Python高级编程学习
第一部分:多任务编程
#1.1 多任务编程的概念
#多任务是指同时处理多个任务或处理多个工作的能力。计算机编程中,多任务编程可以通过多线程,多进程或协程等方式实现。每个任务或线程可以并行或交替执行,实现并发处理。多任务编程可以提高程序的性能和响应能力,并充分利用多核处理器或处理器系统的性能优势。多任务编程面临的挑战:如并发访问共享资源可能引起竞态条件和数据一致性问题,需要采取合适的同步机制来解决,此外,调度算法的设计和任务切换的开销也需要考虑
#1.2 多任务编程
在实际开发中,Python多任务编程可以通过以下三种形式实现:
- 线程
- 进程
- 协程
多线程可以在同一个程序内同时运行多个线程,每个线程负责执行不同的任务,能够充分利用多核心处理器的性能优势,提高程序的并发能力。多线程编程需要注意线程安全问题,比如访问共享资源时需要使用锁来保证数据的一致性。
多进程编程,它可以在操作系统级别同时运行多个独立的进程。每个进程拥有独立的内存空间和资源,可以实现更高的隔离性。
协程是一种轻量级的多任务编程技术,它可以在同一个线程中实现多个任务的切换和调度,类似于一个人同时炖汤,炒菜,洗菜和切菜,每个任务暂停切换执行另一个任务,因切换时间很短看起来是同时执行。协程通过yield语句和生成器函数实现任务的暂停和恢复,避免了线程切换的开销并减少了锁的使用。协程常用于异步编程场景,比如网络编程和IO密集型任务。
第二部分:多任务进程编程
#2.1 进程实现多任务
#一个正在运行的程序或者软件就是一个进程,它是操作系统进行资源分配的基本单位,也就是说每启动一个进程,操作系统都会给其分配一定的运行资源(内存空间)保证进程的运行。比如现实生活中的公司
#可以理解为一个进程,公司提供办公资源(电脑,办公桌椅等),而公司下属的分公司,可以理解为子进程。
#2.1.1 创建进程
#multiprocessing 模块使用process类创建进程实例对象,实现进程任务的创建

#一个正在运行的程序或者软件就是一个进程,它是操作系统进行资源分配的基本单位,也就是说每启动一个进程,操作系统都会给其分配一定的运行资源(内存空间)保证进程的运行。比如现实生活中的公司
#可以理解为一个进程,公司提供办公资源(电脑,办公桌椅等),而公司下属的分公司,可以理解为子进程。
#2.1.1 创建进程
multiprocessing 模块使用process类创建进程实例对象,实现进程任务的创建
import multiprocessing as mp
import time
def task1():
for i in range(10):
print(mp.current_process(), “task1 is running……”)
time.sleep(0.2)
def task2():
for i in range(10):
print(mp.current_process(),“task2 is running……”)
time.sleep(0.2)
def create_task():
p1 = mp.Process(target=task1,name='myprocess-1')
p2 = mp.Process(target=task2)
p1.start()
p2.start()
if name == ‘main’:
create_task()
print(‘main:’,mp.current_process())
部分运行结果如下图:
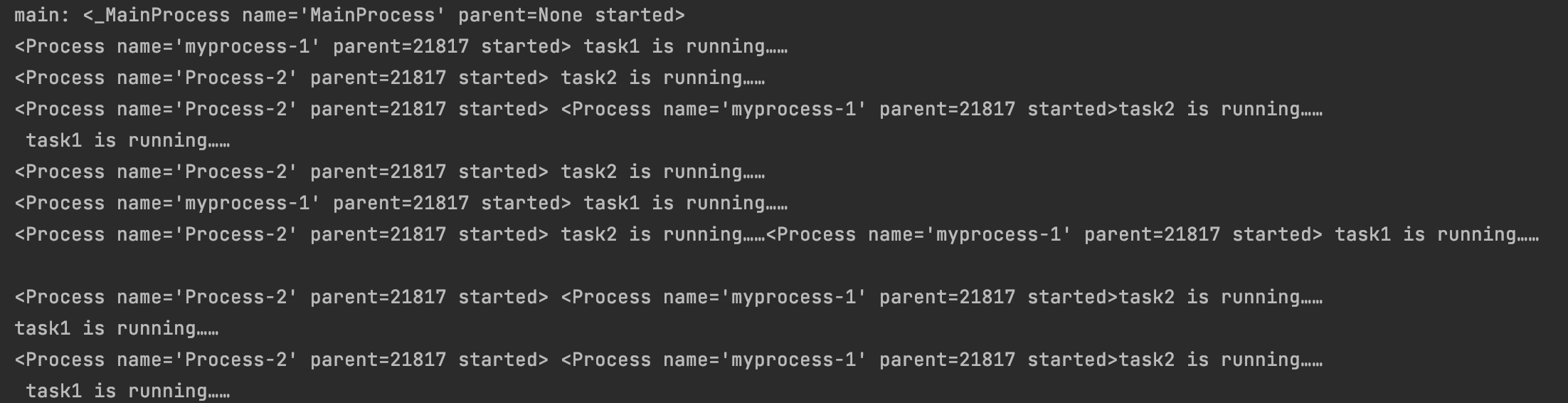
#2.2 进程相关操作
#2.2.1 启动进程
#进程对象创建成功后,需要启动进程才会开始执行
p1.start()
p2.start()
#2.2.2 获取当前进程
multiprocessing.current_process() 可以获取当前进程
#2.2.3 获取进程名
#进程对象的name属性可以获取进程的名称
#2.2.4 获取进程ID
#每一个进程产生时,操作系统都为进程分配一个ID编号,可以通过os模块中的方法获取进程的ID
#os.getpid()获取当前进程ID
#os.getppid()获取当前进程的父进程ID
import multiprocessing as mp
def task():
for i in range(10):
if mp.current_process().name==‘Process-1’:
print(mp.current_process().name,“TASK-1 is run……”)
print(f"{mp.current_process().name}_ID:“,os.getpid())
print(f”{mp.current_process().name}_parent_ID:“,os.getppid())
print(”" * 30)
time.sleep(0.2)
else:
print(mp.current_process().name,“TASK-2 is run……”)
print(f"{mp.current_process().name}_ID:“,os.getpid())
print(f”{mp.current_process().name}_parent_ID",os.getppid())
print("" * 30)
time.sleep(0.2)
def create_process():
p1 = mp.Process(target=task)
p2 = mp.Process(target=task)
p1.start()
p2.start()
if name == ‘main’:
create_process()
部分运行结果如下图:
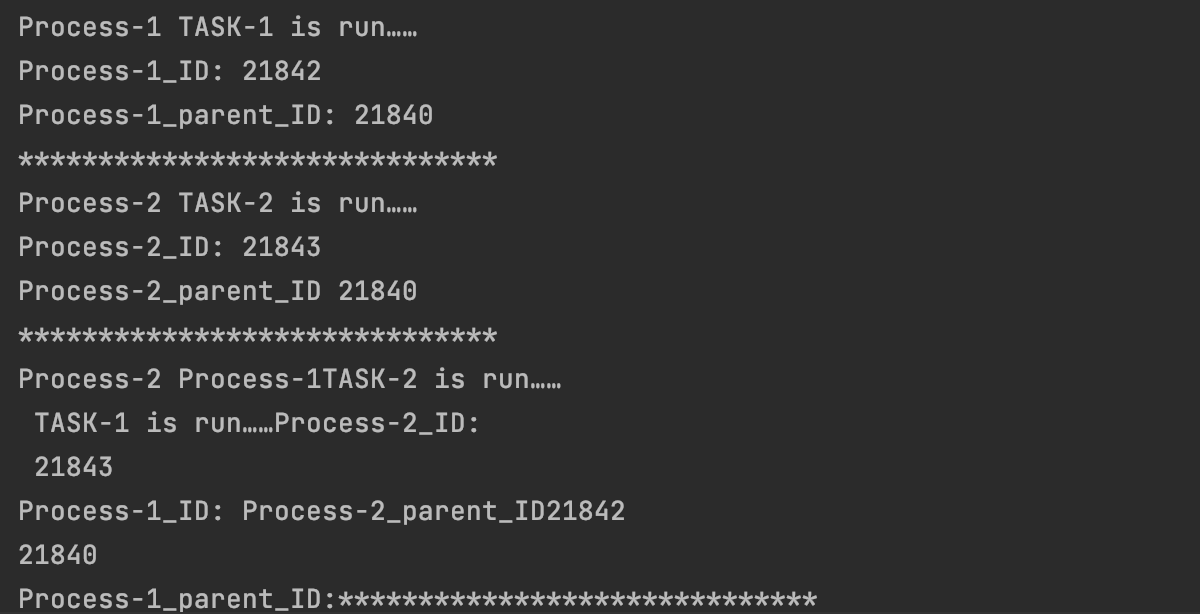
#2.2.5 进程任务函数传参
#在创建进程对象的时候,为进程任务函数传递参数,可以使用两种方式为任务函数传参:
#args:使用可变位置参数形式传参
#kwargs:使用可变关键字参数形式传参
def task_take_arg(n,msg):
for i in range(n):
if mp.current_process().name==‘Process-1’:
print(mp.current_process().name,“TASK-1 is run……”,msg)
else:
print(mp.current_process().name,"TASK-2 is run……",msg)
time.sleep(0.2)
def create_process():
# args:使用可变位置参数形式传参
p1 = mp.Process(target=task_take_arg,args=(5,“hello”))
# kwargs:使用可变关键字参数形式传参
p2 = mp.Process(target=task_take_arg,kwargs={“msg”:“hogwarts”,“n”:5})
p1.start()
p2.start()
if name == ‘main’:
create_process()
部分运行结果如下图:
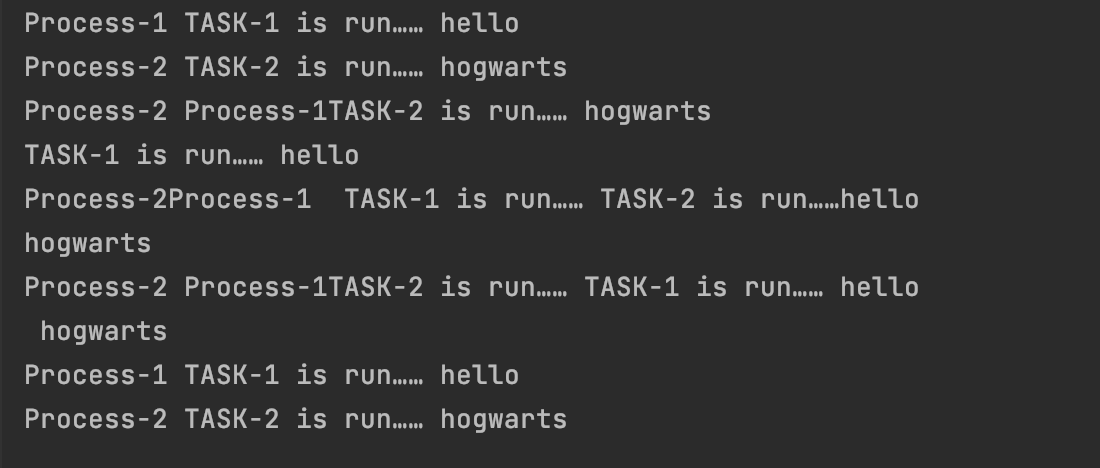
#2.2.6 进程同步
#join()方法用来将子进程添加到当前进程之前执行,直到子进程执行结束后当前进程才会继续向下执行。多个进程间的代码是交替执行的,如果使用join()方法后,
#当前进程会进入到阻塞状态,等待子进程结束后,解除阻塞状态,继续执行当前进程。使用join()方法后,会使多进程的异步执行变成同步执行,过多使用会使执行
#效率变低
import multiprocessing as mp
def task_take_arg(n,msg):
for i in range(n):
if mp.current_process().name==‘Process-1’:
print(mp.current_process().name,“TASK-1 is run……”,msg)
else:
print(mp.current_process().name,"TASK-2 is run……",msg)
time.sleep(0.2)
def create_process():
# args:使用可变位置参数形式传参
p1 = mp.Process(target=task_take_arg,args=(5,“hello”))
# kwargs:使用可变关键字参数形式传参
p2 = mp.Process(target=task_take_arg,kwargs={“msg”:“hogwarts”,“n”:5})
p1.start()
p1.join()
p2.start()
p2.join()
print("main run……")
if name == ‘main’:
create_process()
运行结果如下图:
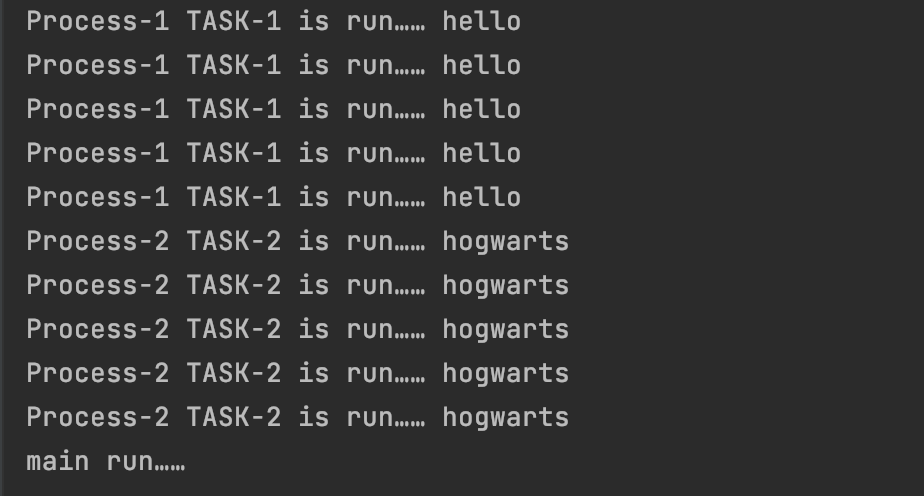
#2.2.6 守护进程
#若需要子进程在父进程执行结束后就结束执行,无论子进程是否执行完毕,可以将子进程设置为守护进程。比如只有开启企业微信时,才能使用企业微信的会议功能,
#当企业微信退出时,会议也会随之退出。设置守护进程方式有2种:
#使用子进程.daemon = True在子进程启动之前将子进程设置为守护进程
#使用子进程.terminate()在主进程退出前手动将子进程结束
def task_take_arg(n,msg):
for i in range(n):
if mp.current_process().name==‘Process-1’:
print(mp.current_process().name,“TASK-1 is run……”,msg,i)
else:
print(mp.current_process().name,"TASK-2 is run……",msg,i)
time.sleep(0.2)
def create_process():
# args:使用可变位置参数形式传参
p1 = mp.Process(target=task_take_arg,args=(10,“hello”))
# kwargs:使用可变关键字参数形式传参
p2 = mp.Process(target=task_take_arg,kwargs={“msg”:“hogwarts”,“n”:10})
print(“main run……”)
#方法一:设置子进程为守护进程
# p1.daemon = True
# p2.daemon = True
p1.start()
p2.start()
time.sleep(1)
#方法二:手动杀死子进程
p1.terminate()
p2.terminate()
print(“main over”)
if name == ‘main’:
create_process()
运行结果如下:
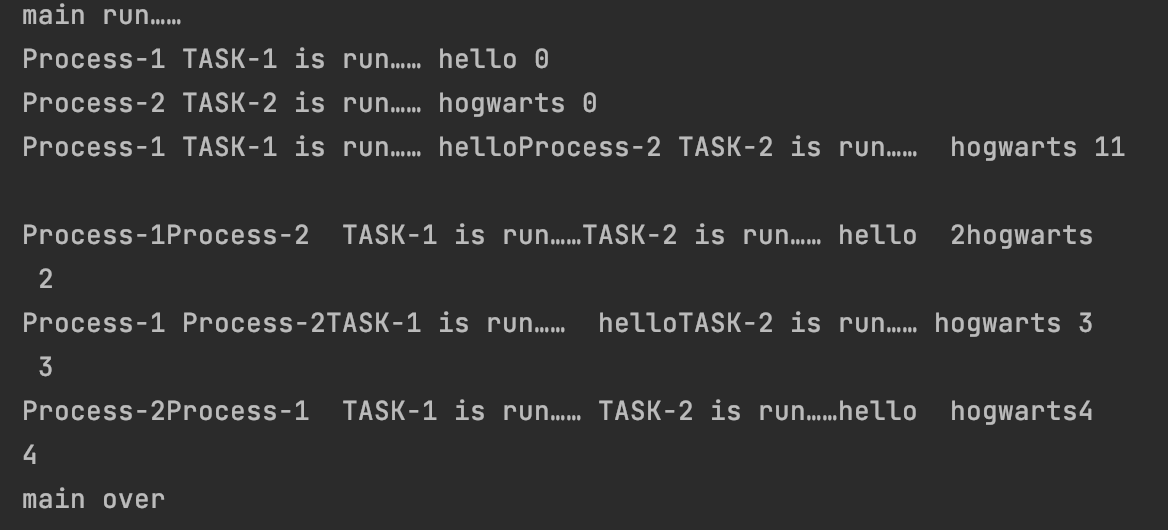
#2.2.7 进程间不共享全局变量
#因为进程是程序执行的最小资源分配单位,当一个进程被创建时,子进程会复制父进程的资源,形成一个独立的空间,所以多个进程之间的数据是独立不共享的
import time
#定义全局变量
g_list = list()
#添加数据的任务
def add_data():
for i in range(5):
g_list.append(i)
print(“add:”,i)
time.sleep(0.2)
print(“add data:”,g_list)
def read_data():
print(“read_data:”,g_list)
def create_task():
p1 = mp.Process(target=add_data)
p2 = mp.Process(target=read_data)
p1.start()
p1.join()
p2.start()
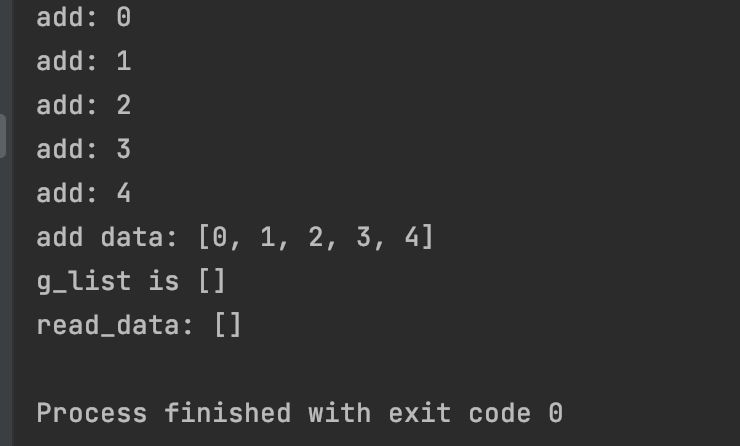
print("g_list is",g_list)
if name == ‘main’:
create_task()
运行结果如下:
第三部分:多任务线程编程
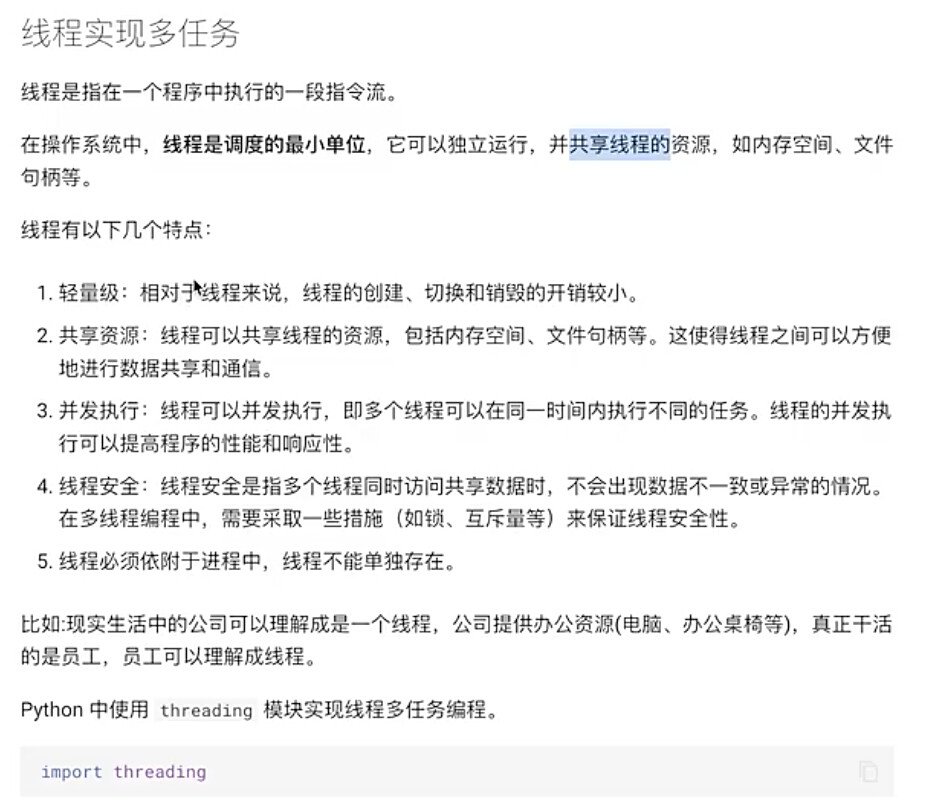
#3.1 线程的概念
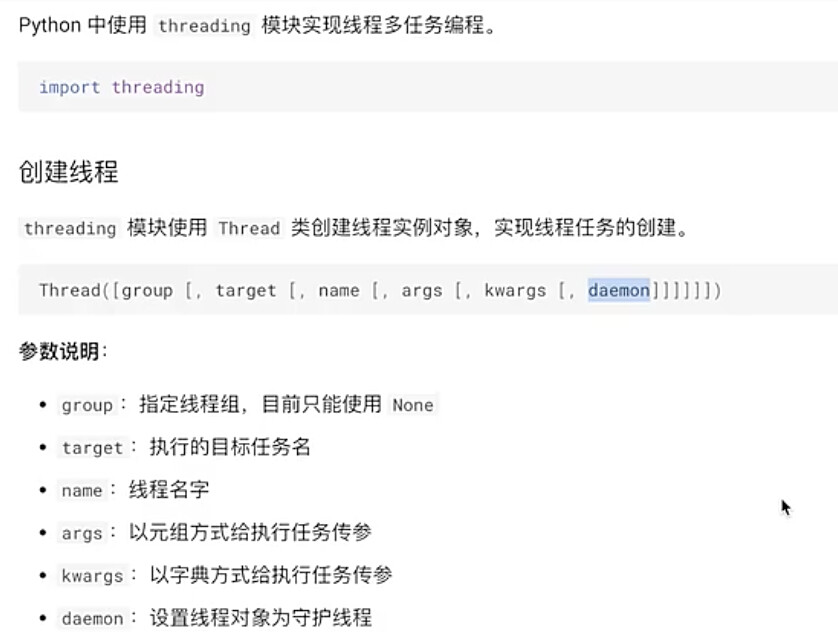
#3.2 线程的创建,启用及属性

import threading
def task1():
for i in range(10):
print(threading.current_thread().name,f"第{i}次运行",“Task-1 run……”)
time.sleep(0.5)
def task2():
for i in range(10):
print(threading.current_thread().name, f"第{i}次运行", “Task-2 run……”)
time.sleep(0.5)
def create_task():
t1 = threading.Thread(target=task1,name=“Mythread-1”)
t2 = threading.Thread(target=task2)
t1.start()
t2.start()
print(threading.current_thread())
if name == ‘main’:
create_task()
部分运行结果为:
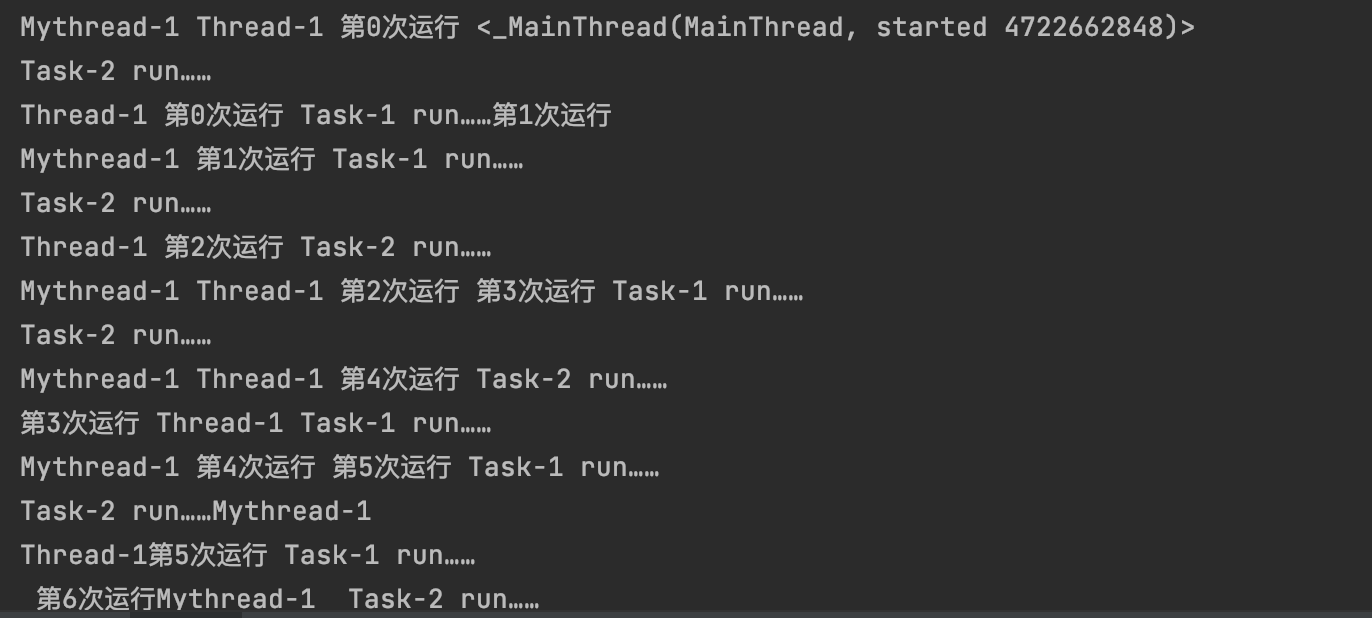
#3.3 线程无序性

import threading
def task3():
time.sleep(1)
print(“当前线程:”,threading.current_thread().name)
def create_task3():
for i in range(5):
p = threading.Thread(target=task3)
p.start()
if name == ‘main’:
create_task3()
运行结果为:
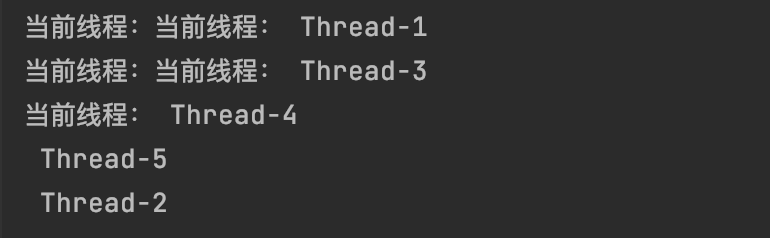
#3.4 线程任务函数传参

def task_take_arg(n,msg):
for i in range(n):
if threading.current_thread().name==‘Thread-1’:
print(threading.current_thread().name,“TASK-1 is run……”,msg,i)
else:
print(threading.current_thread().name,"TASK-2 is run……",msg,i)
time.sleep(0.2)
def create_task():
# args:使用可变位置参数形式传参
t1 = threading.Thread(target=task_take_arg,args=(10,“hello”))
# kwargs:使用可变关键字参数形式传参
t2 = threading.Thread(target=task_take_arg,kwargs={“msg”:“hogwarts”,“n”:10})
print(“main run……”)
t1.start()
t2.start()
print("main over")
if name == ‘main’:
create_task()
部分运行结果为:
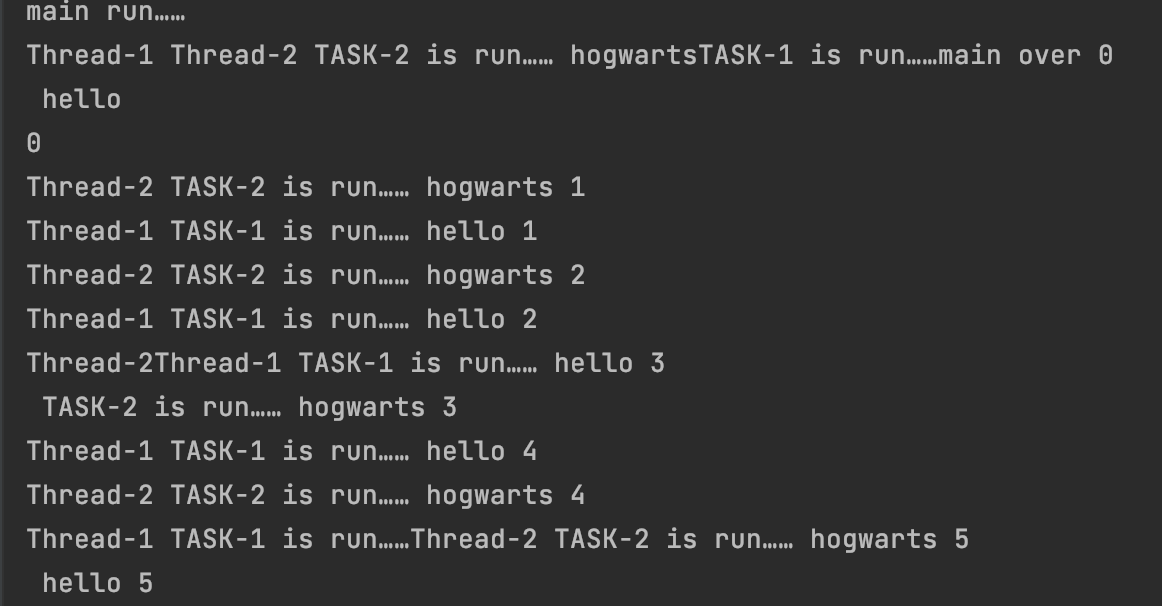
#3.5 线程同步

import threading
def task_take_arg(n,msg):
for i in range(n):
if threading.current_thread().name==‘Thread-1’:
print(threading.current_thread().name,“TASK-1 is run……”,msg,i)
else:
print(threading.current_thread().name,"TASK-2 is run……",msg,i)
time.sleep(0.2)
def create_task():
# args:使用可变位置参数形式传参
t1 = threading.Thread(target=task_take_arg,args=(10,“hello”))
# kwargs:使用可变关键字参数形式传参
t2 = threading.Thread(target=task_take_arg,kwargs={“msg”:“hogwarts”,“n”:10})
print(“main run……”)
t1.start()
t1.join()
t2.start()
t2.join()
print("main over")
if name == ‘main’:
create_task()
部分运行结果:
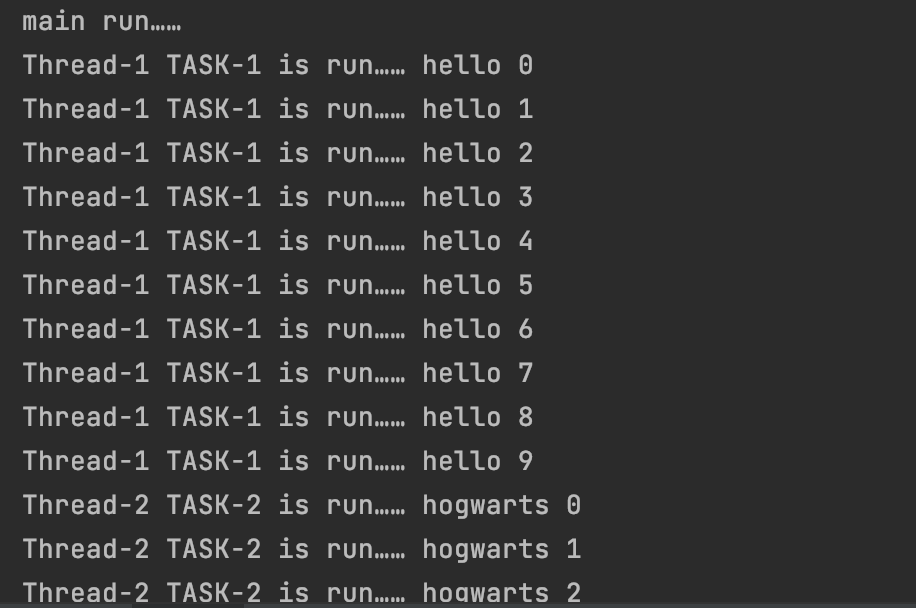
#3.6 守护线程

import threading
def task_take_arg(n,msg):
for i in range(n):
if threading.current_thread().name==‘Thread-1’:
print(threading.current_thread().name,“TASK-1 is run……”,msg,i)
else:
print(threading.current_thread().name,"TASK-2 is run……",msg,i)
time.sleep(0.2)
def create_task():
# 第一种方式,定义线程的时候设置为守护线程
t1 = threading.Thread(target=task_take_arg,args=(10,“hello”),daemon=True)
t2 = threading.Thread(target=task_take_arg,kwargs={“msg”:“hogwarts”,“n”:10})
# 第二种方式,手动设置守护线程
t2.daemon = True
print(“main run……”)
t1.start()
t2.start()
time.sleep(1)
print("main over")
if name == ‘main’:
create_task()
运行结果:
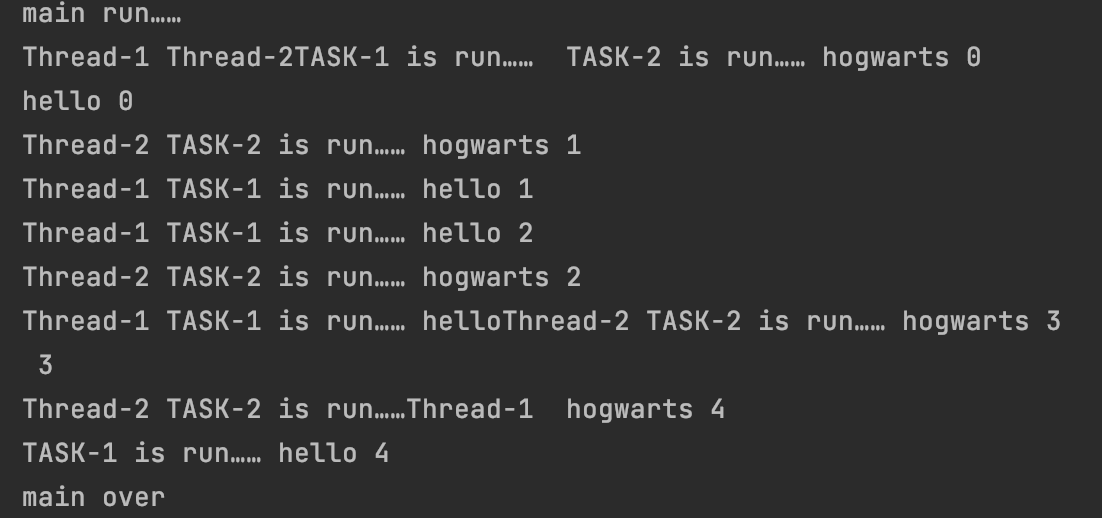
#3.7 线程间共享全局变量
因为线程是程序执行的最小单位,当一个子线程被创建时,子线程会在当前进程中复制父线程的资源,所以多个线程之间的数据是共享的。备注:下面截图中的文字描述不准确。

import threading
import time
#定义全局变量
g_list = list()
#添加数据的任务
def add_data():
for i in range(5):
g_list.append(i)
print(“add:”,i)
time.sleep(0.2)
print(“add data:”,g_list)
def read_data():
print(“read_data:”,g_list)
def create_task():
t1 = threading.Thread(target=add_data)
t2 = threading.Thread(target=read_data)
t1.start()
t1.join()
t2.start()
print("g_list is",g_list)
if name == ‘main’:
create_task()
运行结果为:
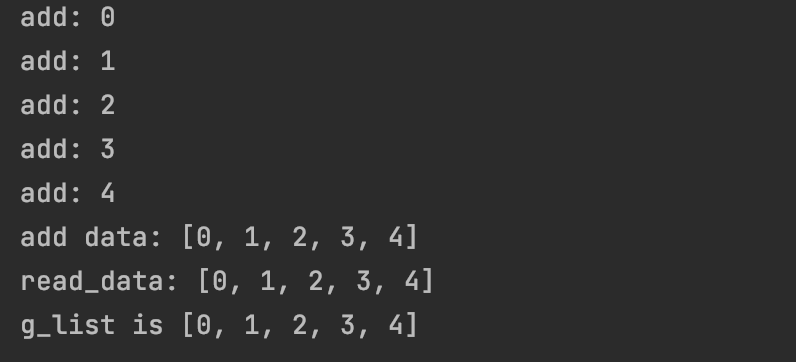
#3.8 线程安全问题

import threading
sum = 0
def add_one():
global sum
for i in range(1000001):
sum += 1
print(f"当前线程:{threading.current_thread().name} 运行结果:",sum)
def create_task():
t1 = threading.Thread(target=add_one)
t2 = threading.Thread(target=add_one)
t3 = threading.Thread(target=add_one)
t1.start()
t2.start()
t3.start()
time.sleep(2)
print(“计算结果为:”,sum)
if name == ‘main’:
create_task()
运行结果为:
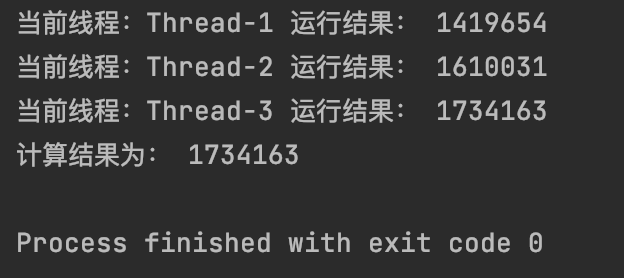
#3.9 互斥锁
import threading
sum = 0
#定义全局锁
lock = threading.Lock()
def add_one():
global sum
#加锁
lock.acquire()
for i in range(1000000):
sum += 1
#解锁
lock.release()
print(f"当前线程:{threading.current_thread().name} 运行结果:",sum)
def create_task():
t1 = threading.Thread(target=add_one)
t2 = threading.Thread(target=add_one)
t3 = threading.Thread(target=add_one)
t1.start()
t2.start()
t3.start()
time.sleep(2)
print(“计算结果为:”,sum)
if name == ‘main’:
create_task()
运行结果为:

#3.10 死锁

import threading
numbers = [3,6,8,1,9]
lock = threading.Lock()
def get_value(index):
lock.acquire()
if index >= len(numbers):
print(f"线程{threading.current_thread().name} 下标越界!“)
return
else:
num = numbers[index]
print(f"线程{threading.current_thread().name} 下标值为:”,num)
lock.release()
def create_task():
for i in range(10):
#注意下面的写法,只有一个参数要用元祖的方式进行传参,不然会报错
t = threading.Thread(target=get_value,args=(i,))
t.start()
if name == ‘main’:
create_task()
运行结果:
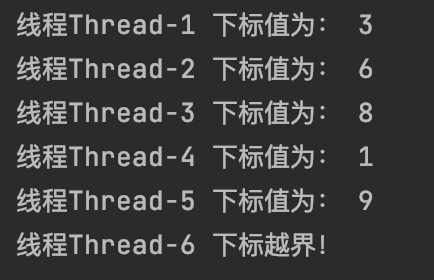
结果分析:当第6个线程运行出现下标越界之后,函数直接return了,没有释放锁,出现了死锁,然后第7-10个线程被阻塞一直等待,所以不会被执行。
代码修改为:
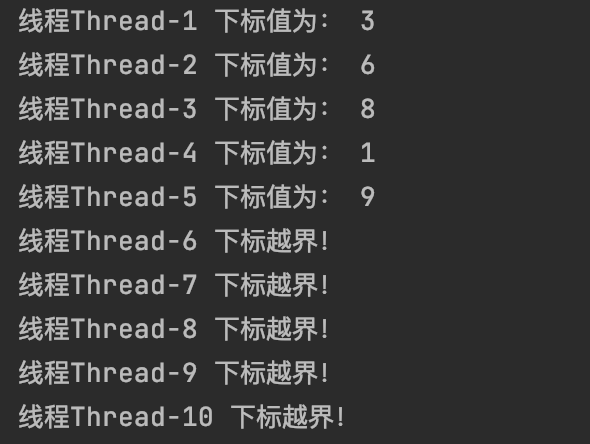
运行结果为:
#3.11 进程与线程对比

第四部分:多任务协程编程
第五部分:网络编程

#5.1 IP地址与端口概念

#5.2 常用通信协议



#5.3 使用Socket实现网络编程

#5.3.1 Socket客户端开发流程
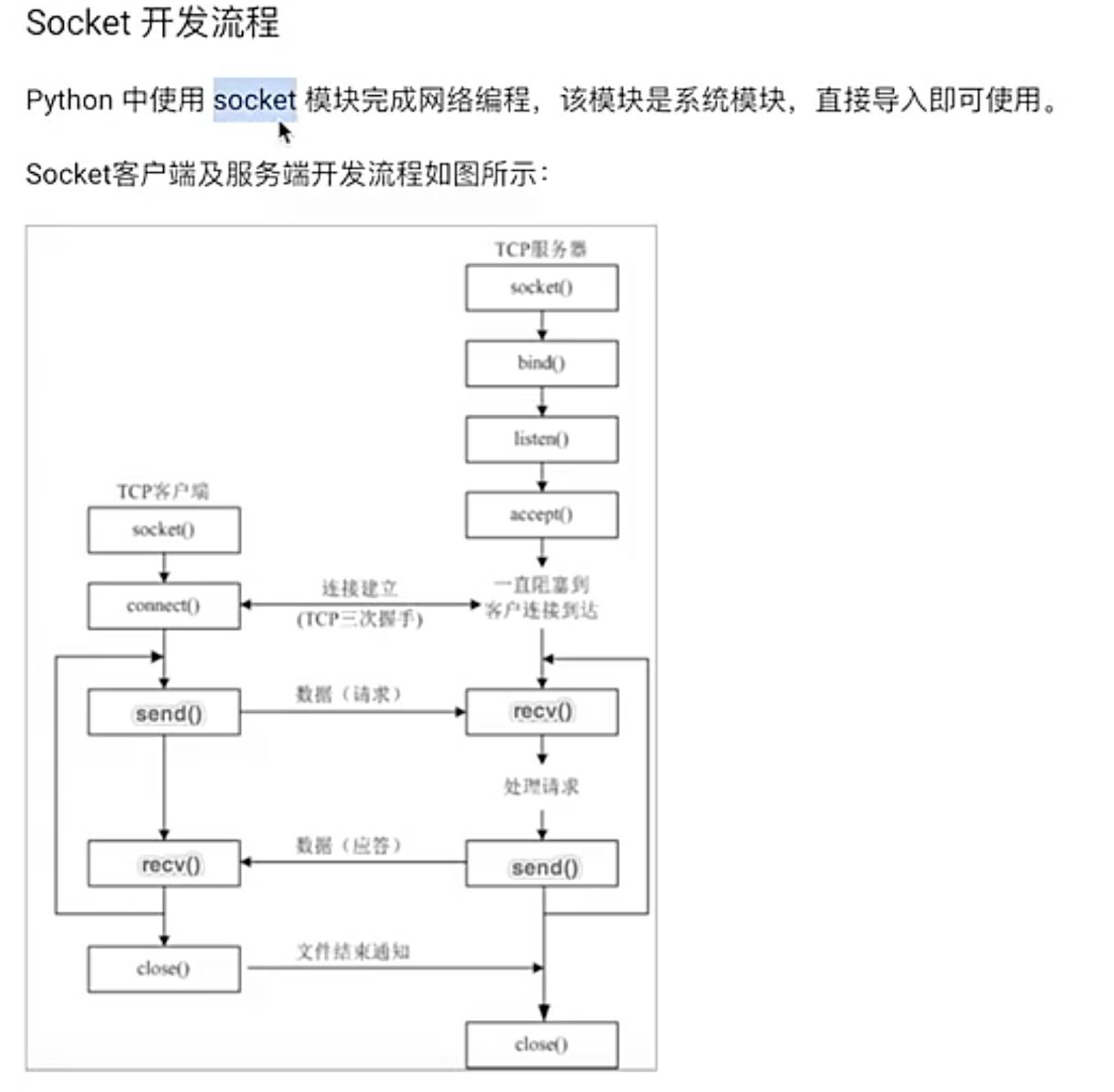

#代码实现 使用Socket实现网络编程-客户端
import socket
#1.创建套接字 socket.AF_INET为IPV4协议,socket.SOCK_STREAM为字节流
client_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
#2.建立连接 注意:这里需要用元祖的形式传IP和端口
client_socket.connect((‘127.0.0.1’,8888))
#3.发送数据 注意:socket是以字节流形式传输,所以需要转码
send_data = “Hello hogwarts!哈利.波特”.encode(‘utf-8’)
client_socket.send(send_data)
#4.接受数据 注意:socket是以字节流形式传输,所以需要解码才能正常显示不乱码
recv_data = client_socket.recv(1024)
print(recv_data.decode(‘utf-8’))
#5.关闭连接
client_socket.close()
运行结果为:
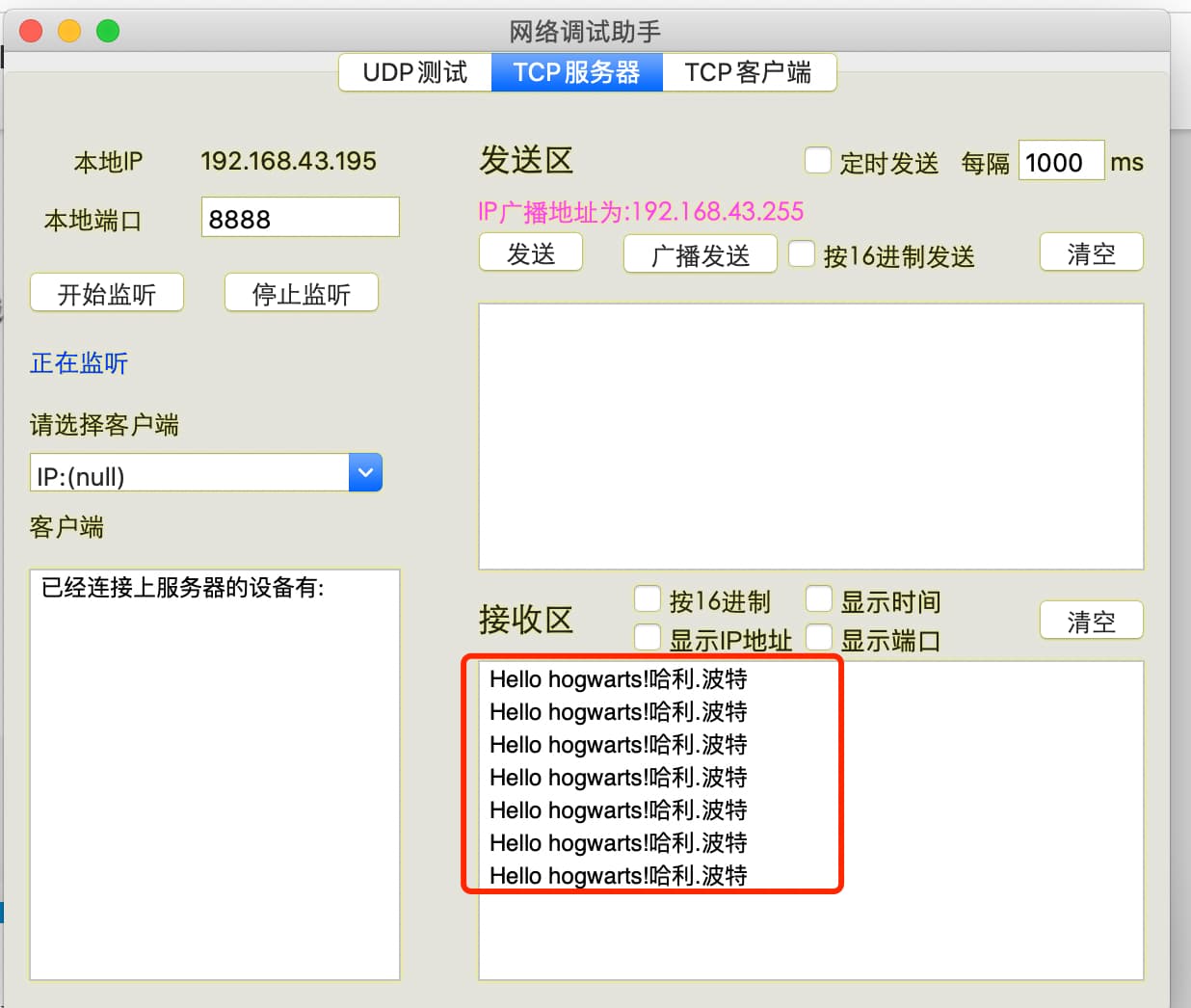
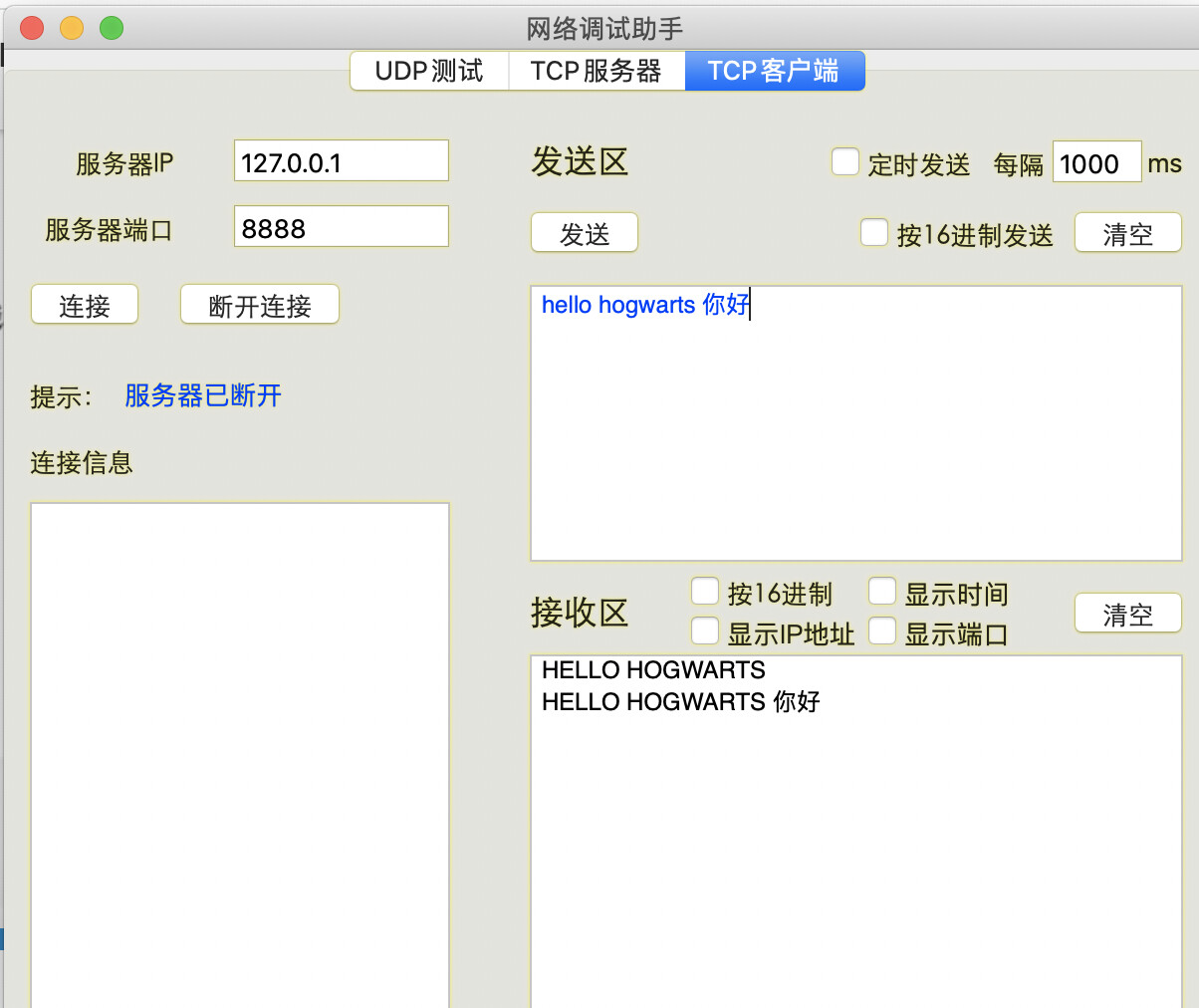
网络调试助手(需提前下载安装)收到的信息截图如下:
#5.3.2 socket服务端开发流程

#代码实现:Socket实现网络编程-服务端
import socket
#1.创建服务端套接字对象
server = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
#2.设置端口复用(非必须选项,因端口在本地使用一次之后短时间内不能重复使用,故需要设置)
server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEPORT,True)
#3.绑定端口号 注意:和客户端类似,绑定的IP和端口也是以元祖形式传参
server.bind((‘127.0.0.1’,8888))
#4.设置监听 备注:需要设置最大连接的客户数,这里设为128
server.listen(128)
print(“服务端启动成功,等待客户端连接……”)
#5.等待接受客户端的连接
client,IP = server.accept()
print(f"客户端使用 IP:{IP[0]} 端口号:{IP[1]} 连接成功……“)
#6.接收客户端的数据 注意:编码方式在utf-8或gbk之间灵活选择
recv_data = client.recv(1024).decode(‘gbk’)
print(f"收到客户端的数据为:{recv_data} 数据长度为:{len(recv_data)}”)
#7.向客户端发送数据 注意:给客户端发送数据,是使用建立连接之后的client,这样才能知道向哪个客户端
send_data = recv_data.upper().encode(‘gbk’)
client.send(send_data)
#8.关闭客户端套接字连接
client.close()
#9.关闭服务端套接字连接
server.close()
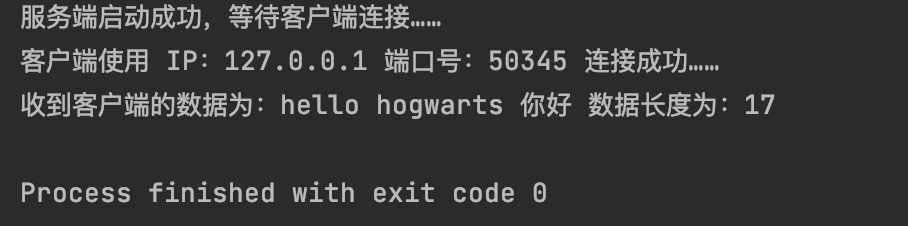
运行结果截图:
网络调试助手截图:

多线程编程实现demo:
import threading
import socket
class MultiServer(object):
def init(self,port,ip=‘127.0.0.1’,):
self.ip = ip
self.port = port
#1.创建服务端套接字
self.server = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
#2.设置端口复用
self.server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEPORT,True)
#3.服务器绑定IP和端口
self.server.bind((self.ip,self.port))
#4.服务器开始监听,设定监听数量
self.server.listen(128)
def run(self):
print("服务端启动成功……")
while True:
#5.等待接受客户端连接
client,IP = self.server.accept()
print(f"客户端使用IP: {IP[0]} 端口号:{IP[1]} 连接成功")
t = threading.Thread(target=self.hand_thread,args=(client,IP))
t.daemon = True
t.start()
# 8.服务端断开套接字
# self.server.close()
def hand_thread(self,client,IP):
#6.接收客户端发送过来的数据并解码,指定接受的最大长度为1024
recv_data = client.recv(1024).decode('gbk')
print(f"接收到客户端发送过来的数据为{recv_data},数据长度为{len(recv_data)}")
#7.发送数据给客户端
send_data = recv_data.upper().encode('gbk')
client.send(send_data)
# 7.客户端断开套接字
client.close()
#思考如何让客户端一直可以发送数据
if name == ‘main’:
multi = MultiServer(8888)
multi.run()
第六部分:数据库操作

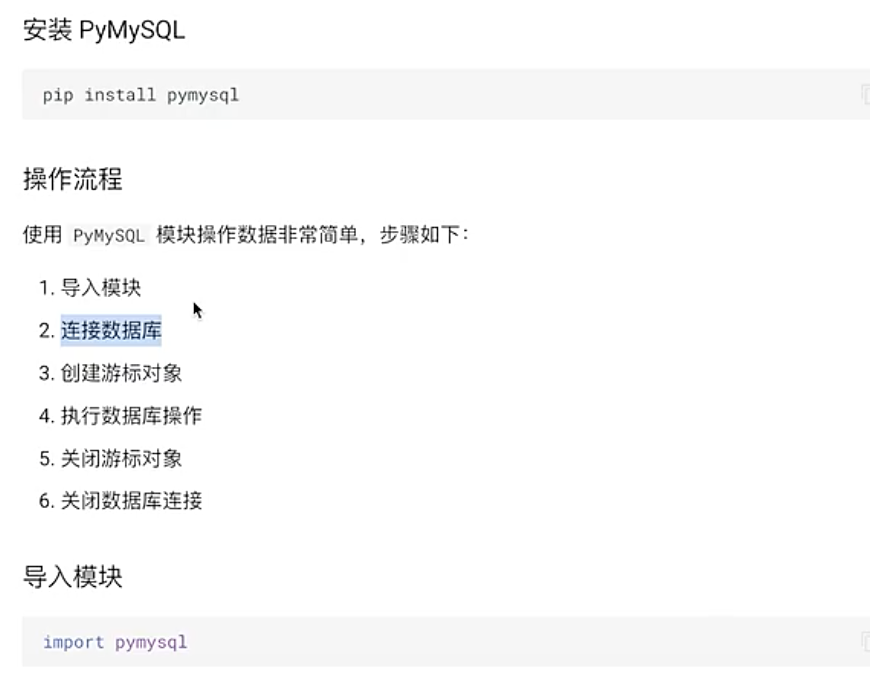
#6.1 数据库连接创建 使用完成后记得关闭连接
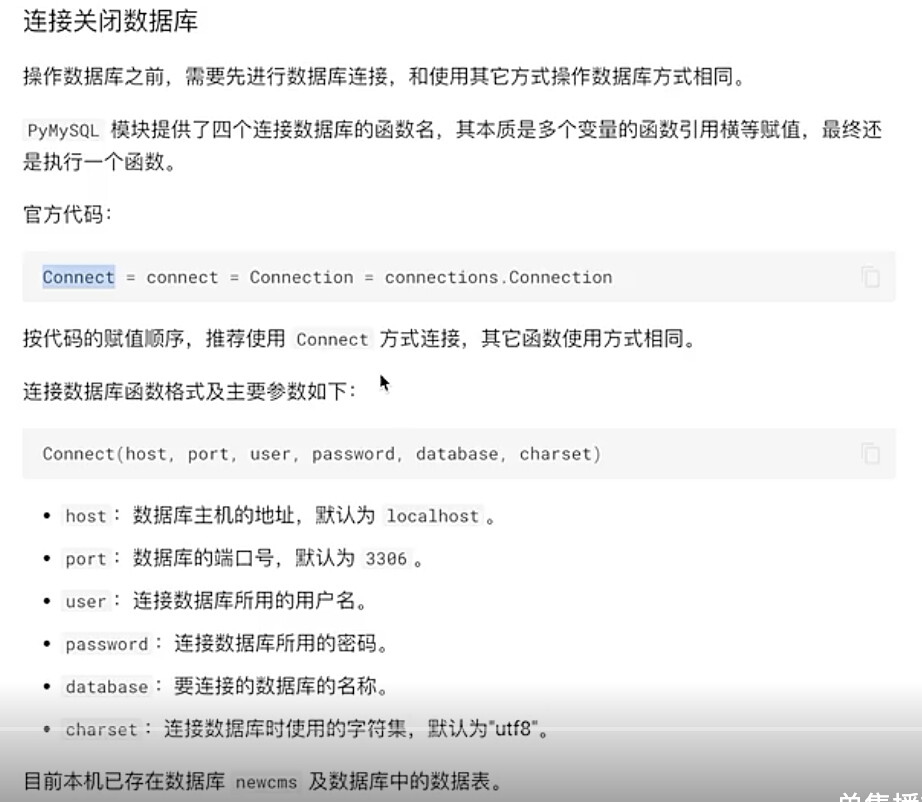
import pymysql
db_connect = pymysql.Connection(host=‘101.132.159.87’,port=3306,user=‘petclinic’,password=‘petclinic’,database=‘petclinic’,charset=‘utf8’)
db_connect.close()
#6.2 游标对象使用 使用完成后记得关闭cursor
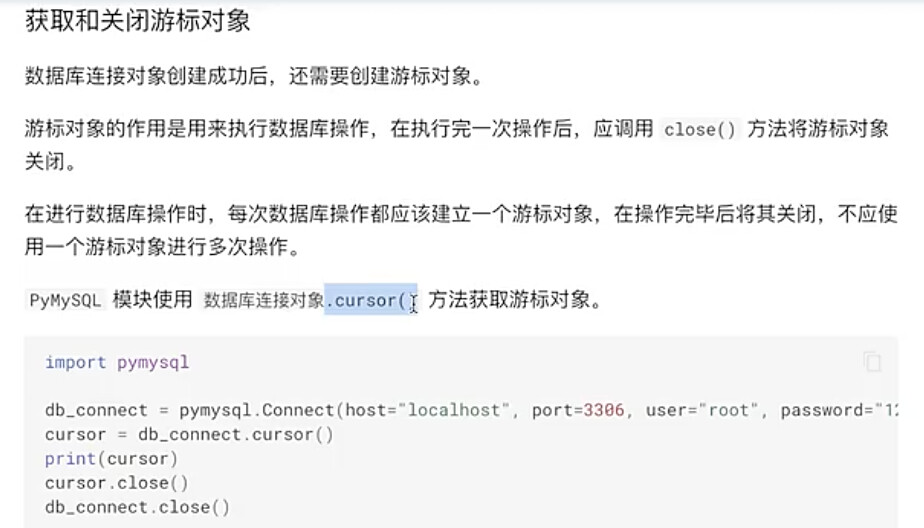
cursor = db_connect.cursor()
cursor.close()
#6.3 查询操作

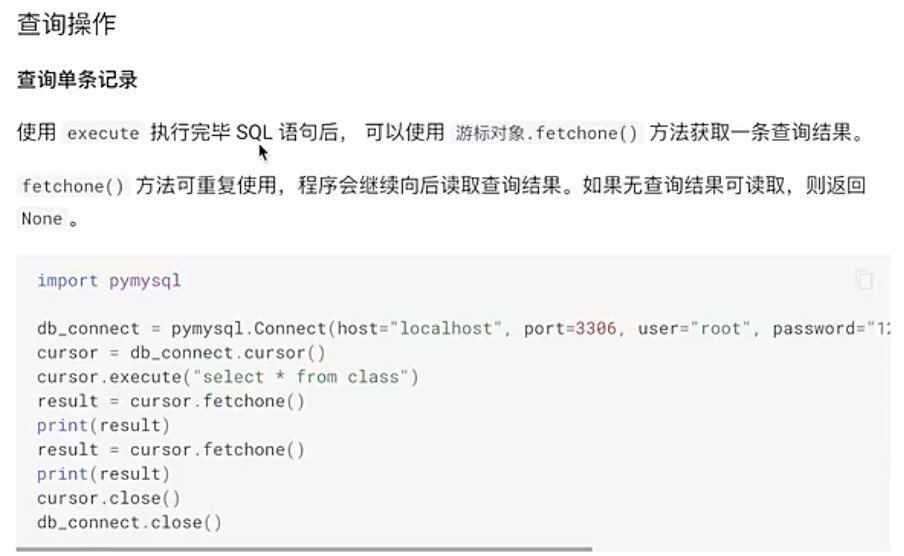
sql_str = ‘’‘select * from owners’‘’
cursor.execute(sql_str)
#获取单条查询结果
result = cursor.fetchone()
print(result)
#获取全部查询结果
result = cursor.fetchall()
print(result)
#获取指定条数如3条查询结果
result = cursor.fetchmany(3)
print(result)
部分执行结果如下:

#6.4 插入操作 备注:在sql中使用%s代替值,真正的值用元祖存入另一个数据中
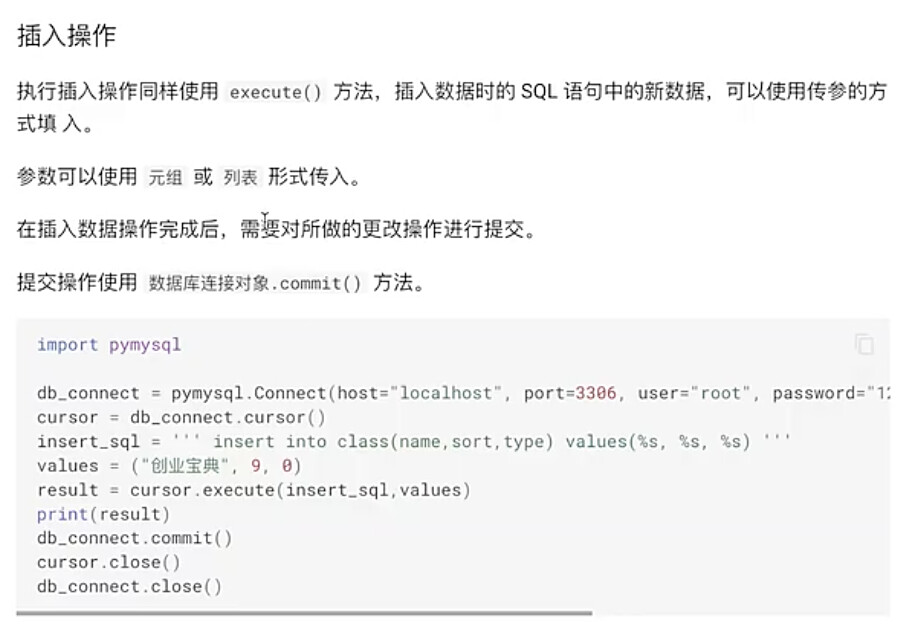
insert_sql = ‘’‘insert into owners (id,first_name,last_name ,address,city,telephone) values (%s,%s,%s,%s,%s,%s)’‘’
insert_sql_data = (9789,‘Aileen’,‘Fen’,‘111 w.liberty’,‘武汉’,‘6085551024’)
cursor.execute(insert_sql,insert_sql_data)
db_connect.commit()
执行结果:

数据库截图:

#6.5 更新操作
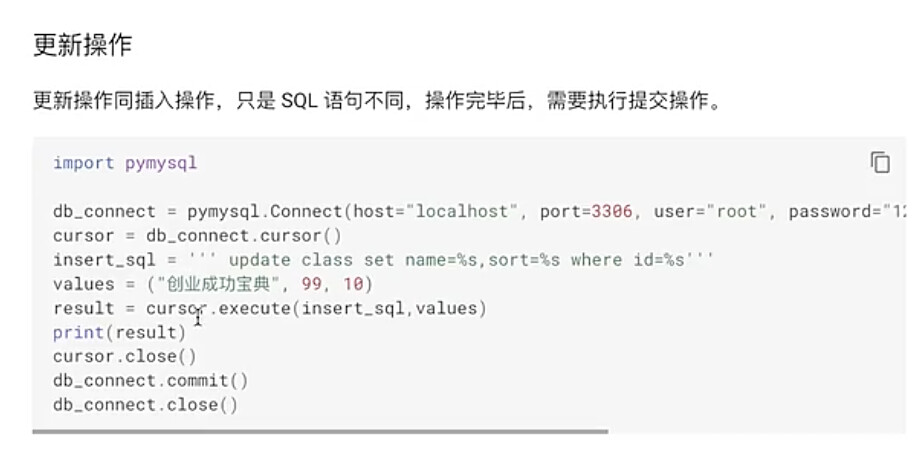
update_sql = ‘’‘update owners set first_name=%s where id=%s ‘’’
update_sql_data = (‘yangyang’,9789)
cursor.execute(update_sql,update_sql_data)
db_connect.commit()
数据库更新截图如下:
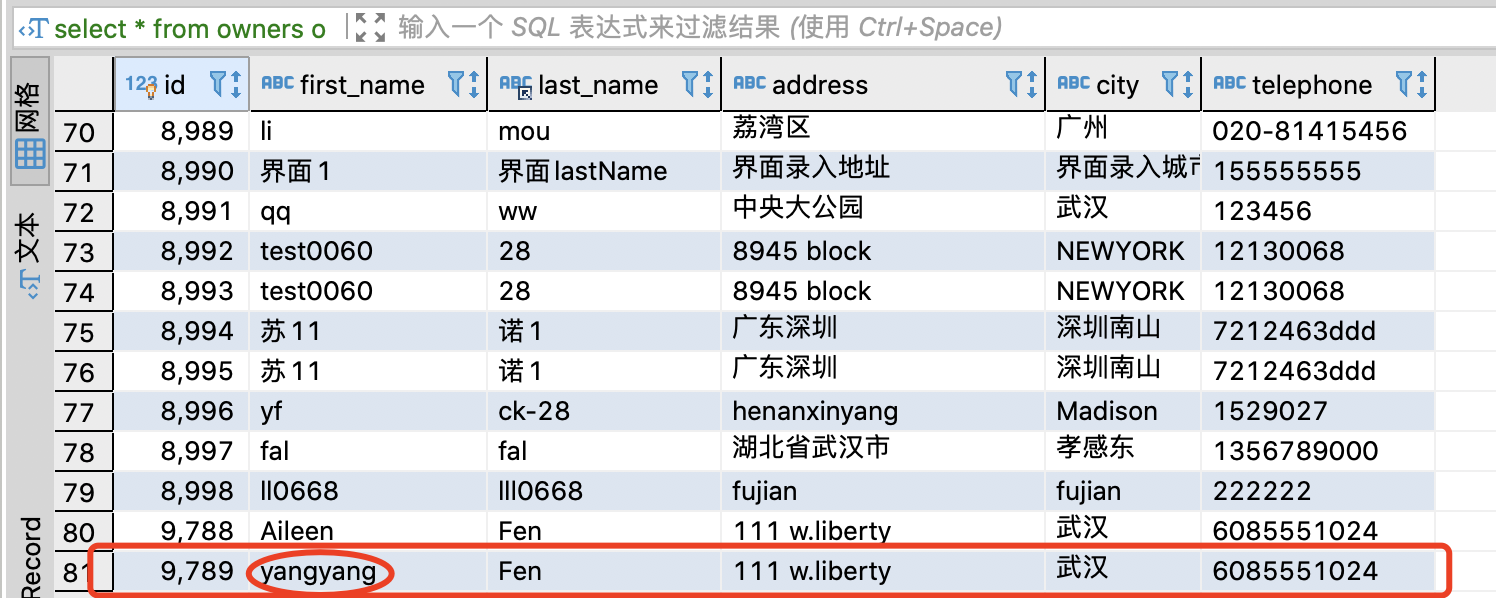
#6.6 删除操作
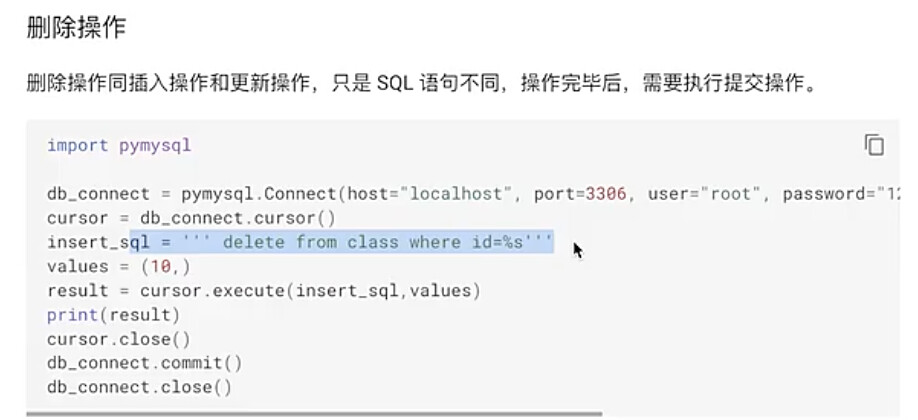
delete_sql = ‘’‘delete from owners where id = %s ‘’’
delete_sql_data = (9789,)
cursor.execute(delete_sql,delete_sql_data)
db_connect.commit()
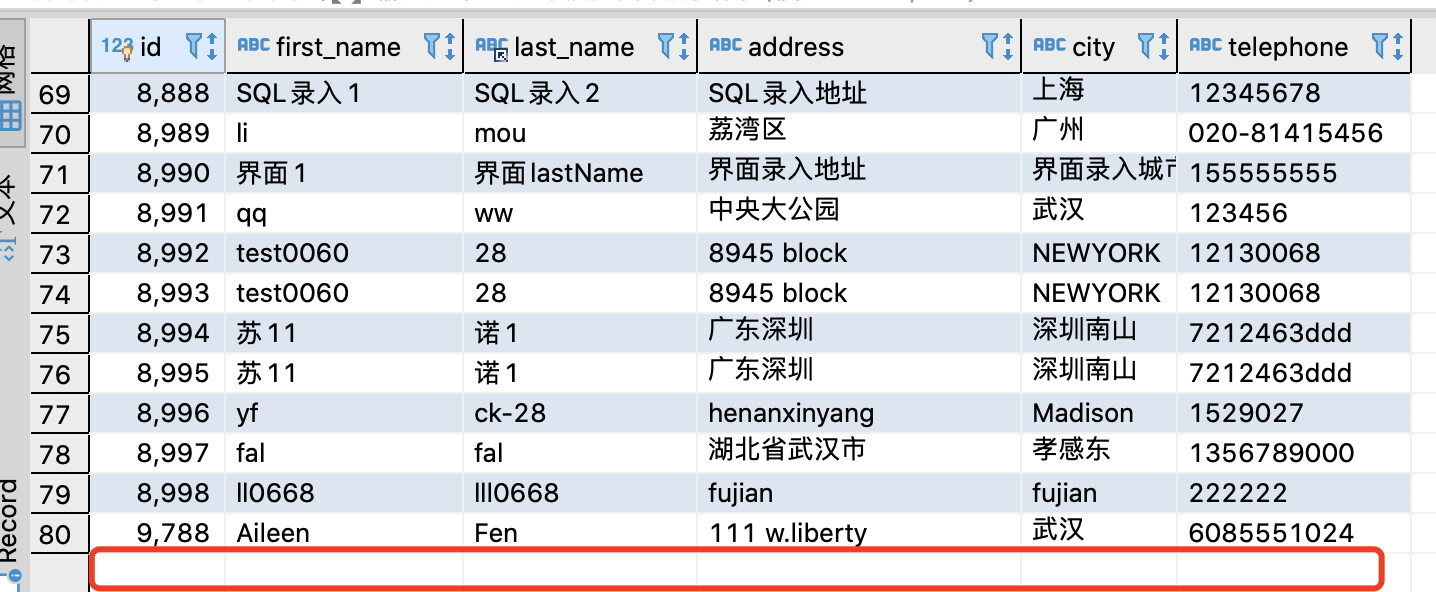
数据库数据更新截图:
第七部分:yaml文件处理
#7.1 什么是YAML文件

#7.2 为什么要使用YAML文件

#7.3 YAML的基本语法规则

#7.4 YAML的数据结构

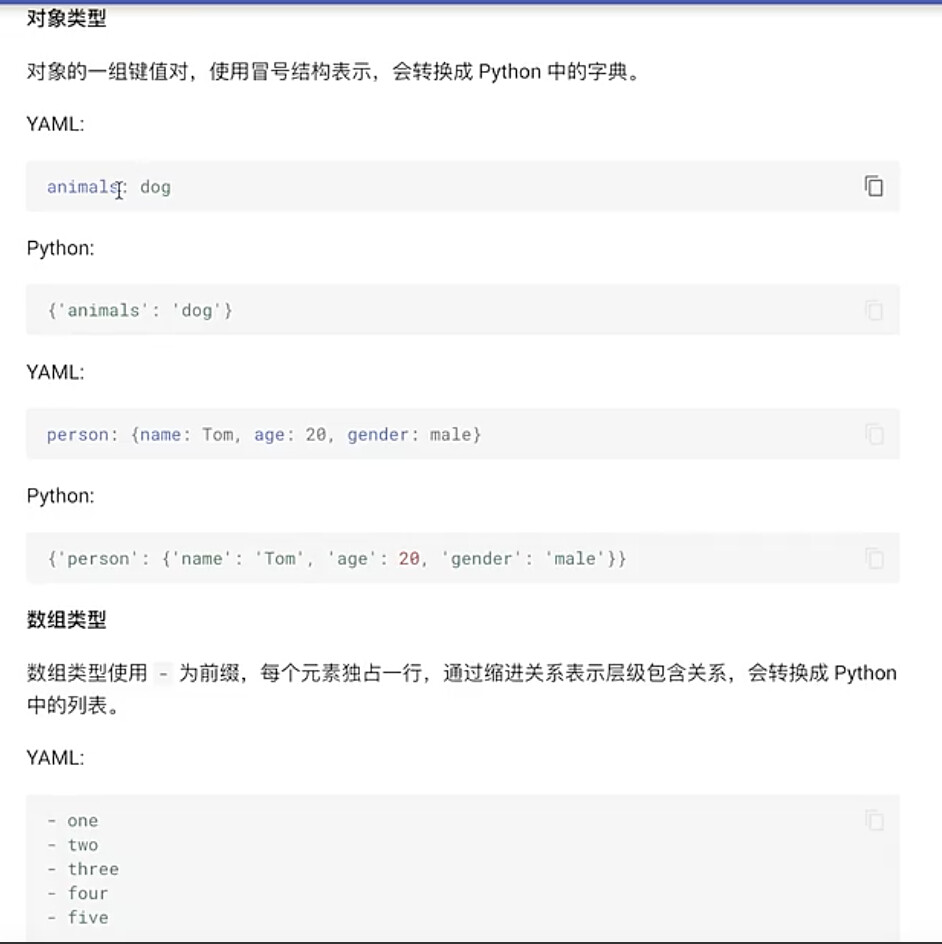
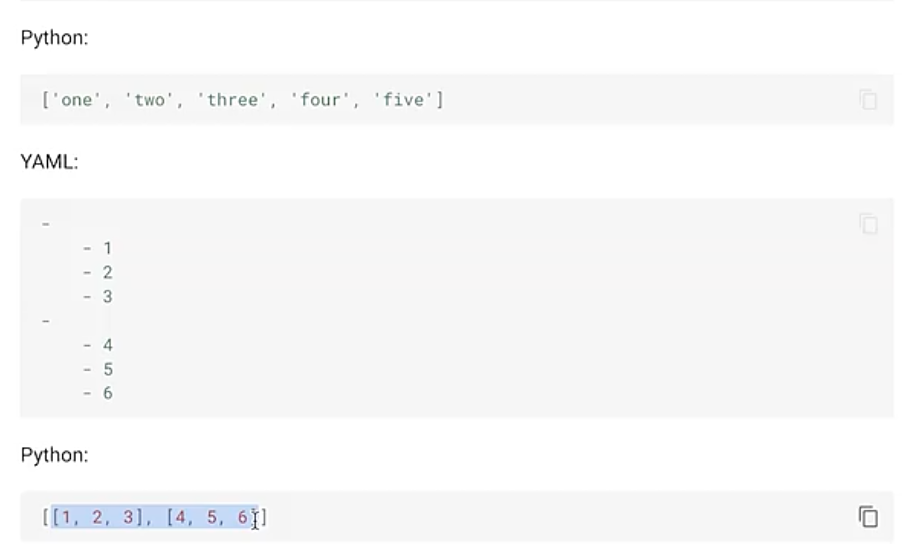

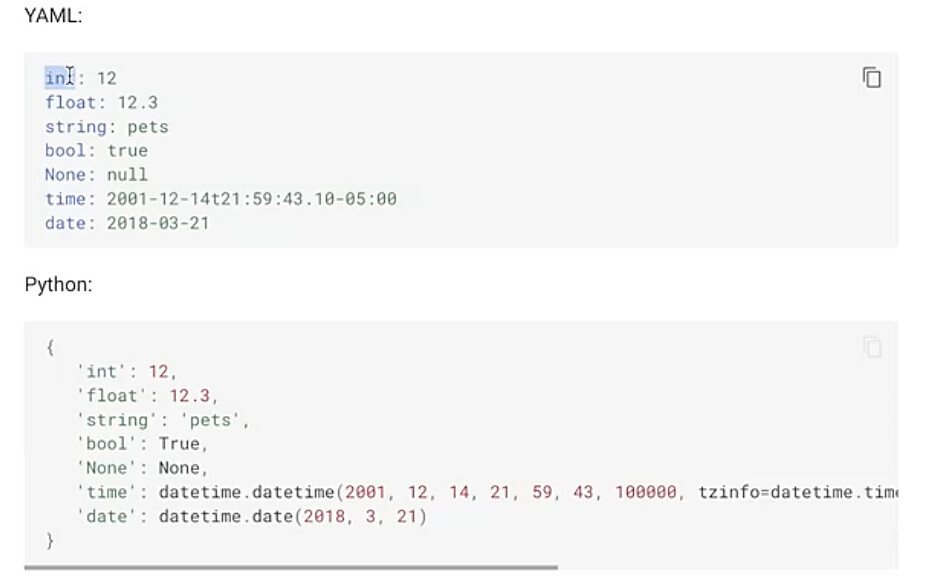
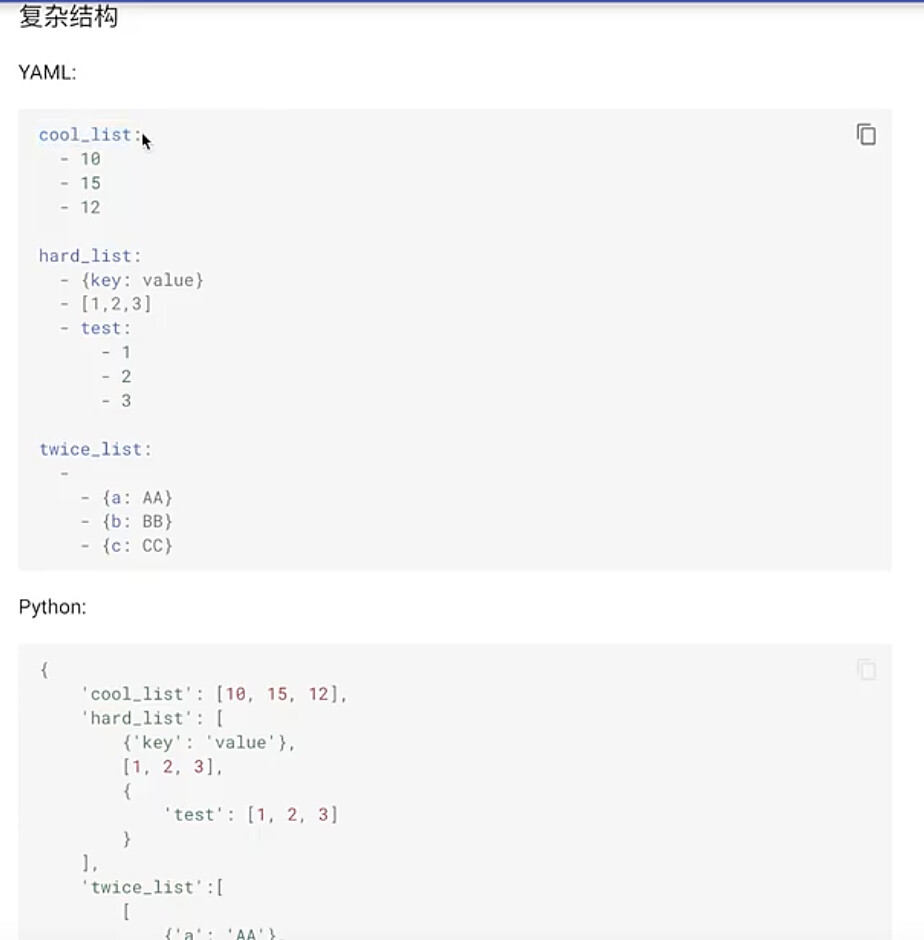

#7.5 YAML文件处理

python代码实现:
#从yaml文件中读取数据
import yaml
with open(‘data.yaml’, ‘r’) as file:
content = yaml.safe_load(file)
print(content)
for k,v in content.items():
print(k,v)
print(content[‘hard_list’][2][‘test’][2])
#向yaml文件写入数据
response_data = {
‘status_code’ : 200,
‘message’: ‘OK’,
“data”: [
{“accept5”:“.”},
{“accept4”:“.”},
{“accept3”: “.”},
{“accept2”: “.”},
{“accept1”: “.”},
{“content-type”:[“image/png”,“image/jpeg”,“image/gif”,“image/webp”]}
]
}
with open(‘writeyaml.yaml’,‘w’) as file:
yaml.safe_dump(response_data,file)
运行结果如下:
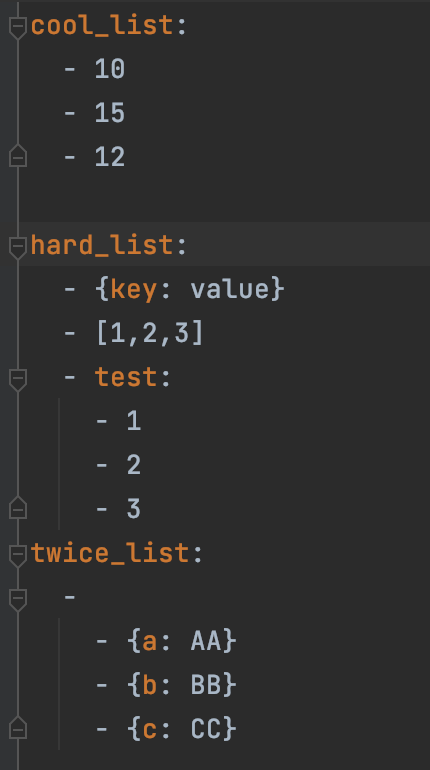
1、data.yaml文件数据如下,注意空格
2、程序运行结果如下:

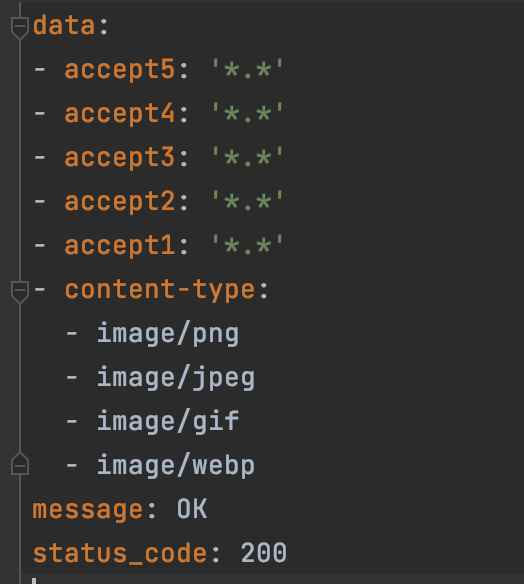
3、writeyaml.yaml文件结果如下:
第八部分:pytest测试框架
#8.1 Pytest简介

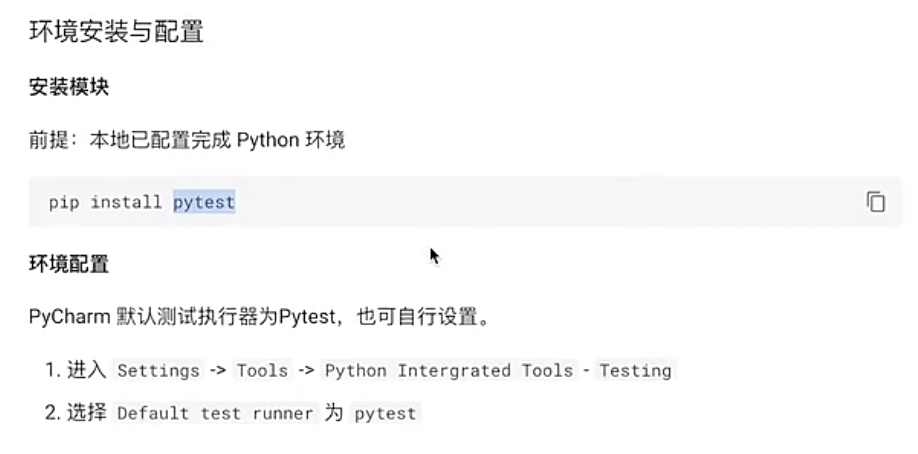
#8.2 环境安装与配置
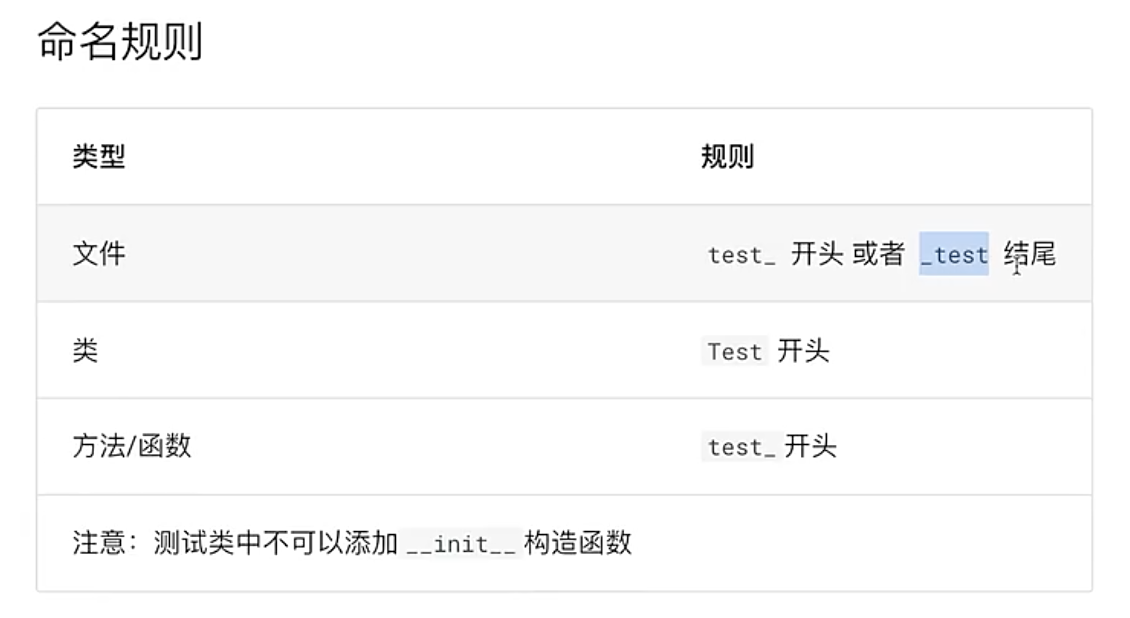
#8.3 命名规则
1)函数级别测试用例示例:

import pytest
def add_one(x):
return x+1
def test_answer1():
result = add_one(10)
assert result==11
def test_answer2():
result = add_one(10)
assert result==11
def test_answer3():
result = add_one(10)
assert result==12
运行结果:
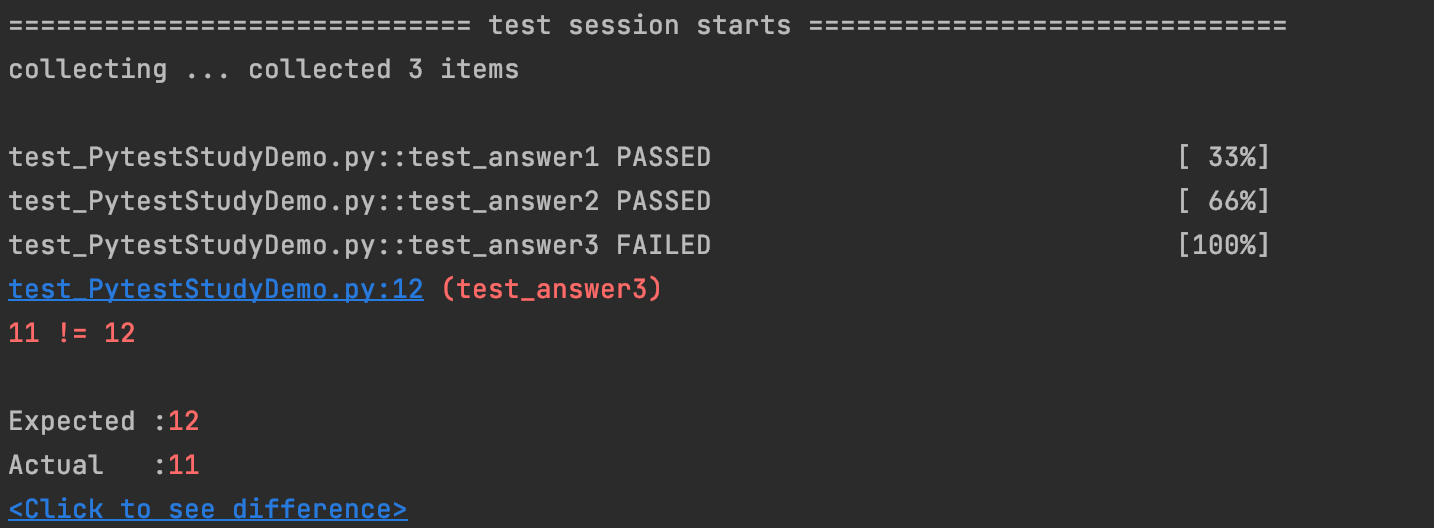
备注:和普通程序代码不一样,因为我们提前在tools中配置了pytest运行用例测试环境,测试用例执行器,虽然代码中没有写程序运行的入口,但是pytest在自动符合规则的程序当中(如以test_开头的文件名和test_开头的函数名),它会收集测试用例,并展示执行结果。
2)类级别测试用例示例:
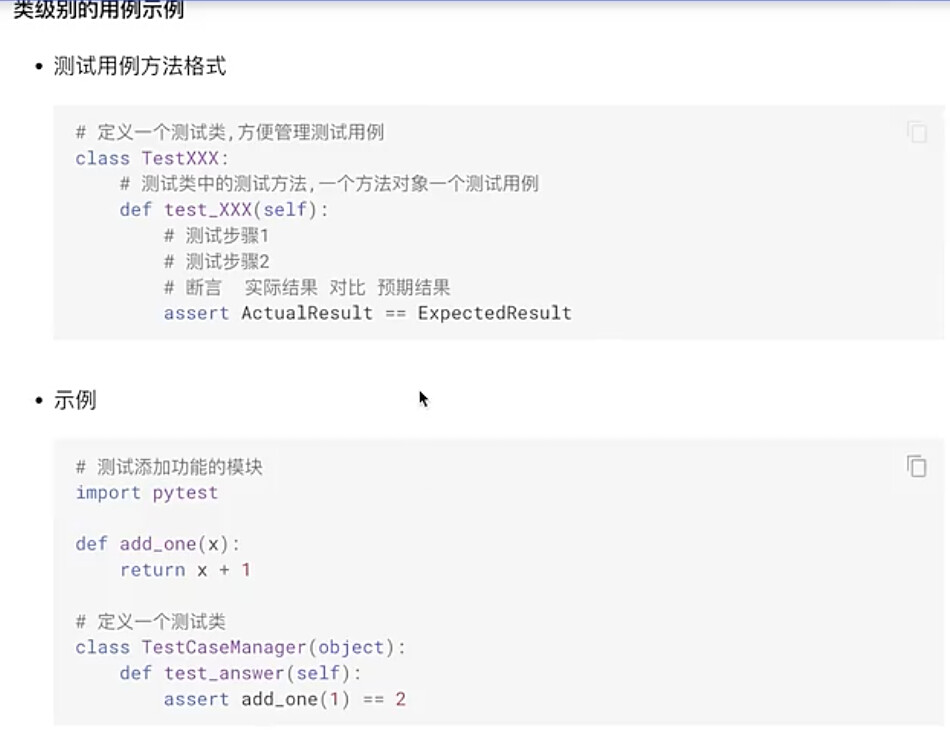
#8.3.1 类级别测试用例
class Test_Collection(object):
def test_add_one1(self):
result = add_one(10)
assert result==11
def test_add_one2(self):
result = add_one(10)
assert result==11
def test_add_one3(self):
result = add_one(10)
assert result==12
if name == “main”: #备注:加上这段话可以运行全部测试用例,不然程序会从光标所在位置的用例开始运行
pytest.main()
部分运行结果如下:

#8.4 断言
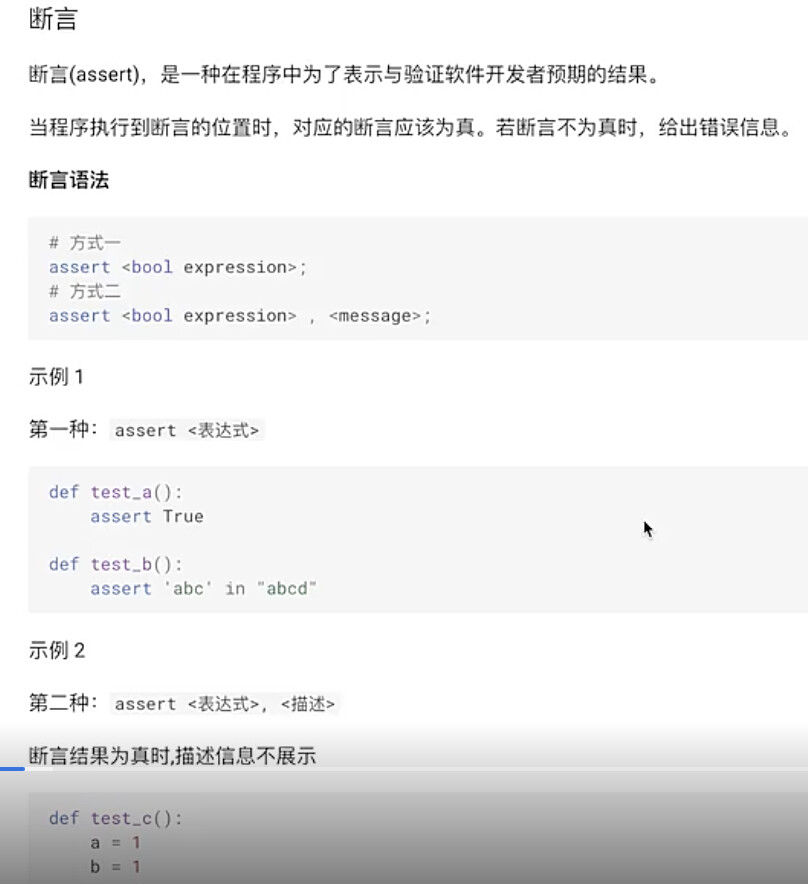

def test_a():
assert True
def test_b():
assert ‘abc’ in ‘abcd’
运行结果:
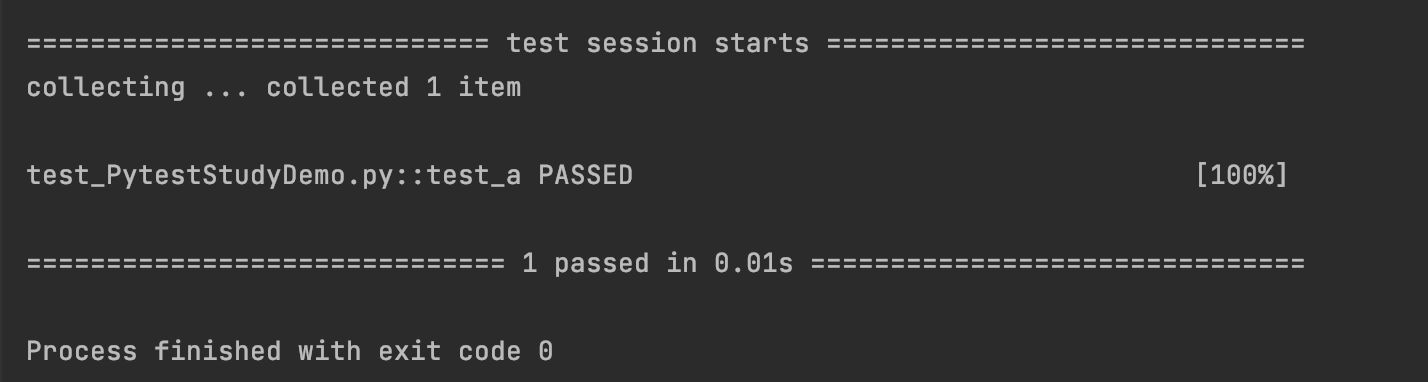
def test_c():
a = 1
b = 2
c = 21
assert a+b==c, f"{a}+{b}=={c},结果为假"
运行结果为:说明:f"{a}+{b}=={c},结果为假" 只在断言不通过的时候显示
#8.5 测试装置

import pytest
class TestCollections:
def setup_class(self):
print(“类级开始装置,只在类中所有用例执行前执行一次,一般用来初始化一次性的资源,比如数据库连接对象的创建”)
def teardown_class(self):
print(“类级结束装置,只在类中所有用例执行后执行一次,一般用来关闭一次性的资源,比如数据库连接对象的关闭”)
def setup(self):
print("方法/函数开始装置,只在每个用例执行前执行一次,一般用来初始化资源,比如数据库游标对象的创建")
def teardown(self):
print("方法/函数结束装置,只在每个用例执行后执行一次,一般用来关闭初始化资源,比如数据库游标对象的关闭")
def test_demo1(self):
print("demo1 is run")
def test_demo2(self):
print("demo2 is run")
def test_demo3(self):
print("demo3 is run")
运行结果:

#8.6 数据参数化
#参数化,使用装饰器实现参数化
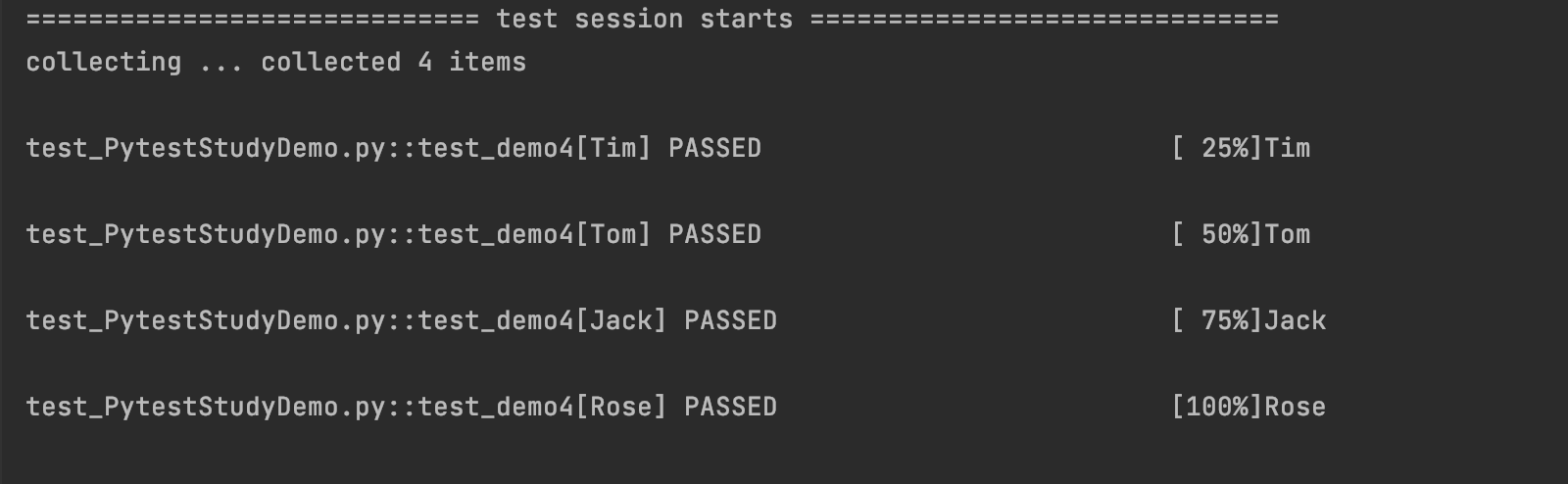
@pytest.mark.parametrize(‘msg’,[‘Tim’,‘Tom’,‘Jack’,‘Rose’])
def test_demo4(msg):
print(msg)
运行结果如下:
@pytest.mark.parametrize(‘a,b,r’,[[1,1,2],[1,2,3],[1,3,3]])
def test_demo5(a,b,r):
assert a+b == r
部分运行结果为:

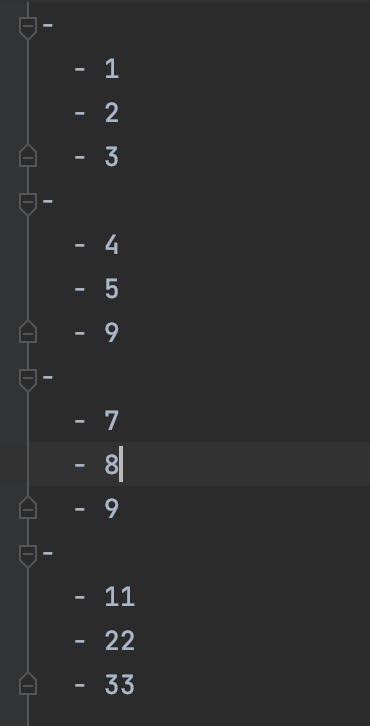
#8.7 使用YAML文件进行数据驱动测试

with open(‘data_demo6.yaml’,‘r’) as file:
data_demo6 = yaml.safe_load(file)
@pytest.mark.parametrize(‘a,b,r’,data_demo6)
def test_demo6(a,b,r):
assert a+b == r
运行结果:
1、data_demo6.yaml文件为:
2、程序运行部分结果为:

