linux 基本命令
文件管理
cd +文件目录名称 进入文件目录
ls 查看当前目录文件
查看当前文件目录路径:pwd
创建目录:mkdir
创建文件: touch
删除文件:rm
拷贝文件:cp
移动/剪切文件/重命名:mv
建立链接文件:ln
查找文件:find
find ./ -name +文件名
文件后缀正则匹配:find ./ -name *.txt
查看文件:tall head cat more less
打包文件:tar zip
文件编辑:vi/vim
屏幕输出:echo
输出重定向:>
查看网卡信息:ifconfig
测试远程主机联通性:ping
-c:ping的次数
-I: 每次ping时间间隔
打印网络信息状态:netstat
-t:列出所有tcp
-n:以数字形式显示地址和端口号
-p:显示进程pid的名字
退出linux系统:exit
文件属性

r:文件阅读查看权限
w:文件写入权限
x:文件执行权限
d:目录
拥有者/组/其他
linux性能与统计命令
查看cpu信息:cat /proc/cpuinfo
cpu代表算法的高效性
men 代表数据结构使用合理性
cpu的关键指标:
cpu利用率,进程的cpu利用情况
load average 系统负载情况
查看cpu,内存使用情况:top
top常用参数 -d 间隔时间
-n次数
-u 用户
-p pid
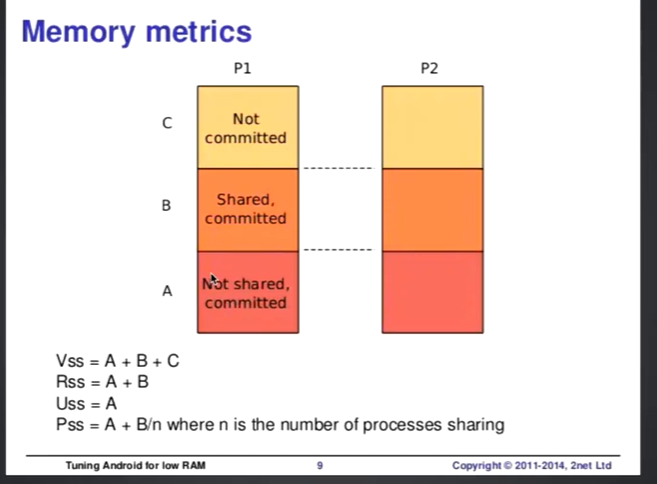
ps 命令cpu平均使用率,内存使用率
free:查看内存占用情况
查看内存数据:cat /proc/meminfo
查看进程:ps -ef , ps -aux
网络连接数 netstat
netstat -tinp 当前机器监听的句柄
-tcp tcp链接数
排序:
sort
常用参数
-b:忽略开头的空白字符
-f:将小写字母看成大写字母
-h:根据存储容量排序
-o:把结果写入文件
-r:以相反的顺序排序
-t:指定分隔符
-v:按照数字版本排序
-k:指定排序的关键字,-t参数配合使用
去除重复:
uniq
常用参数:
-c:统计重复出现的次数
-d:所有临近的重复行只被打印一次,重复次数要大于2
-D:所有临近的重复行将全部打印
-f:跳过对前n个列的比较
-s:跳过对前n个字符的比较
-w:只对每行前n个字符进行比较
字符统计:
wc
常用参数
-l:统计行数
-c:统计字节数
-w:统计单词数
-L:打印最长的长度
三剑客:
awk上下文变量
字段变量用法:
-F参数指定字段分隔符,可以用|指定多个-分割符-F‘<|>’
bengin{FS=“_”}也可以表示分隔符
$0代表当前的记录
$1代表第一个字段
$N 代表第n个字段
$NF代表最后一个字段
$(NF-1)代表倒数第二个字段
pattern表达式
正则匹配$1~/pattern//pattern/
比较表达式$ 2>2 $ 1==“b”
表达式案例
开始和结束 awk ‘begin{}end{}’
正则匹配
·整行匹配 awk ‘Running’
·字段匹配 awk ‘$2~/xxx/’
·行数表达式
·取第二行 awk ‘NR==2’
去掉第一行 awk ‘NR>1’
·区间选择
·awk ‘/aa/,/bb/‘
awk ’/1/,NR==2’
action行为表达式{action}
·打印{print $0}{print $2}
·赋值{$1=“abc”}
·处理函数
·原始内容 $0
`更新后内容{$1=$1;print $0}
