我查我的机器device manager显示的好像有nvidia的显卡

然后不太了解 cuda是需要 我自己安装的吗?
然后是不是 才可以用这个模式跑?
我查我的机器device manager显示的好像有nvidia的显卡
然后不太了解 cuda是需要 我自己安装的吗?
然后是不是 才可以用这个模式跑?
C:\Windows\System32\DriverStore\FileRepository\nvdm*\nvidia-smi.exe 中间nvdm*表示不同的显卡驱动版本,可以自己近似匹配一下我获取到下面的信息
Mon Sep 25 12:17:02 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 528.79 Driver Version: 528.79 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Quadro T2000 WDDM | 00000000:01:00.0 Off | N/A |
| N/A 67C P8 7W / 20W | 0MiB / 4096MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
然后需要怎么做?
CUDA Version: 12.0
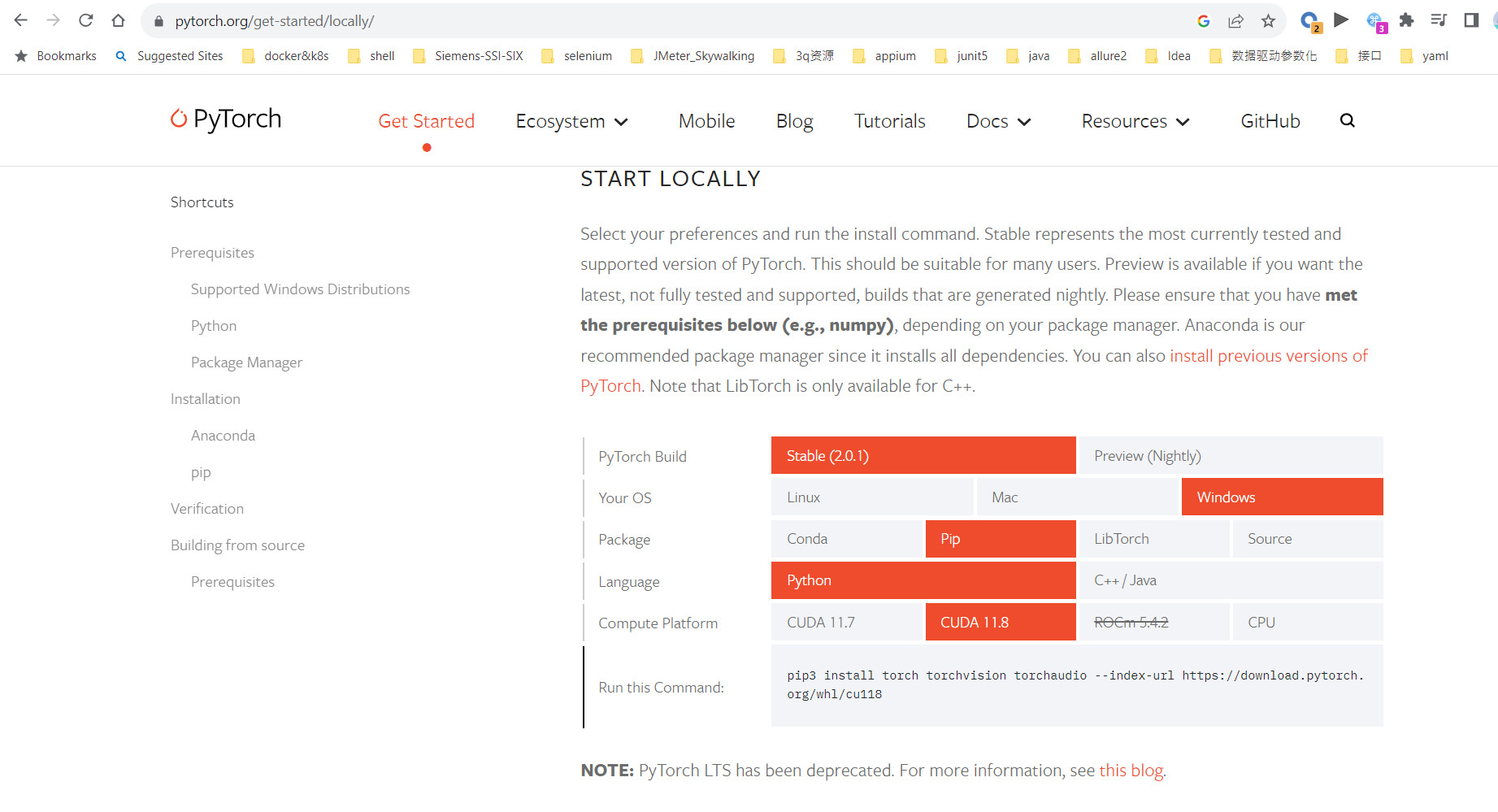
最起码12和12之前的CUDA都可以支持,可以去安装11.7 或者 11.8的CUDA,然后安装对应版本的pytoch
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
要先保证你的CUDA是安装好了的
可以去nvidia官网找到符合版本的cuda-toolkit下载,安装
之后再去装对应的pytorch
尝试装了 cuda_11.8.0_522.06_windows.exe
然后 pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 (pytorch Stable (2.0.1))
代码测试的时候用的
model.half().cuda()
结果出错
D:\rgzn_source_code\ai_testing\venv\Scripts\python.exe "D:/dev_tool/JetBrains/PyCharm Community Edition 2023.2.1/plugins/python-ce/helpers/pycharm/_jb_pytest_runner.py" --target test_hugging_face.py::test_chatglm
Testing started at 9:49 PM ...
Launching pytest with arguments test_hugging_face.py::test_chatglm --no-header --no-summary -q in D:\rgzn_source_code\ai_testing\tests\chatglm
============================= test session starts =============================
collecting ... collected 1 item
test_hugging_face.py::test_chatglm
======================== 1 failed, 1 warning in 38.52s ========================
-------------------------------- live log call --------------------------------
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:1048 21:49:34 DEBUG - Starting new HTTPS connection (1): huggingface.co:443
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 21:49:37 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/tokenizer_config.json HTTP/1.1" 200 0
Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 21:49:37 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/tokenization_chatglm.py HTTP/1.1" 200 0
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 21:49:41 DEBUG - https://huggingface.co:443 "GET /api/models/THUDM/chatglm2-6b HTTP/1.1" 200 5947
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 21:49:41 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/config.json HTTP/1.1" 200 0
Explicitly passing a `revision` is encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision.
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 21:49:42 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/configuration_chatglm.py HTTP/1.1" 200 0
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 21:49:44 DEBUG - https://huggingface.co:443 "GET /api/models/THUDM/chatglm2-6b HTTP/1.1" 200 5947
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 21:49:46 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/config.json HTTP/1.1" 200 0
Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 21:49:46 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/modeling_chatglm.py HTTP/1.1" 200 0
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 21:49:47 DEBUG - https://huggingface.co:443 "GET /api/models/THUDM/chatglm2-6b HTTP/1.1" 200 5947
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 21:49:47 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/configuration_chatglm.py HTTP/1.1" 200 0
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 21:49:48 DEBUG - https://huggingface.co:443 "GET /api/models/THUDM/chatglm2-6b HTTP/1.1" 200 5947
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 21:49:48 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/quantization.py HTTP/1.1" 200 0
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 21:49:51 DEBUG - https://huggingface.co:443 "GET /api/models/THUDM/chatglm2-6b HTTP/1.1" 200 5947
Loading checkpoint shards: 100%|██████████| 7/7 [00:19<00:00, 2.73s/it]
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 21:50:10 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/generation_config.json HTTP/1.1" 404 0
FAILED
chatglm\test_hugging_face.py:8 (test_chatglm)
def test_chatglm():
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
# debug(model)
# cuda + nvidia gpu
> model.half().cuda()
test_hugging_face.py:14:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
..\..\venv\lib\site-packages\torch\nn\modules\module.py:905: in cuda
return self._apply(lambda t: t.cuda(device))
..\..\venv\lib\site-packages\torch\nn\modules\module.py:797: in _apply
module._apply(fn)
..\..\venv\lib\site-packages\torch\nn\modules\module.py:797: in _apply
module._apply(fn)
..\..\venv\lib\site-packages\torch\nn\modules\module.py:797: in _apply
module._apply(fn)
..\..\venv\lib\site-packages\torch\nn\modules\module.py:820: in _apply
param_applied = fn(param)
..\..\venv\lib\site-packages\torch\nn\modules\module.py:905: in <lambda>
return self._apply(lambda t: t.cuda(device))
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
def _lazy_init():
global _initialized, _queued_calls
if is_initialized() or hasattr(_tls, 'is_initializing'):
return
with _initialization_lock:
# We be double-checked locking, boys! This is OK because
# the above test was GIL protected anyway. The inner test
# is for when a thread blocked on some other thread which was
# doing the initialization; when they get the lock, they will
# find there is nothing left to do.
if is_initialized():
return
# It is important to prevent other threads from entering _lazy_init
# immediately, while we are still guaranteed to have the GIL, because some
# of the C calls we make below will release the GIL
if _is_in_bad_fork():
raise RuntimeError(
"Cannot re-initialize CUDA in forked subprocess. To use CUDA with "
"multiprocessing, you must use the 'spawn' start method")
if not hasattr(torch._C, '_cuda_getDeviceCount'):
> raise AssertionError("Torch not compiled with CUDA enabled")
E AssertionError: Torch not compiled with CUDA enabled
..\..\venv\lib\site-packages\torch\cuda\__init__.py:239: AssertionError
Process finished with exit code 1
上面的问题 卸载了最新的版本 用的2.0.0解决了
pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 torchaudio==2.0.1 --index-url https://download.pytorch.org/whl/cu118
再运行有OutOfMemory的错 应该我是没办法继续用这个模式了 只能用CPU的方式了吧?
D:\rgzn_source_code\ai_testing\venv\Scripts\python.exe "D:/dev_tool/JetBrains/PyCharm Community Edition 2023.2.1/plugins/python-ce/helpers/pycharm/_jb_pytest_runner.py" --path D:\rgzn_source_code\ai_testing\src\tests\chatglm\test_hugging_face.py
Testing started at 12:03 AM ...
Launching pytest with arguments D:\rgzn_source_code\ai_testing\src\tests\chatglm\test_hugging_face.py --no-header --no-summary -q in D:\rgzn_source_code\ai_testing\src\tests\chatglm
============================= test session starts =============================
collecting ... collected 1 item
test_hugging_face.py::test_chatglm
======================== 1 failed, 1 warning in 43.64s ========================
-------------------------------- live log call --------------------------------
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:1048 00:03:34 DEBUG - Starting new HTTPS connection (1): huggingface.co:443
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 00:03:38 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/tokenizer_config.json HTTP/1.1" 200 0
Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 00:03:38 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/tokenization_chatglm.py HTTP/1.1" 200 0
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 00:03:42 DEBUG - https://huggingface.co:443 "GET /api/models/THUDM/chatglm2-6b HTTP/1.1" 200 5947
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 00:03:43 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/config.json HTTP/1.1" 200 0
Explicitly passing a `revision` is encouraged when loading a configuration with custom code to ensure no malicious code has been contributed in a newer revision.
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 00:03:43 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/configuration_chatglm.py HTTP/1.1" 200 0
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 00:03:44 DEBUG - https://huggingface.co:443 "GET /api/models/THUDM/chatglm2-6b HTTP/1.1" 200 5947
Explicitly passing a `revision` is encouraged when loading a model with custom code to ensure no malicious code has been contributed in a newer revision.
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 00:03:46 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/config.json HTTP/1.1" 200 0
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 00:03:46 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/modeling_chatglm.py HTTP/1.1" 200 0
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 00:03:47 DEBUG - https://huggingface.co:443 "GET /api/models/THUDM/chatglm2-6b HTTP/1.1" 200 5947
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 00:03:47 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/quantization.py HTTP/1.1" 200 0
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 00:03:50 DEBUG - https://huggingface.co:443 "GET /api/models/THUDM/chatglm2-6b HTTP/1.1" 200 5947
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 00:03:51 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/configuration_chatglm.py HTTP/1.1" 200 0
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 00:03:51 DEBUG - https://huggingface.co:443 "GET /api/models/THUDM/chatglm2-6b HTTP/1.1" 200 5947
Loading checkpoint shards: 100%|██████████| 7/7 [00:18<00:00, 2.66s/it]
D:\rgzn_source_code\ai_testing\venv\lib\site-packages\urllib3\connectionpool.py:546 00:04:11 DEBUG - https://huggingface.co:443 "HEAD /THUDM/chatglm2-6b/resolve/main/generation_config.json HTTP/1.1" 404 0
FAILED
chatglm\test_hugging_face.py:8 (test_chatglm)
def test_chatglm():
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
# debug(model)
# cuda + nvidia gpu
> model.half().cuda()
test_hugging_face.py:14:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
..\..\..\venv\lib\site-packages\torch\nn\modules\module.py:905: in cuda
return self._apply(lambda t: t.cuda(device))
..\..\..\venv\lib\site-packages\torch\nn\modules\module.py:797: in _apply
module._apply(fn)
..\..\..\venv\lib\site-packages\torch\nn\modules\module.py:797: in _apply
module._apply(fn)
..\..\..\venv\lib\site-packages\torch\nn\modules\module.py:797: in _apply
module._apply(fn)
..\..\..\venv\lib\site-packages\torch\nn\modules\module.py:797: in _apply
module._apply(fn)
..\..\..\venv\lib\site-packages\torch\nn\modules\module.py:797: in _apply
module._apply(fn)
..\..\..\venv\lib\site-packages\torch\nn\modules\module.py:797: in _apply
module._apply(fn)
..\..\..\venv\lib\site-packages\torch\nn\modules\module.py:820: in _apply
param_applied = fn(param)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
t = Parameter containing:
tensor([[ 0.0055, -0.0108, 0.0022, ..., 0.0097, 0.0121, -0.0108],
[ 0.0172, 0.0019,...
[ 0.0095, -0.0236, 0.0022, ..., 0.0035, 0.0276, -0.0058]],
dtype=torch.float16, requires_grad=True)
> return self._apply(lambda t: t.cuda(device))
E torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 108.00 MiB (GPU 0; 4.00 GiB total capacity; 3.44 GiB already allocated; 0 bytes free; 3.44 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
..\..\..\venv\lib\site-packages\torch\nn\modules\module.py:905: OutOfMemoryError
Process finished with exit code 1