字典的定义
Python 中使用花括号,保存key-value形式表示字典。
key-value 中的 key 必须是一个可哈希的对象,可以使用 hash() 函数来判断数据是否可哈希。 简单理解在一次程序运行结束前,无论该数据什么时候执行hash()函数,都能得到一个唯一确定的值。 一般情况下,不可变对象数据,都可以得到一个哈希值。 所以,理论上,pyhton中的不可变对象数据都可以做为key使用。 但是,为了方便使用,大多数情况下,都会使用字符串类型数据做为key使用。
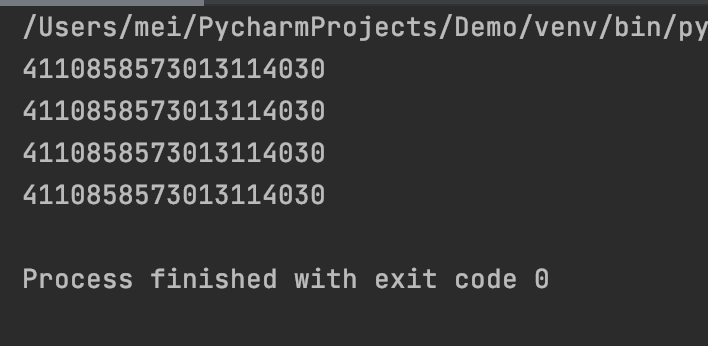
# 在一次程序运行过程中,hash函数得会得到同一个哈希值
print(hash("ab"))
print(hash("ab"))
print(hash("ab"))
def myhash():
print(hash("ab"))
myhash()
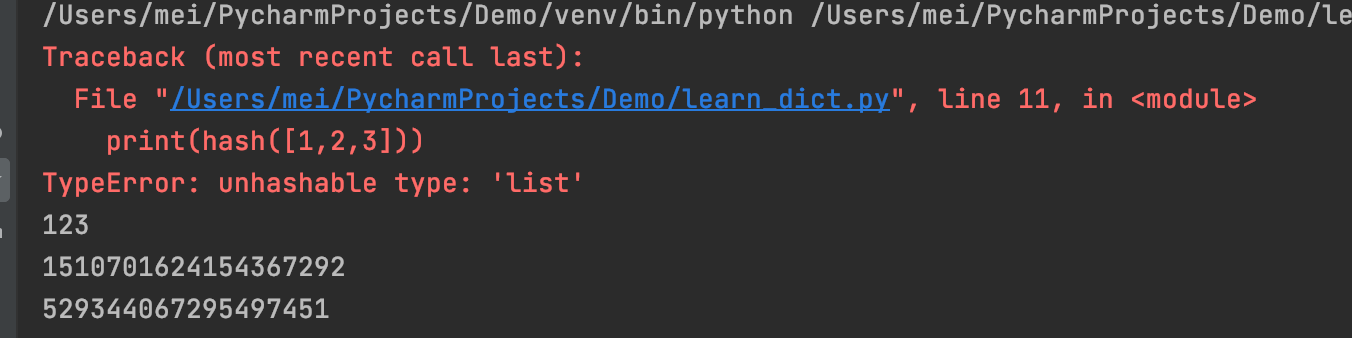
# 可哈希数据:不可变
print(hash(123))
print(hash("abc"))
print(hash((1,2,3)))
# 不可哈希数据:可变
print(hash([1,2,3]))
print(hash((1,2,[3])))
字典的创建
字面量定义字典
def dict_info():
d1 = {}
print(type(d1), d1)
d2 = {"name": "Alice", "age": 25, "gender": True, "hobby": ["eat", "drink", "play", "hahahah"]}
print(type(d2), d2)
dict_info()

构造方法定义字典
Python 中使用构造方法定义字典的形式很多,了解即可
d1 = dict(one=1, two=2, three=3)
d2 = dict([('two', 2), ('one', 1), ('three', 3)])
d3 = dict((('two', 2), ('one', 1), ('three', 3)))
d4 = dict([('two', 2), ['one', 1], ('three', 3)])
d5 = dict({'one': 1, 'two': 2, 'three': 3})
d6 = dict({'one': 1, 'three': 3}, two=2)
keys = ['one', 'two', 'three']
values = (1, 2, 3)
d7 = dict(zip(keys, values))
print(d1)
print(d2)
print(d3)
print(d4)
print(d5)
print(d6)
print(d7)

字典数据访问
字典类型没有类似元组,列表那样的数字下标索引。字典使用 key 来获取对应的值,使用 key的方式同下标索引一样,也使用中括号的方式,将元组,列表中的数字下标索引替换为key。 可以简单将key理解成为自定义的下标索引。
格式:字典对象[key]
字典元素添加与修改
字典中的每一个元素都以键值对形式表示,一个key对应一个value, 在一个字典中,key具有唯一性,当给一个key赋值时,如果key在当前字典中不存在,则是添加数据,如果key存在,则对当前key所对应的值进行修改更新。
格式: 字典对象[key] = value
stu = {"name":"Tom", "age": 23, "gender":"male"}
print(stu["name"])
print(stu["age"])
k = "gender"
print(stu[k])
# 字典修改
stu["name"] = "zhizhi"
stu["age"] = 28
stu["gender"] = "female"
print(stu)
# 字典添加
stu["pet"] = "cat"
print(stu)

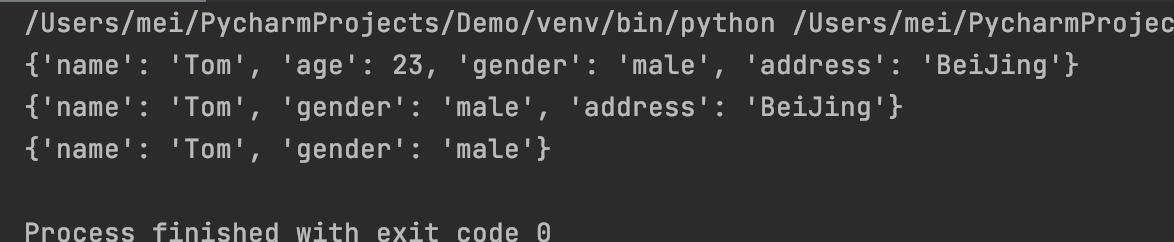
字典元素的删除
字典也可以使用 del 通过key删除元素,当删除元素时,整个键值对都会被删除。
格式:del 字典对象[key]
stu = {'name': 'Tom', 'age': 23, 'gender': 'male', 'address': 'BeiJing'}
print(stu)
# 删除元素
del stu['age']
print(stu)
del stu['address']
print(stu)
字典数据获取类操作
-
keys()用来获取字典中所有的 key, 保存到一个列表中,并以dict_keys类型返回 -
values()用来获取字典中所有的value, 保存到一个列表中,并以dict_values类型返回 -
items()用来获取字典中所有的键值对,每一个元素键值对都以一个元组保存,将所有元素元组保存到一个列表中,并以dict_items类型返回 -
get(key, default)用来获取key对应的值,如果指定的key不存在,则返回默认值。字典可以使用字典对象[key]的形式获取键值对,但是该方法如果指定的 key 不存在,程序会抛出一个错误。此时可以使用get()替代该取值方法
stu = {'name': 'Tom', 'age': 23, 'gender': 'male', 'address': 'BeiJing'}
ks = stu.keys()
vs = stu.values()
its = stu.items()
print(type(ks), ks)
print(type(vs), vs)
print(type(its), its)
# print(stu["name"])
# print(stu["hobby"])
print(stu.get("name"))
print(stu.get("hobby"))
print(stu.get("hobby","无数据"))

字典添加更新类操作
-
setdefault(key,default)给一个不存在的key添加一个默认值并将该键值对保存到字典中。在一些场景下,字典的key存在,但是该key却没有对应的值,此时,就可以使用该方法,为当前的key添加一个默认值。比如服务端要保存客户端发起请求时携带的请求头中的信息。
stu = {'name': 'Tom', 'age': 23, 'gender': 'male', 'address': 'BeiJing'}
stu.setdefault("hobby1")
print(stu)
stu.setdefault("hobby2", "无")
print(stu)

-
fromkeys(keys,val)用于创建一个新字典,以序列 keys 中元素做字典的键,value 为字典所有键对应的初始值,默认为None。该方法是一个静态方法,需要使用字典类型名dict调用。 该方法如果给给定 keys 参数,则所有的key对应值都为默认值None,如果给定 val值,则所有key对应的值为 val。
ks = ("name", "age", "gender")
s1 = dict.fromkeys(ks)
print(s1)
s2 = dict.fromkeys(ks,"无")
print(s2)

-
update(d/iterable)使用参数中的数据更新当前字典。该方法的参数可以接收一个字典(大多数的使用方式),也可以接收一个可迭代对象,如果参数数据中的key在当前字典中存在,则使用新值更新字典中的键值对,如果参数数据中的key在当前字内中不存在,则将键值对添加到当前字典中。
# 更新目标数据是一个字典
stu = {'name': 'Tom', 'age': 23, 'gender': 'male', 'address': 'BeiJing'}
newStu = {"name":"Jack","hobby":"eat"}
stu.update(newStu)
print(stu)
# 更新目标数据是一个可迭代对象
stu = {'name': 'Tom', 'age': 23, 'gender': 'male', 'address': 'BeiJing'}
newStu = (("name","Rose"),["hobby","play"])
stu.update(newStu)
print(stu)

字典删除类操作
-
popitem()用来获取并删除字典中的最后一个键值对,返回一个元组,如果字典为空时,则抛出一个错误
stu = {'name': 'Tom', 'age': 23, 'gender': 'male', 'address': 'BeiJing'}
v = stu.popitem()
print(v)
print(stu)
v = stu.popitem()
print(v)
print(stu)
print({}.popitem())

-
pop(key)用于获取并删除字典中指定key对应的键值对。如果指定的key不存在,则抛出错误
stu = {'name': 'Tom', 'age': 23, 'gender': 'male', 'address': 'BeiJing'}
v = stu.pop("name")
print(v)
print(stu)

-
clear()清空字典中所有的键值对元素
stu = {'name': 'Tom', 'age': 23, 'gender': 'male', 'address': 'BeiJing'}
print(stu)
stu.clear()
print(stu)

字典的有序性(Python 3.7+)
在Python 3.7及更高版本中,字典被认为是有序的,即它们可以保持键值对的添加顺序。这意味着当遍历字典或打印字典时,键值对的顺序与它们添加到字典中的顺序相同。这种有序性是字典的内置特性,不需要额外的操作。
然而,在Python 3.6及更早版本中,字典是无序的,无法保持键值对的顺序。这意味着当遍历字典或打印字典时,键值对的顺序是不确定的,可能与它们添加到字典中的顺序不同。
因此,如果在编程中需要依赖字典键值对的顺序,建议使用Python 3.7及更高版本以确保有序性。如果使用旧版本的Python,可以考虑使用collections.OrderedDict来实现有序字典的功能。
字典的应用场景
- 字典适用于存储具有相关性的数据,如用户信息、学生成绩等。每个键值对表示一个独立的数据项,通过键来关联对应的值。
- 字典提供了快速查找和访问数据的能力,通过键可以直接定位对应的值,而不需要遍历整个字典。这使得字典在需要根据特定键快速获取对应值的场景下非常有用。
- 字典作为数据的容器,提供了丰富的操作方法,可以方便地进行遍历、搜索、插入和删除操作。可以通过循环遍历字典的键或值,通过键进行搜索和更新数据,通过键值对的添加和删除来动态修改字典的内容。这种灵活性使得字典成为处理各种数据结构的重要工具。
集合
集合的定义
- 集合是一种数据类型,用于存储多个元素,并确保元素的唯一性。
- 集合中的元素是无序的,不可通过索引或切片进行访问。
- 集合的主要特点是元素不重复,相同的元素在集合中只会出现一次。
- 我们可以使用大括号 {} 或 set() 函数来定义和创建集合。
- 集合提供了各种集合运算,如并集(两个集合中的所有元素)、交集(两个集合中共有的元素)、差集(第一个集合中存在而第二个集合中不存在的元素)等操作。
创建集合
1、使用大括号填充元素
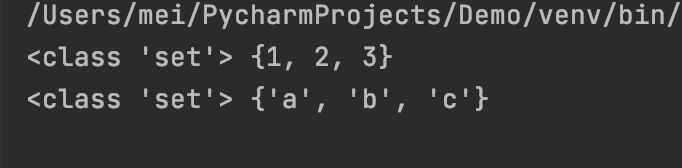
st4 = {1, 2, 3}
print(type(st4), st4)
st5 = {'a', 'b', 'c'}
print(type(st5), st5)
2、使用构造方法创建集合,集合元素具有唯一性
st1 = set()
st2 = set('hogwarts')
print(st1)
print(type(st2), st2)
li = [1, 1, 2, 2, 3, 3]
st3 = set(li)
print(type(st3), st3)

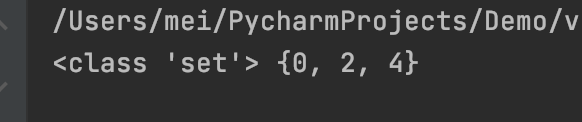
3、使用集合推导式
st6 = {x for x in range(6) if x % 2 == 0}
print(type(st6), st6)
注意:不要单独使用{}来创建空集合,{}是空字典
集合常见的用途包括成员检测、从序列中去除重复项以及数学中的集合类计算,例如交集、并集、差集与对称差集等等。
由于集合不支持下标操作,所以不支持常规方式的获取和修改。
添加操作
-
add(ele)向集合中添加一个元素,如果元素则不产生任何影响
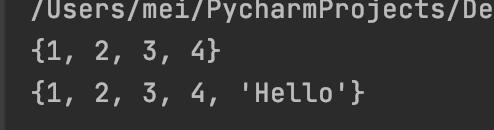
s = {1, 2, 3}
s.add(4)
print(s)
s.add("Hello")
s.add("Hello") # 添加重复数据不会再添加
print(s)
-
update(others)更新集合,添加来自 others 中的所有元素,others是一个可迭代对象,如果数据在集合中存在则不更新。
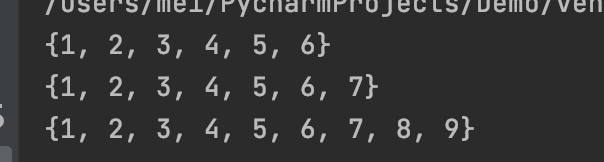
s = {1, 2, 3}
s.update((4,5,6))
print(s)
s.update([5,6,7])
print(s)
s.update({6,7,8,9})
print(s)
删除操作
-
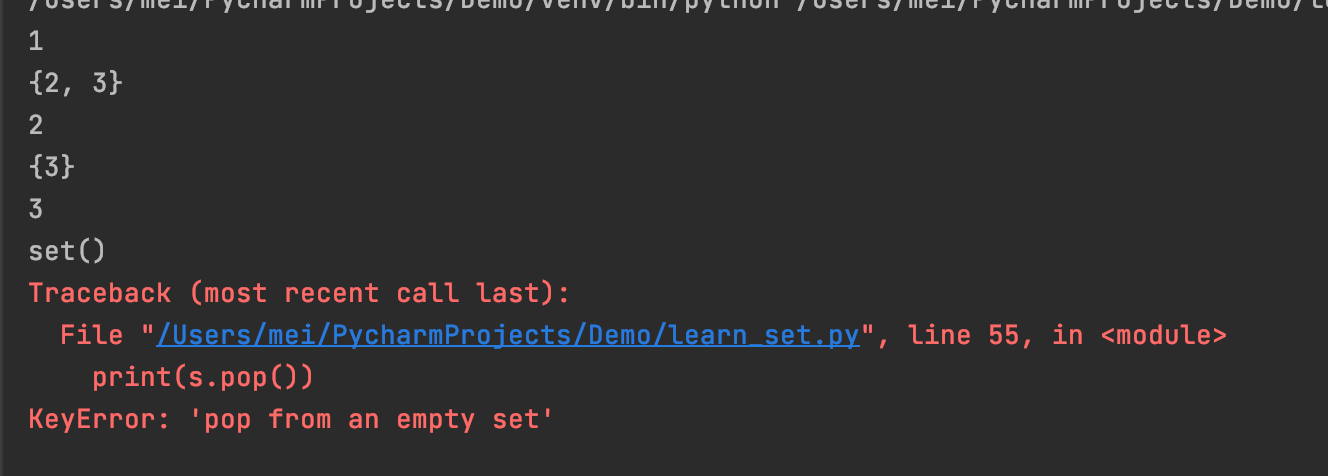
pop()从集合中移除并返回任意一个元素,如果集合为空,则抛出错误
s = {1, 2, 3}
print(s.pop())
print(s)
print(s.pop())
print(s)
print(s.pop())
print(s)
print(s.pop())
-
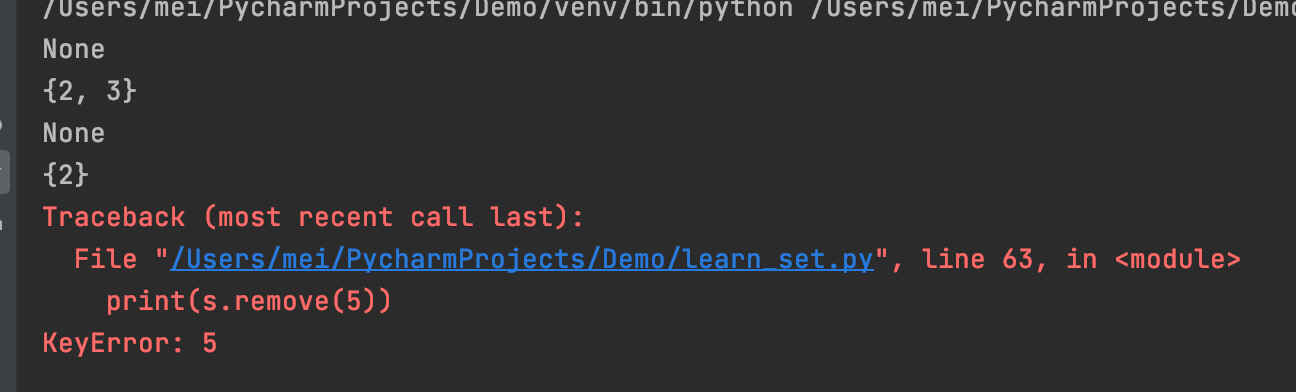
remove(elem)从集合中移除元素 elem。 如果 elem 不存在于集合中则抛出错误。
s = {1, 2, 3}
print(s.remove(1))
print(s)
print(s.remove(3))
print(s)
print(s.remove(5))
-
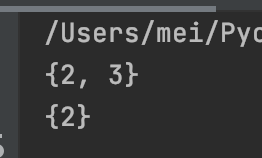
discard(elem)如果元素 elem 存在于集合中则将其移除,如果elem不存在,则什么也不做
s = {1, 2, 3}
s.discard(1)
print(s)
s.discard(3)
print(s)
s.discard(5)
-
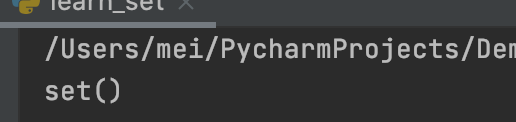
clear()清空集合
s = {1, 2, 3}
s.clear()
print(s)
集合数据操作
判断两个集合是否不相交
-
isdisjoint(other)如果集合中没有与 other 共有的元素则返回 True。 当且仅当两个集合的交集为空集合时,两者为不相交集合。
s = {1, 2, 3}
print(s.isdisjoint({4, 5, 6}))
print(s.isdisjoint({3, 4, 5}))
判断集合是否是另一个集合的子集
-
issubset(other)检测是否集合中的每个元素都在 other 之中。
s = {1, 2, 3}
# 判断 s 是否为 other参数的子集
print(s.issubset({1, 2, 3}))
print(s.issubset({1, 2, 3, 4}))
print(s.issubset({3, 4, 5}))
print("*" * 10)
# 也可以通过运算符 <= 直接判断
print(s <= {1, 2, 3})
print(s <= {1, 2, 3, 4})
print(s <= {3, 4, 5})
print("*" * 10)
# 判断是否为真子集
print(s < {1, 2, 3})
print(s < {1, 2, 3, 4})
print(s < {3, 4, 5})
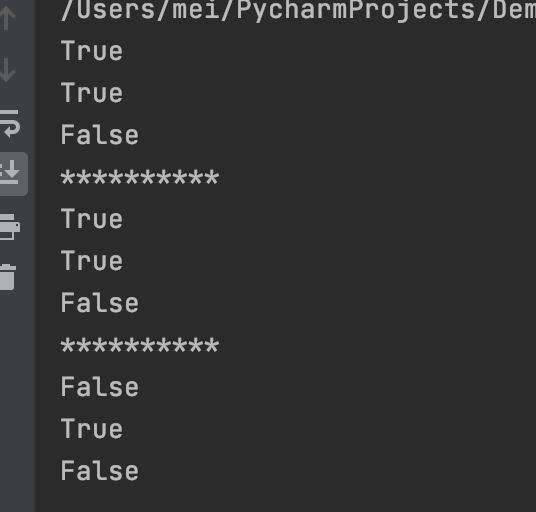
判断集合是否是另一个集合的超集
-
issuperset(other)检测是否 other 中的每个元素都在集合之中。
s = {1, 2, 3, 4}
# 判断 s 是否为 other参数的超集
print(s.issuperset({1, 2, 3}))
print(s.issuperset({1, 2, 3, 4}))
print(s.issuperset({3, 4, 5}))
print("*" * 10)
# 也可以通过运算符 >= 直接判断
print(s >= {1, 2, 3})
print(s >= {1, 2, 3, 4})
print(s >= {3, 4, 5})
print("*" * 10)
# 判断是否为真超集
print(s > {1, 2, 3})
print(s > {1, 2, 3, 4})
print(s > {3, 4, 5})
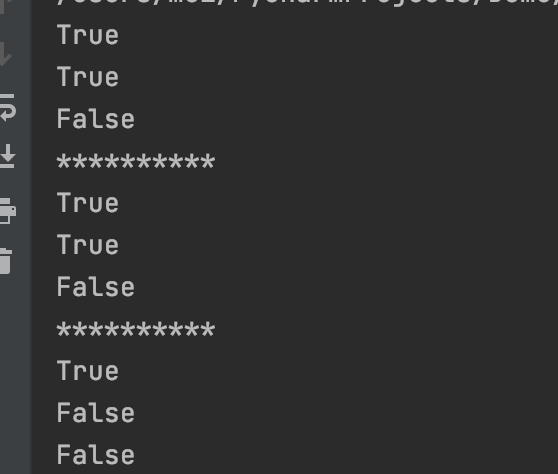
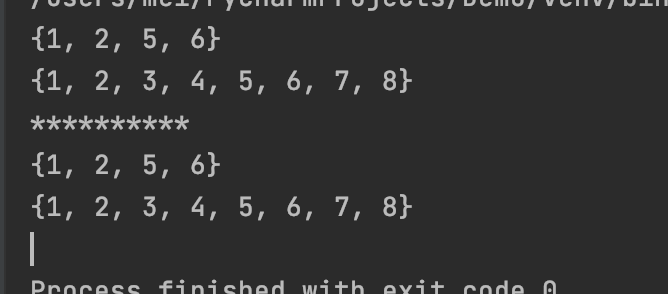
并集
-
union(*other)返回一个新集合,其中包含来自原集合以及 others 指定的所有集合中的元素,other可以指定多个集合。
s1 = {1, 2, 3, 4}
s2 = {3, 4, 5, 6}
s3 = {5, 6, 7, 8}
print(s1.union(s2))
print(s1.union(s2,s3))
# 也可以使用 | 进行集合并集运算
print(s1 | s2)
print(s1 | s2 | s3)
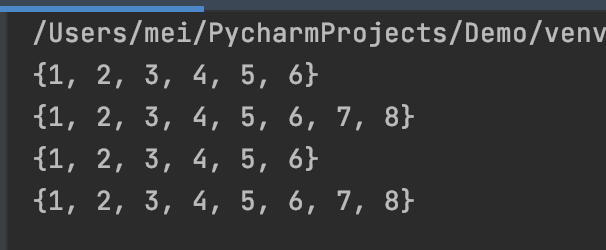
交集
-
intersection(*others)返回一个新集合,其中包含原集合以及 others 指定的所有集合中共有的元素。
s1 = {1, 2, 3, 4}
s2 = {3, 4, 5, 6}
s3 = {5, 6, 7, 8}
print(s1.intersection(s2))
print(s1.intersection(s2, s3))
print(s1.intersection(s3))
print("*" * 10)
# 也可以使用 & 进行集合交集运算
print(s1 & s2)
print(s1 & s2 & s3)
print(s1 & s3)
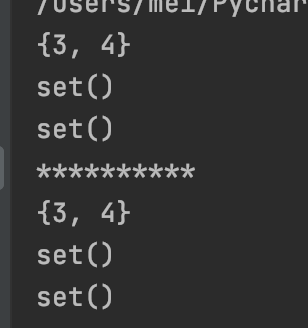
差集
-
difference(*others)返回一个新集合,包含原集合中在 others 指定的其他集合中不存在的元素。
s1 = {1, 2, 3, 4}
s2 = {3, 4, 5, 6}
s3 = {5, 6, 7, 8}
print(s1.difference(s2))
print(s1.difference(s2, s3))
print(s1.difference(s3))
print("*" * 10)
# 也可以使用 - 进行集合差集运算
print(s1 - s2)
print(s1 - s2 - s3)
print(s1 - s3)
对称差集
-
symmetric_difference(other)返回一个新集合,其中的元素或属于原集合或属于 other 指定的其他集合,但不能同时属于两者。
s1 = {1, 2, 3, 4}
s2 = {3, 4, 5, 6}
s3 = {5, 6, 7, 8}
print(s1.symmetric_difference(s2))
print(s1.symmetric_difference(s3))
print("*" * 10)
# 也可以使用 ^ 进行集合对称差集运算
print(s1 ^ s2)
print(s1 ^ s3)