Pychram快捷键
- 查看路径:PychramIDE–help–Keymap Refarence
python编程规范(更多看python的代码风格指南)
- 缩进:4个空格
- 注释:1、单行注释–ctrl+/ 2、多行注释–‘’’ ‘’’
- 命令规范
- 包名尽量短小,全小写字母,不推荐使用下划线
- 模块名尽量短小,全小写字母,可以使用下划线分隔多个字母
- 类名采用单词首字母大写形式
- 常量命名全部采用大写字母,可以使用下划线
- 变量、函数名也全是小写字母,多个字母间采用下划线分隔开
- 使用单下划线_开头的模块、变量、函数是受保护的
- 使用双下划线__开头的实例变量或者方法是私有的
python的数据类型
- 基本的数据类型:Number-数字(整数-int、浮点-float、复数-complex,用j表示复数)、String-字符串、bool-布尔
- 复合数据类型:list-列表、Tuple-元祖、Dict-字典、set-集合
- 空类型:None
- 对上面的类型进一步细分
- 不可变数据类型:Number-数字、String-字符串、bool-布尔、Tuple-元祖
- 可变数据类型:list-列表、Dict-字典、set-集合(不可重复)
- 类型转换:
- 自动类型转换:程序在执行过程中,自动完成,将数据精度低的转换为数据精度高的类型
- 强制类型转换:需要在代码中使用类型函数来转换。
- 类型函数:int()/float()/complex()/bool()/str()/char()
python运算符
- 算数运算符:+、-、*、/、%、//
- 赋值运算符:=、+=、-+、*=、/=
- 关系运算符:==、!=、>、>=、<、<=
- 逻辑运算符:and、or、not
- 成员运算符:in、not in
- 身份运算符:is、is not 、is和==的区别:is–是,==比的是地址值
- 三目运算符:a = true的返回 if 条件表达式 else false的返回
python数据结构的操作
- 字符串、列表、元祖、字典,集合
- 深拷贝与浅拷贝–前提是可变的
- 深拷贝:完全的复制一份,在内存中开辟一份空间存储(父+子对象)
- 浅拷贝:父对象在新的空间内存,子对象还是在原内存中存储。只是父对象的指针发生变化
Python的各种语句
- 分支语句
- if:条件判断语句
- if else:判断语句
- if elif …else:多重判断语句
- 匹配语句:3.10中增加的新特性
- match:语法
-
match expr: case pattern1: xxxx case pattern2: xxxx case patterN: xxxx case _: #默认匹配,即没有匹配任何模式的情况下执行该语句块。 xxxx
-
- match:语法
``
-
循环语句:
- while:while循环
- for in:遍历可迭代对象
- for in range():遍历数字序列
- 循环嵌套:可以for嵌套for ,for嵌套while、while嵌套for
- 循环跳转:continue–结束本次循环进入下次循环 break:终止循环
-
推导式:Python 四种推导式,你学会了没?_python 元组推导式-CSDN博客
- 元祖推导式:元祖推导式和列表推导式的用法相同,只是用()表示,注意:元祖推导式返回的是:生成器对象
- (表达式 for 变量 in 序列)
- (表达式 for 变量 in 序列 if 判断条件)
-
a = (x for x in range(1,10)) # <generator object <genexpr> at 0x7faf6ee20a50> print(tuple(a)) # (1, 2, 3, 4, 5, 6, 7, 8, 9)
-
- 列表推导式:
- [表达式 for 变量 in 列表]
- [表达式 for 变量 in 列表 if 判断条件]
-
names = ['Bob','Tom','alice','Jerry','Wendy','Smith'] new_name = [n for n in names if len(n) > 3]
-
- 字典推导式:
- {key:value for value in 序列}
- {key:value for value in 序列 if 条件表达式} # 也可以写多个for循环
-
listdemo = ['Google','Runoob', 'Taobao'] newdict = {key:len(key) for key in listdemo} print(newdict) # {'Google': 6, 'Runoob': 6, 'Taobao': 6} -
dic = {x: x**2 for x in (2, 4, 6)} print(dic) # {2: 4, 4: 16, 6: 36}
-
- 集合推导式:
- {表达式 for i in 序列}
- {表达式 for i in 序列 if 条件表达式}
- 元祖推导式:元祖推导式和列表推导式的用法相同,只是用()表示,注意:元祖推导式返回的是:生成器对象
-
匿名函数:lambda表达式
- 语法:value = lambda 参数x:对参数x操作的表达式
- value = lambda x:x**2
- lambda表达式的使用场景:
- 对字典进行排序:
- 语法:value = lambda 参数x:对参数x操作的表达式
d = {'a': 1, 'c': 3, 'b': 2}
sorted_items = sorted(d.items(), key=lambda x: x[1])
sorted_dict = {}
for item in sorted_items:
sorted_dict[item[0]] = item[1]
print(sorted_dict)
- 递归算法:函数可以在自己的函数体内根据条件,自己调用自己的函数,那么这样自身调用自身的过程或者说行为,我们称之为递归
- 用递归实现阶乘
-
def n(x): if x == 1: return 1 else: return x * n(x - 1)
-
- 用递归实现阶乘
python面向对象
- 面向对象编程的原则: 面向对象7大设计原则 - 知乎 (zhihu.com)
- 单一职责原则:最简单的面向对象设计原则,可以理解为一个类只负责一个功能领域中响应职责,即一个类不要负责太多的’杂乱’工作
- 开闭原则:对扩展开放,对修改关闭
- 里氏替换原则:此原则针对继承提出的,虽然继承有很大的优势, 可以提高代码的复用性和可扩展性, 但是继承是侵入式的, 只要继承就必须拥有父类的属性和方法,体系结构复杂, 而且继承机制很大的增加了耦合性(父类被子类继承,父类功能修改会影响子类),
也就是说子类继承父类后,尽量不要重写父类的方法,可以新增扩展其他的功能, 保证子类功能的正确性. 不能让功能修改后,导致程序出错. - 依赖倒置原则:上层模块不应该依赖底层模块,它们都应该依赖于抽象, 抽象不应该依赖于细节,细节应该依赖于抽象, 也就是程序要依赖于抽象接口,不要依赖于具体实现。简单的说就是要求对抽象进行编程,不要对实现进行编程,这样就降低了客户与实现模块间的耦合。也就是针对抽象层编程,面向接口编程
- 接口隔离原则:使用多个接口,而不使用单一的总接口,不强迫新功能实现不需要的方法。
- 组合/聚合原则:优先使用组合,使系统更灵话,其次才考虑继承,达到复用的目的。
- 闭包与装饰器
- 函数引用:将
函数名赋值给一个变量,之后用变量去调用此函数,这就是函数引用 - 什么是闭包:嵌套函数,内函数和外函数。
- 内部函数可以访问外部函数定义的变量或者参数即使外部函数已经执行完毕
- 闭包可以在外部函数的作用域之外被调用和执行
- 闭包可以访问并修改外部函数中的局部变量,使其具有持久性。
- nonlocal:内函数是不能直接修改外部函数的变量的,如果需要修改需要在内函数中先声明一下外部函数的变量
- 闭包最大的使用场景:装饰器
- 什么是装饰器:装饰器是python的语法糖,用@加上装饰器名称,用于修改其他函数的行为,并且在不修改原始函数定义的和调用的情况下添加额外的功能。闭包的外部函数名,就作为装饰器的名使用。
-
通用装饰器的模板代码
def out_fun(fun): def in_func(*args, **kwargs): result = fun(*args, **kwargs) return result return in_func -
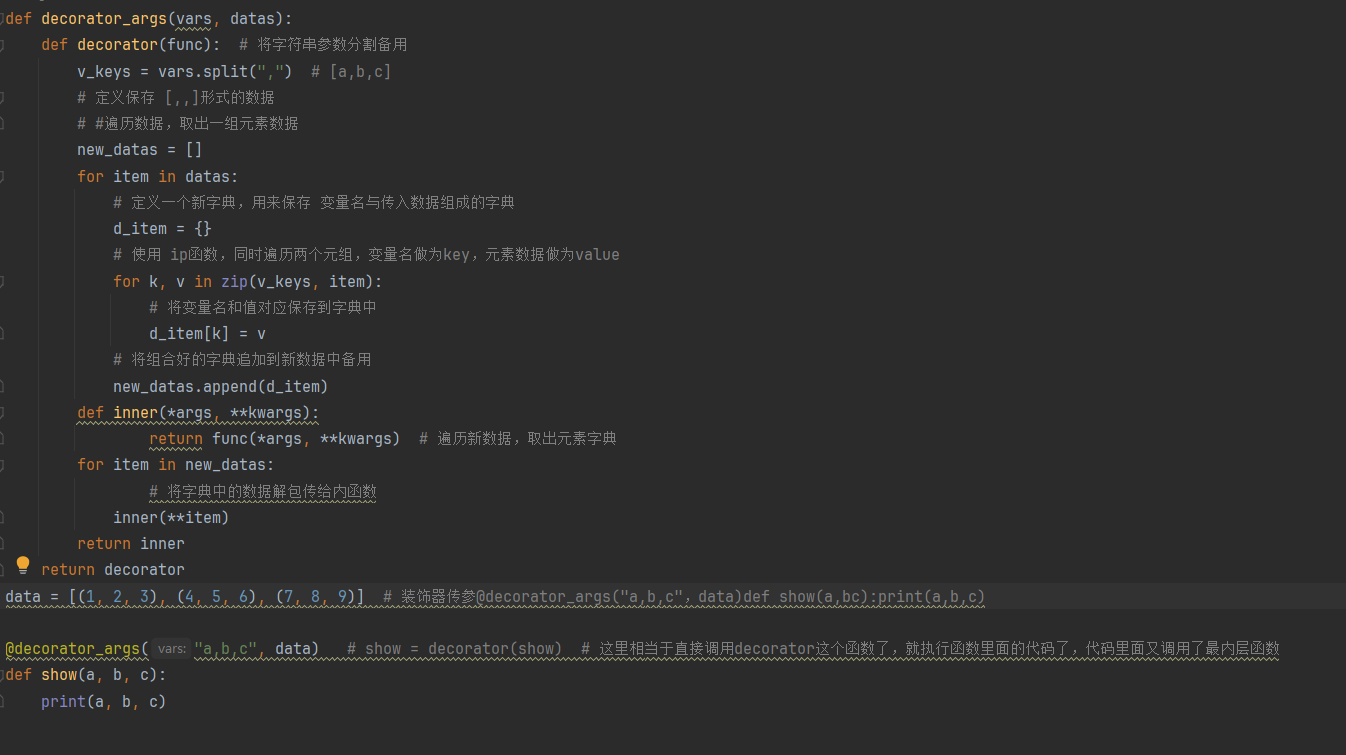
带参数的装饰器:除了普通的装饰器之外,在使用装饰器时还需要向装饰器传递一些参数,比如测试框架pytest实现数据驱动的时候,可以将测试数据以参数的形式传入,那么前面定义的普通装饰器就不能满足需求了,所以在通用装饰器的基础上,再从外层定义一层函数,来接收装饰器的参数(注意:具体的最外层函数,写几个参数,需要根据装饰器具体有几个参数来定义,有1个,就定义1个,以此类推)
def decorator_args(vars, datas): def decorator(func): def inner(*args, **kwargs): return func(*args, **kwargs) return inner return decorator -
带参数的装饰器示例:
-
- 函数引用:将
- 生成器和迭代器 Python高级特性之迭代器与生成器:性能和用法全面解析 (baidu.com)
- 生产器由yield关键字实现;生成器主要用于生成序列
- 迭代器是由:next/__iter__魔术方法实现;迭代器主要用于遍历序列
- 面向对象的三大特性:封装、继承、多态
- 封装:主要包含下面几个方面
- 数据隐藏:将对象的数据属性设置为私有或受保护的,防止外部直接访问和修改对象的数据,这样可以保证对象的对象的数据在被操作时不会被意外篡改或破坏。
- 方法封装:将对象对自身数据的操作封装在方法中,通过方法来访问和修改对象的数据
- 接口定义:通过定义公共接口,将对象的的功能暴露给外部的使用者,使用者只关心如何使用接口提供的定义的方法,而不需要了解内部的实现细节,这样可以提高代码的可读性和可维护性,同时也能够实现代码的模块化和复用。
- python怎么实现访问控制?
- python并没有像java/c++一样的访问控制修饰符,而是通过一种称为 名称改写 的约定来实现访问控制的效果。
- 无下划线:公有权限全,全可以访问
- 单下划线:受保护的权限,外部理论上不能访问,但是继承可以访问
- 双下划线:私有权限,理论上只有类内部可以访问
- 双下划线前后:魔术方法
- 继承:单继承,多继承(根据写的顺序去按个查找)
- 多态:多态是指同一个方法或者操作符在不同的对象实例上可以有不同的行为。这意味着可以通过一个共同的接口或基类引用不同的子类对象,并根据实际的子类对象类型调用响应的方法。
- 多态的好处:
多态的实现通常通过继承和方法的重写实现- 简化代码:通过以相同的方式处理不同的对象,并使用同一的接口进行编程,可以降低代码的复杂性和重复性
- 可维护性:多态可以提高代码的可维护性。当需要新增一个子类的时候,不需要修改已有的代码,只需要新创建一个子类去继承父类,就能够在原有的代码的基础上实现新的功能。
- 扩展性:由于多态允许在不修改已有的代码情况下新增功能,因此可以更容易的对系统进行扩展和适应新需求的变化。
- 鸭子类型:是一种动态类型的概念。源自于,只要走路像鸭子,叫声像鸭子,就任务是鸭子。换到python编程语言上,可以理解的是:只要属性或者方法存在(对比父类),传入子类对象时就可以正常执行。无所谓是不是适合此场景词此类型。由于python语言的动态性导致鸭子类型的存在,这样就会导致只要有一样的方法就能使用,这显然是不对的。就出现了下面两个函数来进行数据的判断。
- isinstance(实例,对象类型)–判断对象是否为某种类型的、issubclass(类,父类)–判断一个类是不是另一个类的子类
- 多态的好处:
- 封装:主要包含下面几个方面
python常用基础库
- random模块:用来生成随机数(整数/小数)、随机取值、随机排序
- sys模块(可以理解为和python解释器交互的模块):系统特定参数和功能库 Python常用标准库-sys库一文详解_python sys库-CSDN博客
- os模块:文件/目录.路径的操作库
- math模块:数学库(可以操作一下加减乘除)
- pikle模块:数据序列化和反序列化时,此模块是非常有用的工具。 数据持久化的利器,Python中的pickle模块详解-CSDN博客
- 用于将Python对象序列化(pickling)为二进制数据,以及从二进制数据反序列化(unpickling)为Python对象
- 数据对象序列化例子,反序列化的例子:
# 将数据对象序列化,写入到文件中,以二进制的形式
import pickle
data = [1, 2, 3, 4, 5]
# 打开一个文件以写入二进制数据
with open('data.pkl', 'wb') as file:
pickle.dump(data, file)
with open('data.pkl', 'wb') as file:
print(pickle.load(file))
- sunprocess模块:直接操作系统命令的库,比如cmd命令/Linux命令 Python subprocess模块学习笔记-CSDN博客
- os.system():也可以执行cmd命令,不带返回值
- os.popen():执行cmd命令,带返回值
- queue模块:数据队列库。 Python队列Queue详解,超详细 - 知乎 (zhihu.com)
- StringIO模块:是python内置的一个标准的库,用于内存中操作字符串,它提供了与文件对象相同的方法,使我们可以像操作文件一样操作字符串,包括:读取,写入与修改。从io模块中导入。 Python(StringIO)模块详解 - 代码先锋网 (codeleading.com)
- logging模块:日志记录模块,logging模块由以下几部分组成 Python日志模块:实战应用与最佳实践 - 知乎 (zhihu.com)
- Logger:用于提供应用程序直接使用的接口
- Handler:将(logger)产生的日志记录发送到合适的目的输出
- Filter:提供了更精细的工具决定输出那些日志记录
- Formatter:指定日志记录的最终输出格式
- logging模块中的日志级别:DEBUG/INFO/ERROR/WARNING/CRITICAL–严重的错误,logging模块默认的日志记录是输出到控制台
- RotatingFileHandler:进行日志的滚动,当我们的应用程序运行很长时间,并产生大量的日志时,所有的日志都写入一个文件可能会导致这个日志文件过大。这时,我们可以使用RotatingFileHandler来进行日志滚动。当达到一定的大小或者一定的时间,RotatingFileHandler会自动备份当前日志文件,并创建一个新的日志文件继续写入
- logger模块的收集器logger:logger的级别设置为WARNING,因此只有级别为WARNING以上的日志会被处理。如果需要打印debug+info日志需要显示的setLevel去设置日志级别
import logging
log = logging.getLogger(__name__)
log.setLevel(logging.DEBUG) # 这是级别,不设置的话默认是warning以上的才会输出
console_handler = logging.StreamHandler() # 这是输出到控制台
log.addHandler(console_handler)
file_handler = logging.FileHandler("./log.log", encoding="utf-8") # 输出到文件
log.addHandler(file_handler)
log_formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
console_handler.setFormatter(log_formatter)
file_handler.setFormatter(log_formatter)
log.debug("这是debug模式")
-
time模块:主要用于处理时间的操作
-
datetime模块:主要用于处理日期和时间的操作 Python中的Time和DateTime (baidu.com)
-
json模块:处理json数据的库;将对象数据编码成json字符串,将json字符串解码成Python对象
【强烈推荐】Python中JSON的基本使用(超详细)_python json-CSDN博客 -
正则表达式re模块:
-
csv模块:处理csv文件的库
csv手册 python csv模块 python_boyboy的技术博客_51CTO博客
解决csv.writer写入文件有多余的空行问题 - Python技术站 (pythonjishu.com)- 读取csv文件:reader()
import csv # 全部是数据的就用这个 with open("data.csv", "rt") as fp: data = csv.reader(fp) for row in data: print(row) # ['1', '2', '3'] # ['4', '5', '6']- 读取csv文件:DictReader
import csv # 如果csv文件第一行是key的就用这个方法 with open("data.csv", "rt") as fp: data = csv.DictReader(fp) for row in data: print(row) # {'1': '4', '2': '5', '3': '6'}- 写csv文件,,无表头:writer()
import csv with open("data1.csv", "wt", newline="") as fp1: # newline不加这个参数写入文件会有默认的空行 writers = csv.writer(fp1) writers.writerow([1, 2, 3]) # 写入单行 writers.writerow(["a", "b", "c"]) writers.writerows([[4, 5, 6], [7, 8, 9]]) # 写入多行- 写csv文件,有表头:DictWriter ()
import csv with open("data2.csv", "wt", newline="") as fp2: fileHeader = ["a", "b", "c"] # 定义文件表头 writers1 = csv.DictWriter(fp2, fileHeader) writers1.writeheader() # 写入文件表头 writers1.writerow({"a": 1, "b": 2, "c": 3}) # 写入一行 writers1.writerows([{"a": 4, "b": 5, "c": 6}, {"a": 7, "b": 8, "c": 9}]) # 写入多行 -
treading模块:多线程库
-
asyncio模块:基于协程的异步编程框架。 「Python」自动化编程之基础库 asyncio 库 (baidu.com)
