一、后置处理器作用
用于对响应数据进行关联处理,比如一个请求需要另一个请求的响应数据作为参数,则需要通过后置处理器获取另一个请求的响应数据。
二、后置处理器类型
1. 正则表达式提取器
(1)正则表达式字符
| 元字符 | 含义 |
|---|---|
| () | 封装待返回的字符串 |
| . | 匹配除换行符以外的任意字符 |
| + | 匹配前面的字符串1次或多次 |
| ? | 匹配前面的字符串0次或1次,在找到第一个匹配项后停止 |
| * | 匹配前面出现的字符0次或多次 |
| ^ | 匹配字符串的开始位置 |
| $ | 匹配字符串的结束位置 |
| | | 模型选择符,从中任选一个匹配 |
(2)正则表达式举例
| 正则表达式内容 | 含义 | 模式 |
|---|---|---|
| <title>(.*)</title> | 匹配左边界为<title>、右边界为</title>的所有字符串 | 贪婪 |
| <title>(.*?)</title> | 匹配左边界为<title>、右边界为</title>的第一个符合条件的字符串 | 懒惰 |
(3)正则表达式提取器使用方法
需求:将请求1(https://www.sina.com.cn)的响应数据(网页标题,即<title>xxx</title>中的文本)作为请求2(https://www.baidu.com/S)的参数(r_title)进行传递
做法:
Step1: 添加线程组

Step2: 添加 http 请求(请求1)
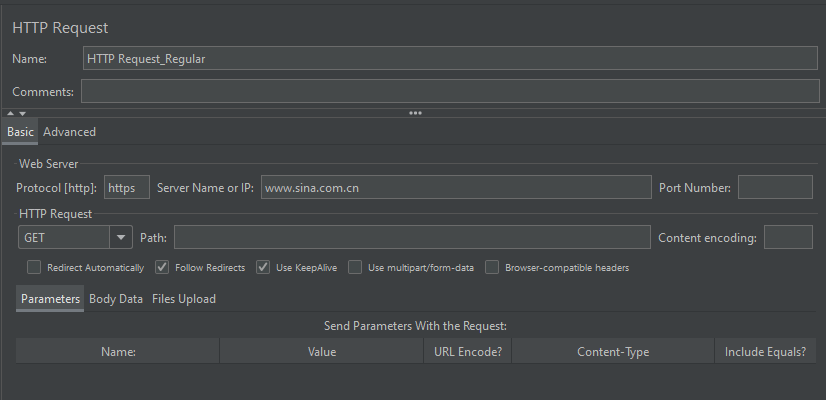
Step3: 对请求1设置 正则表达式后置处理器

Step4: 添加 http 请求(请求2)并设定参数

Step5: 添加 查看结果树

注意:结果树中传递的参数可能以编码形式出现,如何能查看传递的参数是否正确呢?解决方法有两种:
方法一:添加一个Debug Sampler,然后在结果树中查看
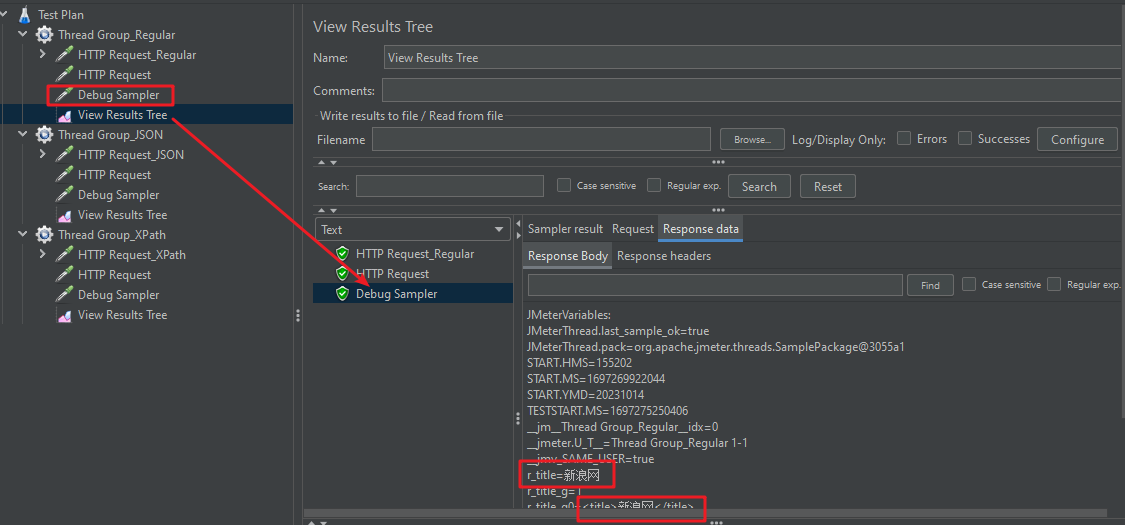
方法二:添加一个BeanShell 后置处理器,以日志方式输出参数内容。

点击界面右上角感叹号,查看日志信息

2. JSON提取器
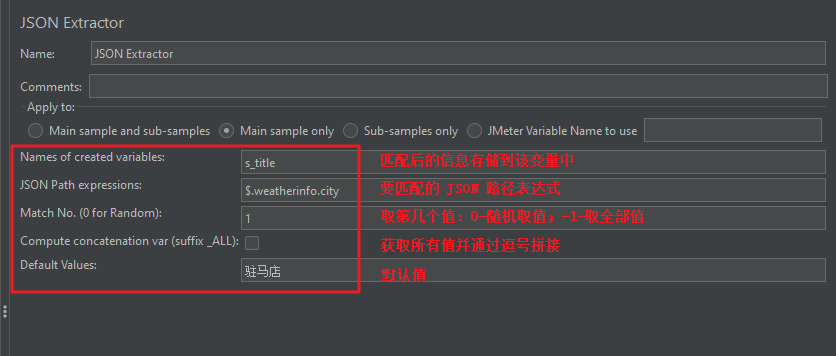
(1)JSON匹配格式表达方式
eg: $.weather.city 表示匹配 weather(一级节点) → city(二级节点) 的取值
(2)JSON提取器使用方法
需求:将请求1( http://www.weather.com.cn/data/sk/101010100.html )的响应数据( {“weatherinfo”:{“city”:“北京”,“cityid”:“101010100”,“temp”:“18”,“WD”:“东南风”,“WS”:“1级”,“SD”:“17%”,“WSE”:“1”,“time”:“17:05”,“isRadar”:“1”,“Radar”:“JC_RADAR_AZ9010_JB”,“njd”:“暂无实况”,“qy”:“1011”,“rain”:“0”}}中的 city 的取值 )作为请求2(https://www.baidu.com/S)的参数(s_title)进行传递
做法:
Step1: 添加线程组
Step2: 添加 http 请求(请求1)
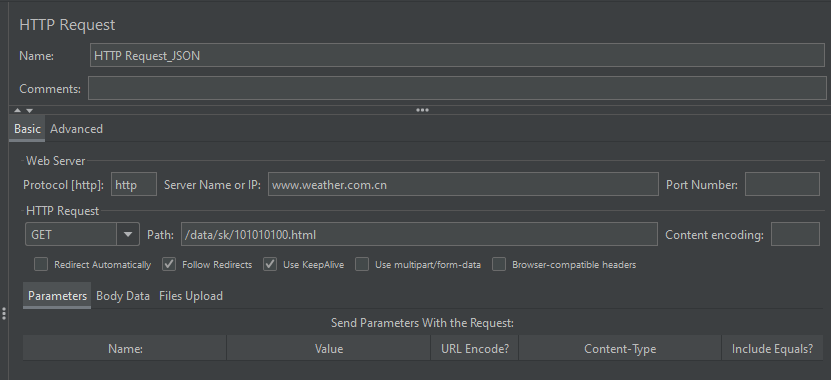
Step3: 添加 JSON 提取器
Step4: 添加 http 请求(请求2)

Step5: 添加查看结果树
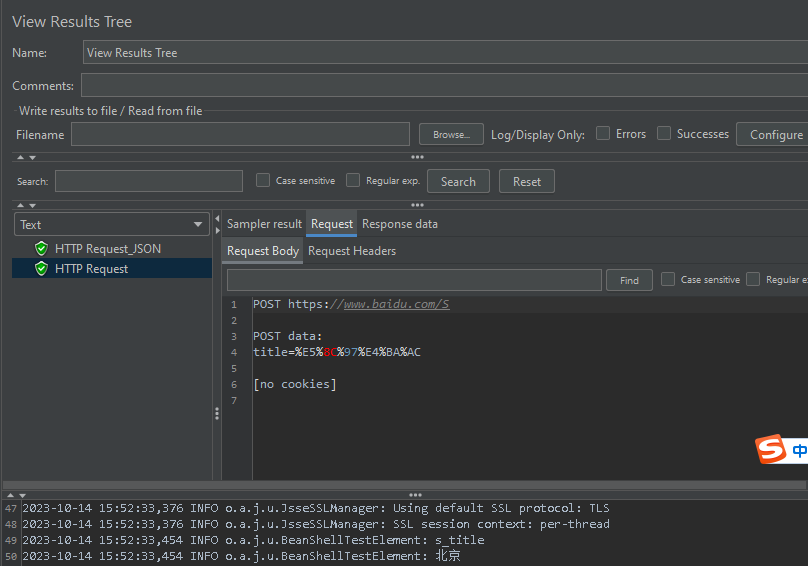
注意:若传递的参数为编码形式,则可参照正则表达式的解决方案。
3. XPath提取器
(1)节点表达方法
| 符号 | 含义 |
|---|---|
| 节点名称 | 选取指定名称的所有节点 |
| / | 从根节点开始选取对应的节点,相当于绝对路径 |
| // | 从任意节点开始选取对应的节点,相当于相对路径 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @属性名 | 选取指定的属性 |
(2)谓语
| 函数 | 含义 |
|---|---|
| position() | 返回当前被处理的节点的位置 |
| last() | 返回当前节点集中的最后一个节点 |
| count() | 返回节点的总数目 |
| name | 返回当前节点的名称 |
| current-date() | 返回当前的日期(含时区) |
| current-time() | 返回当前的时间(含时区) |
| contains(string1,string2) | 若 string1 包含 string2 ,则返回 true,否则返回 false |
(3)XPath举例
| XPath内容 | 含义 |
|---|---|
| bookstore | 选取 bookstore 的所有子节点 |
| /bookstore | 选取根节点 bookstore |
| /bookstore/book | 从根节点 bookstore 开始,向下选取名为 book 的所有节点 |
| //bookstore | 从任意节点开始选取名为 ookstore 的所有节点 |
| /bookstore//book | 从根节点 bookstore 的后代节点中,选取名为 book 的所有子节点 |
| //@lang | 选取所有名为 lang 的属性节点 |
| /bookstore/book[1] | 选取 bookstore 的第一个 book 子节点 |
| /bookstore/book[last()] | 选取 bookstore 的最后一个 book 子节点 |
| /bookstore/book[position<3] | 选取 bookstore 的前两个 book 子节点 |
| //title[@lang] | 选取所有含属性名 lang 的 title 节点 |
| //title[@lang=‘eng’ | 选取所有属性 lang 取值为 eng 的 title 节点 |
(4)XPath提取器使用方法
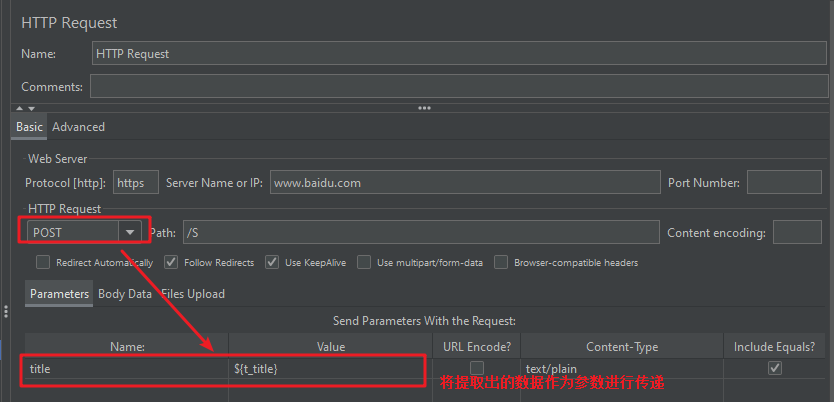
需求:将请求1(htttps://www.itcast.cn)的响应数据(网页标题标签中的内容)作为请求2(https://www.baidu.com/S)的参数(t_title)进行传递
做法:
Step1: 添加线程组
Step2: 添加 http 请求
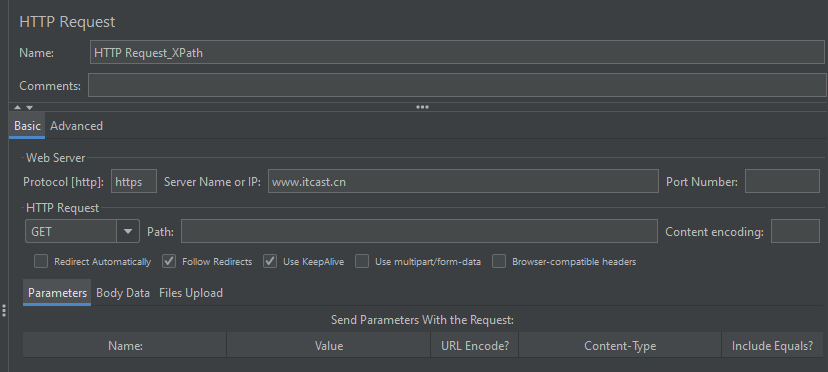
Step3: 添加 XPath 提取器(注意:选中 “Use Tidy” 使 XPath 后置处理器 具备容错能力)

Step4: 添加 http 请求
Step5: 添加查看结果树
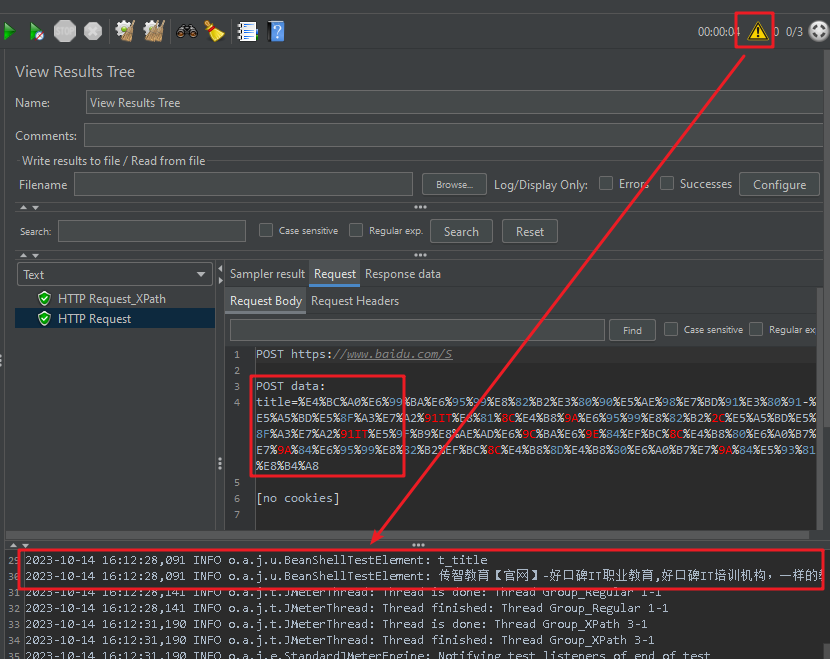
注意:若传递的参数为编码形式,则可参照正则表达式的解决方案。
