一、pymysql
1、操作流程
- 导入模块
- 连接数据库
- 创建游标对象
- 执行数据库操作
- 关闭游标对象
- 关闭数据库连接
2、连接和关闭数据库
-
PyMySQL模块提供了四个连接数据库的函数名,其本质是多个变量的函数引用横等赋值,最终还是执行一个函数。 - 官方代码: 按代码的赋值顺序,推荐使用
Connect方式连接,其它函数使用方式相同。
Connect = connect = Connection = connections.Connection
- 连接数据库:函数格式及主要参数如下:
Connect(host, port, user, password, database, charset)
* `host`:数据库主机的地址,默认为 `localhost`。
* `port`:数据库的端口号,默认为 `3306`。
* `user`:连接数据库所用的用户名。
* `password`:连接数据库所用的密码。
* `database`:要连接的数据库的名称。
* `charset`:连接数据库时使用的字符集,默认为"utf8"。
-
关闭数据库:数据库使用完毕后,需要调用
close()方法将数据库连接对象关闭,让其断开数据库连接,避免资源泄漏。
import pymysql
# 连接数据库
conn = pymysql.Connect(
host="127.0.0.1",
port=3306,
user="root",
password="123456",
database="litemall",
charset="utf8"
)
# 获取游标
cursor = conn.cursor()
# 执行语句
cursor.execute("select version()")
# 获取执行结果第一条数据
fetchone = cursor.fetchone()
print(fetchone)
# 关闭游标
cursor.close()
# 关闭数据库
conn.close()
3、 获取和关闭游标对象
-
在进行数据库操作时,每次数据库操作都应该建立一个游标对象,在操作完毕后将其关闭,不应使用一个游标对象进行多次操作。
-
游标对象的作用是用来执行数据库操作,在执行完一次操作后,应调用
close()方法将游标对象关闭。 -
PyMySQL模块使用数据库连接对象.cursor()方法获取游标对象。
4、执行SQL语句
-
PyMySQL模块使用execute()方法执行 SQL 语句,实现数据库操作。 - 语法格式:
游标对象.execute(query, args=None);-
query:需要执行的 SQL 语句; -
args:为 SQL 语句中的占位符提供参数,防止 SQL 注入的发生;
-
insert_sql = ''' insert into class(name,sort,type) values(%s, %s, %s) '''
values = ("创业宝典", 9, 0)
result = cursor.execute(insert_sql,values)
5、查询操作
(1)获取单条查询记录fetchone()
-
使用
execute执行完毕 SQL 语句后, 可以使用游标对象.fetchone()方法获取一条查询结果。 -
fetchone()方法可重复使用,程序会继续向后读取查询结果。如果无查询结果可读取,则返回None。
(2)获取所有查询记录fetchall()
- 可以使用
游标对象.fetchall()方法获取全部查询结果。
(3)获取指定条数查询结果fetchmany(size)`
- 可以使用
游标对象.fetchmany(size)方法获取指定数量查询结果。
import pymysql
# 连接数据库
conn = pymysql.connect(
host="localhost",
port=3306,
user="root",
password="123456",
database="litemall",
charset="utf8"
)
# 获取游标对象
cursor = conn.cursor()
# 执行查询sql语句
select_sql = "select name from litemall_goods where brand_id = %s;"# %s占位符
value = 1001000
cursor.execute(select_sql,value)
# 执行之后使用游标获取一条数据
one = cursor.fetchone()
# 再获取一条
two = cursor.fetchone()
print(f"第一条数据:{one}")
print(f"第二条数据:{two}")
print("*"*20)
# 获取5条查询记录
five = cursor.fetchmany(5)
print(f"前五条记录为:{five}")
print("*"*20)
# 获取全部查询记录
all = cursor.fetchall()
print(f"全部结果为:{all}")
print("*"*20)
# 关闭游标
cursor.close()
# 关闭数据库连接
conn.cursor()
6、插入操作
-
执行插入操作同样使用 execute() 方法,插入数据时的 SQL 语句中的新数据,可以使用传参的方式填 入。
-
参数可以使用
元组或列表形式传入。 -
在插入数据操作完成后,需要对所做的更改操作进行提交。
-
提交操作使用
数据库连接对象.commit()方法。
import pymysql
# 连接数据库
conn = pymysql.connect(
host="localhost",
port=3306,
user="root",
password="123456",
database="litemall"
)
# 获取游标
cursor = conn.cursor()
# 执行插入语句
insert_sql = "insert into litemall_goods(id,name,brief) values (%s,%s,%s);"
values = (1005001,"夏凉被","夏天冷到感冒")
result = cursor.execute(insert_sql,values)
print(f"执行插入语句后的结果是啥:{result}")# 结果是执行成功的条数
# 插入数据执行完之后需要对操作进行提交
conn.commit()
# 关闭游标
cursor.close()
# 关闭数据库连接
conn.close()
7、更新操作
- 更新操作同插入操作,只是 SQL 语句不同,操作完毕后,需要执行提交操作。
import pymysql
# 连接数据库
conn = pymysql.connect(
host="localhost",
port=3306,
user="root",
password="123456",
database="litemall"
)
# 获取游标
cursor = conn.cursor()
# 执行更新语句
update_sql = "update litemall_goods set name = %s,brief = %s where id = %s;"
# 列表参数
values = ["溜冰鞋","会滑冰的也会倒","1005001"]
result = cursor.execute(update_sql,values)
print(f"执行更新语句后的结果是啥:{result}")# 结果是执行成功的条数
# 更新数据执行完之后需要对操作进行提交
conn.commit()
# 关闭游标
cursor.close()
# 关闭数据库连接
conn.close()
8、删除操作
- 删除操作同插入操作和更新操作,只是 SQL 语句不同,操作完毕后,需要执行提交操作。
import pymysql
# 连接数据库
conn = pymysql.connect(
host="localhost",
port=3306,
user="root",
password="123456",
database="litemall"
)
# 获取游标
cursor = conn.cursor()
# 执行插入语句
delete_sql = "delete from litemall_goods where id = %s;"
# 元组类型参数
values = (1005001,)
result = cursor.execute(delete_sql,values)
print(f"执行删除语句后的结果是啥:{result}")# 结果是执行成功的条数
# 删除数据执行完之后需要对操作进行提交
conn.commit()
# 关闭游标
cursor.close()
# 关闭数据库连接
conn.close()
二、PyYAML及yaml文件
1、什么是YAML文件
-
YAML全称其实是"YAML Ain’t a Markup Language"(YAML不是一种标记语言)的递归缩写,所以它强调的是数据本身,而不是以标记为重点。
-
YAML 是一种可读性非常高,与程序语言数据结构非常接近。同时具备丰富的表达能力和可扩展性,并且易于使用的数据标记语言。
2、YAML的基本语法规则
- 大小写敏感;
- 使用缩进表示层级关系;
- 缩进时不允许使用Tab键,只允许使用空格。(可以将你的ide的tab按键输出替换成4个空格);
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可;
-
表示注释;
3、YAML 的数据结构
- 对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary);
- 数组:一组按次序排列的值,又称为序列(sequence) / 列表(list);
- 纯量(scalars):单个的、不可再分的值;
4、对象类型
- 对象的一组键值对,使用冒号结构表示,会转换成 Python 中的字典。
#Python对应 {'animals': 'dog'}
animals: dog
# python对应 {'person': {'name': 'Tom', 'age': 20, 'gender': 'male'}}
person: {name: tom,age: 20,gender: male}
5、数组类型
- 数组类型使用 - 为前缀,每个元素独占一行,通过缩进关系表示层级包含关系,会转换成 Python 中的列表。
# python:['one', 'two', 'three', 'four', 'five']
- one
- two
- three
- fore
- five
# python:[[1, 2, 3], [4, 5, 6]]
-
- 1
- 2
- 3
-
- 4
- 5
- 6
6、纯量类型
-
纯量类型是最基本的、不可再分的值;类似基本数据类型。
- 字符串, 不需要使用双引号包裹
- 布尔值,true,True,false,False都可以
- 整数
- 浮点数
- 时间,时间使用ISO 8601格式,时间和日期之间使用T连接,最后使用+代表时区
- 日期,日期必须使用ISO 8601格式,即 yyyy-MM-dd
- Null,~ 表示 Null
YAML:
int: 12
float: 12.3
string: pets
bool: true
None: null
time: 2001-12-14t21:59:43.10-05:00
date: 2018-03-21
Python:
{
'int': 12,
'float': 12.3,
'string': 'pets',
'bool': True,
'None': None,
'time': datetime.datetime(2001, 12, 14, 21, 59, 43, 100000, tzinfo=datetime.timezone(datetime.timedelta(days=-1, seconds=68400))),
'date': datetime.date(2018, 3, 21)
}
7、复杂结构
- Tips:有
:后面的内容就解析成字典,有-后面的内容就解析成列表的元素;
YAML:
cool_list:
- 10
- 15
- 12
hard_list:
- {key: value}
- [1,2,3]
- test:
- 1
- 2
- 3
twice_list:
-
- {a: AA}
- {b: BB}
- {c: CC}
Python:
{
'cool_list': [10, 15, 12],
'hard_list': [
{'key': 'value'},
[1, 2, 3],
{
'test': [1, 2, 3]
}
],
'twice_list':[
[
{'a': 'AA'},
{'b': 'BB'},
{'c': 'CC'}
]
]
}
8、使用PyYAML进行YAML 文件处理
(1)安装PyYAML模块
pip install pyyaml
(2)读取 YAML 文件
- YAML 模块使用
safe_load()方法读取 yaml 文件,在读取文件之前,和普通文件一样,需要先将文件打开。
import yaml
# 读取yaml文件
with open("复杂结构.yaml","r") as file:
result = yaml.safe_load(file)
print(result)
print(type(result))
(3)写入 YAML 文件
- YAML 模块使用
safe_dump()方法向 yaml 文件中写入数据,在写入文件之前,也需要先将文件打开。
import yaml
data = [
{
"java":[{"基本数据类型":["字符串","数组","集合","map",]},["IO流","反射"]],
"python": {"高级用法":["装饰器","注解"]}
},
"python上手快",
["要学java","也要学python"]
]
with open("dump.yaml","a",encoding="utf-8") as file:
# allow_unicode=True -- yaml文件显示中文
result = yaml.safe_dump(data,file,allow_unicode=True)
print(result)
print(data)
结果:
- java:
- 基本数据类型:
- 字符串
- 数组
- 集合
- map
- - IO流
- 反射
python:
高级用法:
- 装饰器
- 注解
- python上手快
- - 要学java
- 也要学python
三、urllib3-TODO
四、openpyxl
提示: 如果pycharm无法识别excel文件(显示问号),那就安装插件Atom Material Icons;
1、openpyxl安装
- 安装:
pip install openpyxl - 导入:
import openpyxl
2、openpyxl读取excel的步骤
注意: openpyxl只支持读取xlsx格式的数据,在准备数据的时候新建文件就要建xlsx格式的,不能通过xls的去修改后缀名;
- 读取工作簿
- 读取工作表
- 读取单元格
- 获取单元格数据
import openpyxl
# 获取工作簿
book = openpyxl.load_workbook("exceldata.xlsx")
# 读取当前活跃工作表--活跃的意思关闭excel文件前一刻或者此时正打开的sheet窗口
sheet = book.active
print(f"sheet={sheet}")# sheet=<Worksheet "Sheet1">
print(f"sheet类型={type(sheet)}")# sheet类型=<class 'openpyxl.worksheet.worksheet.Worksheet'>
# 读取单个单元格
# 第一列第一行--方式一
cell_a1 = sheet['A1']
# A3第一列,第三行--方式二
cell_a3 = sheet.cell(column = 1,row = 3)
print(f"cell_a1={cell_a1}")# cell_a1=<Cell 'Sheet1'.A1>
print(f"cell_a1类型={type(cell_a1)}")# cell_a1类型=<class 'openpyxl.cell.cell.Cell'>
# 读取多个单元格,一个正方形区域--结尾为:元组数据,内部将一行也放入一个元组
cells_1 = sheet['A1':'C3']
print(f"cells={cells_1}")# cells=((<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>, <Cell 'Sheet1'.C1>), (<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>), (<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>, <Cell 'Sheet1'.C3>))
print(f"cells类型={type(cells_1)}")# cells类型=<class 'tuple'>
# 获取单元格的值
cell_a1_value = cell_a1.value
print(f"cell_a1_value={cell_a1_value}")# cell_a1_value=1
print(f"cell_a1_value类型={type(cell_a1_value)}")
3、其他api
-
获取所有工作表名:
book.sheetnames; -
指定某张工作表:
- 通过工作表名指定:
current_sheet = book["表二数据"]; - 通过工作表索引指定:
current_sheet = book.worksheets[0];
- 通过工作表名指定:
-
读取列表的行数、列数、行列数;
import openpyxl
# 获取工作簿
book = openpyxl.load_workbook("exceldata.xlsx")
# 获取所有工作表名
sheet_names = book.sheetnames
print(f"sheet_name={sheet_names}")# sheet_name=['表一数据', '表二数据', 'Sheet3']
# 通过工作表名指定工作表
current_sheet = book["表二数据"]
# 通过工作表索引指定工作表--索引默认从0开始
current_sheet = book.worksheets[0]
print(current_sheet['A1'].row) #读取的表格的行数
print(current_sheet['A1'].column) #读取的表格的列数
print(current_sheet['A8'].coordinate) #读取的表格的行列数。输出的值为'A8'
4、工具封装
from openpyxl import load_workbook
def get_excel(filename,sheetname):
"""
提取数据,格式:[(,,),(,,),(,,)]
:param filename: excel文件名
:param sheetname: excel工作表名
:return:
"""
# 读取工作簿
book = load_workbook(filename)
# 打开指定名称工作表
sheet = book[sheetname]
# 提取数据,格式:[(,,),(,,),(,,)]
result = []
for row in sheet:# 遍历表得到每一行
print(f"这是表的什么:{row}")
temp = []
for cell in row:# 获取每一行的每一个cell
print(f"这又是什么:{cell}")
value = cell.value
temp.append(value)
result.append(tuple(temp))
return result
if __name__ == '__main__':
filename = "exceldata.xlsx"
sheetname = "表二数据"
result = get_excel(filename,sheetname)
print(result)
---------------------------------------------------------------
这是表的什么:(<Cell '表二数据'.A1>, <Cell '表二数据'.B1>, <Cell '表二数据'.C1>)
这又是什么:<Cell '表二数据'.A1>
这又是什么:<Cell '表二数据'.B1>
这又是什么:<Cell '表二数据'.C1>
这是表的什么:(<Cell '表二数据'.A2>, <Cell '表二数据'.B2>, <Cell '表二数据'.C2>)
这又是什么:<Cell '表二数据'.A2>
这又是什么:<Cell '表二数据'.B2>
这又是什么:<Cell '表二数据'.C2>
这是表的什么:(<Cell '表二数据'.A3>, <Cell '表二数据'.B3>, <Cell '表二数据'.C3>)
这又是什么:<Cell '表二数据'.A3>
这又是什么:<Cell '表二数据'.B3>
这又是什么:<Cell '表二数据'.C3>
[('A-1', 'B-1', 'C-1'), ('A-2', 'B-2', 'C-2'), ('A-3', 'B-3', 'C-3')]
五、pandas-TODO
六、mitmproxy-mock工具与定制化
1、mitmproxy介绍
- 工具一:mitmproxy:交互式的命令行工具;
- 注意:不支持 windows;
- 工具二:mitmweb:基于浏览器的界面交互工具;
- 工具三:mitmdump:简单的终端输出,可以编写强大的插件和脚本;
- mitmproxy官网;
2、mitmproxy第三方库安装
注意:
- python版本最好在3.8以上;
2.库的名称是mitmproxy,但是模块却使用的是mitmdump;
# 方式一
pip install mitmproxy==5.2.0
# 方式二
pip install pipx
pipx install mitmproxy==5.2.0
# 验证是否安装成功
mitmdump --version
3、PC 端证书配置
- 配置电脑代理;
- 启动 mitmproxy;
- 在系统自带浏览器输入地址
mitm.it; - 选择对应系统下载证书并安装;
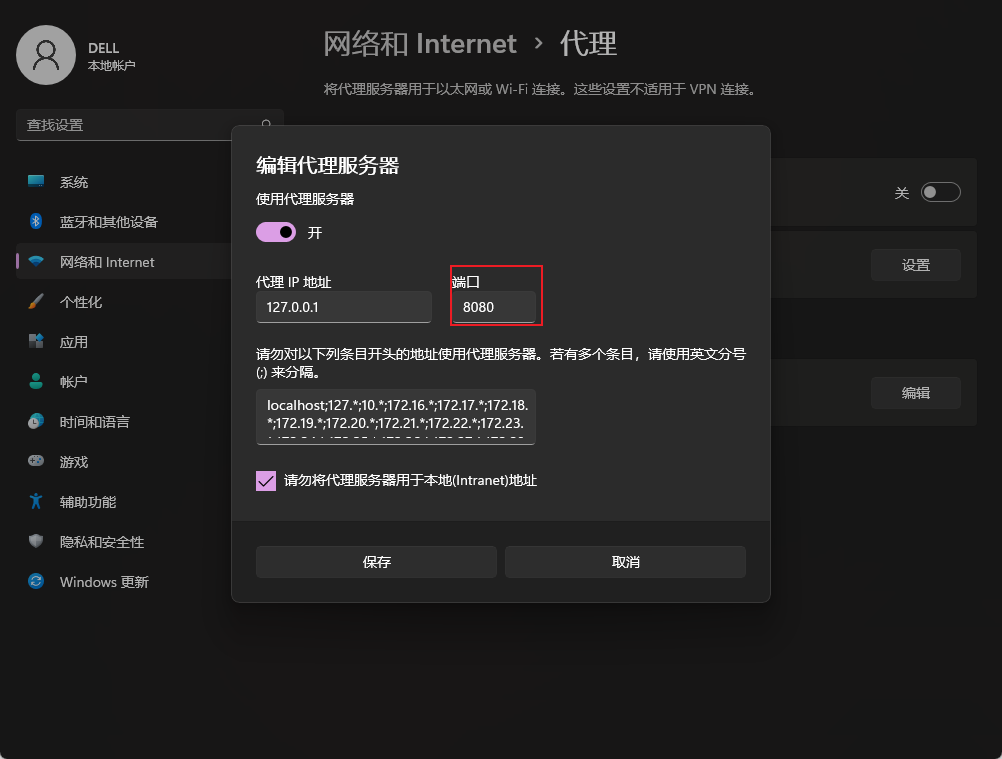
1. 配置电脑代理;
- 先通过命令查看mitmproxy监听的端口号:
命令 mitmdump;

- 配置电脑代理;
2. 启动 mitmproxy;
- 启动mitmproxy服务命令:
mitmdump;
3. 在系统自带浏览器输入地址 mitm.it;
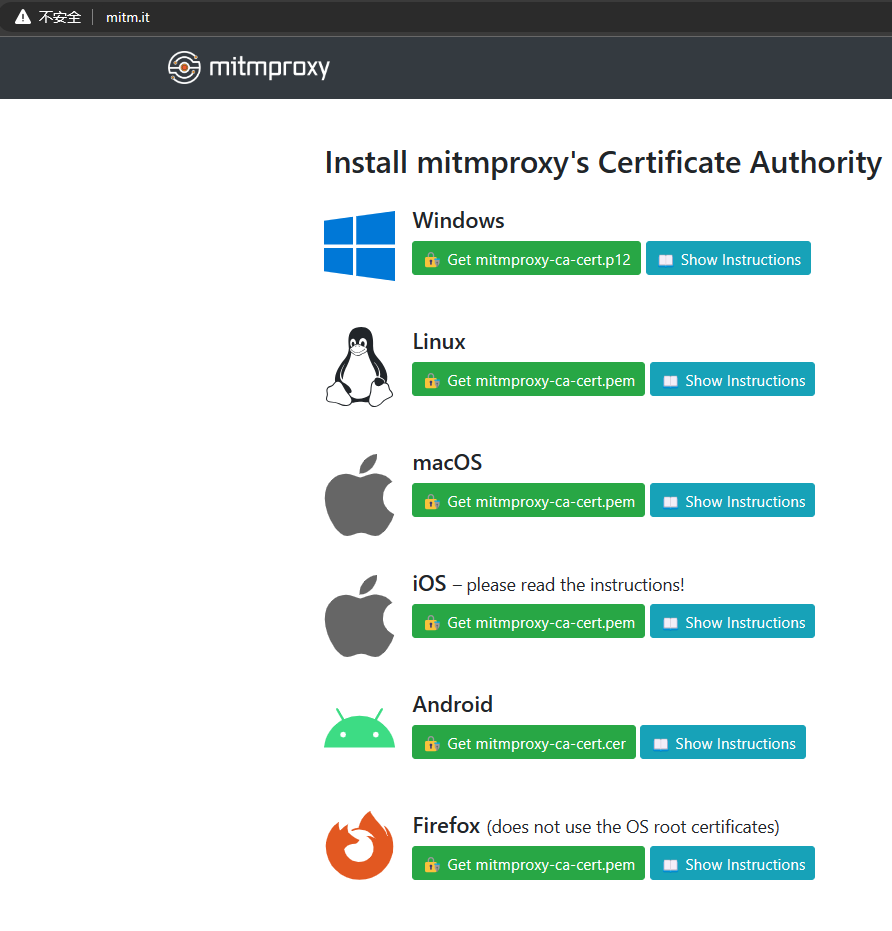
4. 选择对应系统下载证书并安装;

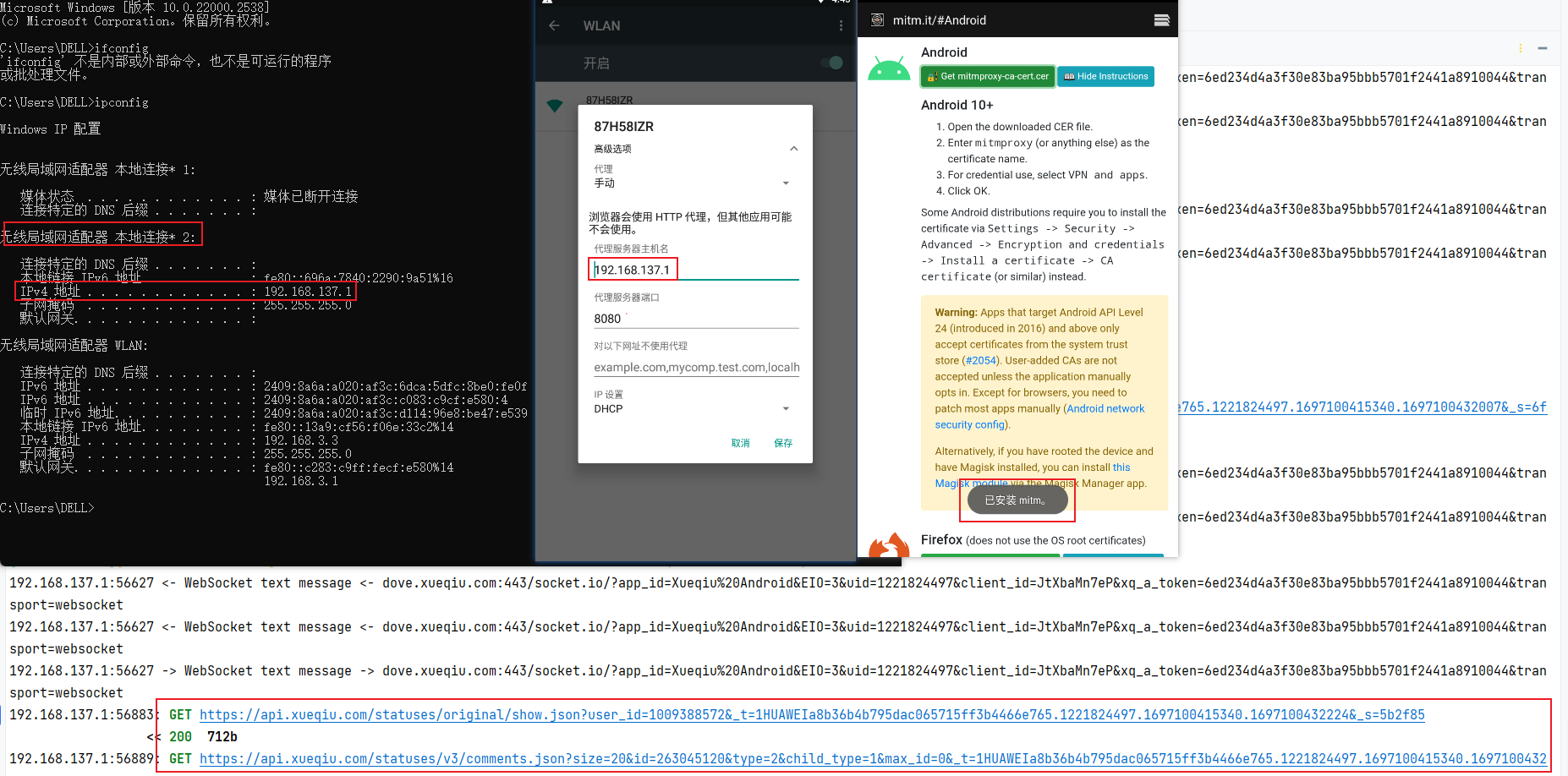
4、移动端证书配置
- 在手机配置代理,ip 配置为电脑的 ip 地址,端口配置为 mitmproxy 监听端口8080;
- 启动 mitmproxy;
- 在手机浏览器输入地址 mitm.it;
- 选择 Android,下载并安装,即可成功抓取手机端的 https 的数据包。
5、mitmdump 使用-结合python脚本
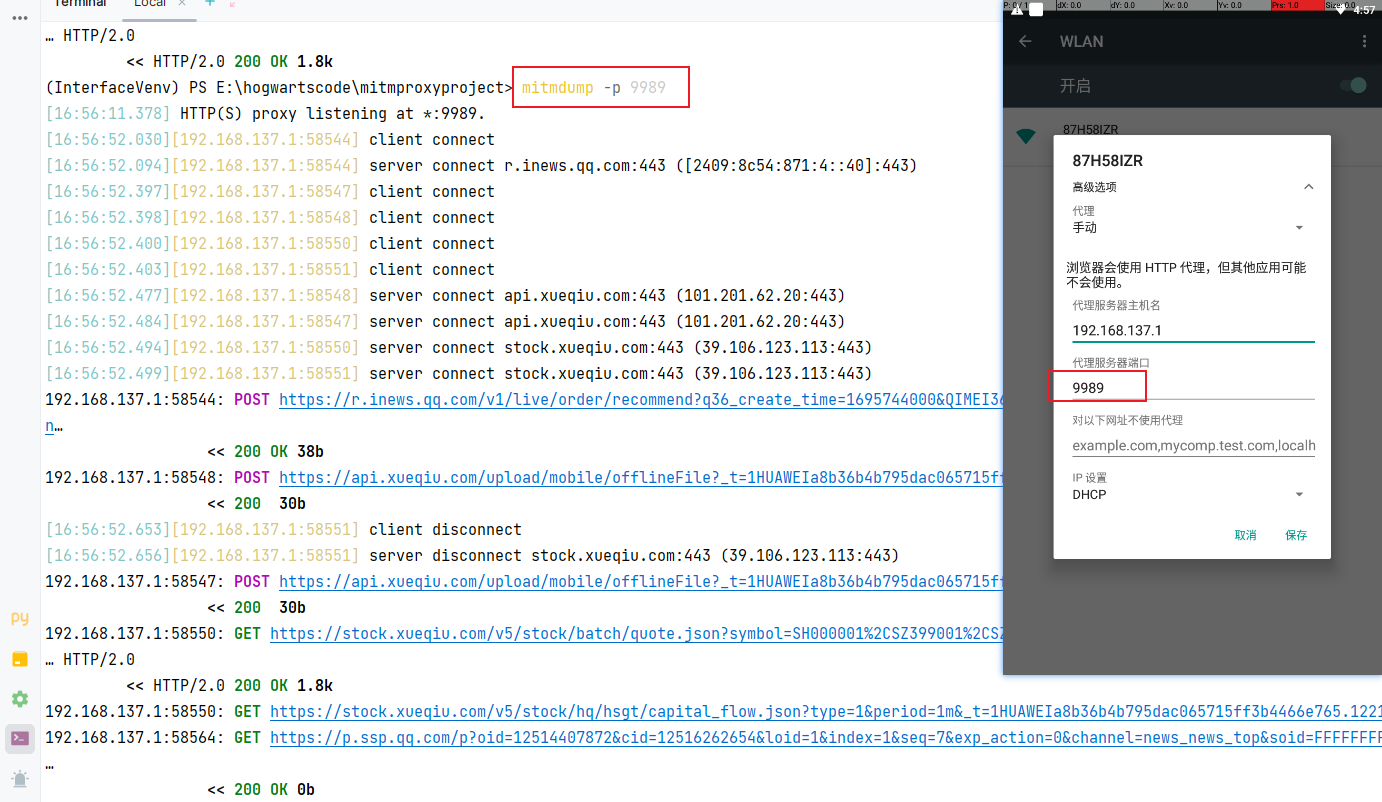
(1)mitmdump常用参数
-
-p参数,指定监听端口,默认监听 8080; -
-s参数,执行 python 脚本;
(2)mitmdump核心组件
- Addons(插件):https://docs.mitmproxy.org/archive/v5/addons-overview/
- Events(事件):Events
(3)脚本初体验
from mitmproxy import http
def request(flow: http.HTTPFlow):
"""
重写request方法,意思是需要对请求信息进行mock
:param flow: 这就是mitmproxy抓取到的请求,通过参数注解的方式指定为HTTPFlow类型
:return:
"""
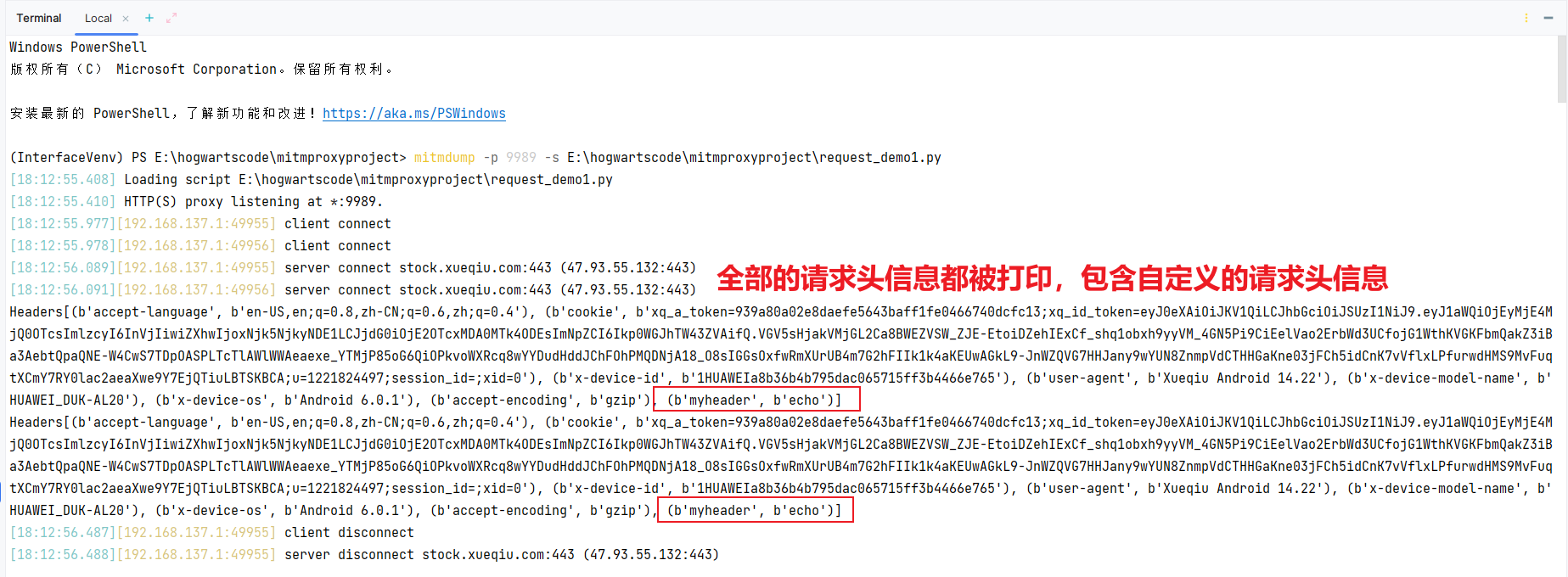
# 添加自定义的请求头信息
flow.request.headers['myheader'] = 'echo'
# 打印所有的请求头信息
print(flow.request.headers)
6、mitmdump 具体使用
(1)实现 MapLocal
- 原理:监听到请求之后直接返回设置好的本地文件数据,直接拦截请求,请求没有发送到服务器;
- 步骤:
- 创建一个本地文件,设定响应数据;
- 编写脚本重写
request()方法,在请求事件中,即给响应对象复制; - 执行命令启动mitmdump:
mitmdump -p 9989 -s E:\hogwartscode\mitmproxyproject\xueqiu_maplocal.py; - 访问浏览器(app)验证结果;
"""
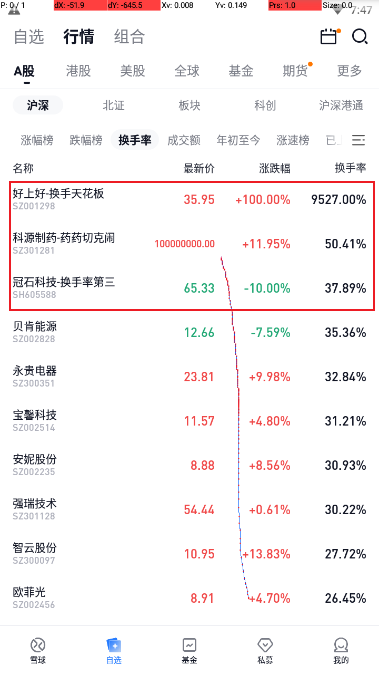
对雪球行情中的数据进行maplocal处理
url=https://stock.xueqiu.com/v5/stock/screener/quote/list.json
"""
from mitmproxy import http
# request 名称不能被改变
# mitmdump 加载这个脚本的时候,当有请求来的时候,就会回调这个request方法
# flow 为抓取到的请求信息
def request(flow: http.HTTPFlow) -> None:
print("flow=",flow)
print("*"*20)
print("type(flow)=",type(flow))
# 发起请求,判断url是不是等于一个路径
if "https://stock.xueqiu.com/v5/stock/screener/quote/list.json" in flow.request.pretty_url:
# 打开本地maplocal数据文件
file = "E:/hogwartscode/mitmproxyproject/xuqiu_maplocal.json"
with open(file,'r',encoding="utf8") as f:
# 一旦请求的url等于我们的预期,我们就会创造一个response:status=200,内容为本地数据文件,数据格式为json
flow.response = http.Response.make(
200, # status状态码
f.read(), # content需要是bytes类型
# 请求头信息,字典形式
{"Content-Type": "application/json"}# --数据类型为json
)
(2)实现 Rewrite
- 原理:请求发送到服务器返回的时候,篡改返回的内容;
- 实现:重写
response()方法,获取到响应数据之后进行修改再返回;
"""
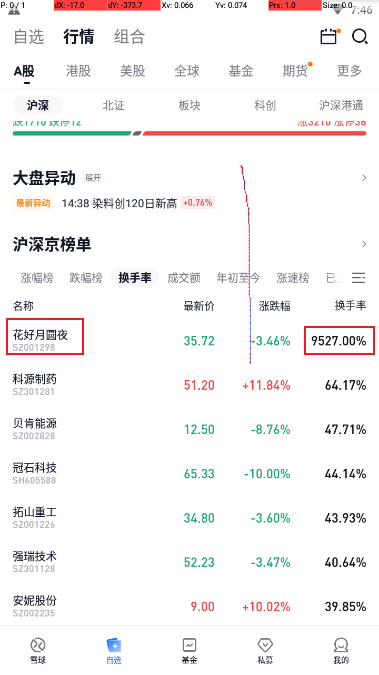
需求:对雪球行情页股票名称和换手率数据进行修改
"""
import json
from mitmproxy.http import HTTPFlow
def response(flow: HTTPFlow):
if "https://stock.xueqiu.com/v5/stock/screener/quote/list.json" in flow.request.pretty_url:
print("响应内容:", flow.response.content)# 类容是bytes类型
content = json.loads(flow.response.content)
print("content====",content)
# 从响应内容中获取第一支股票数据
items_1 = content["data"]["list"][0]
# 股票名称
items_1["name"] = "花好月圆夜"
# 换手率
items_1["turnover_rate"] = 9527
# 响应的数据是bytes类型,所以mock数据之后需要把数据转成bytes类型
# 注意:这里返回的变量不再是content,而是text
flow.response.text = json.dumps(content)
7、Pydantic
(1)pydantic介绍
Pydantic 是一个使用Python类型注解进行数据验证和管理的模块。
pip install pydantic
它类似于 Django DRF 序列化器的数据校验功能,不同的是,Django里的序列化器的Field是有限制的,如果你想要使用自己的Field还需要继承并重写它的基类:
# Django 序列化器
class Book(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
author = models.CharField(max_length=32)
publish = models.CharField(max_length=32)
而 Pydantic 基于Python3.7以上的类型注解特性,实现了可以对任何类做数据校验的功能:
# Pydantic 数据校验功能
from datetime import datetime
from typing import List, Optional
from pydantic import BaseModel
class User(BaseModel):
id: int
name = 'John Doe'
signup_ts: Optional[datetime] = None
friends: List[int] = []
external_data = {
'id': '123',
'signup_ts': '2019-06-01 12:22',
'friends': [1, 2, '3'],
}
user = User(**external_data)
print(user.id)
print(type(user.id))
#> 123
#> <class 'int'>
print(repr(user.signup_ts))
#> datetime.datetime(2019, 6, 1, 12, 22)
print(user.friends)
#> [1, 2, 3]
print(user.dict())
"""
{
'id': 123,
'signup_ts': datetime.datetime(2019, 6, 1, 12, 22),
'friends': [1, 2, 3],
'name': 'John Doe',
}
"""
从上面的基本使用可以看到,它甚至能自动帮你做数据类型的转换,比如代码中的 user.id, 在字典中是字符串,但经过Pydantic校验器后,它自动变成了int型,因为User类里的注解就是int型。
当我们的数据和定义的注解类型不一致时会报这样的Error:
from datetime import datetime
from typing import List, Optional
from pydantic import BaseModel
class User(BaseModel):
id: int
name = 'John Doe'
signup_ts: Optional[datetime] = None
friends: List[int] = []
external_data = {
'id': '123',
'signup_ts': '2019-06-01 12:222',
'friends': [1, 2, '3'],
}
user = User(**external_data)
"""
Traceback (most recent call last):
File "1.py", line 18, in <module>
user = User(**external_data)
File "pydantic\main.py", line 331, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for User
signup_ts
invalid datetime format (type=value_error.datetime)
"""
即 “invalid datetime format”, 因为我传入的 signup_ts 不是标准的时间格式(多了个2)。
(2)Pydantic 模型数据导出
通过Pydantic模型中自带的 json 属性方法,能让经过校验后的数据一行命令直接转成 json 字符串,如前文中的user对象:
print(user.dict()) # 转为字典
"""
{
'id': 123,
'signup_ts': datetime.datetime(2019, 6, 1, 12, 22),
'friends': [1, 2, 3],
'name': 'John Doe',
}
"""
print(user.json()) # 转为json
"""
{"id": 123, "signup_ts": "2019-06-01T12:22:00", "friends": [1, 2, 3], "name": "John Doe"}
"""
非常方便。它还支持将整个数据结构导出为 schema json,它能完整地描述整个对象的数据结构类型:
print(user.schema_json(indent=2))
"""
{
"title": "User",
"type": "object",
"properties": {
"id": {
"title": "Id",
"type": "integer"
},
"signup_ts": {
"title": "Signup Ts",
"type": "string",
"format": "date-time"
},
"friends": {
"title": "Friends",
"default": [],
"type": "array",
"items": {
"type": "integer"
}
},
"name": {
"title": "Name",
"default": "John Doe",
"type": "string"
}
},
"required": [
"id"
]
}
"""
(3)数据导入
除了直接定义数据校验模型,它还能通过ORM、字符串、文件导入到数据校验模型:
- 比如字符串(raw):
from datetime import datetime
from pydantic import BaseModel
class User(BaseModel):
id: int
name = 'John Doe'
signup_ts: datetime = None
m = User.parse_raw('{"id": 123, "name": "James"}')
print(m)
#> id=123 signup_ts=None name='James'
- 此外,它能直接将ORM的对象输入,转为Pydantic的对象,比如从Sqlalchemy ORM:
from typing import List
from sqlalchemy import Column, Integer, String
from sqlalchemy.dialects.postgresql import ARRAY
from sqlalchemy.ext.declarative import declarative_base
from pydantic import BaseModel, constr
Base = declarative_base()
class CompanyOrm(Base):
__tablename__ = 'companies'
id = Column(Integer, primary_key=True, nullable=False)
public_key = Column(String(20), index=True, nullable=False, unique=True)
name = Column(String(63), unique=True)
domains = Column(ARRAY(String(255)))
class CompanyModel(BaseModel):
id: int
public_key: constr(max_length=20)
name: constr(max_length=63)
domains: List[constr(max_length=255)]
class Config:
orm_mode = True
co_orm = CompanyOrm(
id=123,
public_key='foobar',
name='Testing',
domains=['example.com', 'foobar.com'],
)
print(co_orm)
#> <models_orm_mode.CompanyOrm object at 0x7f0bdac44850>
co_model = CompanyModel.from_orm(co_orm)
print(co_model)
#> id=123 public_key='foobar' name='Testing' domains=['example.com',
#> 'foobar.com']
- 从Json文件导入:
from datetime import datetime
from pathlib import Path
from pydantic import BaseModel
class User(BaseModel):
id: int
name = 'John Doe'
signup_ts: datetime = None
path = Path('data.json')
path.write_text('{"id": 123, "name": "James"}')
m = User.parse_file(path)
print(m)
- 从pickle导入:
import pickle
from datetime import datetime
from pydantic import BaseModel
pickle_data = pickle.dumps({
'id': 123,
'name': 'James',
'signup_ts': datetime(2017, 7, 14)
})
m = User.parse_raw(
pickle_data, content_type='application/pickle', allow_pickle=True
)
print(m)
#> id=123 signup_ts=datetime.datetime(2017, 7, 14, 0, 0) name='James'
(4)自定义数据校验
你还能给它增加 validator 装饰器,增加你需要的校验逻辑:
from pydantic import BaseModel, ValidationError, validator
class UserModel(BaseModel):
name: str
username: str
password1: str
password2: str
@validator('name')
def name_must_contain_space(cls, v):
if ' ' not in v:
raise ValueError('must contain a space')
return v.title()
@validator('password2')
def passwords_match(cls, v, values, **kwargs):
if 'password1' in values and v != values['password1']:
raise ValueError('passwords do not match')
return v
@validator('username')
def username_alphanumeric(cls, v):
assert v.isalnum(), 'must be alphanumeric'
return v
上面,我们增加了三种自定义校验逻辑:
1.name 必须带有空格
2.password2 必须和 password1 相同
3.username 必须为字母
让我们试试这三个校验是否成功实现:
user = UserModel(
name='samuel colvin',
username='scolvin',
password1='zxcvbn',
password2='zxcvbn',
)
print(user)
#> name='Samuel Colvin' username='scolvin' password1='zxcvbn' password2='zxcvbn'
try:
UserModel(
name='samuel',
username='scolvin',
password1='zxcvbn',
password2='zxcvbn2',
)
except ValidationError as e:
print(e)
"""
2 validation errors for UserModel
name
must contain a space (type=value_error)
password2
passwords do not match (type=value_error)
"""
可以看到,第一个UserModel里的数据完全没有问题,通过校验。
第二个UserModel里的数据,由于name存在空格,password2和password1不一致,无法通过校验。
(5)性能表现
Pydantic 比 Django-rest-framework 还快了12.3倍:
| Package | Version | Relative Performance | Mean validation time |
|---|---|---|---|
| pydantic | 1.7.3 | 93.7μs | |
| attrs + cattrs | 20.3.0 | 1.5x slower | 143.6μs |
| valideer | 0.4.2 | 1.9x slower | 175.9μs |
| marshmallow | 3.10.0 | 2.4x slower | 227.6μs |
| voluptuous | 0.12.1 | 2.7x slower | 257.5μs |
| trafaret | 2.1.0 | 3.2x slower | 296.7μs |
| schematics | 2.1.0 | 10.2x slower | 955.5μs |
| django-rest-framework | 3.12.2 | 12.3x slower | 1148.4μs |
| cerberus | 1.3.2 | 25.9x slower | 2427.6μs |
