一、grep-过滤文本
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
格式 :grep [options]
主要参数:
-
-A:显示匹配行及后面n行内容

-
-B:显示匹配行及前面n行内容

-
-C:显示匹配行及前后n行内容

-
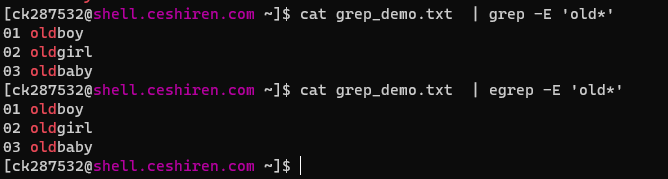
-E:扩展的正则表达式,相当于egrep(可以识别特殊正则符号)
-
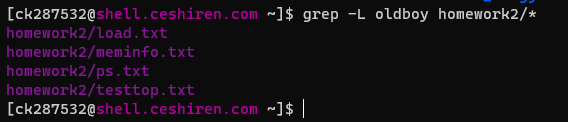
-l:列出匹配文件内容的文件名
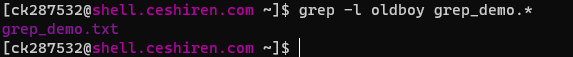
-
-L:列出不匹配文件内容的文件名
-
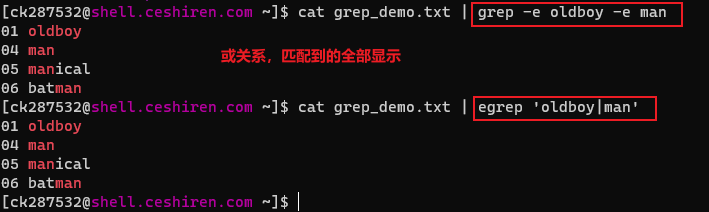
-e:实现多个选项间的逻辑or关系,或者使用egrep
grep -e '^abc' -e 'b$' oldboy.txt -
-i:字符忽略大小写

-
-c:统计匹配成功的行数

-
-n:显示匹配的行号

-
-r:进行递归查找子目录中的文件
-
-v:显示不被pattern匹配到的行,相当于[^]反向匹配(进行匹配信息取反过滤操作)

grep -v '^$':过滤空白行(^$ 表示从首到尾;-v取反,即该命令作用:过滤空白行/符) -
-o:只显示匹配到的字符串

-
-q:静默模式,不输出任何信息
-
-s:不显示错误信息

-
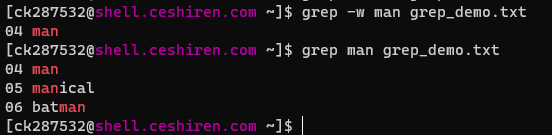
-w:只匹配整个单词,而不是字符串的一部分(如匹配‘magic’,而不是‘magical’)
-
–color:匹配到的关键词会高亮显示
grep xxx ---color=auto --- 查询关键字高亮显示 -
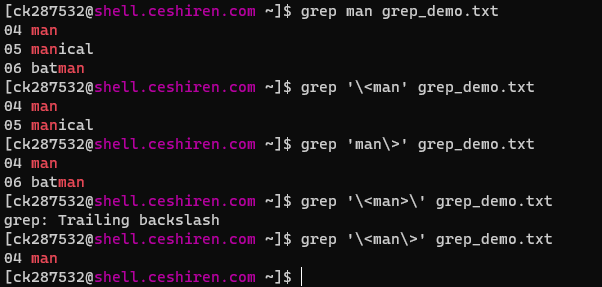
\<和\>分别标注单词的开始与结尾(类似模糊查询)

pattern正则表达式主要参数:
-
\: 忽略正则表达式中特殊字符的原有含义。 -
^:匹配正则表达式的开始行。 -
$: 匹配正则表达式的结束行。 -
\<:从匹配正则表达 式的行开始。 -
\>:到匹配正则表达式的行结束。 -
[ ]:单个字符,如[A]即A符合要求 。 -
[ - ]:范围,如[A-Z],即A、B、C一直到Z都符合要求 。 -
.:所有的单个字符。 -
*:有字符,长度可以为0
进程检索:
- 进程过滤场景比较特殊, grep 本身会开启新进程,所以需要单独过滤掉 grep 进程;
ps -ef | grep ssh | grep -v grep
二、awk-分段处理文本
- 用来处理文本,将文本按照指定的格式输出。其中包含了变量,循环以及数组。
- awk 具备完整的编程特性。比如执行命令,网络请求等
格式:
awk [选项] '匹配规则和{处理规则} ' [处理文本路径]
-
匹配规则:字符串、正则表达式,主要是正则表达式;
-
{处理规则}:
- 设置变量
- 设置数组
- 定义函数 (用的比较少)
- 数组循环
- 加减乘除运算
- 字符串拼接
awk pattern 匹配表达式案例
- 开始和结束
awk 'BEGIN{}END{}' - 正则匹配
- 整行匹配
awk '/Running/' - 字段匹配
awk '$2~/xxx/'
- 整行匹配
- 行数表达式
- 取第二行
awk 'NR==2' - 去掉第一行
awk 'NR>1'
- 取第二行
- 区间选择
awk '/aa/,/bb/'awk '/1/,NR==2'
1、工作原理
-
(1)awk会接收一行作为输入,并将这一行赋给awk的内部变量$0,每一行也可称为一个记录,行的边界是以换行符作为结束(表明:awk是一行一行的去处理文本的);
-
(2)然后,刚刚读入的行被以:为分隔符分解成若干字段(或域),每个字段存储在已编号的变量中,编号从$1开始,最多达100个字段;
- 注意:如果未指定行分隔符,awk将使用内置变量FS的值作为默认的行分隔符,FS默认值为空格,如果说要指定分隔符,需要使用-F参数或者重新定义FS变量;
-
(3)使用print函数打印,如果$1$3之间没有逗号,它俩在输出时将贴在一起,应该在$1,$3之间加逗号,该逗号与awk的内置变量OFS保持一致,OFS默认为空格,于是以空格为分隔符输出$1和$3;
-
(4)输出之后,将从文件中获取另一行,然后覆盖给$0,继续(2)的步骤将该行内容分隔成字段。。。继续(3)的步骤,该过程一直持续到所有行处理完毕。
2、awk中的变量
上下文变量
- 开始 BEGIN 结束 END
echo '1,10
2,20
3,30' | awk 'BEGIN{total=0;FS=","}{total+=$2}END{print total/NR}'

-
行数 NR
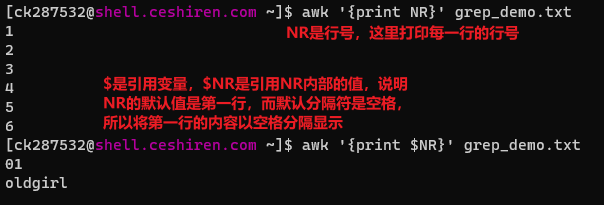
-
字段与字段数 $1 $2 … $NF NF

-
整行 $0

-
字段分隔符 FS
echo '1
2
3' | awk 'BEGIN{RS="";FS="\n";OFS=":"}{$1=$1;print $0}'

- 输出数据的字段分隔符 OFS
echo '1
2
3' | awk 'BEGIN{RS="";FS="\n";OFS=":"}{$1=$1;print $0}'
- 记录分隔符 RS
echo 1:2:3 | awk 'BEGIN{RS=":"}{print $0}'

- 输出字段的行分隔符 ORS
echo '1
2
3' | awk 'BEGIN{ORS=":"}{$1=$1;print $0}'

字段变量用法
- -F 指定字段分隔符,可以用|指定多个,多分隔符 -F ‘<|>’
- BEGIN{FS=“_”} 也可以表示分隔符
- $0 代表当前的记录
- $1 代表第一个字段
- $N 代表第 N 个字段
- $NF 代表最后一个字段
- $(NF-1) 代表倒数第二个字段
3、格式化输出
-
print:普通打印;
awk -F: '{print "username:",$1,"编号:",$2}' awk_demo.txt

-
printf:格式化打印;
awk -F: '{printf "用户名:%s 用户id:%s\n",$1,$2}' awk_demo.txt awk -F: '{printf "|%-15s| %10s|\n", $1,$2}' awk_demo.txt

- %s 字符类型
- %d 数值类型
- 占15格的字符串
- - 表示左对齐,默认是右对齐
- printf默认不会在行尾自动换行,需要加\n
4、处理规则执行流程
- BEGIN{} : BEGIN是在awk处理文本之前运行
- // : 包裹 使用的匹配规则(正则表达式)
- {} : 循环(每次只处理一行数据)
- END{} : 当所有的处理全部执行完毕之后,执行END中的相关操作
5、操作模式
正则模式
awk '/[z]/ {print $0}' awk_demo.txt

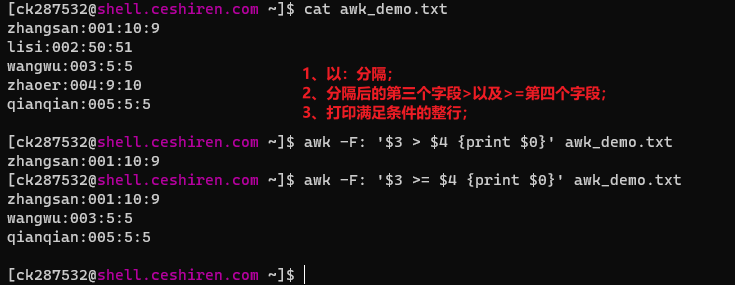
比较模式
awk -F: '$3 >= $4 {print $0}' awk_demo.txt
逻辑表达式
awk -F: '$3==50 || $3==5 {print $0}' awk_demo.txt

算术模式
awk -F: '{printf "%d+%d=%d\n",$3,$4,$3+$4}' awk_demo.txt

范围模式
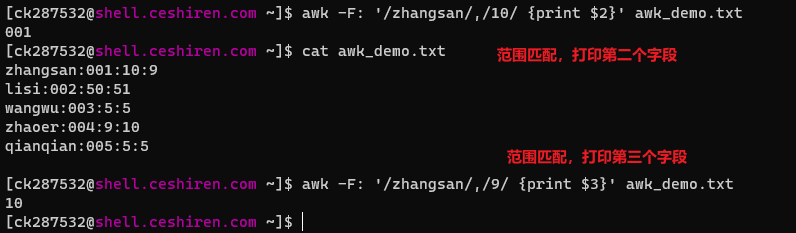
6、流程控制
if判断
单分支
if () {}
双分支
if () {} else {}
多分支
if(){} else if() {} else{}
awk -F: '{if( NR % 2 ){print NR,$0}}' awk_demo.txt

for循环
for (变量 in 数组) {语句}
for (变量;条件;表达式){语句}
说明:
++ : 每次在原来值加1
-- : 每次在原来值减1
# /etc/nginx/nginx.conf中的所有单词的个数
egrep -o "[a-zA-Z0-9]+" /etc/nginx/nginx.conf | awk '{arr[$1]++}END{for(i in arr){printf "%-20s %d\n",i,arr[i]}}'

while循环
while(判断条件) {}
awk '{i=0;while(i<3){print $0;i++}}' awk_demo.txt

三、sed-修改文本
1、什么是sed
简介
sed 全名为 stream editor,流编辑器,用程序的方式来编辑文本,功能相当的强大。是贝尔实验室的 Lee E.McMahon 在 1973 年到 1974 年之间开发完成,目前可以在大多数操作系统中使用,sed 的出现作为 grep 的继任者。与vim等编辑器不同,sed 是一种非交互式编辑器(即用户不必参与编辑过程),它使用预先设定好的编辑指令对输入的文本进行编辑,完成之后再输出编辑结构。sed 基本上就是在玩正则模式匹配,所以,玩sed的人,正则表达式一般都比较强。
工作原理
sed会一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,成为"模式空间",接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。
2、用法
语法及参数
语法 :sed [-nefri] [动作]
参数:
- -n :使用安静(silent)模式。sed默认会把模式空间处理完毕后的内容输出到标准输出,也就是输出到屏幕上,加上-n选项后被设定为安静模式,也就是不会输出默认打印信息,除非子命令中特别指定打印选项,则只会把匹配修改的行进行打印。
- -e :直接在命令列模式上进行 sed 的动作编辑;
- -f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作;
- -r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法)
- -i :直接修改读取的文件内容,而不是输出到终端。
- -E: 扩展表达式
- –debug :调试
动作: [n1[,n2]]function
- n1, n2 :不见得会存在,一般代表『选择进行动作的行数』,举例来说,如果我的动作是需要在 10 到 20 行之间进行的,则『 10,20[动作行为] 』;
-
function:
- a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行);
- c :改变, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
- i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p :列印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行;
- s :查找替换,可以直接进行取代的工作,通常这个 s 的动作可以搭配正规表示法;
具体使用案例
-n:使用安静(silent)模式; s:查找替换;
echo -e 'hello world \n nihao' | sed -n 's/hello/A/'
echo -e 'hello world \n nihao' | sed 's/hello/A/'
echo -e 'hello world \n nihao' | sed -n 's/hello/A/p'

-e:直接在命令列模式上进行 sed 的动作编辑,如果需要用sed对文本内容进行多种操作,则需要执行多条子命令来进行操作。
echo 'hello world' | sed -e 's/hello/A/' -e 's/world/B/'
echo 'hello world' | sed 's/hello/A/;s/world/B/'

说明:例子1和例子2的写法的作用完全等同,可以根据喜好来选择,如果需要的子命令操作比较多的时候,无论是选择-e选项方式,还是选择分号的方式,都会使命令显得臃肿不堪,此时使用-f选项来指定脚本文件来执行各种操作会比较清晰明了。
-f:把多个子命令操作写入脚本文件,然后使用 -f 选项来指定该脚本。
sed.script:在脚本中不需要使用单引号;
s/hello/A/
s/world/B/
echo 'hello world' | sed -f sed.script

-r:sed命令默认只能支持基本正则表达式,如果需要支持扩展正则表达式,那么需要添加-r选项
echo "hello world" | sed -r 's/(hello)|(world)/A/g'

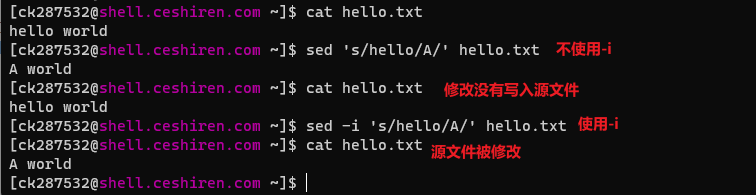
-i:sed默认会把输入行读取到模式空间,简单理解就是一个内存缓冲区,sed子命令处理的内容是模式空间中的内容,而非直接处理文件内容。因此在sed修改模式空间内容之后,并非直接写入修改输入文件,而是打印输出到标准输出。如果需要修改输入文件,那么就可以指定-i选项。
sed -i 's/hello/A/' hello.txt
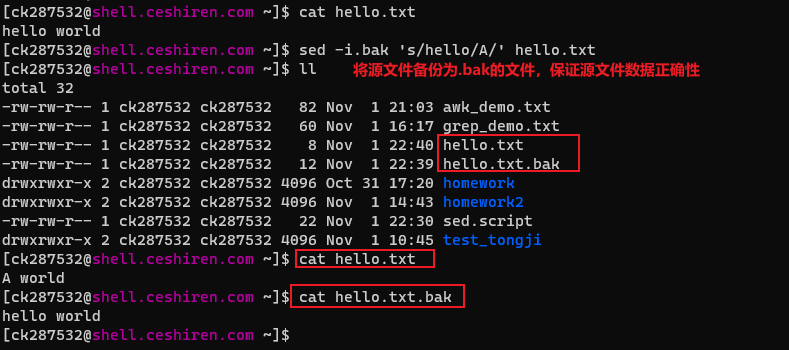
补充: 为确保原始文件内容安全性,防止错误操作而无法恢复原来内容,使用如下操作;
sed -i.bak 's/hello/A/' hello.txt