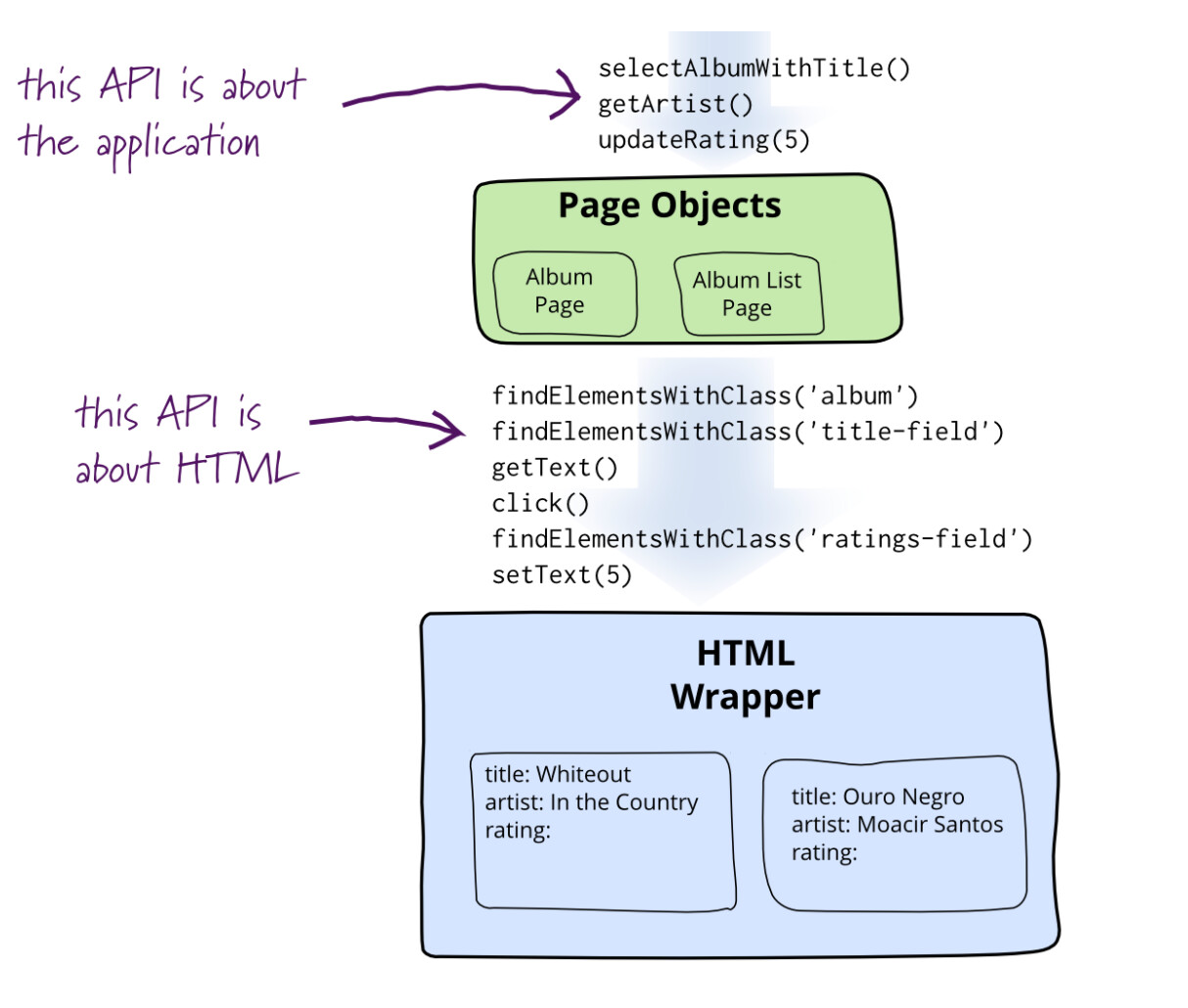
一、page object 模式简介
1.1、传统 UI 自动化的问题
- 无法适应 UI 频繁变化
- 无法清晰表达业务用例场景
- 大量的样板代码 driver/find/click
二、page object 设计原则
2.1、POM 模式的优势
- 降低 UI 变化导致的测试用例脆弱性问题
- 让用例清晰明朗,与具体实现无关
2.2、POM 建模原则
- 字段意义
- 不需要暴露页面内部的元素给外部
- 不需要建模UI内的所有元素
- 方法意义
- 用公共的方法代表UI所提供的功能
- 方法应该返回其他page object或者返回用于断言的数据
- 同样的行为不同的结果可以建模为不同的方法
- 不要在方法内断言
2.3、POM 使用方法
- 把元素信息和操作细节封装到 PageObject 类中
- 根据业务逻辑,在测试用例中链式调用
三、page object示例展示
3.1、搜索场景:传统线性脚本(Python)
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestSearch:
def test_search(self):
# 初始化浏览器
self.driver = webdriver.Chrome()
self.driver.get("https://xueqiu.com/")
self.driver.implicitly_wait(3)
# 输入搜索关键词
self.driver.find_element(By.NAME, "q").send_keys("阿里巴巴-SW")
# 点击搜索按钮
self.driver.find_element(By.CSS_SELECTOR, "i.search").click()
# 获取搜索结果
name = self.driver.find_element(By.XPATH, "//table//strong").text
# 断言
assert name == "阿里巴巴-SW"
3.2、POM 脚本(Python)
from selenium import webdriver
from selenium.webdriver.common.by import By
class SearchPage:
__INPUT_SEARCH = (By.NAME, "q")
__BUTTON_SEARCH = (By.CSS_SELECTOR, "i.search")
__SPAN_STOCK = (By.XPATH, "//table//strong")
def __init__(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3)
self.driver.get("https://xueqiu.com/")
def search_stock(self, stock_name: str):
self.driver.find_element(*self.__INPUT_SEARCH).send_keys(stock_name)
self.driver.find_element(*self.__BUTTON_SEARCH).click()
name = self.driver.find_element(By.XPATH, "//table//strong").text
return name
from onSelenium.fei.page_objects.search_page import SearchPage
class TestSearch:
def test_search(self):
text = SearchPage().search_stock("阿里巴巴-SW")
# 断言
assert "阿里巴巴-SW" == text