[TOC]
L1
Pytest安装
pip install pytest
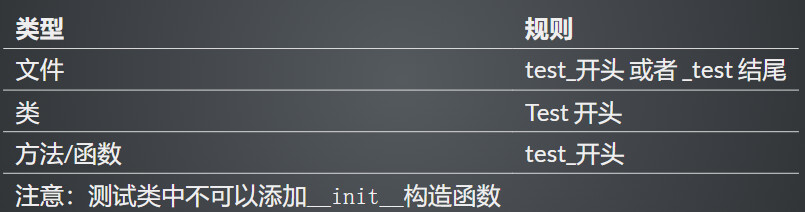
Pytest命名规则
Pytest测试装置介绍

L2
参数化用例
@pytest.mark.parametrize
- 单参数,可以将数据放在列表中
search_list = ['appium','selenium','pytest'] @pytest.mark.parametrize('name',search_list) def test_search(name): assert name in search_list - 多参数, 将数据放在列表嵌套元组或者嵌套列表中
# 数据放在元组中 @pytest.mark.parametrize("test_input,expected",[ ("3+5",8),("2+5",7),("7+5",12) ]) def test_mark_more(test_input,expected): assert eval(test_input) == expected # 数据放在列表中 @pytest.mark.parametrize("test_input,expected",[ ["3+5",8],["2+5",7],["7+5",12] ]) def test_mark_more(test_input,expected): assert eval(test_input) == expected - 用例重命名-添加 ids 参数
@pytest.mark.parametrize("test_input,expected",[ ("3+5",8),("2+5",7),("7+5",12) ],ids=["3和5相加","2和5相加","7和5相加"]) def test_mark_more(test_input,expected): assert eval(test_input) == expected# 当重命名参数为中文时,为保证中文正常显示,需要创建conftest.py文件 # 在conftest.py 文件 ,将下面内容添加进去,运行脚本 def pytest_collection_modifyitems(items): """ 测试用例收集完成时,将收集到的用例名name和用例标识nodeid的中文信息显示在控制台上 """ for i in items: i.name=i.name.encode("utf-8").decode("unicode_escape") i._nodeid=i.nodeid.encode("utf-8").decode("unicode_escape") - 笛卡尔积
@pytest.mark.parametrize("b",["a","b","c"]) @pytest.mark.parametrize("a",[1,2,3]) def test_param1(a,b): print(f"笛卡积形式的参数化中 a={a} , b={b}")
标记测试用例
- 场景:只执行符合要求的某一部分用例 可以把一个web项目划分多个模块,然后指定模块名称执行。
- 解决: 在测试用例方法上加 @pytest.mark.标签名
- 执行: -m 执行自定义标记的相关用例
pytest -s test_mark_zi_09.py -m=webtestpytest -s test_mark_zi_09.py -m apptestpytest -s test_mark_zi_09.py -m "not ios"
设置跳过、预期失败测试用例
- skip - 始终跳过该测试用例
- 添加装饰器
@pytest.mark.skip @pytest.mark.skipif- 代码中添加跳过代码:
pytest.skip(reason)
- skipif - 遇到特定情况跳过该测试用例
- xfail - 遇到特定情况,产生一个“期望失败”输出
- 添加装饰器
@pytest.mark.xfail
- 添加装饰器
运行指定用例
- 执行包下所有的用例:
pytest/py.test [包名] - 执行单独一个 pytest 模块:
pytest 文件名.py - 运行某个模块里面某个类:
pytest 文件名.py::类名 - 运行某个模块里面某个类里面的方法:
pytest 文件名.py::类名::方法名
测试用例调度及运行
-
--lf(--last-failed)只重新运行故障。 -
--ff(--failed-first)先运行故障然后再运行其余的测试
命令行参数

python代码执行pytest
- 使用 main 函数
if __name__ == '__main__': # 1、运行当前目录下所有符合规则的用例,包括子目录(test_*.py 和 *_test.py) pytest.main() # 2、运行test_mark1.py::test_dkej模块中的某一条用例 pytest.main(['test_mark1.py::test_dkej','-vs']) # 3、运行某个 标签 pytest.main(['test_mark1.py','-vs','-m','dkej']) 运行方式 `python test_*.py ` - 使用 python -m pytest 调用 pytest(jenkins 持续集成用到)
pytest异常处理
- try…exception
try: 可能产生异常的代码块 except [ (Error1, Error2, ... ) [as e] ]: 处理异常的代码块1 except [ (Error3, Error4, ... ) [as e] ]: 处理异常的代码块2 except [Exception]: 处理其它异常 - pytest.raise()
def test_raise(): with pytest.raises(ValueError, match='must be 0 or None'): raise ValueError("value must be 0 or None") def test_raise1(): with pytest.raises(ValueError) as exc_info: raise ValueError("value must be 42") assert exc_info.type is ValueError assert exc_info.value.args[0] == "value must be 42"
L3
数据驱动
数据驱动就是数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变。简单来说,就是参数化的应用。数据量小的测试用例可以使用代码的参数化来实现数据驱动,数据量大的情况下建议大家使用一种结构化的文件(例如 yaml,json 等)来对数据进行存储,然后在测试用例中读取这些数据
yaml
基础
- 对象:键值对的集合,用冒号 “:” 表示
- 数组:一组按次序排列的值,前加 “-”
- 纯量:单个的、不可再分的值
- 字符串
- 布尔值
- 整数
- 浮点数
- Null
- 时间
- 日期
yaml安装、读取
- 安装:
pip install pyyaml - 读取方法:
yaml.safe_load(f) - 写入方法:
yaml.safe_dump(f)
excel
常用库
-
xlrd* 官方文档: https://openpyxl.readthedocs.io/en/stable/ xlwingspandas
openpyxl
- 安装:
pip install openpyxl - 读取工作簿
- 读取工作表
- 读取单元格
import openpyxl # 获取工作簿 book = openpyxl.load_workbook('../data/params.xlsx') # 读取工作表 sheet = book.active # 读取单个单元格 cell_a1 = sheet['A1'] cell_a3 = sheet.cell(column=1, row=3) # A3 # 读取多个连续单元格 cells = sheet["A1":"C3"] # 获取单元格的值 cell_a1.value
csv
基础介绍
- 以纯文本形式存储数字和文本
- 文件由任意数目的记录组成
- 每行记录由多个字段组成
数据读取
- 内置函数:open()
- 内置模块:csv
csv.reader(iterable)- 参数:iterable ,文件或列表对象
- 返回:迭代器,每次迭代会返回一行数据
import csv def get_csv(): """ 获取csv数据 :return: 返回数据的结构:[[1, 1, 2], [3, 6, 9], [100, 200, 300]] """ with open('../data/params.csv', 'r') as file: raw = csv.reader(file) data = [] for line in raw: data.append(line) return data
json
json 结构
- 对象
{"key": value} - 数组
[value1, value2 ...]
读取文件
- 内置函数 open()
- 内置库 json
- 解析json转为字典:
json.loads() - 将字典转为json对象:
json.dumps()
- 解析json转为字典:
