一、多任务进程编程
一个正在运行的程序或者软件就是一个进程,它是操作系统进行资源分配的基本单位,也就是说每启动一个进程,操作系统都会给其分配一定的运行资源(内存资源)保证进程的运行。
比如:现实生活中的公司可以理解成是一个进程,公司提供办公资源(电脑、办公桌椅等),而公司下属的分公司,可以理解为子进程。
Python 中使用 multiprocessing 模块实现进程多任务编程。
import multiprocessing
创建进程
multiprocessing 模块使用 Process 类创建进程实例对象,实现进程任务的创建。
Process([group [, target [, name [, args [, kwargs]]]]])
参数说明:
-
group:指定进程组,目前只能使用None -
target:执行的目标任务名 -
name:进程名字 -
args:以元组方式给执行任务传参 -
kwargs:以字典方式给执行任务传参
import multiprocessing
import time
# 跳舞任务
def task1():
for i in range(5):
print("跳舞中...")
time.sleep(0.2)
# 唱歌任务
def task2():
for i in range(5):
print("唱歌中...")
time.sleep(0.2)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task1, name="myprocess1")
p2 = multiprocessing.Process(target=task2)
启动进程
进程对象创建成功后,需要启动进程才会开始执行。
p1.start()
p2.start()
# 导入模块
import multiprocessing as mp
import time
# 定义任务函数
def task1():
for i in range(10):
print("Task 1 Run...")
time.sleep(0.2)
def task2():
for i in range(10):
print("Task 2 Run...")
time.sleep(0.2)
# 创建任务函数
def create_task():
p1 = mp.Process(target=task1, name= "Myprocess-1")
p2 = mp.Process(target=task2)
p1.start()
p2.start()
# 程序入口
if __name__ == "__main__":
create_task()
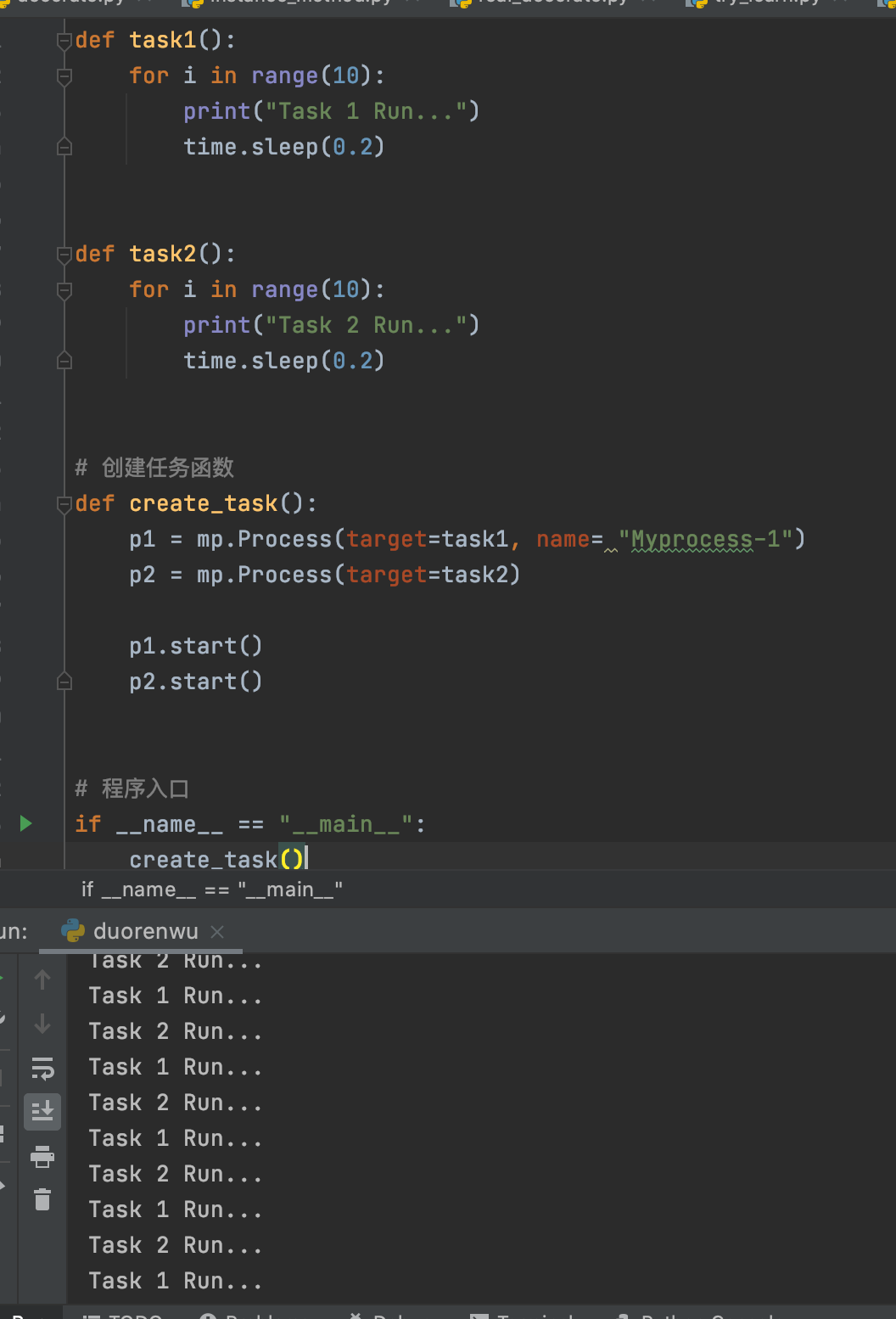
获取当前进程
multiprocessing.current_process() 可以获取当前进程。
def task1():
print(multiprocessing.current_process())
def task2():
print(multiprocessing.current_process())
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task1, name="myprocess-1")
p2 = multiprocessing.Process(target=task2)
p1.start()
p2.start()
import multiprocessing as mp
import time
# 定义任务函数
def task1():
for i in range(10):
print(mp.current_process, "Task 1 Run...")
time.sleep(0.2)
def task2():
for i in range(10):
print(mp.current_process, "Task 2 Run...")
time.sleep(0.2)
# 创建任务函数
def create_task():
p1 = mp.Process(target=task1, name= "Myprocess-1")
p2 = mp.Process(target=task2)
p1.start()
p2.start()
print("main: ", mp.current_process)
# 程序入口
if __name__ == "__main__":
create_task()
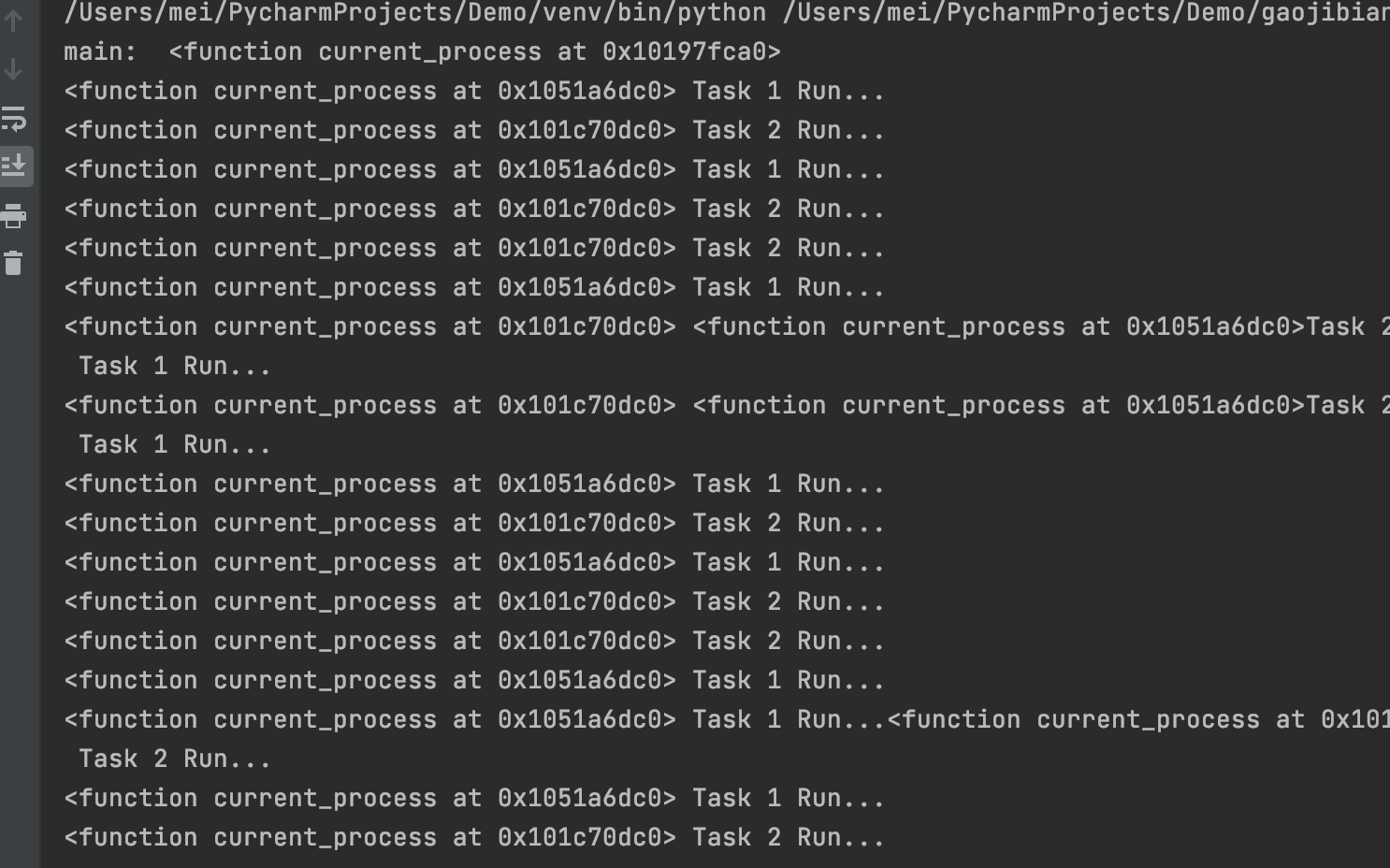
获取进程名
进程对象的 name 属性可以获取进程的名称。
def task1():
print(multiprocessing.current_process().name)
def task2():
print(multiprocessing.current_process().name)
if __name__ == '__main__':
print(multiprocessing.current_process().name)
p1 = multiprocessing.Process(target=task1, name="myprocess-1")
p2 = multiprocessing.Process(target=task2)
p1.start()
p2.start()
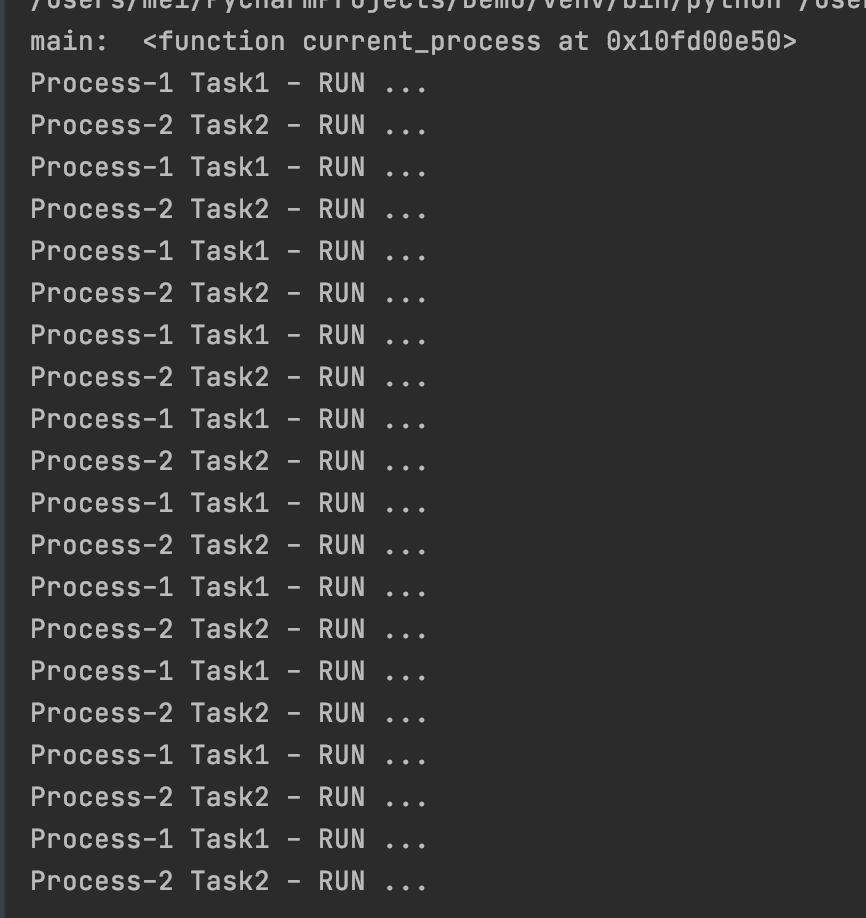
def task():
for i in range(10):
if mp.current_process().name == "Process-1":
print(mp.current_process().name, "Task1 - RUN ...")
else:
print(mp.current_process().name, "Task2 - RUN ...")
time.sleep(0.2)
def create_task2():
p1 = mp.Process(target=task)
p2 = mp.Process(target=task)
p1.start()
p2.start()
print("main: ", mp.current_process)
# 程序入口
if __name__ == "__main__":
create_task2()
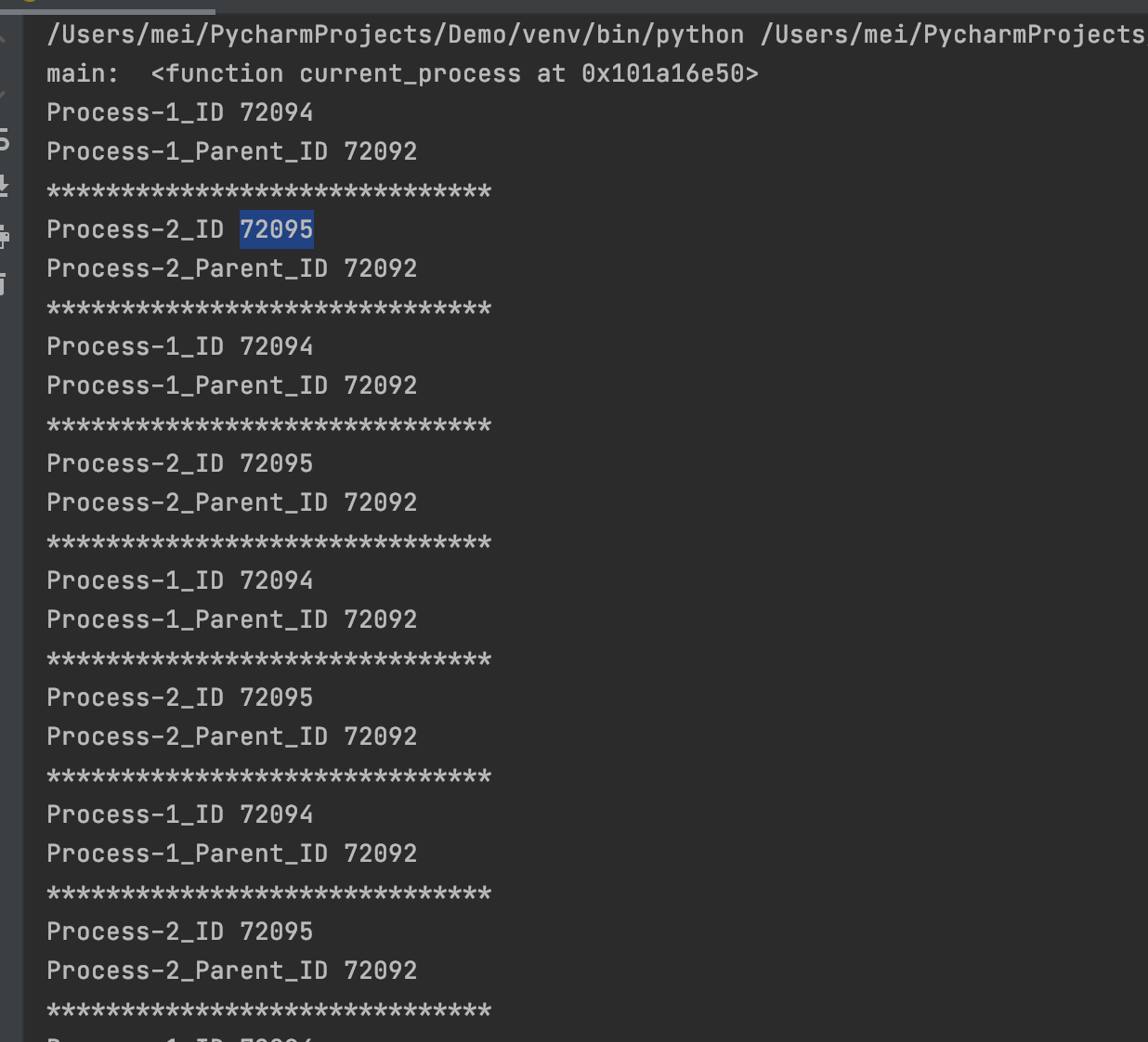
获取进程ID
每一个进程产生时,操作系统都分为进程分配一个ID编号,可以通过 os 模块中的方法获取进程的ID。
-
os.getpid()获取当前进程ID -
os.getppid()获取当前进程的父进程的ID
def task1():
print(f"{multiprocessing.current_process().name}_ID", os.getpid())
print(f"{multiprocessing.current_process().name}_Parent_ID", os.getppid())
def task2():
print(f"{multiprocessing.current_process().name}_ID", os.getpid())
print(f"{multiprocessing.current_process().name}_Parent_ID", os.getppid())
if __name__ == '__main__':
print(f"{multiprocessing.current_process().name}_ID", os.getpid())
print(f"{multiprocessing.current_process().name}_Parent_ID", os.getppid())
p1 = multiprocessing.Process(target=task1, name="myprocess-1")
p2 = multiprocessing.Process(target=task2)
p1.start()
p2.start()
def task():
for i in range(10):
if mp.current_process().name == "Process-1":
# print(mp.current_process().name, "Task1 - RUN ...")
print(f"{mp.current_process().name}_ID", os.getpid())
print(f"{mp.current_process().name}_Parent_ID", os.getppid())
print("*" * 30)
else:
# print(mp.current_process().name, "Task2 - RUN ...")
print(f"{mp.current_process().name}_ID", os.getpid())
print(f"{mp.current_process().name}_Parent_ID", os.getppid())
print("*" * 30)
time.sleep(0.2)
进程任务函数传参
在创建进程对象的时候,为进程任务函数传递参数,可以使用两种方式为任务函数传参。
-
args: 使用可变位置参数形式传参 -
kwargs: 使用可变关键字参数形式传参
import multiprocessing
import time
def task(n, msg):
for i in range(n):
print(multiprocessing.current_process().name, f"打印第 {i+1} 次 {msg}")
time.sleep(0.2)
if __name__ == '__main__':
# 使用可变位置参数传参
p1 = multiprocessing.Process(target=task, args=(10, "Python"))
# 使用可变关键字参数传参
p2 = multiprocessing.Process(target=task, kwargs={"n": 10, "msg": "Hogwarts"})
p1.start()
p2.start()
def task_take_arg(n, msg):
for i in range(n):
if mp.current_process().name == "Process-1":
print(mp.current_process().name, "Task1 - RUN ...", msg)
else:
print(mp.current_process().name, "Task2 - RUN ...", msg)
time.sleep(0.2)
def create_task3():
p1 = mp.Process(target=task_take_arg, args=(5, "hello"))
p2 = mp.Process(target=task_take_arg, kwargs={"msg": "zhizhi", "n": 5})
p1.start()
p2.start()

进程同步
join() 方法用来将子进程添加到当前进程之前执行,直到子进程执行结束后,当前进程才会继续向下执行。
多个进程间的代码在运行时是交替执行的,如果使用 join() 方法后,当前进程会进入到阻塞状态,等待子进程结束后,解除阻塞状态,继续执行当前进程。
使用 join() 方法后,可使多进程的异步执行变成同步执行, 过多使用会使程序效率变低。
import multiprocessing
import time
def task(n, msg):
for i in range(n):
print(multiprocessing.current_process().name, f"打印第 {i+1} 次 {msg}")
time.sleep(0.2)
if __name__ == '__main__':
# 使用可变位置参数传参
p1 = multiprocessing.Process(target=task, args=(10, "Python"))
# 使用可变关键字参数传参
p2 = multiprocessing.Process(target=task, kwargs={"n": 10, "msg": "Hogwarts"})
p1.start()
p1.join()
print("main run ...")
p2.start()
p2.join()
def create_task4():
p1 = mp.Process(target=task1, name= "Myprocess-1")
p2 = mp.Process(target=task2)
p1.start()
p1.join()
p2.start()
p2.join()
print("main: ", mp.current_process)
守护进程
多进程在执行时,父进程会等待子进程执行结束才会结束。
如果需要子进程在父进程执行结束后就结束执行,无论子进程是否执行完毕,可以将子进程设置为守护进程。
比如:只有开启企业微信后,才可以使用企业微信的会议功能,当企业微信退出时,会议也会随之退出。
设置守护进程方式有两种:
- 使用
子进程对象.daemon = True在子进程启动前将子进程设置为守护进程。 - 使用
子进程对象.terminate()在主进程退出前手动将子进程结束。
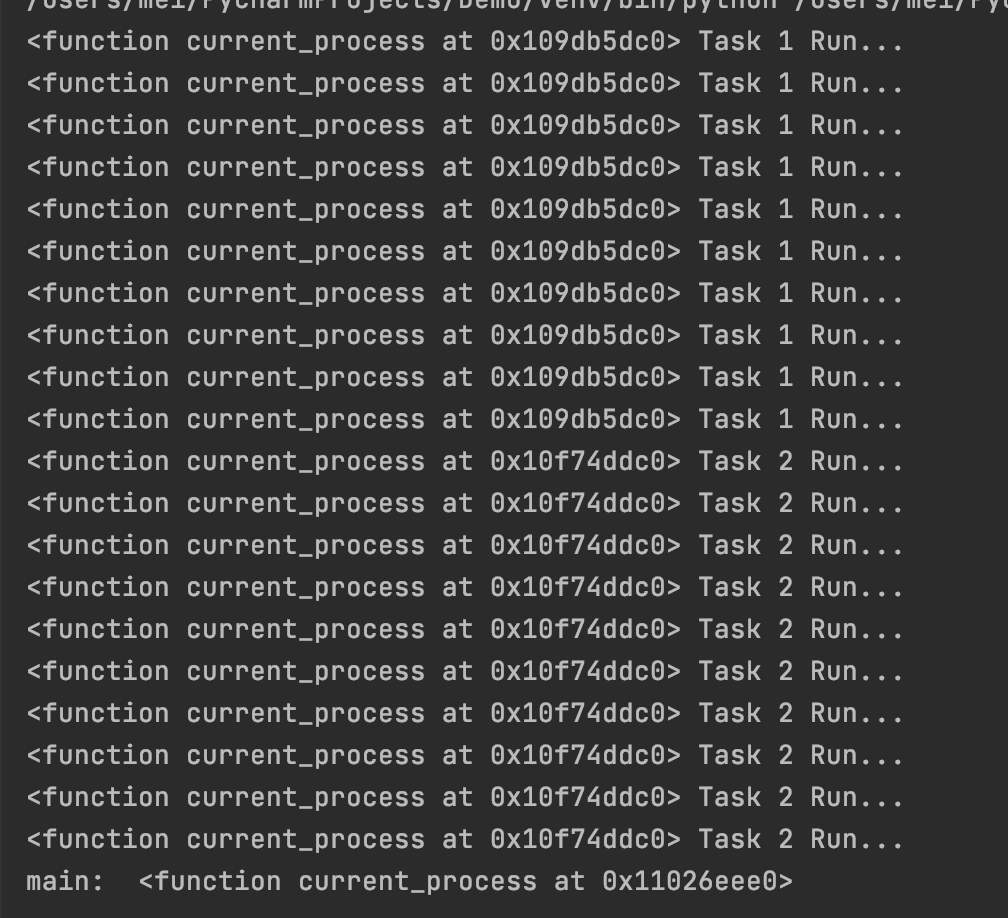
设置子进程为守护进程
import multiprocessing
import time
def task(n, msg):
for i in range(n):
print(multiprocessing.current_process().name, f"打印第 {i+1} 次 {msg}")
time.sleep(0.2)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task, args=(10, "Python"))
p2 = multiprocessing.Process(target=task, kwargs={"n": 10, "msg": "Hogwarts"})
p1.daemon = True
p1.start()
p2.start()
time.sleep(1)
print("main")
def create_task5():
p1 = mp.Process(target=task1, name= "Myprocess-1")
p2 = mp.Process(target=task2)
print("main: ", mp.current_process)
# 设置子进程为守护进程
p1.daemon = True
p2.daemon = True
p1.start()
p2.start()
time.sleep(1)
print("Main Over")
手动杀死子进程
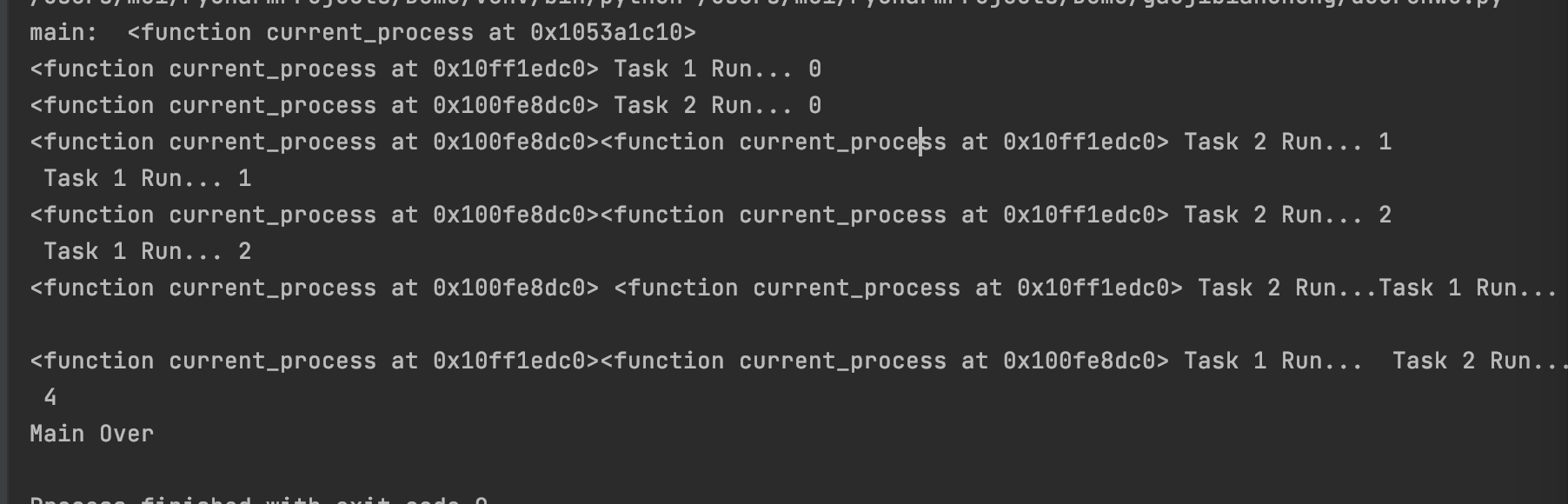
import multiprocessing
import time
def task(n, msg):
for i in range(n):
print(multiprocessing.current_process().name, f"打印第 {i+1} 次 {msg}")
time.sleep(0.2)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task, args=(10, "Python"))
p2 = multiprocessing.Process(target=task, kwargs={"n": 10, "msg": "Hogwarts"})
p1.start()
p2.start()
time.sleep(1)
p2.terminate()
print("main")
def create_task5():
p1 = mp.Process(target=task1, name= "Myprocess-1")
p2 = mp.Process(target=task2)
print("main: ", mp.current_process)
# 设置子进程为守护进程
# p1.daemon = True
# p2.daemon = True
p1.start()
p2.start()
time.sleep(1)
# 手动杀死子进程实现守护效果
p1.terminate()
p2.terminate()
print("Main Over")
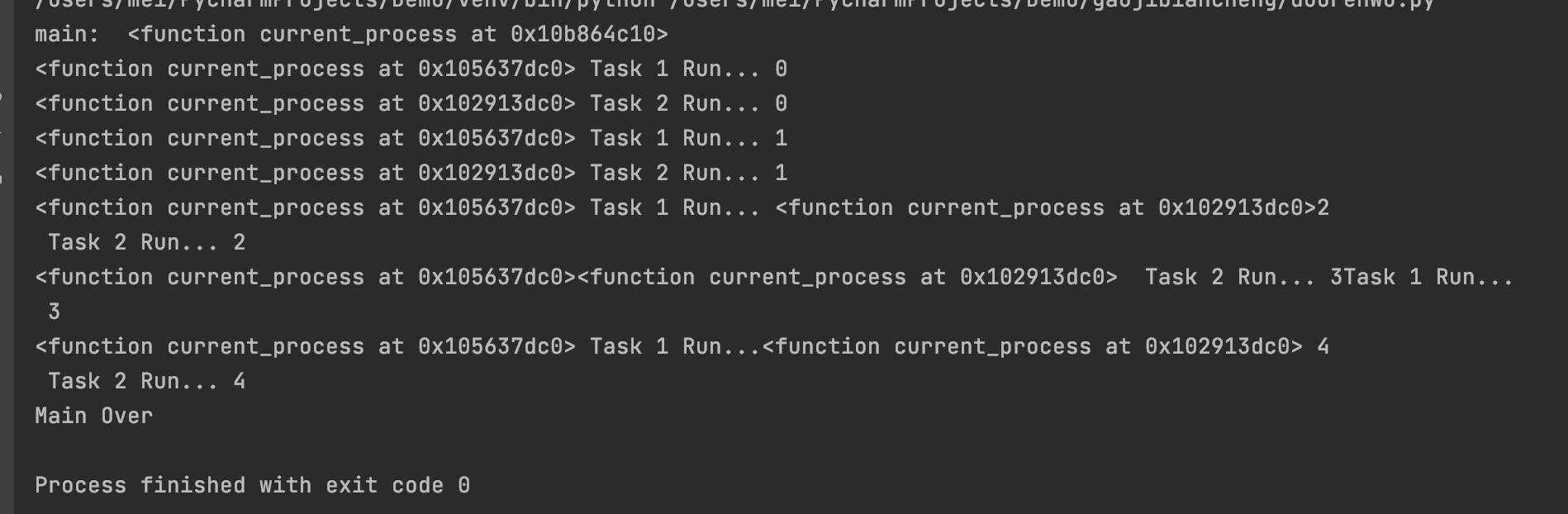
进程间不共享全局变量
因为进程是程序执行的最小资源分配单位,当一个子进程被创建时,子进程会复制父进程的资源,形成一个独立的空间,所以多个进程之间的数据是独立不共享的。
import multiprocessing
import time
# 定义全局变量
g_list = list()
# 添加数据的任务
def add_data():
for i in range(5):
g_list.append(i)
print("add:", i)
time.sleep(0.2)
print("add_data:", g_list)
def read_data():
print("read_data", g_list)
if __name__ == '__main__':
add_data_process = multiprocessing.Process(target=add_data)
read_data_process = multiprocessing.Process(target=read_data)
add_data_process.start()
add_data_process.join()
read_data_process.start()
print("main:", g_list)
二、多任务线程编程
线程是指在一个程序中执行的一段指令流。
在操作系统中,线程是调度执行的最小单位,它可以独立运行,并共享线程的资源,如内存空间、文件句柄等。
线程有以下几个特点:
- 轻量级:相对于进程来说,线程的创建、切换和销毁的开销较小。
- 共享资源:线程可以共享线程的资源,包括内存空间、文件句柄等。这使得线程之间可以方便地进行数据共享和通信。
- 并发执行:线程可以并发执行,即多个线程可以在同一时间内执行不同的任务。线程的并发执行可以提高程序的性能和响应性。
- 线程安全:线程安全是指多个线程同时访问共享数据时,不会出现数据不一致或异常的情况。在多线程编程中,需要采取一些措施(如锁、互斥量等)来保证线程安全性。
- 线程必须依附于进程中,线程不能单独存在。
比如:现实生活中的公司可以理解成是一个进程,公司提供办公资源(电脑、办公桌椅等),真正干活的是员工,员工可以理解成线程。
Python 中使用 threading 模块实现线程多任务编程。
import threading
创建线程
threading 模块使用 Thread 类创建线程实例对象,实现线程任务的创建。
Thread([group [, target [, name [, args [, kwargs [, daemon]]]]]])
参数说明:
-
group:指定线程组,目前只能使用None -
target:执行的目标任务名 -
name:线程名字 -
args:以元组方式给执行任务传参 -
kwargs:以字典方式给执行任务传参 -
daemon:设置线程对象为守护线程
import threading
import time
# 跳舞任务
def task1():
for i in range(5):
print("跳舞中...")
time.sleep(0.2)
# 唱歌任务
def task2():
for i in range(5):
print("唱歌中...")
time.sleep(0.2)
if __name__ == '__main__':
t1 = threading.Thread(target=task1, name="mythread-1")
t2 = threading.Thread(target=task2)
import threading
import time
def task1():
for i in range(10):
print(threading.current_thread().name, f"第{i+1}次输出 Task 1 Run...")
time.sleep(0.5)
def task2():
for i in range(10):
print(threading.currentThread().name, f"第{i+1}次输出 Task 2 Run...")
time.sleep(0.5)
def create_task1():
t1 = threading.Thread(target=task1, name="MyThead-1")
t2 = threading.Thread(target=task2)
t1.start()
t2.start()
if __name__ == "__main__":
create_task1()

启动线程
线程对象创建成功后,需要启动线程才会开始执行。
t1.start()
t2.start()
获取当前线程
threading.current_thread() 可以获取当前线程。
def task1():
print(threading.current_thread())
def task2():
print(threading.current_thread())
if __name__ == '__main__':
t1 = threading.Thread(target=task1, name="myThread-1")
t2 = threading.Thread(target=task2)
t1.start()
t2.start()
获取线程名
线程对象的 name 属性可以获取线程的名称。
def task1():
print(threading.current_thread().name)
def task2():
print(threading.current_thread().name)
if __name__ == '__main__':
print(threading.current_thread().name)
t1 = threading.Thread(target=task1, name="myThread-1")
t2 = threading.Thread(target=task2)
t1.start()
t2.start()
线程无序性
线程执行时是无序的。它是由cpu调度决定的 ,cpu调度哪个线程,哪个线程就先执行,没有调度的线程不能执行。
import threading
import time
def task():
time.sleep(1)
print("当前线程:", threading.current_thread().name)
if __name__ == '__main__':
for _ in range(5):
t = threading.Thread(target=task)
t.start()
线程任务函数传参
在创建线程对象的时候,为线程任务函数传递参数,可以使用两种方式为任务函数传参。
-
args: 使用可变位置参数形式传参 -
kwargs: 使用可变关键字参数形式传参
import threading
import time
def task(n, msg):
for i in range(n):
print(threading.current_thread().name, f"打印第 {i+1} 次 {msg}")
time.sleep(0.2)
if __name__ == '__main__':
# 使用可变位置参数传参
t1 = threading.Thread(target=task, args=(10, "Python"))
# 使用可变关键字参数传参
t2 = threading.Thread(target=task, kwargs={"n": 10, "msg": "Hogwarts"})
t1.start()
t2.start()
线程同步
join() 方法用来将子线程添加到当前线程之前执行,直到子线程执行结束后,当前线程才会继续向下执行。
多个线程间的代码在运行时是交替执行的,如果使用 join() 方法后,当前线程会进入到阻塞状态,等待子线程结束后,解除阻塞状态,继续执行当前线程。
使用 join() 方法后,可使多线程的异步执行变成同步执行, 过多使用会使程序效率变低。
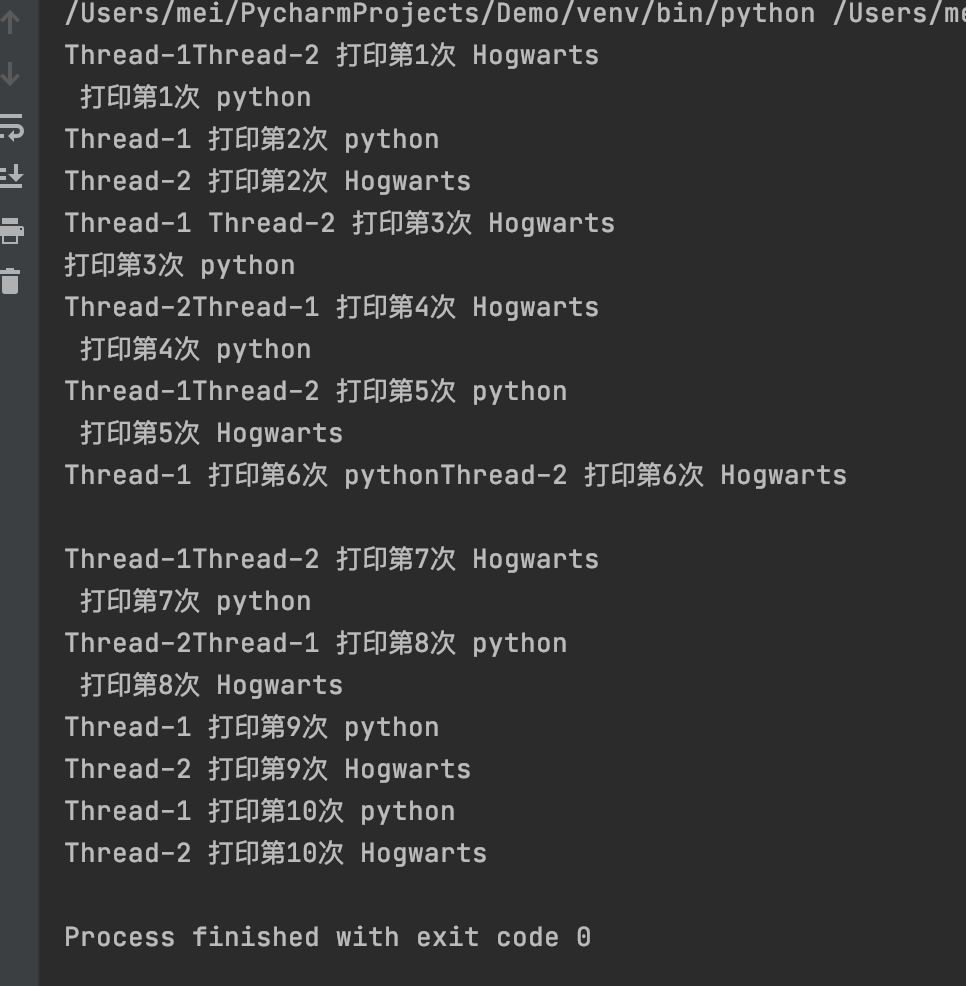
import threading
import time
def task(n, msg):
for i in range(n):
print(threading.current_thread().name, f"打印第 {i+1} 次 {msg}")
time.sleep(0.2)
if __name__ == '__main__':
# 使用可变位置参数传参
t1 = threading.Thread(target=task, args=(10, "Python"))
# 使用可变关键字参数传参
t2 = threading.Thread(target=task, kwargs={"n": 10, "msg": "Hogwarts"})
t1.start()
t1.join()
print("main run ...")
t2.start()
t2.join()
守护线程
多线程在执行时,父线程会等待子线程执行结束才会结束。
如果需要子线程在父线程执行结束后就结束执行,无论子线程是否执行完毕,可以将子线程设置为守护线程。
比如:在使用下载软件进行下载多个视频时,每个下载任务都是一个线程,如果下载软件退出,则下载任务也会停止并退出。
设置守护线程方式有两种:
- 使用
daemon = True参数在子线程对象创建时将子线程设置为守护线程。 - 使用
子线程对象.daemon = True属性在子线程对象启动前将子线程对象设置为守护线程。
设置子线程为守护线程
import threading
import time
def task(n, msg):
for i in range(n):
print(threading.current_thread().name, f"打印第 {i+1} 次 {msg}")
time.sleep(0.2)
if __name__ == '__main__':
t1 = threading.Thread(target=task, args=(10, "Python"),daemon=True)
t2 = threading.Thread(target=task, kwargs={"n": 10, "msg": "Hogwarts"})
t2.daemon = True
t1.start()
t2.start()
time.sleep(1)
print("main")
线程间共享全局变量
因为线程是程序执行的最小执行单位,当一个子线程被创建时,子线程会使用父线程的资源,所以多个线程之间的数据是共享的。
import threading
import time
# 定义全局变量
g_list = list()
# 添加数据的任务
def add_data():
for i in range(5):
g_list.append(i)
print("add:", i)
time.sleep(0.2)
print("add_data:", g_list)
def read_data():
print("read_data", g_list)
if __name__ == '__main__':
add_data_Thread = threading.Thread(target=add_data)
read_data_Thread = threading.Thread(target=read_data)
add_data_Thread.start()
add_data_Thread.join()
read_data_Thread.start()
print("main:", g_list)
线程安全问题
线程间可以访问全局变量,在多个线程间进行数据传递时非常方便,但是随之也会产生很大的问题。
当多个线程同时对共享的全局变量进行操作时,可能会出现脏数据的问题。
注意:
- Python 3.9 版本解释器之前,线程安全问题非常明显
- Python 3.10 版本后,引入了新的 GIL2.0 版本的锁,有效的提升了线程安全问题,但某些时刻还需要使用互斥锁保证线程安全。
示例: 使用多个线程对象,分别对共享全局变量 sum 做一百万次加 1 操作,查看计算结果。
import time
import threading
# 定义全局变量
sum = 0
# 循环一次给全局变量加1
def add_one():
global sum
for i in range(1000000):
sum += 1
print(threading.current_thread().name , " : ", sum)
if __name__ == '__main__':
# 创建两个线程
t1 = threading.Thread(target=add_one)
t2 = threading.Thread(target=add_one)
t3 = threading.Thread(target=add_one)
# 启动线程
t1.start()
t2.start()
t3.start()
time.sleep(3)
print(threading.current_thread().name , " : ", sum)
错误分析:
多个线程线程对象 t1,t2,t3 都要对全局变量 sum (默认是0)进行加 1 运算,但是由于是多线程同时操作,有可能出现下面情况:
- 在
sum=0时,线程对象t1取得sum=0。 - 此时系统把线程对象
t1调度为sleeping状态 - 把线程对象
t2转换为running状态,t2也获得sum=0 - 然后线程对象
t2对得到的值进行加 1 并赋给sum,使得sum=1 - 然后系统又把线程对象
t2调度为sleeping - 再把线程对象
t1转为running状态 - 线程对象
t1又把它之前得到的 0 加 1 后赋值给sum,结果为sum=1 - 三个线程对象都会在执行过程中出现这种情况
- 这样导致虽然线程对象
t1,t2,t3都对sum加 1,但结果却是产生了无效的计算过程
互斥锁
在 Python 中,可以使用互斥锁(Mutex)来保护共享资源,避免多个线程同时对共享资源进行写操作,从而避免竞争条件和数据不一致的问题。
使用 threading.Lock() 获取互斥锁对象。
lock = threading.Lock()
互斥锁操作:
- 加锁操作:
lock.acquire() - 解锁操作:
lock.release()
使用互斥锁解决 Python3.9 版本线程间数据安全问题。
import time
import threading
# 定义全局变量
sum = 0
lock = threading.Lock()
# 方式一
def add_one():
global sum
lock.acquire()
for i in range(1000000):
sum += 1
lock.release()
print(threading.current_thread().name , " : ", sum)
# 方式二
# def add_one():
# global sum
# for i in range(1000000):
# lock.acquire()
# sum += 1
# lock.release()
# print(threading.current_thread().name , " : ", sum)
if __name__ == '__main__':
# 创建两个线程
t1 = threading.Thread(target=add_one)
t2 = threading.Thread(target=add_one)
t3 = threading.Thread(target=add_one)
# 启动线程
t1.start()
t2.start()
t3.start()
time.sleep(3)
print(threading.current_thread().name , " : ", sum)
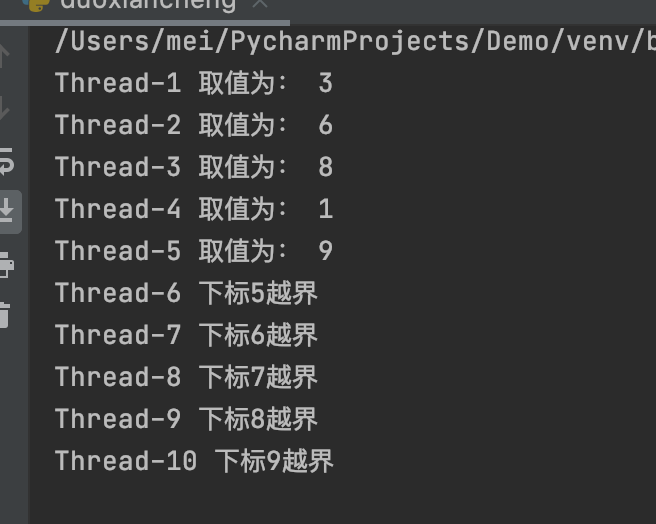
死锁
虽然使用互斥锁可以解决线程间数据安全问题,但是,如果互斥锁使用不当,会出现死锁现象。
死锁是指一个线程获取锁权限后,并未释放锁,导致其它线程无法获取互斥锁的使用权,持续进行等待的过程。
import threading
import time
# 创建互斥锁
lock = threading.Lock()
numbers = [3, 6, 8, 1, 9]
# 根据下标去取值, 保证同一时刻只能有一个线程去取值
def get_value(index):
# 上锁
lock.acquire()
# 判断下标释放越界
if index >= len(numbers):
print(threading.current_thread().name, f"下标 {index} 越界")
return
value = numbers[index]
print(threading.current_thread().name, "取值为: ", value)
time.sleep(0.2)
# 释放锁
lock.release()
if __name__ == '__main__':
# 模拟大量线程去执行取值操作
for i in range(10):
sub_thread = threading.Thread(target=get_value, args=(i,))
sub_thread.start()
避免死锁
程序开发过程中,应该避免死锁的发生。
可以在程序的合适位置,将锁释放掉,让其它线程对象有能获取到互斥锁的机会。
import threading
import time
# 创建互斥锁
lock = threading.Lock()
numbers = [3, 6, 8, 1, 9]
# 根据下标去取值, 保证同一时刻只能有一个线程去取值
def get_value(index):
# 上锁
lock.acquire()
# 判断下标释放越界
if index >= len(numbers):
print(threading.current_thread().name, f"下标 {index} 越界")
lock.release()
return
value = numbers[index]
print(threading.current_thread().name, "取值为: ", value)
time.sleep(0.2)
# 释放锁
lock.release()
if __name__ == '__main__':
# 模拟大量线程去执行取值操作
for i in range(10):
sub_thread = threading.Thread(target=get_value, args=(i,))
sub_thread.start()
进程与线程对比
- 关系对比
- 线程是依附在进程里面的,没有进程就没有线程。
- 一个进程默认提供一条线程,进程可以创建多个线程。
- 区别对比
- 进程之间不共享全局变量
- 线程之间共享全局变量,但是要注意资源竞争的问题,解决办法: 互斥锁或者线程同步
- 创建进程的资源开销要比创建线程的资源开销要大
- 进程是操作系统资源分配的基本单位,线程是CPU调度的基本单位
- 线程不能够独立执行,必须依存在进程中
- 多进程开发比单进程多线程开发稳定性要强
- 优缺点对比
- 进程优缺点:
- 优点:可以用多核
- 缺点:资源开销大
- 线程优缺点:
- 优点:资源开销小
- 缺点:不能使用多核(3.10版本后有改善)
