一、 DDL 数据库操作
(一) 创建
创建数据库语法
- IF NOT EXISTS:可选项,创建前先判断,未存在时才执行创建语句
- 数据库名:必须指定的
- CHARACTER SET =字符集:可选项,用于指定数据库的字符集
-- 创建数据库
CREATE {DATABASE|SCHEMA} [IF NOT EXISTS] 数据库名
CHARACTER SET [=] 字符集
创建数据库注意事项
- 不能与其他数据库重名
- 名称可以由任意字母、阿拉伯数字、下划线(_)和“$”组成,但不能使用单独的数字
- 名称最长可为 64 个字符,别名最长为 256 个字符。
- 不能使用 MySQL 关键字作为数据库名
- 建议采用小写来定义数据库名
创建基本数据库
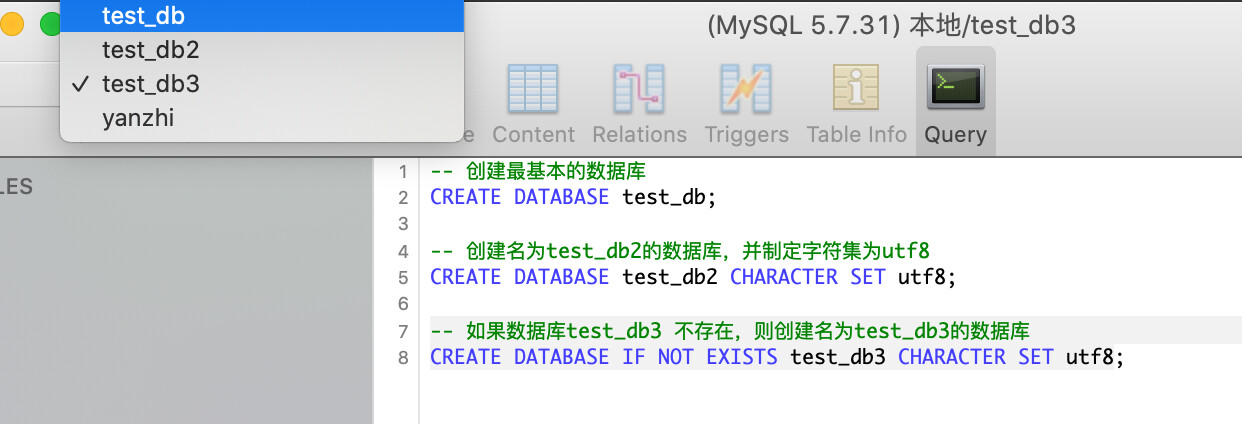
-- 创建名为 test_db 的数据库
CREATE DATABASE test_db;
创建指定字符集的数据库
-- 创建名为 test_db2 的数据库,并指定字符集为 utf8
CREATE DATABASE test_db2 CHARACTER SET utf8;
创建数据库前判断是否存在同名数据库
-- 如果数据库 test_db3 不存在,则创建名为 test_db3 的数据库
CREATE DATABASE IF NOT EXISTS test_db3 CHARACTER SET utf8;
(二)查看
查看数据库语法
- DATABASES:必选项,用于列出当前用户权限范围内所能查看到的所有数据库名称
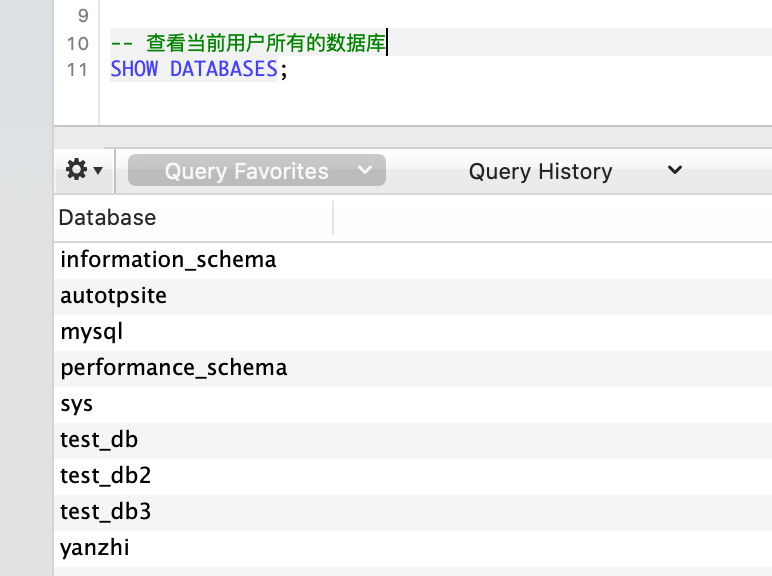
-- 查看所有数据库
SHOW DATABASES;
选择数据库语法
-- 选择数据库为当前数据库
USE 数据库名;
查看数据库的定义信息语法
-- 查看数据库定义信息
SHOW CREATE DATABASE 数据库名;
-- 选择数据库
USE test_db;
-- 查看test_db 数据库的定义信息
SHOW CREATE DATABASE test_db;

(三)修改
修改数据库语法
- DATABASE:必选项
- 数据库名:可选项,如果不指定要修改的数据库,那么将表示修改当前(默认)的数据库
- CHARACTER SET = 字符集:可选项,用于指定数据库的字符集
-- 修改数据库相关参数
ALTER {DATABASE} [数据库名]
CHARACTER SET [=] 字符集
修改数据库字符集
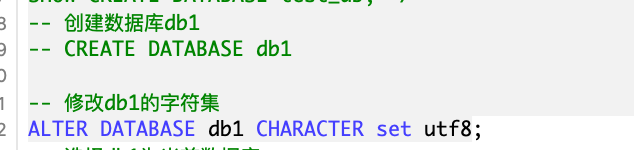
-- 创建数据库 db1,指定字符集为 GBK
CREATE DATABASE db1 CHARACTER SET GBK;
-- 将数据库 db1 的字符集修改为 utf8
ALTER DATABASE db1 CHARACTER SET utf8;
(四) 删除
删除数据库语法
- DATABASES:必选项
- IF EXISTS:用于指定在删除数据前,先判断该数据库是否已经存在,可以避免删除不存在的数据库时产生异常
-- 删除数据库
DROP DATABASE [IF EXISTS] 数据库名;
删除某个数据库
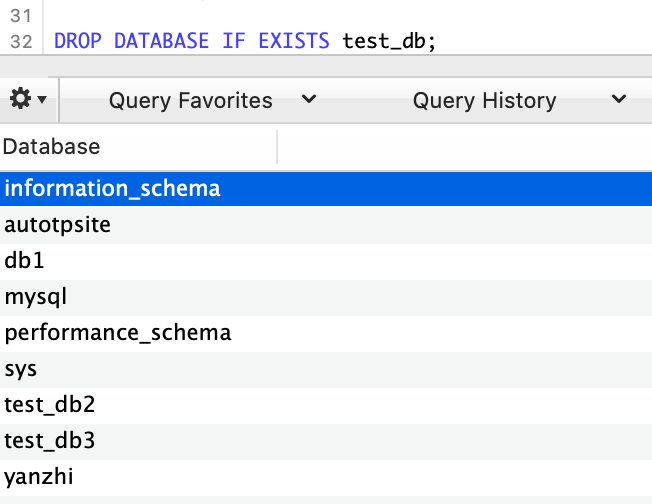
-- 查看当前所有数据库
SHOW DATABASES;
-- 删除某个数据库
DROP DATABASE test_db;
-- 如果某个数据库存在,则删除这个数据库
DROP DATABASE IF EXISTS test_db2;
添加新列
-- 添加新列
ALTER TABLE 表名 ADD 列名 列属性;
# 实例
-- 选择数据库 db1
USE db1;
-- 添加新列
ALTER TABLE student ADD email varchar(50) NOT NULL;
-- 查看表结构
DESC student;
(五)DDL 数据库表操作简介
MySQL 的数据类型
- 数字类型
- 字符串类型
- 日期和时间类型
数字类型
| 数据类型 | 说明 |
|---|---|
| TINTINT | 0~255 或 -128~127,1字节,最小的整数 |
| SMALLINT | 0~65535 或 -32768~32767,2字节,小型整数 |
| MEDIUMINT | 0~16777215 或 -8388608~8388607,3字节,中型整数 |
| INT | 0~4294967295 或 -2147683648~2147683647,4字节,标准整数 |
| BIGINT | 8字节,大整数 |
| FLOAT | 单精度浮点值 |
| DOUBLE | 双精度浮点值 |
| BOOLEAN | 布尔值 |
字符串类型
| 数据类型 | 说明 |
|---|---|
| CHAR | 1~255 个字符,固定长度字符串 |
| VARCHAR | 长度可变,最多不超过 255 个字符 |
| TEXT | 最大长度为 64K 的变长文本 |
| TINYTEXT | 与 TEXT 相同,但最大长度为 255 字节 |
| MEDIUMTEXT | 与 TEXT 相同,但最大长度为 16K |
| LONGTEXT | 与 TEXT 相同,但最大长度为 4GB |
日期和时间类型
| 数据类型 | 说明 |
|---|---|
| DATE | 日期,格式 YYYY-MM-DD |
| TIME | 时间,格式 HH:MM:SS |
| DATETIME | 日期和时间,格式 YYYY-MM-DD HH:MM:SS |
| TIMESTAMP | 时间标签,功能和 DATETIME 相同,但范围较小 |
| YEAR | 年份可指定两位数字和四位数字的格式 |
常用数据类型
- INT:整型
- DOUBLE:浮点型
- VARCHAR:字符串型
- DATE:日期类型
(六)DDL 数据库表操作 - 创建
创建表语法
-- 创建表
CREATE TABLE 数据表名 (
列名1 属性,
列名2 属性…
);
列属性
- NOT NULL | NULL:该列是否允许是空值
- DEFAULT:表示默认值
- AUTO_INCREMENT:表示是否是自动编号
- PRIMARY KEY:表示是否为主键
列名 数据类型 [NOT NULL | NULL] [DEFAULT 默认值] [AUTO_INCREMENT]
[PRIMARY KEY ] [注释]
创建学员表
- 创建在 db1 数据库中
- 表名为 student
- 包含两个字段
- 学员 id
- 学员姓名
-- 切换到数据库 db1
USE db1;
-- 创建学员表
CREATE TABLE student(
id INT,
name VARCHAR(20)
);
复制表语法
- 数据表名:表示新创建的数据表的名
- LIKE 源数据表名:必选项,指定依照哪个数据表来创建新表
-- 复制表
CREATE TABLE数据表名
{LIKE 源数据表名 | (LIKE 源数据表名)}
复制结构相同的表
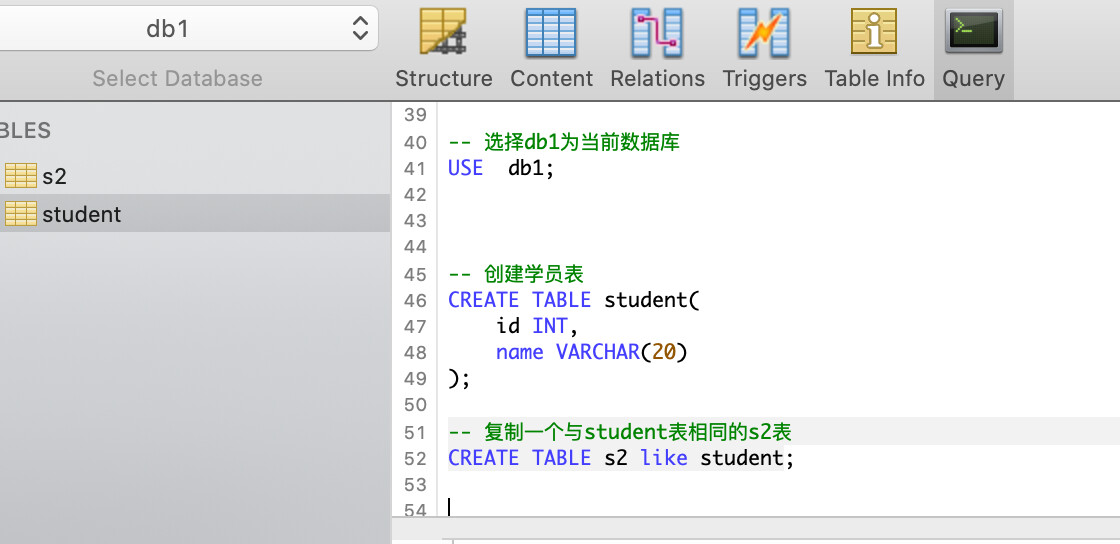
-- 创建一个表结构与 student 相同的 s2 表
CREATE TABLE s2 LIKE student;
(七) DDL 数据库表操作 - 查看
查看表名语法
-- 查看当前数据库中所有的表名
SHOW TABLES;
查看表结构语法
-- 查看表结构
DESCRIBE 数据表名;
DESCRIBE 数据表名 列名;
-- 查看表结构简写
DESC 数据表名;
DESC 数据表名 列名;
实例
-- 选择数据库
USE db1;
-- 查看数据库中的表
SHOW TABLES;
-- 查看学员表的表结构
DESC student;
-- 查看学员表中 name 列的信息
DESC student name;
(八)DDL 数据库表操作 - 修改
添加新列
-- 添加新列
ALTER TABLE 表名 ADD 列名 列属性;
# 实例
-- 选择数据库 db1
USE db1;
-- 添加新列
ALTER TABLE student ADD email varchar(50) NOT NULL;
-- 查看表结构
DESC student;
修改列定义
-- 修改列定义
ALTER TABLE 表名 MODIFY 列名 列属性;
# 实例
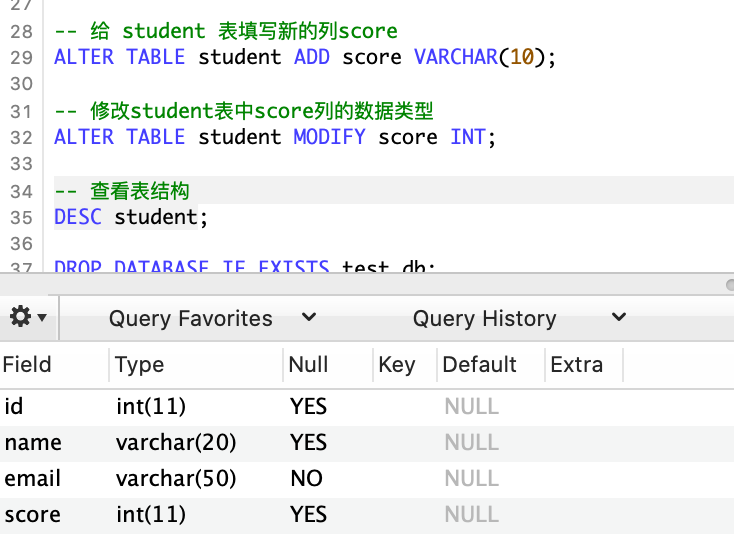
-- 添加分数列,先定义为字符类型
ALTER TABLE student ADD score varchar(10);
-- 修改字段类型
ALTER TABLE student modify score int;
-- 查看表结构
DESC student;
修改列名
-- 修改列名
ALTER TABLE 表名 CHANGE 旧列名 新列名 类型;
# 实例
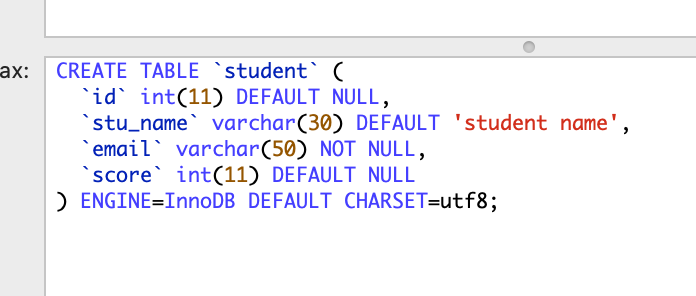
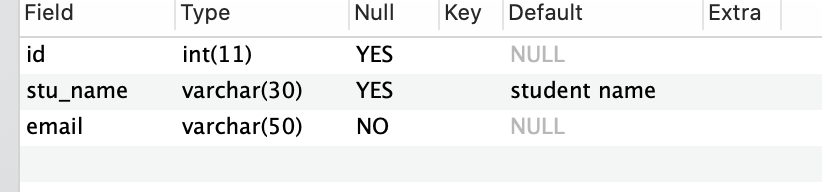
-- 修改列名并指定列的默认值
ALTER TABLE student
CHANGE COLUMN name stu_name VARCHAR(30) DEFAULT NULL;
-- 查看表结构
DESC student;
-- 修改 student 表中name列名为stu_name,指定列的默认值为student name
ALTER TABLE student CHANGE COLUMN name stu_name VARCHAR(30) DEFAULT "student name";
删除列
-- 删除列
ALTER TABLE 表名 DROP 列名;
# 实例
-- 将数据表 student 中的列 score 删除
ALTER TABLE student DROP score;
-- 查看表结构
DESC student;
修改表名
-- 修改表名方式一
ALTER TABLE 旧表名 RENAME AS 新表名;
-- 修改表名方式二
RENAME TABLE 旧表名 To 新表名;
# 实例
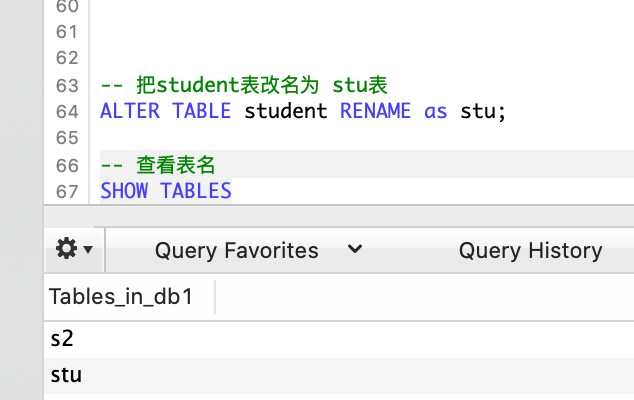
-- 将数据表 student 更名为 stu
ALTER TABLE student RENAME AS stu;
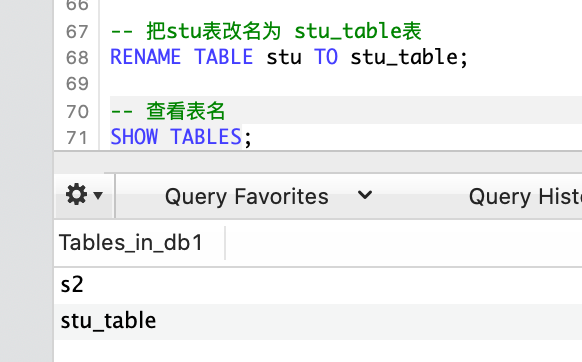
-- 将数据表 stu 更名为 stu_table
RENAME TABLE stu TO stu_table;
-- 查看表名
SHOW TABLES;s
(九) DDL 数据库表操作 - 删除
删除表语法
- IF EXISTS:可选项,先判断是否存在要删除的表,存在时才执行删除操作
- 数据表名:用于指定要删除的数据表名
DROP TABLE [IF EXISTS] 数据表名;
实例
-- 切换到数据库 db1
USE db1;
-- 创建 student 表
CREATE TABLE student(
id INT,
name VARCHAR(20)
);
-- 直接删除 student 表
DROP TABLE student;
-- 先判断再删除 student 表
DROP TABLE IF EXISTS student;
二、 DML
(一)DML 表数据操作 - 插入
表数据插入语法
- INTO 数据表名:指定被操作的数据表
- (列名1, 列名2…):可选项,向数据表的指定列插入数据
- VALUES(值1, 值2…):需要插入的数据
-- 插入数据
INSERT INTO 数据表名
(列名1, 列名2...)
VALUES(值1, 值2...);
完整插入数据
向数据表中插入一条完整的数据
-- 选择数据库
USE db1;
-- 创建 user 表
CREATE TABLE user(
id INT,
name VARCHAR(20),
age INT,
sex CHAR(1),
address VARCHAR(40)
);
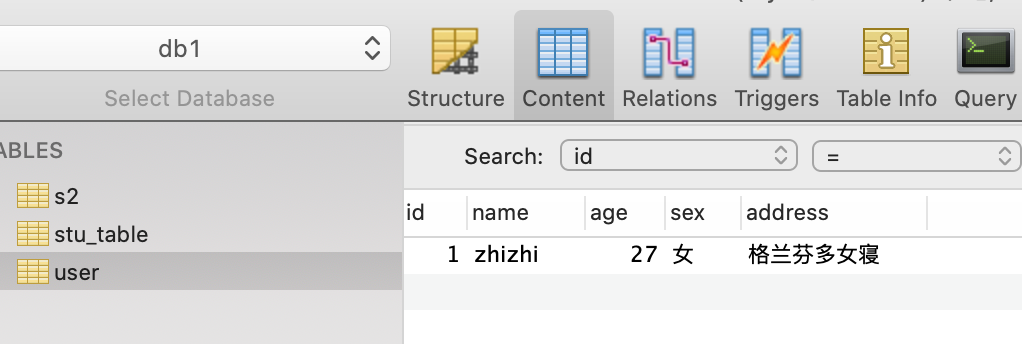
-- 插入一条完整的数据,写出全部的列名
INSERT INTO user (
id, name, age, sex, address
) VALUES(
1, "zhizhi", 27, "女", "格兰芬多女寝"
)
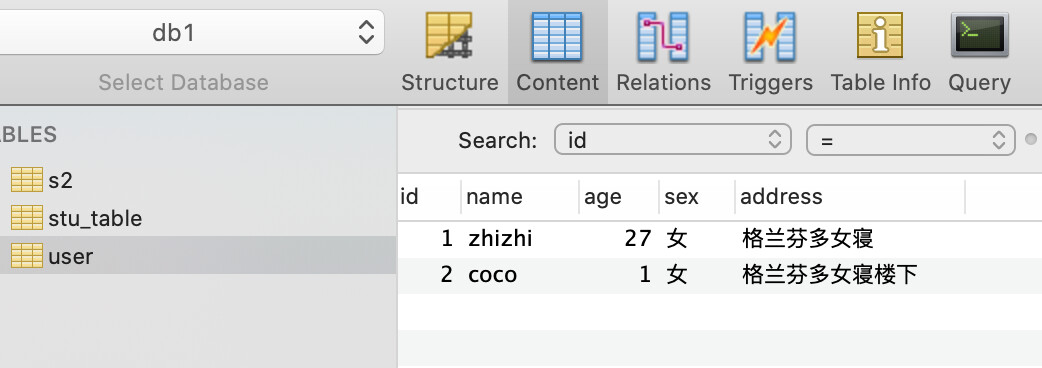
-- 插入一条完整的数据,不写列名
insert into user values(2, "coco", 1, "女", "格兰芬多女寝楼下")
插入数据记录的一部分
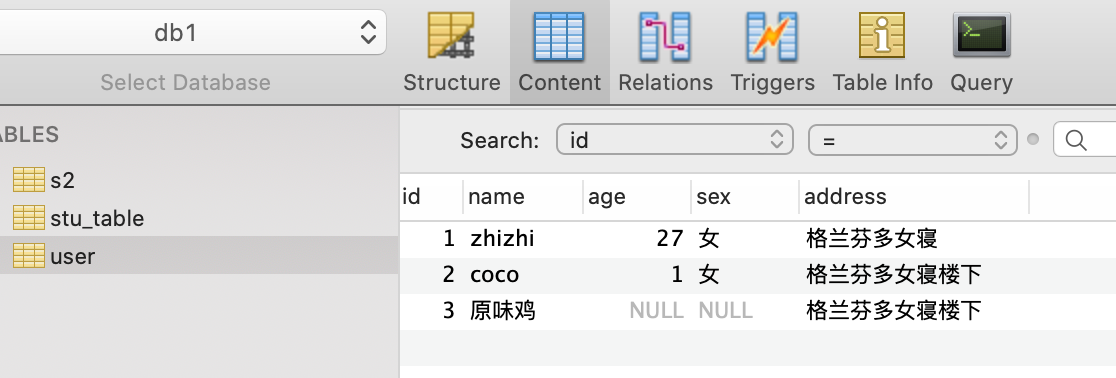
只插入表的一行中的某几个字段的值
-- 插入表中一行中的某几列信息
insert into user (id, name, address) values (3, "原味鸡", "格兰芬多女寝楼下");
插入多条记录
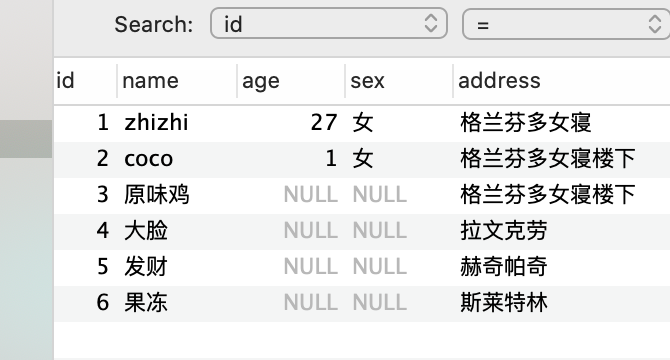
一次性插入多条数据记录
-- 一次插入多条数据
insert into user (
id, name, address
) values (4, "大脸", "拉文克劳"),(5, "发财", "赫奇帕奇"),(6, "果冻", "斯莱特林");
注意事项
- 值与字段必须要对应,个数相同并且数据类型相同
- 值的数据大小,必须在字段指定的长度范围内
- VARCHAR CHAR DATE 类型的值必须使用单引号包裹
- 如果要插入空值,可以忽略不写,或者插入 NULL
- 如果插入指定字段的值,必须要上写列名
(二) DML 表数据操作 - 修改
表数据修改语法
- SET 子句:必选项,用于指定表中要修改的字段名及其字段值
- WHERE 子句:可选项,用于限定表中要修改的行
-- 修改表中数据
UPDATE 数据表名
SET 列名1=值1 [, 列名2=值2...]
[WHERE 条件表达式]
实例
-- 选择 db1 为当前数据库
USE db1;
-- 创建 student 表
CREATE TABLE student(
id INT,
name VARCHAR(20),
sex CHAR(1),
age TINYINT,
city VARCHAR(50)
);
-- 插入 5 条数据
INSERT INTO student
VALUES(1,'小李','男', 18, '北京'),
(2,'小白','女', 20, '成都'),
(3,'小王','男', 23, '上海'),
(4,'小赵','女', 21, '深圳'),
(5,'小周','男', 25, '杭州');
-- 不带条件修改,将所有的性别改为女
UPDATE student SET sex = '女';
-- 带条件的修改,将 id 为 3 的学生,性别改为男
UPDATE student SET sex = '男' WHERE id = 3;
-- 一次修改多个列, 将 id 为 2 的学员,年龄改为 30,地址改为 北京
UPDATE student SET age = 30, city = '北京' WHERE id = 2;
(三) DML 表数据操作 - 删除
通过 DELETE 语句删除数据
- 数据表名:指定要删除的数据表的表名
- WHERE 子句:限定表中要删除的行
-- 删除表中指定行的数据
DELETE FROM 数据表名
WHERE 条件表达式
通过 TRUNCATE TABLE 语句删除数据
-- 删除表中全部数据
TRUNCATE TABLE 数据表名
实例
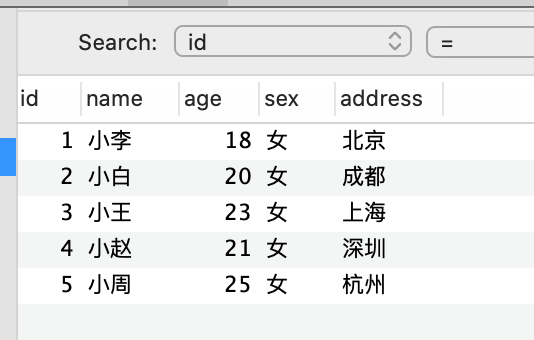
-- 选择 db1 为当前数据库
USE db1;
# 数据准备
-- 创建 student 表
CREATE TABLE student(
id INT,
name VARCHAR(20),
sex CHAR(1),
age TINYINT,
city VARCHAR(50)
);
-- 插入 5 条数据
INSERT INTO student
VALUES(1,'小李','男', 18, '北京'),(2,'小白','女', 20, '成都'),(3,'小王','男', 23, '上海'),(4,'小赵','女', 21, '深圳'),(5,'小周','男', 25, '杭州');
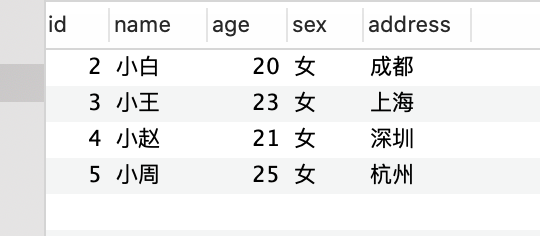
-- 删除 id 为 1 的数据
DELETE FROM student WHERE id = 1;
-- 删除 student 表中所有数据
DELETE FROM student;
-- 删除 student 表中所有数据
TRUNCATE TABLE student;
三、 DQL
(一)DQL表查询操作 - 简介
数据准备
- 测试数据库:
- 网盘下载:
-
提取码:gxow
cd 数据所在目录
mysql -h 127.0.0.1 -uroot -p < employees.sql
单表查询
- 单表查询:从一张表中查询所需要的数据,所有查询操作都比较简单
-
*代表所有的列 - 语法:
SELECT * FROM 表名;
-- 查询部门表中的信息
SELECT * FROM departments;
字段查询
- 查询多个字段(列),可以使用
,对字段进行分隔 - 语法:
SELECT 列名 FROM 表名;
-- 查询部门的名称
SELECT dept_name FROM departments;
起别名
- 为表起别名:
SELECT 列名 FROM 表名 表别名;
- 为字段起别名:
SELECT 列名 AS 别名 FROM 表名;
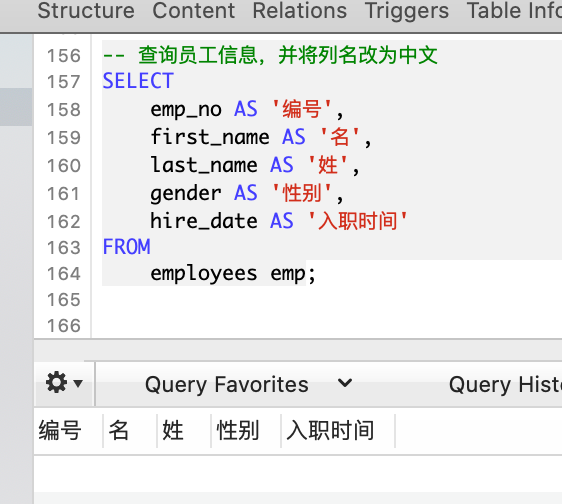
-- 查询员工信息,并将列名改为中文
SELECT
emp_no AS '编号',
first_name AS '名',
last_name AS '姓',
gender AS '性别',
hire_date AS '入职时间'
FROM
employees emp;
去重
- DISTINCT 关键字:去掉重复信息
- 语法:
SELECT DISTINCT 列名 FROM 表名;
-- 去掉重复职级信息
SELECT DISTINCT title FROM titles;
运算查询
- 查询结果参与运算
SELECT (列名 运算表达式) FROM 表名;
-- 所有员工的工资 +1000 元进行显示
SELECT emp_no , salary + 1000 FROM salaries;
(二) DQL 表查询操作 - 条件查询
条件查询语法
-- 条件查询
SELECT 列名 FROM 表名 WHERE 条件表达式
比较运算符
| 运算符 | 说明 |
|---|---|
> < <= >= = <> != |
大于、小于、小于等于、大于等于、等于、不等于 |
BETWEEN...AND... |
范围限定 |
IN |
子集限定 |
LIKE '%or%' |
模糊查询 |
IS NULL |
为空 |
比较大小
- 语法:
WHERE <列名> [> < <= >= = <> !=] <值>
-- 查询出生日期晚于 1965-01-01 的员工编号、姓名和生日
SELECT
emp_no, first_name, last_name, birth_date
FROM
employees
WHERE
birth_date > '1965-01-01';
使用 BETWEEN 进行模糊查询
- 语法:
WHERE <列名> [NOT] BETWEEN <起始表达式> AND <结束表达式> -
<起始表达式>和<结束表达式>的顺序不能颠倒
-- 查询年薪介于 70000 到 70003 之间的员工编号和年薪
SELECT
emp_no, salary
FROM
salaries
WHERE
salary BETWEEN 70000 AND 70003;
使用 IN 进行模糊查询
- 语法:
WHERE <列名> IN <(常量列表)> -
(常量列表)中各常量值用逗号隔开
-- 查询入职日期为 1995-01-27 和 1995-03-20 日的员工信息
SELECT
*
FROM
employees
WHERE
hire_date IN ('1995-01-27', '1995-03-20');
判断是否为空
- 语法:
WHERE <列名> IS [NOT] NULL
-- 选择 hog_demo 为当前数据库
USE hog_demo;
-- 更新 student 表中 id 为 2 的 age 值为 NULL
UPDATE student SET age = NULL WHERE id = 2;
-- 查询学生表中年龄为 NULL 的学生信息
SELECT
*
FROM
student
WHERE
age IS NULL;
逻辑运算符
| 运算符 | 说明 |
|---|---|
AND && |
多个条件同时成立 |
OR || |
多个条件任一成立 |
NOT |
不成立 |
-- 查询名字为 Lillian 并且姓氏为 Haddadi 的员工信息
SELECT
*
FROM
employees
WHERE
first_name = 'Lillian'
AND last_name = 'Haddadi';
-- 查询名字为 Lillian 或者姓氏为 Terkki 的员工信息
SELECT
*
FROM
employees
WHERE
first_name = 'Lillian'
OR last_name = 'Terkki';
-- 查询名字为 Lillian 并且性别不是女的员工信息
SELECT
*
FROM
employees
WHERE
first_name = 'Lillian'
and not gender='F';
通配符
| 运算符 | 说明 |
|---|---|
% |
匹配任意多个字符 |
- |
匹配一个字符 |
-- 查询名字中包含 fai 的员工的信息
SELECT
*
FROM
employees
WHERE
first_name LIKE '%fai%';
-- 查询名字中 fa 开头的名字长度为 3 位的员工信息
SELECT
*
FROM
employees
WHERE
first_name LIKE 'fa_';
(三)DQL 表查询操作 - 排序
排序语法
- ASC 表示升序排序(默认)
- DESC 表示降序排序
-- 对查询结果进行排序
SELECT 列名 FROM 表名
[WHERE 条件表达式]
ORDER BY 列名1 [ASC / DESC],
列名2 [ASC / DESC]
单列排序
- 只按照某一个列进行排序, 就是单列排序
-- 使用 salary 字段,对 salaries 表数据进行升序排序
SELECT * FROM salaries ORDER BY salary;
-- 使用 salary 字段,对 salaries 表数据进行降序排序
SELECT * FROM salaries ORDER BY salary DESC;
-- 查询员工的编号和入职日期,按照员工入职日期从晚到早排序
SELECT
emp_no, hire_date
FROM
employees
ORDER BY hire_date DESC;
组合排序
- 同时对多个字段进行排序
- 如果第一个字段相同,就按照第二个字段进行排序
-- 在入职时间排序的基础上,再使用 emp_no 进行排序
-- 组合排序
SELECT
emp_no, hire_date
FROM
employees
ORDER BY hire_date DESC, emp_no DESC;
(四)DQL 表查询操作 - 聚合函数
聚合函数
- COUNT():统计指定列不为 NULL 的记录行数
- MAX():计算指定列的最大值
- MIN():计算指定列的最小值
- SUM():计算指定列的数值和
- AVG():计算指定列的平均值
聚合查询
- 语法:
SELECT 聚合函数(列名) FROM 表名;
-- 查询职级名称为 Senior Engineer 的员工数量
SELECT
COUNT(*)
FROM
titles
WHERE
title = 'Senior Engineer';
-- 查询员工编号为 10002 的员工的最高年薪
SELECT
MAX(salary)
FROM
salaries
WHERE
emp_no = 10002;
-- 查询员工编号为 10002 的员工的最低年薪
SELECT
MIN(salary)
FROM
salaries
WHERE
emp_no = 10002;
-- 查询员工编号为 10002 的员工的薪水总和
SELECT
SUM(salary)
FROM
salaries
WHERE
emp_no = 10002;
-- 查询员工编号为 10002 的员工的平均年薪
SELECT
AVG(salary)
FROM
salaries
WHERE
emp_no = 10002;
(五)DQL 表查询操作 - 分组
分组查询语法
- 分组列:按哪些列进行分组
- HAVING:对分组结果再次过滤
-- 分组查询
SELECT 分组列/聚合函数 FROM 表名
GROUP BY 分组列
[HAVING 条件];
实例
-- 查询每个员工的薪资和
SELECT
emp_no, SUM(salary)
FROM
salaries
GROUP BY emp_no;
-- 查询员工编号小于 10010 的,薪资和小于 400000 的员工的薪资和
SELECT
emp_no, SUM(salary)
FROM
salaries
WHERE
emp_no < 10010
GROUP BY emp_no
HAVING SUM(salary) < 400000;
子句区别
- WHERE 子句:从数据源中去掉不符合其搜索条件的数据
- GROUP BY 子句:搜集数据行到各个组中,统计函数为各个组计算统计值
- HAVING 子句:去掉不符合其组搜索条件的各行数据行
(六)DQL 表查询操作 - LIMIT 关键字
LIMIT 关键字
- 限制查询结果的数量
- 开始的行数:从 0 开始记数, 如果省略则默认为 0
- 查询记录的条数:返回的行数
-- 限制查询结果行数
SELECT 列名1, 列名2...
FROM 表名
LIMIT [开始的行数], <查询记录的条数>
-- 使用 OFFSET 关键字指定开始的行数
SELECT 列名1, 列名2...
FROM 表名
LIMIT <查询记录的条数> OFFSET <开始的行数>
实例
-- 展示前 10 条员工信息
SELECT * FROM employees LIMIT 10;
SELECT * FROM employees LIMIT 0, 10;
SELECT * FROM employees LIMIT 10 OFFSET 0;
-- 显示年薪从高到低排序,第 15 位到第 20 位员工的编号和年薪
SELECT
emp_no, salary
FROM
salaries
ORDER BY salary DESC
LIMIT 14, 6;
SELECT
emp_no, salary
FROM
salaries
ORDER BY salary DESC
LIMIT 6 OFFSET 14;
单表查询总结
-- 基础查询语法
SELECT DISTINCT <列名>
FROM <表名>
WHERE <查询条件表达式>
GROUP BY <分组的列名>
HAVING <分组后的查询条件表达式>
ORDER BY <排序的列名> [ASC / DESC]
LIMIT [开始的行数], <查询记录的条数>
SQL 语句执行顺序
原始数据库 -> 虚拟表1: FROM 子句
虚拟表1 -> 虚拟表2: WHERE 子句
虚拟表2 -> 虚拟表3: GROUP BY 子句
虚拟表3 -> 虚拟表4: HAVING 子句
虚拟表4 -> 虚拟表5: SELECT
虚拟表5 -> 虚拟表6: DISTINCT
虚拟表6 -> 虚拟表7: ORDER BY 子句
虚拟表7 -> 最终结果: LIMIT
四、SQL 约束
(一)主键约束
SQL 约束
- 对表中的数据进行进一步的限制
- 保证数据的正确性、有效性、完整性
- 违反约束的不正确数据无法插入到表中
- 常见的约束
- 主键:PRIMARY KEY
- 非空:NOT NULL
- 唯一:UNIQUE
- 默认:DEFAULT
- 外键:FOREIGN KEY
主键约束
- 主键:一列(或一组列),其值能够唯一标识表中每一行
- 特点:不可重复,唯一,非空
- 语法:
列名 字段类型 PRIMARY KEY
添加主键约束
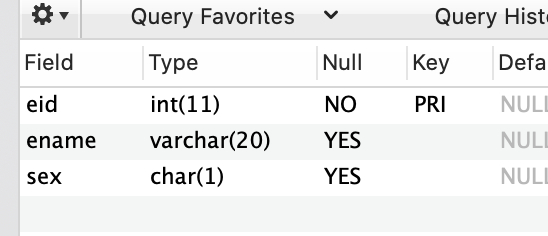
-- 创建一个带主键的表
CREATE TABLE emp1(
-- 设置主键 唯一 非空
eid INT PRIMARY KEY,
ename VARCHAR(20),
sex CHAR(1)
);
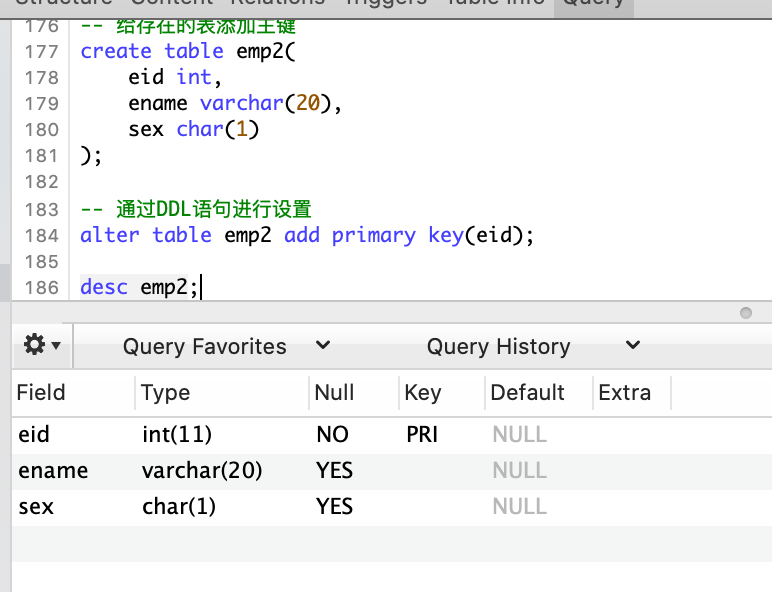
-- 给存在的表添加主键
CREATE TABLE emp2(
eid INT ,
ename VARCHAR(20),
sex CHAR(1)
)
-- 通过 DDL 语句进行设置
ALTER TABLE emp2 ADD PRIMARY KEY(eid);
创建主键自增的表
- AUTO_INCREMENT:表示自动增长(字段类型必须是整数类型)
-- 创建主键自增的表
CREATE TABLE emp3(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
sex CHAR(1)
);
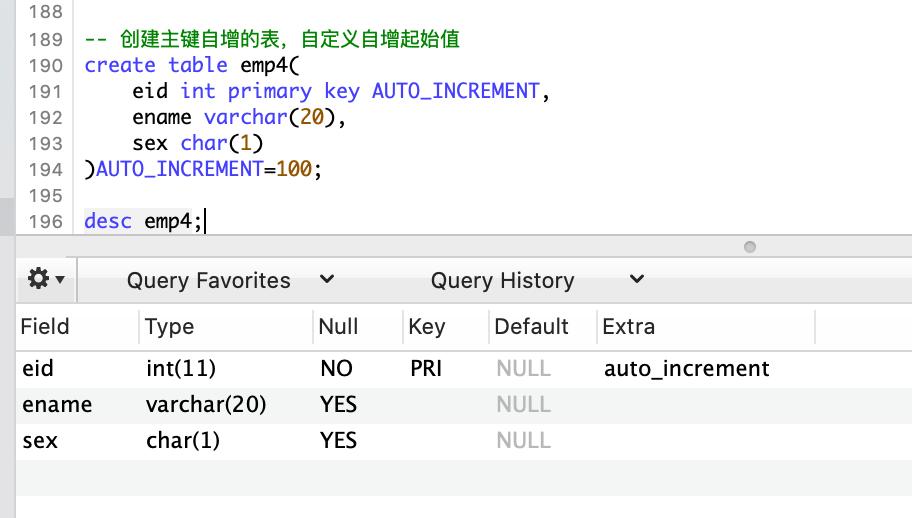
修改主键自增的起始值
-- 创建主键自增的表,自定义自增起始值
CREATE TABLE emp4(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
sex CHAR(1)
)AUTO_INCREMENT=100;
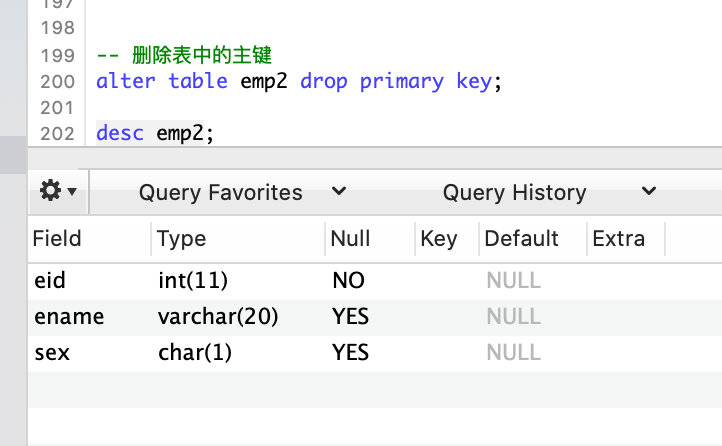
删除主键约束
-- 删除表中的主键
ALTER TABLE 表名 DROP PRIMARY KEY;
-- 使用 DDL 语句删除表中的主键
ALTER TABLE emp2 DROP PRIMARY KEY;
-- 查看表结构
DESC emp2;
选择主键原则
- 针对业务设计主键,往建议每张表都设计一个主键
- 主键可以没有业务意义,只需要保证不重复
(二)SQL 约束 - 非空约束
非空约束
- 非空约束特点: 某一列不予许为空
- 语法:
列名 字段类型 NOT NULL
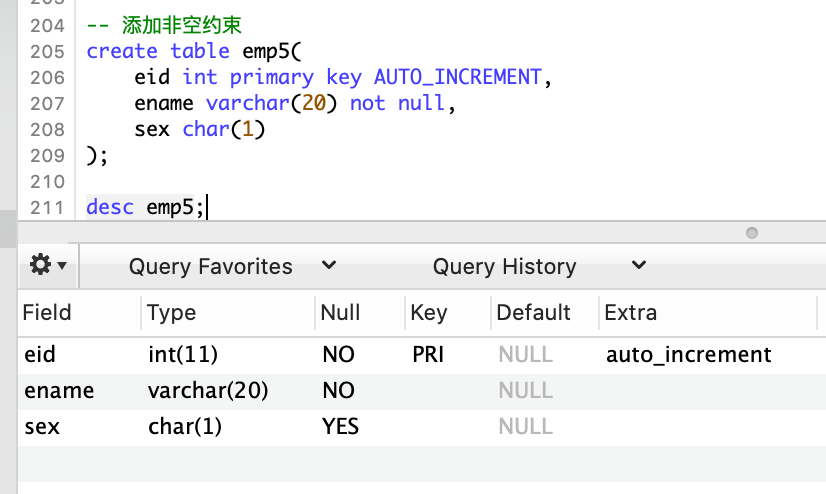
添加非空约束
-- 添加非空约束
CREATE TABLE emp5(
eid INT PRIMARY KEY AUTO_INCREMENT,
-- ename 字段不能为空
ename VARCHAR(20) NOT NULL,
sex CHAR(1)
);
(三)SQL 约束 - 唯一约束
唯一约束
- 唯一约束: 表中的某一列的值不能重复
- 对 NULL 不做唯一的判断
- 语法:
列名 字段类型 UNIQUE
添加唯一约束
-- 创建带有唯一约束的表
CREATE TABLE emp6(
eid INT PRIMARY KEY AUTO_INCREMENT,
-- 为 ename 字段添加唯一约束
ename VARCHAR(20) UNIQUE,
sex CHAR(1)
);
主键约束与唯一约束的区别
- 主键约束,唯一且不能够为空
- 唯一约束,唯一但是可以为空
- 一个表中只能有一个主键,但是可以有多个唯一约束
(四)SQL 约束 - 默认值
默认值
- 默认值约束:用来指定某列的默认值
- 语法:
列名 字段类型 DEFAULT 默认值
字段指定默认值
-- 创建带有默认值的表
CREATE TABLE emp7(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
-- 为 sex 字段添加默认值
sex CHAR(1) DEFAULT '女'
);

