接口自动化测试框架介绍
目录
- 接口自动化测试介绍
- 接口自动化测试的学习体系
- 接口自动化测试框架介绍
接口测试场景
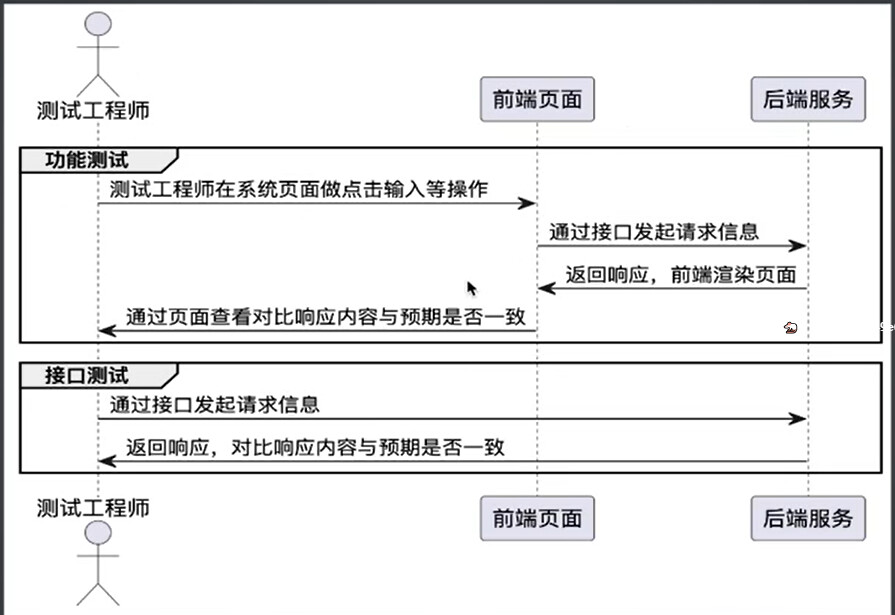
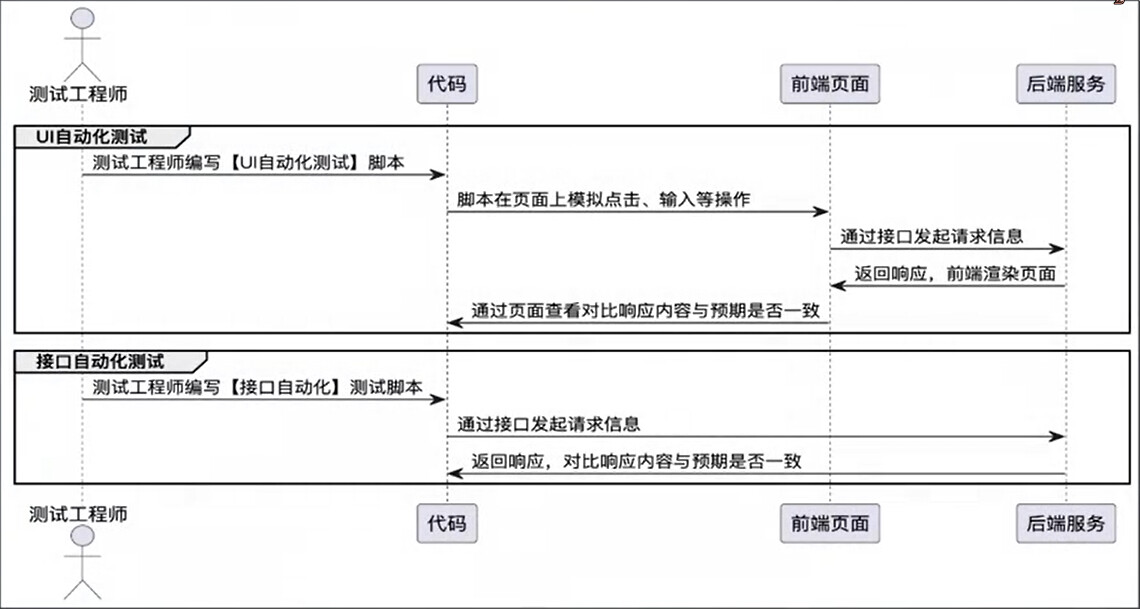
自动化测试场景
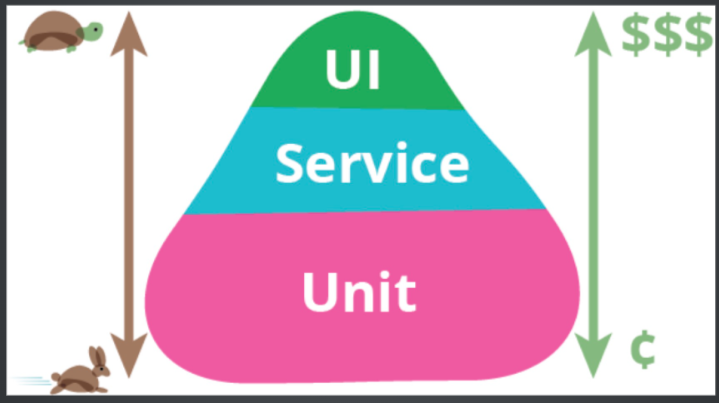
接口测试在分层测试中的位置
接口自动化测试与 Web/App 自动化测试对比

接口自动化测试与 Web/App 自动化测试对比
看起来接口自动化测试什么都比 Web/App 自动化测试要好,为什么还要做 Web/App 自动化测试?
- 接口关注数据无法触达用户体验。
接口测试工具类型

为什么推荐 Requests
- 是由 Python 实现的 API 测试框架。
- 支持发起 POST, GET, PUT, DELETE 等请求。
- 可以用来验证和校对响应信息。
官网地址: Requests: HTTP for Humans™ — Requests 2.31.0 documentation
Requests 优势
- 功能全面:HTTP/HTTPS 支持全面。
- 使用简单:简单易用,不用关心底层细节。
- 定制性高:结合测试框架完成二次封装,比如 HttpRunner。
Requests 环境准备
- 安装命令:
pip install requests
接口请求方法
目录
- 常见 HTTP 请求方法构造
- 演练环境
- HTTP 协议知识回顾
- 构造请求方法
常见 HTTP 请求方法构造

底层设计
演练环境地址
HTTP 协议知识回顾
- URL 结构
- HTTP 请求
- HTTP 响应
具体详见《常见接口协议》录播
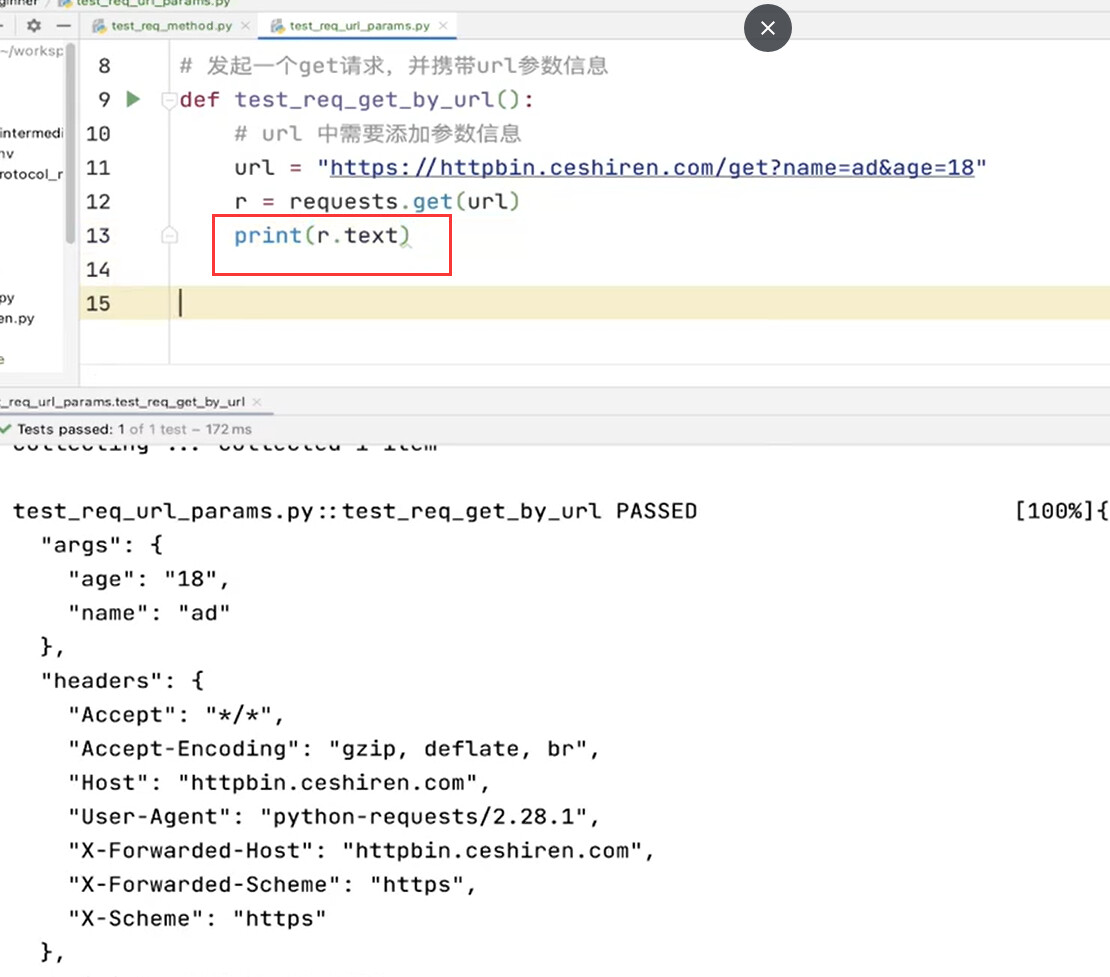
构造 GET 请求
-
requests.get(url, params=None, **kwargs)- url: 接口 url。
- params:拼接在 url 中的请求参数。
- **kwargs:更多底层支持的参数。
# 导入依赖
import requests
def test_get():
# 定义接口的 url 和拼接在 url 中的请求参数
url = "https://httpbin.ceshiren.com/get"
# 发出 GET 请求,r 接收接口响应
r = requests.get(url)
# 打印接口响应
logger.info(f"接口响应为 {r}")
构造 POST 请求
-
requests.post(url, data=None, json=None, **kwargs)- url: 接口 url。
- data:表单格式请求体。
- json:JSON 格式请求体。
- **kwargs:更多底层支持的参数。
# 导入依赖
import requests
def test_post():
# 定义接口的 url
url = "https://httpbin.ceshiren.com/post"
# 发出 POST 请求,r 接收接口响应
r = requests.post(url)
# 打印接口响应
logger.info(f"接口响应为 {r}")
构造 PUT 请求
-
requests.put(url, data=None, **kwargs)- url: 接口 url。
- data:表单格式请求体。
- **kwargs:更多底层支持的参数。
# 导入依赖
import requests
def test_put():
# 定义接口的 url
url = "https://httpbin.ceshiren.com/put"
# 发出 POST 请求,r 接收接口响应
r = requests.put(url)
# 打印接口响应
logger.info(f"接口响应为 {r}")
构造 DELETE 请求
-
requests.delete(url, **kwargs)- url: 接口 url。
- **kwargs:更多底层支持的参数。
# 导入依赖
import requests
def test_delete():
# 定义接口的 url 和表单格式请求体
url = "https://httpbin.ceshiren.com/delete"
# 发出 POST 请求,r 接收接口响应
r = requests.delete(url)
# 打印接口响应
logger.info(f"接口响应为 {r}")
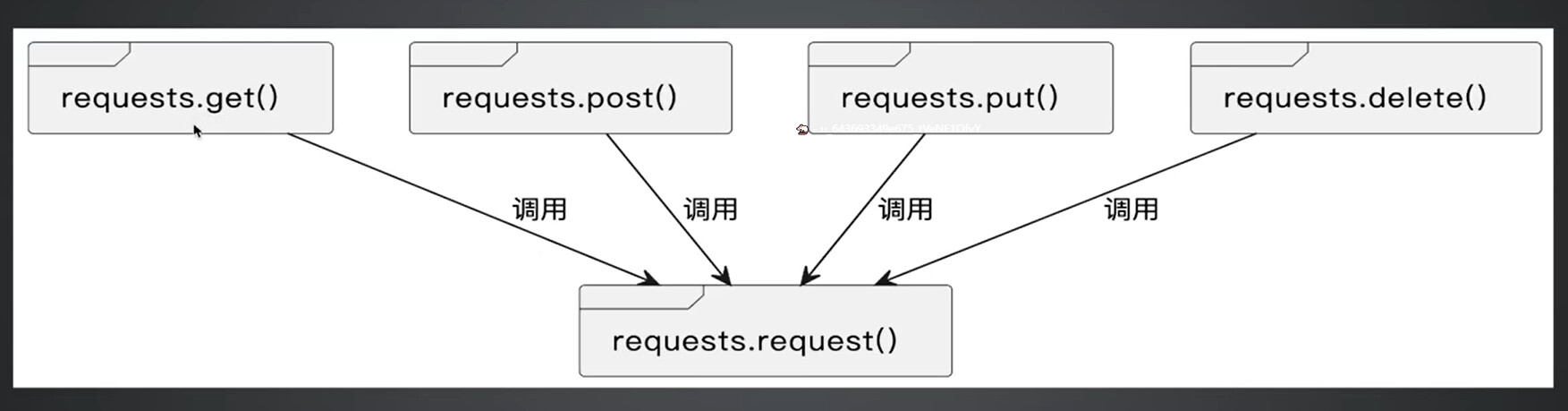
构造请求方法
-
requests.request(method, url, **kwargs)- method: 请求方法。
-
GET,OPTIONS,HEAD,POST,PUT,PATCH,DELETE。
-
- url: 接口 url。
- **kwargs:更多底层支持的参数。
- method: 请求方法。
底层参数说明
| 参数 | 应用场景 |
|---|---|
| method | 请求方法 |
| url | 请求 URL |
| params | 请求中携带 URL 参数 |
| data | 请求中携带请求体(默认为表单请求) |
| json | 请求中携带 json 格式的请求体 |
| headers | 请求中携带头信息 |
| cookies | 请求中携带 cookies |
| files | 请求中携带文件格式的请求体 |
| auth | 请求中携带认证信息 |
| timeout | 设置请求超时时间 |
| allow_redirects | 请求是否允许重定向 |
| proxies | 设置请求代理 |
| verify | 请求是否要认证 |
| cert | 请求中携带 ssl 证书 |
接口请求参数

请求参数简介
- 接口请求中携带的,会在路径之后使用
?代表客户端向服务端传递的参数。 - 使用
key=value形式拼接在 URL 中。 - 如果有多个,则使用
&分隔
携带请求参数的方式
- 常用两种方式:
- 直接在 URL 中拼接:
?username=Hogwarts&id=666。 - 通过 params 参数传递:
requests.get(url, params)
- 直接在 URL 中拼接:
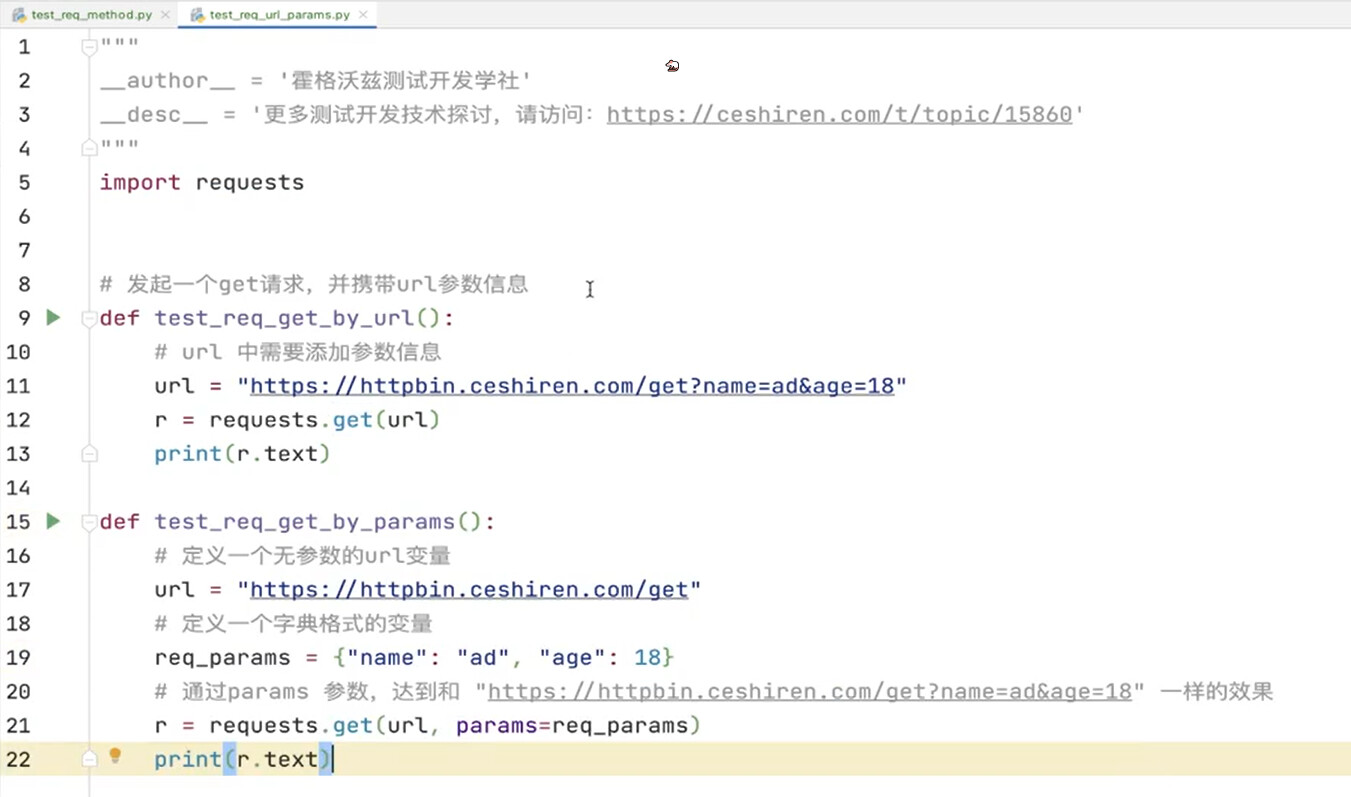
携带请求参数的 GET 请求
# 导入依赖
import requests
def test_get_by_params():
# 定义接口的 url 和拼接在 url 中的请求参数
url = "https://httpbin.ceshiren.com/get"
params ={
"get_key": "get_value"
}
# 发出 GET 请求,r 接收接口响应
r = requests.get(url, params=params)
def test_get_by_url():
# 定义接口的 url 和拼接在 url 中的请求参数
url = "https://httpbin.ceshiren.com/get?get_key=get_value"
# 发出 GET 请求,r 接收接口响应
r = requests.get(url)
携带请求参数的 POST 请求
# 导入依赖
import requests
def test_post_by_params():
# 定义接口的 url 和表单格式请求体
url = "https://httpbin.ceshiren.com/post"
params = {
"post_key": "post_value"
}
# 发出 POST 请求,r 接收接口响应
r = requests.post(url, params=params)
接口请求头
请求头信息的使用场景
- 身份认证
- 指定数据类型

请求头信息
- HTTP 请求头是在 HTTP 请求消息中包含的元数据信息,用于描述请求或响应的一些属性和特征。
- 实际工作过程中具体要关注的头信息字段需要和研发沟通。
- 常见的头信息(右侧表格):
| 内容 | 含义 |
|---|---|
| Authorization | 表示客户端请求的身份验证信息 |
| Cookie | 表示客户端的状态信息,通常用于身份验证和会话管理 |
| Content-Type | 表示请求消息体的 MIME 类型 |
| User-Agent | 发送请求的客户端软件信息 |
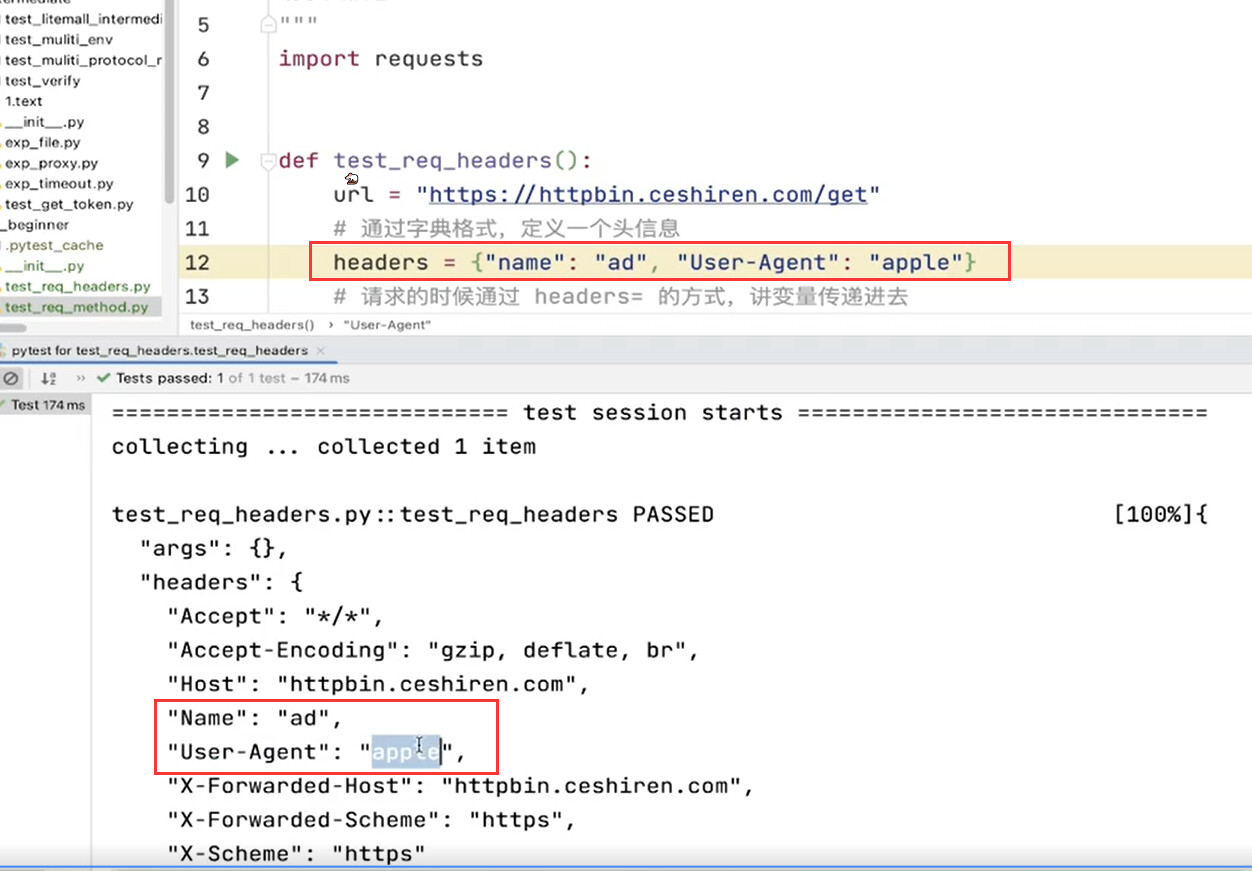
构造头信息
- 使用 headers 参数传入。
- 通常使用字典格式。
headers = {'user-agent': 'my-app/0.0.1'}
r = requests.get(url, headers=headers)
接口请求体 - JSON
目录
- 接口请求体
- JSON 格式请求体介绍
- 如何构造 JSON 格式请求体
接口请求体简介
- 进行HTTP请求时,发送给服务器的数据。
- 数据格式类型可以是JSON、XML、文本、图像等格式。
- 请求体的格式和内容取决于服务器端API的设计和开发人员的要求。

常用接口请求体
| 类型 | 介绍 | Content-type |
|---|---|---|
| JSON(JavaScript Object Notation) | 轻量级的数据交换格式,最常见的一种类型。 | application/json |
| 表单数据(Form Data) | 以键值对的形式提交数据,例如通过 HTML 表单提交数据。 | application/x-www-form-urlencoded |
| XML(eXtensible Markup Language) | 常用的标记语言,通常用于传递配置文件等数据。 | application/xml |
| text/xml | ||
| 文件(File) | 可以通过请求体上传文件数据,例如上传图片、视频等文件。 | 上传文件的 MIME 类型,例如 image/jpeg |
| multipart/form-data | ||
| 纯文本(Text) | 纯文本数据,例如发送邮件、发送短信等场景 | text/plain |
| 其他格式 | 二进制数据、protobuf 等格式 |
JSON 简介
- 是 JavaScript Object Notation 的缩写。
- 是一种轻量级的数据交换格式。
- 是理想的接口数据交换语言。
- Content-Type 为 application/json。
JSON 格式请求体示例
- 进入登录页面。
- 打开开发者工具。
- 输入用户名密码,点击登录。
litemall
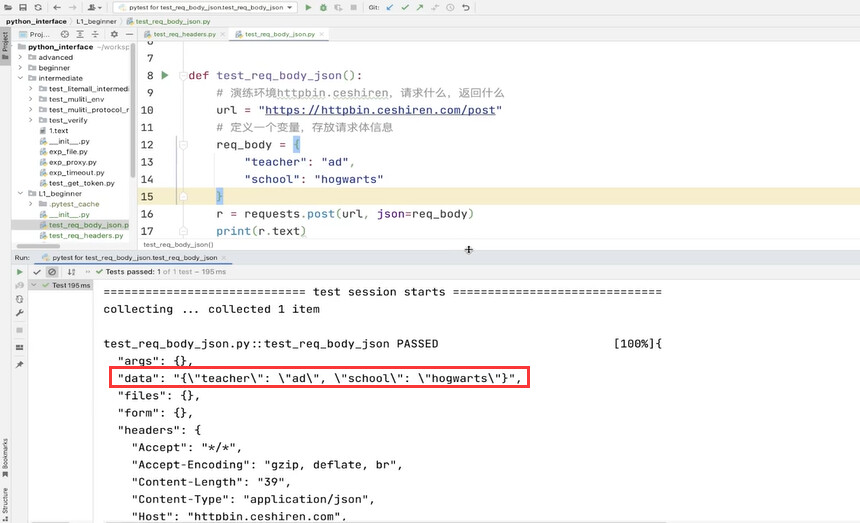
构造 JSON 格式请求体
- 定义为字典格式。
- 使用 json 参数传入。
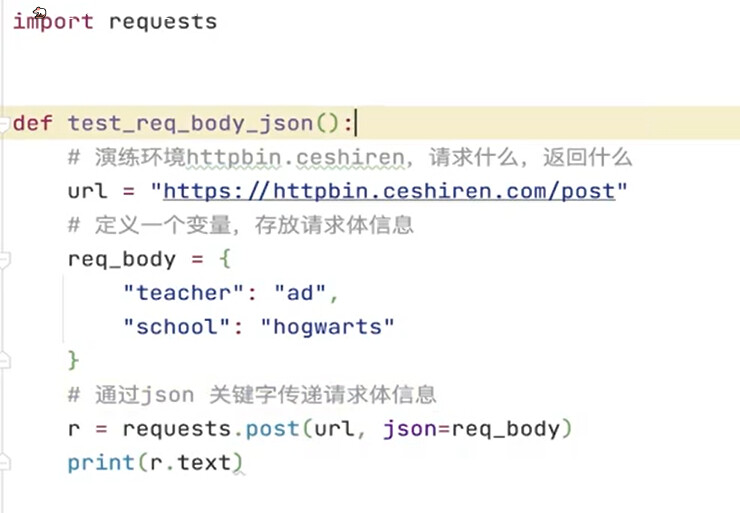
# 导入依赖
import requests
def test_post_json():
# 定义接口的 url 和 json 格式请求体
url = "https://httpbin.ceshiren.com/post"
params = {
"post_key": "post_value"
}
# 发出 POST 请求,r 接收接口响应
r = requests.post(url, json=params)
接口响应断言
目录
- 接口断言使用场景
- 响应结果对象
- 响应结果断言
接口断言使用场景
- 问题:
- 如何确保请求可以发送成功。
- 如何保证符合业务需求。
- 解决方案:
- 通过获取响应信息,验证接口请求是否成功,是否符合业务需求。
Requests 中的响应结果对象
import requests
from requests import Response
# Response就是一个响应对象
r: Response = requests.get('http://www.example.com')
响应结果类型
| 属性 | 含义 |
|---|---|
| r | 响应 Response 对象(可以使用任意的变量名) |
| r.status_code | HTTP 响应状态码 |
| r.headers | 返回一个字典,包含响应头的所有信息。 |
| r.text | 返回响应的内容,是一个字符串。 |
| r.url | 编码之后的请求的 url |
| r.content | 返回响应的内容,是一个字节流。 |
| r.raw | 响应的原始内容 |
| r.json() | 如果响应的内容是 JSON 格式,可以使用该方法将其解析成 Python 对象。 |
# 导入依赖
import requests
def test_res_assert():
# 定义接口的 url 和 json 格式请求体
url = "https://httpbin.ceshiren.com/get"
# 发出 GET 请求,r 接收接口响应
r = requests.post(url)
响应状态码断言
- 基础断言:
r.status_code
import requests
def test_req():
r = requests.get("https://httpbin.ceshiren.com/get")
assert r.status_code == 200
JSON 响应体断言
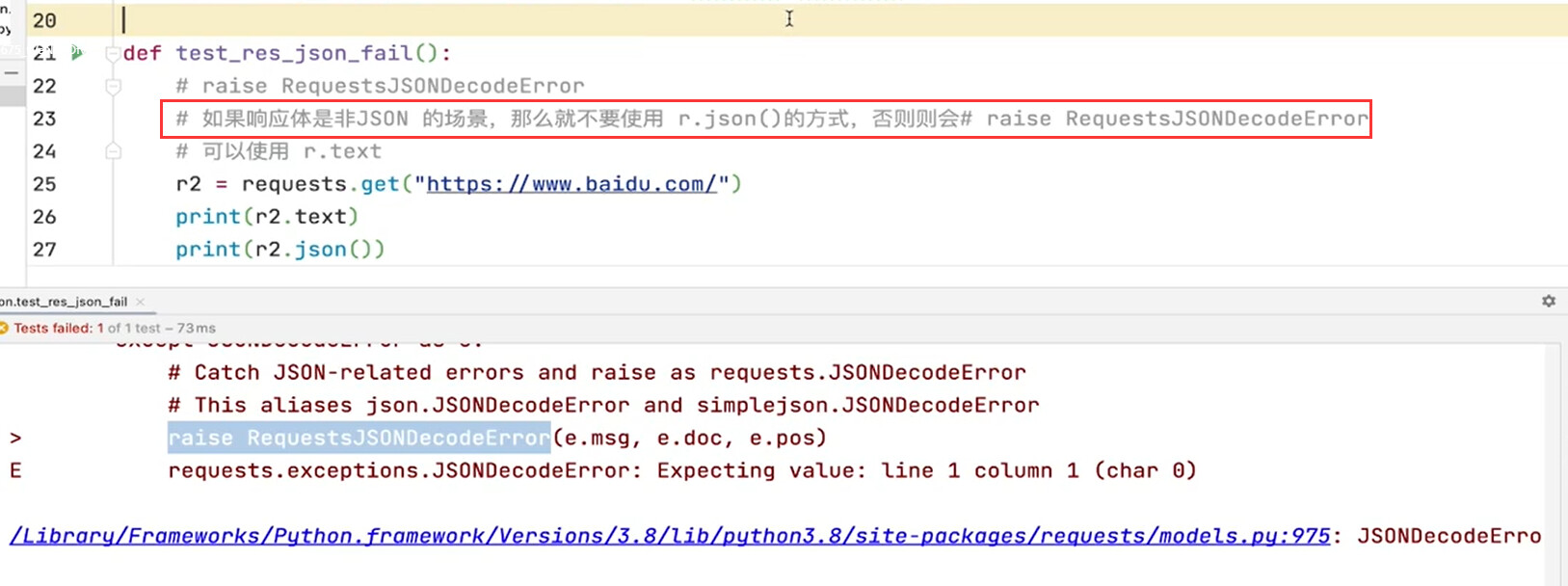
什么是 JSON 响应体
- JSON格式的响应体指的是HTTP响应中的消息体(message body),它是以JSON格式编码的数据。
{
"name": "John",
"age": 30,
"city": "New York"
}
断言 JSON 格式响应体使用场景
- 验证API接口的返回结果是否符合预期。
- 业务场景上是否符合预期。
- 格式是否符合文档规范。
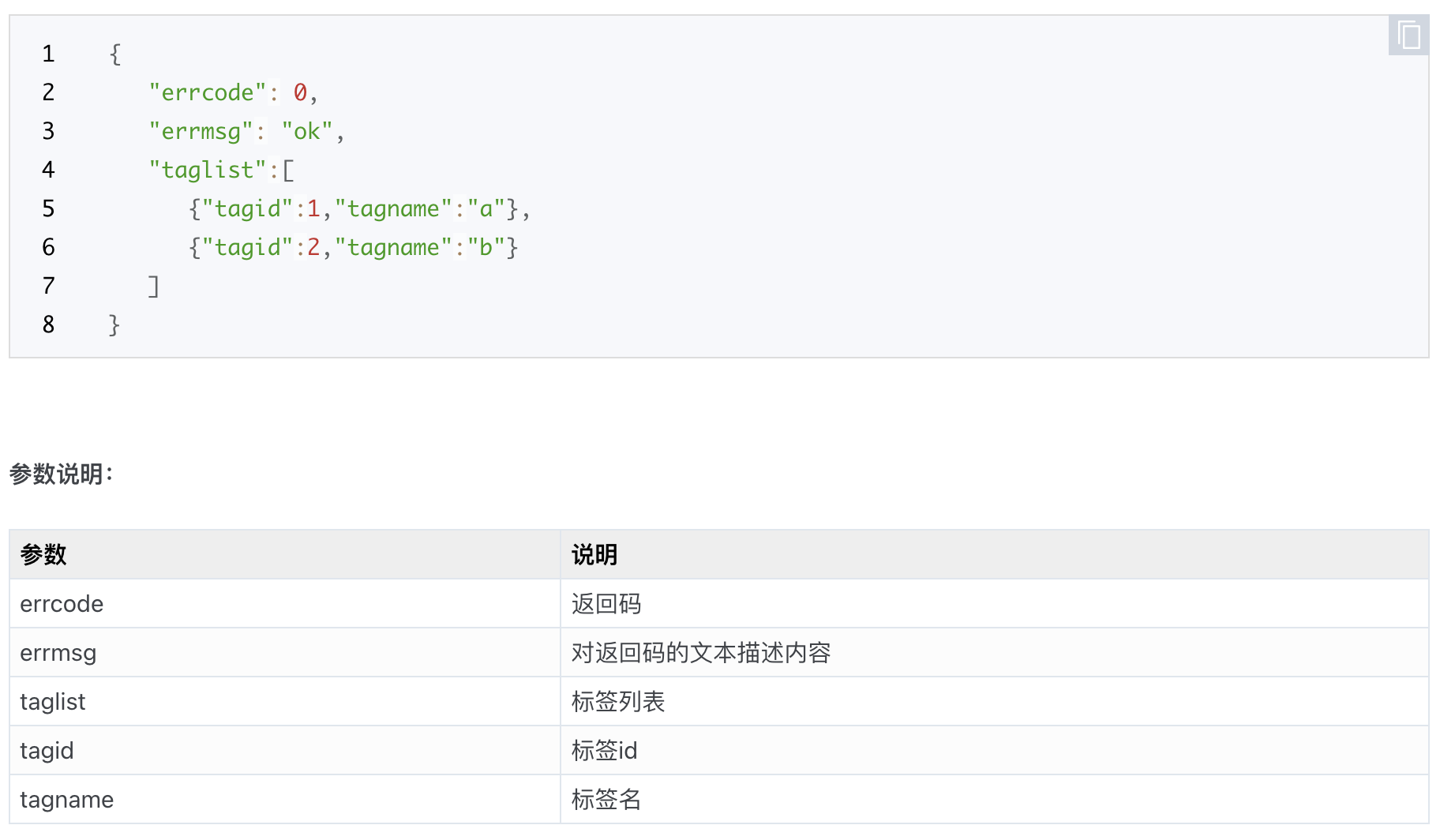
断言 JSON 格式响应体
-
r.json():返回 python 字典。
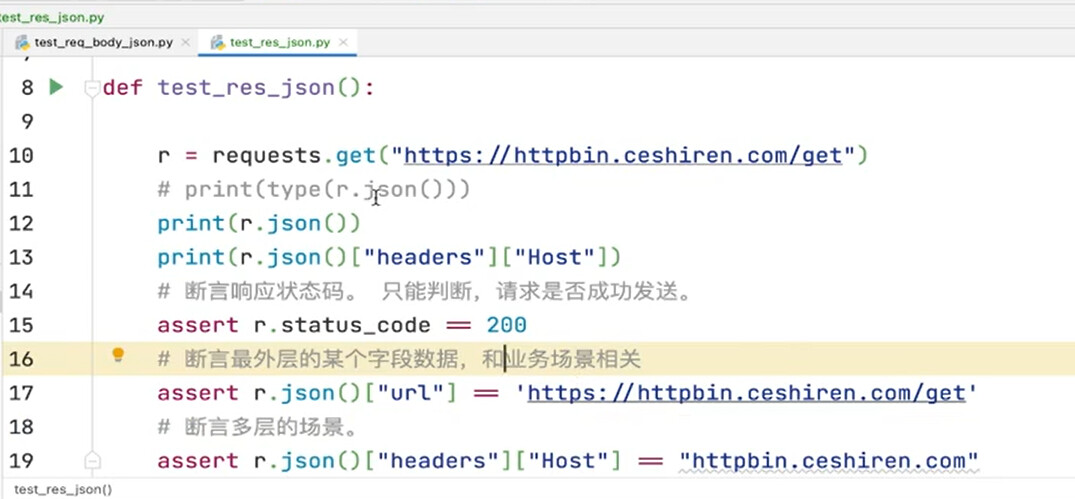
import requests
def test_res_json():
r = requests.get("https://httpbin.ceshiren.com/get")
assert r.status_code == 200
assert r.json()["url"] == "https://httpbin.ceshiren.com/get"
若碰到复杂断言应该如何处理?
- 多层嵌套的数据提取与断言: JSONPath
- 整体结构响应断言: JSONSchema
- 自行编写解析算法
宠物商店接口自动化测试实战

目录
- 被测产品
- 需求说明
- 相关知识点
- 接口自动化测试实战
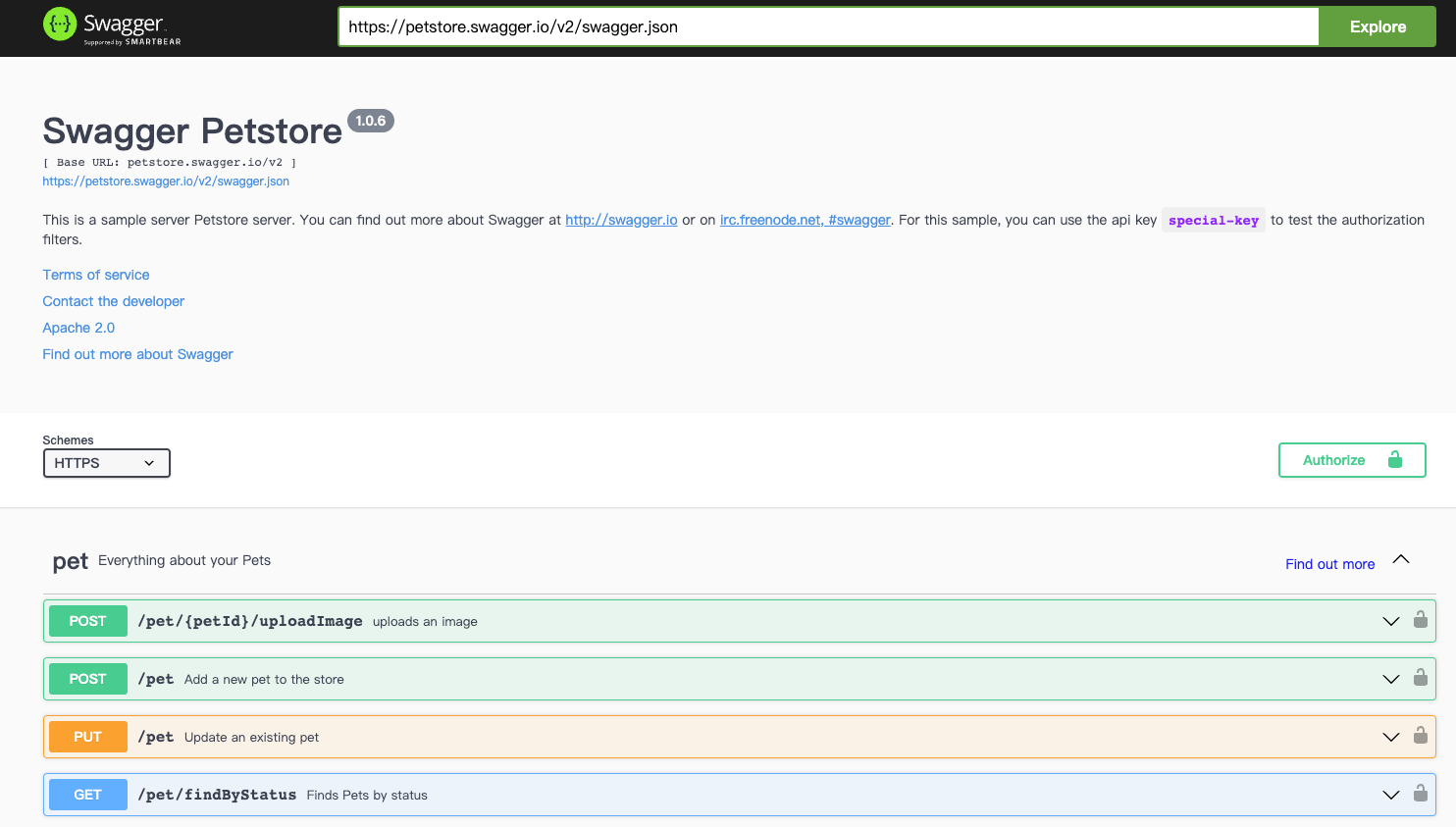
被测产品
- PetStore 宠物商城:
- 一个在线的小型的商城。
- 主要提供了增删查改等操作接口。
- 结合 Swagger 实现了接口的管理。
需求说明
- 完成宠物商城宠物查询功能接口自动化测试。
- 编写自动化测试脚本。
- 完成断言。
相关知识点
| 形式 | 章节 | 描述 |
|---|---|---|
| 知识点 | 接口请求方法 | http 接口请求方法构造 |
| 知识点 | 接口请求参数 | http 接口请求参数构造 |
| 知识点 | 接口请求体-json | http 接口请求体为 json 格式 |
| 知识点 | 接口响应断言 | http 接口响应状态码断言 |
实战思路
@startmindmap
scale 10
* 实战思路
** 需求分析
** 接口测试用例设计
** 编写接口自动化测试脚本
*** 脚本优化-添加日志
*** 脚本优化-参数化
** 生成测试报告
@endmindmap
宠物商店需求分析
- 被测产品:宠物商店系统 - 查询宠物信息
- 宠物商店接口文档:https://petstore.swagger.io/
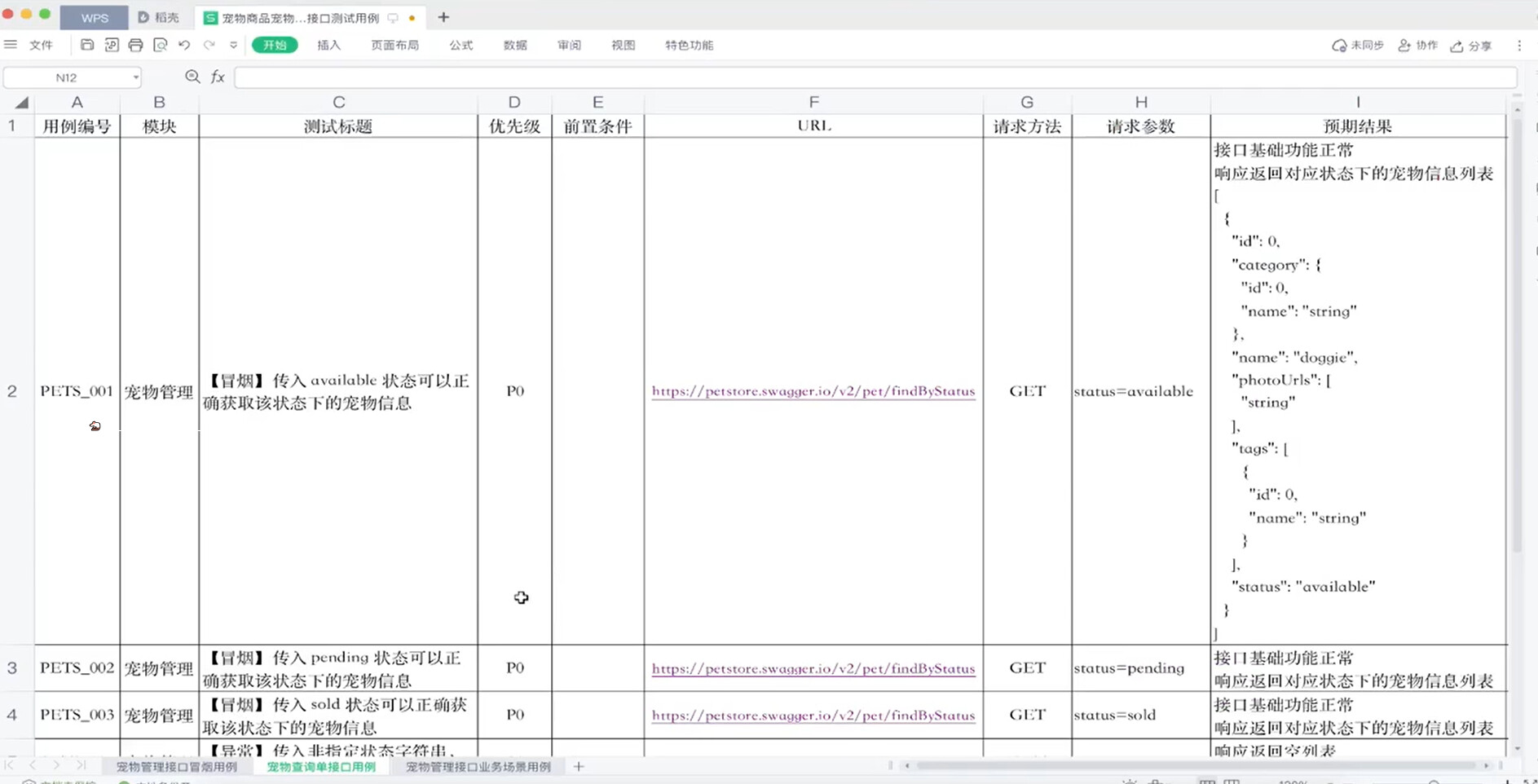
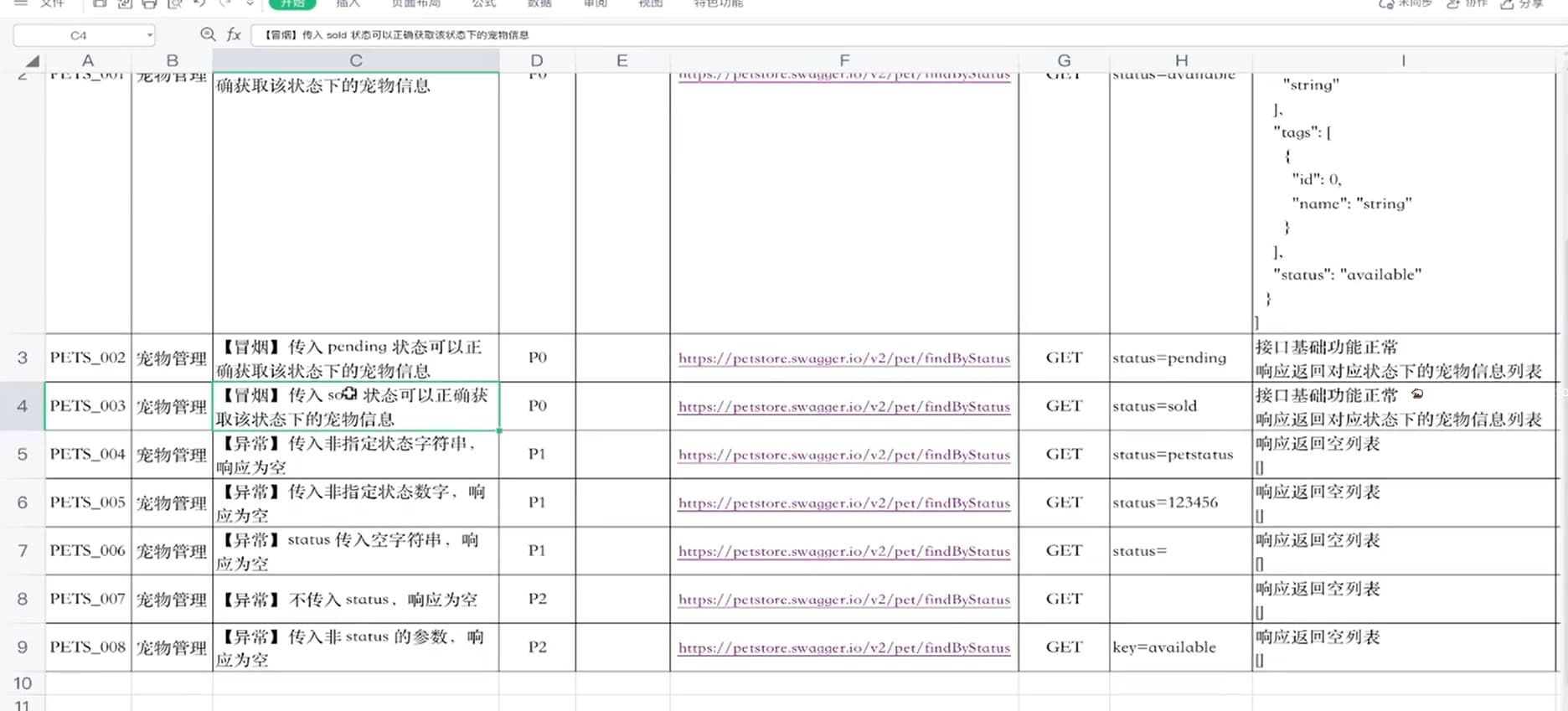
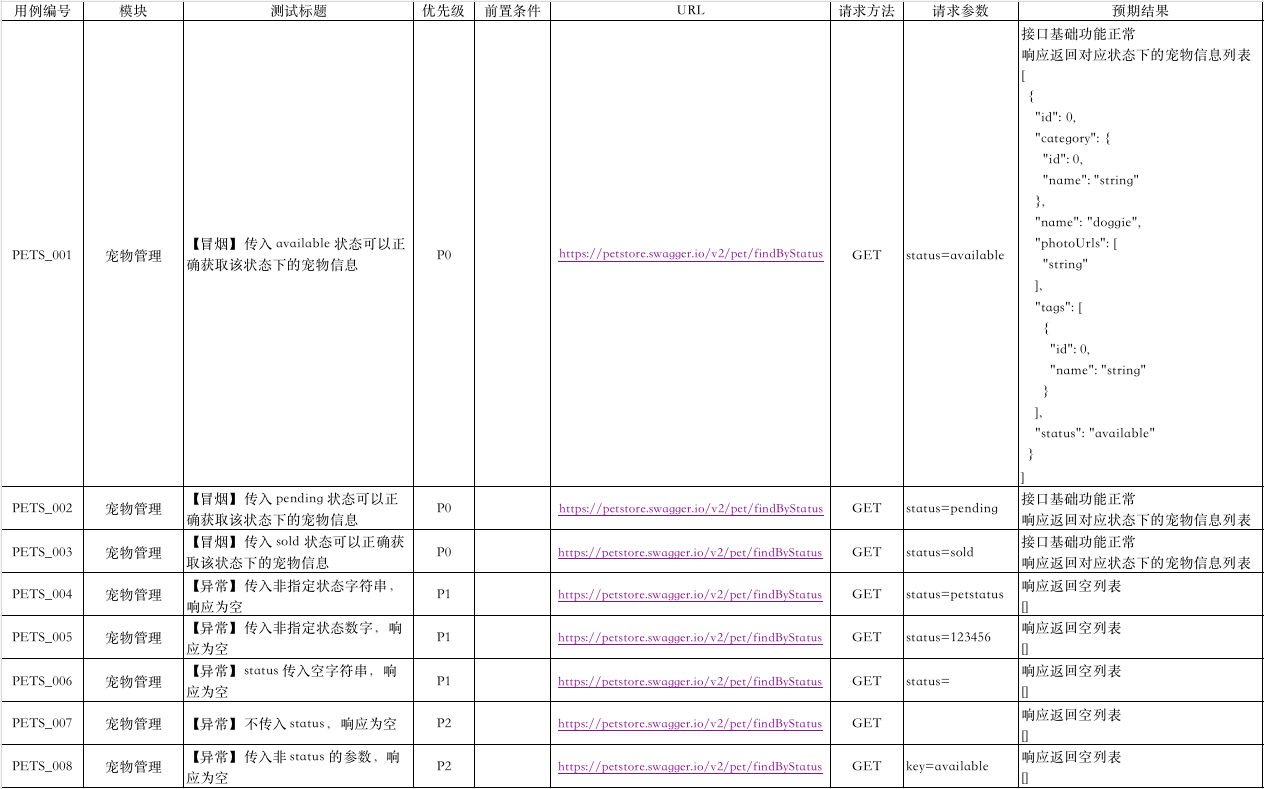
接口测试用例设计
- 宠物查询单接口用例
编写接口自动化测试脚本思路
- 查询宠物信息。
@startmindmap
scale 3
* 思路
** 获取接口信息
*** swagger 接口文档
*** 前端抓包
** 单步调通接口
** 添加断言,确认流程正常
@endmindmap
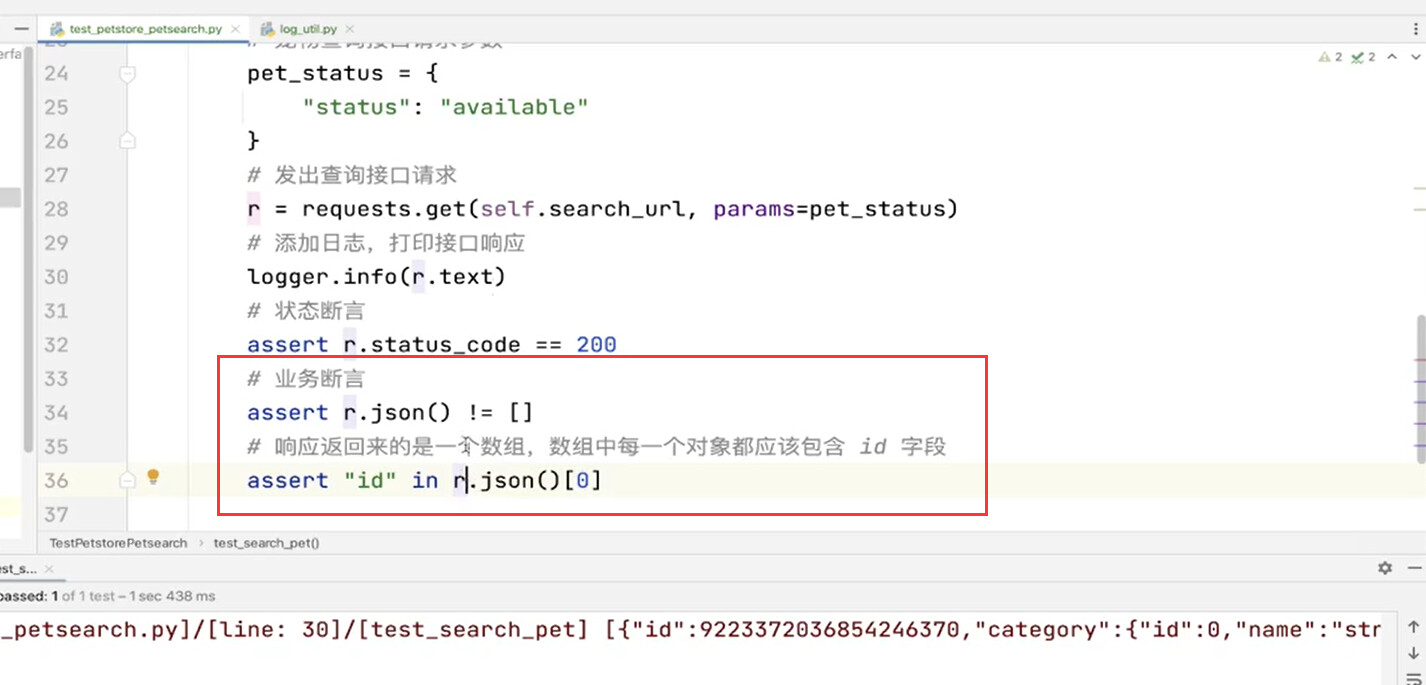
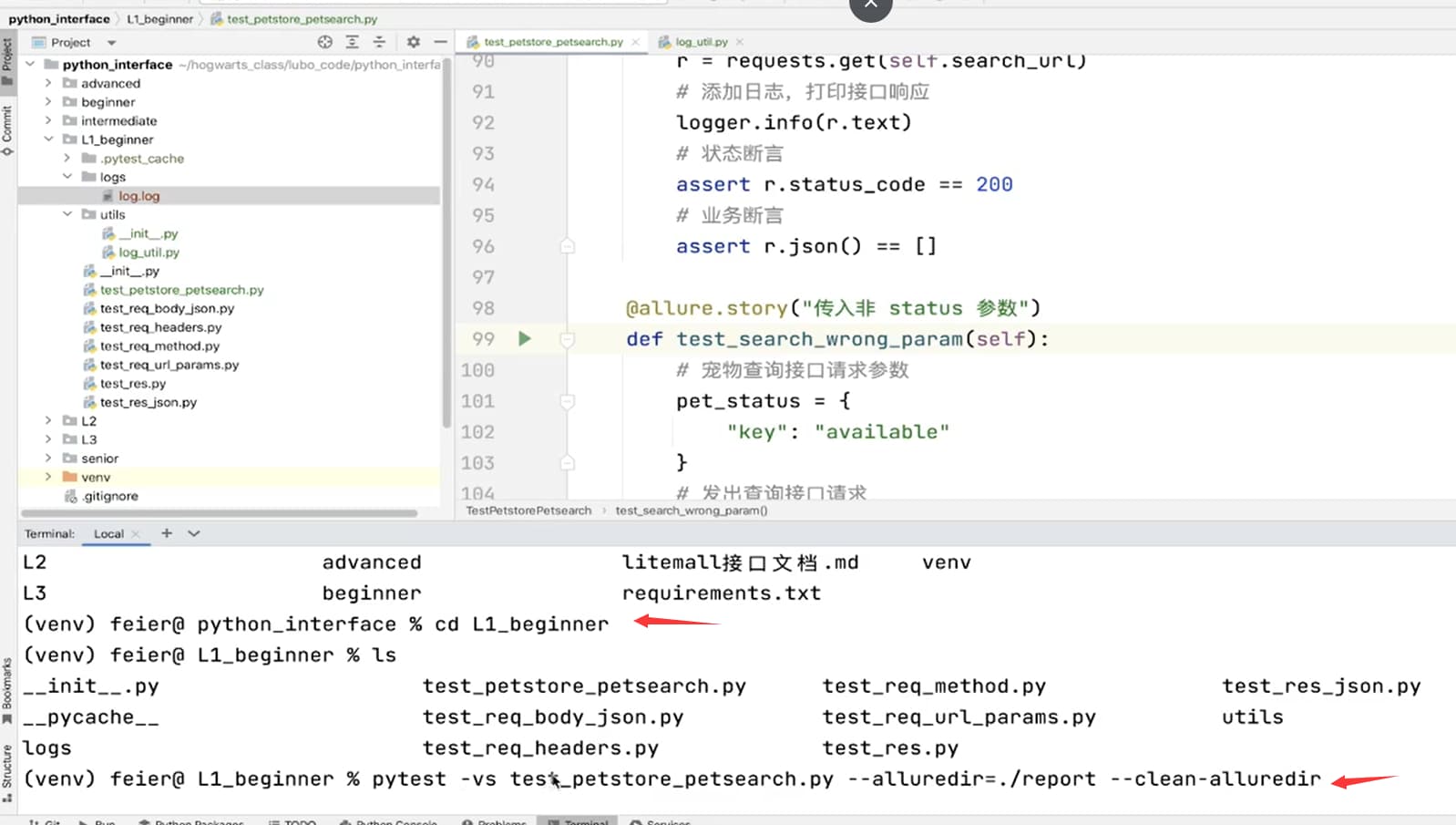
编写自动化测试脚本
class TestPetstorePetsearch:
def setup_class(self):
# 定义接口请求 URL
self.base_url = "https://petstore.swagger.io/v2/pet"
self.search_url = self.base_url + "/findByStatus"
def test_search_pet(self):
# 查询接口请求参数
params = {
"status": "available"
}
# 发出查询请求
r = requests.get(self.search_url, params=params)
# 状态断言
assert r.status_code == 200
# 业务断言
assert r.json() != []
脚本优化 - 添加日志
- 新建日志配置。
- 在用例中使用配置好的日志实例。
# 配置日志
import logging
import os
from logging.handlers import RotatingFileHandler
# 绑定绑定句柄到logger对象
logger = logging.getLogger(__name__)
# 获取当前工具文件所在的路径
root_path = os.path.dirname(os.path.abspath(__file__))
# 拼接当前要输出日志的路径
log_dir_path = os.sep.join([root_path, '..', f'/logs'])
if not os.path.isdir(log_dir_path):
os.mkdir(log_dir_path)
# 创建日志记录器,指明日志保存路径,每个日志的大小,保存日志的上限
file_log_handler = RotatingFileHandler(os.sep.join([log_dir_path, 'log.log']), maxBytes=1024 * 1024, backupCount=10)
# 设置日志的格式
date_string = '%Y-%m-%d %H:%M:%S'
formatter = logging.Formatter(
'[%(asctime)s] [%(levelname)s] [%(filename)s]/[line: %(lineno)d]/[%(funcName)s] %(message)s ', date_string)
# 日志输出到控制台的句柄
stream_handler = logging.StreamHandler()
# 将日志记录器指定日志的格式
file_log_handler.setFormatter(formatter)
stream_handler.setFormatter(formatter)
# 为全局的日志工具对象添加日志记录器
# 绑定绑定句柄到logger对象
logger.addHandler(stream_handler)
logger.addHandler(file_log_handler)
# 设置日志输出级别
logger.setLevel(level=logging.INFO)
脚本优化 - 参数化
- 使用 pytest parametrize 装饰器实现宠物状态的参数化。
@pytest.mark.parametrize("status",
["available", "pending", "sold"]
)
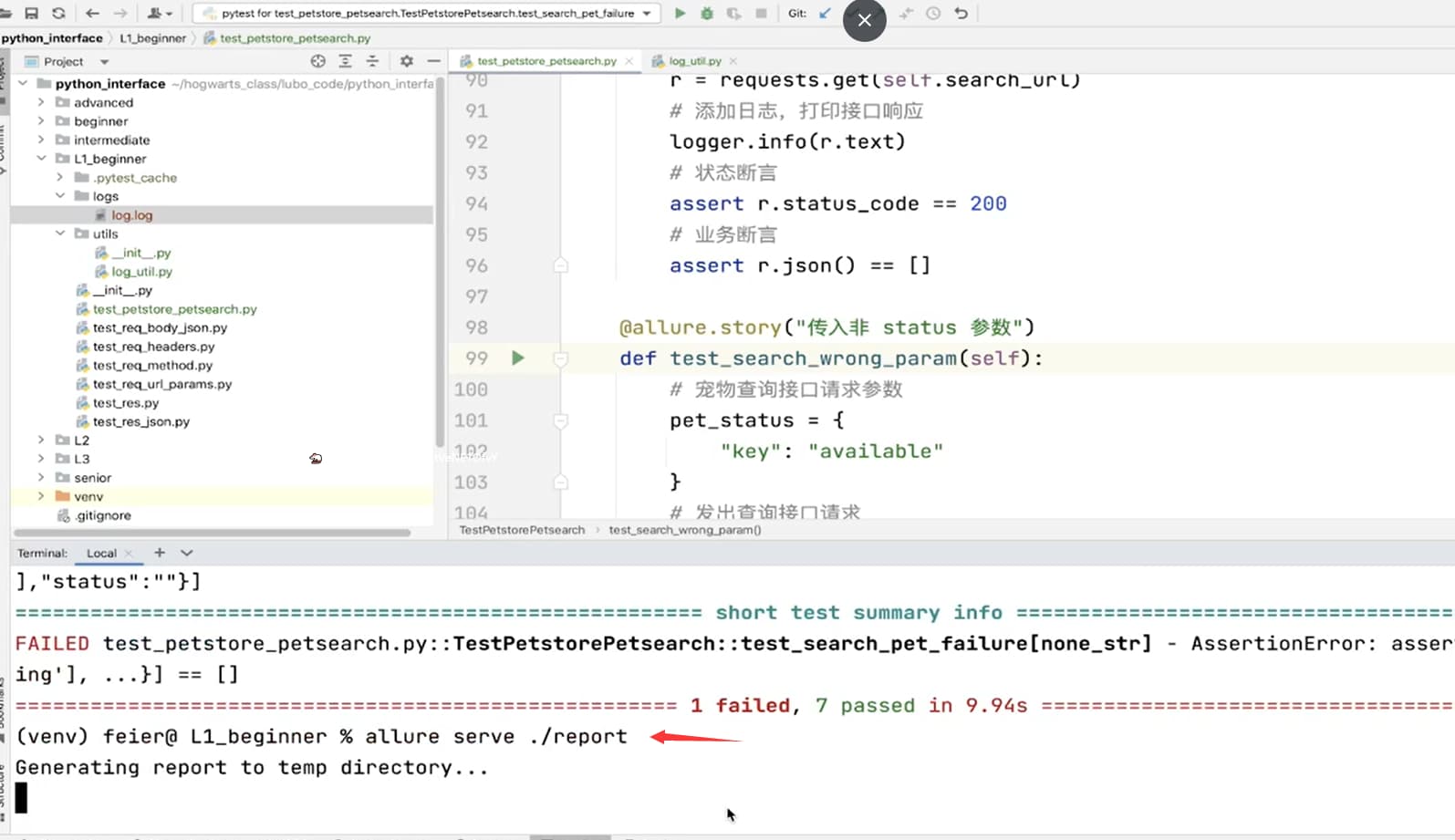
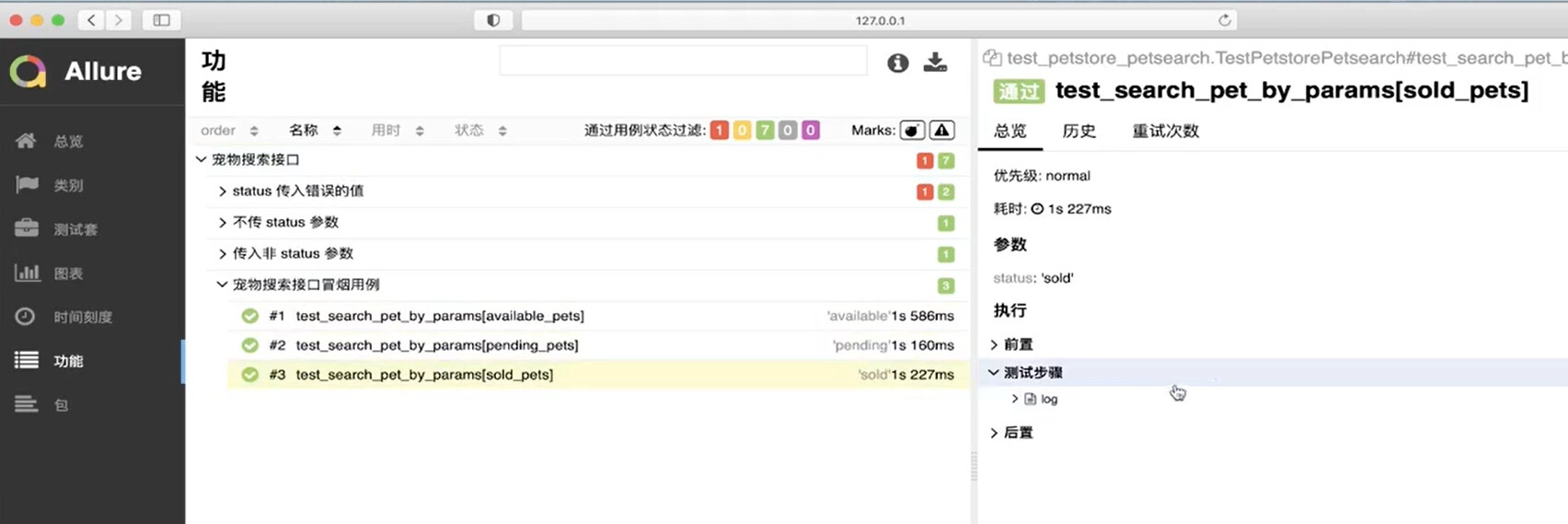
生成测试报告
- 安装 allure 相关依赖。
# 生成报告信息
pytest --alluredir=./report
# 生成报告在线服务,查看报告
allure serve ./report/
总结
- 通过 Swagger 文档获取接口信息。
- 使用 Requests 发出携带请求参数的 GET 请求。
- 断言响应符合是否符合预期。
- 添加 Log 日志。
- 使用参数化方式实现一条用例可执行多个测试数据。
- 生成 Allure 测试报告。
接口请求体 - 文件
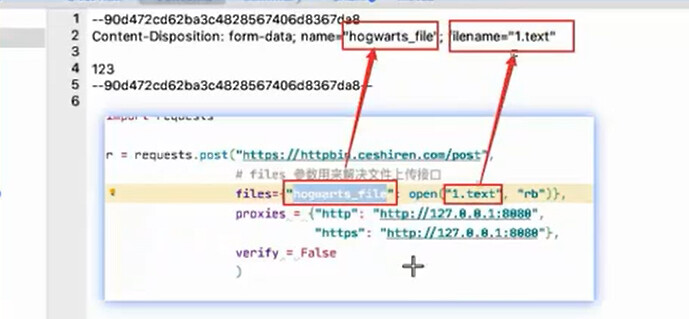
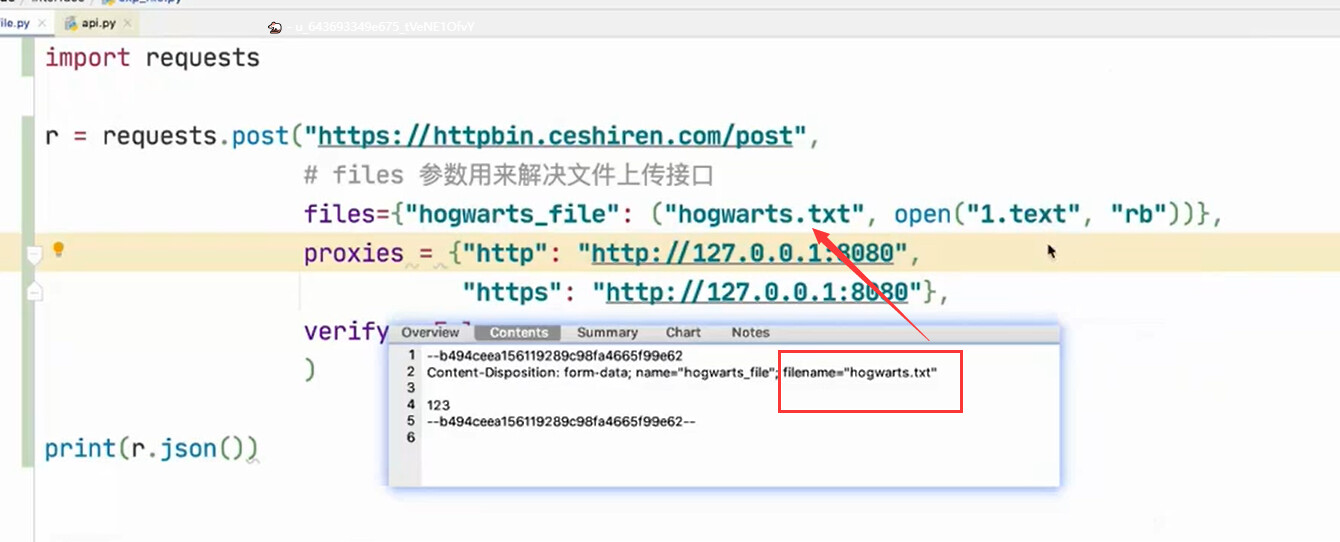
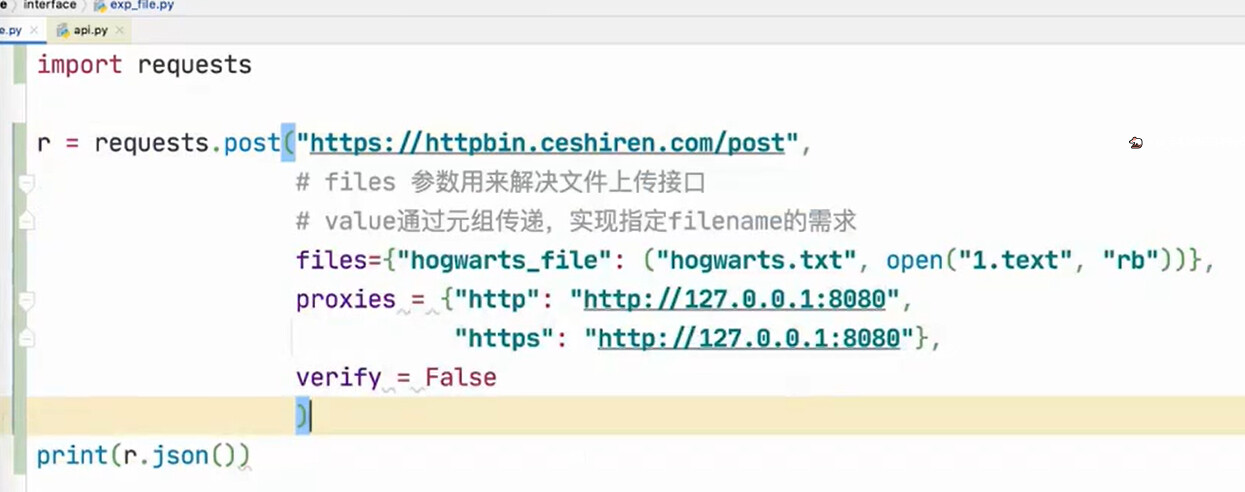
通过接口上传文件
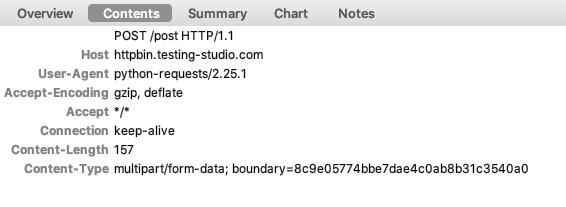
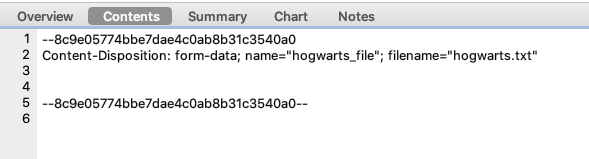
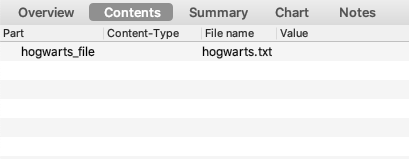
文件上传的由来
- 1867 文档中说明文件上传是一种常见的需要求,但是使用html中的form表单格式却不支持,
- 提出了一种兼容此需求的mime type。
使用 requests 如何上传
r = requests.post("https://httpbin.ceshiren.com/post",
files={"hogwarts_file": open("hogwarts.txt", "rb")})
接口请求体 - FORM 请求
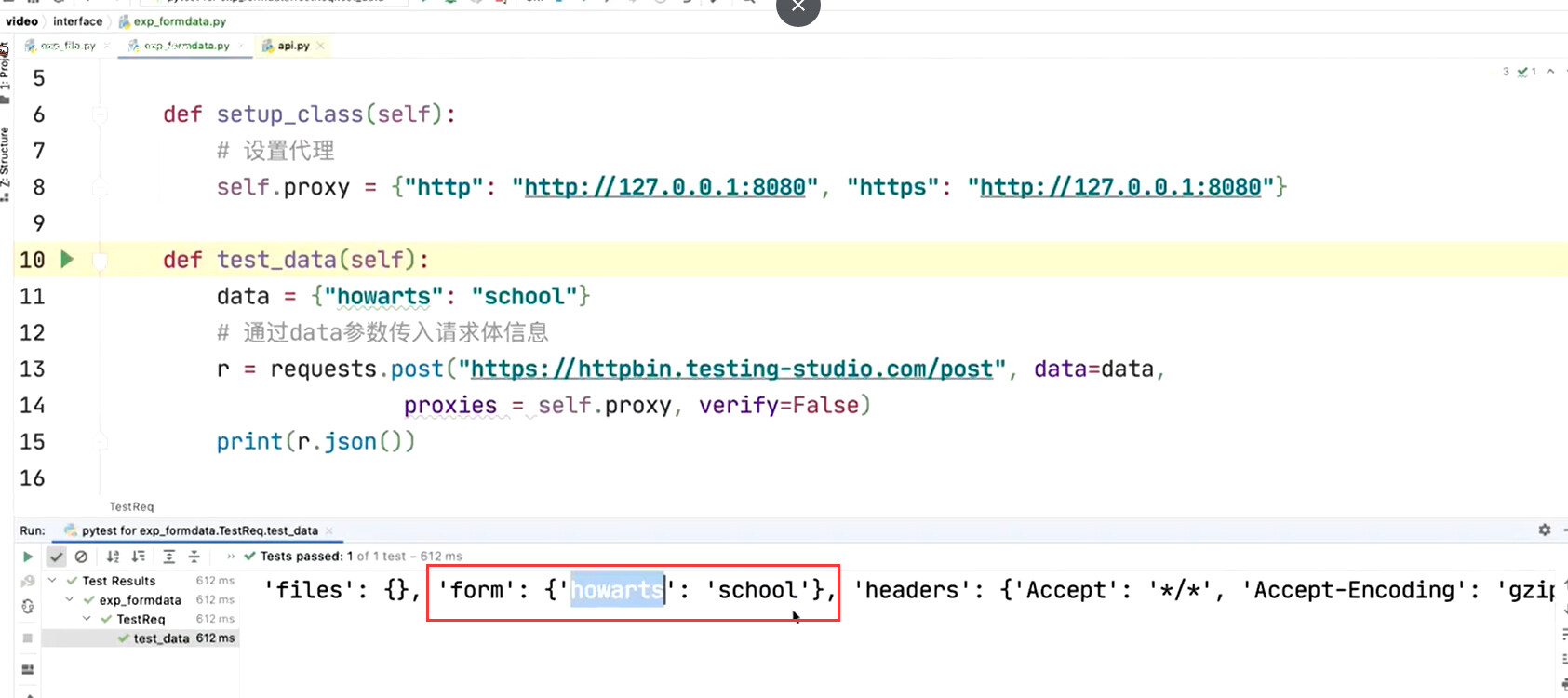
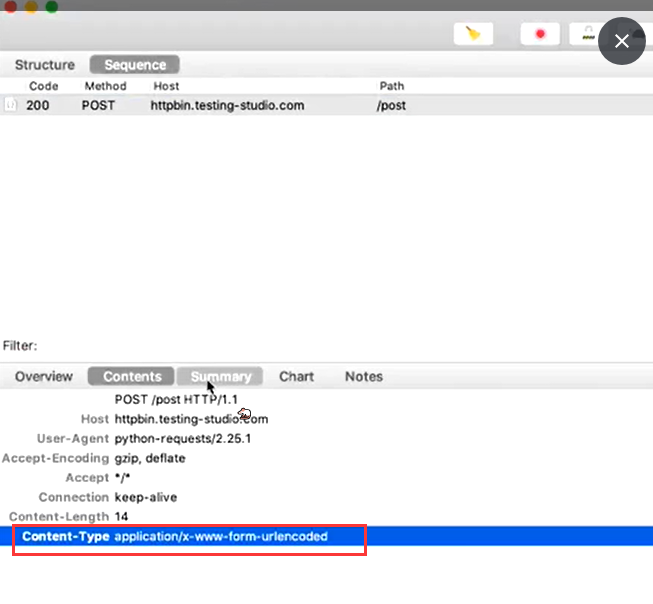
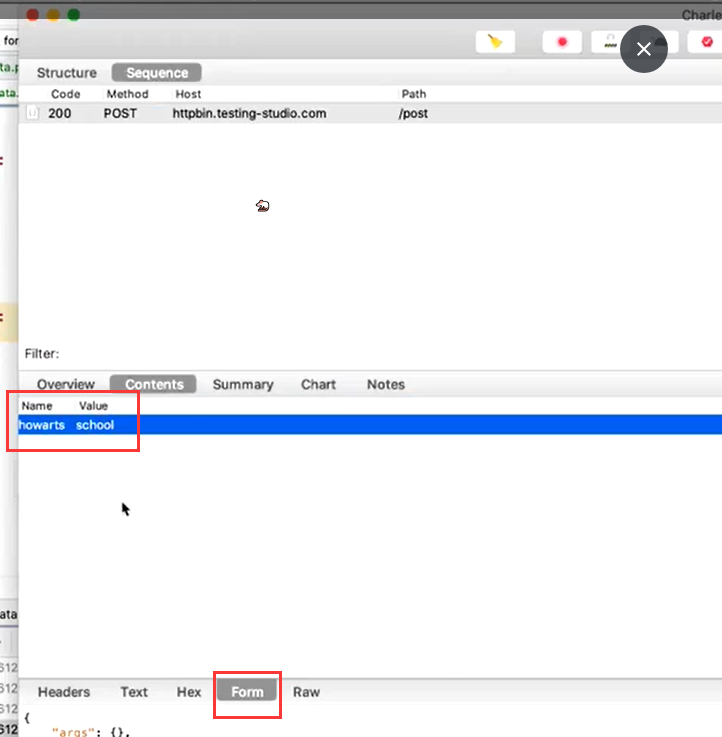
什么是 FORM 请求
- 数据量不大
- 数据层级不深的情况
- 通常以键值对传递
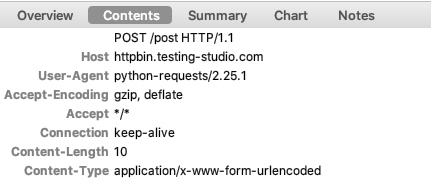
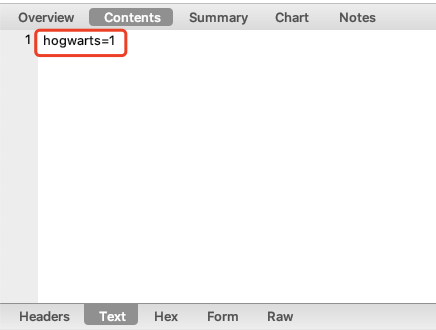
如何使用
r = requests.post("https://httpbin.ceshiren.com/post",
data=data)
接口请求体-xml



XML 响应断言


什么是 XML
- 可扩展标记语言(Extensible Markup Language)的缩写
- 也是一种结构化的数据
XML 断言
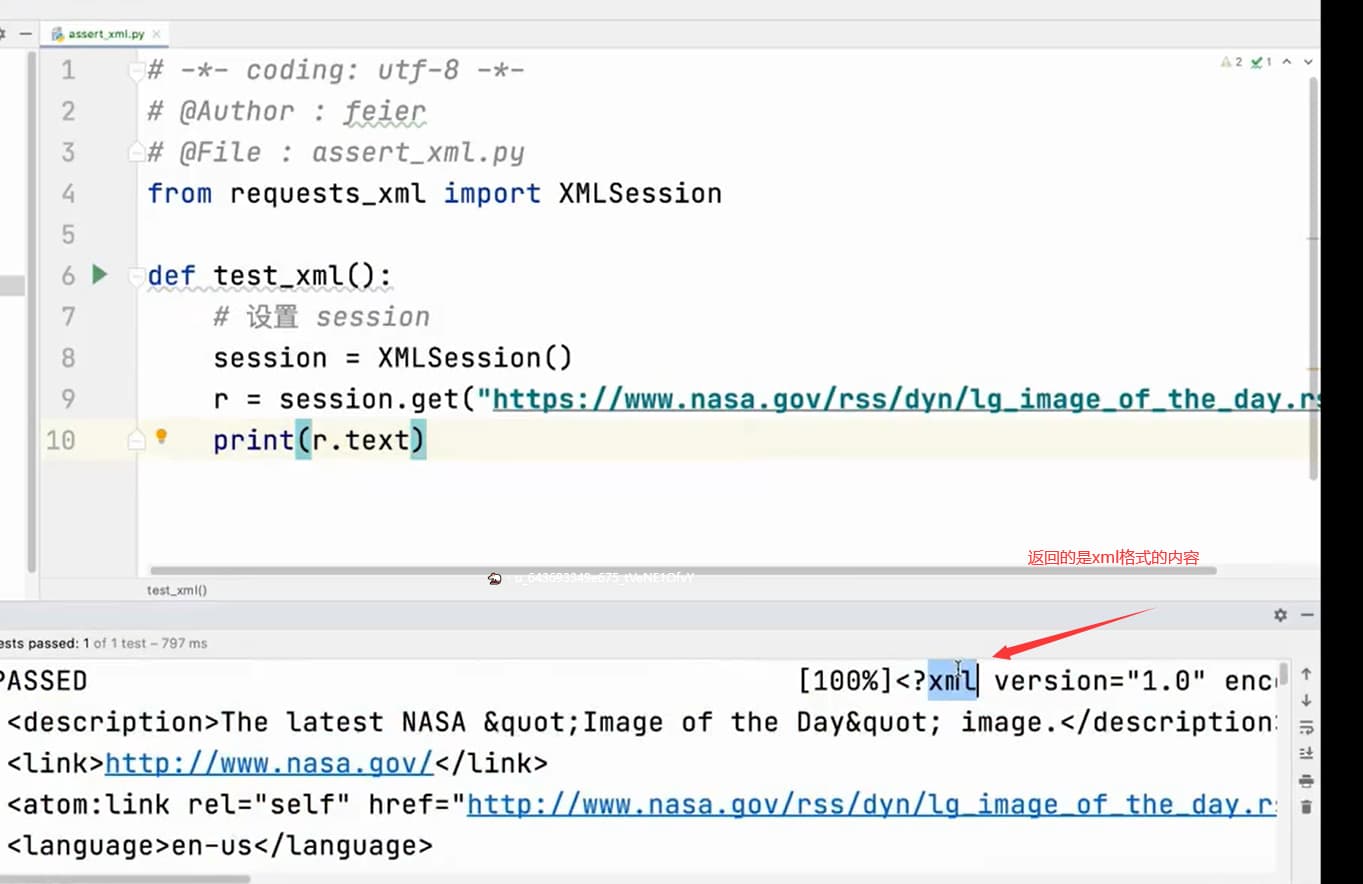
from requests_xml import XMLSession
session = XMLSession()
r = session.get('https://www.nasa.gov/rss/dyn/lg_image_of_the_day.rss')
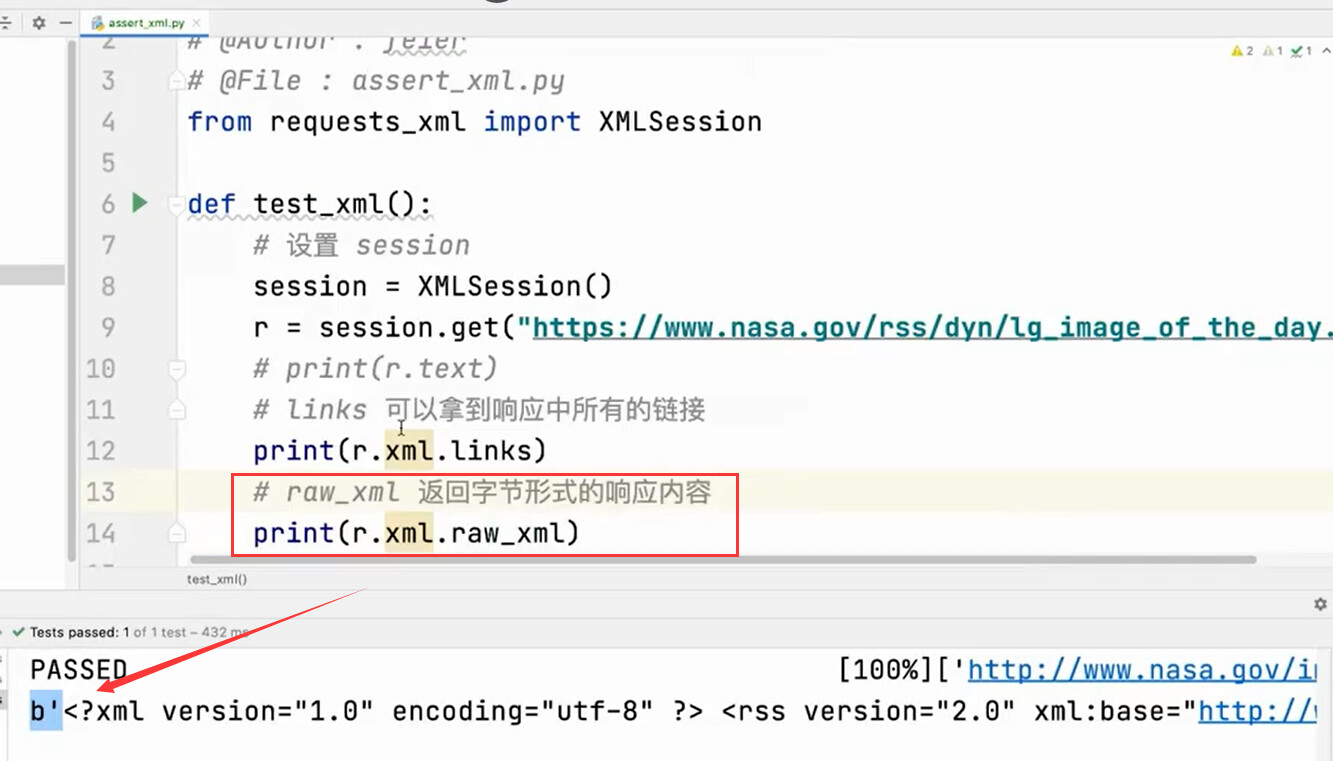
r.xml.links
XPath 断言
from requests_xml import XMLSession
session = XMLSession()
r = session.get('https://www.nasa.gov/rss/dyn/lg_image_of_the_day.rss')
r.xml.links
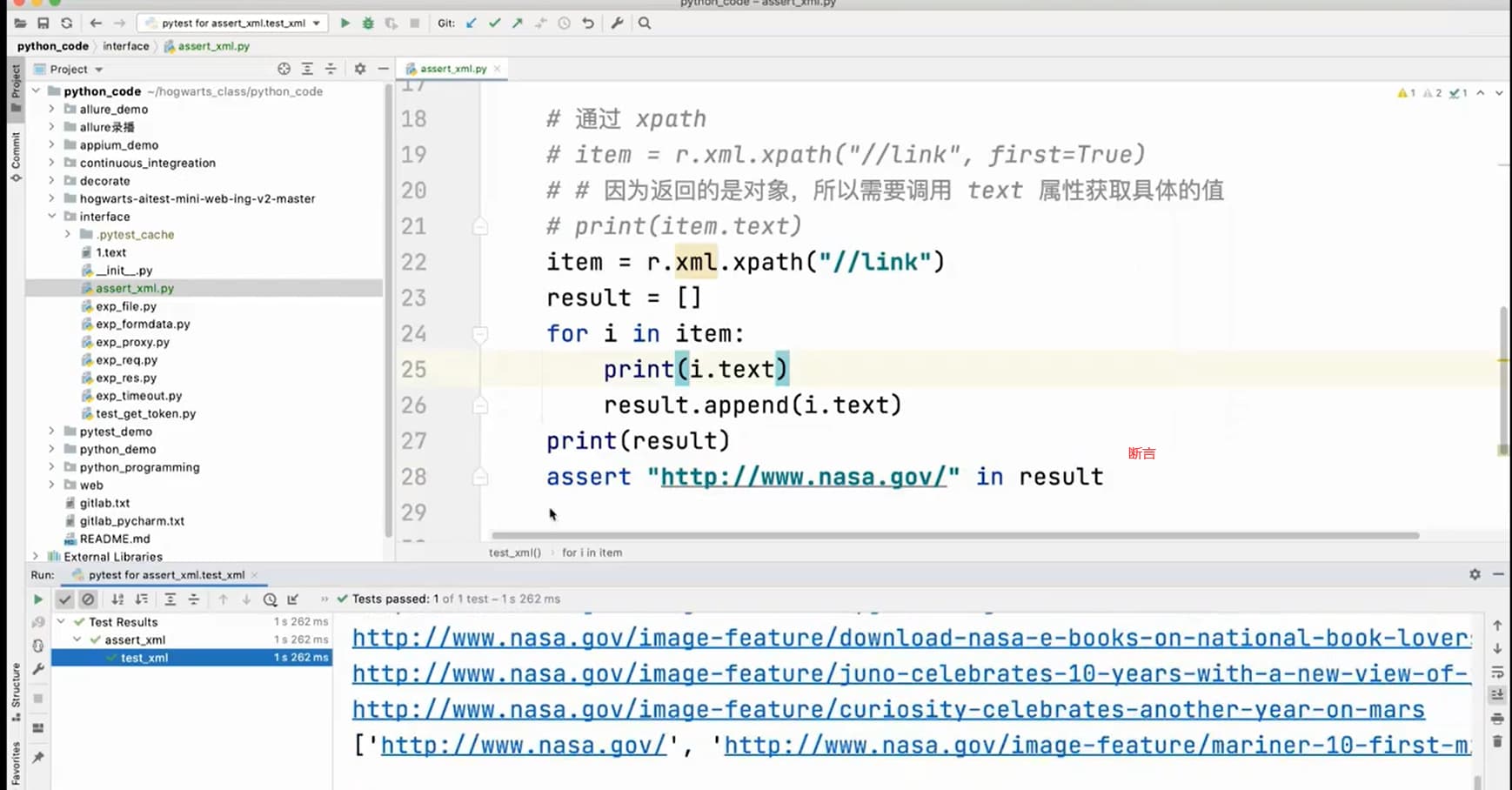
item = r.xml.xpath('//item', first=True)
print(item.text)
XML 解析
import xml.etree.ElementTree as ET
root = ET.fromstring(countrydata)
root.findall(".")
root.findall("./country/neighbor")
root.findall(".//year/..[@name='Singapore']")
root.findall(".//*[@name='Singapore']/year")
root.findall(".//neighbor[2]")
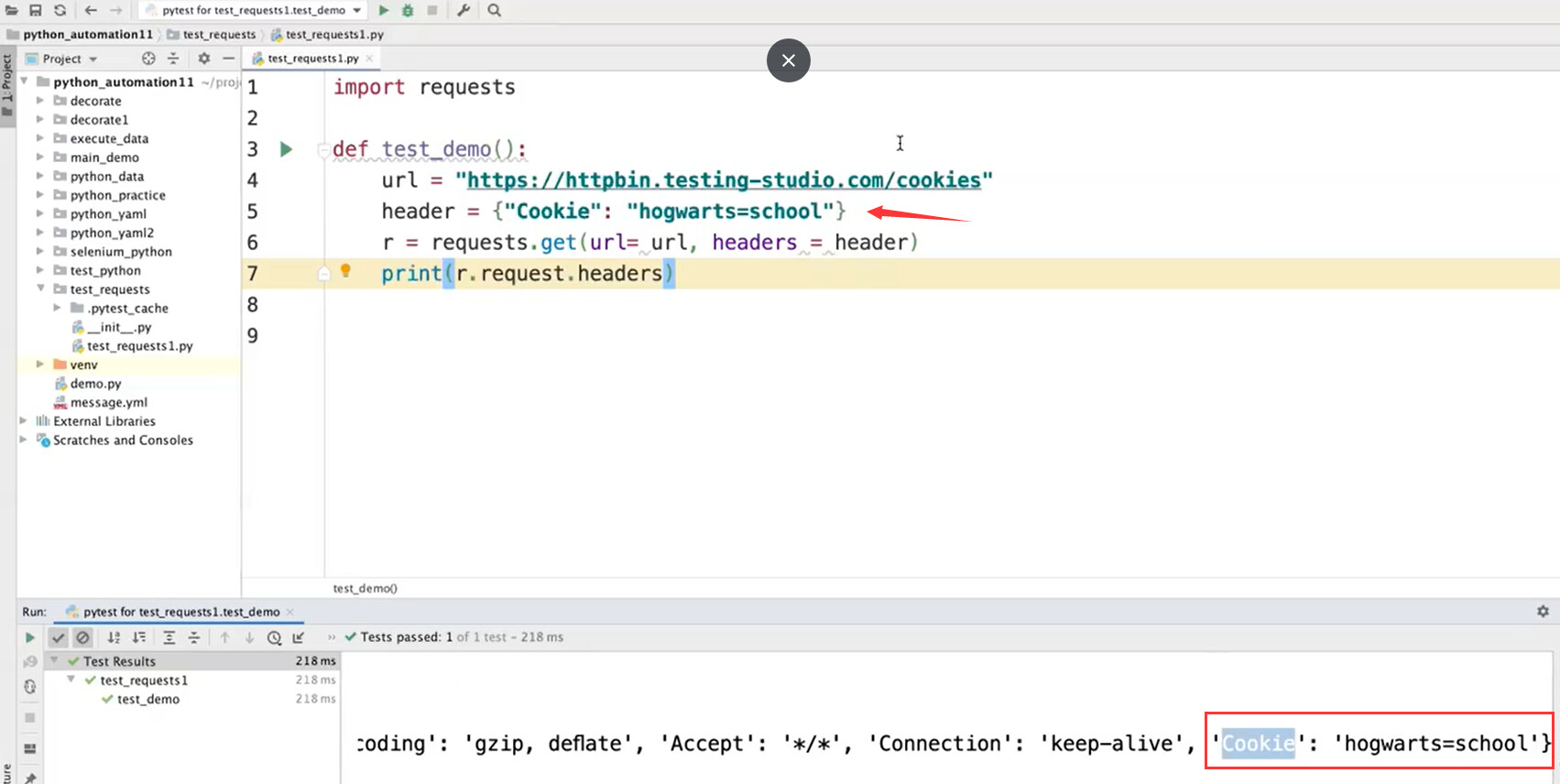
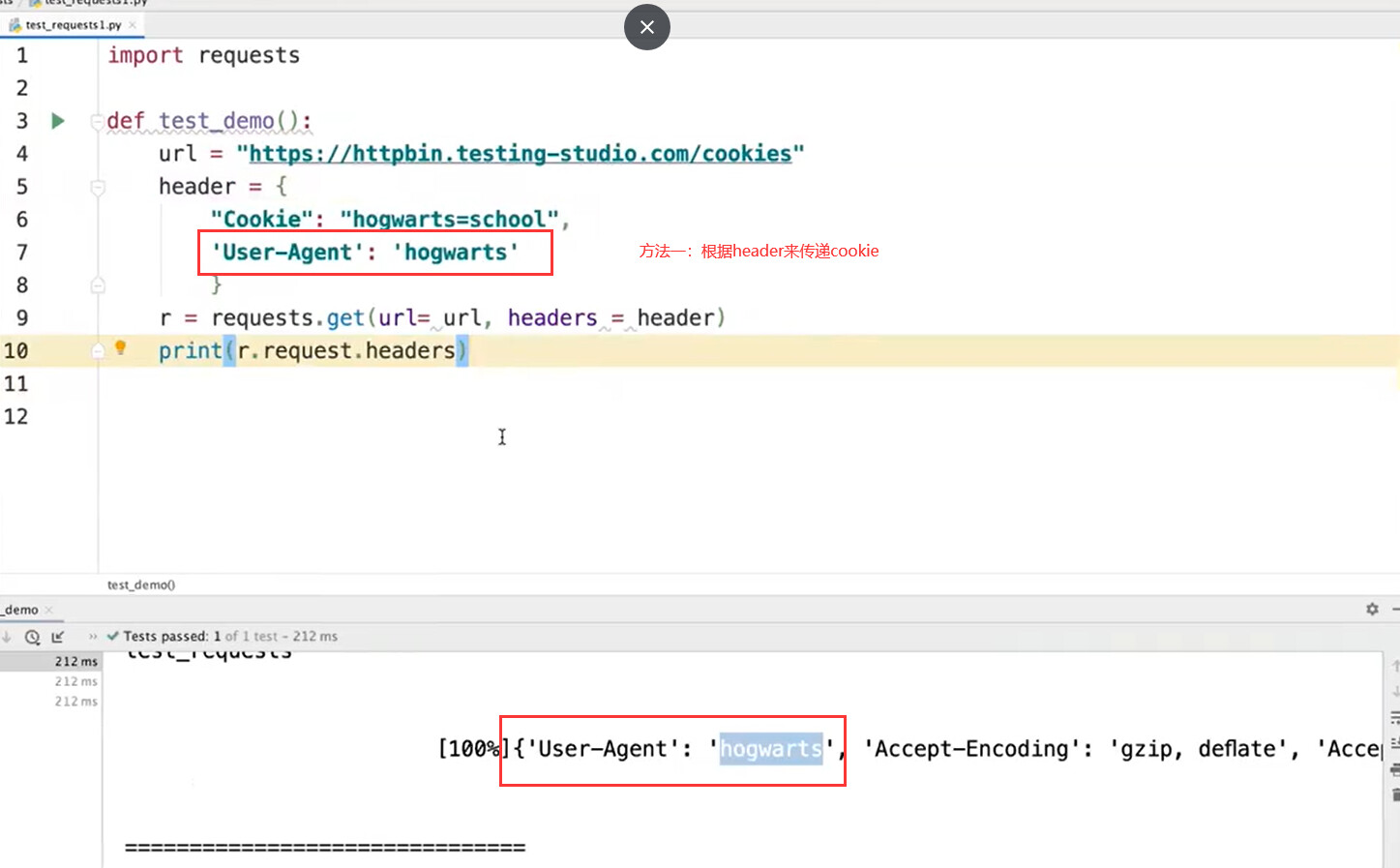
##cookie处理




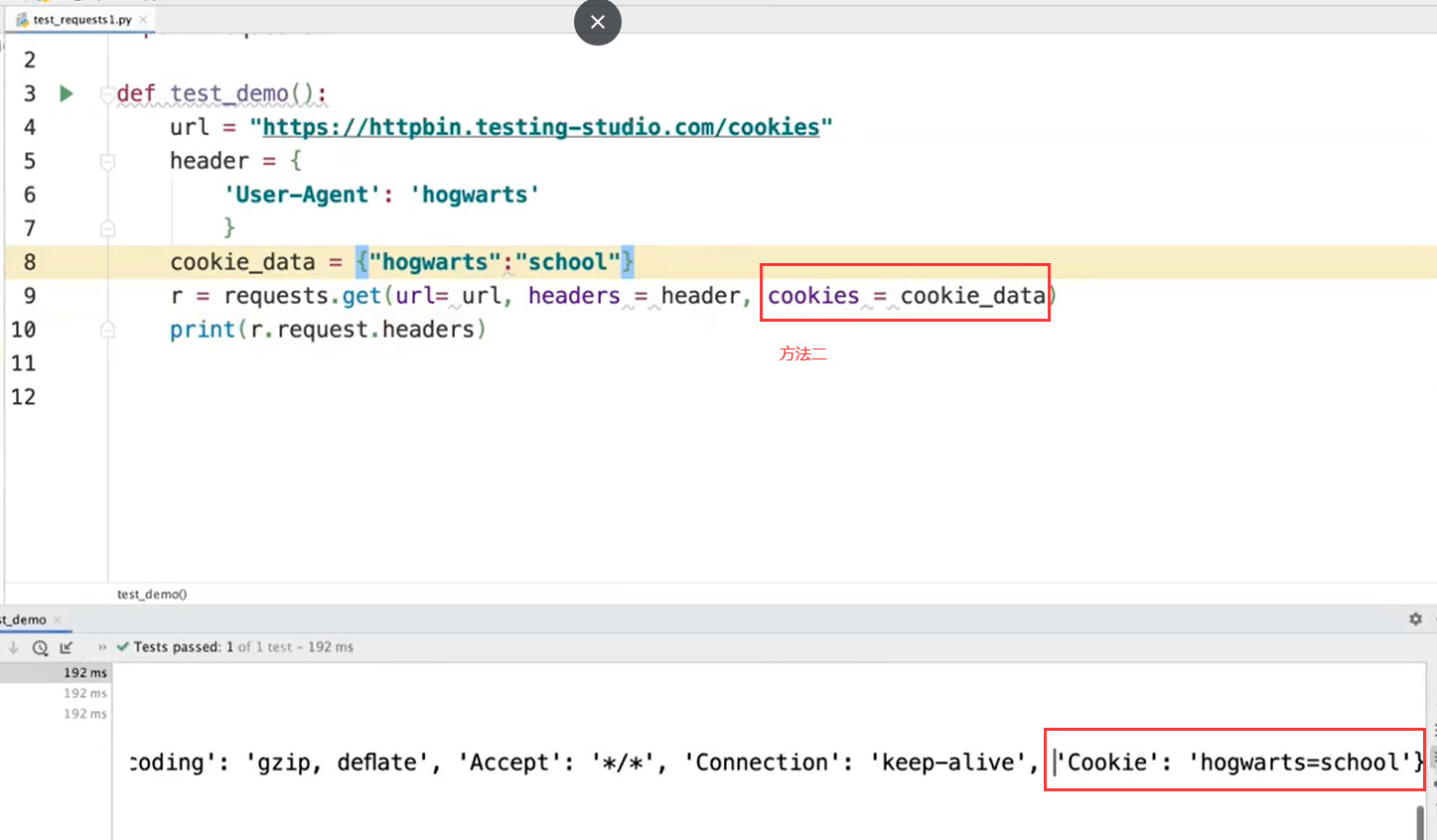
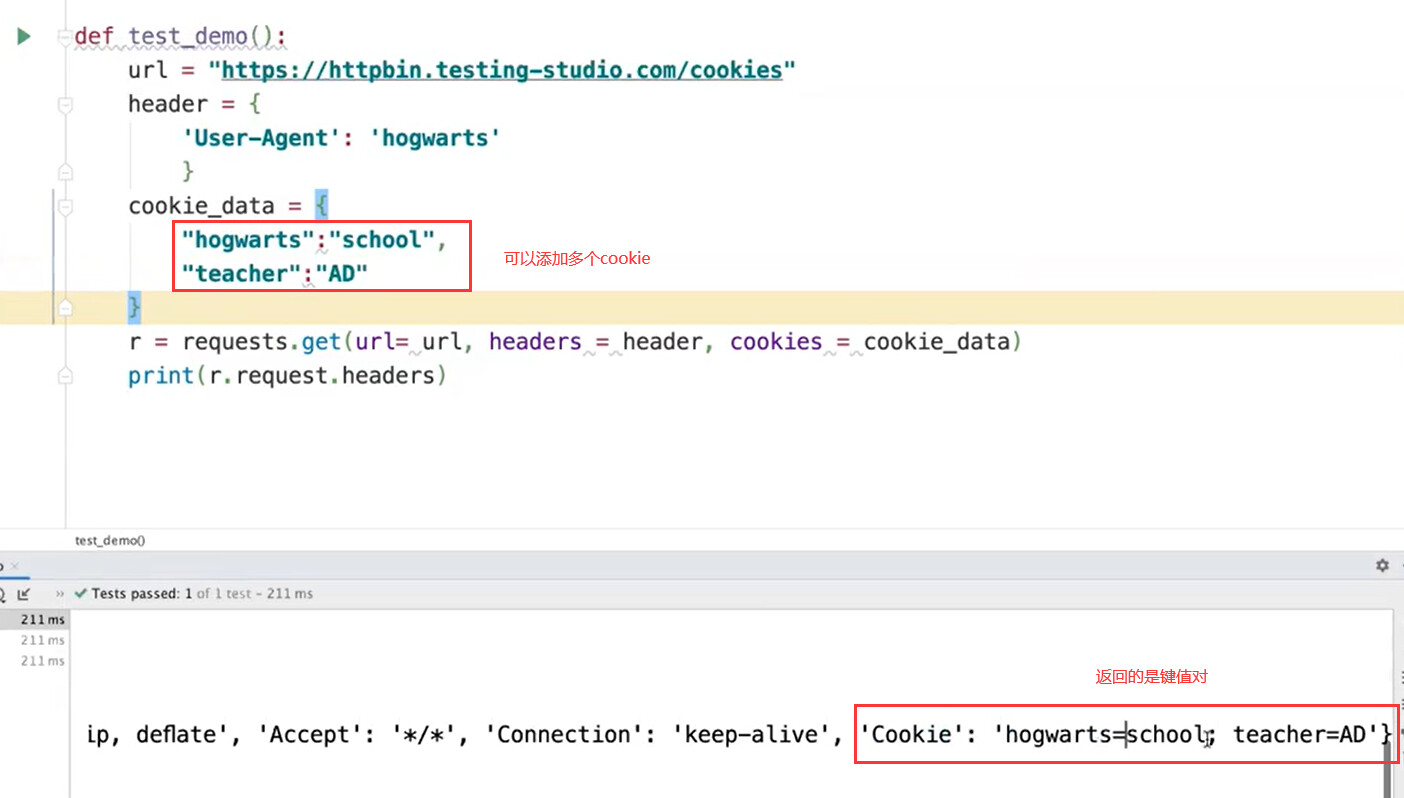
超时处理
请求超时
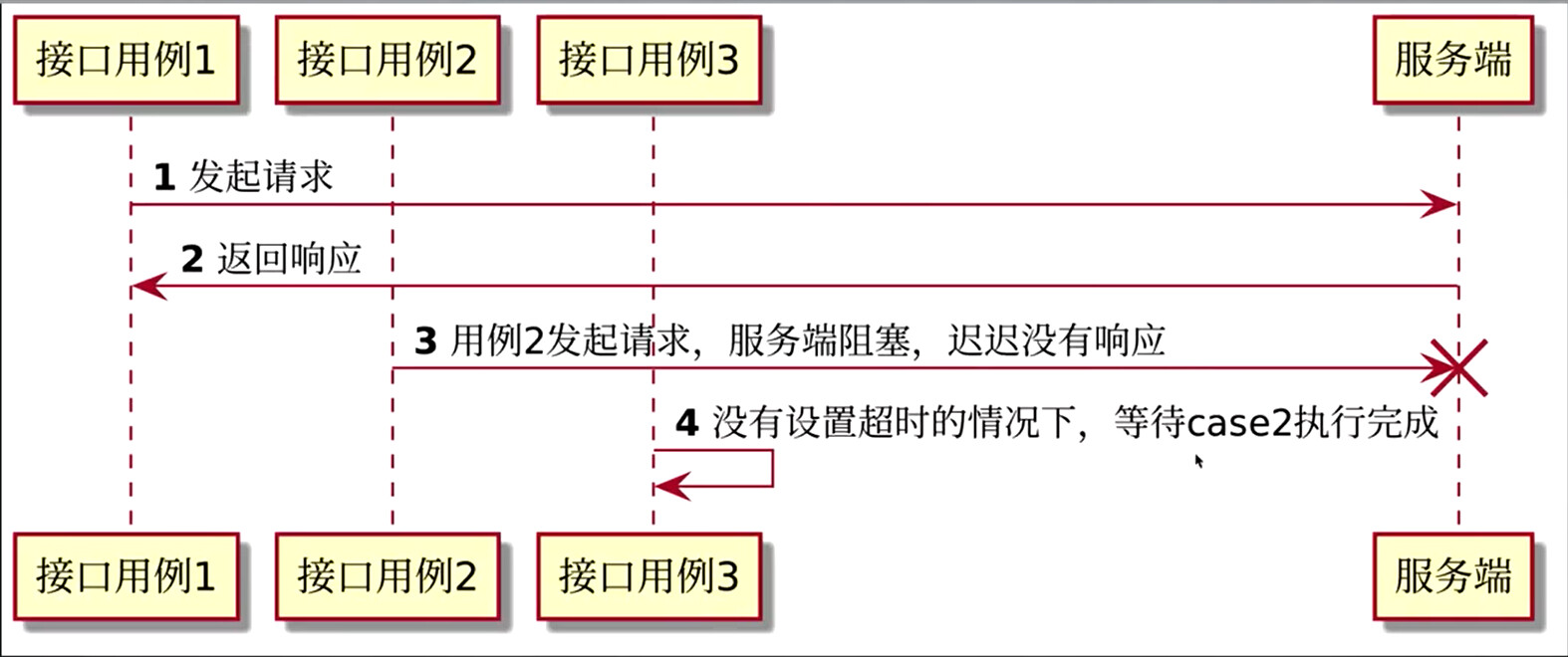
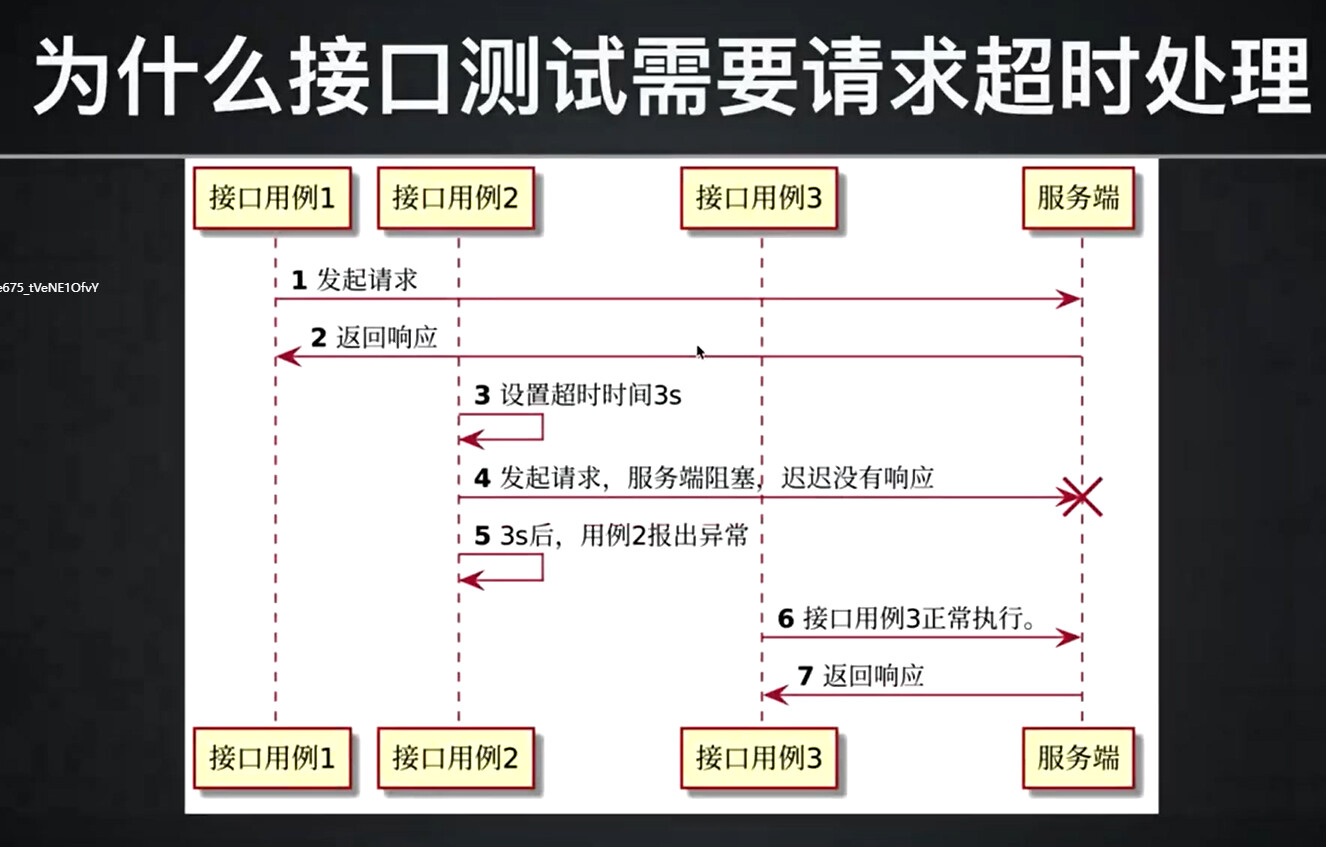
为什么接口测试需要请求超时处理
autonumber
scale 200 width
scale 700 height
participant 接口用例1 as case1
participant 接口用例2 as case2
participant 接口用例3 as case3
participant 服务端 as server
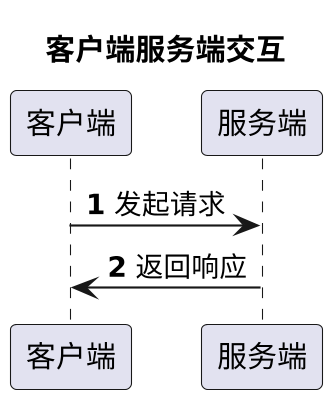
case1 -> server : 发起请求
server -> case1 : 返回响应
case2 -> server !!: 用例2发起请求,服务端阻塞,迟迟没有响应
case3 -> case3 : 没有设置超时的情况下,等待case2执行完成
如何设置
import requests
class TestReq:
def test_timeout(self):
r = requests.get('http://github.com', timeout = 0.01)
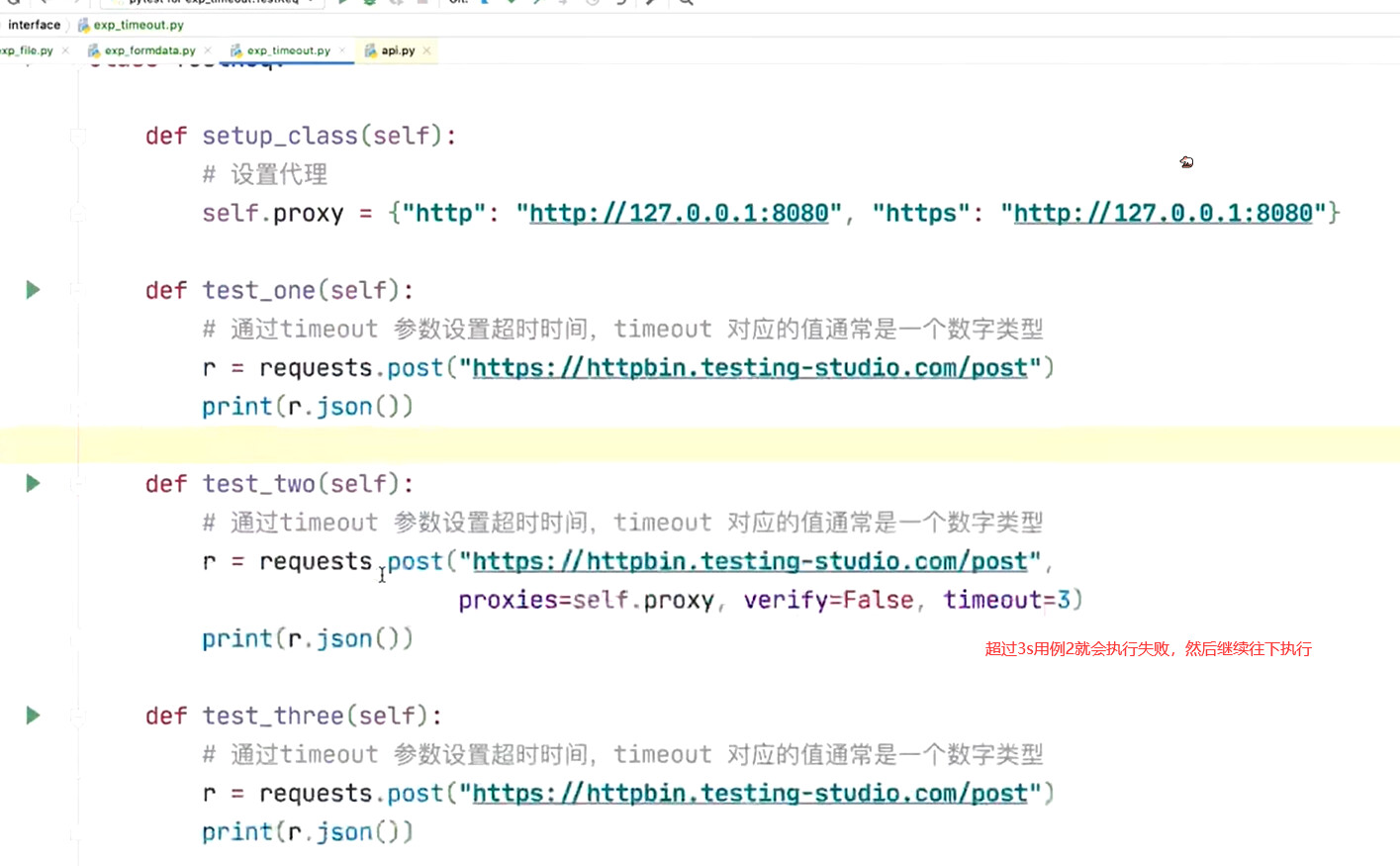
可以提高自动化测试用例的容错性,以及提高测试用例的健壮性
代理配置
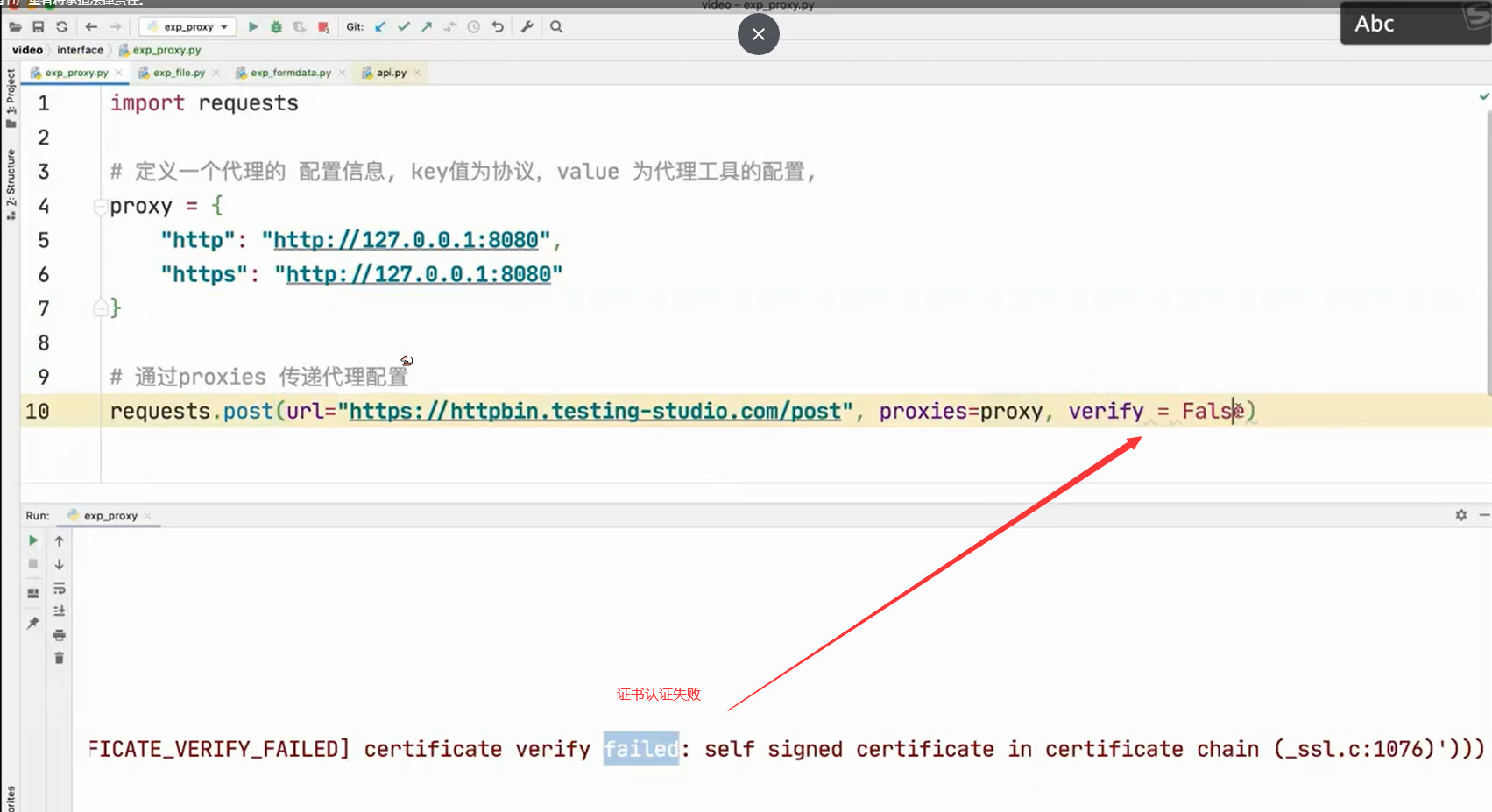

使用代理之前
使用代理之后

代理在接口自动化的使用场景
- 测试脚本,更直观的排查请求错误,相当于编写代码时的 debug
- 获取没有错误的,真实的接口请求响应信息
- 通过代理获取自动化测试的请求响应
- 对比两次请求响应的区别
Requests 如何使用代理
Requests 代理
通过 proxies 参数,监听请求与响应信息

如何使用
- 设定代理格式
- 通过 proxies 参数传递代理设置
- 开启代理工具监听请求
多层嵌套响应断言
目录
- 多层嵌套响应
- JSONPath 语法
- JSONPath 使用
什么是多层嵌套结构
/ - 层级多。
// - 嵌套关系复杂。
{
"errcode": 0,
"errmsg": "ok",
"userid": "zhangsan",
"name": "张三",
"department": [1, 2],
"order": [1, 2],
"position": "后台工程师",
"mobile": "13800000000",
"gender": "1",
"email": "zhangsan@gzdev.com",
"biz_mail": "zhangsan@qyycs2.wecom.work",
"is_leader_in_dept": [1, 0],
"direct_leader": ["lisi", "wangwu"],
"avatar": "http://wx.qlogo.cn/mmopen/ajNVdqHZLLA3WJ6DSZUfiakYe37PKnQhBIeOQBO4czqrnZDS79FH5Wm5m4X69TBicnHFlhiafvDwklOpZeXYQQ2icg/0",
"thumb_avatar": "http://wx.qlogo.cn/mmopen/ajNVdqHZLLA3WJ6DSZUfiakYe37PKnQhBIeOQBO4czqrnZDS79FH5Wm5m4X69TBicnHFlhiafvDwklOpZeXYQQ2icg/100",
"telephone": "020-123456",
"alias": "jackzhang",
"address": "广州市海珠区新港中路",
"open_userid": "xxxxxx",
"main_department": 1,
"extattr": {
"attrs": [
{
"type": 0,
"name": "文本名称",
"text": {
"value": "文本"
}
},
{
"type": 1,
"name": "网页名称",
"web": {
"url": "http://www.test.com",
"title": "标题"
}
}
]
},
"status": 1,
"qr_code": "https://open.work.weixin.qq.com/wwopen/userQRCode?vcode=xxx",
"external_position": "产品经理",
"external_profile": {
"external_corp_name": "企业简称",
"wechat_channels": {
"nickname": "视频号名称",
"status": 1
},
"external_attr": [
{
"type": 0,
"name": "文本名称",
"text": {
"value": "文本"
}
},
{
"type": 1,
"name": "网页名称",
"web": {
"url": "http://www.test.com",
"title": "标题"
}
},
{
"type": 2,
"name": "测试app",
"miniprogram": {
"appid": "wx8bd80126147dFAKE",
"pagepath": "/index",
"title": "my miniprogram"
}
}
]
}
}
复杂场景响应提取
| 场景 | 方式 |
|---|---|
| 提取 errcode 对应的值 | res[errcode] |
| 提取 title 对应的值 | res[extattr][external_profile][external_attr][1][web][title] |
| 提取 type 为 0 的 name | 编码实现 |
| 提取 attrs 下的所有的 name | 编码实现 |
JSONPath 简介
- 在 JSON 数据中定位和提取特定信息的查询语言。
- JSONPath 使用类似于 XPath 的语法,使用路径表达式从 JSON 数据中选择和提取数据。
- 相比于传统的提取方式,更加灵活,并且支持定制化。
JSONPath 对比
| 场景 | 对应实现 | JSONPath 实现 |
|---|---|---|
| 提取 errcode 对应的值 | res[errcode] | $.errcode |
| 提取 title 对应的值 | res[extattr][external_profile][external_attr][1][web][title] 等 | $…title |
| 提取 type 为 0 的 name | 编码实现 | $…external_attr[?(@.type==0)].name |
| 提取 attrs 下的所有的 name | 编码实现 | $…attrs…name |
JSONPath 如何使用
- 语法知识。
- 第三方库调用。
JSONPath 语法
| 符号 | 描述 |
|---|---|
| $ | 查询的根节点对象,用于表示一个 json 数据,可以是数组或对象 |
| @ | 过滤器(filter predicate)处理的当前节点对象 |
| * | 通配符 |
| . | 获取子节点 |
| … | 递归搜索,筛选所有符合条件的节点 |
| ?() | 过滤器表达式,筛选操作 |
| [start:end] | 数组片段,区间为[start,end),不包含 end |
| [A]或[A,B] | 迭代器下标,表示一个或多个数组下标 |
JSONPath 的练习环境
{
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
},
"expensive": 10
}
JSONPath 练习题目
- 获取所有书籍的作者
- 获取所有作者
- 获取 store 下面的所有内容
- 获取所有的价格
- 获取第三本书
- 获取所有包含 isbn 的书籍
- 获取所有价格小于 10 的书
- 获取所有书籍的数量
JSONPath 练习
| 需求 | JsonPath |
|---|---|
| 所有书籍的作者 | $.store.book[*].author |
| 所有作者 | $…author |
| store 下面的所有内容 | $.store.* |
| 所有的价格 | $.store…price |
| 第三本书 | $…book[2] |
| 所有包含 isbn 的书籍 | $…book[?(@.isbn)] |
| 所有价格小于 10 的书 | $.store.book[?(@.price < 10)] |
| 所有书籍的数量 | $…book.length |
JSONPath 与代码结合(Python)
- 环境安装:
pip install jsonpath
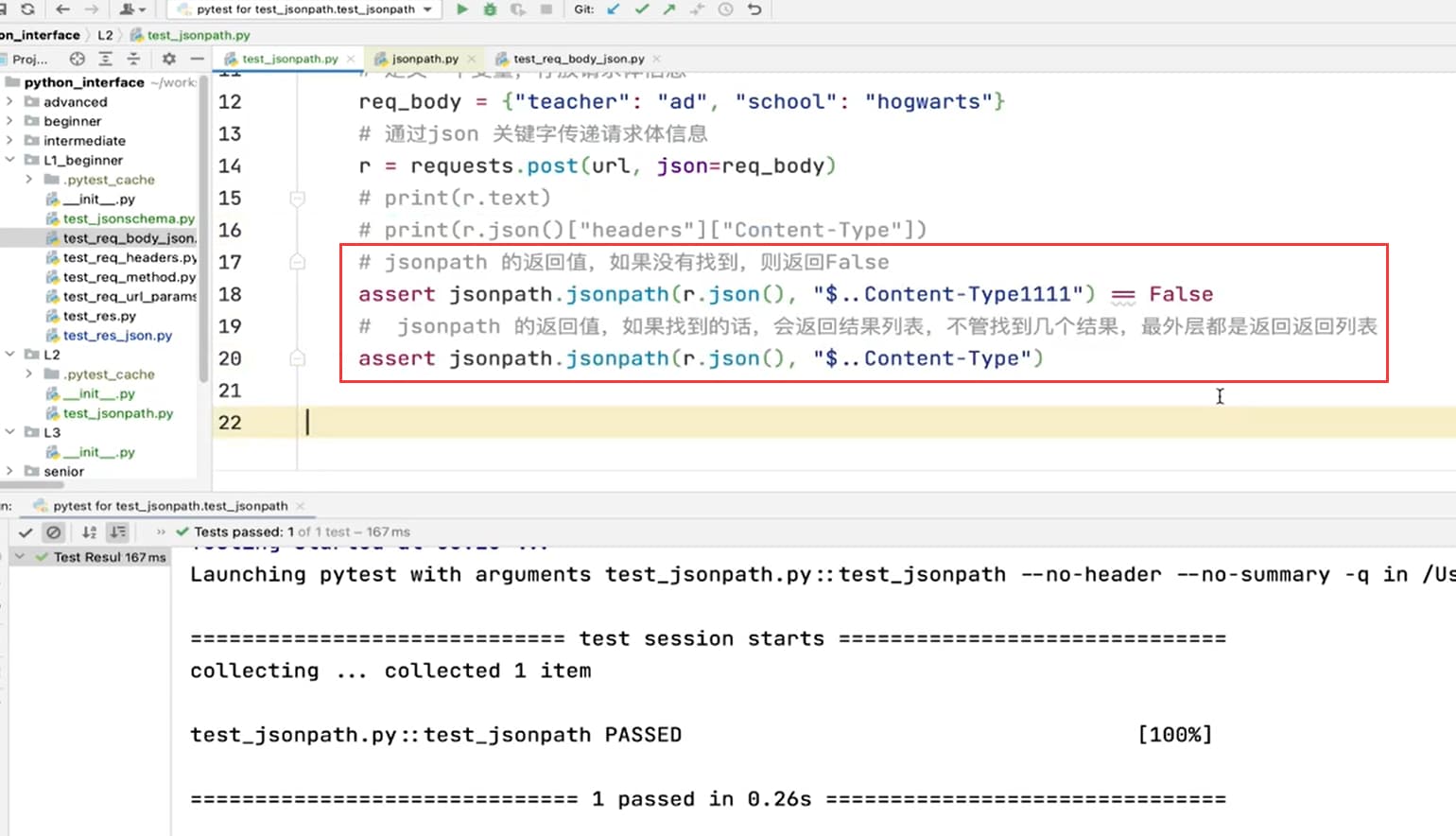
具体的使用。
jsonpath.jsonpath(源数据对象, jsonpath表达式)
宠物商店接口自动化测试实战


目录
- 被测产品
- 需求说明
- 相关知识点
- 接口自动化测试实战
被测产品
- PetStore 宠物商城:
- 一个在线的小型的商城。
- 主要提供了增删查改等操作接口。
- 结合 Swagger 实现了接口的管理。
需求说明
- 完成宠物商城宠物管理功能接口自动化测试。
- 编写自动化测试脚本。
- 完成复杂断言。
相关知识点
| 形式 | 章节 | 描述 | |
|---|---|---|---|
| 知识点 | 代理配置 | 利用代理分析测试脚本,排查请求错误 | |
| 知识点 | 多层嵌套响应断言 | 利用 jsonpath 进行多层嵌套的响应断言 |
实战思路
@startmindmap
scale 10
* 实战思路
** 需求分析
** 接口测试用例设计
** 编写接口自动化测试脚本
*** 脚本优化-配置代理查看接口数据
*** 脚本优化-添加日志
*** 脚本优化-使用 jsonpath 断言
** 生成测试报告
@endmindmap
需求分析
- 被测产品:宠物商店系统 - 宠物管理。
- 宠物商店接口文档:https://petstore.swagger.io/
- 宠物管理业务场景:
- 添加宠物。
- 查询宠物信息。
- 修改宠物信息。
- 删除宠物。
scale 10
autonumber
participant 测试人员 as tester
participant 宠物管理模块 as pet
participant 宠物商店 as petStore
tester -> pet: 编写脚本
pet -> petStore: 添加宠物
pet -> petStore: 查询添加后宠物
customer -> tester: 测试断言
pet -> petStore: 修改宠物信息
pet -> petStore: 查询添加后宠物
customer -> tester: 测试断言
pet -> petStore: 删除宠物
pet -> petStore: 查询添加后宠物
customer -> tester: 测试断言
宠物管理接口业务流程测试用例

编写自动化测试脚本思路
@startmindmap
scale 10
* 思路
** 获取接口信息
*** swagger 接口文档
*** 前端抓包
** 单步调通接口
** 根据业务流程串联起来
** 添加断言,确认流程正常
@endmindmap
编写自动化测试脚本
class TestPetstorePetmanager:
def setup_class(self):
self.base_url = "https://petstore.swagger.io/v2/pet"
self.search_url = self.base_url + "/findByStatus"
self.pet_id = 9223372000001084222
pet_status = "available"
self.pet_info = {
"id": self.pet_id,
"category": {
"id": 1,
"name": "cat"
},
"name": "miao",
"photoUrls": [
"string"
],
"tags": [
{
"id": 5,
"name": "cute"
}
],
"status": pet_status
}
self.search_param = {
"status": pet_status
}
self.update_name = "miao-hogwarts"
self.update_info = {
"id": self.pet_id,
"category": {
"id": 1,
"name": "cat"
},
"name": self.update_name,
"photoUrls": [
"string"
],
"tags": [
{
"id": 5,
"name": "cute"
}
],
"status": pet_status
}
self.delete_url = self.base_url + f"/{self.pet_id}"
def test_pet_manager(self):
# 新增宠物
add_r = requests.post(self.base_url, json=self.pet_info)
# 状态断言
assert add_r.status_code == 200
# 修改宠物
update_r = requests.put(self.base_url, json=self.update_info)
# 状态断言
assert update_r.status_code == 200
# 删除宠物
delete_r =requests.delete(self.delete_url)
# 状态断言
assert delete_r.status_code == 200
脚本优化 - 配置代理查看接口数据
- 在脚本中配置代理。
- 抓包查看接口测试中的接口请求和响应数据。
proxy = {
"http": "http://127.0.0.1:8888",
"https": "http://127.0.0.1:8888"
}
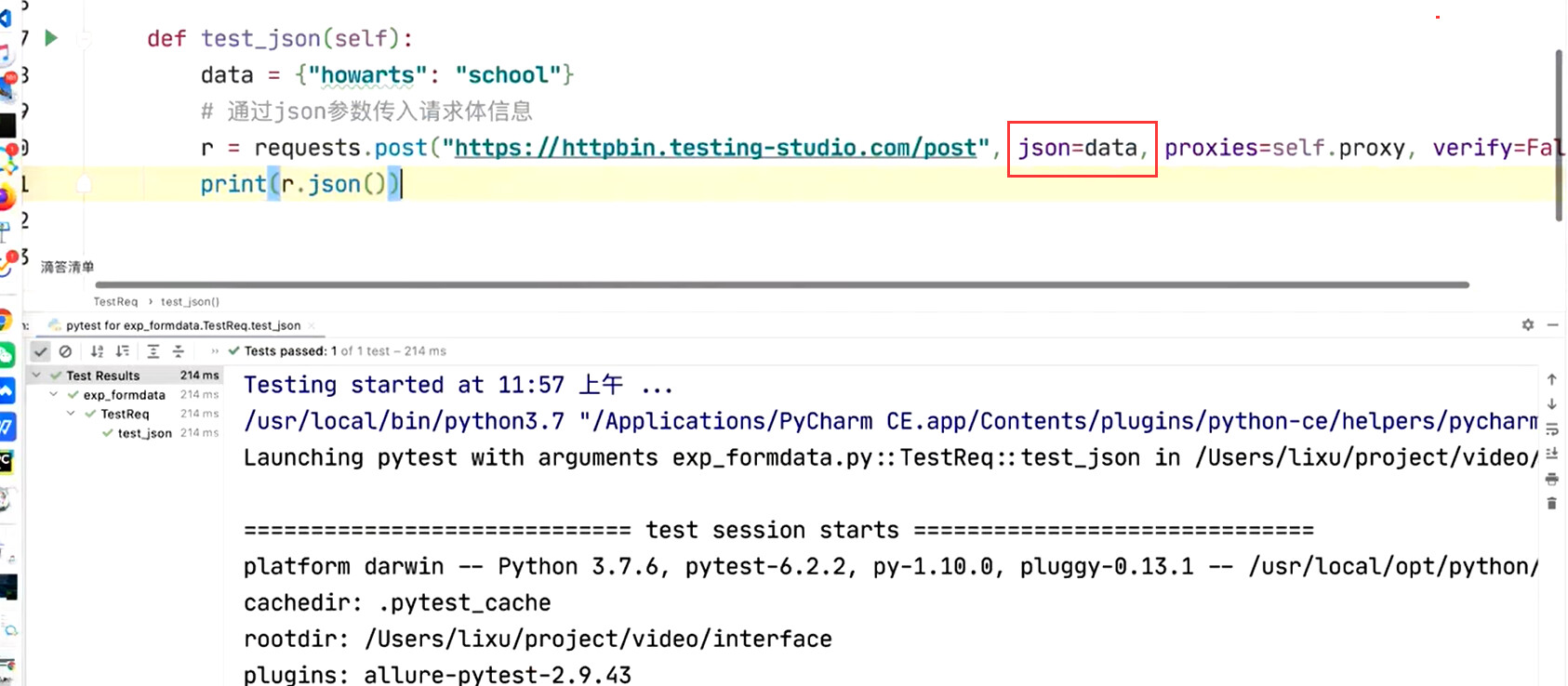
requests.post(url, json=pet_info, proxies=proxy, verify=False)
脚本优化 - 添加日志
- 新建日志配置。
- 在用例中使用配置好的日志实例。
# 配置日志
import logging
import os
from logging.handlers import RotatingFileHandler
# 绑定绑定句柄到logger对象
logger = logging.getLogger(__name__)
# 获取当前工具文件所在的路径
root_path = os.path.dirname(os.path.abspath(__file__))
# 拼接当前要输出日志的路径
log_dir_path = os.sep.join([root_path, '..', f'/logs'])
if not os.path.isdir(log_dir_path):
os.mkdir(log_dir_path)
# 创建日志记录器,指明日志保存路径,每个日志的大小,保存日志的上限
file_log_handler = RotatingFileHandler(os.sep.join([log_dir_path, 'log.log']), maxBytes=1024 * 1024, backupCount=10)
# 设置日志的格式
date_string = '%Y-%m-%d %H:%M:%S'
formatter = logging.Formatter(
'[%(asctime)s] [%(levelname)s] [%(filename)s]/[line: %(lineno)d]/[%(funcName)s] %(message)s ', date_string)
# 日志输出到控制台的句柄
stream_handler = logging.StreamHandler()
# 将日志记录器指定日志的格式
file_log_handler.setFormatter(formatter)
stream_handler.setFormatter(formatter)
# 为全局的日志工具对象添加日志记录器
# 绑定绑定句柄到logger对象
logger.addHandler(stream_handler)
logger.addHandler(file_log_handler)
# 设置日志输出级别
logger.setLevel(level=logging.INFO)
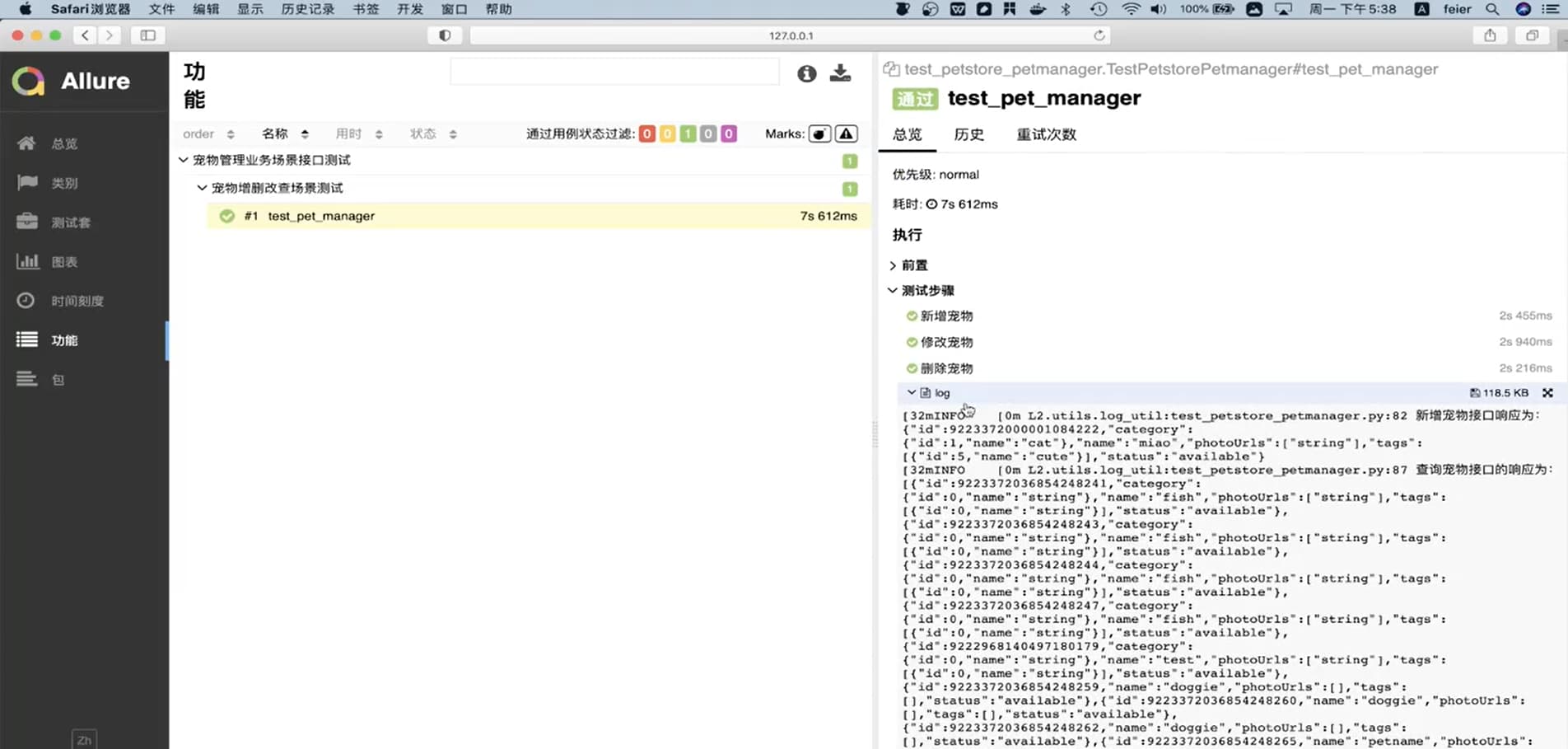
脚本优化 - 使用 jsonpath 断言
- 使用 jsonpath 实现多层嵌套响应的断言。
jsonpath.jsonpath(r.json(), “$…id”)
生成测试报告
- 安装 allure 相关依赖。
生成报告信息
pytest --alluredir=./report
生成报告在线服务,查看报告
allure serve ./report/
总结
- 通过 Swagger 文档获取接口信息。
- 使用 Requests 发出请求。
- 添加代理,抓包查看接口请求和响应数据。
- 使用 Jsonpath 提取复杂结构响应数据,然后进行断言。
- 添加 Log 日志。
- 生成 Allure 测试报告。
整体结构响应断言

目录
- 结构断言介绍
- JSONSchema 数据生成
- JSONSchema 验证
响应信息数据极为庞大
针对与“大响应数据”如何断言
- 针对主要且少量的业务字段断言。
- 其他字段不做数据正确性断言,只做类型与整体结构的校验。
- 与前面的版本进行 diff,对比差异化的地方。
JSONSchema 简介
- 使用 JSON 格式编写的
- 可以用来定义校验 JSON 数据的结构
- 可以用来校验 JSON 数据的一致性
- 可以用来校验 API 接口请求和响应
JSONSchema 整体结构响应断言
- 预先生成对应结构的 Schema。
- 将实际获取到的响应与生成的 Schema 进行对比。
JSONSchema 的生成
- 通过界面工具生成。
- 通过第三方库生成。
- 通过命令行工具生成。
JSONSchema 的生成效果
// # 预期的 JSON 文档结构
{
"name": "Hogwarts",
"Courses": ["Mock", "Docker"]
}
// jsonschema
{
"$schema": "http://json-schema.org/draft-06/schema#",
"$ref": "#/definitions/Welcome",
"definitions": {
"Welcome": {
"type": "object",
"additionalProperties": false,
"properties": {
"name": {
"type": "string"
},
"Courses": {
"type": "array",
"items": {
"type": "string"
}
}
},
"required": ["Courses", "name"],
"title": "Welcome"
}
}
}
界面工具生成
- 复制 JSON 数据
- 粘贴到在线生成工具中
- 自动生成 JSON Schema 数据
JSON Schema 在线生成工具:https://app.quicktype.io
第三方库生成(Python)
- 安装:
pip install genson。 - 调用方法生成对应的 JSONSchema 数据结构。
from genson import SchemaBuilder
def generate_jsonschema(obj):
# 实例化jsonschem
builder = SchemaBuilder()
# 传入被转换的对象
builder.add_object(obj)
# 转换成 schema 数据
return builder.to_schema()
JSONSchema 验证(Python)
- 安装:
pip install jsonschema。 - 调用
validate()进行验证。
def schema_validate(obj, schema):
'''
对比 python 对象与生成的 JSONSchame 的结构是否一致
'''
try:
validate(instance=obj, schema=schema)
return True
except Exception as e:
return False
JSONSchema 二次封装
- 生成JSONSchema
- 验证JSONSchema
class JSONSchemaUtils:
@classmethod
def generate_schema(cls, obj):
# 实例化jsonschem
builder = SchemaBuilder()
# 传入被转换的对象
builder.add_object(obj)
# 转换成 schema 数据
return builder.to_schema()
@classmethod
def schema_validate(cls, obj, schema):
'''
对比 python 对象与生成的 json schame 的结构是否一致
'''
try:
validate(instance=obj, schema=schema)
return True
except Exception as e:
return False
数据库操作与断言
接口测试响应验证
如何在测试过程中验证接口没有 Bug?
- 通过接口响应值
- 通过查询数据库信息辅助验证
接口测试数据清理
自动化测试过程中,会产生大量的脏数据,如何处理?
- 通过 Delete 接口删除
- 自动化测试使用干净的测试环境,每次自动化测试执行完成之前或之后做数据还原。
数据库操作注意事项
直接对数据库做查询之外的操作是非常危险的行为
- 权限管理严格的公司数据库权限给的非常低
- 表结构复杂,随便删除数据会影响测试,甚至会导致系统出现异常
接口自动化测试常用的数据库操作
- 连接与配置
- 查询数据与断言
- 查询数据与断言
Python技术栈:章节《常用第三方库pymsql》;Java技术栈:《常用标准库:数据库操作-JDBC》
实战目标
- 第一次全流程实战的断言通过数据库验证
数据库信息
- 主机: litemall.hogwarts.ceshiren.com
- 端口: 13306
- 用户名: test
- 密码: test123456
注意:只有查询权限
数据库封装(Python)
- 封装数据库配置
- 封装 sql 查询操作
- 调用方法执行 sql 语句
import pymysql
# 封装建立连接的对象
def get_conn():
conn = pymysql.connect(
host="litemall.hogwarts.ceshiren.com",
port=13306,
user="test",
password="test123456",
database="litemall",
charset="utf8mb4"
)
return conn
# 执行sql语句
def execute_sql(sql):
connect = get_conn()
cursor = connect.cursor()
cursor.execute(sql) # 执行SQL
record = cursor.fetchone() # 查询记录
return record
if __name__ == '__main__':
# 执行sql语句查询user123这个用户的购物车有一个名称为 hogwarts1 的商品
execute_sql("select * from litemall_cart where "
"user_id=1 and deleted=0 and "
"goods_name='hogwarts1'")
查询数据与数据库断言(Python)
- 查询数据,添加查询条件
- 断言结果不为 None
# 查询查询user123这个用户的购物车有一个名称为 hogwarts1 的商品
sql_res = execute_sql("select * from litemall_cart where "
"user_id=1 and deleted=0 and "
"goods_name='hogwarts1'")
assert sql_res != None
接口鉴权的多种情况与解决方案
接口鉴权是什么
- 身份认证
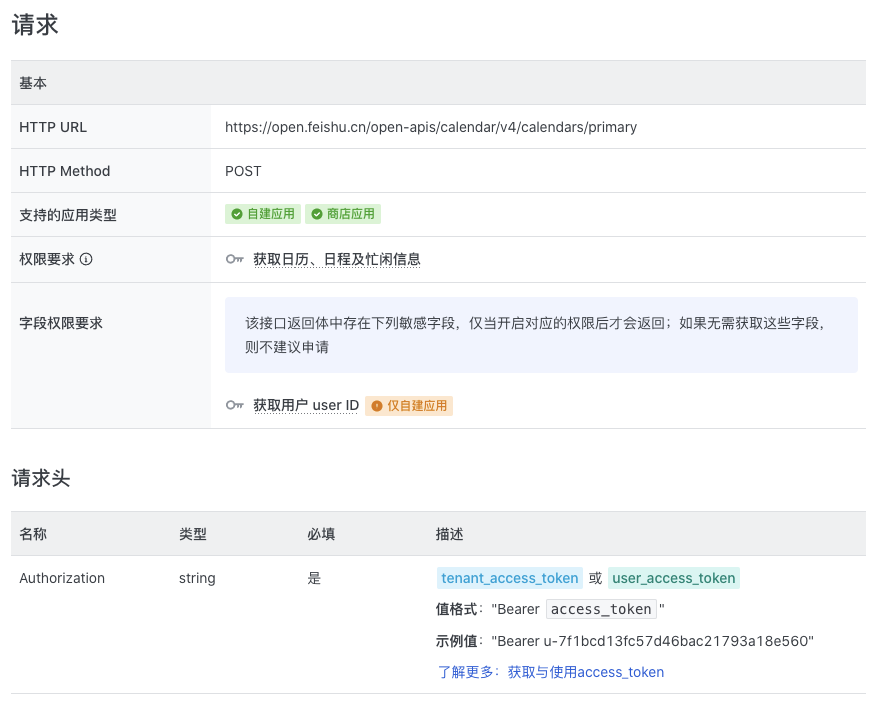
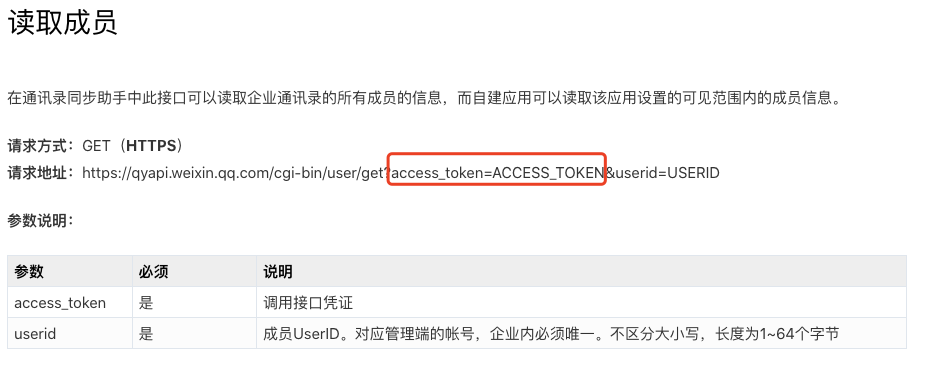
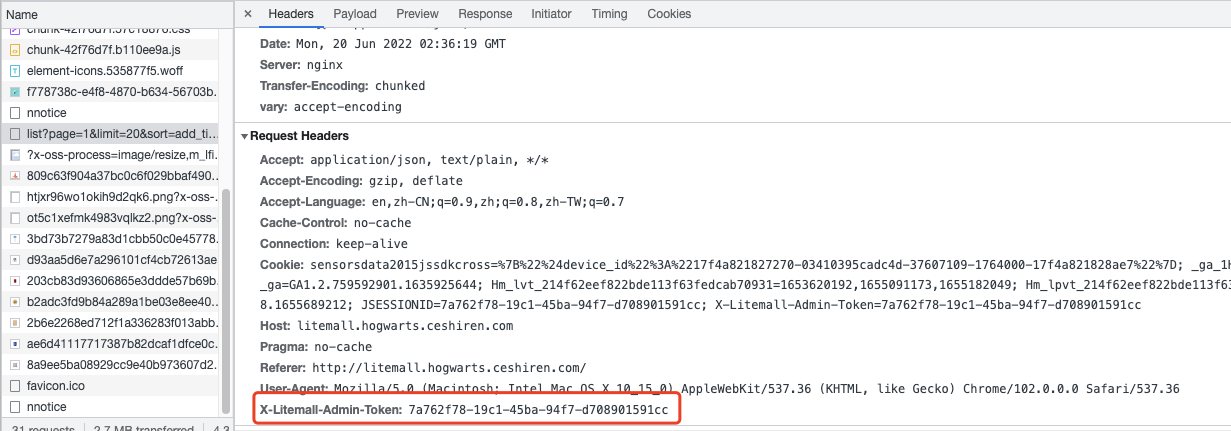
接口鉴权通用的解决方案
- 认证信息的获取
- 认证信息的携带
@startuml
scale 800
if (登录成功?) then
#pink:响应错误;
detach
endif
#palegreen:响应认证信息;
#palegreen:携带认证信息发起其他请求;
@enduml
后端接口鉴权常用方法
@startmindmap
- 常用方式
** cookie
*** 1. 携带身份信息请求认证
*** 2. 之后的每次请求都携带cookie信息,cookie记录在请求头中
** token
*** 1. 携带身份信息请求认证
*** 2. 之后的每次请求都携带token认证信息
*** 3. 可能记录在请求头,可能记录在url参数中
** auth
*** 每次请求携带用户的username和password,并对其信息加密
** oauth2(选修)
*** 1. 携带身份信息请求认证
*** 2. 服务端向指定回调地址回传code
*** 3. 通过code获取token
*** 4. 之后的请求信息都携带token。
*** 典型产品 微信自动化测试
@endmindmap
cookie 鉴权
- cookie 的获取(根据接口文档获取)
- 发送携带 cookie 的请求
- 直接通过 cookies 参数
- 通过
Session()对象
import requests
class TestVerify:
def setup_class(self):
self.proxy = {"http": "http://127.0.0.1:8080",
"https": "http://127.0.0.1:8080"}
def test_cookies_by_write(self):
# 简单场景,直接写入cookie
url = "https://httpbin.ceshiren.com/cookies"
requests.get(url, proxies=self.proxy, verify=False, cookies={"hogwarts": "ad"})
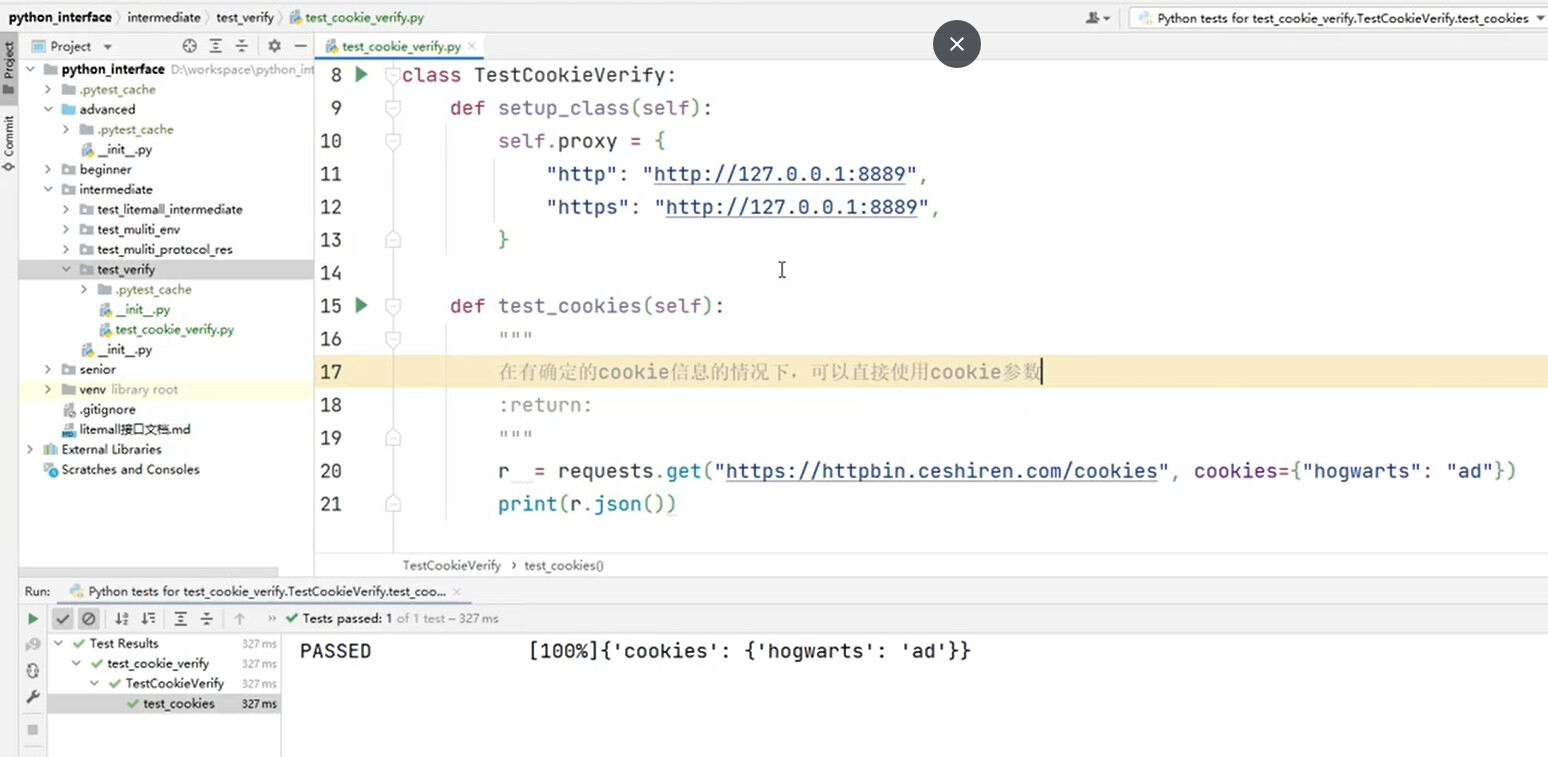
def test_cookies(self):
# 获取session 的实例,需要通过Session()保持会话,
# 即为认证之后,之后所有的实例都会携带cookie
# 可以模仿用户在浏览器的操作
req = requests.Session()
# 第一次登陆,植入cookie
set_url = "https://httpbin.ceshiren.com/cookies/set/hogwarts/ad"
req.get(set_url, proxies=self.proxy, verify=False)
# 第二次请求的时候即可携带cookie信息
url = "https://httpbin.ceshiren.com/cookies"
req.get(url, proxies=self.proxy, verify=False)
token 鉴权
- token 的获取(根据接口文档获取)
- 发送携带 token 的请求(根据接口文档获取)
class TestVerify:
def setup_class(self):
self.proxy = {"http": "http://127.0.0.1:8080",
"https": "http://127.0.0.1:8080"}
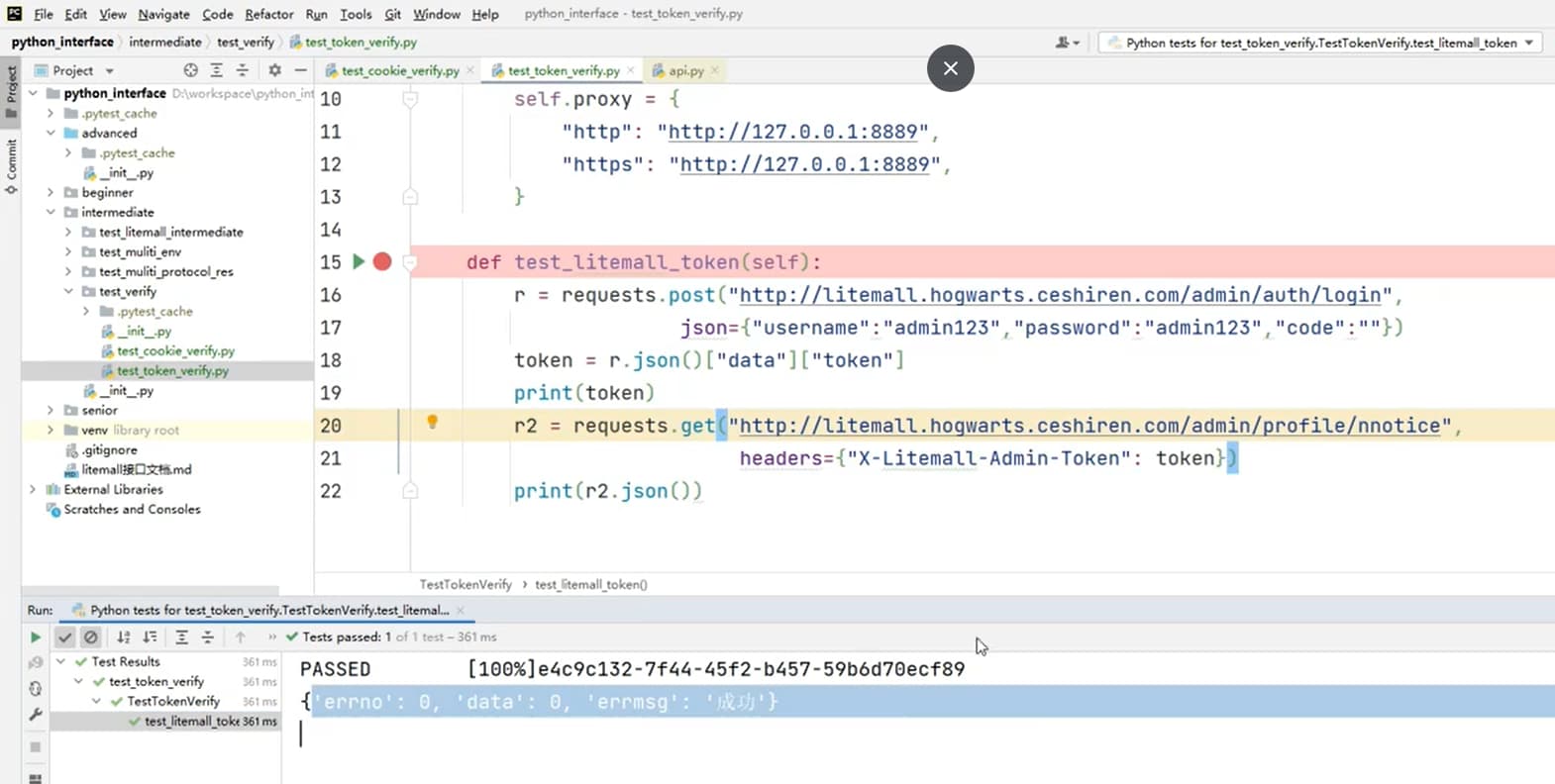
def test_token(self):
# 1. 获取token
url = "http://litemall.hogwarts.ceshiren.com/admin/auth/login"
user_data = {"username": "admin123", "password": "admin123", "code": ""}
r = requests.post(url, json=user_data, proxies=self.proxy, verify=False, )
self.token = r.json()["data"]["token"]
# 2. 之后的请求均携带token
goods_list_url = "http://litemall.hogwarts.ceshiren.com/admin/goods/list"
goods_data = {"name": "hogwarts", "order": "desc", "sort": "add_time"}
r = requests.get(goods_list_url, params=goods_data,
headers={"X-Litemall-Admin-Token": self.token},
proxies=self.proxy, verify=False)
auth 鉴权(了解即可)
- 在基本 HTTP 身份验证中,请求包含格式为 的标头字段Authorization: Basic
- 其中credentials是 ID 和密码的Base64编码,由单个冒号连接:。

auth 鉴权-代码示例
import requests
from requests.auth import HTTPBasicAuth
class TestVerify:
def setup_class(self):
self.proxy = {"http": "http://127.0.0.1:8080",
"https": "http://127.0.0.1:8080"}
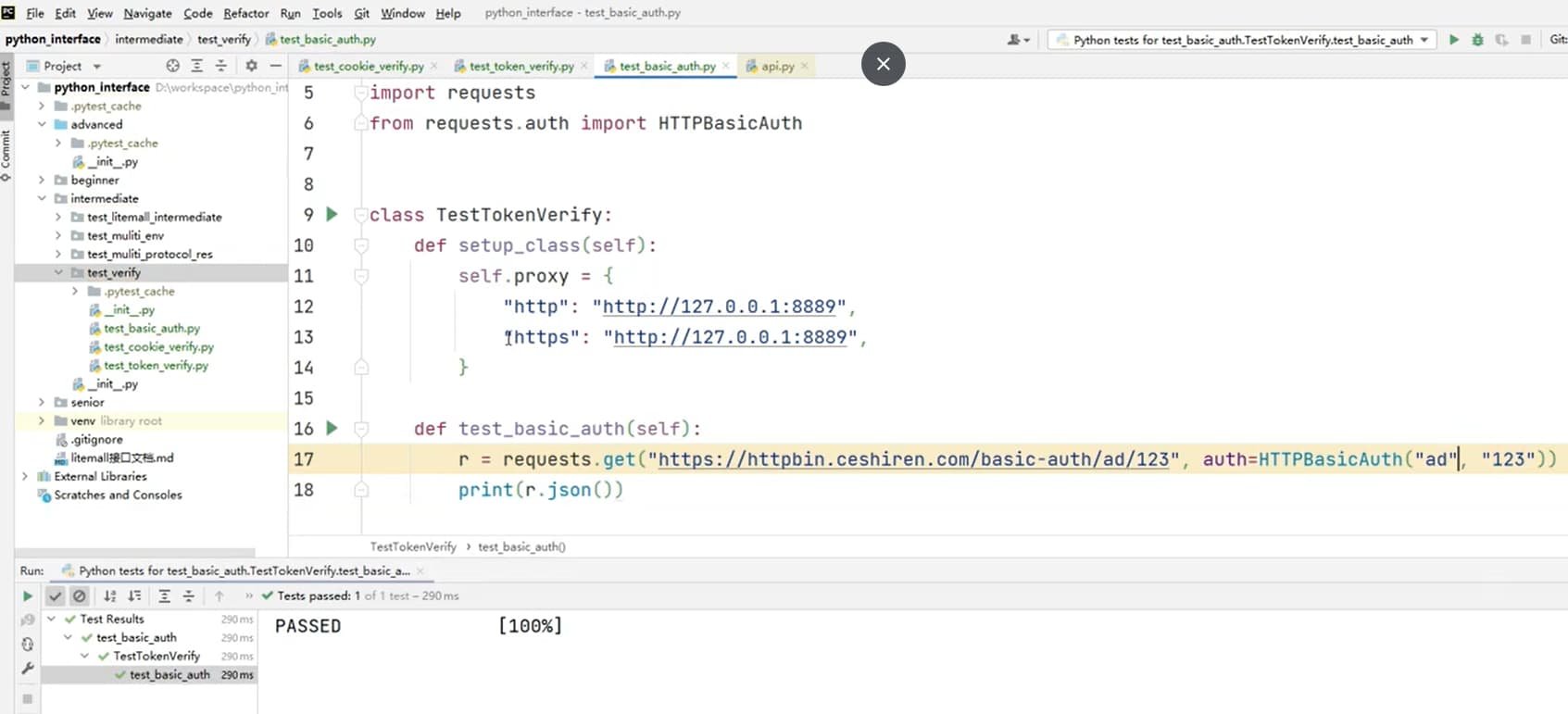
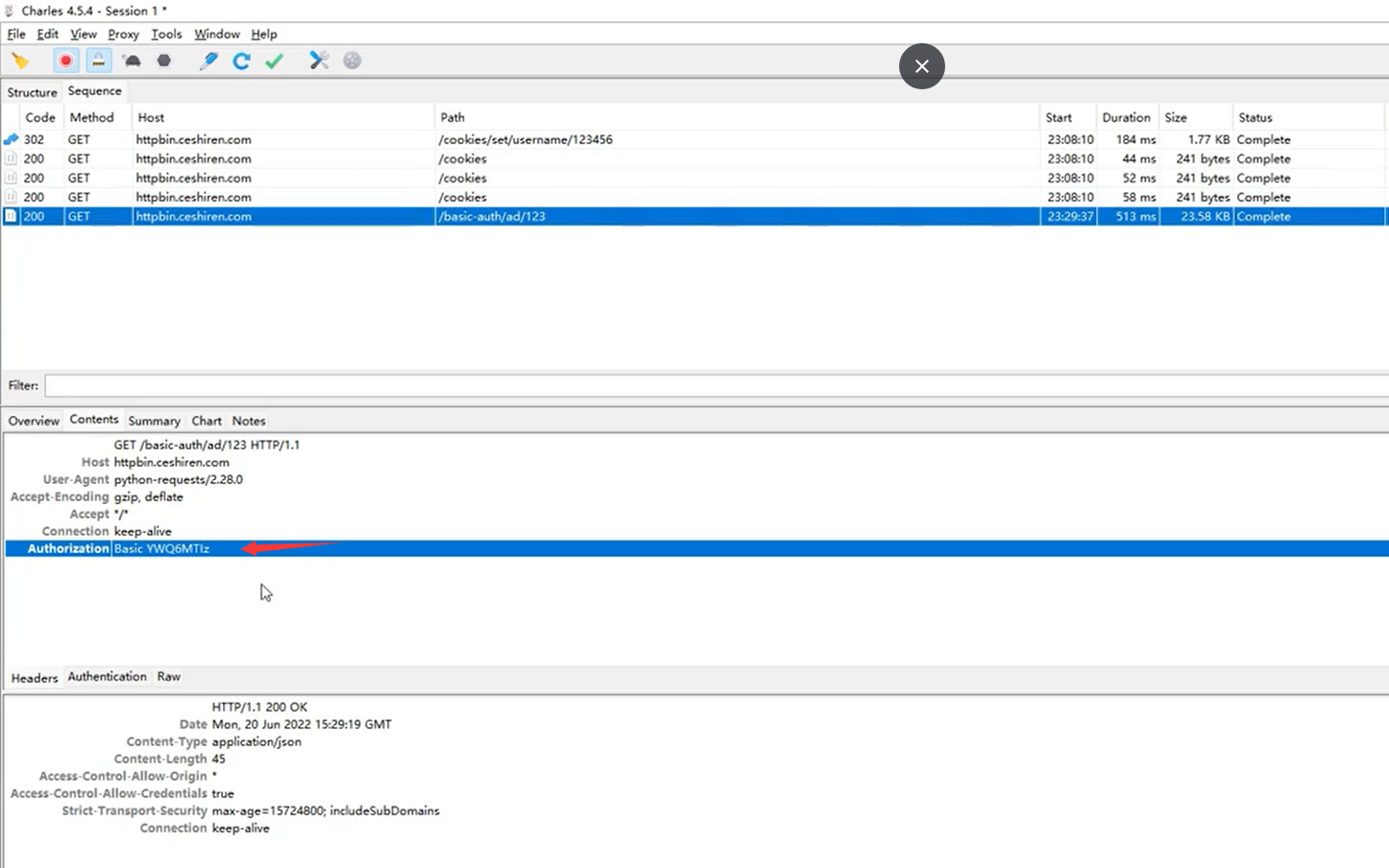
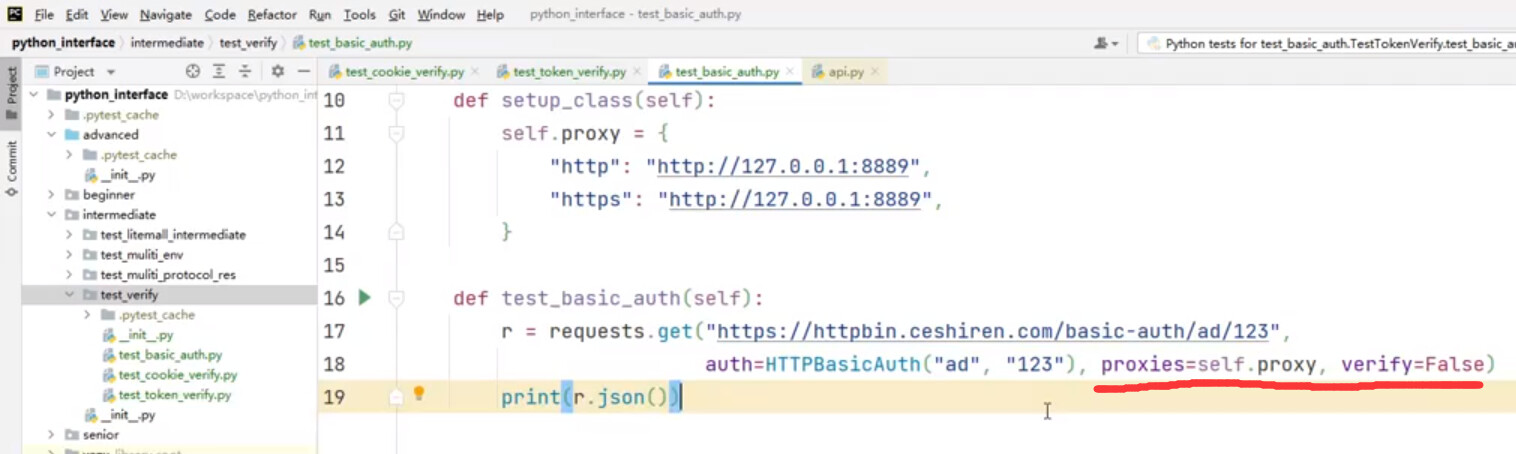
def test_basic_auth(self):
# 表示访问一个需要BasicAuth认证的路径
# username=用户名,password=密码
# 如果不使用basic auth 则会失败
r = requests.get("https://httpbin.ceshiren.com/basic-auth/username/password",
proxies=self.proxy, verify=False,
auth=HTTPBasicAuth("username", "password"))
电子商城接口自动化测试实战
目录
- 接口测试流程
- 产品需求分析
- 测试用例设计思路
- 接口自动化脚本编写
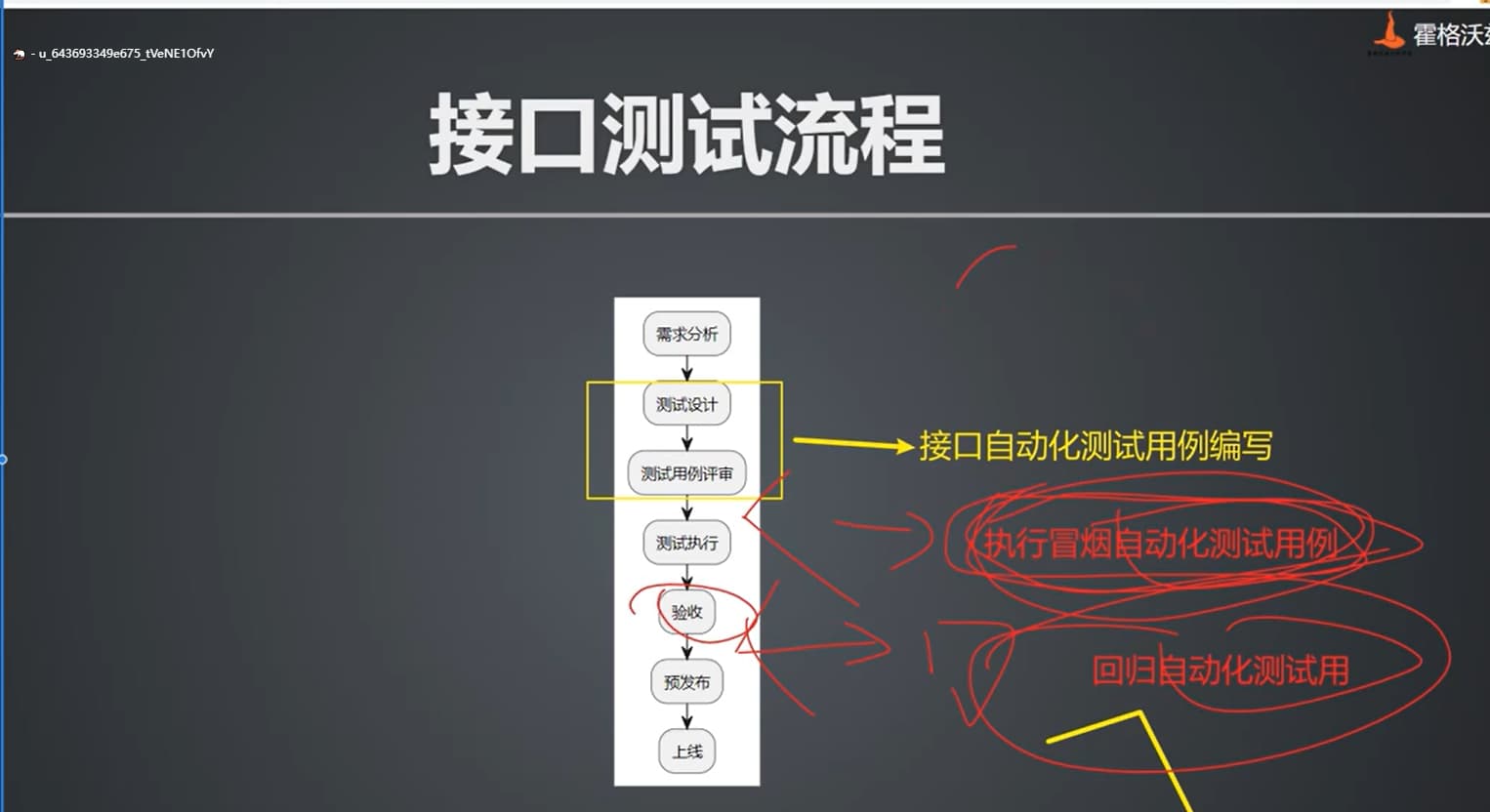
接口测试流程
@startuml
:需求分析;
:测试设计;
:测试用例评审;
:测试执行;
:验收;
:预发布;
:上线;
@enduml
电子商城需求分析
- 商城管理后台
- 商城客户端
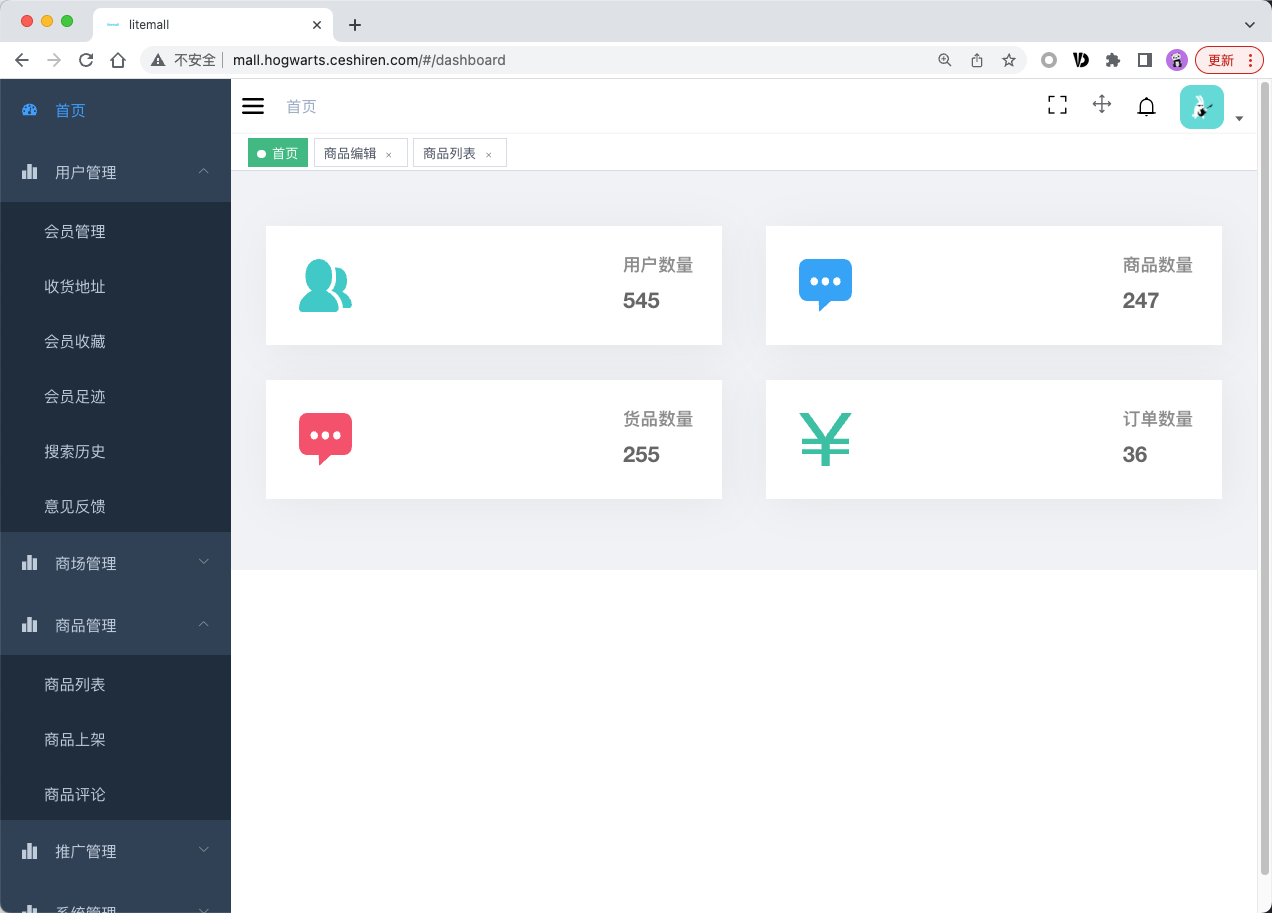
商城业务场景
- 商品上架
- 商品查询
- 加入购物车
scale 700*500
autonumber
participant 测试人员 as tester
participant 登录模块 as login
participant 管理后台 as admin
participant 客户端 as customer
tester -> login: 编写脚本
login -> admin: 登录接口
admin -> customer: 商品上架接口
admin -> customer: 商品查询接口
customer -> customer: 加购接口
customer -> tester: 测试断言
研发技术评审
- 管理后台接口文档
Swagger UI
接口测试用例设计思路
startmindmap
*[#Orange] 接口测试思路
**[#lightblue] 基本功能流程测试(p1)
***[#lightgreen] 冒烟测试
***[#lightgreen] 正常流程覆盖测试
**[#lightblue] 基于输入域的测试(p2)
***[#lightgreen] 边界值测试
***[#lightgreen] 特殊字符校验
***[#lightgreen] 参数类型校验
***[#lightgreen] 必选参数校验
***[#lightgreen] 组合参数校验
***[#lightgreen] 有效性校验
***[#lightgreen] 默认值校验
***[#lightgreen] 排重逻辑
left side
**[#lightblue] 接口幂等性
***[#lightgreen] 重复提交
**[#lightblue] 故障注入
***[#lightgreen] Redis故障降级测试
***[#lightgreen] 服务故障转移测试
**[#lightblue] 线程安全测试
***[#lightgreen] 并发测试
***[#lightgreen] 分布式测试
***[#lightgreen] 数据库读写安全测试
@endmindmap
添加购物车流程脚本编写
title 编写思路
@startmindmap
- 思路
** 获取接口信息
*** swagger 接口文档
*** 前端抓包
** 单步调通接口后,根据业务流程串联起来
** 添加断言,确认流程正常
@endmindmap
* 思路
** 获取接口信息
*** swagger 接口文档
*** 前端抓包
** 单步调通接口后,根据业务流程串联起来
** 添加断言,确认流程正常
@endmindmap
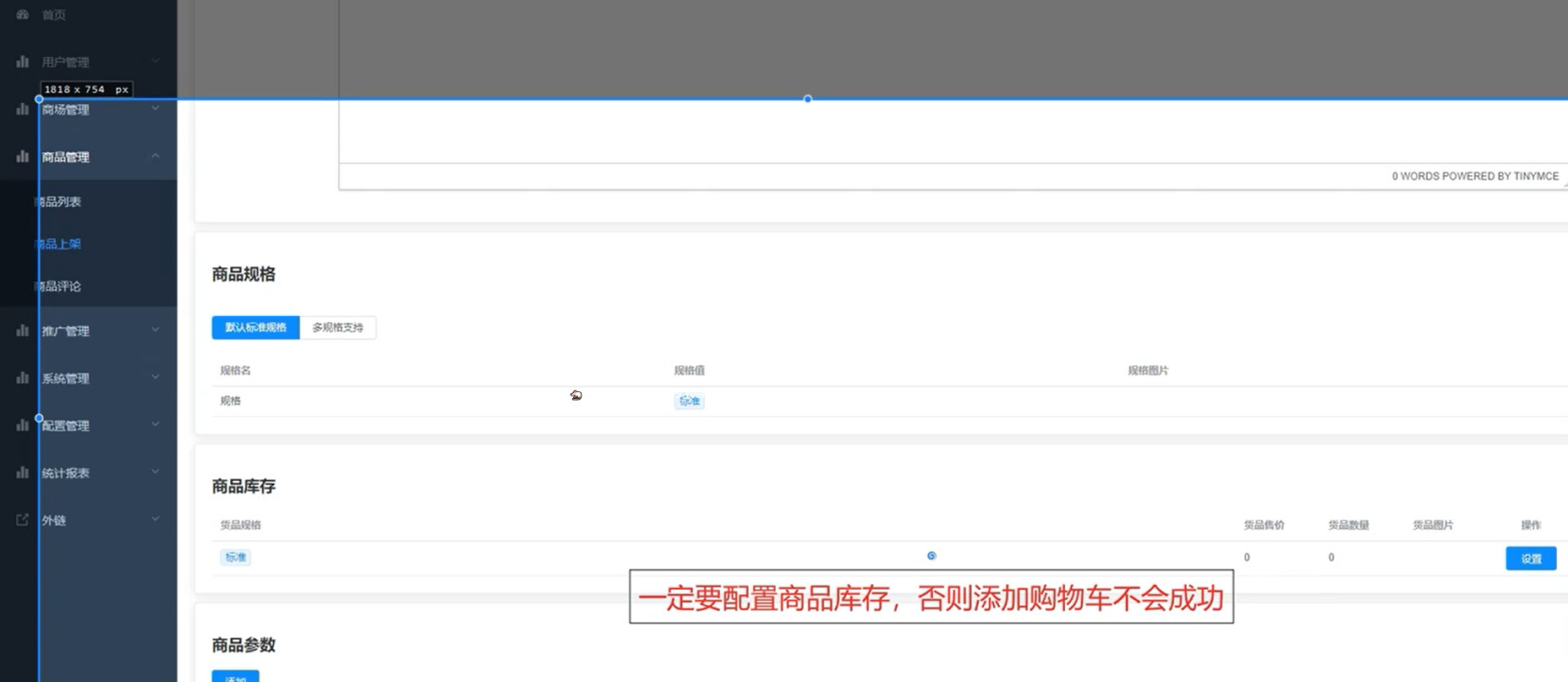
- 上架商品
- 查询商品列表,获取商品ID
- 查询商品详情,获取商品库存ID
- 加入购物车
脚本优化-参数化(Python)
- 使用pytest parametrize装饰器实现商品名称的参数化
@pytest.mark.parametrize(“goods_name”, [“hogwarts1”, “hogwarts2”])
脚本优化-添加日志(Python)
- 新建日志配置
- 在用例中使用配置好的日志实例
"""
__author__ = '霍格沃兹测试开发学社'
__desc__ = '更多测试开发技术探讨,请访问:https://ceshiren.com/t/topic/15860'
"""
# 日志配置
import logging
# 创建logger实例
logger = logging.getLogger('simple_example')
# 设置日志级别
logger.setLevel(logging.DEBUG)
# 流处理器
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
# 日志打印格式
formatter = logging.Formatter\
('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 添加格式配置
ch.setFormatter(formatter)
# 添加日志配置
logger.addHandler(ch)
脚本优化-数据清理(Python)
- 在用例执行完成之后调用删除接口完成数据清理
# 删除操作
def teardown(self):
url = "http://litemall.hogwarts.ceshiren.com/admin/goods/create"
data = {
"id": self.goods_id,
}
r = requests.post(url=url, json=data)
logger.debug("删除商品响应:"+json.dumps(r.json(), ensure_ascii=False, indent=2))
脚本优化-报告展示
- 安装allure相关依赖
# 生成报告信息
pytest test_add_to_cart.py --alluredir=./report
# 生成报告在线服务,查看报告
allure serve ./report/
上课代码:
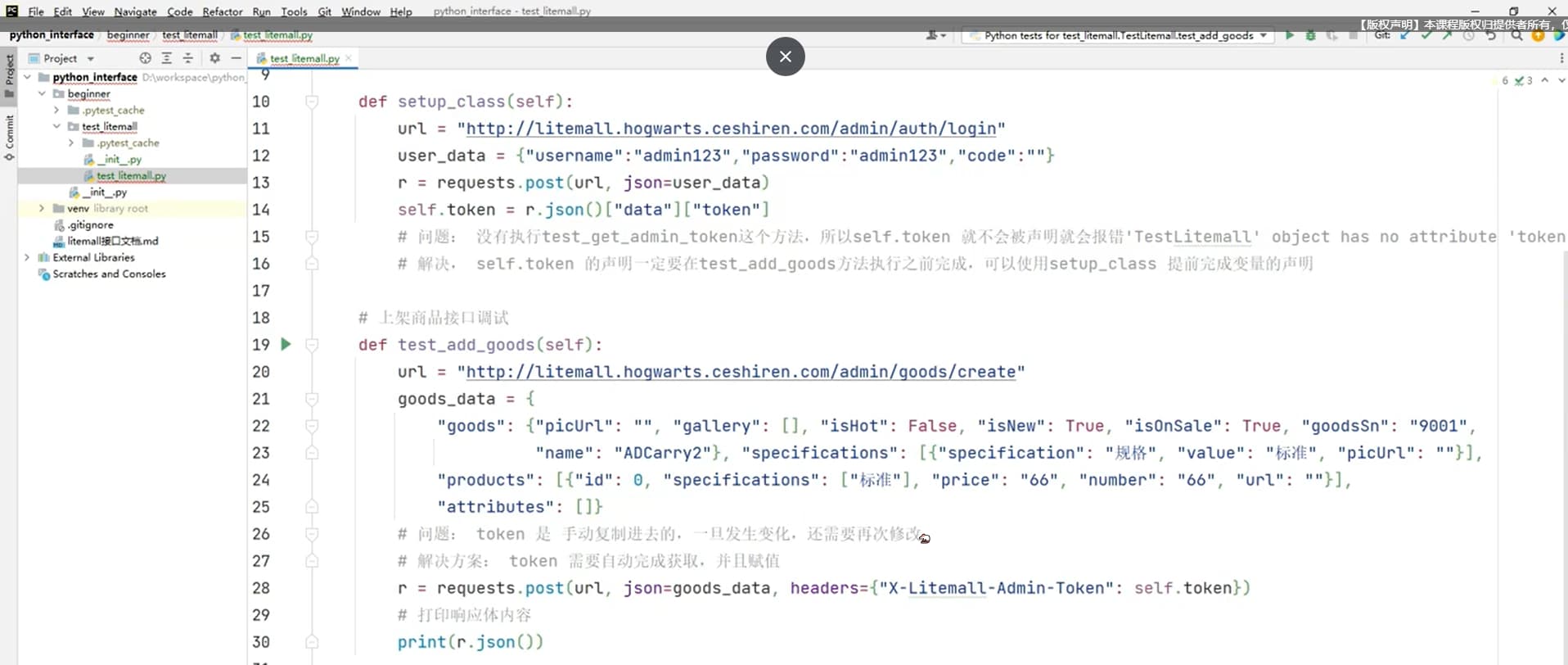
import json
import pytest
import requests
from beginner.test_litemall.log_utils import logger
class TestLitemall:
def setup_class(self):
# 1. 管理端登录接口
url = "http://litemall.hogwarts.ceshiren.com/admin/auth/login"
user_data = {"username": "admin123", "password": "admin123", "code": ""}
r = requests.post(url, json=user_data)
self.token = r.json()["data"]["token"]
# 问题: 没有执行test_get_admin_token这个方法,所以self.token 就不会被声明就会报错'TestLitemall' object has no attribute 'token'
# 解决, self.token 的声明一定要在test_add_goods方法执行之前完成,可以使用setup_class 提前完成变量的声明
# 2. 用户端登录接口
url = "http://litemall.hogwarts.ceshiren.com/wx/auth/login"
client_data = {"username": "user123", "password": "user123"}
r = requests.post(url, json=client_data)
self.client_token = r.json()["data"]["token"]
# ======= 数据清理,建议使用delete接口不要直接删表中的数据
def teardown(self):
url = "http://litemall.hogwarts.ceshiren.com/admin/goods/delete"
r = requests.post(url, json={"id":self.goods_id}, headers={"X-Litemall-Admin-Token": self.token})
logger.debug(f"删除商品的响应信息为{json.dumps(r.json(), indent=2, ensure_ascii=False)}")
# 上架商品接口调试
# ====问题2: goods_name 不能重复,所以需要添加参数化
@pytest.mark.parametrize("goods_name", ["ADcarry12", "ADcarry13"])
def test_add_goods(self, goods_name):
# 3. 上架商品接口
url = "http://litemall.hogwarts.ceshiren.com/admin/goods/create"
goods_data = {
"goods": {"picUrl": "", "gallery": [], "isHot": False, "isNew": True, "isOnSale": True, "goodsSn": "9001",
"name": goods_name}, "specifications": [{"specification": "规格", "value": "标准", "picUrl": ""}],
"products": [{"id": 0, "specifications": ["标准"], "price": "66", "number": "66", "url": ""}],
"attributes": []}
# 问题: token 是 手动复制进去的,一旦发生变化,还需要再次修改
# 解决方案: token 需要自动完成获取,并且赋值
r = requests.post(url, json=goods_data, headers={"X-Litemall-Admin-Token": self.token})
# 打印响应体内容
# print(r.json())
# logger.debug(f"上架商品接口接口的相应信息为{r.json()}")
logger.debug(f"上架商品接口接口的相应信息为{json.dumps(r.json(), indent=2, ensure_ascii=False)}")
# 4. 获取商品列表
goods_list_url = "http://litemall.hogwarts.ceshiren.com/admin/goods/list"
# 是一个get请求,参数需要通过params也就是url参数传递
goods_data = {
"name": goods_name,
"order": "desc",
"sort": "add_time"
}
r = requests.get(goods_list_url, params=goods_data,
headers={"X-Litemall-Admin-Token": self.token})
self.goods_id = r.json()["data"]["list"][0]["id"]
logger.debug(f"获取商品列表接口的响应信息为{json.dumps(r.json(), indent=2, ensure_ascii=False)}")
# 5.获取商品详情接口=========
goods_detail_url = "http://litemall.hogwarts.ceshiren.com/admin/goods/detail"
r = requests.get(goods_detail_url, params={"id": self.goods_id},
headers={"X-Litemall-Admin-Token": self.token} )
product_id = r.json()["data"]["products"][0]["id"]
logger.debug(f"获取商品详情接口的响应信息为{json.dumps(r.json(), indent=2, ensure_ascii=False)}")
# 6. 添加购物车接口
url = "http://litemall.hogwarts.ceshiren.com/wx/cart/add"
# 问题: goodsId 和 productId 是写死的,变量的传递没有完成
# 解决方案: goodsId 和 productId 从其他的接口获取,并传递给添加购物车接口
cart_data = {"goodsId": self.goods_id, "number": 1, "productId": product_id}
r = requests.post(url, json=cart_data, headers={"X-Litemall-Token": self.client_token})
res = r.json()
logger.info(f"添加购物车接口响应信息为{json.dumps(r.json(), indent=2, ensure_ascii=False)}")
# ===============问题1: 缺少断言
# ===============解决: 添加断言
assert res["errmsg"] == "成功"
接口加密与解密
大纲
- 环境准备
- 实战练习
环境准备
- 对响应加密的接口。对它发起一个get请求后,得到一个加密过后的响应信息。(如果有可用的加密过的接口以及了解它的解密方法,可以跳过)
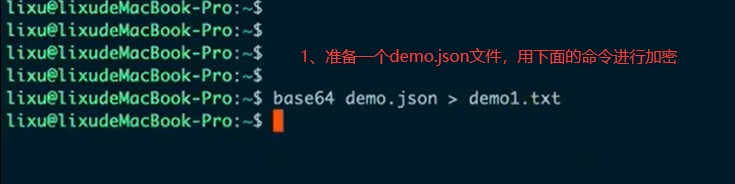
- 准备一个加密文件
- 使用python命令在有加密文件的所在目录启动一个服务
- 访问该网站
mac和linux都自带base64算法
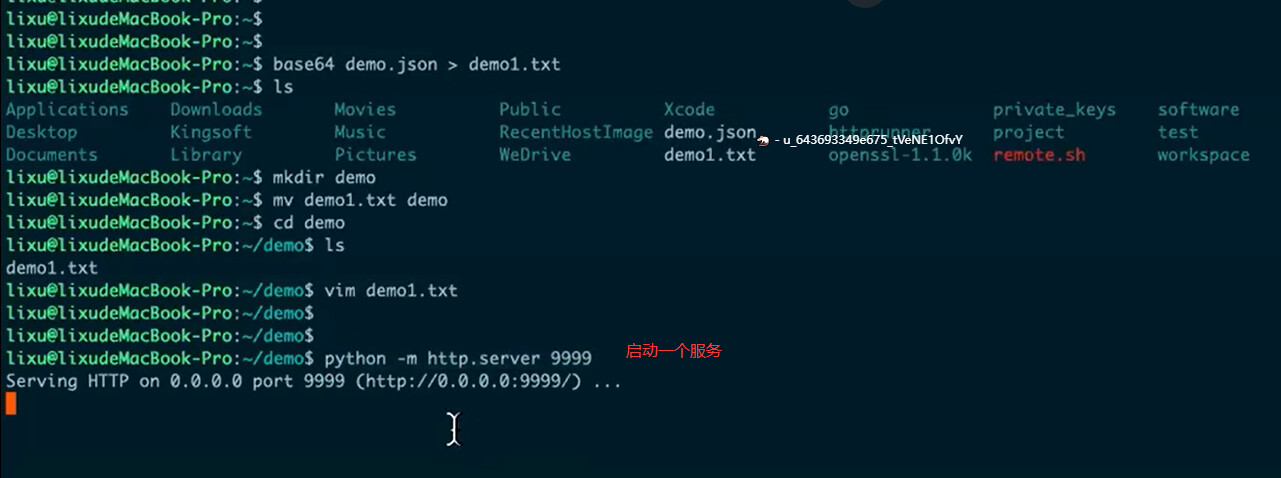
python -m http.server 9999
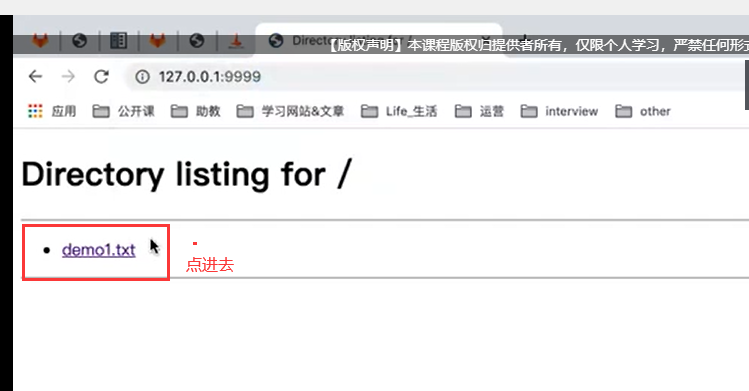
启动后本地访问地址:127.0.0.1:9999
原理
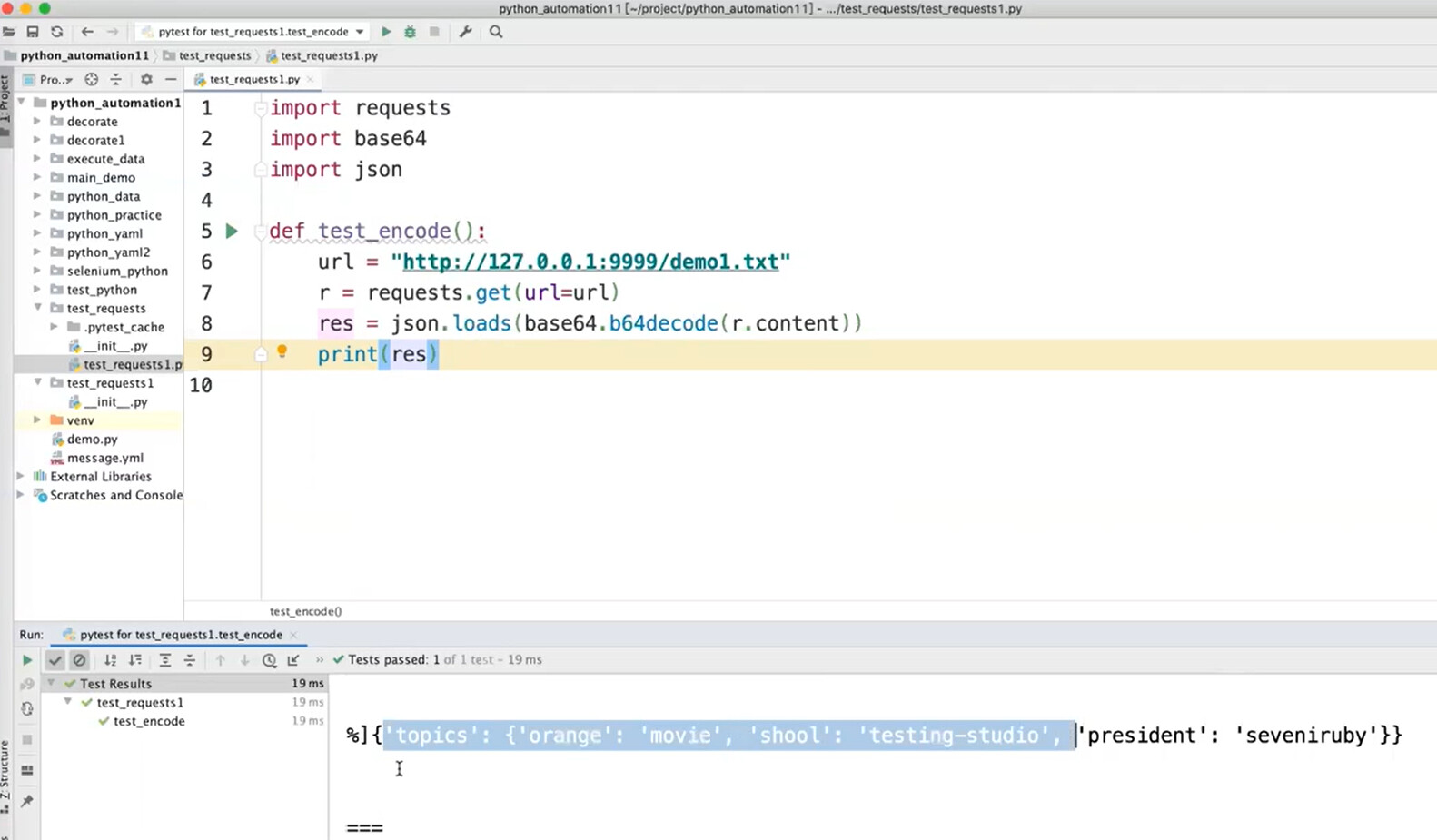
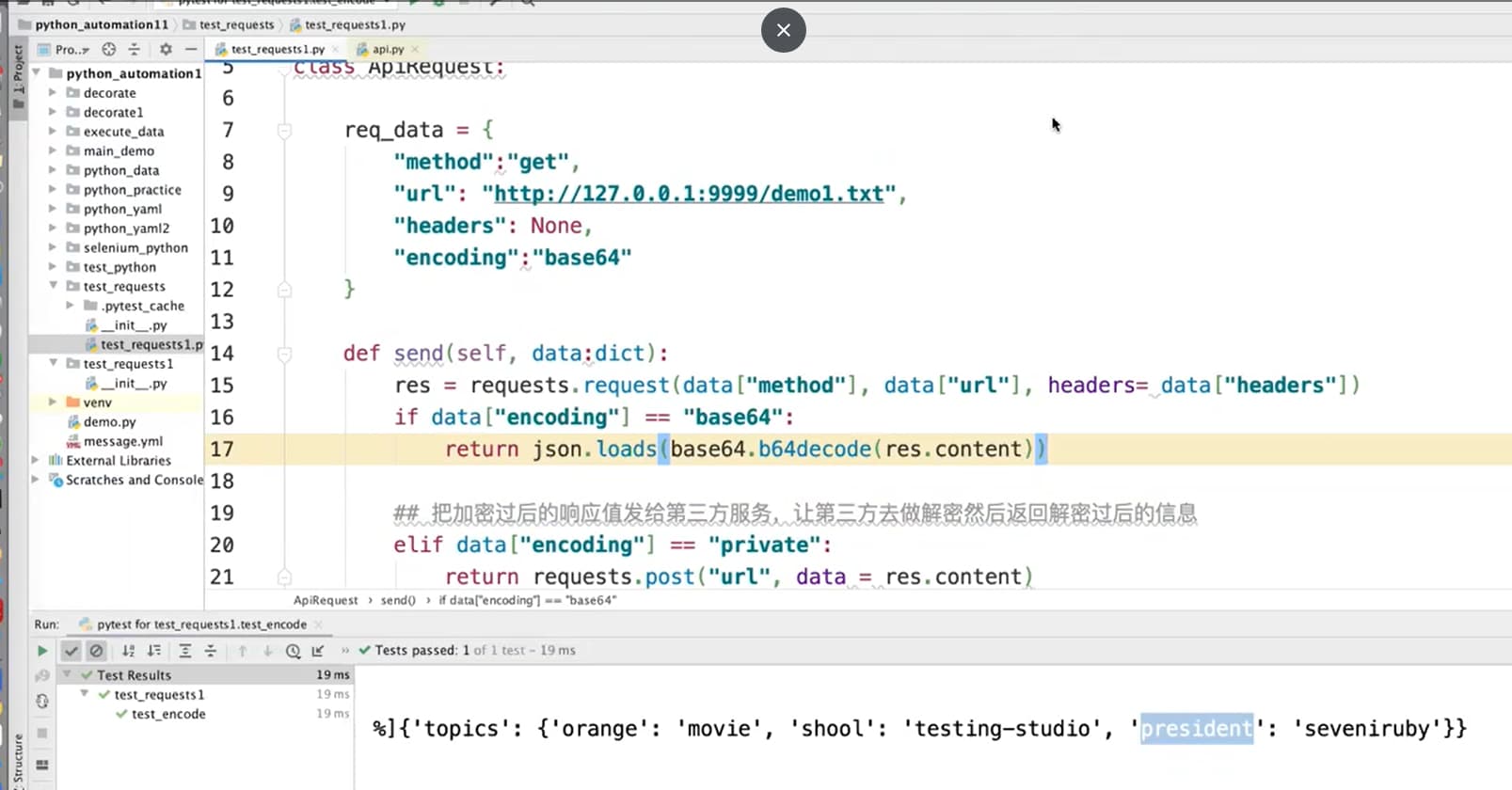
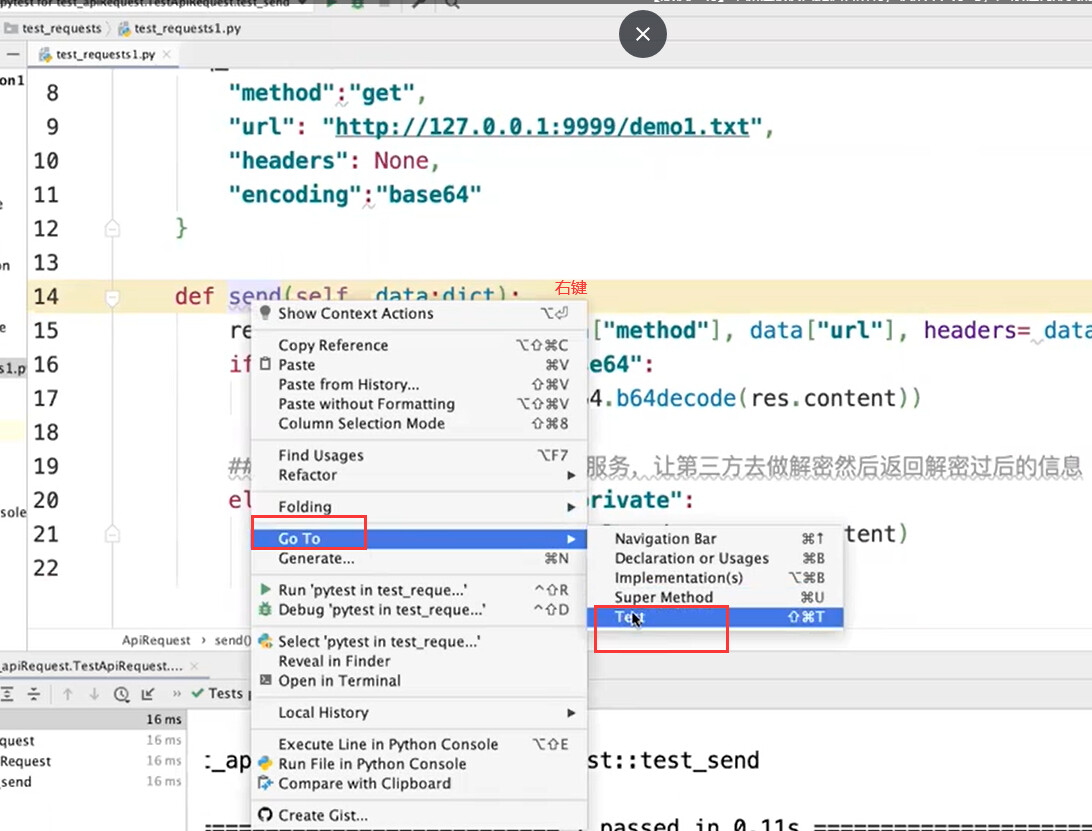
在得到响应后对响应做解密处理: 1. 如果知道使用的是哪个通用加密算法的话,可以自行解决。 2. 如果不了解对应的加密算法的话,可以让研发提供加解密的lib。 3. 如果既不是通用加密算法、研发也无法提供加解密的lib的话,可以让加密方提供远程解析服务,这样算法仍然是保密的。
实战练习
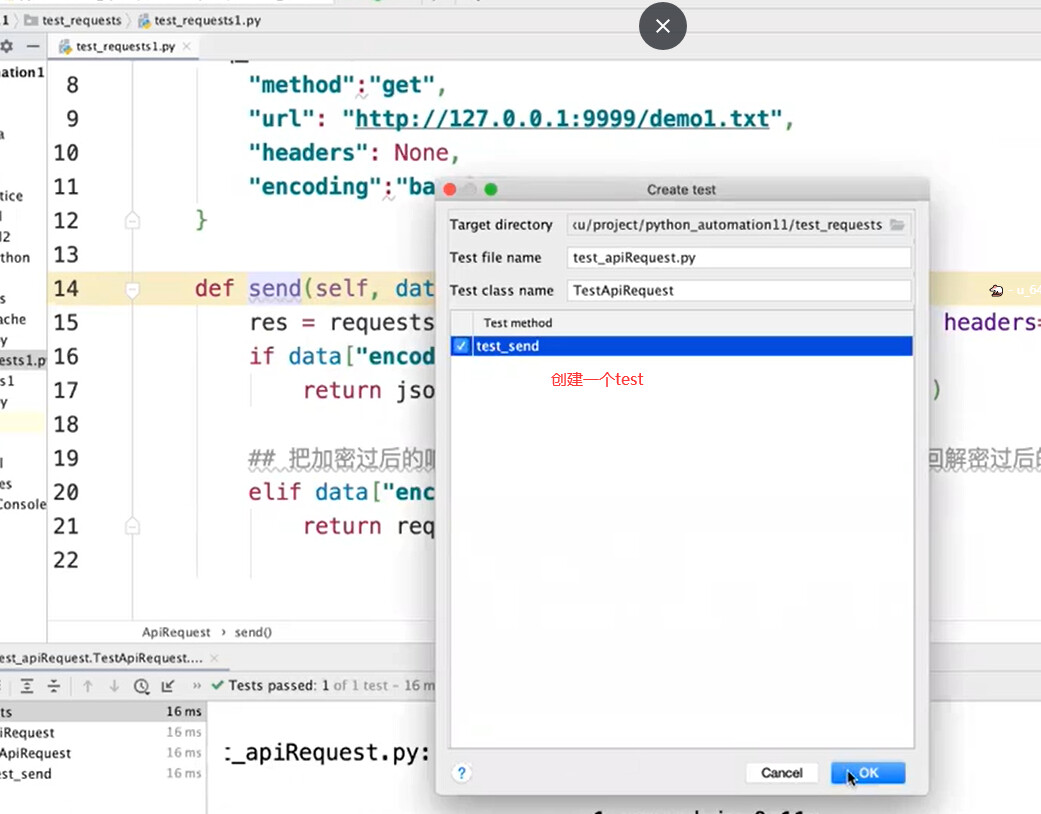
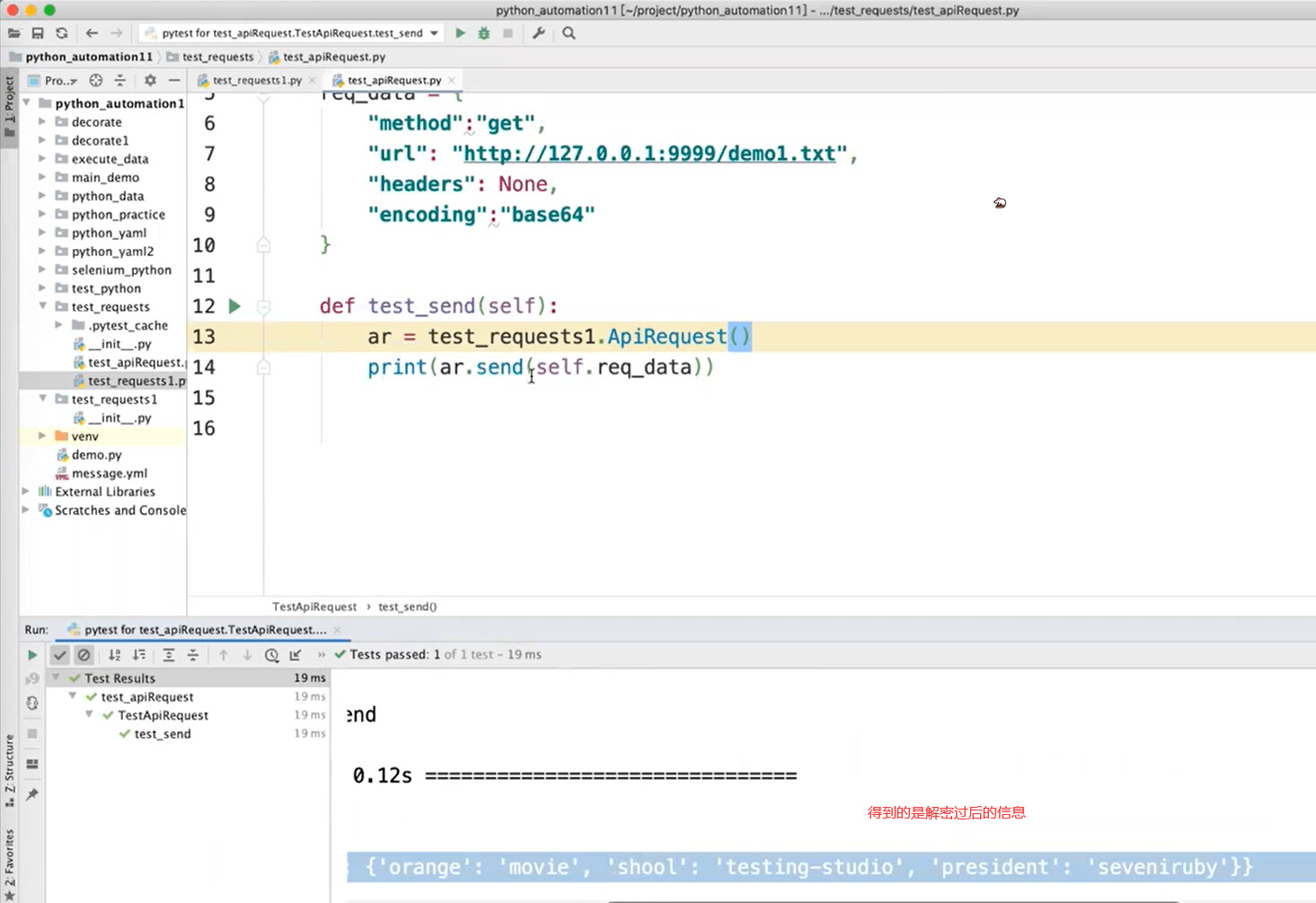
- 调用python自带的base64,直接对返回的响应做解密,即可得到解密后的响应。
- 封装对于不同算法的处理方法。
解密:
封装的算法:
多套被测环境

多环境介绍
| 环境 | 使用场景 | 备注 |
|---|---|---|
| dev | 开发环境 | 开发自测 |
| QA | 测试环境 | QA日常测试 |
| preprod | 预发布环境 | 回归测试、产品验测试 |
| prod | 线上环境 | 用户使用的环境 |
多套被测环境切换的意义和价
- 访问信息: 不同环境的域名或ip都不一样,部分产品Host也会有区别
- 配置信息: DB、Redis、ES等中间件的配置信息不同环境也不一样
# 每条用例的url都是写死的,一旦切换环境,所有的用例都要修改。
r = requests.post("https://httpbin.ceshiren.com/post",
data=data)
实现目标
- 全局控制,一键切换
- 可维护性和扩展性强,可以应对不断演进的环境变化。
- 环境管理
- 环境切换
实现方案-环境管理
- 使用环境管理文件
- yaml
- ini
- 常量类
- 使用不同的文件管理不同的环境
- 在接口用例中只指定path,不指定url
# test.yaml 测试环境的配置
env_config:
base_url: https://httpbin.org/
db_config:
host: httpbin.org
username: xxxx
password: xxxx
redis_config:
host: httpbin.org
port: 8100
# dev.yaml 开发环境的配置
env_config:
base_url: https://httpbin.ceshiren.com/
db_config:
host: httpbin.ceshiren.com
username: xxxx
password: xxxx
redis_config:
host: httpbin.ceshiren.com
port: 8100
环境切换
- 通过环境变量进行切换
- 通过命令行参数进行切换
通过环境变量进行切换
- 设置环境变量
- 读取环境变量
# mac设置环境变量
export env=dev
# windows 设置环境变量
set env=dev
# 在python中读取环境变量
import os
import requests
import yaml
class TestMulitiEnv:
def setup_class(self):
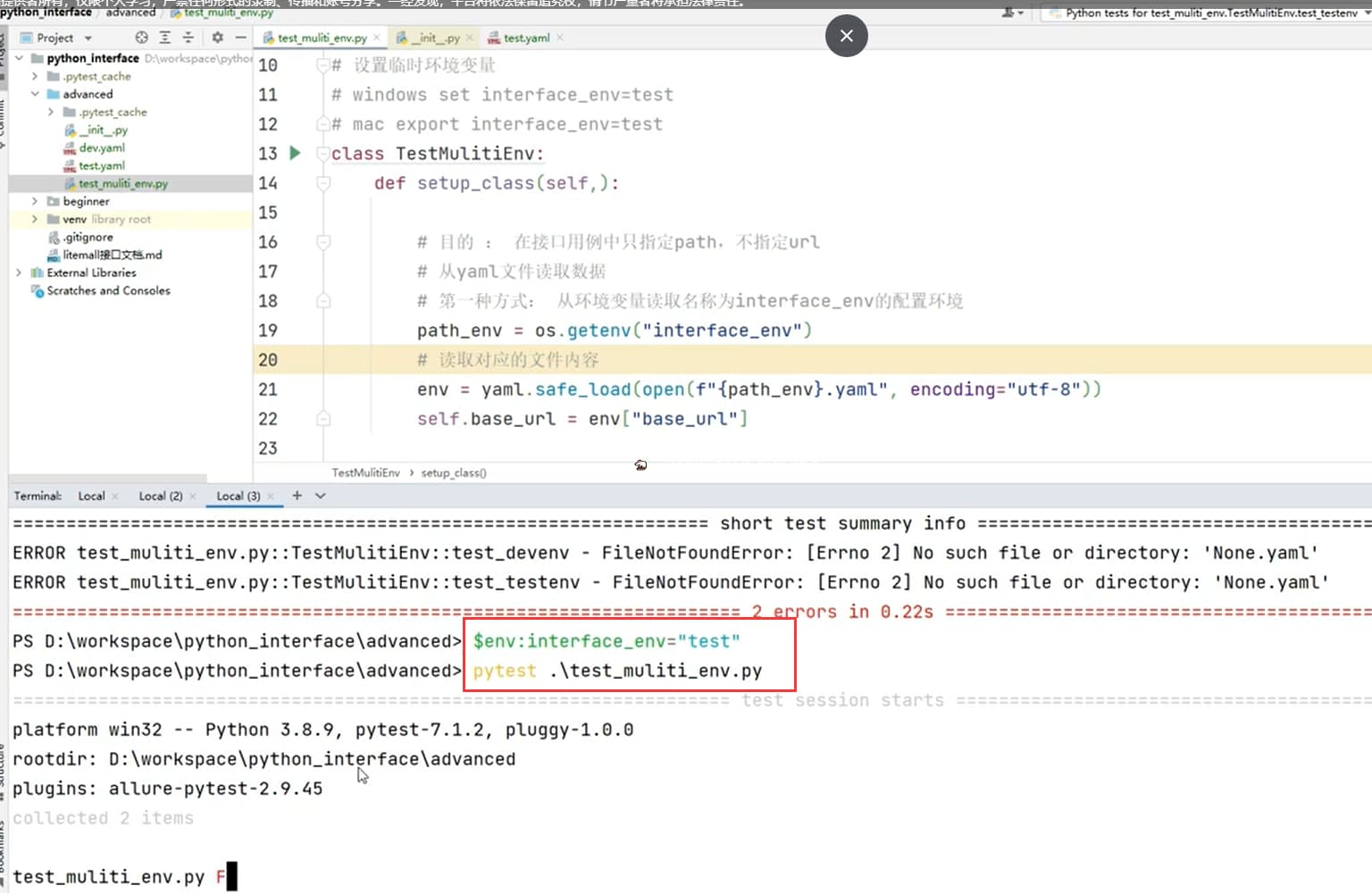
default = os.getenv("env", default="test")
data = yaml.safe_load(open(f"{default}.yaml"))
self.env = data
self.base_url = self.env["env_config"]["base_url"]
def test_devenv(self):
path = "/get"
r = requests.get(self.base_url+path)
assert r.json()["headers"]["Host"] == "httpbin.org"
def test_testenv(self):
path = "/post"
r = requests.post(self.base_url+path)
assert r.json()["headers"]["Host"] == "httpbin.ceshiren.com"
使用命令行进行切换
与《selenium 多浏览器处理》章节逻辑相同
participant 命令行参数 as command
participant 测试用例 as cases
participant 环境配置 as env
autonumber
command -> cases : 通过命令执行测试用例,通过参数指定环境
command -> env: 通过命令行参数获取指定的环境
cases -> env: 测试用例获取指定的环境。如果没有指定,那么就执行默认的环境
# conftest.py
global_env = {}
def pytest_addoption(parser):
# group 将下面所有的 option都展示在这个group下。
mygroup = parser.getgroup("hogwarts")
# 注册一个命令行选项
mygroup.addoption("--env",
# 参数的默认值
default='test',
# 存储的变量
dest='env',
# 参数的描述信息
help='设置接口自动化测试默认的环境'
)
def pytest_configure(config):
default_ev = config.getoption("--env")
tmp = {"env": default_ev}
global_env.update(tmp)
# test_muliti_env.py
class TestMulitiEnv:
def setup_class(self):
# 获取命令行配置的环境变量
default = global_env.get("env", "test")
data = yaml.safe_load(open(f"{default}.yaml"))
self.env = data
self.base_url = self.env["env_config"]["base_url"]
def test_devenv(self):
path = "/get"
r = requests.get(self.base_url+path)
assert r.json()["headers"]["Host"] == "httpbin.org"
def test_testenv(self):
path = "/post"
r = requests.post(self.base_url+path)
assert r.json()["headers"]["Host"] == "httpbin.ceshiren.com"
多协议封装设计
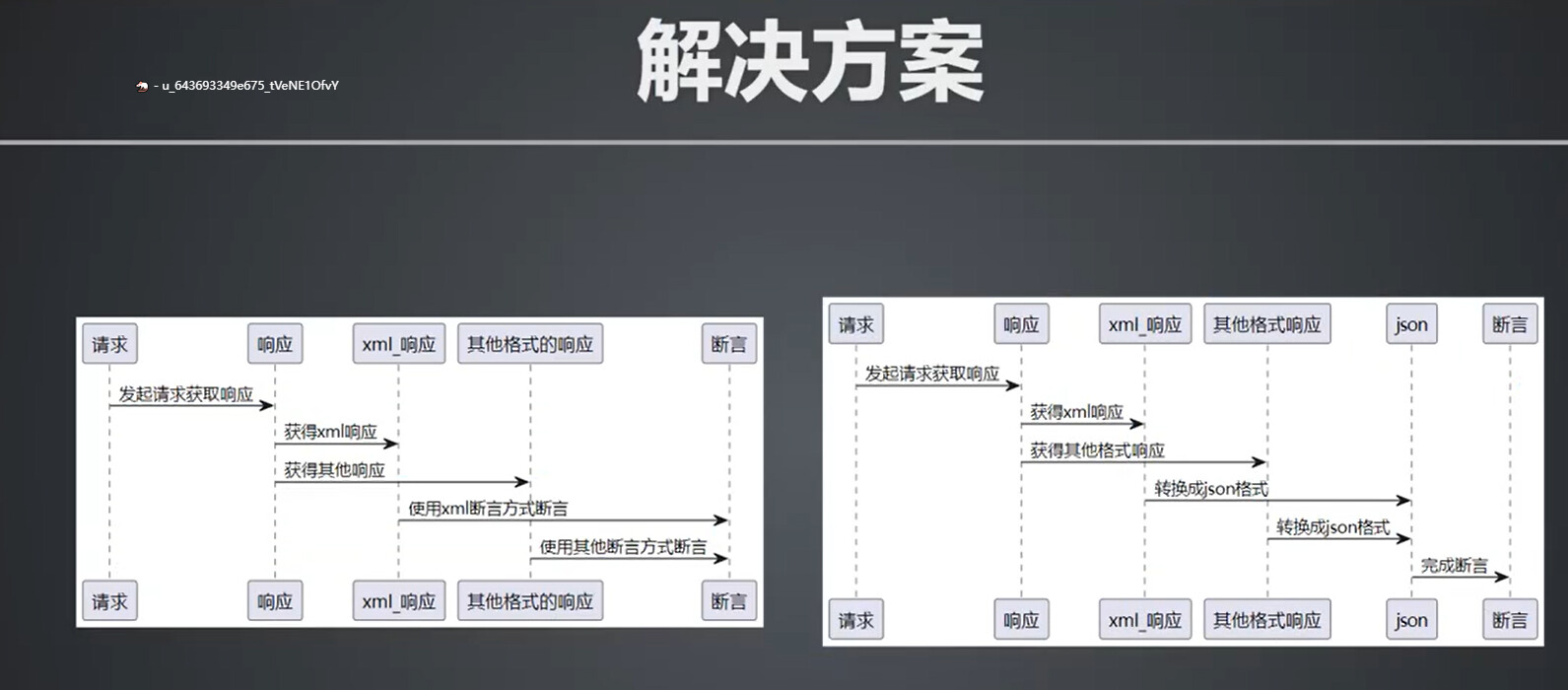
多协议封装应用场景
- 问题:
- 响应值不统一
- json
- xml
- 断言比较困难
- 响应值不统一
解决方案:获得的响应信息全部转换为结构化的数据进行处理
解决方案
实战演示
实战目标: 对响应值做二次封装,可以使用统一提取方式完成断言
- 环境准备: pip install xmltodict
- 依赖包版本: 0.13
import json
import xmltodict
import requests
def test_xml_res():
"""
xml转换为json
:return:
"""
res = requests.get("https://www.nasa.gov/rss/dyn/lg_image_of_the_day.rss")
dict_res = xmltodict.parse(res.text)
多协议封装(Python)
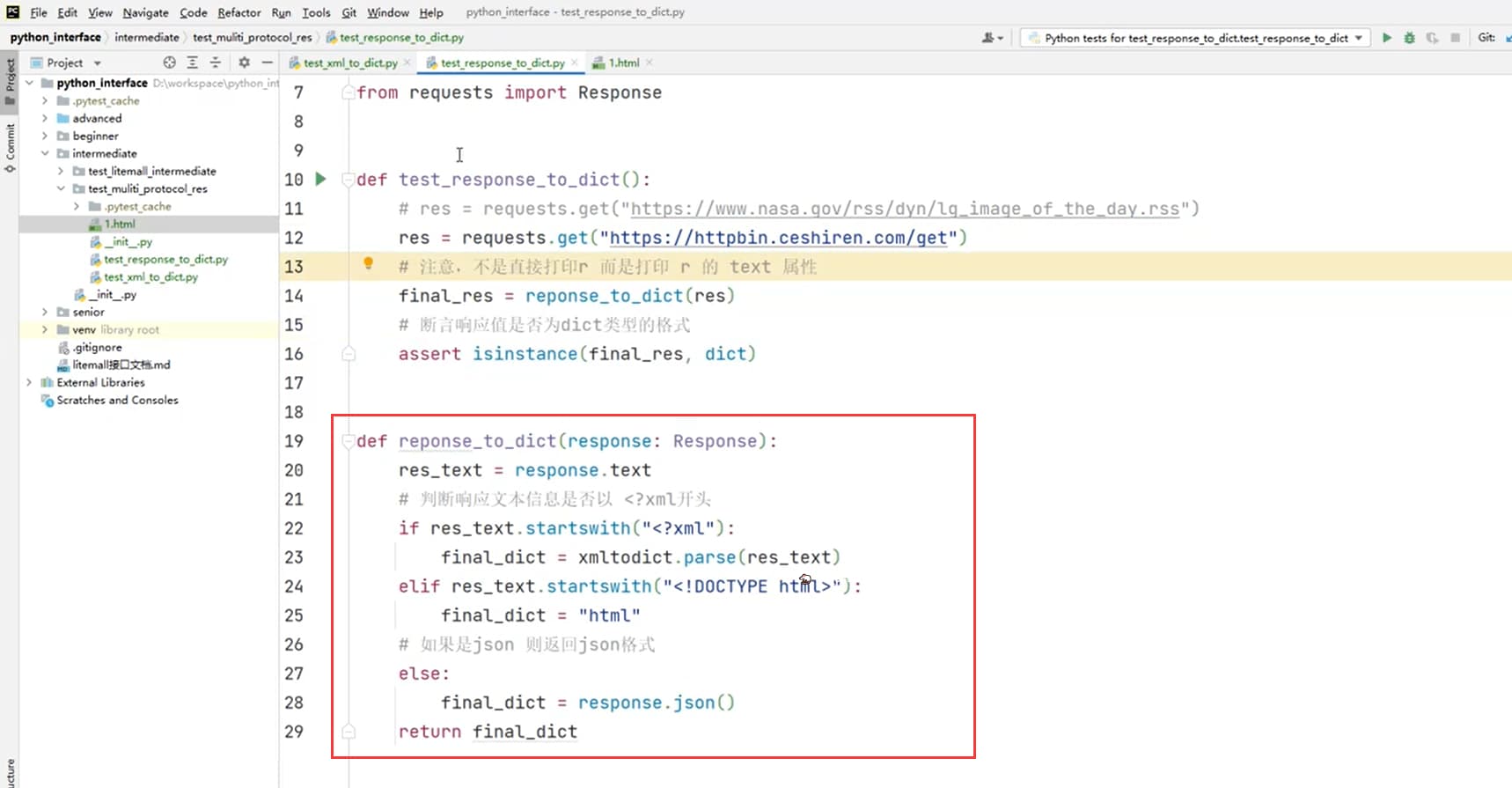
def response_to_dict(response: Response):
"""
获取 Response对象,将多种响应格式统一转换为dict
:param response:
:return:
"""
res_text = response.text
if res_text.startswith("<?xml"):
final_res = xmltodict.parse(res_text)
else:
final_res = response.json()
return final_res
# 测试响应是否可以转换为dict
def test_response_to_dict():
"""
xml转换为json
:return:
"""
# res = requests.get("https://www.nasa.gov/rss/dyn/lg_image_of_the_day.rss")
res = requests.get("https://httpbin.ceshiren.com/get")
r = response_to_dict(res)
assert isinstance(r, dict)
xml 转换 dict(Python)
WebSocket 协议的接口测试

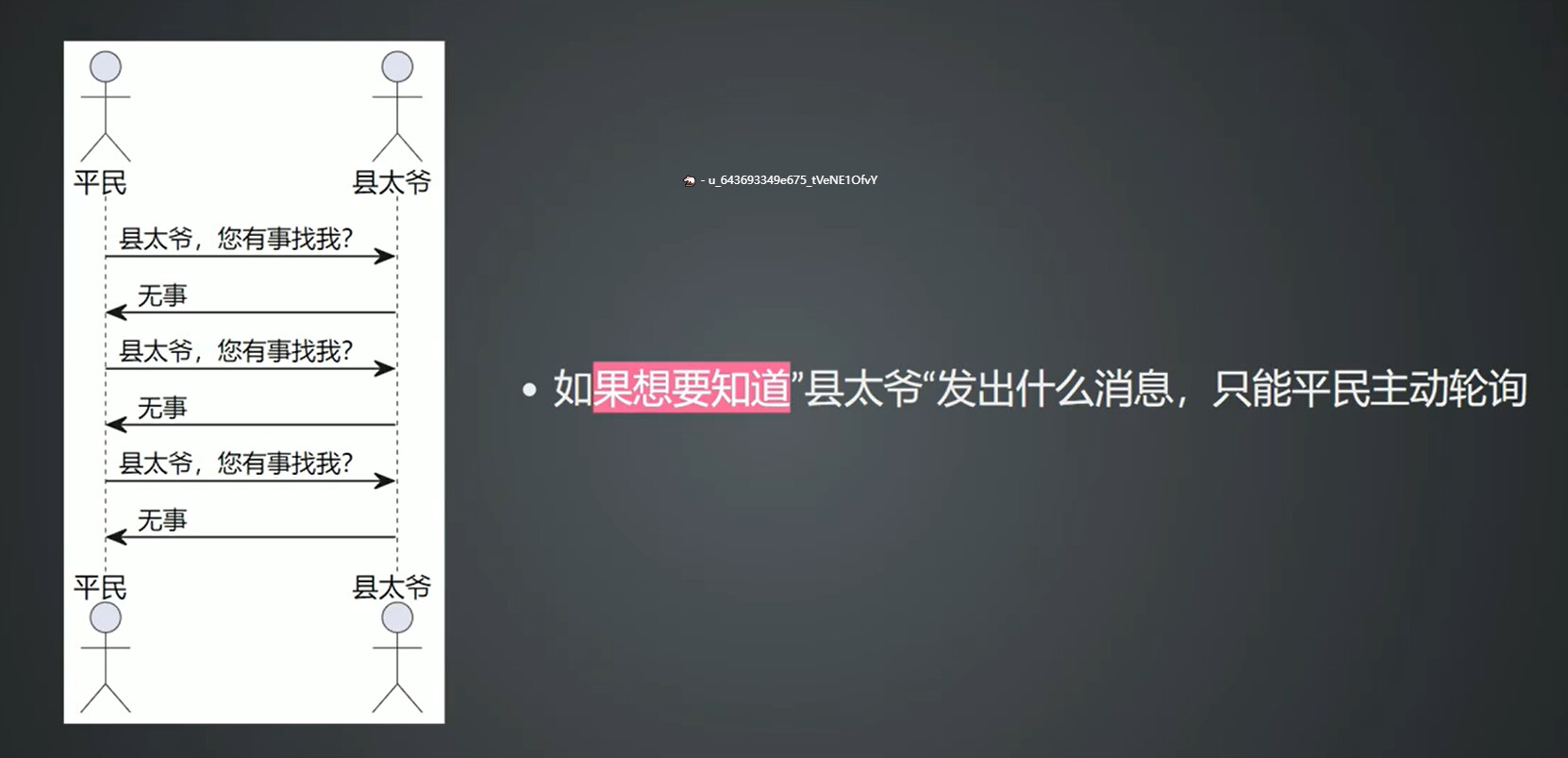
一次请求对应一次响应
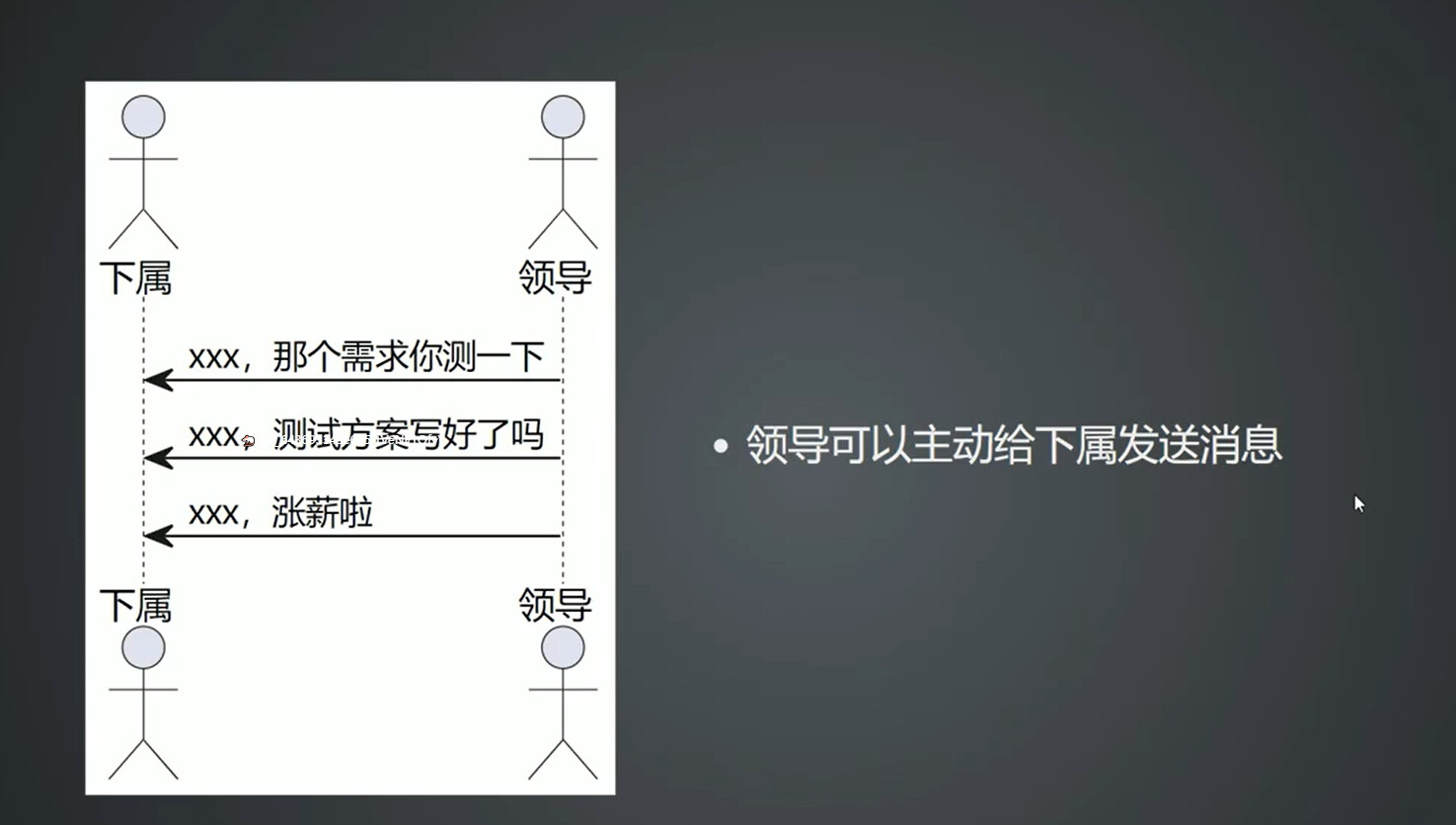
服务端可以主动给客户端发送消息的

微信、游戏使用的是websocket协议
直到请求关闭连接




WebSocket 协议
- 服务器可以主动向客户端推送信息,客户端也可以主动向服务器发送信息
- 数据格式比较轻量,性能开销小,通信高效。
- 可以发送文本,也可以发送二进制数据。
- 协议标识符是 ws(如果加密,则为 wss),服务器网址就是 URL。
title Websocket协议
participant Client as c
participant Server as s
c -> s: 请求握手
s -> c: 握手确认
s -> c: "AD"拍了拍你,并向你丢了一颗鸡蛋
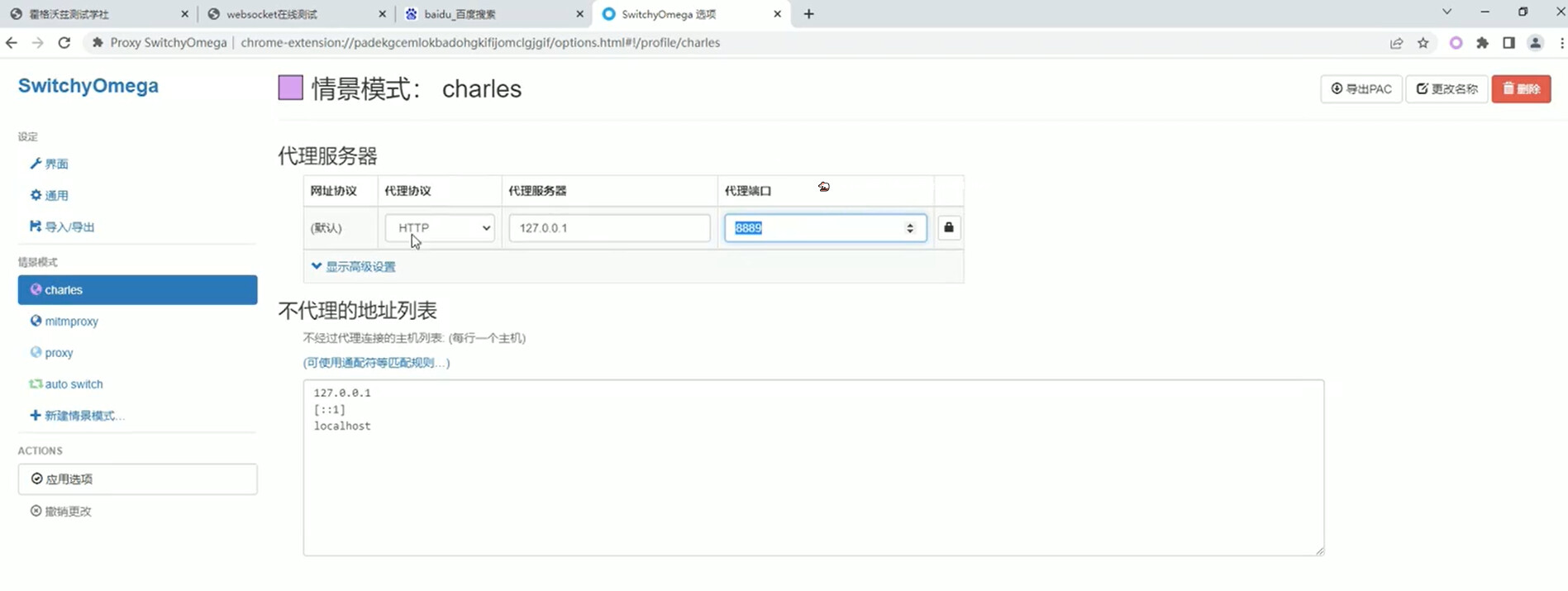
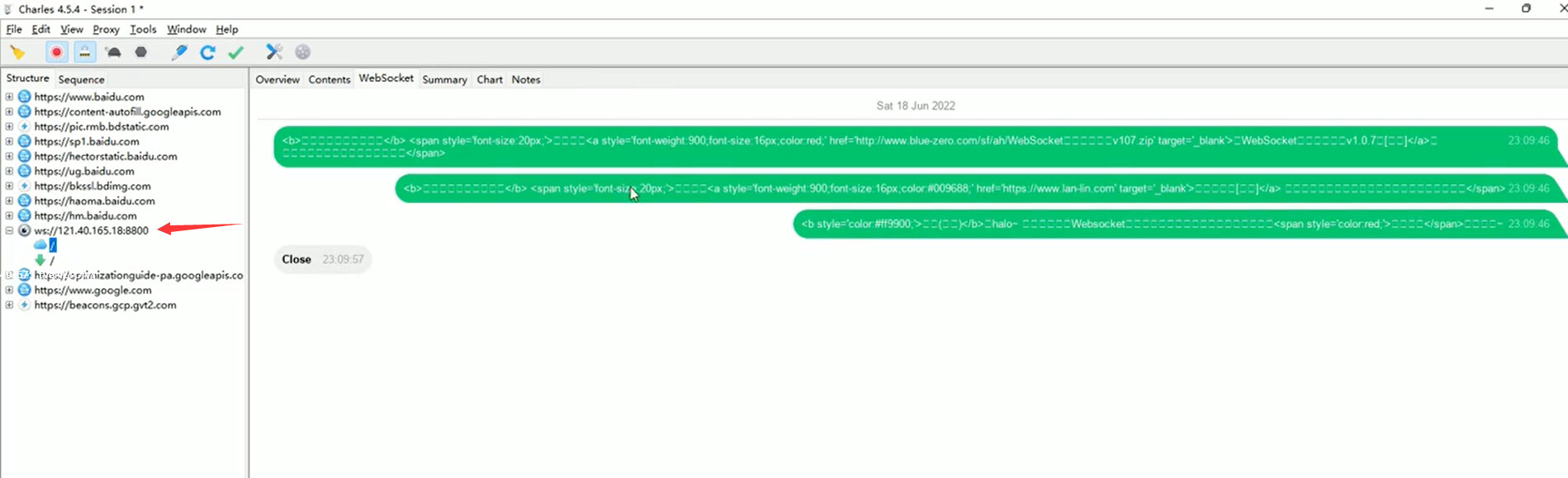
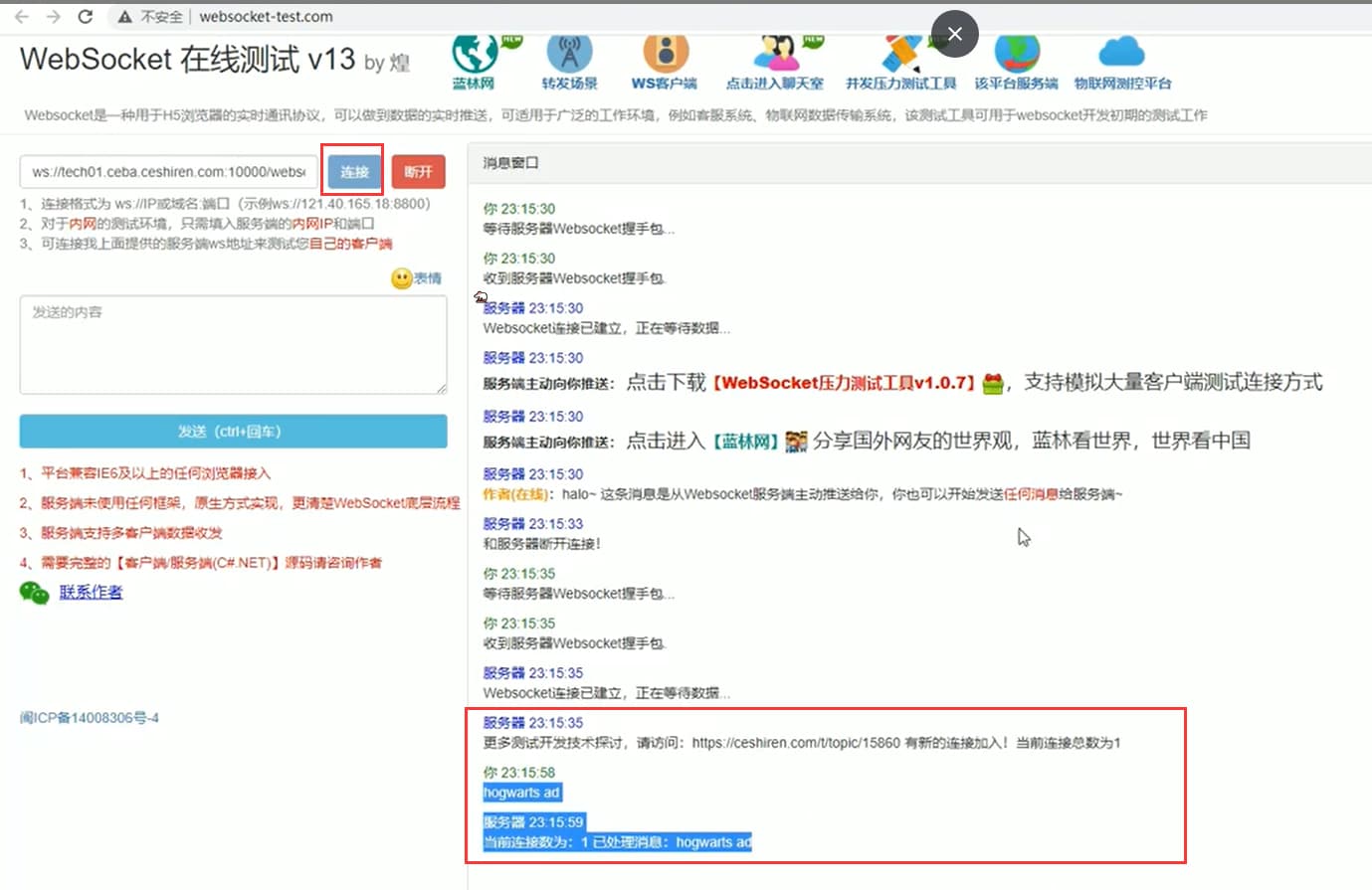
WebSocket 协议 - Charles 抓包
- 浏览器添加代理配置
- 访问演示网站
- 查看 websocket 数据包信息
演示网站:http://www.websocket-test.com/
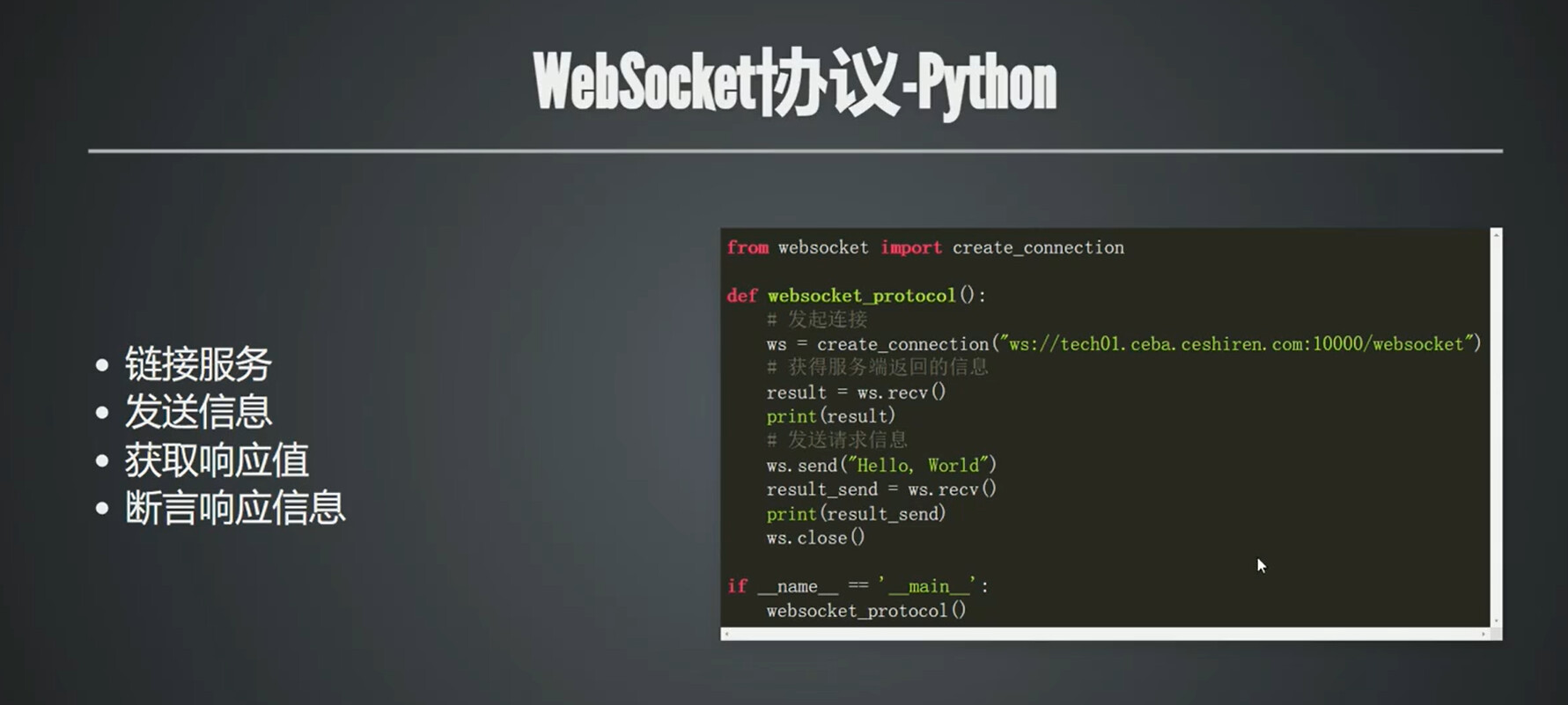
WebSocket 协议 - Python
- 链接服务
- 发送信息
- 获取响应值
- 断言响应信息
from websocket import create_connection
def websocket_protocol():
# 发起连接
ws = create_connection("ws://tech01.ceba.ceshiren.com:10000/websocket")
# 获得服务端返回的信息
result = ws.recv()
print(result)
# 发送请求信息
ws.send("Hello, World")
result_send = ws.recv()
print(result_send)
ws.close()
if __name__ == '__main__':
websocket_protocol()
上课代码:
from websocket import create_connection
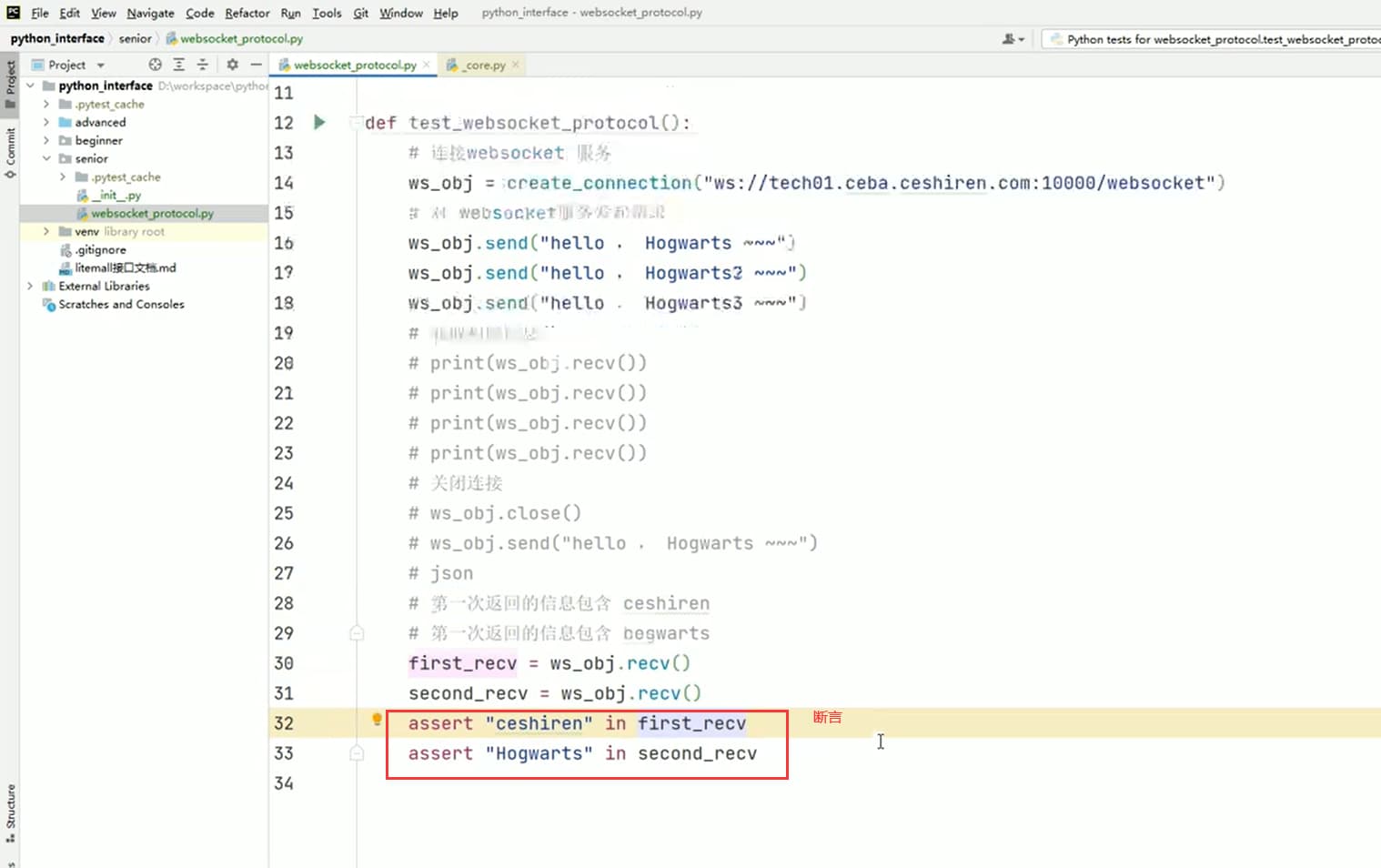
def test_websocket_protocol():
# 连接websocket 服务
ws_obj = create_connection("ws://tech01.ceba.ceshiren.com:10000/websocket")
# 对 websocket服务发起请求
ws_obj.send("hello , Hogwarts ~~~")
ws_obj.send("hello , Hogwarts2 ~~~")
ws_obj.send("hello , Hogwarts3 ~~~")
# 获取相应信息
# print(ws_obj.recv())
# print(ws_obj.recv())
# print(ws_obj.recv())
# print(ws_obj.recv())
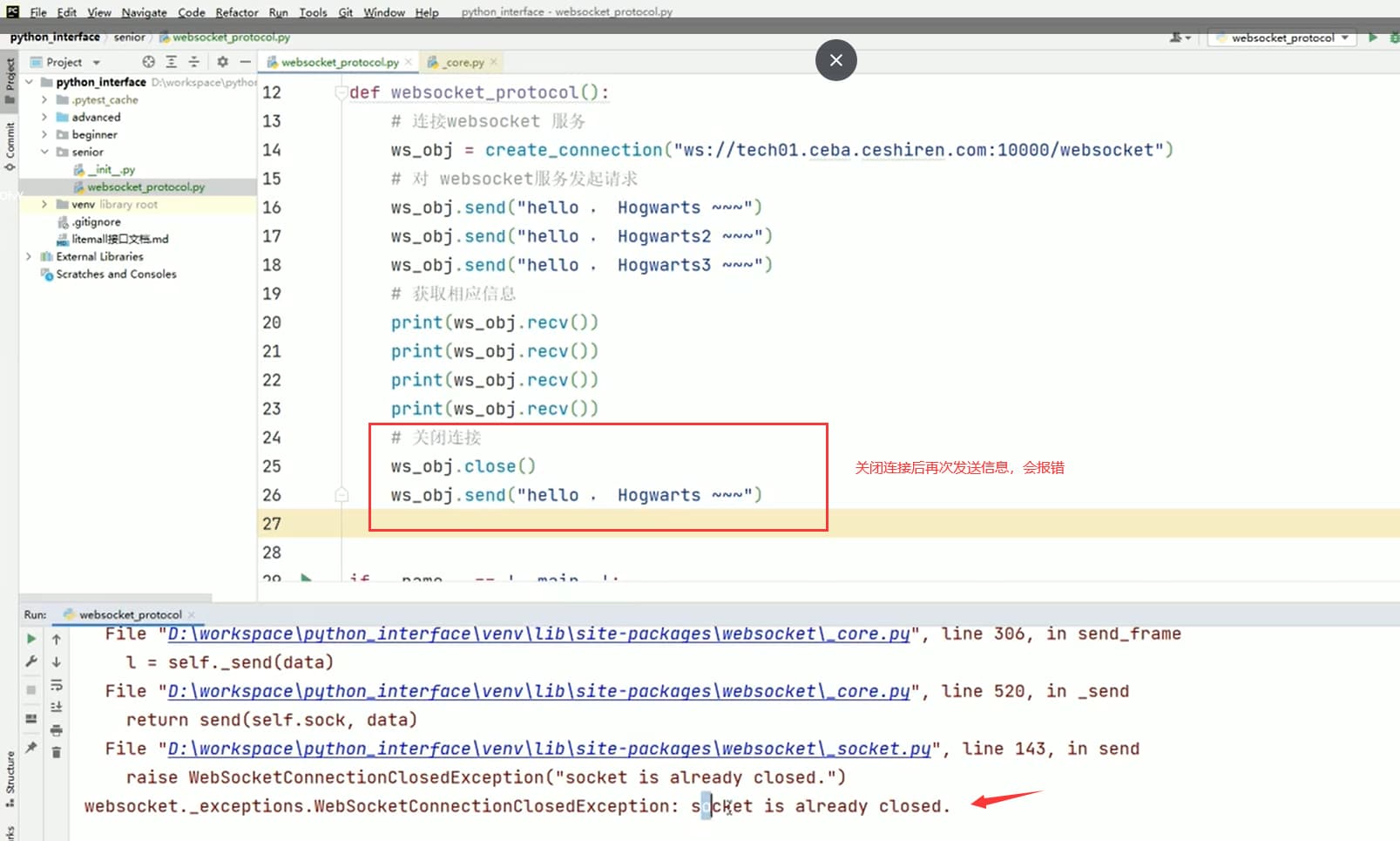
# 关闭连接
# ws_obj.close()
# ws_obj.send("hello , Hogwarts ~~~")
# json
# 第一次返回的信息包含 ceshiren
# 第一次返回的信息包含 hogwarts
first_recv = ws_obj.recv()
second_recv = ws_obj.recv()
assert "ceshiren" in first_recv
assert "Hogwarts" in second_recv
生成单元测试用例:
har 生成用例
目录
- 课程目标
- 应用场景
- Har 介绍
- har 生成用例
课程目标
- 掌握 Har 转换成脚本的能力。
应用场景
- 通过 Har 格式的接口数据,转换为接口自动化测试脚本:
- 提升脚本的编写效率
- 降低脚本的出BUG的几率

HttpRunner的har2case生成用例功能
Har 简介
- Har格式是指HTTP归档格式(HTTP Archive Format)。
- 用于记录HTTP会话信息的文件格式。
- 多个浏览器都可以生成 Har 格式的数据。
实现思路
title Har 格式转换为测试用例
autonumber
participant har
participant 用例 as testcase
participant 接口信息 as data
participant 模版技术 as template
group 获取用例信息阶段
har -> data: 从har格式数据中提取测试用到的接口信息
end
group 生成用例阶段
testcase -> template: 在原有的用例格式基础之上定义一个模版
data -> template: 接口信息填入到模版中,生成测试用例
end
相关技术
- 文件读写
- 模版技术
模板技术
- Mustache是一种轻量级的模板语言。
- 需要定义模板,然后可以将数据填充到设定好的位置。
- 官网地址:https://mustache.github.io/
# 模版
Hello {{name}}!
# 填充name的位置
Hello AD!
模版技术-环境安装(Python)
环境安装
pip install chevron
模版技术使用(Python)
- 参数1: 模板数据
- 参数2: 要替换的数据
import chevron
chevron.render('Hello, {{ mustache }}!', {'mustache': 'World'})
har 生成用例实现思路
- 读取Har数据。
- 提前准备测试用例模版。
- 将读取的Har数据写入到模板中。
常用模板
# python 接口测试用例
import requests
def test_request():
r = requests.get(url="{{url}}")
har 生成用例实现(Python)
import json
import pymustache
class GenerateCase:
# 读取har 文件的数据。
def __load_har(self, har_filename):
with open(har_filename) as f:
har_data = json.load(f)
return har_data["log"]["entries"][0]["request"]
# 根据 har 文件生成用例。
def generate_case_by_har(self, origin_template, tescase_filename, har_filename):
with open(origin_template) as f:
template_data = pymustache.render(f.read(), self.__load_har(har_filename))
with open(f"{tescase_filename}.py", "w") as f:
f.write(template_data)
