转自韩照光
原文链接:【藏经阁】基于自动化用例的精准测试探索_代码
☞背景☜
(
在当前web系统或app后端服务测试过程中,黑盒测试占据了大部分的测试,即便是接口测试,也是基于场景的用例设计,这种测试方法完全依赖于测试人员的能力,经验和业务熟悉度,而互联网行业的一大特点就是人员流动性高,这使得线上质量经常是“靠天吃饭”。基于黑盒的测试使的项目测试在测试过程中存在以下几个问题:
(1)黑盒测试受主观人为因素影响太大:黑盒测试完全依赖测试人员的个人能力,经验和业务熟悉度,受主观因素影响太大,不确定性太多,这是产生漏测的根本原因。
(2)测试覆盖面无客观数据可衡量:测试对代码覆盖程度,质量高低,没有客观数据可衡量,完全靠人为主观介定。虽然我们可以拿到全量或增量代码覆盖率数据(增量覆盖率一般需要运行2次全量用例),但对增量代码具体路径是否有覆盖,只能靠人工分析全量覆率报告,且无法区分哪些是原有代码,哪些是diff代码,在代码量稍微大点的项目中,测试排期基本上不允许这种测试方式,从而把测试人员推向黑盒测试,由于没有代码分析支撑,黑盒测试覆盖率随着时间和用例增多,便会触达覆盖率的天花板,更多的是重复的无效测试。
(3)自动化用例作用无发有效发挥:对于web/api或app 后端服务系统,测试人员对除手工测试外,尝试最多的测试手段改进就是接口自动化建设,但自动化建设很少有公司在这个方向做的特别好,投放产出比(ROI)特别高的,其根本原因就是自动化的一个核心指标:稳定性太差,随着项目的迭代,自动化用例积累越来越多,从几百到几千,想要这些自动化用例以CI级别触发(代码提交一次即触发一次),用例全部通过稳定在80%以上,几乎都是不太可能做到的事情。自动化用例稳定性太差,不能产生收益不说,反而会成为QA的包袱,使他们把大量的时间花在自动化用例失败排查上面,疲于应付,又不能发现有效的bug,久而久之,便对自动化失去信任,甚至废弃。
☞问题分析与思路☜
笔者所在产品线后端服务是基于java的SSH框架搭建的,模块数量多,模块间基于rpc分步式协议通信,模块间耦合多,各个投放系统业务逻辑都比较复杂,且RD和QA新人都比较多,传统黑盒测试只能通过人员堆砌和不断的加班加点来适应不断扩充的业务,这使得项目测试质量很难保持在一个较高水平,和业界面临问题一样,也无可避免存在背景中提到的3个问题。产品线的接口自动化测试用例随着迭代积累,用例数多达几千个,如果让这些自动化用例发挥它们的效用呢?
对于背景1,2的问题,我们可以总结为:测试覆盖面是否可以很容易客观数据衡量,测试覆盖面是没有置信度,且在达到这个置信度的过程中有没有工具可以支持QA更快更有效达成?对于背景3中的问题,当自动化用例数到千级别的量级,若100%每次都让这些用例全部运行通过,几乎是不可能的事情,那我们能不能减少这些用例数量呢,每次只运行和代码变更相关的用例,将无关用例的筛选出去呢?
通过对业界和公司其它产品线一些调研,我们发现有些团队也有在这些问题上做一些探索,即精准测试,但基本上都是聚焦在第3个问题上,即通过用例筛选来减少用例执行以提高升CI的稳定性,思路基本上相同,只是实现过程不各不相同。公司内部一些团队尝试也是基于不同的产品特点,如app和前端模板,实现过程不同,这里不再赘述。我们探索方向是,适用于后端服务模块(web或app后端服务,或api,不局限于实现语言),基于接口自动化的精准测试,并将这个概念做了扩展,不再局限于用例筛选,而是3个层面,即:
(1)自动化用例筛选
(2)测试影响面范围评估
(3)增量代码覆盖率分析
下面具体解释一下这3个层面的含义。
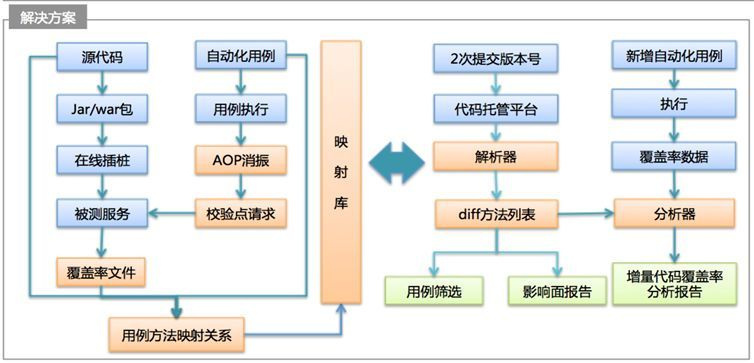
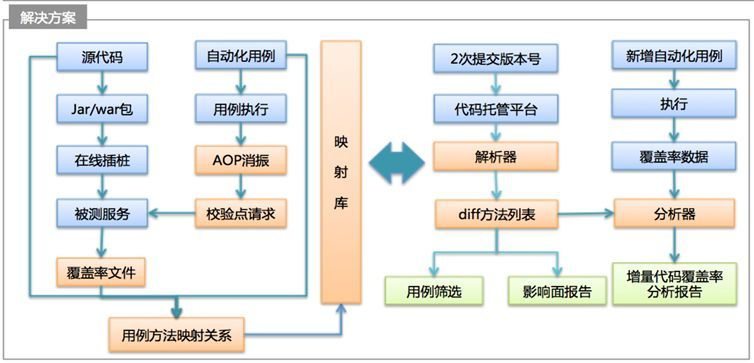
我们方案/设想:基于自动化用例和覆盖率信息,获取单个自动化用例对应代码覆盖路径信息,并建立相应的映射库(知识库),做为数据源。如下图所示
基于获取的映射库信息及系统提供的附加能力,支持以下3个基本场景:
(1)自动化用例筛选:在生成用例和代码覆盖路径映射库信息后,当RD提测时,可以根据代码diff计算出变更的方法列表(新增/修改/删除) ,用方法列表反查映射库,便可以筛选出与变更代码相关联自动化用例,与CI相结合,达到精简用例,减少执行时间,同时减少不必要的用例执行,进而提升CI稳定性,减少CI维护排查代价。
(2)测试范围评估:与场景1相似,在RD 提交代码代码后,以变更方法列表做为条件反查映射库,获取与之关联的自动化用例,根据用例URI聚合,并结合用例描述和FE代码注释,分析给出手工测试范围,一是可以减少测试回归范围,二是可以防止漏评导致的漏测
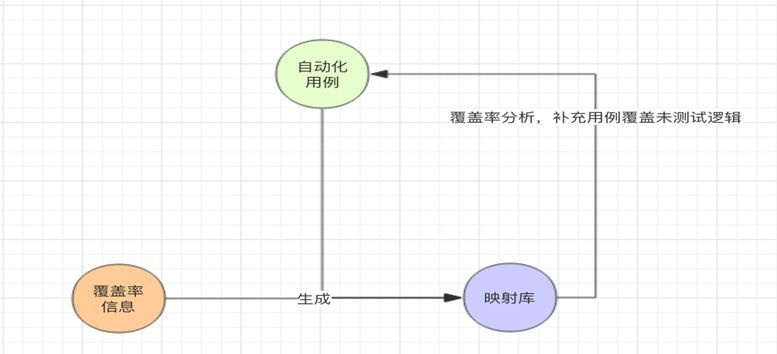
(3)增量代码覆盖分析:新项目测试过程中,新增自动化用例对增量代码变更diff 覆盖信息(生成映射库过程),可以和增量代码变更方法列表做为数据源,通过算法生成增量代码行和分支覆盖率报告,并具体标记哪个分支或行未覆盖,QA可以根据增量代码覆盖率分析报告,针对性进行用例设计补充,从而提升覆盖率,减少漏测。同时报告也使得对增量代码覆盖情况可量化(常见的增量覆盖率数据生成要运行2次全量用例集合,自动化稳定性很难保证,手动回归成本太大,基本不太可行)。另外,对未覆盖函数或分支进行提醒QA做相应的自动化用例补充,从面形成精准测试,双向反馈提升良性循环,更有的放矢,更有据可依,更自信任。
☞方案☜
整体的设计方案如下:
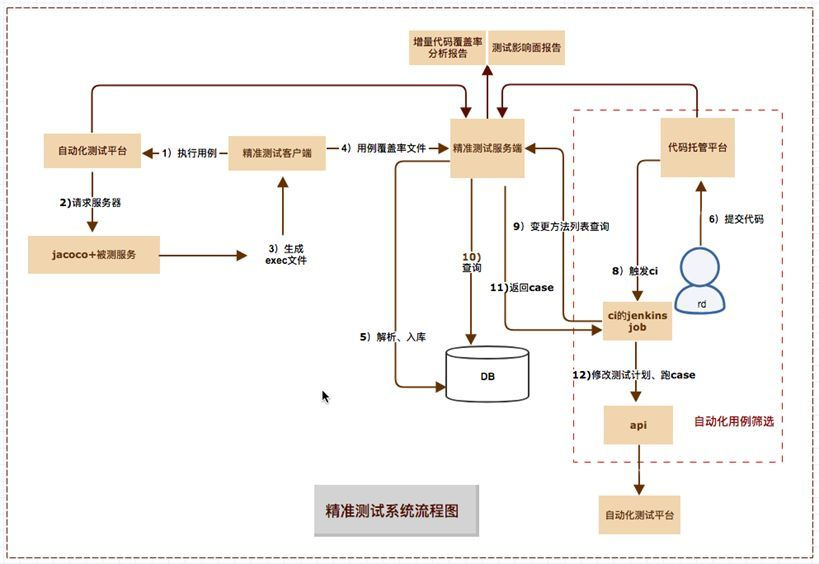
方案背景介绍:
(1)接口自动化用例:基于公司通知接口自动化框架平台书写,分为Http和Rpc两种接口类型
(2)后端服务实现语言为Java,基于SSH+ RPC分布式协议框架
(3)覆盖率工具采用Jacoco开源框架
(4)代码管理系统为公司基于git开发通用代码管理平台
3.1 基础用例和覆盖代码映射信息库生成
顾名思义,用例与代码映射关系即:单个用例与其能覆盖所有代码方法列表(不是类,分支或行)映射关系,这里面有2个难点要解决:一是单个用例覆盖率文件生成代价比较大,二是要消除自动化用例数据构造和清理带来的代码覆盖路径干扰,在这里我们称之为消振。
先看第一个问题,单个用例覆盖率文件生成代价大。对于收集web或jvm运行后端服务来说,接口级用例覆盖率收集比单测更为复杂,需要很大的时间、空间开销,并带来稳定性隐患。具体如下
(1)时间开销,每个用例都需要命令行插桩,启动被测服务,停止补测服务,dump并生成覆盖率文件,且不说覆盖率工具的命令行操作,单服务的启停服务就会带来不菲的时间开销
(2)空间开销调用脚本及源代码,用列执行,被测服务分别处于不同的机器,在生成覆盖报告时需要源代码和覆盖文件同源,需要额外的操作成本
(3)启停被测服务给覆盖文件生成带来不可控因素,每次服务启动都可能在启动中或启动失败
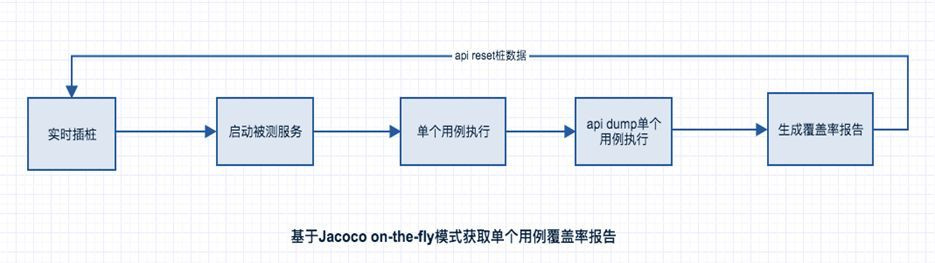
常见的离线插桩方式获取单个用例覆盖报告流程如下:

通过调研选型,我们发现基于Jacocoon-the-fly模式可以在不停服的情况下,通过api导致覆盖率文件。关于Jacoco的注入原理以及注入方式,在官方网站上写的非常详细了,不做过多赘述。基于On-the-fly 方式无须入侵应用启动脚本,只需在JVM 中通过-javaagent 参数指定jar 文件启动Instrumentation 的代理程序,代理程序在通过Class Loader 装载一个class 前判断是否需要注入class 文件,将统计代码插入class ,测试覆盖率分析就可以在JVM 执行测试的过程中完成。Jacoco提供了自己的Agent,完成插桩的同时,还提供了丰富的dump输出机制,如File,Tcp Server,Tcp Client。覆盖率信息可以通过文件或是Tcp的形式输出。这样外部程序可很方便在任意机器上通过api随时拿到被测程序的覆盖率。
基于Jacocoon-the-fly 模式获取单个用例覆盖率报告流程如下:
再来看第二个问题:如何消除自动化用例数据构造和清理带来的代码覆盖路径干扰。即单个用例可以独立重复在不同环境间重复运行,要求用例只能依赖setup/teardown做数据构造和清理,举例来说,验证一个update物料属性A的用例,setup里需要构造2个请求创建物料管理计划,及物料本身,Case为修改物料属性A接口请求及其对应的校验点,最后是teardown里的数据清理,删除物料及基对应的管理计划。在这种情况下,若以Case为粒度收集与之对应的代码方法列表,会有很多干扰数据进来,物料所属的管理计划,物料对应add和delete接口关联的方法都会被收集到,所以我们要清除这些干扰数据,要收集以包含校验点请求与之对应代码方法列表,即只收集update 物料属性A这个请求对应关联方法列表。
来看我们的解决方案:
(1)自动化用例的原子性:单个用例验证一个接口,且被校验接口所在请求统一命名,如”request”。
(2)利用AOP原理,在自动化框架的执行器加一个拦截器,在覆盖率收集开关打开且请求名称命中request的请求时,请求执行前:reset 被测服务桩数据,请求执行后:用api导出内存中的覆盖率数据,生成exec文件
(3)在全局变量设置覆盖率收集开关及其它配置,这样即不影响其它产品线使用,就可以在同一台机器上完成用例执行,覆盖率数据收集,桩数据重置,覆盖率报告生成等一系列操作了。
解决这两个问题后,用例和覆盖代码方法列表映射关系生成方案如下图:

3.2 自动化用例筛选
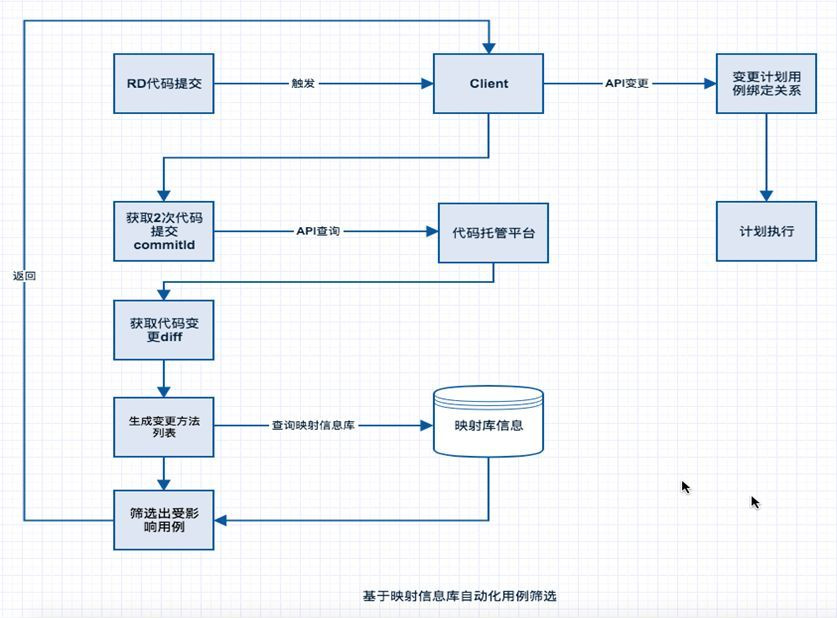
有了用例和代码方法列表映射基础信息库后,我们来看下用例筛选实现逻辑,这里有2个点,一是如何获取变更代码方法列表,二是如何将筛选出散列的用例在自动化框架规则里执行。
先来看获取变更代码方法列表,在这里我们没有采用git原生diff 函数获取代码库2次代码提交中间的代码变更,若基于git原生diff功能,不管是命令行还是api方式,都需要在本地维护一个代码库的副本,过于笨重且稳定性差。所以我们在实现是基于公司通用代码托管平台提供版本对比功能,可以直接获取2次commitid间的代码变更文件,并以json格式返回,处理起来更为方便。获取到代码变更文件,再基于不同语言方法结构,便可直接获取到变更方法列表。
用变更方法列表查询映射信息库便可筛选出受影响的自动化用例,但这些用例是处在松散状态,批量执行需要在计划或测试套件绑定后,加上全局变量配置等要素是无法在自动化框架下执行的。为解决这个问题,我们在自动化框架内开发计划动态更新的API,使计划和用例绑定可以动态更新,并同时配置环境,变量,权限等要素,这样就可以以计划为单位执行筛选出来的自动化用例了。具体的业务逻辑实现见下图:
3.3 测试影响范围评估
在敏捷开发模式下,迭代多,且快。项目在迭代升级的过程,虽然自动化能帮忙覆盖一部分后端代码逻辑回归,但和前端交互部分,当前还没有好的自动化手段来解决,这部分内容回归还是主要靠手工测试来保障。影响范围评估大了,全量手动回归低效,代价太大;影响范围评估小了,容易造成漏评漏测。
这种测试影响范围评估完全靠RB和QA 主观判断来评估,强依赖于个人的经验和能力,再加上人员变更,项目交接等外在因素,经常会有测试范围漏评的现象。例如:工具类B项目开发过程中,对主流程A底层方法methodA有改动,由于RD和QA测试范围评估,经常专注B 升级业务点测试,主流程A的回归测试没有评估到,从而导致没有回归到造成线上问题。那我们能不能用客观的数据来精准评估哪部分需要测试,使手工测试范围也更具体针对性呢?
在这里当某模块的核心接口主流程场景都被自动化用例覆盖到以后,我们可以认为,底层业务逻辑的改动方法列表,同样查询映射库关系获取影响到用例列表,然后将这些用例请求URI或者接口名称去重,聚合,以报告的形式展示出来,QA便可以根据这个报告更有针对性去做手动回归测试,防止漏评现象发生,同时可以减少回归范围,使回归更有针对性。具体的实现原理和3.3中用例筛选类似,这里不再展开。
3.4 增量代码覆盖率分析
在传统黑盒测试过程中,在测试前期能够比较有效发现bug,但在后期主要依赖个人能力和经验探索性测试,往往都是在进行无效的重复测试,而且测试质量没有置信度,基本上没有度量,或者因为度量代价太大被裁剪掉了。
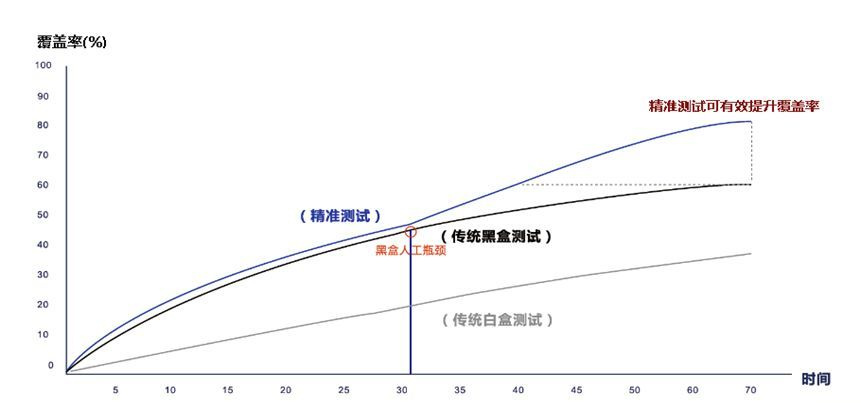
就java语言来说,要产出模块代码增量覆盖率,一般要运行前后2个代码版本全量的用例,分别生成2次生成的全量代码覆盖率做,再计算出增量代码覆盖率。这种情况下全量手工用例回归太低效,自动化全量运行情况下,稳定性很难保证,所以没有可操作性。
另外,在黑盒测试过程,如果想针对提升增量代码覆盖率,只能依赖开源工具生成全量代码覆盖率报告,但全量代码覆盖率报告是无法标记变更代码和已有代码区别的,也不具备可操作性。
为解决这2个问题,我们利用从代码托管平台获取变更方法列表和新增自动化用例生成的覆盖率报告,在分析器中组合计算,一次性产出变更代码增量覆盖率报告,同时标记出未覆盖到方法和分支代码,为测试覆盖提供衡量数据并可以针对设计用例走到未覆盖到的代码,具体的业务逻辑实现如下图:
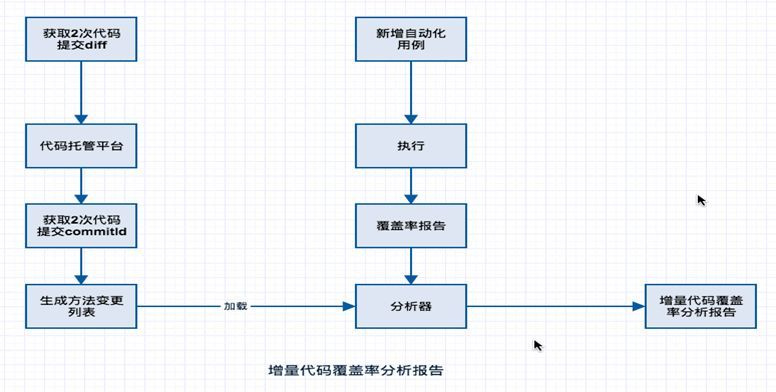
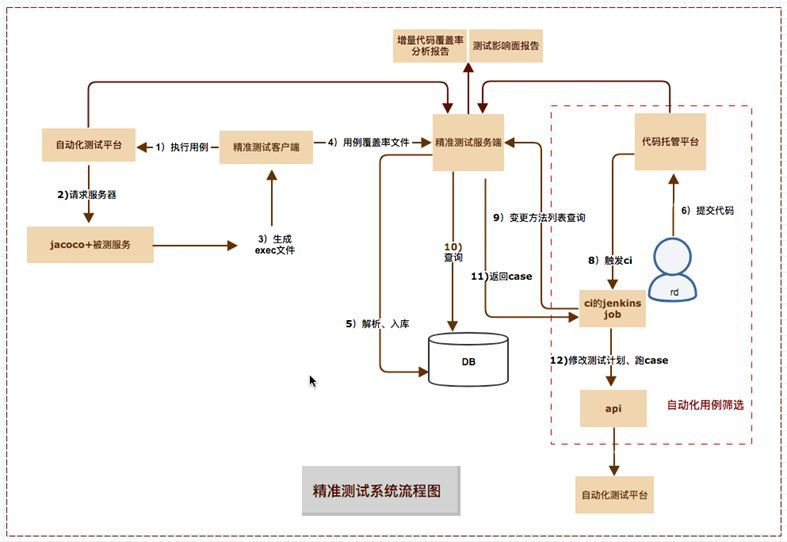
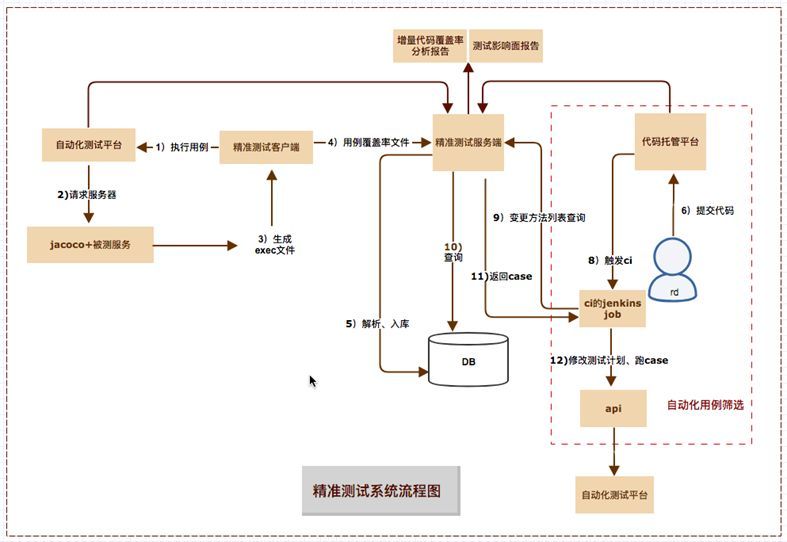
到现在我们便可以将精准测试3个落地场景的业务逻辑综合起来,如下:
☞当前进展(应用现状)☜
(1)产品线后端模块接口自动化用例对应增量代码分支覆盖率>40%做为测试准出标准,测试覆盖面可衡量且可针对性提升。
(2)产品线核心模块local 阶段自动化用例回归,接入自动化用例筛选,CI级别的触发只运行和代码变更相关的用例,用例平均精简比例在50%以上。
(3)产品线线下拦截漏评4次,增量代码覆盖率提升过程中发现10个bug。
☞后续规划☜
(1)支持CI trunk/slow 阶段接入精准测试
(2)用例筛选能力接入业务端系统级测试流量筛选
(3)通用能力开放和扩展,开放api 并支持常见其它语言和自动化框架用例接入
(4)将更多的测试数据源包含进来,为我所用,如rd的历史代码质量情况,方法历史的线下线上bug情况,都可以囊括进来,为更有效的测试提供底层数据支持,即将更多的测试数据为我所用
(5)扩展精准测试范围到精细化测试,针对于代码变更,甚至不同的RD,需要进行什么范围的测试,要进行哪些类型的测试,这些测试有什么的技术手段,测试到什么样的程度,系统都可以给出分析建议和衡量指标。