__len__():查看对象的长度 -
__iter__():迭代容器时,调用,返回一个新的迭代去对象 -
__contains__():in成员运算符,如果没有实现这个方法,就会调用__iter__方法遍历 -
__getitem__():实现self[key]的访问,序列化对象,key接受整数作为索引。 -
__setitem__():和__getitem__类似是设置值的方法 -
__missing__():字典调用_getitem__时,key不存在时执行该方法 -
__call__():类中实现这个方法,实例就可以像调用函数一样去调用实例 - 上线文管理对象:当一个对象同时实现了这面的两个方法,就变成了上下文管理器
-
__enter__():进入与对象相关的上下文,如果存在此方法,with语法会把该方法返回的值,绑定到as 后面的变量身上 -
__exit__(exc_type, exc_value, exc_tb):退出与此对象相关的上下文。参数都和异常有关,异常的类型,异常的值,异常的追踪信息
-
- 反射:概述–Python中,能通过一个对象找出其type、class、attribute、或method的能力,称为反射或者自省。
- 具有反射能力的函数:type()、isinstance()、callable()、dir()、getattr()
-
getattr(object,name[default]):通过name返回object对象的属性值,当属性不存在时,将使用default返回,如果没有default,则抛出AttributeError的错误 -
setattr(object, name, value):object的属性存在,则覆盖,不存在,新增 -
hasattr(object, name):判断对象是否有name名字的属性,name必须为字符串
- 反射相关的魔术方法:
-
__getattr__(): 一个类的属性会按着继承关系去找,如果找不到会执行__getattr__()这个方法的实现,如果没有定义这个方法,就会抛出AttributeError的错误; -
__setattr__():可以拦截对实例属性的增加,修改操作,如果要设置生效,需要自己操作实例的__dict__()方法; -
__delattr__(): 可以阻止通过实例删除属性的操作,,但是通过类依然可以删除属性; -
__getattribute__():实例的所有属性访问都会调用这个方法,它阻止的属性的查找,该方法返回值或者抛出AttributeError异常;如果抛出了AttributeError这个异常,会紧跟着调用__getattr__方法,因为表示属性没有存在
-
- 描述器:一个类如果实现了__get__/set/__delete__三个方法任意一个方法,就是描述器。如果只实现__get__这一个方法,就是非数据描述符,如果同时也实现了__set__方法,就是数据描述符。一个类的类属性设置为描述器,那么被称为owner属性。
- 属性的访问顺序:
__dict__优先于非数据描述符,数据描述符优先于__dict__
- 属性的访问顺序:
-
