#第一部分 模块
#模块的导入,重命名,以及模块中有调试代码使用’name = "main"来区分’
import module1_demo as cm1
if name == “main”:
print(cm1.num)
print(cm1.isOk)
print(cm1.s)
cm1.show()
from module1_demo import num,isOk,s,show
if name == ‘main’:
print(num)
print(isOk)
print(s)
show()
#第二部分 包
#包和路径的区别:创建package的时候会自动创建__init__.py文件;而目录文件中没有该文件,当在目录文件中添加__init__.py文件后,目录文件会自动变为package
#包导入时,需要导入包目录下的模块,比如mp包下有m1.py和m2.py 2个文件,需要导入mp.m1和mp.m2
import mp.m1,mp.m2
if name == ‘main’:
print(mp.m1.num1)
mp.m1.show()
print(mp.m2.num2)
mp.m2.show()
#包导入时可以用as重命名
import mp.m1 as m1
import mp.m2 as m2
if name == ‘main’:
print(m1.num1)
print(m2.num2)
#也可以使用from …………import导入
from mp import m1,m2
print(m1.num1)
print(m2.num2)
#当使用from-import方式导入时,可以通过在__init__.py文件中添加__all__属性来设置包中哪些模块可以被导入
#例如,在__init__.py文件中添加如下代码__all__ = [‘m2’]
from mp import *
#下面这行代码可以直接运行
print(m2.num2)
#而下面这行代码运行会报错
print(m1.num1)
运行结果如下图:

第三部分 random模块
#1、随机获取一个数
#随机获取[0,1)的浮点数
import random
result = random.random()
print(result)
#随机获取[a,b]之间的一个整数
result = random.randint(1,100)
print(result)
#随机获取[a,b]之间的一个浮点数
result = random.uniform(1,100)
print(result)
#2、随机获取指定列表或元祖中的一个元素
s = “hello world Python”
result = random.choice(s)
print(result)
#3、打乱指定列表或元祖的顺序
nums = [1,2,3,4,5,6,7,8,9,0]
print(nums)
random.shuffle(nums)
print(nums)
#练习,实现一个公司的年会抽奖程序
#需求:1、从文件中读取参与抽奖的员工名字;2、抽奖:分别按顺序抽取锦鲤精,一,二,三等奖;3,每次抽完奖都需要将已经中奖的员工名字从抽奖名单中移除
import random
if name == ‘main’:
name_file = “参与抽奖员工姓名.txt”
jiangxiang = [‘锦鲤奖’,‘一等奖’,‘二等奖’,‘三等奖’]
#读取参与抽奖的员工姓名
try:
file1 = open(name_file,‘r’)
name_list = file1.readlines()
except Exception as err:
print(“文件读取错误,请检查参与抽奖员工姓名文件是否存在,详细报错信息如下:”,err)
else:
file1.close()
while(True):
# 抽奖
try:
random.shuffle(name_list)
xinyuner = random.choice(name_list)
item = jiangxiang[0]
print(f’获得{item}的幸运儿是:', xinyuner)
#移除已获奖人员名单
name_list.remove(xinyuner)
jiangxiang.remove(item)
except Exception as err1:
print(“所有员工都中奖啦!”)
break
else:
Flag = input(“请输入Y或y继续抽奖,其他字符表示退出抽奖程序:”)
if Flag != ‘Y’ and Flag != ‘y’:
print(“退出抽奖程序,欢迎下次再来!”)
break
#第四部分 sys模块
#4.1、sys常用属性
sys指的是解释器系统,os指的是操作系统
#sys.argv获取命令行参数列表,包括脚本名称和传递给脚本的其他参数
import sys
script_name = sys.argv
print(script_name)
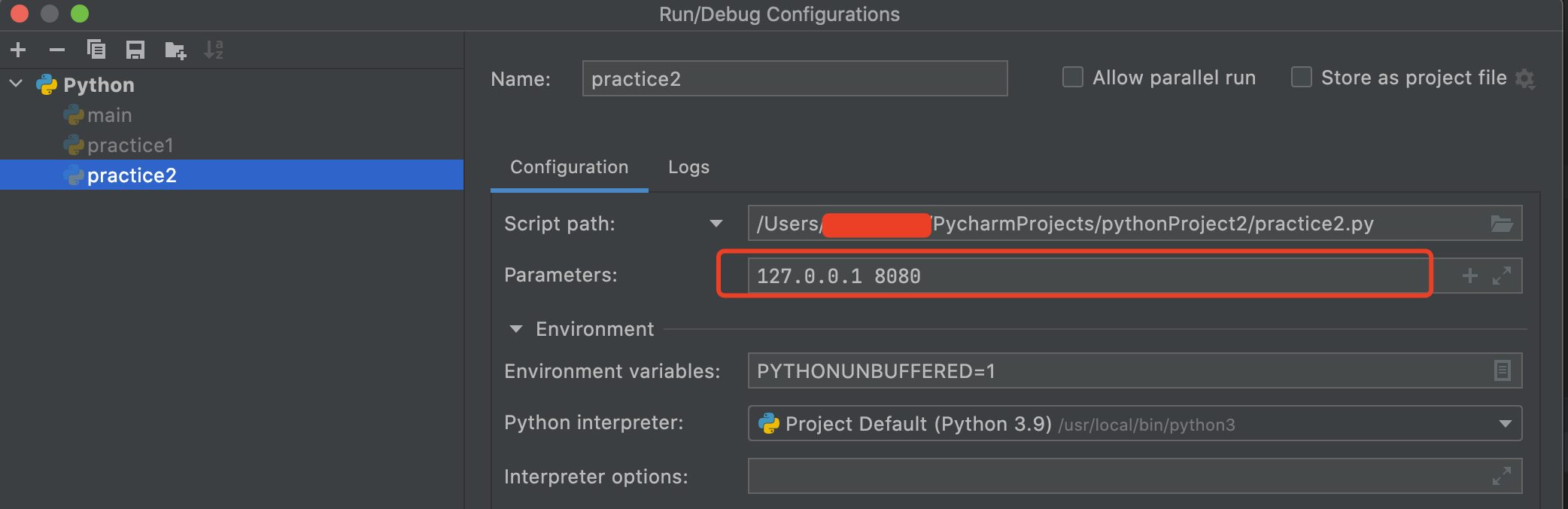
if len(script_name)<3:
#代码运行之前在Run/Debug configurations的parameters中输入参数,可以输入多个,每个参数之间用空格分隔,如输入127.0.0.1 8080
# 则代码运行时则认为该脚本执行时外部还传递了2个参数(127.0.0.1和8080)配置方法如下截图1和2
print(“请配置服务器的IP和端口”)
else:
print(f"WebServer start on {sys.argv[1]} {sys.argv[2]}")
配置方法截图1:

配置方法截图2:
#sys.version获取当前Python解释器的版本信息
#sys.version_info获取当前Python解释器的版本信息,以元祖形式表示详细的版本号信息
import sys
print(f"当前解释器的版本信息为:{sys.version}")
print(type(sys.version))
print(sys.version_info)
print(sys.version_info[0],sys.version_info[1],sys.version_info[2])
运行结果如下:

#sys.platform获取当前系统运行的操作系统名称
print(sys.platform)
print(sys.modules)
#返回已导入的模块信息,返回一个字典
for items_key,items_value in sys.modules.items():
print(f"模块名:{items_key},模块对象:{items_value}")
#sys.path获取模块搜索路径列表,用于指定python解释器搜索模块的路径
print(sys.path)
#4.2 sys常用方法
import time
#获取编码方式
print(sys.getdefaultencoding())
#运行时退出
sys.exit()
n = 0
while(True):
time.sleep(1)
n += 1
print(n)
if n ==5:
sys.exit()
第五部分 os模块
#python的内置库os提供了与操作系统交互的函数,允许您与操作系统进行各种操作,如文件和目录操作,环境变量访问,进程管理等。
#5.1 路径操作
import os
#获取当前路径
print(“当前路径是:”,os.getcwd())
#切换到指定路径下
os.chdir(‘/Users/PycharmProjects/pythonProject2/my_dir’)
#path相关的操作:返回绝对路径
path1 = os.getcwd()
path = path1 + ‘/practice2.py’
print(‘绝对路径为:’,os.path.abspath(path))
#path相关的操作:返回指定路径的文件名
print(‘文件名为:’,os.path.basename(path))
#path相关的操作:返回指定路径的目录
print(‘目录为:’,os.path.dirname(path))
#path相关的操作:将指定路径分隔成文件名和路径,并以一个元祖的形式储存
print(os.path.split(path))
#path相关操作:将多个路径连接起来形成一个路径
str1,str2 = os.path.split(path)
path_new = os.path.join(str1,str2)
print(‘重新拼接之后的路径为:’,path_new)
#path相关操作:判断一个路径是否存在
print(‘路径存在吗?’,os.path.exists(path))
#path相关操作:判断是否是目录
print(‘目录存在吗?’,os.path.isdir(path))
#path相关操作:判断是否是文件
print(‘文件存在吗?’,os.path.isfile(path))
#path相关操作:获取文件大小
print(‘文件大小为:’,os.path.getsize(path))
#5.2 目录和文件操作
#列出当前目录内容
print(“当前目录下文件有:”)
print(os.listdir(‘.’))
#创建一个新目录
os.mkdir(‘aa’)
open(‘aa/test.txt’,‘w’)
#递归创建多级目录
os.makedirs(‘a/b/c/d’)
#删除目录
os.rmdir(‘aa’)
#给文件或目录重命名
os.rename(‘mp’,‘mp_new’)
#删除文件
os.remove(‘aa/test.txt’)
#其他操作
#获取系统名称,windows系统值为nt,在linux,macos系统中值为:posix
print(‘系统名称为:’,os.name)
#获取系统分隔符
print(‘系统分隔符为:’,os.sep)
#更改文件权限模式,mode是权限模式,通常用八进制表示,如0o755
file_path = ‘/Users/ailing.feng/PycharmProjects/pythonProject2/data.txt’
os.chmod(file_path,0o755)
#第六部分 datetime模块
#datetime模块是Python标准库中用于处理日期和时间的模块,它提供了多种类和函数,用于处理日期,时间,时间间隔等操作。
#6.1、获取当前日期时间
from datetime import datetime
current_time = datetime.now()
print(“当前日期时间为:”,current_time)
#6.2、格式化当前日期时间
result = current_time.strftime(‘%Y-%m-%d %H:%M:%S’)
print(result)
result2 = current_time.strftime(‘%Y 年 %m 月 %d 日’)
print(result2)
result3 = current_time.strftime(‘%H 时 %M 分 %S 秒’)
print(result3)
#6.3、解析日期时间
date = ‘2023-03-29 10:30:33’
cdt = datetime.strptime(date,‘%Y-%m-%d %H:%M:%S’)
print(cdt,type(cdt))
#6.4、计算日期间隔 使用timedelta类可以进行日期间隔的计算
from datetime import timedelta
date1 = datetime(2023,3,29)
date2 = datetime(2023,11,20)
date_diff = date2 - date1
print(‘Date Difference is:’,date_diff)
work_time = date1 + timedelta(days=208)
print(‘work date is:’,work_time)
#6.5、比较日期 可以直接比较datetime对象来判断日期的先后关系
date1 = datetime(2023,10,27)
date2 = datetime(2023,10,27)
if date1 < date2:
print(“date1 is earlier than date2”)
elif date1 > date2:
print(“date1 is later than date2”)
else:
print(“date1 is the same with date2”)
#6.6、获取日期和时间的部分信息
current_time = datetime.now()
print(‘年:’,current_time.year)
print(‘月:’,current_time.month)
print(‘日:’,current_time.day)
print(‘时:’,current_time.hour)
print(‘分:’,current_time.minute)
print(‘秒:’,current_time.second)
#第七部分 正则表达式
#7.1、正则表达式符号
#常用正则表达式语法及含义
#7.1.1 普通字符:大多数只会匹配字符本身
#7.1.1 字符’.':匹配换行符 \n 外的任意字符
import re
print(re.match(“.”, “a”))
print(re.match(“.”, “A”))
print(re.match(“.”, “7”))
print(re.match(“.”, “#\n”))
print(re.match(“.”, “\n”))
运行结果:
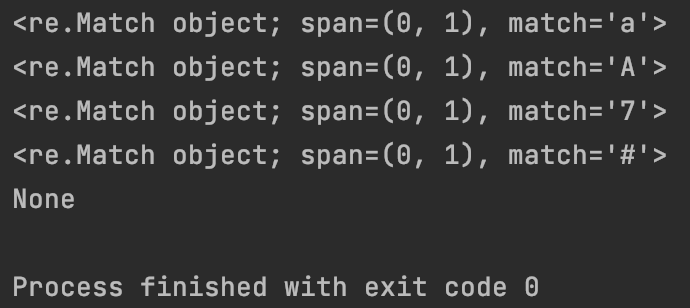
匹配的结果span=(0,1) 包含0,但不包含1
#7.1.2 字符’[]':匹配[]中列举的字符
print(re.match(“[abc]”, “a”))
print(re.match(“[abc]”, “b”))
print(re.match(“[abc]”, “cb”))
print(re.match(“[abc]”, “d”))
print(re.match(“[hH][eE][lL][lL][oO]”, “HelLO World”))
运行结果:
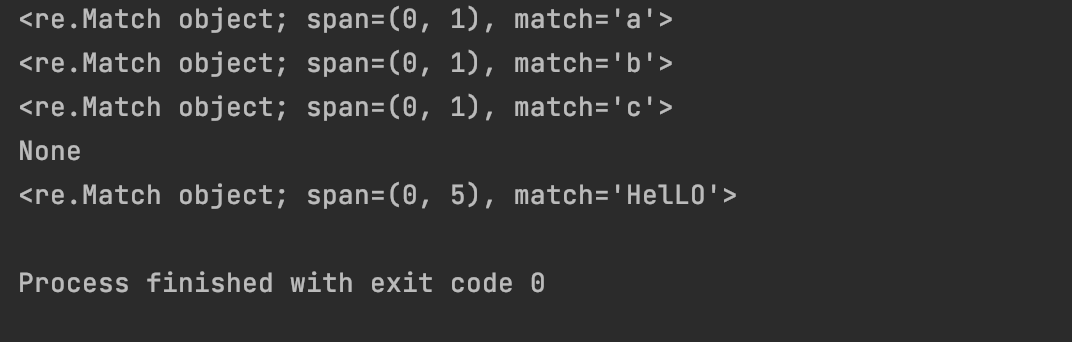
补充:
#补充
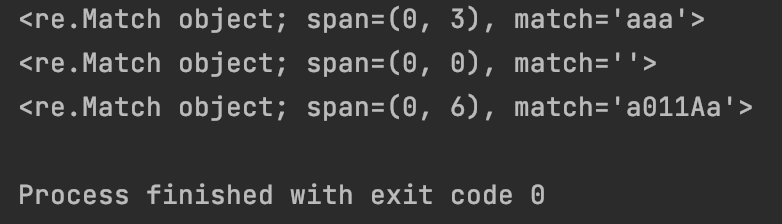
print(re.match(“[a-z]“, “aaaAa#$%”))
print(re.match(”[0-9]”, “a0Aa#$%”))
print(re.match(“[a-zA-Z0-9]*”, “a011Aa#$%”))
运行结果:
#7.1.3 字符’*':匹配前一个字符的零个或多个实例
print(re.match(“.“, “abcd”))
print(re.match(”.”, “abc\n”))
print(re.match(“.“, “”))
print(re.match(”.”, “\n”))
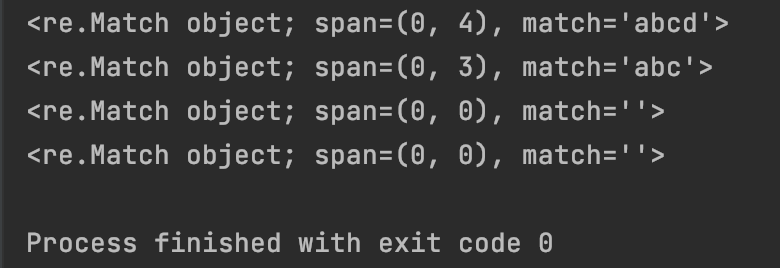
#7.1.4 字符’+':匹配前一个字符的一个或多个实例
print(re.match(“.+”, “ab7#&”))
print(re.match(“.+”, “abc\n”))
print(re.match(“.+”, “”))
print(re.match(“.+”, “\n”))
运行结果:
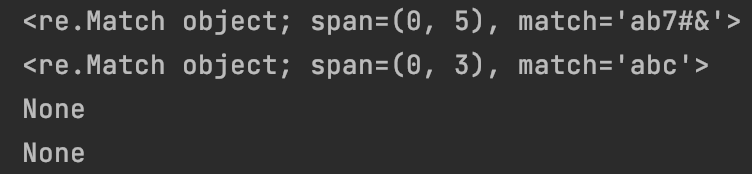
.+号表示任意字符匹配一次或多次,倒数第二个为空字符代表没有,所以匹配结果为none,最后一个.不能匹配\n,所以匹配结果也为none
#7.1.5 字符’?':匹配前一个字符的零个或多个实例
print(re.match(“[abc]?”, “a”))
print(re.match(“[abc]?”, “cb”))
print(re.match(“[abc]?”, “”))
print(re.match(“[abc]?”, “d”))
运行结果为:
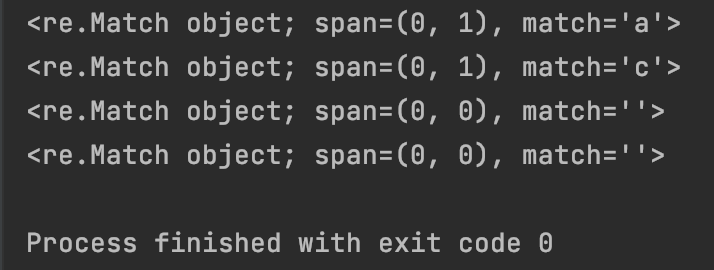
#7.1.6 字符’{m}':匹配前一个字符的m个实例
print(re.match(“[abc]{3}”, “a”))
print(re.match(“[abc]{3}”, “ab”))
print(re.match(“[abc]{3}”, “abc”))
print(re.match(“[abc]{3}”, “aaa”))
print(re.match(“[abc]{3}”, “adbabab”))
运行结果为:

#7.1.7 字符’{m,n}':匹配前一个字符的m到n个实例
print(re.match(“.{3,5}”, “a”))
print(re.match(“.{3,5}”, “ab”))
print(re.match(“.{3,5}”, “abc”))
print(re.match(“.{3,5}”, “aaa7&68#”))
print(re.match(“.{3,5}”, “ad\nbabab”))
运行结果为:
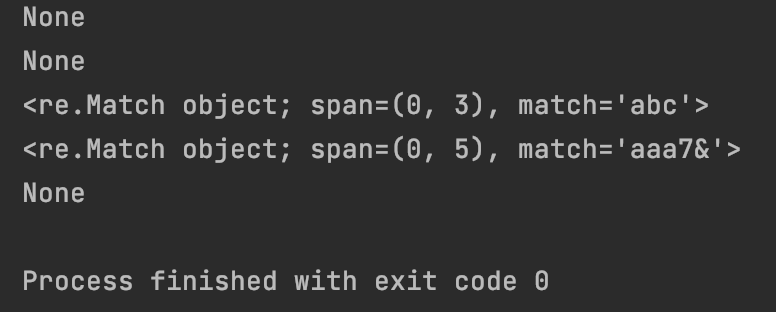
#7.1.8 字符’^':匹配字符串的开头
print(re.match(“[1]”, “a”))
print(re.match(“[2]”, “cb”))
print(re.match(“[3]”, “d”))
运行结果为:
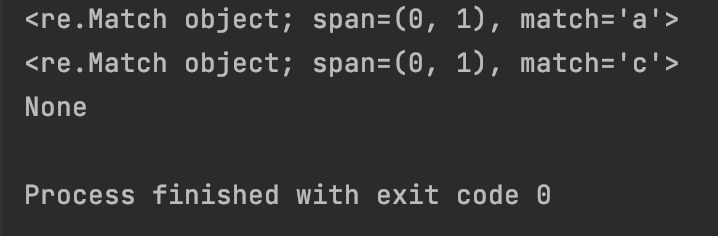
#7.1.9 字符’$':匹配字符串的结尾
print(re.match(“[abc]$”, “123a”))
print(re.match(“[abc]$”, “a”))
print(re.match(“.*[abc]$”, “123b”))
运行结果为:

第一个匹配结果为none,是因为match是从头开始匹配,所以结果为none
#7.1.10 字符’\d’:匹配任意数字字符,相当于[0-9]
print(re.match(“\d+”, “123b”))
print(re.match(“\d+”, “17”))
运行结果为:
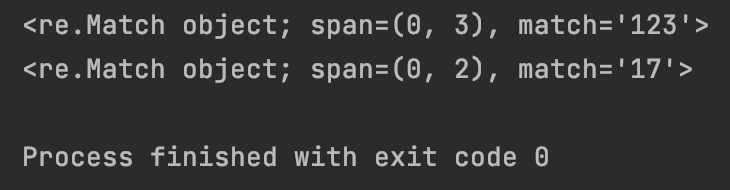
#7.1.11 字符’\D’:匹配任意非数字字符,相当于除[0-9]以外的字符
print(re.match(“\D+”, “17”))
print(re.match(“\D+”, “a”))
print(re.match(“\D+”, “&”))
print(re.match(“\D+”, “\n”))
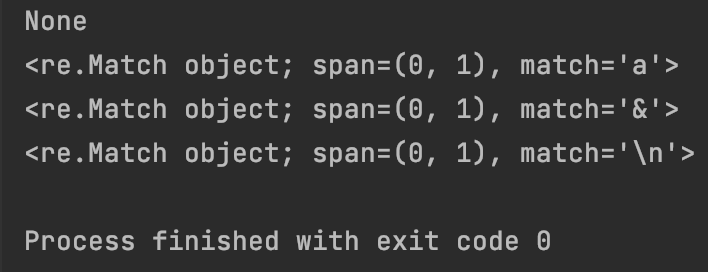
#7.1.12 字符’\w’:匹配任意字母、数字或下划线字符等非特殊字符,相当于[a-zA-Z0-9_]
print(re.match(“\w+”, “adsf123”))
print(re.match(“\w+”, “123_adsf”))
print(re.match(“\w+”, “adsf_”))
print(re.match(“\w+”, “&adsf”))
print(re.match(“\w+”, “你好”))
运行结果为:
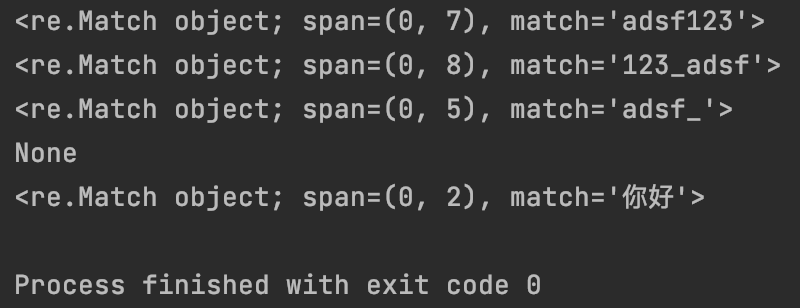
#7.1.13 字符’\W’:匹配任意字母、数字或下划线字符以外的特殊字符,相当于除[a-zA-Z0-9_]以外的字符
print(re.match(“\W+”, “adsf123”))
print(re.match(“\W+”, “123_adsf”))
print(re.match(“\W+”, “adsf_”))
print(re.match(“\W+”, “&adsf”))
print(re.match(“\W+”, “你好”))
运行结果为:
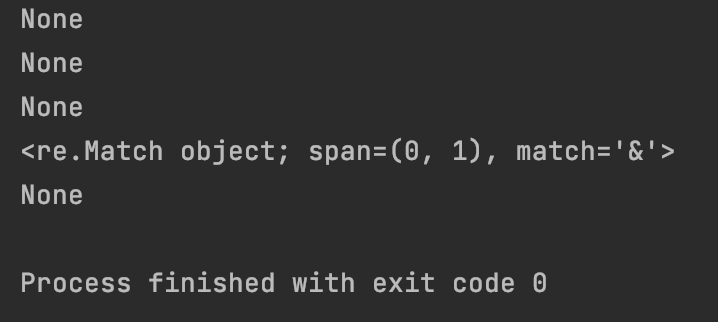
#7.1.14 字符’\s’:匹配任意空白字符,如空格、制表符、换行等
print(re.match(“\s+”, " “))
print(re.match(”\s+“, “\n”))
print(re.match(”\s+“, “\r”))
print(re.match(”\s+“, “\t”))
print(re.match(”\s+", “\b”))
运行结果为:
备注:\b 为特殊字符,所以匹配结果为none
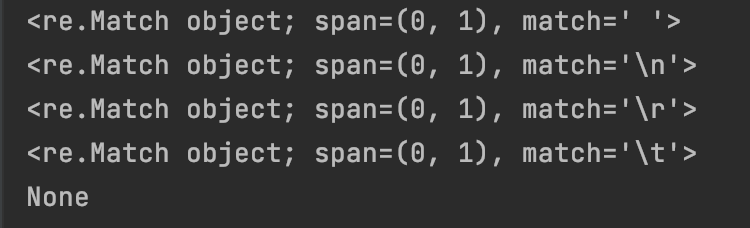
#7.1.15 字符’\S’:匹配任意非空白字符
print(re.match(“\S+”, “absdf”))
print(re.match(“\S+”, " absdf"))
运行结果为:
#7.2 正则表达式常用的方法
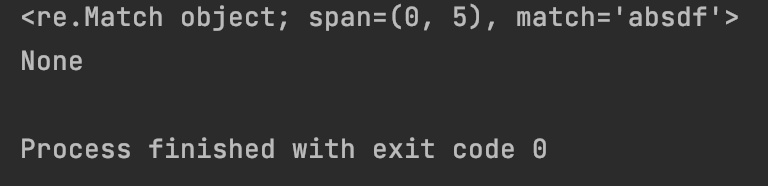
#7.2.1 re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none
import re
print(re.match(“hello”, “hello world”))
print(re.match(“hello”, “Helloworld”))
运行结果:
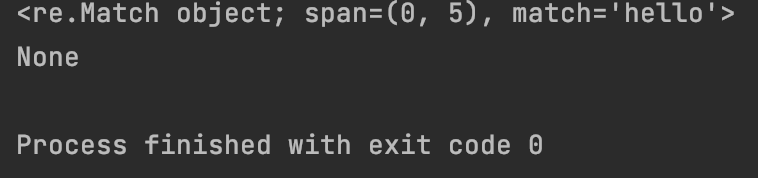
#1)、group获取匹配结果
#2)、span获取匹配结果在原字符中的位置,注意为左开右闭区间
#3)、start获取匹配结果在原字符中的起始下标位置
#4)、end获取匹配结果在原字符中的结束下标位置
result = re.match(“hello”,“helloworld”)
print(result.group())
print(result.span())
print(result.start())
print(result.end())
运行结果为:
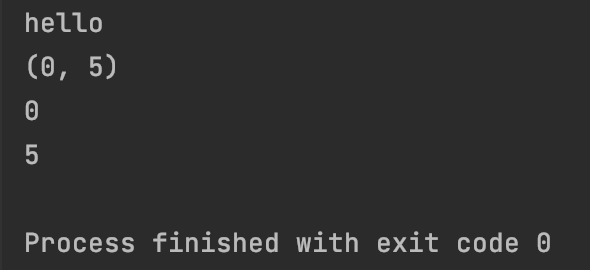
#7.2.2、re.search在字符串中搜索匹配指定的模式,如果找到则返回匹配对象,否则则返回none
result = re.search(“\d+”,“123abc”)
print(result.group())
print(result.span())
print(result.start())
print(result.end())
result = re.search(“\d+”,“abc1234”)
print(result.group())
print(result.span())
print(result.start())
print(result.end())
result = re.search(“\d+”,“abc12345abc”)
print(result.group())
print(result.span())
print(result.start())
print(result.end())
运行结果为:
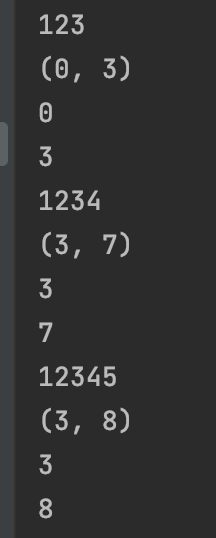
#7.2.3、re.findall 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元祖列表,如果没有找到匹配的,则返回空列表
result = re.findall(‘(\w+)=(\d+)’,‘asd width=20 sdf height=10 python:100’)
print(result)
运行结果为:
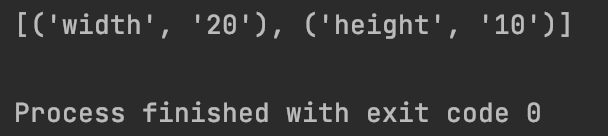
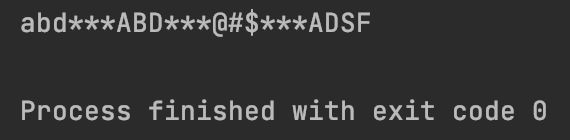
#7.2.4、re.sub:用于替换字符串中的匹配项
result = re.sub(‘\d+’,‘***’,‘abd123ABD234@#$36456ADSF’)
print(result)
运行结果为:
#7.2.5、按照能够匹配的子串将字符串分割后返回列表
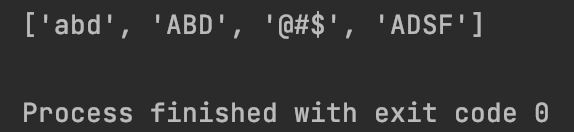
result = re.split(‘\d+’,‘abd123ABD234@#$36456ADSF’)
print(result)
#7.3 匹配模式
#7.3.1 re.IGNORECASE:用于在正则表达式中启用大小写不敏感的匹配,可简写为re.I
pattern1 = r’apple’
str1 = ‘Apple is a fruit. I like apple pie aPPle.’
print(“未启用大小写不敏感的匹配结果为:”,re.findall(pattern1,str1))
print(“启用大写小不敏感的匹配结果为:”,re.findall(pattern1,str1,re.IGNORECASE))

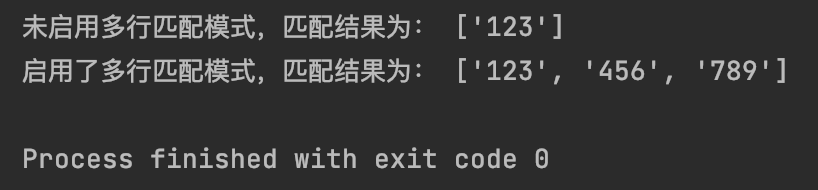
#7.3.2 re.MULTLINE:用于启用多行模式,使用^和S在每行的开头和结尾都能匹配,可简写为re.M
pattern2 = r’^\d+’
str2 = ‘123 apple\n456 banana\n789 cherry’
print(“未启用多行匹配模式,匹配结果为:”,re.findall(pattern2,str2))
print(“启用了多行匹配模式,匹配结果为:”,re.findall(pattern2,str2,re.MULTILINE))
运行结果为:
#7.4 匹配分组
#7.4.1 “|”:使用"|"匹配左右任意一个表达式
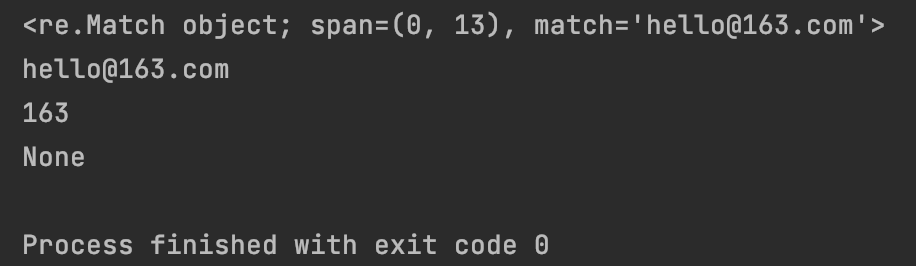
match_obj1 = re.match(‘[a-zA-Z0-9_]{4,20}@(163|126|qq|sina|yahoo).com’,‘hello@163.com’)
print(match_obj1)
print(match_obj1.group(0))
print(match_obj1.group(1))
match_obj2 = re.match(‘[a-zA-Z0-9_]{4,20}@(163|126|qq|sina|yahoo).com’,‘hell@gmail.com’)
print(match_obj2)
运行结果为:
#7.4.2 (XXX):将括号中字符作为一个分组
match_obj3 = re.match(“(\d{3,4})-(\d{4,10})”,“010-888999”)
print(match_obj3.group()) #默认取匹配到的全部结果
print(match_obj3.group(0)) #取匹配到的全部结果
print(match_obj3.group(1)) #取匹配到的第一个()里的结果
print(match_obj3.group(2)) #取匹配到的第二个()里的结果
运行结果为:

#7.4.3 \num:引用分组num匹配到的字符串
match_obj4 = re.match(“<([a-zA-Z1-6]+)>.</\1>“,”hh“)
print(match_obj4)
运行结果为:

【#7.4.4 (?P):分组起别名】
【#7.4.5 (?P=name):引用别名为name分组匹配到的字符串】
#【(?P)(?P=name)分组别名与引用】:在使用分组时,可以给分组进行命名,在匹配规则中,可以通过分组命名引用某个分组中的规则
match_obj5 = re.match(”<(?P[a-zA-Z1-6]+)><(?P[a-zA-Z1-6]+)>.<(?P=name2)><(?P=name1)>”,“

