Pytest 命名规则
| 类型 | 规则 |
|---|---|
| 文件 | test_开头 或者 _test 结尾 |
| 类 | Test 开头 |
| 方法/函数 | test_开头 |
注意:测试类中不可以添加__init__构造函数 |
注意:pytest对于测试包的命名没有要求
方法:类中定义的函数
函数:类外面定义的函数
谷歌风格开源项目风格指南:
https://zh-google-styleguide.readthedocs.io/en/latest/google-python-styleguide/python_style_rules/
Pytest用例断言
断言的概念
断言(assert),是一种在程序中的一阶逻辑(如:一个结果为真或假的逻辑判断式),目的为了表示与验证软件开发者预期的结果。当程序执行到断言的位置时,对应的断言应该为真。若断言不为真时,程序会中止执行,并给出错误信息。
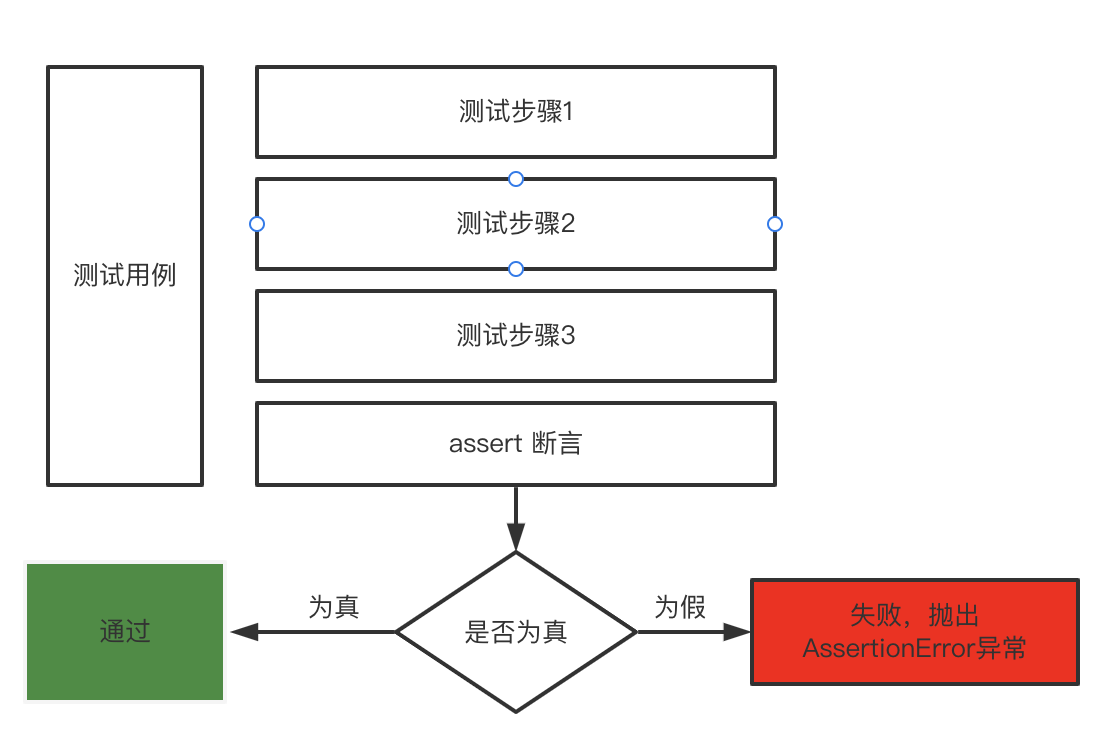
断言的用法
- 断言写法
assert <表达式>assert <表达式>,<描述>
assert <bool expression>;
assert <bool expression> : <message>;
示例一
def test_a():
assert True
def test_b():
a = 1
b = 1
c = 2
assert a + b == c, f"{a}+{b}=={c}, 结果为真"
示例二
def test_c():
a = 1
b = 1
c = 2
assert 'abc' in "abcd"
import sys
def test_plat():
assert ('linux' in sys.platform), "该代码只能在 Linux 下执行"
Pytest测试框架结构(setup/teardown)
测试装置介绍
| 类型 | 规则 |
|---|---|
| setup_module/teardown_module | 全局模块级 |
| setup_class/teardown_class | 类级,只在类中前后运行一次 |
| setup_function/teardown_function | 函数级,在类外 |
| setup_method/teardown_method | 方法级,类中的每个方法执行前后 |
| setup/teardown | 在类中,运行在调用方法的前后(重点) |
Pyrest参数化用例
参数化
- 通过参数的方式传递数据,从而实现数据和脚本分离。
- 并且可以实现用例的重复生成与执行。
参数化测试函数使用
单参数情况
- 单参数,可以将数据放在列表中
search_list = ['appium','selenium','pytest']
@pytest.mark.parametrize('name',search_list)
def test_search(name):
assert name in search_list
多参数情况
- 将数据放在列表嵌套元组中
- 将数据放在列表嵌套列表中
# 数据放在元组中
@pytest.mark.parametrize("test_input,expected",[
("3+5",8),("2+5",7),("7+5",12)
])
def test_mark_more(test_input,expected):
assert eval(test_input) == expected
# 数据放在列表中
@pytest.mark.parametrize("test_input,expected",[
["3+5",8],["2+5",7],["7+5",12]
])
def test_mark_more(test_input,expected):
assert eval(test_input) == expected
用例重命名-添加 ids 参数
- 通过ids参数,将别名放在列表中
@pytest.mark.parametrize("test_input,expected",[
("3+5",8),("2+5",7),("7+5",12)
],ids=['add_3+5=8','add_2+5=7','add_3+5=12'])
def test_mark_more(test_input,expected):
assert eval(test_input) == expected
用例重命名-添加 ids 参数(中文)
@pytest.mark.parametrize("test_input,expected",[
("3+5",8),("2+5",7),("7+5",12)
],ids=["3和5相加","2和5相加","7和5相加"])
def test_mark_more(test_input,expected):
assert eval(test_input) == expected
ids不支持中文,默认是unicode编码格式,可以用如下方法转换
# 在项目(最末一级)下创建conftest.py 文件 ,将下面内容添加进去,运行脚本
def pytest_collection_modifyitems(items):
"""
测试用例收集完成时,将收集到的用例名name和用例标识nodeid的中文信息显示在控制台上
"""
for i in items:
i.name=i.name.encode("utf-8").decode("unicode_escape")
i._nodeid=i.nodeid.encode("utf-8").decode("unicode_escape")
笛卡尔积
接口测试中用的较多,因为接口的值很多
- 两组数据
- a=[1,2,3]
- b=[a,b,c]
- 对应有几种组合形势 ?
- (1,a),(1,b),(1,c)
- (2,a),(2,b),(2,c)
- (3,a),(3,b),(3,c)
@pytest.mark.parametrize("b",["a","b","c"])
@pytest.mark.parametrize("a",[1,2,3])
def test_param1(a,b):
print(f"笛卡积形式的参数化中 a={a} , b={b}")
执行方向:由近致远
使用 Mark 标记测试用例
Mark:标记测试用例
- 场景:只执行符合要求的某一部分用例 可以把一个web项目划分多个模块,然后指定模块名称执行。
- 解决: 在测试用例方法上加
@pytest.mark.标签名 - 执行: -m 执行自定义标记的相关用例
pytest -s 文件名 -m=webtestpytest -s test_mark_zi_09.py -m apptest-
pytest -s test_mark_zi_09.py -m "not ios"(必须要是双引号) - pytest -v是能输出更详细的用例信息,成功与失败不再是.和F
如何解决warnings问题
[pytest]
# 在项目目录下创建一个pytest.ini放标签,这样这些标签就不会warning。而且要换行写,也不要顶头写,会被认为是key
# 在这里注册好标签名后,pytest可以识别
markers = str
bignum
float
int
minus
zero
pytest 设置跳过、预期失败
Mark:跳过(Skip)及预期失败(xFail)
- 这是 pytest 的内置标签,可以处理一些特殊的测试用例,不能成功的测试用例
- skip - 始终跳过该测试用例
- skipif - 遇到特定情况跳过该测试用例
- xfail - 遇到特定情况,产生一个“期望失败”输出
Skip 使用场景
- 调试时不想运行这个用例
- 标记无法在某些平台上运行的测试功能
- 在某些版本中执行,其他版本中跳过
- 比如:当前的外部资源不可用时跳过
- 如果测试数据是从数据库中取到的,
- 连接数据库的功能如果返回结果未成功就跳过,因为执行也都报错
- 解决 1:添加装饰器
@pytest.mark.skip@pytest.mark.skipif
- 解决 2:代码中添加跳过代码
pytest.skip(reason)
# 形式一:跳过这个方法
@pytest.mark.skip(reason="存在bug")
def test_double_str():
print("代码未开发完")
assert 'aa' == 'aa'
# 形式二:跳过这个方法
@pytest.mark.skipif(sys.platform == "win32", reason="does not run on win32")
def test_case():
print(sys.platform)
assert True
# 形式二:在代码中跳过代码
def check_login():
return False
def test_double_str():
print("start")
if not check_login():
pytest.skip("未登录,不进行下去")
print("end")
# ============================= 1 skipped in 0.02s ======
xfail 使用场景
用于标记此用例可能会失败,当脚本失败时,测试报告也不会打印错误追踪,只是会显示xfail状态。xfail的主要作用是比如在进行测试提前时,当产品某功能尚未开发完成而进行自动化脚本开发,当然此时也可以把这些脚本注释起来,但这不是pytest推荐的做法,pytest推荐使用xfail标记,如此则虽然产品功能尚未开发完成,但是自动化脚本已经可以跑起来了,只不过在测试报告中会显示xfail而已。
- 与 skip 类似 ,预期结果为 fail ,标记用例为 fail
- 与skip不同,xfail标记的用例依然会被执行,如果执行成功就返回XPASS,执行失败就返回XFAIL。只是起到一个提示的作用。
- 用法:添加装饰器
@pytest.mark.xfail
@pytest.mark.xfail
def test_case():
print("test_xfail 方法执行")
assert 2 == 2
# XPASS [100%]test_xfail
@pytest.mark.xfail
def test_case():
print("test_xfail 方法执行")
assert 1 == 2
# XFAIL [100%]test_xfail 方法执行
xfail = pytest.mark.xfail
@xfail(reason="bug 110")
def test_case():
print("test_xfail 方法执行")
assert 1 == 2
# XFAIL (bug 110) [100%]test_xfail 方法执行
pytest 运行用例-命令行
参数介绍
运行多条用例方式
如果要进入某个文件所在的目录终端,可以右键文件->选择open in terminal
- 执行包下所有的用例:
pytest/py.test [包名] - 执行单独一个 pytest 模块:
pytest 文件名.py - 运行某个模块里面某个类:
pytest 文件名.py::类名 - 运行某个模块里面某个类里面的方法:
pytest 文件名.py::类名::方法名 - 加-v可以具体展示,如pytest -v 文件名.py::类名::方法名 (-v在前在后都行)
- test_skip.py::TestDemo::test_demo1 PASSED [100%]
运行结果分析
- 常用的:fail/error/pass(error可能是代码写错了)
- 特殊的结果:warning/deselect(后面会讲)
pytest 测试用例调度与运行
命令行参数-使用缓存状态
-
--lf(--last-failed)只重新运行故障。 -
--ff(--failed-first)先运行故障然后再运行其余的测试
例如 pytest --lf
常用命令行参数
—help
-x 用例一旦失败(fail/error),就立刻停止执行
--maxfail=num 用例达到num个失败就停止
-m 标记用例
-k "关键字" 执行包含某个关键字的测试用例(windows一定要用双引号)
-v 打印详细日志
-s 打印输出日志(一般-vs一块儿使用)
—collect-only 只收集不运行(测试平台,pytest 自动导入功能 )
-s:默认情况下,pytest在运行测试时将禁止标准输出(stdout)和标准错误(stderr)的输出。但是,使用了 -s 参数后,pytest将允许测试中的打印语句、错误信息等在控制台上显示出来。
建议使用命令行的方式执行,因为后期做持续集成都会使用命令行的方式
python 执行 pytest
前面已经介绍了几种执行用例的方法,一个是点击代码方法或类的左侧绿色箭头,一个是右键测试用例,一个是终端pytest解释器执行,我们也可以用python解释器执行
Python 代码执行 pytest
- 方法一:使用 main 函数
- 方法二:使用 python -m pytest 调用 pytest(jenkins 持续集成用到),相当于在原来pytest 用例前加了python -m。
- 方便指定python版本,比如有的用例使用python老版本写的
Python 代码执行 pytest - main 函数
if __name__ == '__main__':
# 1、运行当前目录下所有符合规则的用例,包括子目录(test_*.py 和 *_test.py)
pytest.main()
# 2、运行test_mark1.py::test_dkej模块中的某一条用例
pytest.main(['test_mark1.py::test_dkej','-vs'])
# 3、运行某个 标签
pytest.main(['test_mark1.py','-vs','-m','dkej'])
运行方式
`python test_*.py `
pytest 异常处理
异常处理方法 try …except
try:
可能产生异常的代码块
except [ (Error1, Error2, ... ) [as e] ]:
处理异常的代码块1
except [ (Error3, Error4, ... ) [as e] ]:
处理异常的代码块2
except [Exception]:
处理其它异常
异常处理方法 pytest.raise()
- 可以捕获特定的异常
- 获取捕获的异常的细节(异常类型,异常信息)
- 发生异常,后面的代码将不会被执行
def test_raise():
with pytest.raises(ValueError, match='must be 0 or None'):
raise ValueError("value must be 0 or None")
def test_raise1():
with pytest.raises(ValueError) as exc_info:
raise ValueError("value must be 42")
assert exc_info.type is ValueError
assert exc_info.value.args[0] == "value must be 42"
这样可以选择一个异常
def test_raise():
with pytest.raises((ZeroDivisionError,ValueError)):
raise ZeroDivisionError("value must be 0 or None")
Pytest 结合数据驱动
工程目录结构(看项目文件datadriver_。。)
- data 目录:存放 yaml 数据文件
- func 目录:存放被测函数文件
- testcase 目录:存放测试用例文件
# 工程目录结构
.
├── data
│ └── data.文件格式
├── func
│ ├── __init__.py
│ └── operation.py
└── testcase
├── __init__.py
└── test_add.py
Pytest 结合数据驱动 YAML
数据驱动
- 什么是数据驱动?
- 数据驱动就是数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变。简单来说,就是参数化的应用。数据量小的测试用例可以使用代码的参数化来实现数据驱动,数据量大的情况下建议大家使用一种结构化的文件(例如 yaml,json 等)来对数据进行存储,然后在测试用例中读取这些数据。
- 应用:
- App、Web、接口自动化测试
- 测试步骤的数据驱动
- 测试数据的数据驱动
- 配置的数据驱动
yaml 文件介绍
- 对象:键值对的集合,用冒号 “:” 表示
- 数组:一组按次序排列的值,前加 “-”
- 纯量:单个的、不可再分的值
- 字符串
- 布尔值
- 整数
- 浮点数
- Null
- 时间
- 日期
# 编程语言
languages:
- PHP
- Java
- Python
book:
Python入门: # 书籍名称
price: 55.5
author: Lily
available: True
repertory: 20
date: 2018-02-17
Java入门:
price: 60
author: Lily
available: False
repertory: Null
date: 2018-05-11
相当于:
languages:['PHP', 'Java', 'Python'] # languages是key值
yaml 文件使用
- 查看 yaml 文件
- pycharm
- txt 记事本
- 读取 yaml 文件
- 安装:
pip install pyyaml - 方法:
yaml.safe_load(f)(yaml->python) - 方法:
yaml.safe_dump(f)(python->yaml)
- 安装:
import yaml
file_path = './my.yaml'
with open(file_path, 'r', encoding='utf-8') as f:
data = yaml.safe_load(f)
测试准备
- 被测对象:
operation.py - 测试用例:
test_add.py - 测试数据:
data.yaml
# operation.py 文件内容
def my_add(x, y):
result = x + y
return result
# test_add.py 文件内容
class TestWithYAML:
@pytest.mark.parametrize('x,y,expected', [[1, 1, 2]])
def test_add(self, x, y, expected):
assert my_add(int(x), int(y)) == int(expected)
# data.yaml 文件内容
-
- 1
- 1
- 2
-
- 3
- 6
- 9
-
- 100
- 200
- 300
Pytest 数据驱动结合 yaml 文件
# 读取yaml文件
def get_yaml():
"""
获取json数据
:return: 返回数据的结构:[[1, 1, 2], [3, 6, 9], [100, 200, 300]]
"""
with open('../datas/data.yaml', 'r') as f:
data = yaml.safe_load(f)
return data
Pytest 结合数据驱动 Excel
读取 Excel 文件
- 第三方库
xlrdxlwingspandas
- openpyxl
openpyxl 库的安装
- 安装:
pip install openpyxl - 导入:
import openpyxl
openpyxl 库的操作
- 读取工作簿
- 读取工作表
- 读取单元格
import openpyxl
# 获取工作簿
book = openpyxl.load_workbook('../data/params.xlsx')
# 读取工作表
sheet = book.active
# 读取单个单元格
cell_a1 = sheet['A1']
cell_a3 = sheet.cell(column=1, row=3) # A3
# 读取多个连续单元格
cells = sheet["A1":"C3"]
# 获取单元格的值
cell_a1.value
测试准备
- 被测对象:
operation.py - 测试用例:
test_add.py
# operation.py 文件内容
def my_add(x, y):
result = x + y
return result
# test_add.py 文件内容
class TestWithEXCEL:
@pytest.mark.parametrize('x,y,expected', get_excel())
def test_add(self, x, y, expected):
assert my_add(int(x), int(y)) == int(expected)
测试准备
- 测试数据:
params.xlsx

注意:.xlsx文件要在外面创建,不要在编辑器里创建
Pytest 数据驱动结合 Excel 文件
# 读取Excel文件
import openpyxl
import pytest
def get_excel():
# 获取工作簿
book = openpyxl.load_workbook('../data/params.xlsx')
# 获取活动行(非空白的)
sheet = book.active
# 提取数据,格式:[[1, 2, 3], [3, 6, 9], [100, 200, 300]]
values = []
for row in sheet:
line = []
for cell in row:
line.append(cell.value)
values.append(line)
return values
Pytest 结合数据驱动 csv
csv 文件介绍
- csv:逗号分隔值
- 是 Comma-Separated Values 的缩写
- 以纯文本形式存储数字和文本
- 文件由任意数目的记录组成
- 每行记录由多个字段组成
Linux从入门到高级,linux,¥5000
web自动化测试进阶,python,¥3000
app自动化测试进阶,python,¥6000
Docker容器化技术,linux,¥5000
测试平台开发与实战,python,¥8000
csv 文件使用
- 读取数据
- 内置函数:
open() - 内置模块:
csv
- 内置函数:
- 方法:
csv.reader(iterable)- 参数:iterable ,文件或列表对象
- 返回:迭代器,每次迭代会返回一行数据。
# 读取csv文件内容
def get_csv():
with open('demo.csv', 'r') as file:
raw = csv.reader(file)
for line in raw:
print(line)
测试准备
- 被测对象:
operation.py - 测试用例:
test_add.py - 测试数据:
params.csv
# operation.py 文件内容
def my_add(x, y):
result = x + y
return result
# test_add.py 文件内容
class TestWithCSV:
@pytest.mark.parametrize('x,y,expected', [[1, 1, 2]])
def test_add(self, x, y, expected):
assert my_add(int(x), int(y)) == int(expected)
# params.csv 文件内容
1,1,2
3,6,9
100,200,300
Pytest 数据驱动结合 csv 文件
# 读取 data目录下的 params.csv 文件
import csv
def get_csv():
"""
获取csv数据
:return: 返回数据的结构:[[1, 1, 2], [3, 6, 9], [100, 200, 300]]
"""
with open('../data/params.csv', 'r') as file:
raw = csv.reader(file)
data = []
for line in raw:
data.append(line)
return data
Pytest 结合数据驱动 json
json 文件介绍
- json 是 JS 对象
- 全称是 JavaScript Object Notation
- 是一种轻量级的数据交换格式
- json 结构
- 对象
{"key": value} - 数组
[value1, value2 ...]
- 对象
{
"name:": "hogwarts ",
"detail": {
"course": "python",
"city": "北京"
},
"remark": [1000, 666, 888]
}
json 文件使用
- 查看 json 文件
- pycharm
- txt 记事本
- 读取 json 文件
- 内置函数 open()
- 内置库 json
- 方法:
json.loads() - 方法:
json.dumps()
# 读取json文件内容
def get_json():
with open('demo.json', 'r') as f:
data = json.loads(f.read())
print(data)
测试准备
- 被测对象:
operation.py - 测试用例:
test_add.py - 测试数据:
params.json
# operation.py 文件内容
def my_add(x, y):
result = x + y
return result
# test_add.py 文件内容
class TestWithJSON:
@pytest.mark.parametrize('x,y,expected', [[1, 1, 2]])
def test_add(self, x, y, expected):
assert my_add(int(x), int(y)) == int(expected)
# params.json 文件内容
{
"case1": [1, 1, 2],
"case2": [3, 6, 9],
"case3": [100, 200, 300]
}
Pytest 数据驱动结合 json 文件
# 读取json文件
def get_json():
"""
获取json数据
:return: 返回数据的结构:[[1, 1, 2], [3, 6, 9], [100, 200, 300]]
"""
with open('../data/params.json', 'r') as f:
data = json.loads(f.read())
return list(data.values())
pytest测试用例生命周期管理
Fixture 用法
Fixture 特点及优势
- 1、命令灵活:对于 setup,teardown,可以不起这两个名字
- 2、数据共享:在 conftest.py 配置⾥写⽅法可以实现数据共享,不需要 import 导⼊。可以跨⽂件共享
- 3、scope 的层次及神奇的 yield 组合相当于各种 setup 和 teardown
- 4、实现参数化
Fixture 在自动化中的应用- 基本用法
-
场景:
测试⽤例执⾏时,有的⽤例需要登陆才能执⾏,有些⽤例不需要登陆。
setup 和 teardown ⽆法满⾜。fixture 可以。默认 scope(范围)function
-
步骤:
- 1.导⼊ pytest
- 2.在登陆的函数上⾯加
@pytest.fixture() - 3.在要使⽤的测试⽅法中传⼊(登陆函数名称),就先登陆
- 4.不传⼊的就不登陆直接执⾏测试⽅法。
# test_fixture.py
import pytest
# 定义登录的fixture
@pytest.fixture()
def login():
print("完成登录操作")
def test_search():
print("搜索")
def test_cart(login): #不需要把login放在函数里面,只要传参就可以
print("购物车")
def test_order(login):
print("下单")
Fixture 在自动化中的应用 - 作用域
| 取值 | 范围 | 说明 |
|---|---|---|
| function | 函数级 | 每一个函数或方法都会调用 |
| class | 类级别 | 每个测试类只运行一次 |
| module | 模块级 | 每一个.py 文件调用一次 |
| package | 包级 | 每一个 python 包只调用一次(暂不支持) |
| session | 会话级 | 每次会话只需要运行一次,会话内所有方法及类,模块都共享这个方法 |
注:整个项目就是一个会话
import pytest
# 定义登录的fixture
@pytest.fixture(scope="class")
def login():
print("完成登录操作")
def test_search(login):
print("搜索")
def test_cart(login):
print("购物车")
def test_order(login):
print("下单")
class TestDemo:
def test_case1(self,login):
print("case1")
def test_case2(self,login):
print("case2")
Fixture 在自动化中的应用 - yield 关键字
- 场景:
你已经可以将测试⽅法【前要执⾏的或依赖的】解决了,
测试⽅法后销毁清除数据的要如何进⾏呢?
- 解决:
通过在 fixture 函数中加⼊ yield 关键字,yield 是调⽤第⼀次返回结果,
第⼆次执⾏它下⾯的语句返回。
- 步骤:
在@pytest.fixture(scope=module)。
在登陆的⽅法中加 yield,之后加销毁清除的步骤
import pytest
# 定义登录的fixture
@pytest.fixture(scope="class")
def login():
# setup 操作
print("完成登录操作")
token = "abcd"
username = "hogwarts"
yield token, username # 相当于return
# teardown 操作
print("完成登出操作")
def test_search(login):
token, username = login
print(f"token:{token},name:{username}")
print("搜索")
def test_cart(login):
print("购物车")
def test_order(login):
print("下单")
class TestDemo:
def test_case1(self,login):
print("case1")
def test_case2(self,login):
print("case2")
Fixture 在自动化中的应用 - 数据共享
- 场景:
你与其他测试⼯程师合作⼀起开发时,公共的模块要在不同⽂件中,要在⼤家都访问到的地⽅。
- 解决:
使⽤ conftest.py 这个⽂件进⾏数据共享,并且他可以放在不同位置起着不同的范围共享作⽤。
-
前提:
- conftest ⽂件名是不能换的
- 放在项⽬下是全局的数据共享的地⽅
-
执⾏:
- 系统执⾏到参数 login 时先从本模块中查找是否有这个名字的变量什么的,
- 之后在 conftest.py 中找是否有。
-
步骤:
- 将登陆模块带
@pytest.fixture写在 conftest.py
- 将登陆模块带
Fixture 在自动化中的应用 - 自动应用
场景:
不想原测试⽅法有任何改动,或全部都⾃动实现⾃动应⽤,
没特例,也都不需要返回值时可以选择⾃动应⽤
解决:
使⽤ fixture 中参数 autouse=True 实现
步骤:
在⽅法上⾯加 @pytest.fixture(autouse=True)
比如要实现fixture时session级别的,就要每个用例都添加fixture方法。可以通过自动应用来避免。
问题:那yield返回参数的怎么办?
Fixture 在自动化中的应用 -参数化
场景:
测试离不开数据,为了数据灵活,⼀般数据都是通过参数传的
解决:
fixture 通过固定参数 request 传递
步骤:
在 fixture 中增加@pytest.fixture(params=[1, 2, 3, 'linda'])
在⽅法参数写 request,方法体里面使用 request.param 接收参数
# test_fixture_param.py
import pytest
@pytest.fixture(params=[["selenium",123], ["appium",123]])
def login(request):
print(f"用户名:{request.param}")
return request.param
def test_demo1(login):
print(f"demo1 case:数据为{login}")
我们之前学过一种添加参数的方法:在用例方法上方添加
@pytest.mark.parametrize('my_fixture', ['value'], indirect=True)
当设置 indirect=True 时,参数化的参数将被解释为 fixture 的名称,并被视为函数参数传递给测试函数。这样,测试函数将使用由参数化提供的参数调用同名的 fixture 函数,而不是将参数直接传递给测试函数。
# conftest.py
import pytest
@pytest.fixture()
def my_fixture(request):
param1, param2 = request.param
print(f"Param1: {param1}, Param2: {param2}")
# test_example.py
@pytest.mark.parametrize('my_fixture', [['selenium', 123], ['appium', 456]], indirect=True)
def test_example():
print("Test")
两种方法的区别:
-
@pytest.fixture:这种方法意味着每次运行测试函数时,my_fixture将使用相同的参数值。 -
@pytest.mark.parametrize:这种方法非常灵活,可以根据需要为每个测试用例提供不同的参数。
Fixture 的用法总结
- 模拟 setup,teardown(一个用例可以引用多个 fixture)
- yield 的用法
- 作用域( session,module, 类级别,方法级别 )
- 自动执行 (autouse 参数)
- conftest.py 用法,一般会把 fixture 写在 conftest.py 文件中(这个文件名字是固定的,不能改)
- 实现参数化
pytest.ini 配置
pytest.ini 是什么
- pytest.ini 是 pytest 的配置文件
- 可以修改 pytest 的默认行为
- 不能使用任何中文符号,包括汉字、空格、引号、冒号等等
pytest.ini的作用
- 修改用例的命名规则
- 配置日志格式,比代码配置更方便
- 添加标签,防止运行过程报警告错误
- 指定执行目录
- 排除搜索目录
pytest 配置- 改变运行规则
;执行check_开头和 test_开头的所有的文件,后面一定要加*
python_files = check_* test_*
;执行所有的以Test和Check开头的类
python_classes = Test* Check*
;执行所有以test_和check_开头的方法
python_functions= test_* check_*
pytest 配置- 添加默认参数
addopts = -v -s --alluredir=./results # 会帮我生成一个默认的allure测试报告
pytest 配置- 指定/忽略执行目录
;设置执行的路径(指定某个目录)
;testpaths = bilibili baidu
;忽略某些文件夹/目录
norecursedirs = result logs datas test_demo*
pytest 配置- 日志
配置参考链接:pytest logging 收集日志
包括输出到屏幕上和输出到文件中
Pytest 插件开发
pytest 插件分类
- 外部插件:pip install 安装的插件,也就是第三方库
- 本地插件:pytest 自动模块发现机制(conftest.py 存放的)
- 内置插件:代码内部的_pytest 目录加载,也就是hook函数
pytest 常用的插件
pip install pytest-ordering 控制用例的执行顺序(重点)
pip install pytest-xdist 分布式并发执行测试用例(重点)
pip install pytest-dependency 控制用例的依赖关系 (了解)
pip install pytest-rerunfailures 失败重跑(了解)
pip install pytest-assume 多重较验(了解)
pip install pytest-random-order 用例随机执行(了解)
pip install pytest-html 测试报告(了解)
pytest 执行顺序控制
场景:
对于集成测试,经常会有上下文依赖关系的测试用例。
比如 10 个步骤,拆成 10 条 case,这时候能知道到底执行到哪步报错。
用例默认执行顺序:自上而下执行
解决:
可以通过 setup,teardown 和 fixture 来解决。也可以使用对应的插件。
安装:pip install pytest-ordering
用法:@pytest.mark.run(order=2),也可以用@pytest.mark.first和@pytest.mark.second
注意:多个插件装饰器(>2)的时候,有可能会发生冲突、
举例:https://github.com/ftobia/pytest-ordering
ps:尽量不要让测试用例有顺序
Pytest 并行与分布式执行
场景 1:
测试用例 1000 条,一个用例执行 1 分钟,一个测试人员执行需要 1000 分钟。
通常我们会用人力成本换取时间成本,加几个人一起执行,时间就会 缩短。
如果 10 人一起执行只需要 100 分钟,这就是一种分布式场景。
场景 2:
假设有个报名系统,对报名总数统计,数据同时进行修改操作的时候有可能出现问题,
需要模拟这个场景,需要多用户并发请求数据。
解决:
使用分布式并发执行测试用例。分布式插件:pytest-xdist
安装及运行: pip install pytest-xdist
结合命令:pytest -n 核数(核数尽量不要超过电脑实际内核数,否则也没有特别大的效果),或者用pytest -n auto(自动获取我们的空闲核数)
注意: 用例多的时候效果明显,多进程并发执行,同时支持 allure
要使用pytest-xdist插件执行多进程或多线程的测试,可以使用以下命令行选项: - -n:用于指定并发工作进程或线程的数量。 - --dist:用于指定并发工作模式,可以是load(进程)或loadscope(线程)。 - -d:用于指定并发工作进程之间的数据传递方式(仅对进程模式有效)。 以下是一些示例使用pytest-xdist插件的命令行示例: - 使用4个进程运行测试(数据传递方式为“load”):
pytest -n 4 --dist load
- 使用2个线程运行测试(数据传递方式为“loadscope”):
pytest -n 2 --dist loadscope
如果要在pytest.ini文件(或者其他INI格式的配置文件)中设置这些选项,可以添加类似以下内容的节:
[pytest]
addopts = -n auto --dist load
上述配置会自动使用所有可用的CPU核心数,并使用“load”模式执行测试。 希望以上信息对你有所帮助。如果你有其他问题,请随时提问。
分布式执行测试用例原则
- 用例之间是独立的,不要有依赖关系
- 用例执行没有顺序,随机顺序都能正常执行
- 每个用例都能重复运行,运行结果不会影响其他用例
pytest 内置插件 hook 体系
pytest hook 介绍
- 是个函数,在系统消息触时被系统调用
- 自动触发机制
- Hook 函数的名称是确定的(如果你想实现某个hook函数就要去把它复制粘贴过来)
- pytest 有非常多的勾子函数
- 使用时直接编写函数体
- 要放在conftest.py里
pytest 执行顺序
site-package/_pytest/hookspec.py
....
pytest_addoption : 添加命令行参数,运时会先读取命令行参数
pytest_collection_modifyitems : 收集测试用例,收集之后(改编码,改执行顺序)
pytest_collection_finish:收集之后的操作
pytest_runtest_setup:在调用 pytest_runtest_call 之前调用
pytest_runtest_call:调用执行测试的用例
pytest_runtest_makereport:运行测试用例,返回setup,call,teardown的执行结果
....
详细介绍:定制pytest插件必备之pytest hook的执行顺序
简单的例子
def pytest_runtest_setup(item):
# 执行测试用例前执行的setup方法
print("setting up", item)
def pytest_runtest_call(item):
# 调用执行测试的用例
print("pytest_runtest_call")
def pytest_runtest_teardown(item):
# 执行测试用例后执行的teardown
print("pytest runtest teardown",item)
