一、Neo4J数据库中数据的结构
简单例子:
-
Nodes:节点,代表实体,图中的每个矩形 代表一个实体,最简单的图只有一个节点。

-
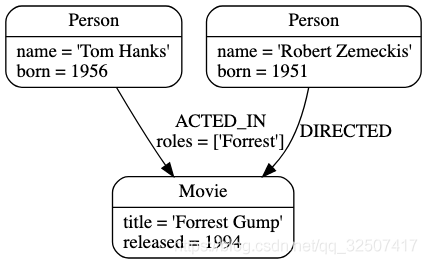
Labels: 标签,代表 Node/节点/实体 属于哪一个集体,每一个 Node/节点/实体 可以有0个或多个标签。标签也可以在运行时添加,所以标签也可以描述节点的状态信息。如下图所示,
Tom Hanks既属于Person,又属于Actor。
-
Relationship: 关系,即代表图中的边,
Relationship连接两个节点,使得组织成列表、树、图等更为复杂的结构。 比如下图表示Tom Hanks在电影Forrest Gump中饰演角色Forrest Gump,其中 饰演角色 就是Tom Hanks和Forrest Gump的关系/Relationship。
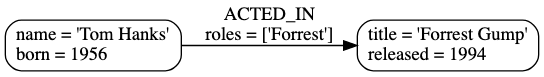
-
Properties:属性,即描述 Node/节点 或者 Relationship/关系 的属性。比如下图,
Person有name和born属性,Movie有title和released属性,ACTED_IN有roles属性。
-
Schema: 模式,在Neo4J中是可选的,即可以不预先定义一个
schema而直接产生数据,以上图例子中,可以不需要为Person定义一个Schema必须包含name和born两个属性。
添加Schema可以提高性能,所以如果需要更高性能可以考虑schema,参见8.schema
二、 图数据库查询语言Cypher介绍
1、什么是Cypher
全称Graph Query Language,Cypher 是 Neo4j 提出的图查询语言,是一种声明式的图数据库查询语言,它拥有精简的语法和强大的表现力,能够精准且高效地对图数据进行查询和更新。它是一种受 SQL 启发的语言,用于使用 ASCII-Art 语法描述图中的可视模式。它允许声明想要从图数据库中选择、插入、更新或删除什么,而不需要精确地描述如何做到这一点。通过 Cypher,用户可以构建表达性强且高效的查询,处理所需的创建、读取、更新和删除功能。
2、 Cypher 设计理念
Cypher 的设计理念是:无论是开发工程师,数据库管理员,还是运维工程师,甚至非技术人员都可以轻松读懂 Cypher。这使得图数据库的使用者可以专注于自身业务需求,而不必花费很多时间去理解图数据库的底层实现原理。
(1)人性化设计
Cypher 在语法设计上十分人性化,它提供了一个直观方式来匹配图中的节点和关系。例如想要查询一个一跳路径,()代表节点,[] 代表关系,看起来就像两个点一条关系组成的一跳路径。
MATCH (n)-[r]-(m) RETURN *
(2)博采众长
Cypher 集思广益,借鉴和吸收了已有数据库查询语言的习惯写法。例如 WHERE、ORDER BY、SKIP 和 LIMIT 就来源于关系数据库查询语言 SQL,例如可视化模式匹配的语法设计来源于 RDF 查询语言 SPARQL 等。
(3)语句组合 Cypher
类似于 SQL 语言,一条完整的查询可由多个语句(Clause)组合而成,每条语句的执行结果将保存为中间结果,并往下一条语句传递,值得一提的是,Cypher 执行采用火山模型(Vocalno),所以除了聚合(Eager)操作,当前语句完全执行完之前就会把部分已完成的结果往下一条语句传递。
三、Cypher的基本命令和语法
- create命令
- match命令
- merge命令
- relationship关系命令
- where命令
- delete命令
- sort命令
- 字符串函数
- 聚合函数
- index索引命令
说明:
- 语法中不区分大小写;
- 所有的符号都必须是英文输入;
1、 create命令: 创建图数据中的节点
创建命令格式一
-
语法:
CREATE (e:Employee{id:222, name:'Bob', salary:6000, deptnp:12}) return e -
参数说明:
- CREATE :关键字;
- e:节点(相当于mysql中的表中的一条记录)的变量名称;
- Employee为:节点对应标签(相当于myslq中的一张表), e和Employee放在小括号里面(),中间用冒号表示关系;后面把所有属性(相当于Myslq中表的列名)以键值对的形式放在大括号’{}‘里面, 依次写出属性名称:属性值, 不同属性用逗号’,'分隔;
-
说明:
-
节点名称 e 是当前语句中的临时变量,节点标签 Employee 才真正保存到图数据库中;
- 无论你节点起什么名字都无所谓,它相当于是python语言里面的一个变量名,指向一个对象,可以对其进行操作;
- 节点是可写可不写的,需要操作实例的时候就需要写节点,也可以理解为节点是对应实例的变量名.
-
节点名称 e 是当前语句中的临时变量,节点标签 Employee 才真正保存到图数据库中;
-
节点对应标签是一定要写的.标签是Neo4j图数据库的分类.需要根据这个进行搜索。
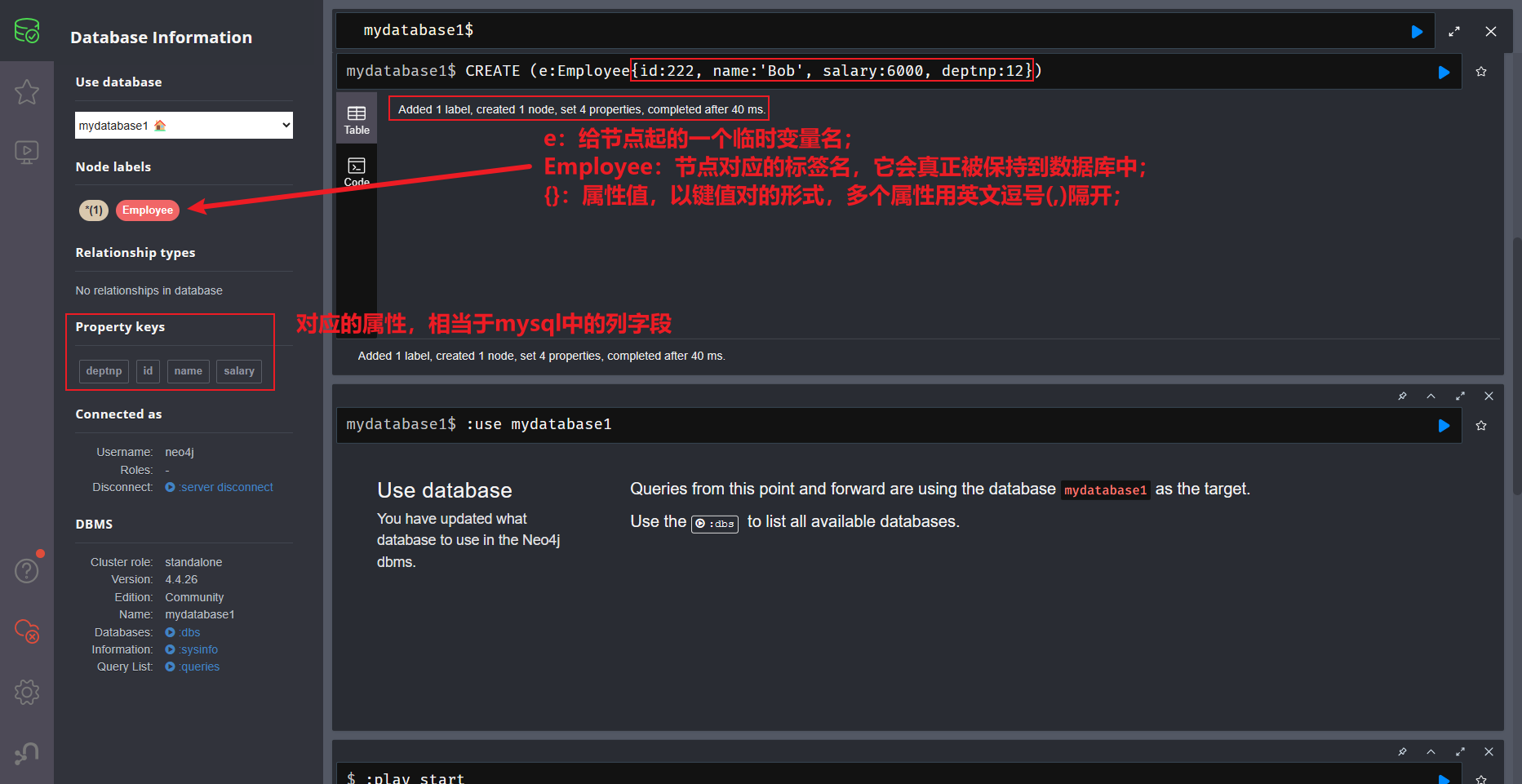
- 结果查看:
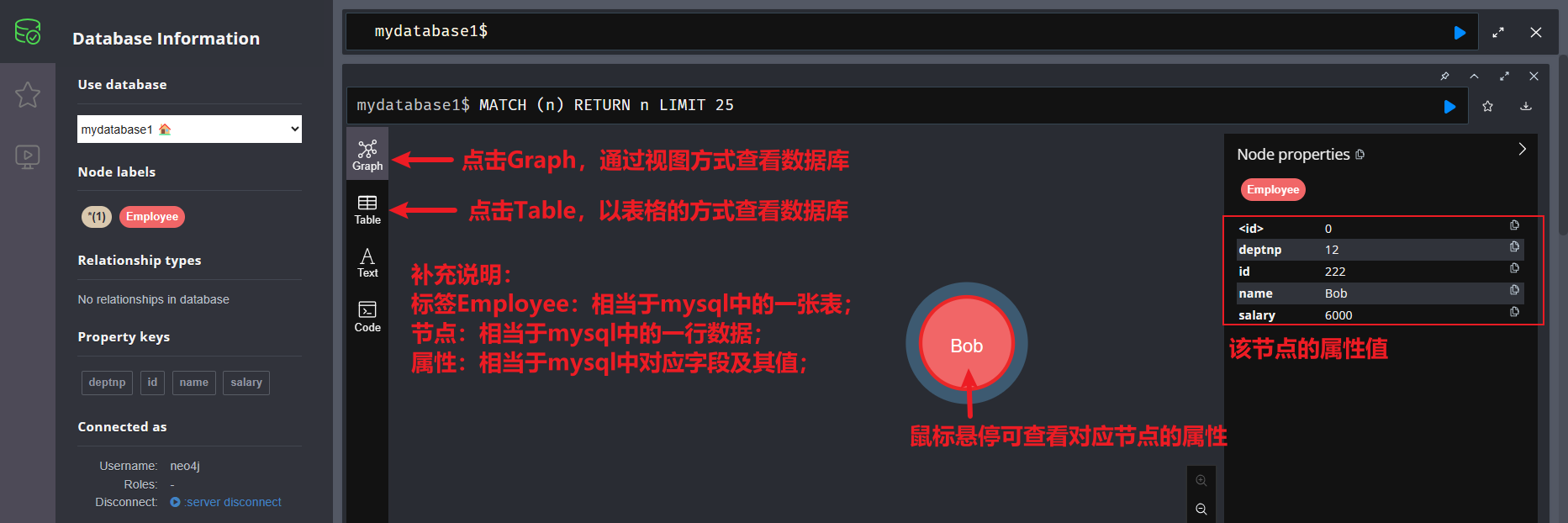
创建命令格式二
- 语法:
CREATE (e:Employee) set e.id=223, e.name='Tom', e.salary=6000, e.deptnp=12 return e
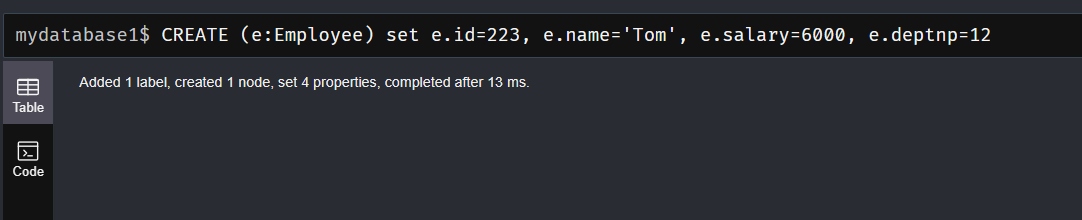
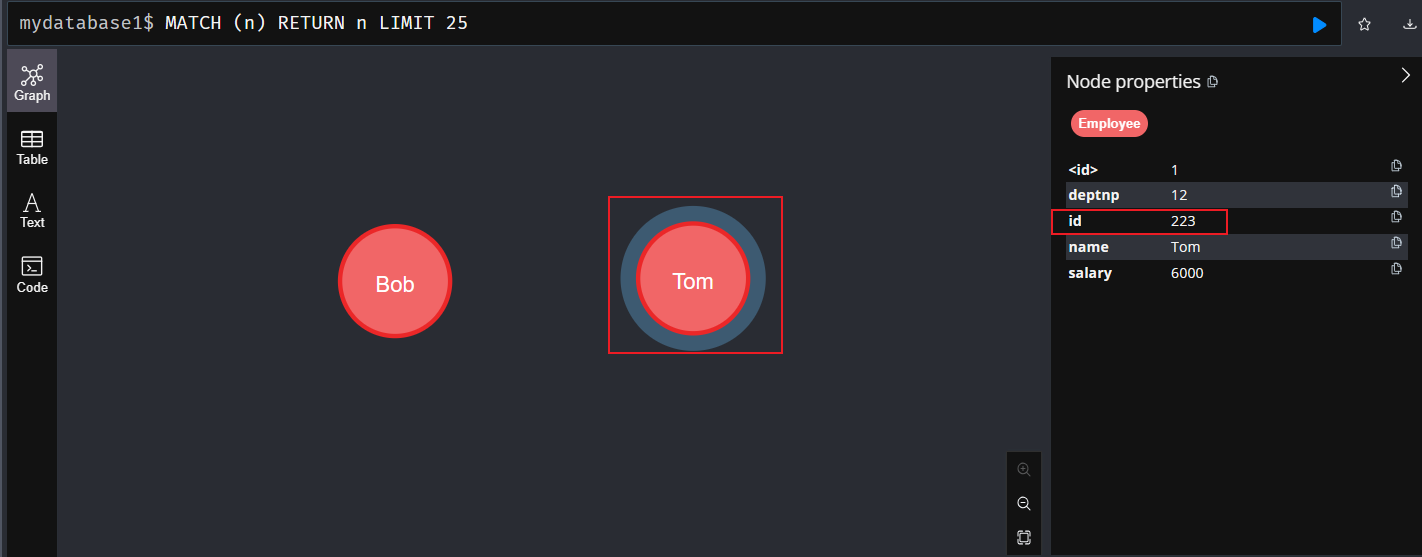
2、 match命令: 匹配(查询)已有数据
- 语法:
match (e:Employee) return e.id,e.salary,e.name - 参数说明:
- match:关键字;
- e:节点的临时变量,相当于别名;
- Employee:标签名,e和Employee使用冒号相连,之后放在括号中;
- return:关键字
- 返回值:用节点别名
.属性名表示要返回的哪个属性值,多个用逗号隔开;
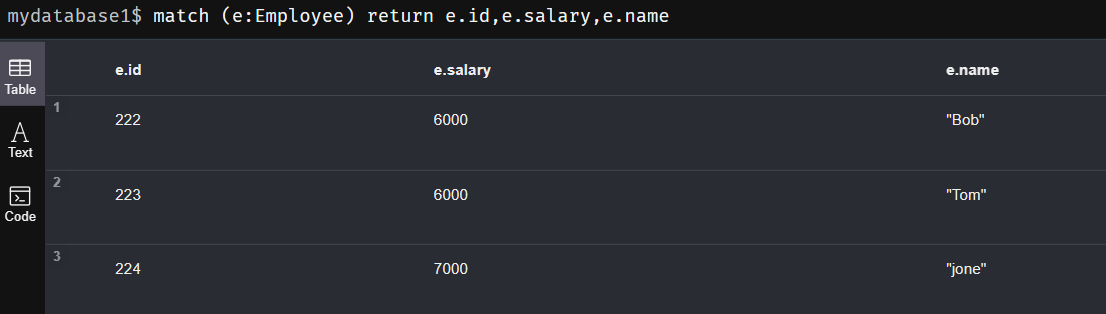
3、 merge命令: 若节点存在, 则等效与match命令; 节点不存在, 则等效于create命令
- 语法:
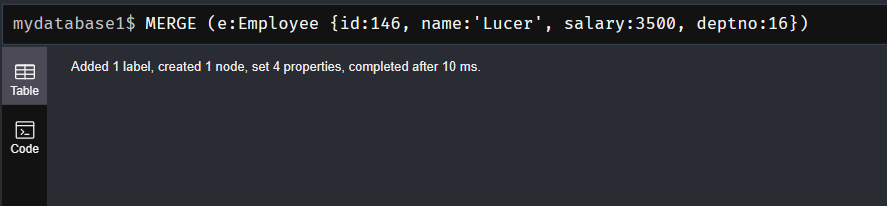
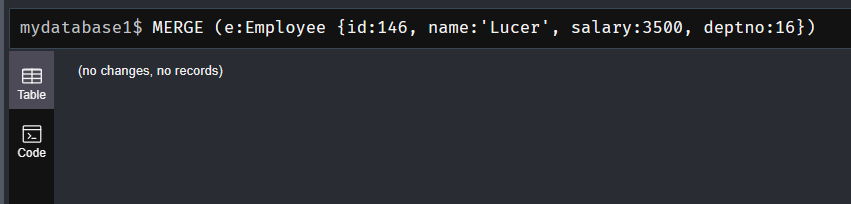
MERGE (e:Employee {id:146, name:'Lucer', salary:3500, deptno:16})
使用merge创建
使用merge查询
4、 使用create创建关系
-
说明:
- 必须创建有方向性的关系, 否则报错;
- 在Neo4j中,有两种关系- incoming 和 outgoing,为了表示 cypher 中的传出或传入关系,我们使用 → 或 ←;
-
语法:
create (节点变量1:标签)-[关系变量:关系]->(节点变量2:标签)
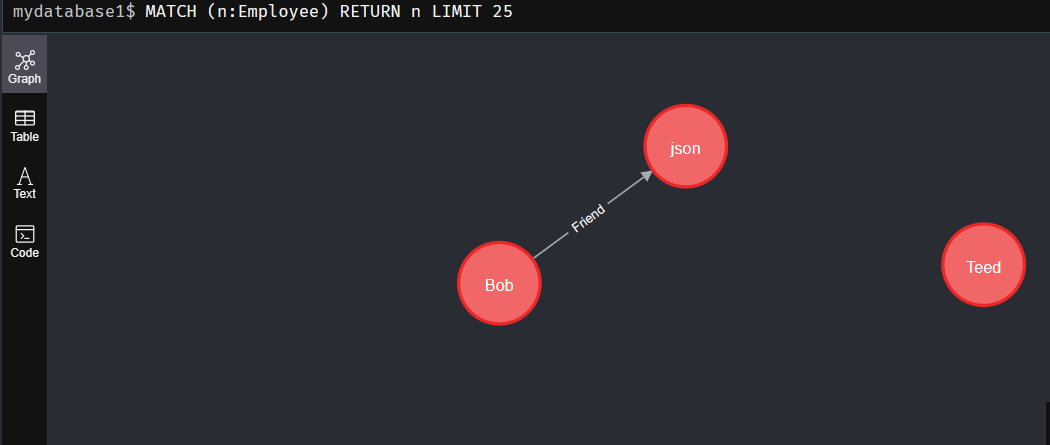
案例: 给标签Employee中,name=‘Bob’和name=‘json’的两个节点建立Friend关系:
match (e1:Employee),(e2:Employee) where e1.name='Bob' and e2.name='json' create (e1)-[f:Friend]->(e2) return type(f)

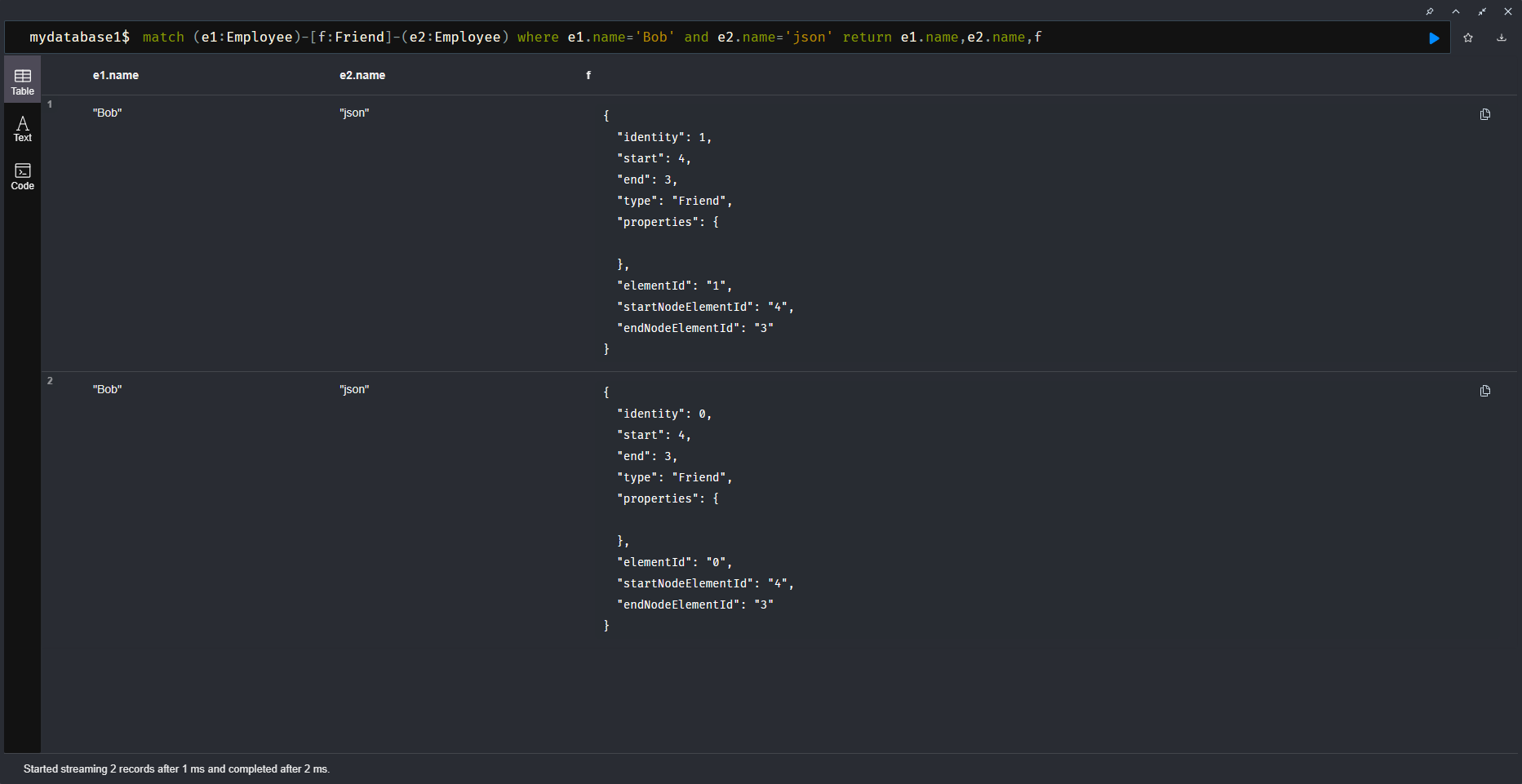
- 注意:虽然在创建关系的时候给定了放心,但是在查询的时候不指定方向也是可以查询成功
match (e1:Employee)-[f:Friend]-(e2:Employee) where e1.name='Bob' and e2.name='json' return e1.name,e2.name,f
5、 使用merge创建关系
-
说明: merge在创建的时候可以不用
->指定方向,但是系统会自动给上方向; - 语法:
merge(节点变量1:标签)-[关系变量:关系]-(节点变量2:标签)
match (e1:Employee),(e2:Employee) where e1.name='Bob' and e2.name='Lucer' merge (e1)-[l:Love]-(e2) return e1.name,e2.name,type(l)

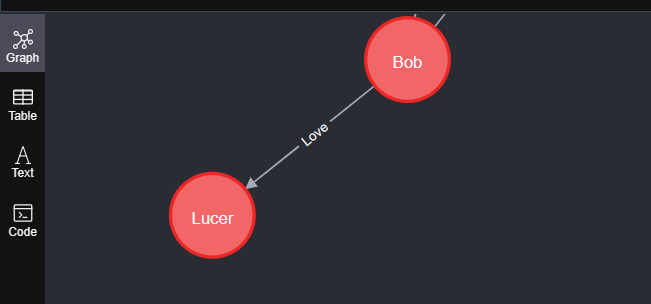
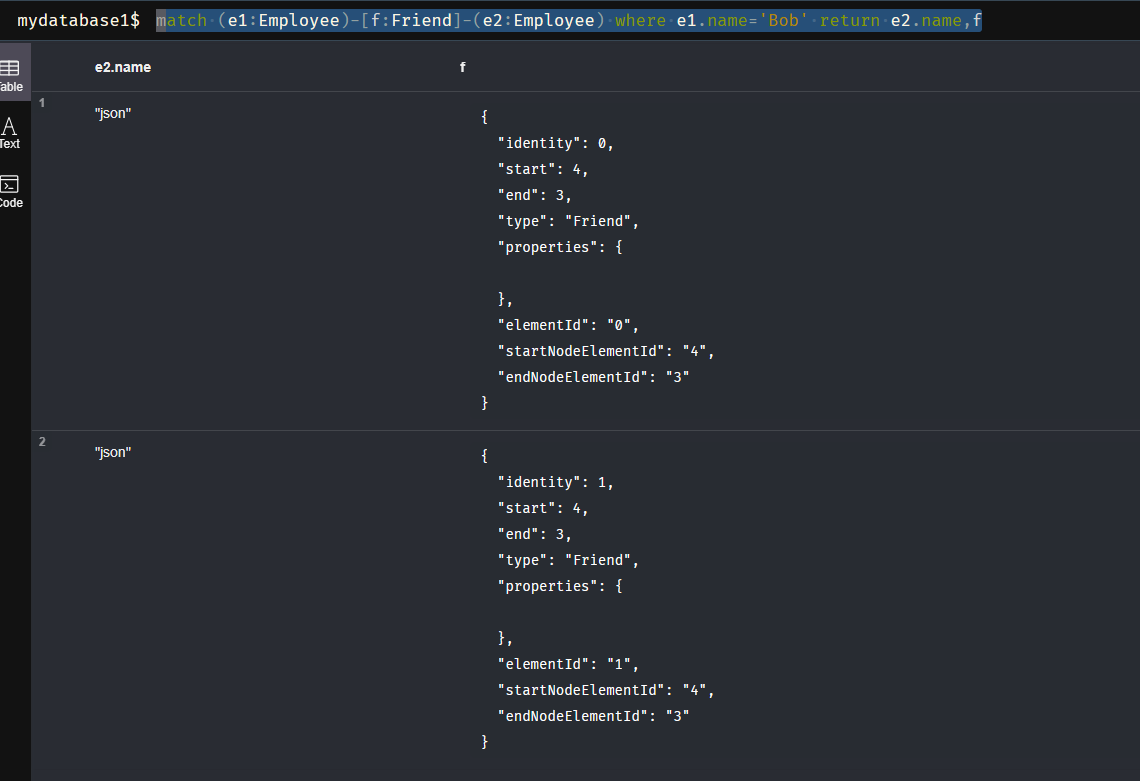
6、 where命令: 类似于SQL中的添加查询条件
- 语法:
match (e1:Employee)-[f:Friend]-(e2:Employee) where e1.name='Bob' return e2.name,f
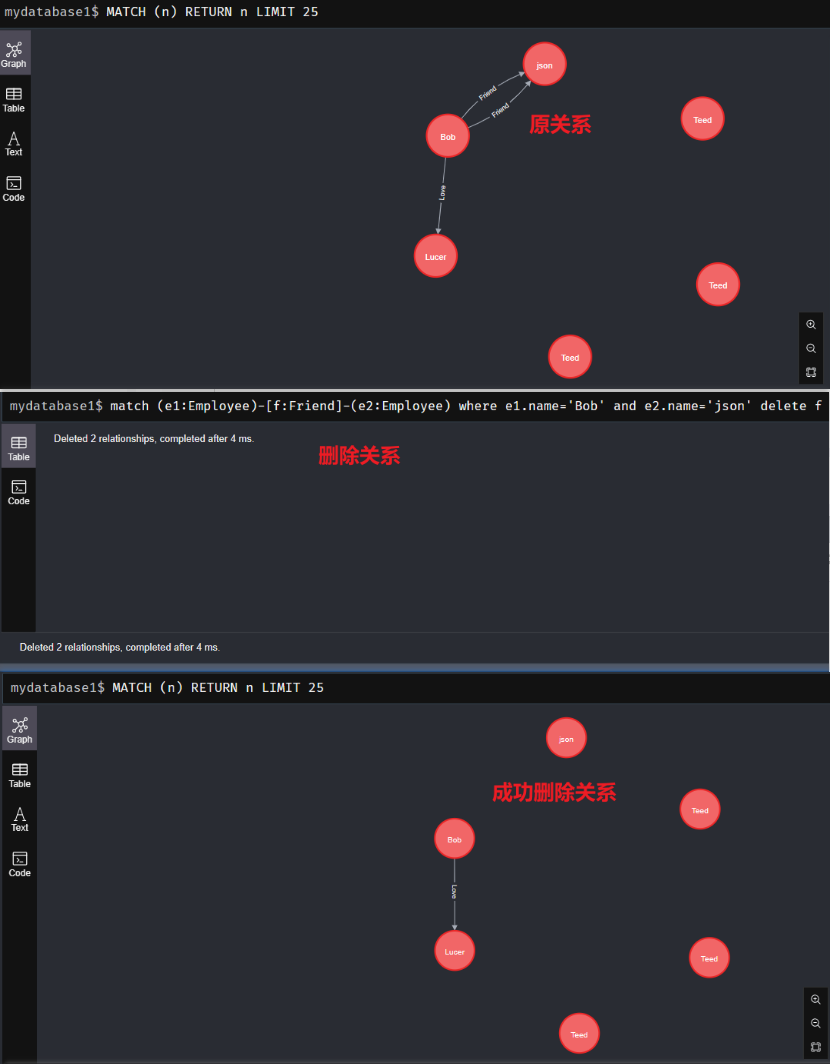
7、 delete命令: 删除节点和关系
删除关系
- 语法:
match (e1:Employee)-[f:Friend]-(e2:Employee) where e1.name='Bob' and e2.name='json' delete f
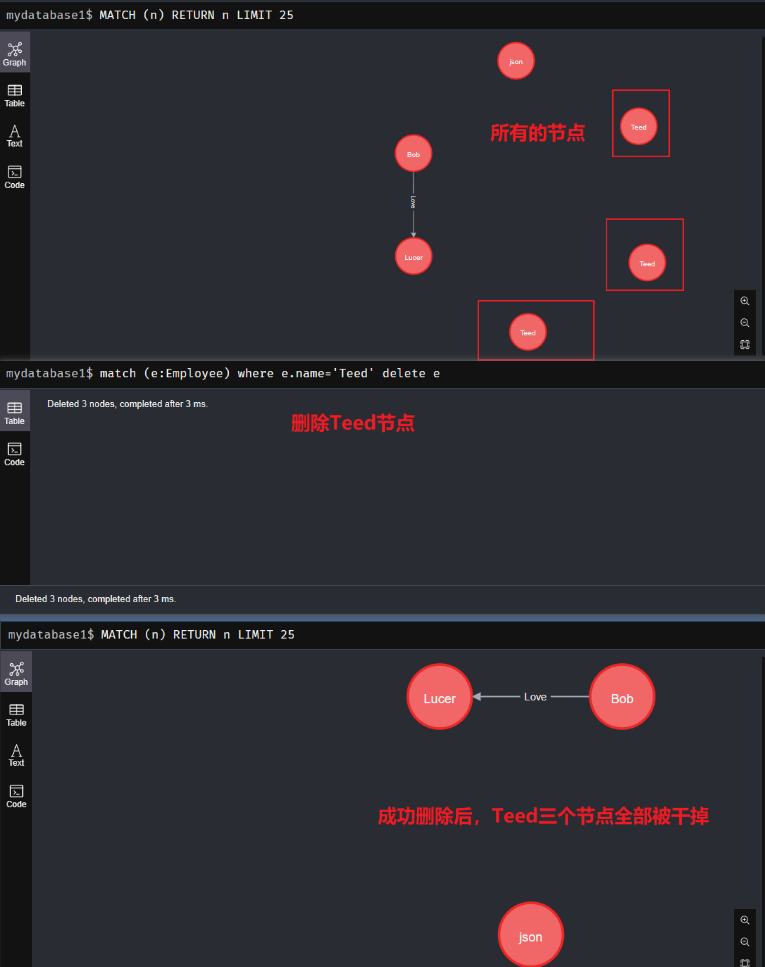
删除节点
- 语法:
match (e:Employee) where e.name='Teed' delete e
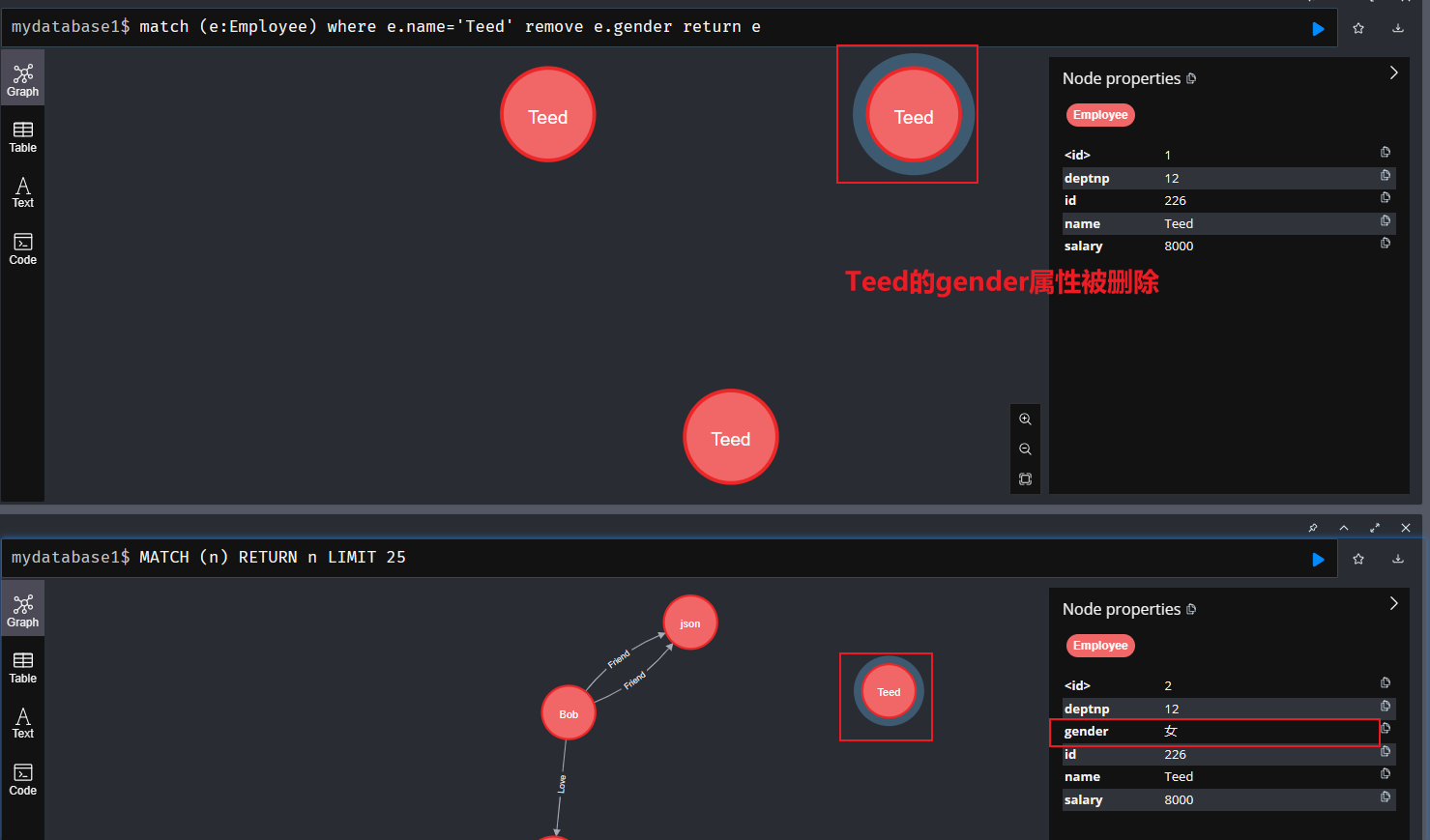
8、remove命令:删除标签和属性
删除属性
- 语法:
match (e:Employee) where e.name='Teed' remove e.gender return e
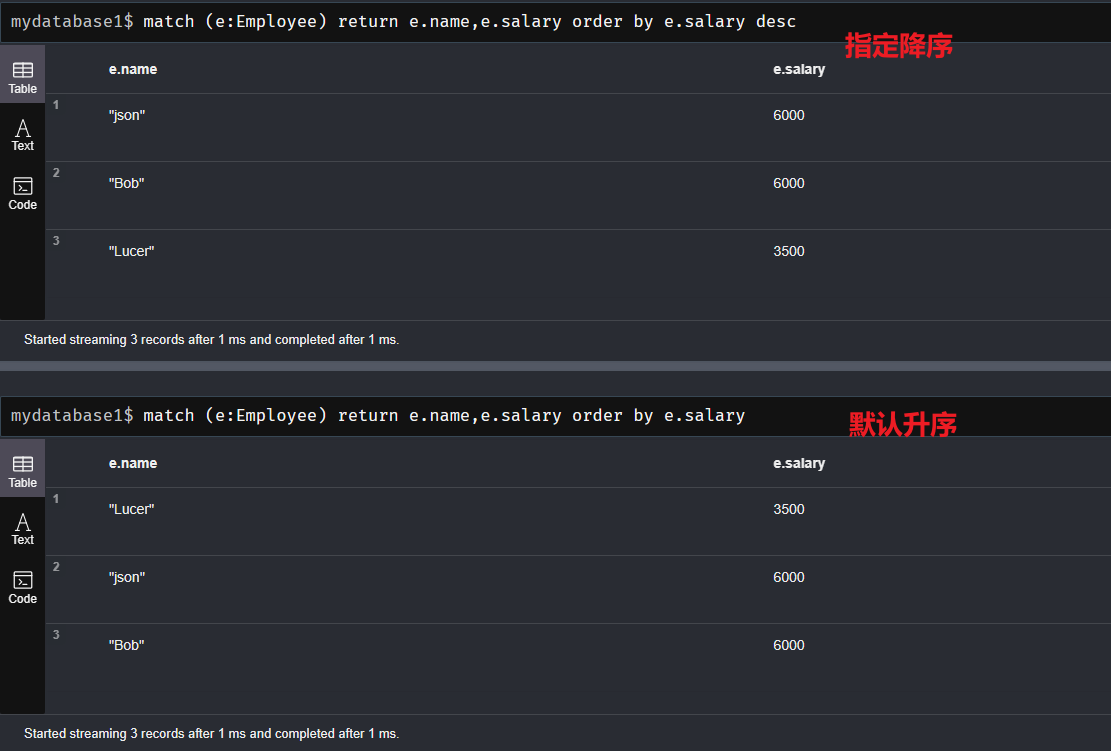
9、order by命令:排序
- 语法:
match (e:Employee) return e.name,e.salary order by e.salary desc- 默认升序;
- desc:降序;
10、字符串函数
(1) toUpper(str)函数:将一个输入字符串转换为大写字母
MATCH (e:Employee) RETURN e.id, toUpper(e.name), e.salary, e.deptno
(2) toLower(str)函数:将一个输入字符串转换为小写字母
MATCH (e:Employee) RETURN e.id, toLower(e.name), e.salary, e.deptno
(3) substring(input_str, start_index, end_index)函数:返回一个子字符串
MATCH (e:Employee) RETURN e.id, substring(e.name,0,2), e.salary, e.deptno
(4) replace(input_str, origin_str, new_str)函数:替换掉子字符串
MATCH (e:Employee) RETURN e.id, replace(e.name,e.name,e.name + "_HelloWorld"), e.salary, e.deptno
11、聚合函数
- count()函数
- max()函数
- min()函数
- sum()函数
- avg()函数
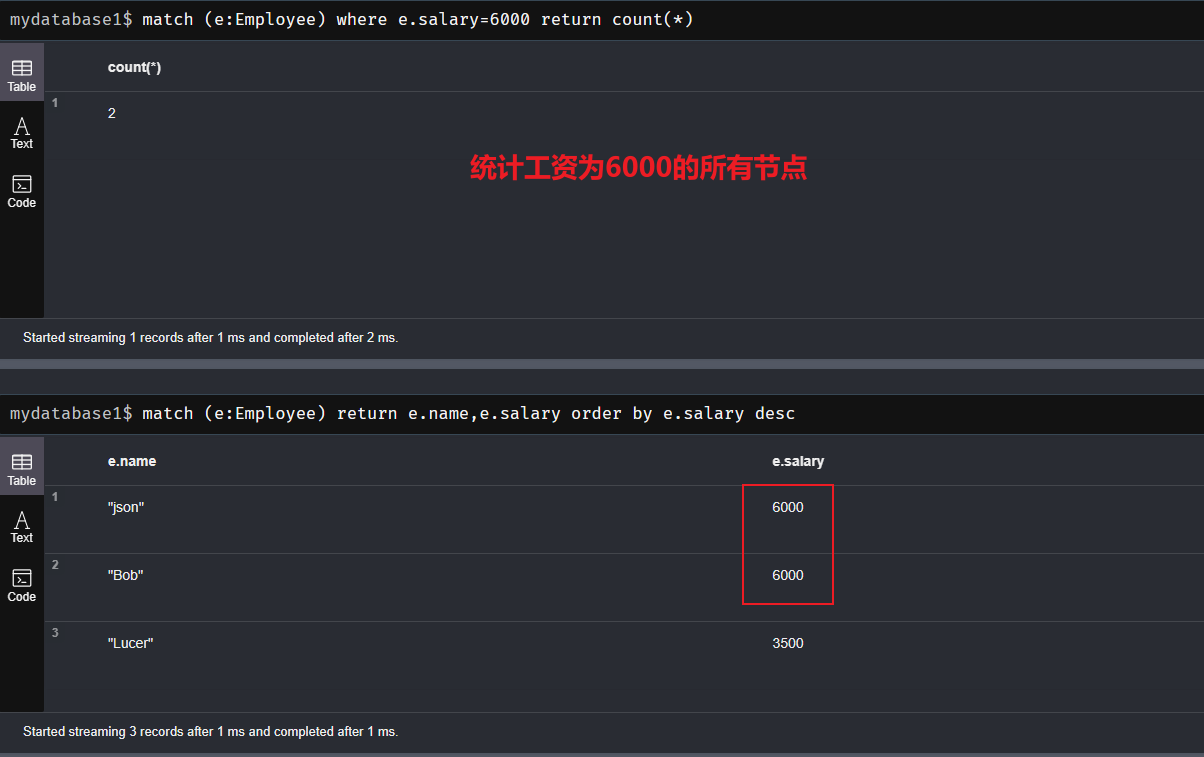
(1) count()函数:返回由match命令匹配成功的条数
match (e:Employee) where e.salary=6000 return count(*)
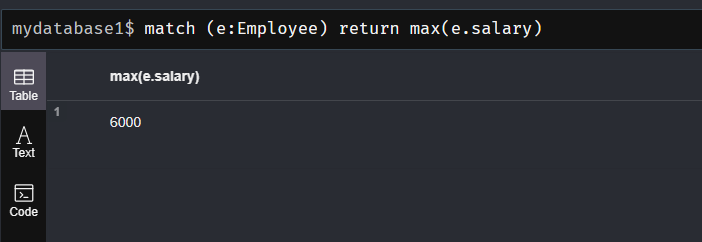
(2) max()函数:返回由match命令匹配成功的记录中的最大值
match (e:Employee) return max(e.salary)
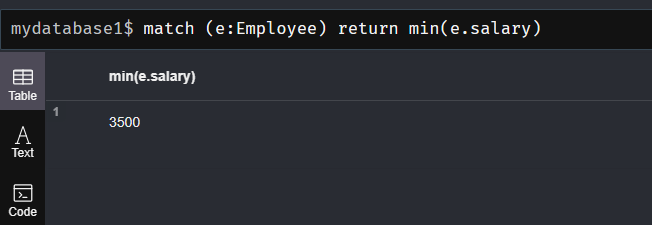
(3) min()函数:返回由match命令匹配成功的记录中的最小值
match (e:Employee) return min(e.salary)
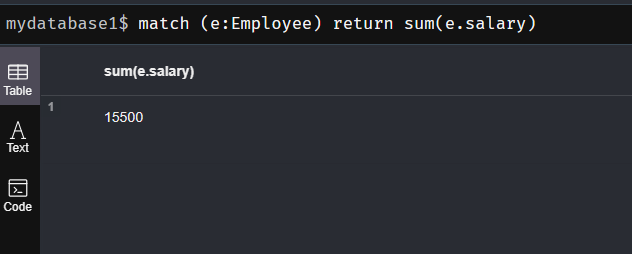
(4) sum()函数:返回由match命令匹配成功的记录中某字段的全部加和值
match (e:Employee) return sum(e.salary)
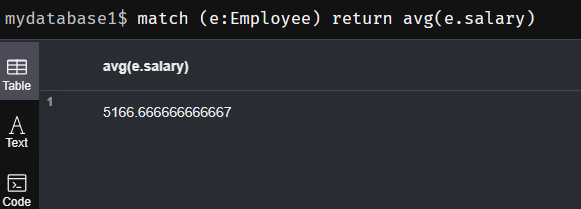
(5) avg()函数:返回由match命令匹配成功的记录中某字段的平均值
match (e:Employee) return avg(e.salary)
12、索引
-
Neo4j支持在节点或关系属性上的索引, 以提高查询的性能.
-
可以为具有相同标签名称的所有节点的属性创建索引.
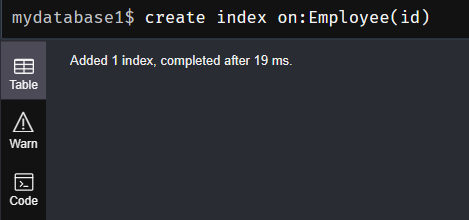
(1)create index on:创建索引
create index on:Employee(id)
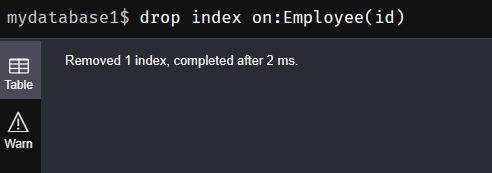
(2)drop index on:删除索引
drop index on:Employee(id)