一、ORM介绍
1、什么是ORM
-
全程Object Relational Mapping对象关系映射;
-
作用:在关系型数据库和对象之间做一个映射,这样在具体操作数据库的时候,就不需要再去和复杂的SQL语句打交道,只要像平时操作对象一样操作就可以;数据库中一条数据就是一个ORM对象,而里面的字段就是ORM的属性;

2、ORM优缺点
-
优点:
- 隐藏了数据访问细节;
- ORM使我们构造固化数据结构变得非常简单;
-
缺点:
- 性能下降,添加了关联操作,性能不可避免的会下降一些;
- 无法解决特别复杂的数据库操作;
二、ORM中间件配置-Flask-SQLAlchemy插件
1、安装
pip install flask-sqlalchemy
2、flask-sqlalchemy配置
- Flask-SQLAlchemy 扩展能够识别的配置键的清单:
| 配置键 | 说明 |
|---|---|
| SQLALCHEMY_DATABASE_URI | 用于连接数据的数据库。例如:sqlite:////tmp/test.db或者mysql://username:password@server(host:port)/db
|
| SQLALCHEMY_BINDS | 一个映射绑定 (bind) 键到 SQLAlchemy 连接 URIs 的字典。 更多的信息请参阅 绑定多个数据库。 |
| SQLALCHEMY_ECHO | 如果设置成 True,SQLAlchemy 将会记录所有 发到标准输出(stderr)的语句,这对调试很有帮助。 |
| SQLALCHEMY_RECORD_QUERIES | 可以用于显式地禁用或者启用查询记录。查询记录 在调试或者测试模式下自动启用。更多信息请参阅 get_debug_queries() 。 |
| SQLALCHEMY_NATIVE_UNICODE | 可以用于显式地禁用支持原生的 unicode。这是 某些数据库适配器必须的(像在 Ubuntu 某些版本上的 PostgreSQL),当使用不合适的指定无编码的数据库 默认值时。 |
| SQLALCHEMY_POOL_SIZE | 数据库连接池的大小。默认是数据库引擎的默认值 (通常是 5)。 |
| SQLALCHEMY_POOL_TIMEOUT | 指定数据库连接池的超时时间。默认是 10。 |
| SQLALCHEMY_POOL_RECYCLE | 自动回收连接的秒数。这对 MySQL 是必须的,默认 情况下 MySQL 会自动移除闲置 8 小时或者以上的连接。 需要注意地是如果使用 MySQL 的话, Flask-SQLAlchemy 会自动地设置这个值为 2 小时。 |
| SQLALCHEMY_MAX_OVERFLOW | 控制在连接池达到最大值后可以创建的连接数。当这些额外的 连接回收到连接池后将会被断开和抛弃。 |
| SQLALCHEMY_TRACK_MODIFICATIONS | 如果设置成 True (默认情况),Flask-SQLAlchemy 将会追踪对象的修改并且发送信号。这需要额外的内存, 如果不必要的可以禁用它。不配置该设置会抛出警告。 |
- SQLALCHEMY_DATABASE_URI连接串配置格式:
dialect+driver://username:password@server(host:port)/database
说明:
· dialect:数据库实现,也就是用的什么数据库,mysql、sqlite、MongoDB等;
· driver:python对应的驱动,比如:pymysql、mysqldb(默认);
· database:数据库名;
3、具体使用步骤
-
实例化服务app;
-
使用
app.config[SQLAlchemy配置键]进行SQLAlchemy配置,比如设置连接方式、修改数据是否发出警告等; -
将app传给SQLAlchemy进行绑定;
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
# 1. 实例化服务app;
app = Flask(__name__)
# 2. 使用`app.config[SQLAlchemy配置键]`进行SQLAlchemy配置,比如设置连接方式、修改数据是否发出警告等;
username = "root"
password = "123456"
host = "127.0.0.1"
port = "3306"
database = "litemall"
app.config["SQLALCHEMY_DATABASE_URI"] = f"mysql+pymsql://{username}:{password}@{host}:{port}/{database}"
# 3. 将app传给SQLAlchemy进行绑定;
db = SQLAlchemy(app)
三、数据库与表管理
说明: Alchemy在操作数据库的时候其实是使用对应驱动去完成,而这些驱动就是操作数据库的第三方库,比如pymysql,所以在使用的时候需要同时安装pymysql;
1、创建表与删除表
注意:一个表就是一个类,这个类需要继承db.Model;
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import *
# 1. 实例化服务app;
app = Flask(__name__)
username = "root"
password = "123456"
host = "127.0.0.1"
port = "3306"
database = "litemall"
# 2. 使用`app.config[SQLAlchemy配置键]`进行SQLAlchemy配置,比如设置连接方式、修改数据是否发出警告等;
app.config["SQLALCHEMY_DATABASE_URI"] = f"mysql+pymysql://{username}:{password}@{host}:{port}/{database}"
# 3. 将app传给SQLAlchemy进行绑定;
db = SQLAlchemy(app)
app_context = app.app_context() # 创建app上下文
app_context.push() # 将这个app上下文推栈上
# 创建表类PrivateUser表--一个类就是一个表,类名相当于表名,但是如果是驼峰命名会转小写下划线private_user
class PrivateUser(db.Model):
# 可以使用__tablename__属性指定表名
__tablename__ = "MyUser"
# id字段,integer类型,设置为主键
id = Column(Integer,primary_key=True)
username = Column(String(40))
# 需要创建多个表就创建多个类
class PrivateStudent(db.Model):
__tablename__ = "student"
# id字段,integer类型,设置为主键
id = Column(Integer,primary_key=True)
name = Column(String(40))
grades = Column(Float)
if __name__ == '__main__':
# 创建表--如果表已经存在不会被重新创建,也不会报错
db.create_all()
# 删除表--有数据也会删除表,直接干掉表
# 删除所有的表
# db.drop_all()
# 删除指定表,需要使用bind_key参数--TODO
# db.drop_all(bind_key="users")
补充:
上面代码中使用了app.app_context().push()将当前上下文推到栈顶,不然无法正常和数据库进行通信;
什么是上下文
-
在Flask的底层中拥有LocalStack的栈,这个栈专门用来存储app上下文。而current_app永远的指向这个栈的栈顶。如果通过url的方式访问,那么flask会自动的创建一个appcontext应用程序上下文,并且将这个应用程序上下文给放入到栈中,因此在视图函数中是存在该应用程序的上下文的,所以就可以通过currnet_app来访问栈中的第一个元素。
-
应用上下文和请求上下文都是存放到一个LocalStack的栈中。和应用app相关的操作就必须要应用到应用上下文,比如通过’currnet_app’获取到当前的这个’app’。和请求相关的操作就必须用到请求上下文,比如使用’url_for’反转视图函数。
-
在视图函数中不用担心上下文的问题。因为视图函数要执行,那么肯定是通过访问url的方式执行的,那么这种情况下,Flask底层就已经自动的帮我们把请求上下文和应用上下文都推如到相应的栈中。
-
如果想要在视图函数外面执行相关的操作,比如获取当前的app(currnet_app),或者反转url(url_for),那么就必须要手动的推入相关的上下文。
第一种方式
app_context = app.app_context()
app_context.push()
print(current_app)
第二种方式
with app.app_context():
print(current_app)
- 手动推入请求上下文:推入请求上下文到栈中,会首先判断有没有应用上下文,如果没有那么就会首先推入应用上下文到栈中,然后再推入请求上下文到栈中。
with app.test_request_context():
print(url_for('my_list'))
为什么上下文需要放在栈上?
-
应用上下文:在flask底层是基于werkzeug,werkzeug是可以包含多个app的,所以这个时候用一个栈来保存,如果你使用app1,那么app1应该是要在栈的顶部,如果用完了app1,那么app1应该从栈中删除,方便其他代码使用下面的app。
-
如果在写测试代码,或者离线脚本的时候,我们有可能需要创建多个请求上下文,这个时候就需要存放在一个栈中。使用哪个请求上下文的时候,就把对应的请求上下文放到栈的顶部,用完就要把这个请求上下文从栈中移除。
2、CRUD操作
(1)添加数据
- 步骤:
- 1、实例化类,创建表数据,单个对象或多个;
- 2、将实例对象添加到session:
添加单个db.session.add(user);添加多个db.session.add_all([user1,user2]); - 3、提交session:
db.session.commit(); - 4、关闭session:
db.session.close();
(2)查询数据
-
查询所有数据:
类.query.all();–得到一个列表,元素是一个一个的对象; -
单条件查询:
类.query.filter_by(条件).单条或多条;- 单条件查询-单条:
类.query.filter_by(gender='男').first(); - 单条件查询-多条:
类.query.filter_by(gender='男').all();
- 单条件查询-单条:
-
多条件查询:
类.query.filter_by(条件).filter_by(条件)...单条或多条;- 多条件查询-单条:
类.query.filter_by(gender='男').filter_by(grand = 60).first(); - 多条件查询-多条:
类.query.filter_by(gender='男').filter_by(grand = 60).all();
- 多条件查询-单条:
(3)更新修改数据
-
方式一:
- 对查询出来的数据对象进行属性的赋值修改;
- 提交session:
db.session.commit() - 关闭session:
db.session.close();
-
方式二:
- 给定条件查询之后,直接进行update操作:
类.query.filter_by(条件).update({'属性':'值'}); - 提交session:
db.session.commit() - 关闭session:
db.session.close();
- 给定条件查询之后,直接进行update操作:
(4)删除数据
-
方式一:删除一个;
- 对查询出来的数据对象进行删除操作:
db.session.delete(对象urser); - 提交session:
db.session.commit() - 关闭session:
db.session.close();
- 对查询出来的数据对象进行删除操作:
-
方式二:删除查出的所有;
- 给定条件查询之后,直接进行delete操作:
类.query.filter_by(条件).delete(); - 提交session:
db.session.commit() - 关闭session:
db.session.close();
- 给定条件查询之后,直接进行delete操作:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import *
# 创建服务实例
app = Flask(__name__)
# 将服务和sql进行关联
username = "root"
password = "123456"
host = "127.0.0.1"
port = "3306"
database = "litemall"
app.config["SQLALCHEMY_DATABASE_URI"] = f"mysql+pymysql://{username}:{password}@{host}:{port}/{database}"
db = SQLAlchemy(app)
# 将当前上下文推到栈顶
context = app.app_context()
context.push()
# 定义表结构
class Student(db.Model):
# 设置表面
__tablename__ = "student"
# 定义表字段
id = Column(Integer,primary_key=True)# 主键
name = Column(String(20))
card = Column(Integer,autoincrement=True,unique=True)# 自增并且不能重复
grades = Column(JSON)
age = Column(Integer)
if __name__ == '__main__':
# 创建表
db.create_all()
# 插入单条数据
# stu1 = Student(id=1,name="张三",card=10,grades={"语文":90,"数学":95,"英语":87})
# db.session.add(stu1)
# 插入多条数据
# stu2 = Student( name="张四", grades={"语文": 91, "数学": 95, "英语": 87})
# stu3 = Student( name="张三", grades={"语文": 80, "数学": 95, "英语": 87})
# db.session.add_all([stu2,stu3])
# 查询所有
# all_student = Student.query.all()
# print(all_student)# [<Student 1>, <Student 2>, <Student 3>, <Student 5>, <Student 6>, <Student 7>, <Student 8>]
# 但条件查询单个
# filter_first = Student.query.filter_by(name = "张三").first()
# print(filter_first)# <Student 1>
# 但条件查询所有
# filter_all = Student.query.filter_by(name="张三").all()
# print(filter_all)# [<Student 1>, <Student 3>, <Student 6>, <Student 8>]
# 多条件查询单个
# more_filter_first = Student.query.filter_by(name="张三").filter_by(age=18).first()
# print(more_filter_first)# <Student 1>
# 多条件查询所有
# more_filter_all = Student.query.filter_by(name="张三").filter_by(age=18).all()
# print(more_filter_all)# [<Student 1>, <Student 6>]
# 更新,方式一:通过给查询结果赋值进行更新
# id_stu = Student.query.filter_by(id=1).first()
# id_stu.name = "张三三"
# id_stu = Student.query.filter_by(id=1).first()
# print(id_stu.name)# 张三三
# 更新,方式二:给查询结果直接update
# Student.query.filter_by(id=1).update({"name":"张三三三"})
# name_stu = Student.query.filter_by(id=1).first()
# print(name_stu.name)# 张三三三
# 删除,方式一:先获取查询结果,然后用session进行删除
# zss_student = Student.query.filter_by(name="张三三三").first()
# db.session.delete(zss_student)
# zss_student = Student.query.filter_by(name="张三三三").first()
# print(zss_student)
# 删除,方式二:查询之后直接删除
zssi_stu = Student.query.filter_by(name="张四四").first()
print(zssi_stu)# <Student 7>
Student.query.filter_by(name="张四四").delete()
zssi_stu = Student.query.filter_by(name="张四四").first()
print(zssi_stu)# None
# 提交session
db.session.commit()
# 关闭session
db.session.close()
四、多表关系
1、多表关系-一对多
(1)一对多关系
-
场景:
- 学生表:一个班级里面有多个学生;
- 班级表:有很多个班级,但是一个学生只会有一个班级
-
处理:建立两个表的关系,在学生表中,将学生的班级id作为外键,和班级表的班级id进行联系;
(2)一对多表结构
-
外键:在“一”的表中使用“多”的表中的值作为外键;
-
class_id = Column(Integer,ForeignKey("classinfo.id"))–在学生表中,本表中的class_id以班级表中的id为外键;
-
-
指定两个表的关系:这样在查询操作的时候,直接通过本表就可以查询的对应关系表中的信息,而不用去查另一个表;
-
class_info = db.relationship("ClassInfo",backref="student");- 1、relationship()方法是让两个表建立关系;
- 2、第一个参数表示关系的另一端是哪个表;–参数是当前类的类名;;
- 3、第二个参数backref表示反向引用,需要从班级id为1反向获取多个学生的时候使用的属性;–参数是给当前这个表起了一个别名;
-
创建表结构:
"""
多表关系-一对多-表结构
场景:
学生表:一个班级里面有多个学生;班级表:有很多个班级,但是一个学生只会有一个班级
处理:建立两个表的关系,在学生表中,将学生的班级id作为外键,和班级表的班级id进行联系
"""
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import *
# 实例化服务
app = Flask(__name__)
# 对服务进行配置:和数据库建立连接
username = "root"
password = "123456"
host = "127.0.0.1"
port = "3306"
database = "studentmanager"
app.config["SQLALCHEMY_DATABASE_URI"] = f"mysql+pymysql://{username}:{password}@{host}:{port}/{database}"
# 将服务给到SQLAlchemy获取db对象
db = SQLAlchemy(app)
# 获取当前上下文,并将其推到栈顶
context = app.app_context()
context.push()
# 创建班级表
class ClassInfo(db.Model):
# 设置表名
__tablename__ = "classinfo"
# 设置表字段
id = Column(Integer,primary_key=True)
name = Column(String(20))
# 创建学生表
class StudentInfo(db.Model):
# 设置表名
__tablename__ = "studentinfo"
# 设置表字段
id = Column(Integer,primary_key=True)
name = Column(String(20))
# 学生班级,作为外键,和班级表进行关联
class_id = Column(Integer,ForeignKey("classinfo.id"))
"""
问题:当需要通过学生的信息直接查询班级表中的信息时要如何查询?
1、通过学生表查询到班级id,然后再通过班级id去查班级表查班级信息---需要查询两个表;
2、通过在学生表中指定两个表的关系信息,再通过这个关系信息直接获取班级信息---只查询一个表;
方法:db.relationship("ClassInfo",backref="StudentInfo")
1、relationship()方法是让两个表建立关系;
2、第一个参数表示关系的另一端是哪个表;--参数是当前类的类名;
3、第二个参数backref表示反向引用,需要从班级id为1反向获取多个学生的时候使用的属性;--参数是给当前这个表起了一个别名;
"""
class_info = db.relationship("ClassInfo",backref="student")
if __name__ == '__main__':
# 创建所有表
db.create_all()
(3)一对多增删改查
添加数据
- 注意:作为外键的数据需要先被添加才行,不然会报错;比如下方的代码,需要先添加班级信息之后才能添加学生信息;
添加数据:
"""
给表添加数据
"""
from L3.multi_table_relationship.one_to_more_relationship.table_structure import ClassInfo, StudentInfo, db
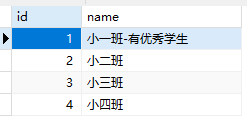
# 班级信息数据
class_1 = ClassInfo(id=1,name="小一班")
class_2 = ClassInfo(id=2,name="小二班")
class_3 = ClassInfo(id=3,name="小三班")
class_4 = ClassInfo(id=4,name="小四班")
# 学生信息数据
stu_1 = StudentInfo(id=1,name="张三",class_id=1)# 在小一班
stu_2 = StudentInfo(id=2,name="张四",class_id=1)# 在小一班
stu_3 = StudentInfo(id=3,name="张五",class_id=1)# 在小一班
stu_4 = StudentInfo(id=4,name="李三",class_id=2)# 在小二班
stu_5 = StudentInfo(id=5,name="李四",class_id=2)# 在小二班
stu_6 = StudentInfo(id=6,name="李五",class_id=2)# 在小二班
stu_7 = StudentInfo(id=7,name="王三",class_id=3)# 在小三班
stu_8 = StudentInfo(id=8,name="王四",class_id=3)# 在小三班
stu_9 = StudentInfo(id=9,name="赵三",class_id=4)# 在小四班
stu_10 = StudentInfo(id=10,name="赵四",class_id=4)# 在小四班
# 全部添加到表--注意,由于学生表用到了班级表的id作为外键,在条件数据的时候,需要先添加班级信息
db.session.add_all([class_1,class_2,class_3,class_4])
db.session.add_all([stu_1,stu_2,stu_3,stu_4,stu_5,stu_6,stu_7,stu_8,stu_9,stu_10])
# session提交
db.session.commit()
# 关闭session
db.session.close()

查询数据-多查一
- 通过学生姓名查询这个学生所在的班级;
from L3.multi_table_relationship.one_to_more_relationship.table_structure import StudentInfo, ClassInfo
# 通过学生id查询这个学生所在的班级name
# 方法一:通过学生表查询到班级id,然后再通过班级id去查班级表查班级信息---需要查询两个表;
stu_zhangsan = StudentInfo.query.filter_by(name="张三").first()
class_zhangsan = ClassInfo.query.filter_by(id=stu_zhangsan.id).first()
print(f"张三所在班级为:{class_zhangsan.name}")# 张三所在班级为:小一班
# 方法二:不需要通过班级表,直接在学生表查---只差一个表
stuinfo_zhangsan = StudentInfo.query.filter_by(id=stu_zhangsan.id).first()
print(stuinfo_zhangsan.class_info)# <ClassInfo 1> --得到了班级所有信息
print(f"张三所在班级为:{stuinfo_zhangsan.class_info.name}")# 张三所在班级为:小一班
查询数据-一查多
- 通过班级id查询这个班有多少学生;
from L3.multi_table_relationship.one_to_more_relationship.table_structure import ClassInfo
classinfo = ClassInfo.query.filter_by(id=1).first()
# 因为在StudentInfo表的结构中使用了db.relationship("ClassInfo",backref="student")指定了两个表的关系
print(classinfo.student)# [<StudentInfo 1>, <StudentInfo 2>, <StudentInfo 3>]
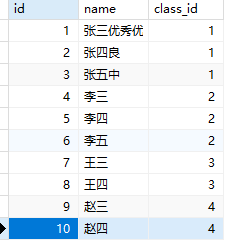
更新修改数据-一改多
- 通过班级修改学生信息;
from L3.multi_table_relationship.one_to_more_relationship.table_structure import ClassInfo, db
class_info = ClassInfo.query.filter_by(id=1).first()
print(class_info.student)# [<StudentInfo 1>, <StudentInfo 2>, <StudentInfo 3>]
# 把所有学生的名字都进行修改
class_info.student[0].name = class_info.student[0].name + "优秀"
class_info.student[1].name = class_info.student[1].name + "良"
class_info.student[2].name = class_info.student[2].name + "中"
# 提交session
db.session.commit()
# 关闭sess
db.session.close()
更新修改数据-多改一
- 通过学生修改班级信息;
from L3.multi_table_relationship.one_to_more_relationship.table_structure import StudentInfo, db
stu_info = StudentInfo.query.filter_by(id=1).first()
print(stu_info.class_info)
# 修改该学生所在班级信息
stu_info.class_info.name = stu_info.class_info.name + "-有优秀学生"
# 提交和关闭session
db.session.commit()
db.session.close()
删除数据
- 一般都是一删多,比如删除一个班级下所有的学生;
from L3.multi_table_relationship.one_to_more_relationship.table_structure import StudentInfo, db, ClassInfo
# 删除id为1班级的所有学生
# StudentInfo.query.filter_by(class_id = 1).delete()
# db.session.commit()
# db.session.close()
# 使用filter,而不用filter_by
class_2 = ClassInfo.query.filter_by(id=2).first()
# 删除
StudentInfo.query.filter(StudentInfo.class_id == class_2.id).delete()
db.session.commit()
db.session.close()
2、多表关系-多对多
- 场景:
- 一个学生对应多个老师;
- 一个老师对应多个学生;
- 定义三张表,需要创建一个中间表(关系表);
- 在两个业务表中的任意一个中需要使用
relationship()方法关联两张表;

(1)表结构
"""
* 场景:
* 一个学生对应多个老师;
* 一个老师对应多个学生;
* 定义三张表,需要创建一个中间表(关系表);
* 在两个业务表中的任意一个中需要使用`relationship()`方法关联两张表;
"""
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import *
from sqlalchemy.orm import relationship
# 创建服务实例
app = Flask(__name__)
# 服务配置连接数据库
username = "root"
password = "123456"
host = "127.0.0.1"
port = "3306"
database = "studentmanager"
app.config["SQLALCHEMY_DATABASE_URI"] = f"mysql+pymysql://{username}:{password}@{host}:{port}/{database}"
# 通过SQLAlchemy得到db对象
db = SQLAlchemy(app)
# 将当前上下文推到栈顶
context = app.app_context()
context.push()
# 创建学生表
class StudentNew(db.Model):
__tablename__ = "student_new"
# 创建表字段
id = Column(Integer,primary_key=True,autoincrement=True)
name = Column(String(20),nullable=False,unique=True)
# 重写这个魔法函数定义返回的数据格式
def __repr__(self):
return f"<Teacher id={self.id},name={self.name}>"
# 创建中间表
teacher_student_relationship = db.Table(
# 第一个参数--表名
"teacher_student",
# 第二个参数--定义一个字段,以teacher的id作为外键,目的是关联teacher表
# 参数一:关系表的字段名;
# 参数二:字段数据类型;
# 参数三:以teacher.id为外键;
# 参数四:不能为空;
# 参数五:为主键;
Column("teacher_id",Integer,ForeignKey("teacher_new.id"),nullable=False,primary_key=True),
Column("student_id",Integer,ForeignKey("student_new.id"),nullable=False,primary_key=True)
)
# 创建老师表,并指定和学生表和中间表的关系
class TeacherNew(db.Model):
__tablename__ = "teacher_new"
# 定义字段
id = Column(Integer,primary_key=True,autoincrement=True)
name = Column(String(20),nullable=False,unique=True)
# 指定和学生表及中间表的关系
"""
参数一:指定关系另一边是什么表,需要使用类名;
参数二:指定关系表,用表名或者表对象都可以;
参数三:给当前表起一个别名,发射到当前表;
"""
students = relationship(
"StudentNew",
secondary=teacher_student_relationship,
backref="teachers"
)
# 重写这个魔法函数定义返回的数据格式
def __repr__(self):
return f"<Teacher id={self.id},name={self.name}>"
if __name__ == '__main__':
# 创建表
db.create_all()
(2)添加数据
from L3.multi_table_relationship.more_to_more_relationship.table_structure import StudentNew, TeacherNew, db
# 添加三个学生三个老师--id为自增,不用传
stu1 = StudentNew(name="学生1")
stu2 = StudentNew(name="学生2")
stu3 = StudentNew(name="学生3")
teacher1 = TeacherNew(name="老师1")
teacher2 = TeacherNew(name="老师2")
teacher3 = TeacherNew(name="老师3")
db.session.add_all([stu1,stu2,stu3,teacher1,teacher2,teacher3])
# 建立关联关系
# 老师1 --学生1,学生2
# 老师2 --学生2,学生3
# 老师3--学生1,学生2,学生3
teacher1.students = [stu1,stu2]
teacher2.students = [stu2,stu3]
teacher3.students = [stu1,stu2,stu3]
# session提交
db.session.commit()
# 关闭session
db.session.close()
(3)查询数据
"""
查询学生对应的老师
查询老师对应的学生
"""
from L3.multi_table_relationship.more_to_more_relationship.table_structure import StudentNew, TeacherNew
# 查询学生对应的老师
stu1 = StudentNew.query.filter_by(id=1).first()
print(stu1)# <Teacher id=1,name=学生1>
# 通过老师表中定义的反向引用,在学生对象中可以通过反向引用时的别名去访问老师
print(stu1.teachers)# [<Teacher id=1,name=老师1>, <Teacher id=3,name=老师3>]
# 查询老师对应的学生
teacher1 = TeacherNew.query.filter_by(id=1).first()
print(teacher1)# <Teacher id=1,name=老师1>
# 通过老师表中定义的关系有一个students属性去获取学生信息
print(teacher1.students)# [<Teacher id=1,name=学生1>, <Teacher id=2,name=学生2>]
(4)更新数据
"""
查询学生id=1,修改对应的老师名字
查询老师id=2,修改对应的学生姓名
"""
from L3.multi_table_relationship.more_to_more_relationship.table_structure import StudentNew, db, TeacherNew
# 查询学生id=1,修改对应的老师名字
stu1 = StudentNew.query.filter_by(id=1).first()
print(stu1.teachers)# [<Teacher id=1,name=老师1>, <Teacher id=3,name=老师3>]
# stu1.teachers[1].name = "老师三-修改"
# 查询老师id=2,修改对应的学生姓名
teacher2 = TeacherNew.query.filter_by(id=2).first()
print(teacher2.students)# [<Teacher id=2,name=学生2>, <Teacher id=3,name=学生3>]
teacher2.students[1].name = "学生3-修改"
# 提交session
db.session.commit()
# 关闭sess
db.session.close()
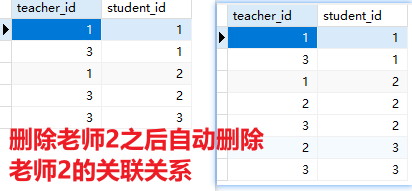
(5)删除操作
- 删除学生
- 删除老师
- 关联关系会被自动删除
from L3.multi_table_relationship.more_to_more_relationship.table_structure import TeacherNew, db, StudentNew
# 删除id=2老师
teacher2 = TeacherNew.query.filter_by(id=2).first()
# db.session.delete(teacher2)
# 删除id=2学生
stu2 = StudentNew.query.filter_by(id=2).first()
db.session.delete(stu2)
# 提交和关闭session
db.session.commit()
db.session.close()