一、时间模块
1、时间模块有:
1)time
2)datetime(内置库)
3)calendar:日历方面
datetime 常用的类
1)datetime.datetime:表示日期时间的类
2)datetime.timedelta:表示时间间隔的类
3)datetime.date:表示日期的类
4)datetime.time:表示时间的类
5)datetime.tzinfo:时区相关的类
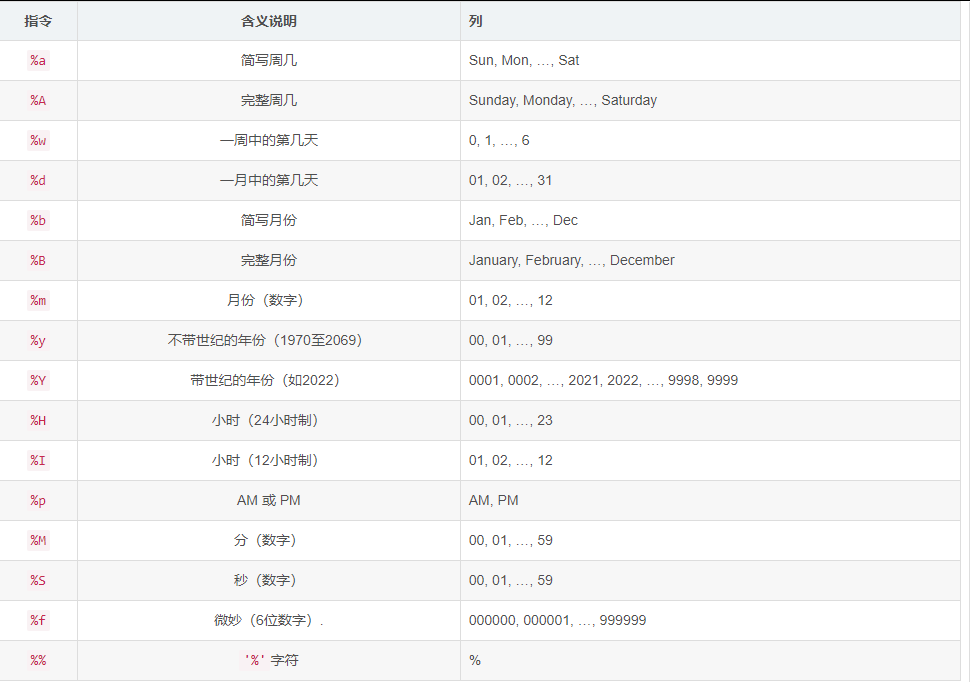
练习1 - 获取当前日期和时间
import datetime
# 获取当前时间
now = datetime.datetime.now()
print(now)
print(f'当前年份是{now.year}年')
print(f'当前月份是{now.month}月')
print(f'当前是{now.day}号')
# 获取当前时间的时间戳
print(now.timestamp())
# 获取指定时间
print(datetime.datetime(2023, 5, 20))
练习2 - 字符串与时间互转
s="2021-09-27 06:47:06"
# 将字符串 转换为datetime实例
s1=datetime.datetime.strptime(s,'%Y-%m-%d %H:%M:%S')
# 时间转成字符串
now = datetime.datetime.now()
result = now.strftime('%a, %b %d %H:%M')
练习3 - 时间戳 与时间互转
import datetime
mtimestamp = 1632725226.129461
# 将时间戳转成时间
s = datetime.datetime.fromtimestamp(mtimestamp)
# 将时间转成时间戳
print(s.timestamp())
写一段代码,生成一个以时间命名的日志文件。并向日志文件中写入日志数据。
import datetime
# 获取当前时间的时间戳
now = datetime.datetime.now()
# 将时间戳转为str格式
str1 = now.strftime('%Y %m %d %H:%M:%S')
# 以日期生成文件名称时,时间不能加符号
str12 = now.strftime('%Y%m%d_%H%M%S')
print(f'当前时间为{str12}')
# 生成日志文件
log_time = str12 + '.log'
with open(log_time, 'w+', encoding='utf-8') as f:
message = f'{now} [info] line: 13 this is a message'
f.write(message)
内置库-json
一、json概述
JSON 是用于存储和交换数据的语法,是一种轻量级的数据交换格式。
使用场景
接口数据传输
序列化
配置文件
二、json结构
键值对形式
数组形式
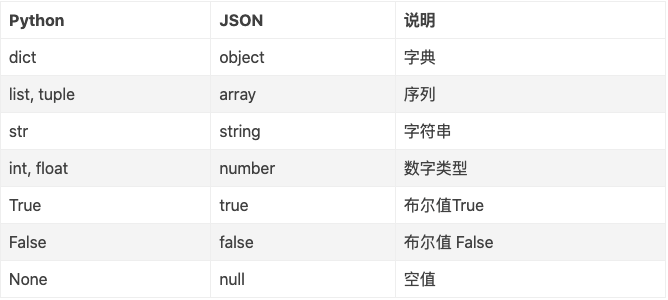
三、 Python 与 JSON 数据类型对应
四、 json 库
可以从字符串或文件中解析 JSON
该库解析 JSON 后将其转为 Python 字典或者列表
五、常用方法
dumps():将 Python 对象编码成 JSON 字符串
loads():解码 JSON 数据,该函数返回 Python 对象
dump(): Python 对象编码,并将数据写入 json 文件中
load():从 json 文件中读取数据并解码为 Python 对象
json和python相互转化
import json
date = {'a': 1, 's': [1, 2, 3, 4], 'd': True, 'f': False, 'w': None, 'qw': 2.35}
# 将python对象转为json,indent是换行显示
json_date = json.dumps(date, indent=4)
print(json_date)
# 把date数据写入json文件中
with open('date.json', 'w', encoding='utf-8')as f:
json.dump(date, f)
# 读取json文件
with open('date.json', 'r')as f:
data = json.load(f)
print(data)
# 将json转化为python类型
json_num = '''{"a": 1, "s": [1, 2, 3, 4], "d": true, "f": false, "w": null, "qw": 2.35}'''
python_date = json.loads(json_num)
print(python_date)
----------------------------------------->
{
"a": 1,
"s": [
1,
2,
3,
4
],
"d": true,
"f": false,
"w": null,
"qw": 2.35
}
{'a': 1, 's': [1, 2, 3, 4], 'd': True, 'f': False, 'w': None, 'qw': 2.35}
{'a': 1, 's': [1, 2, 3, 4], 'd': True, 'f': False, 'w': None, 'qw': 2.35}
内置库-re
正则表达式
一、概念
正则表达式就是记录文本规则的代码
可以查找操作符合某些复杂规则的字符串
二、使用场景
处理字符串
处理日志
三、 在 python 中使用正则表达式
把正则表达式作为模式字符串
正则表达式可以使用原生字符串来表示
原生字符串需要在字符串前方加上 r'string'
正则表达式对象转换
compile():将字符串转换为正则表达式对象
需要多次使用这个正则表达式的场景
import re
str1 = r'sakasjkajs'
prog = re.compile(str1)
匹配字符串
match():从字符串的开始处进行匹配
search():在整个字符串中搜索第一个匹配的值
findall():在整个字符串中搜索所有符合正则表达式的字符串,返回列表
import re
'''
pattern: 正则表达式
string: 要匹配的字符串
flags: 可选,控制匹配方式
- A:只进行 ASCII 匹配
- I:不区分大小写
- M:将 ^ 和 $ 用于包括整个字符串的开始和结尾的每一行
- S:使用 (.) 字符匹配所有字符(包括换行符)
- X:忽略模式字符串中未转义的空格和注释
'''
import re
str1 = r'sa'
str2 = 'sasssssssaaaaaaaaa'
str3 = 'str'
# re.I代表忽略大小写
# search方法返回搜索到的第一个信息
# findall方法返回搜索到的所有信息
match1 = re.match(str1, str2, re.I)
match3 = re.search(str1, str2, re.I)
match4 = re.findall(str1, str2, re.I)
print(match1)
print(match3)
print(match4)
# 打印match信息
print(f'匹配值的起始位置:{match1.start()}')
print(f'匹配值的结束位置:{match1.end()}')
print(f'匹配值的元祖为:{match1.span()}')
print(f'匹配值的字符串为:{match1.string}')
print(f'匹配值的数据为:{match1.group()}')
# match方法是匹配开头,如果开头不是sa就会返回none
match2 = re.match(str1, str3, re.I)
print(match2)
-------------------------------->
<re.Match object; span=(0, 2), match='sa'>
<re.Match object; span=(0, 2), match='sa'>
['sa', 'sa']
匹配值的起始位置:0
匹配值的结束位置:2
匹配值的元祖为:(0, 2)
匹配值的字符串为:sasssssssaaaaaaaaa
匹配值的数据为:sa
None
替换字符串
sub():实现字符串替换
import re
'''
pattern:正则表达式
repl:要替换的字符串
string:要被查找替换的原始字符串
count:可选,表示替换的最大次数,默认值为 0,表示替换所有匹配
flags:可选,控制匹配方式
'''
re.sub(pattern, repl, string, [count], [flags])
patten = r'1[3579]\d{9}'
# 替换
s1 = '中奖号码是135686,联系电话是:13911111111'
result = re.sub(patten, '139xxxxxxxx', s1)
print(result)
分割字符串
split():根据正则表达式分割字符串,返回列表
import re
'''
pattern:正则表达式
string:要匹配的字符串
maxsplit:可选,表示最大拆分次数
flags:可选,控制匹配方式
'''
re.split(pattern, string, [maxsplit], [flags])
# 分割
patten1 = r'[?|=]'
url = 'https://mini.eastday.com/?qid=02157&jumpuk=230531071559323233648'
result2 = re.split(patten1, url)
print(result2)
