一、多态
多态优点:
-
消除类型之间的耦合关系
-
可替换性
-
可扩充性
-
接口性
-
灵活性
-
简化性
多态存在的三个必要条件
继承
重写
父类引用指向子类对象
多态的格式:
//子类继承父类
父类名称 对象名= new 子类名称 ();
//实现类实现接口
接口名称 对象名 = new 实现类名称();
多态中成员变量的使用:
1、直接通过对象名称访问
2、间接通过成员方法访问
规则:
重写看右(子类),其余看左(父类)
举例:
//父类
public class Father{
public String name=“father”;
public int age=99;
public void fatherRun(){
system.out.println(“父亲特殊跑法”);
}
public void eat(){
system.out.println(“父亲吃法”);
}
}
//子类
public class Son extend Father{
public String gender=“male”;
public int age=99;
@overide
public void eat(){
system.out.println(“儿子吃法”);
}
public void fatherRun(){
system.out.println(“儿子特殊跑法”);
}
}
public class Demo{
public static void main(String args){
Son son1 = new Son();
son1.eat();
Father father1 = new Son();
System.out.println(father1.gender);//访问不通
System.out.println(father1.age);//优先使用父类--对象名称.成员变量
System.out.println(father1.name);//访问自身(父类)字段
father1.eat();//访问重写的子类方法
father1.fatherRun();//子类没有,父类有,调用父类方法
father1.sonRun();//子类有,父类没有,调用不成功
}
}
二、final关键字
final 修饰 类,代表 不可被继承
final修饰方法,代表不可被子类覆盖
final修饰构造方法–报错
final修饰一般方法–正常
final修饰变量,代表常量,不可被重新赋值
final修饰一般成员变量
final修饰静态成员变量
final修饰形参
final修饰局部变量
对于基本数据类型:final修饰的不可变指的是数值不可变。
对于引用数据类型:final修饰的不可变指的是保存的地址值不可变。
当final关键字修饰对象引用的时候,他只能恒定指向一个对象,无法将其改变指向另一个对象,一个既是static又是final的字段只占据一段不能改变的存储空间。
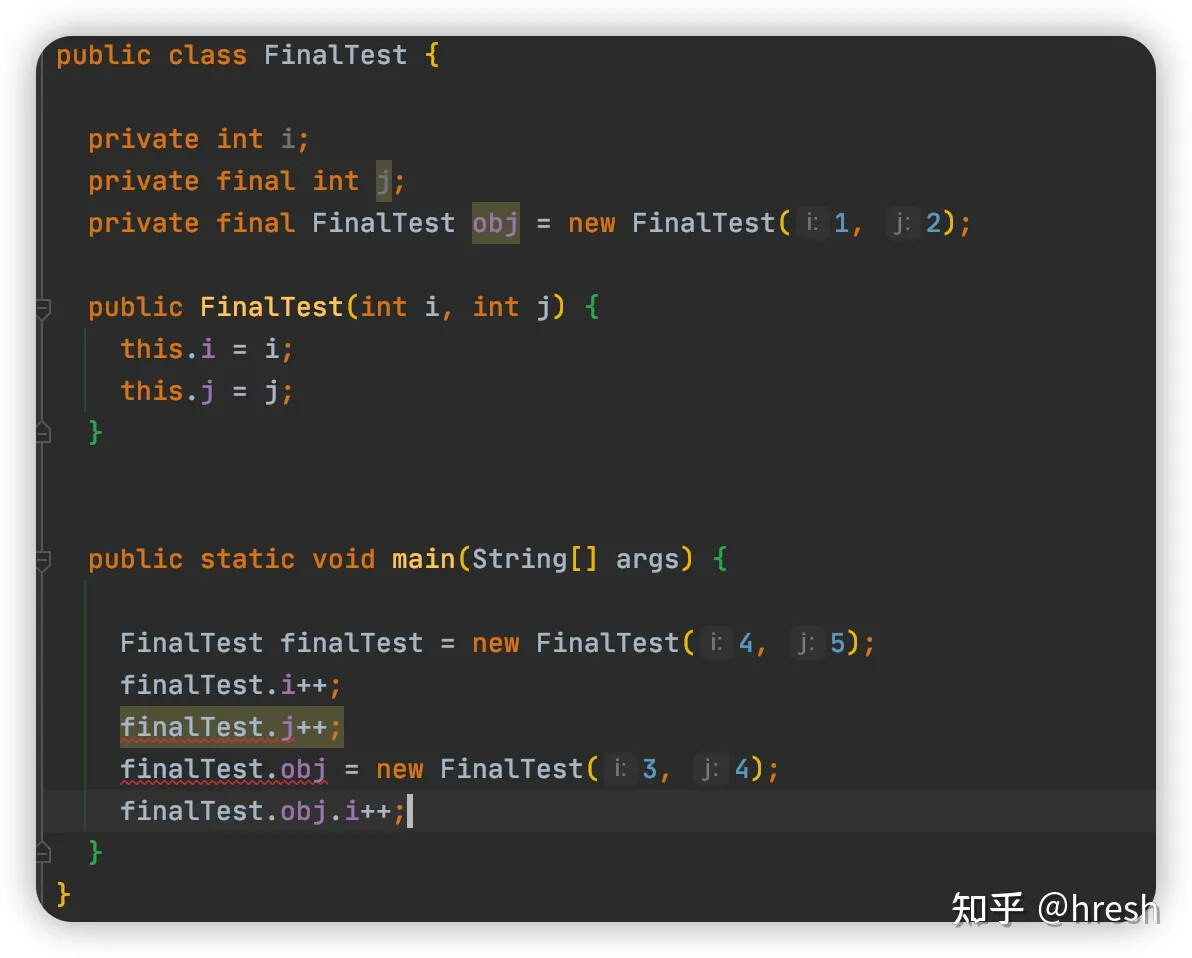
上述代码中,常量 j 和 obj 的重新赋值都报错了,但并不影响 obj 指向的对象中 i 的赋值。
当 final 前加上 static 时,与单独使用 final 关键字有所不同,如下代码所示:
private final int j = 5; private static final int VALUE_ONE = 10; public static final int VALUE_TWO = 100;
static final 要求变量名全为大写,并且用下划线隔开,这样定义的变量被称为编译期常量。
空白final
空白 final 指的是被声明为 final 但又未给定初始值的域,无论什么情况,编译器都确保空白 final 在使用前必须被初始化。比如下面这段代码:
public class FinalTest {
private int i;
private final int j;
public FinalTest(int i, int j)
{ this.i = i; this.j = j; }
}
必须在域的定义处或者每个构造器中用表达式对 final 进行赋值,这正是 final 域在使用前总是被初始化的原因所在。
三、访问权限修饰符
| 本类 | 本包 | 子类 | 其他类 | |
|---|---|---|---|---|
| private | ||||
| 默认 | ||||
| protected | ||||
| public |
四、static关键字
特点:
修饰的变量、方法属于这个类所有,随着类的加载而加载,变量值存储在一个公共的空间;
可以被所有对象共享 :当多个对象中有一个属性都相同时,把这个属性定位static,通过对象调用属性就可共享此属性,能够降低代码重复率;
可以直接被类名调用,工具类不需要创建对象。
使用注意:
静态方法只能访问静态成员。
静态方法中不能写this,super关键字。
- 随意修改static修饰的属性有风险,一般为了避免风险
- final和static配合使用,即把==静态变量==变为==静态常量==
- mian主函数是静态的。
静态代码块:格式: static{}特点:需要通过static关键字修饰,随着类的加载而加载,并且自动触发、只执行一次使用场景:在类加载的时候做一些静态数据初始化的操作,以便后续使用。
五、内部类
内部类的分类:
定义在外部类的局部位置上(如方法内):
1、局部内部类(有类名)
2、匿名内部类(没有类名,重点!!!)
定义在外部类的成员位置上:
1、成员内部类(没有static修饰)
2、静态内部类(使用static修饰)
匿名内部类–Java基础 - 内部类03 - 匿名内部类详解_NorthCastle的博客-CSDN博客
匿名类是不能有名字的类,他们不能被引用,只能在创建时用new语句来声明它们。
匿名类作用:匿名类可以让代码更加简洁,因为它允许声明的同时实例化一个类。类似于局部类,只不过他们没有名字,当只需要一次局部类时,用匿名类更简洁。
匿名类语法格式:
class outerClass { // 定义一个匿名类 object1 = new Type(parameterList) { // 匿名类代码 }; }
以上的代码创建了一个匿名类对象 object1,匿名类是表达式形式定义的,所以末尾以分号 ; 来结束。
匿名类通常继承一个父类或实现一个接口。
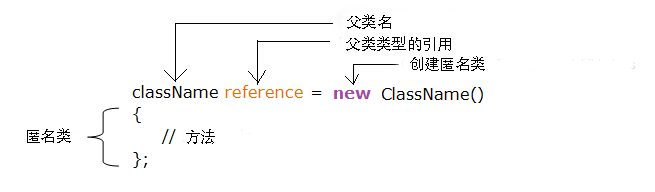
匿名类继承一个父类
以下实例中,创建了 Polygon 类,该类只有一个方法 display(),AnonymousDemo 类继承了 Polygon 类并重写了 Polygon 类的 display() 方法<:/p>
实例
class Polygon {
public void display() {
System.out.println(“在 Polygon 类内部”);
}
}
class AnonymousDemo {
public void createClass() {
// 创建的匿名类继承了 Polygon 类
Polygon p1 = new Polygon() {
public void display() {
System.out.println(“在匿名类内部。”);
}
};
p1.display();
}
}
class Main {
public static void main(String args) {
AnonymousDemo an = new AnonymousDemo();
an.createClass();
}
}
执行以上代码,匿名类的对象 p1 会被创建,该对象会调用匿名类的 display() 方法,输出结果为:
在匿名类内部。
匿名类实现一个接口
以下实例创建的匿名类实现了 Polygon 接口:
实例
interface Polygon {
public void display();
}
class AnonymousDemo {
public void createClass() {
// 匿名类实现一个接口
Polygon p1 = new Polygon() {
public void display() {
System.out.println(“在匿名类内部。”);
}
};
p1.display();
}
}
class Main {
public static void main(String args) {
AnonymousDemo an = new AnonymousDemo();
an.createClass();
}
}
输出结果为:
在匿名类内部。
成员内部类
说明:成员内部类是定义在外部类的成员位置,并且没有static修饰。 1.可以直接访问外部类的所有成员,包含私有的 2.可以添加任意访问修饰符(public、protected、默认、private),因为它的地 位就是一个成员。 3.作用域和外部类的其他成员一样,为整个类体,在外部类的成员方法中创建成员内部类对象,再调用方法. 4.成员内部类—访问---->外部类成员(比如;属性)[访问方式:直接访问] 5.外部类—访问------>成员内部类 访问方式:创建对象,再访问 6.外部其他类—访问---->成员内部类 7.如果外部类和内部类的成员重名时,内部类访问的话,默认遵循就近原则,如果想访问外部类的成员,则可以使用(外部类名.this.成员)去访问
静态成员内部类
和成员内部类的区别是:
1、只可以调用外部类中用static修饰的外部类成员
2、有static就是类层级,类名.调用;没有static就是对象层级,引用.调用
String类
- String 类型不是基本数据类型,而是引用类型
- 引用类型声明的变量称 引用变量
List,quence,set的区别
HashSet、linkedHashSet 和 TreeSet
原文链接:【面试题精讲】比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同-CSDN博客
HashSet 是 Java 集合框架中的一个类,它实现了 Set 接口,并使用哈希表作为其底层数据结构。HashSet 不保证元素的顺序。
LinkedHashSet 是 HashSet 的子类,它通过链表维护插入顺序,即按照元素插入的顺序进行迭代。LinkedHashSet 同样使用哈希表来存储元素。
TreeSet 是 SortedSet 接口的实现类,它使用红黑树(一种自平衡二叉查找树)作为其底层数据结构。TreeSet 会对元素进行排序。
相同点:
都是集合类,用于存储不重复的元素。
都实现了 Set 接口,不允许包含重复元素。
都可以存储 null 元素。
不同点:
底层数据结构:
HashSet 使用哈希表作为底层数据结构,具有较快的插入和查询速度,但不保证元素的顺序。
LinkedHashSet 继承自 HashSet,底层数据结构也是哈希表,但通过链表维护插入顺序,因此能够按照插入顺序进行迭代。
TreeSet 使用红黑树作为底层数据结构,能够对元素进行排序,并且支持有序的集合操作。
元素顺序:
HashSet 不保证元素的顺序,即插入和迭代的顺序可能不一致。
LinkedHashSet 通过链表维护插入顺序,因此可以按照插入顺序进行迭代。
TreeSet 对元素进行排序,默认使用元素的自然顺序(实现 Comparable 接口),或者通过传入 Comparator 进行定制排序。
性能:
HashSet 的插入、删除和查询操作都具有常数时间复杂度 O(1),但由于哈希冲突的存在,性能可能会受到影响。
LinkedHashSet 在 HashSet 的基础上增加了链表来维护插入顺序,因此在迭代方面略微慢于 HashSet。
TreeSet 的插入、删除和查询操作的时间复杂度是 O(logN),其中 N 是元素个数。同时,TreeSet 还提供了一些有序集合操作,如获取子集、范围查找等。
- HashSet、LinkedHashSet 和 TreeSet 的优点
HashSet:插入和查询速度快,适用于需要快速查找元素的场景。
LinkedHashSet:在 HashSet 基础上保持了插入顺序,适用于需要按照插入顺序迭代元素的场景。
TreeSet:能够对元素进行排序,并提供有序集合操作,适用于需要有序集合的场景。
- HashSet、LinkedHashSet 和 TreeSet 的缺点
HashSet:不保证元素的顺序,无法进行有序集合操作。
LinkedHashSet:相比 HashSet 稍微慢一些,在大数据量情况下性能可能受到影响。
TreeSet:插入、删除和查询操作的时间复杂度较高,同时需要实现 Comparable 接口或传入 Comparator 进行定制排序。
- HashSet、LinkedHashSet 和 TreeSet 的使用注意事项
HashSet、LinkedHashSet 和 TreeSet 都是线程不安全的,如果在多线程环境中使用,需要进行外部同步。
在使用 TreeSet 时,要确保元素类实现了 Comparable 接口,或者在构造 TreeSet 时传入 Comparator 进行定制排序。
HashSet 和 LinkedHashSet 允许存储 null 元素,但 TreeSet 不允许。
- 总结
HashSet、LinkedHashSet 和 TreeSet 都是 Java 中的集合类,用于存储不重复的元素。它们之间的主要区别在于底层数据结构和元素顺序。HashSet 使用哈希表作为底层数据结构,不保证元素的顺序;LinkedHashSet 在 HashSet 的基础上通过链表维护插入顺序;TreeSet 使用红黑树作为底层数据结构,并对元素进行排序。选择使用哪种集合取决于具体的需求,如是否需要有序、是否需要快速查找等。
List与 Set
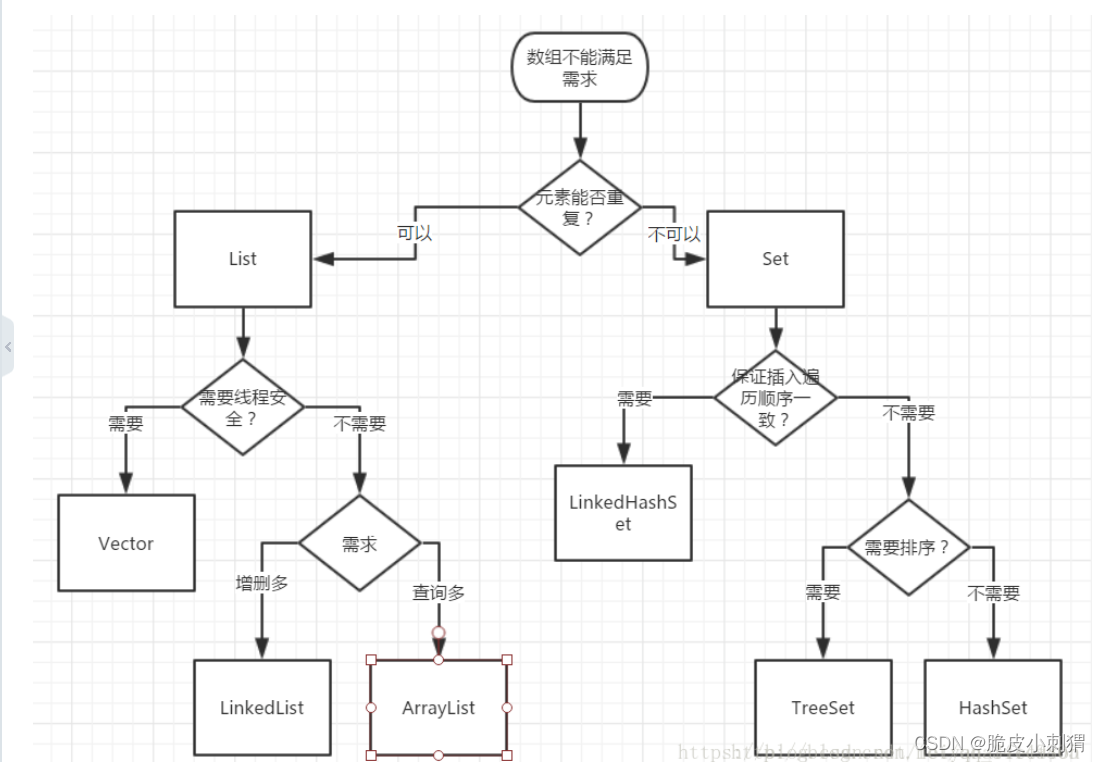
看到array,就要想到索引。
看到link,就要想到first,last。
看到hash,就要想到hashCode,equals.
看到tree,就要想到两个接口。Comparable,Comparator。
HashMap通常比TreeMap快一点(树和哈希表的数据结构使然),建议多使用HashMap,在需要排序的Map时候才用TreeMap
IO流
- 读写数据的基本单位不同,分为 ==字节流== 和 ==字符流==。
- 字节流主要以字节为单位进行数据读写的流
- 字符流主要指以字符(2个字节)为单位进行数据读写的流
- 按照读写数据的方向不同,分为 输入流 和 输出流
- 输入流就是读文件
- 输出流就是写文件
字节流操作的基本单元是字节;字符流操作的基本单元为Unicode码元。 字节流在操作的时候本身不会用到缓冲区的,是与文件本身直接操作的;而字符流在操作的时候使用到缓冲区的。 所有文件的存储都是字节(byte)的存储,在磁盘上保留的是字节。 在使用字节流操作中,即使没有关闭资源(close方法),也能输出;而字符流不使用close方法的话,不会输出任何内容
Stream
ArrayList names= new ArrayList<>();
Collections.addAll(names,“张修饰”,“张三”,“莉丝”,“张武”);
names.stream().filter(s → s.startsWith(“张”)).forEach(s->System.out.println(s));
Stream流式思想核心:
1、先得到集合或数组的stream流(就是一条传送带)
2、把元素放上去
3、然后用stream流式简化的API操作元素
作用:简化集合或数组中的API操作
Stream流常用的API(三类):
获取stream流
创造一条流水线,并把数据放到流水线上准备操作
三种方式如下:
1、集合对象的方法,如names.stream();xxmap.keySet.stream();xxmap.values.stream();xxmap.entrySet.stream()
2、数组-流获取方法一 : Arrays.stream(xxarray)
3、数组-流获取方法二:Stream.of(xxarray)
中间方法
流水线上的操作,一次完毕之后还可以进行其他操作

终结方法
使用其一之后,不可再有其他操作

线程启动
遗留:thread类,rannable接口
错题笔记
1、java中的局部变量一定要初始化,全局变量可以不初始化,有默认值;
2、确保循环不是无限的必要条件是:代码中必须有布尔语句,布尔语句有时是假的,有时是真的。
3、java中操作运算符+ 的优先级大于==
4、所有异常类的基类是:Java.Lang.throwable
5、void函数的返回值是 none
