一、Web浏览器控制
- 模拟功能测试中对浏览器的操作:
| 操作 | 使用场景 | |
|---|---|---|
| get | 打开浏览器 | web自动化测试第一步 |
| refresh | 浏览器刷新 | 模拟浏览器刷新 |
| back | 浏览器退回 | 模拟退回步骤 |
| maximize_window | 最大化浏览器 | 模拟浏览器最大化 |
| minimize_window | 最小化浏览器 | 模拟浏览器最小化 |
实例:

代码:
from selenium import webdriver
import time
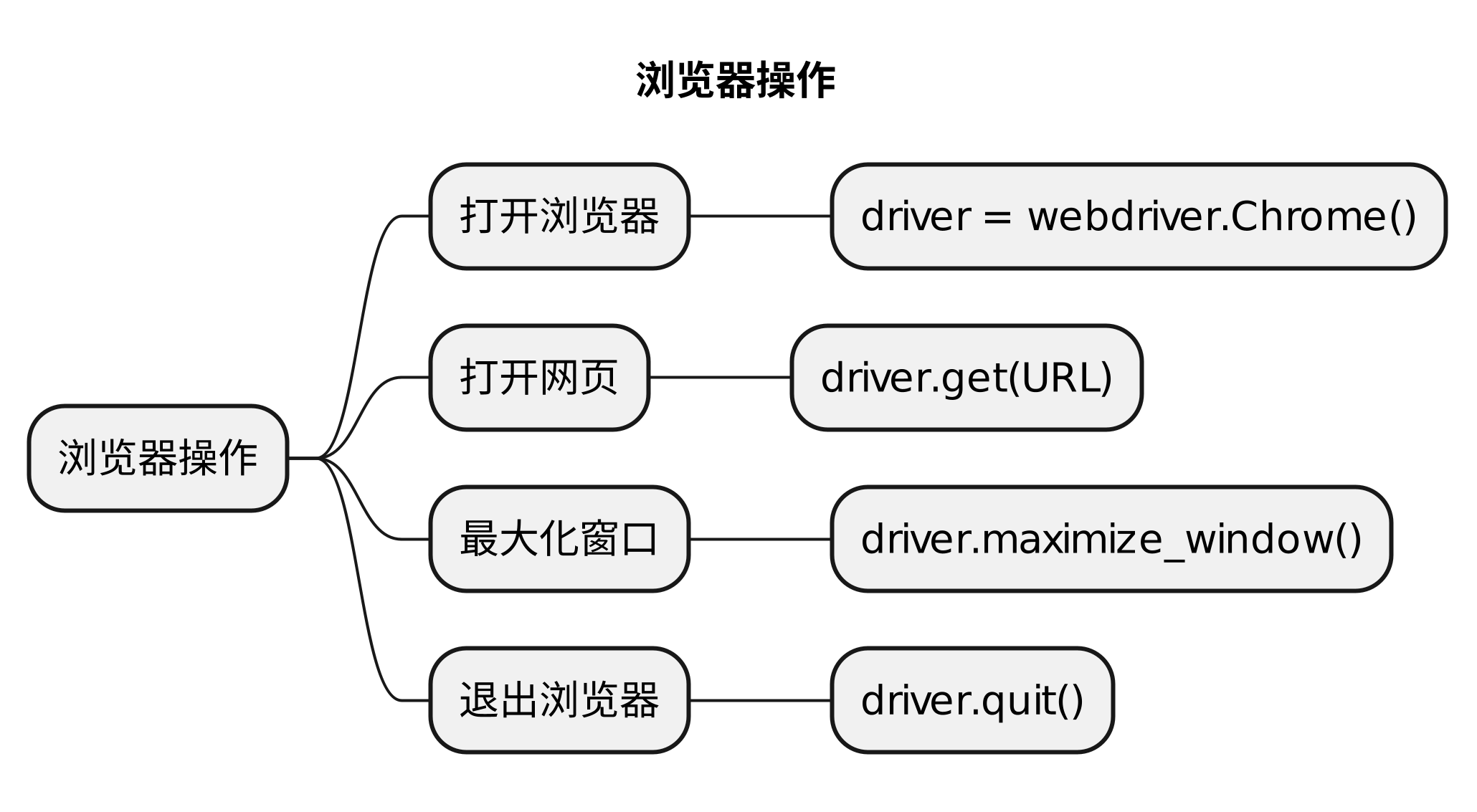
# 打开浏览器
def open_browers():
driver = webdriver.Chrome()
driver.get("https://ceshiren.com/t/topic/24679")
time.sleep(2)
# 刷新浏览器
driver.refresh()
# 通过get跳转到baidu
driver.get("https://www.baidu.com/")
# 退回操作:返回百度之前的页面
driver.back()
# 最大化
driver.maximize_window()
# 最小化
driver.minimize_window()
#关闭窗口
driver.quit()
if __name__ == '__main__':
open_browers()
二、常见控件定位方法
2.1 HTML铺垫
- 标签:
<a> - 属性:href
- 类属性: class
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>测试人论坛</title>
</head>
<body>
<a href="https://ceshiren.com/" class="link">链接</a>
</body>
</html>
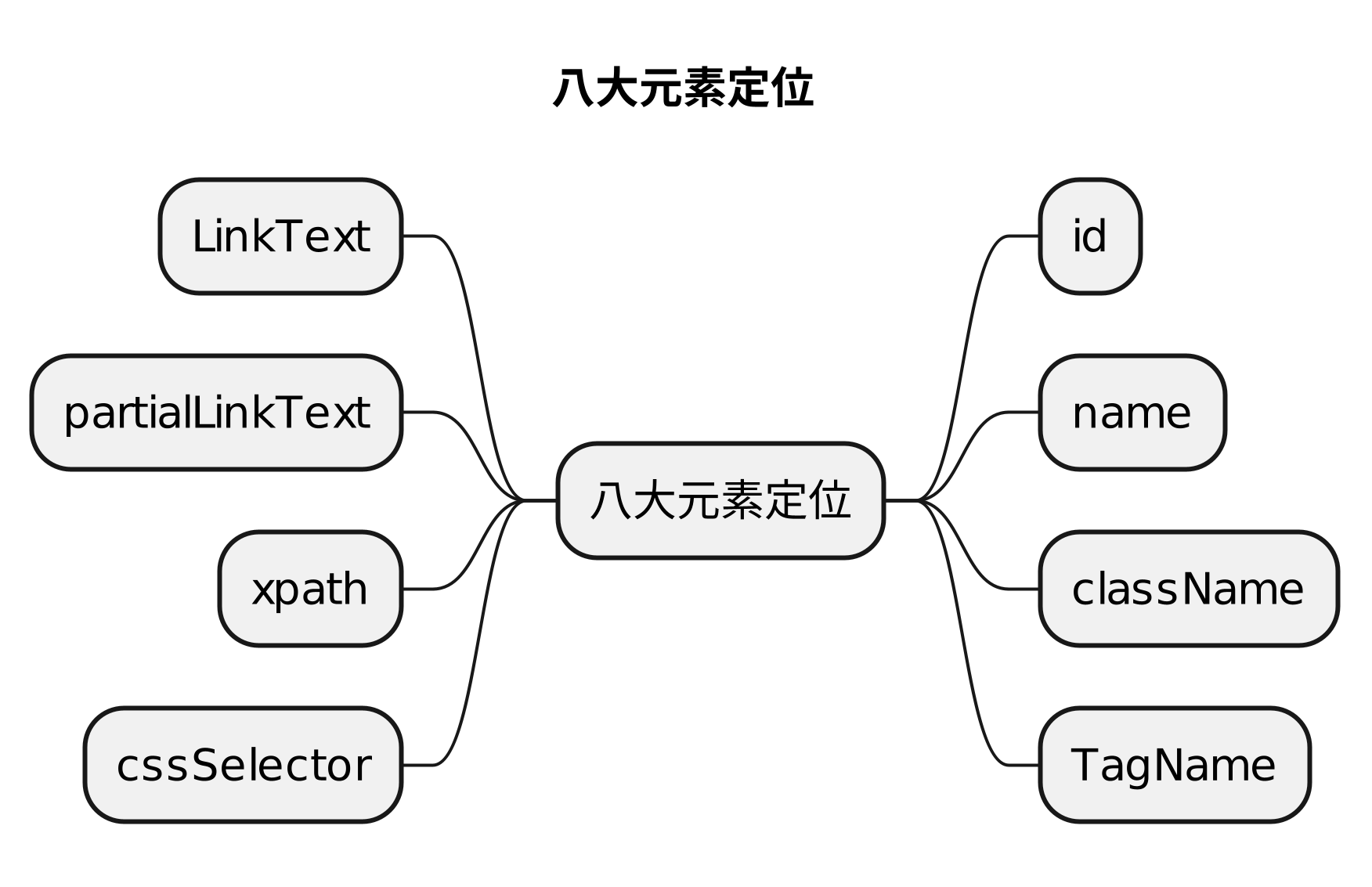
2.2 Selenium八大定位方式
参考教程:Locator strategies | Selenium
- Selenium常用定位方式:
- 格式:
driver.find_element_by_定位方式(定位元素)driver.find_element(By.定位方式, 定位元素)
- 两种方式作用一模一样,官方建议使用第二种方式。
- 格式:
| 方式 | 描述 |
|---|---|
| class name | class 属性对应的值 |
| css selector(重点) | css 表达式 |
| id(重点) | id 属性对应的值 |
| name(重点) | name 属性对应的值 |
| link text | 查找其可见文本与搜索值匹配的锚元素 |
| partial link text | 查找其可见文本包含搜索值的锚元素。如果多个元素匹配,则只会选择第一个元素。 |
| tag name | 标签名称 |
| xpath(重点) | xpath表达式 |
2.2.1 通过ID定位
- 格式:
driver.find_element(By.ID, “ID属性对应的值”)
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
def position_method():
# 实例化chromedriver
driver = webdriver.Chrome()
# 打开网站
driver.get("http://www.ceshiren.com")
# 等待一秒
time.sleep(1)
# 点击”测试内推“,通过ID定位
driver.find_element(By.ID, "ember27").click()
# 等待一秒
time.sleep(1)
if __name__ == '__main__':
position_method()
2.2.2 通过NAME定位
- 格式:
driver.find_element(By.NAME, "NAME属性对应的值")
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
def position_method():
# 实例化chromedriver
driver = webdriver.Chrome()
# 打开网站
driver.get("http://www.baidu.com")
# 等待一秒
time.sleep(1)
# 点击”更多“,通过NAME定位
driver.find_element(By.NAME, "tj_briicon").click()
# 等待一秒
time.sleep(1)
if __name__ == '__main__':
position_method()
2.2.3 通过CSS_SELECTOR定位
- 格式:
driver.find_element(By.CSS_SELECTOR, "css表达式") - 复制绝对定位:
- 编写表达式。
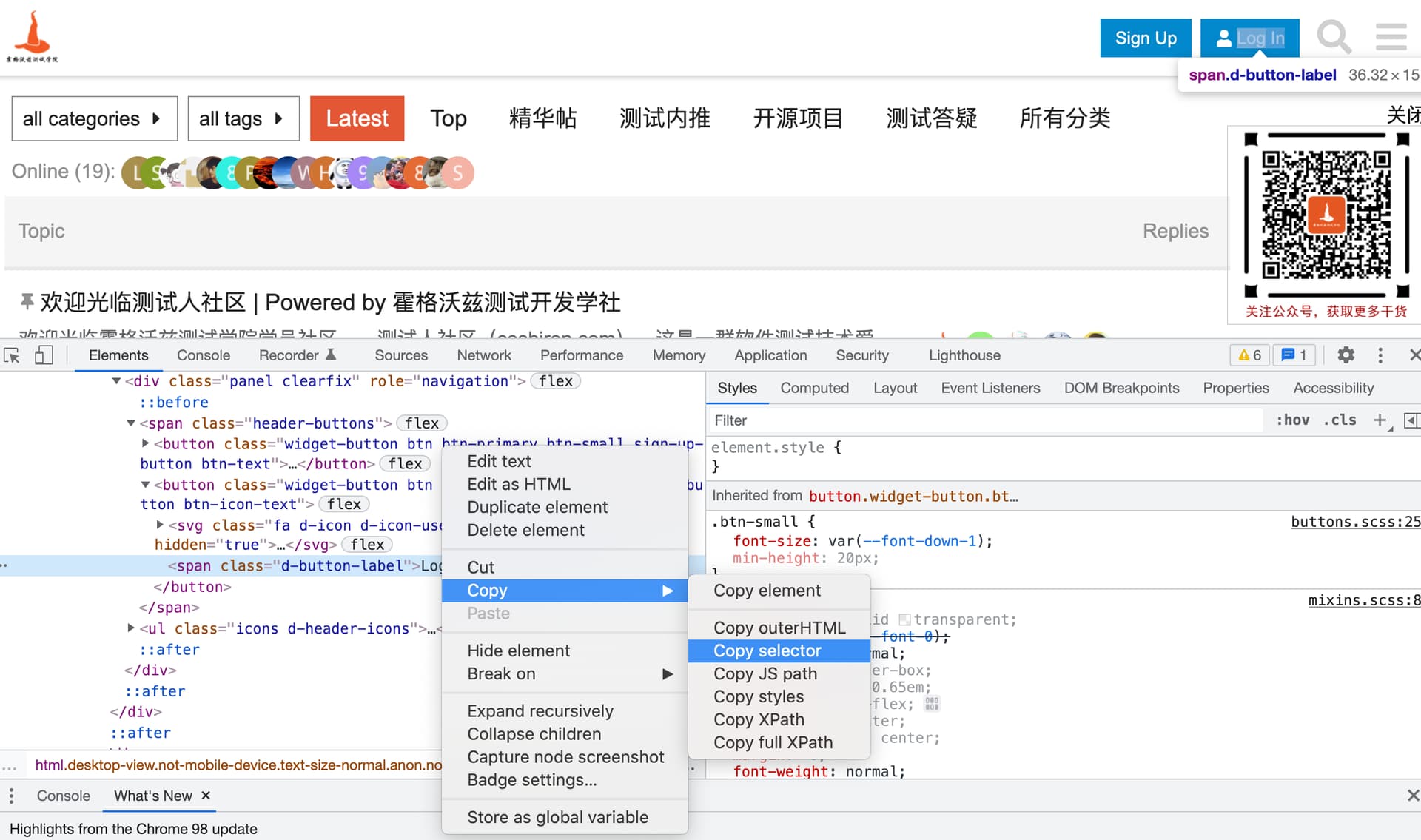
2.2.4 通过XPATH定位
- 格式:
driver.find_element(By.XPATH, "xpath表达式") - 复制绝对定位;
- 编写 xpath 表达式。
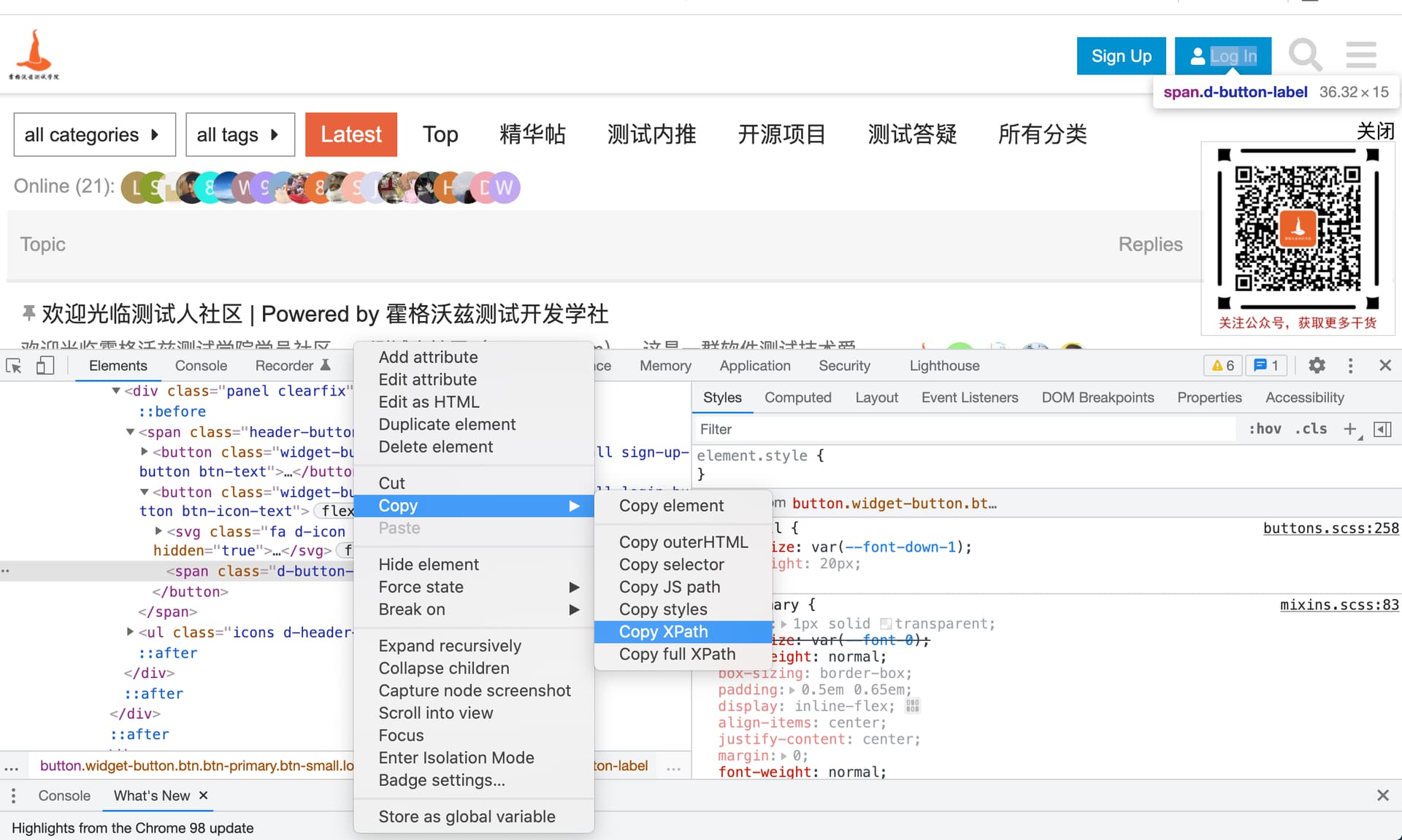
2.2.5 通过LINK定位
- 格式:
driver.find_element(By.LINK_TEXT,"文本信息")
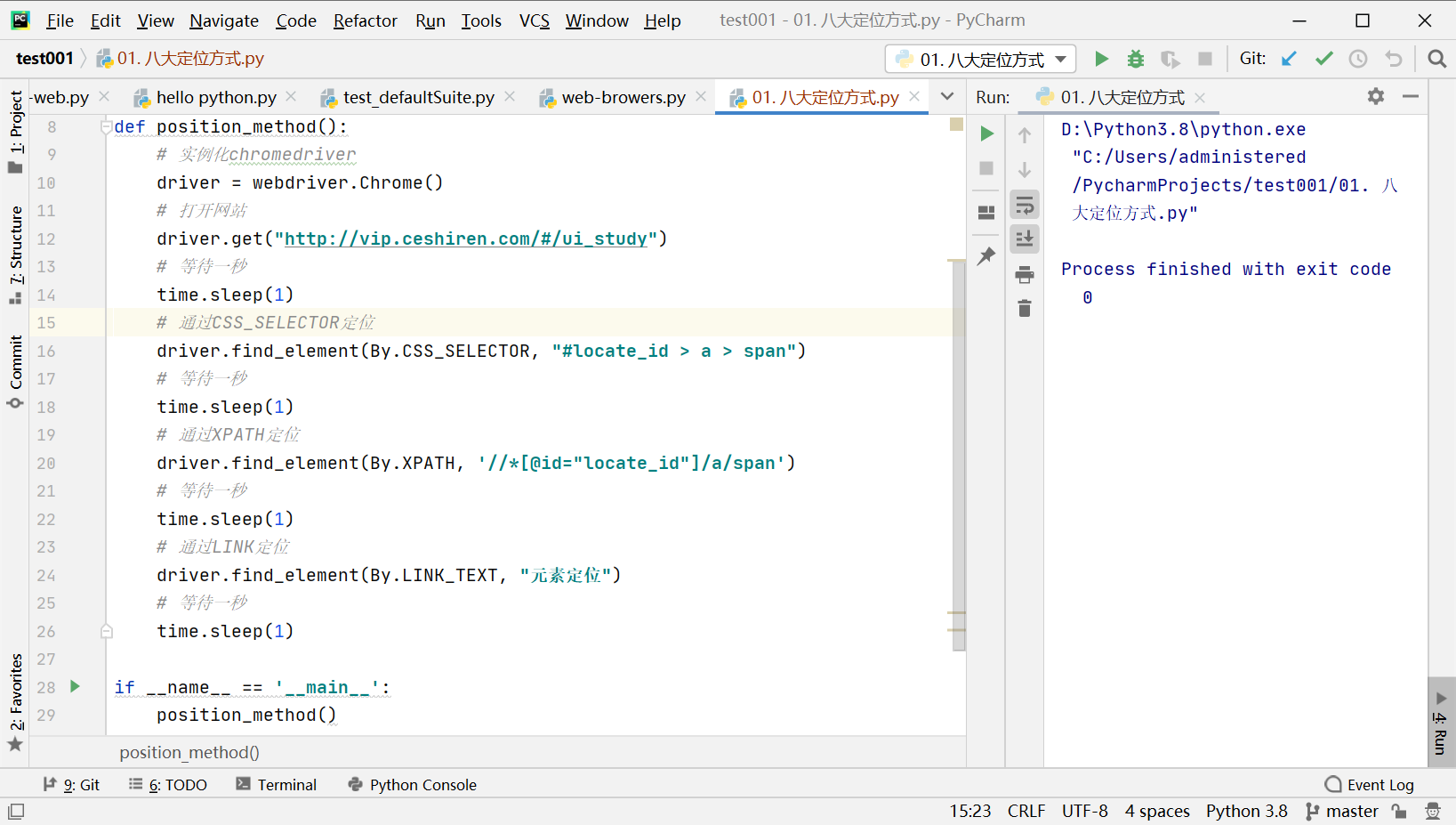
综合练习:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
def position_method():
# 实例化chromedriver
driver = webdriver.Chrome()
# 打开网站
driver.get("http://vip.ceshiren.com/#/ui_study")
# 等待一秒
time.sleep(1)
# 通过CSS_SELECTOR定位
driver.find_element(By.CSS_SELECTOR, "#locate_id > a > span")
# 等待一秒
time.sleep(1)
# 通过XPATH定位
driver.find_element(By.XPATH, '//*[@id="locate_id"]/a/span')
# 等待一秒
time.sleep(1)
# 通过LINK定位
driver.find_element(By.LINK_TEXT, "元素定位")
# 等待一秒
time.sleep(1)
if __name__ == '__main__':
position_method()
三、强制等待与隐式等待
3.1.1 强制(直接)等待
-
问题:页面渲染完成之前操作,导致报错。
-
解决方案:在报错的元素操作之前添加等待。如果没有报错,证明就是页面渲染速度导致的问题;如果依然报错,就可能是别的问题,比如定位错误等。
-
适用场景:调试代码,临时性添加。
-
原理:强制等待,线程休眠一定时间。
-
格式:
time.sleep(等待时间)
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
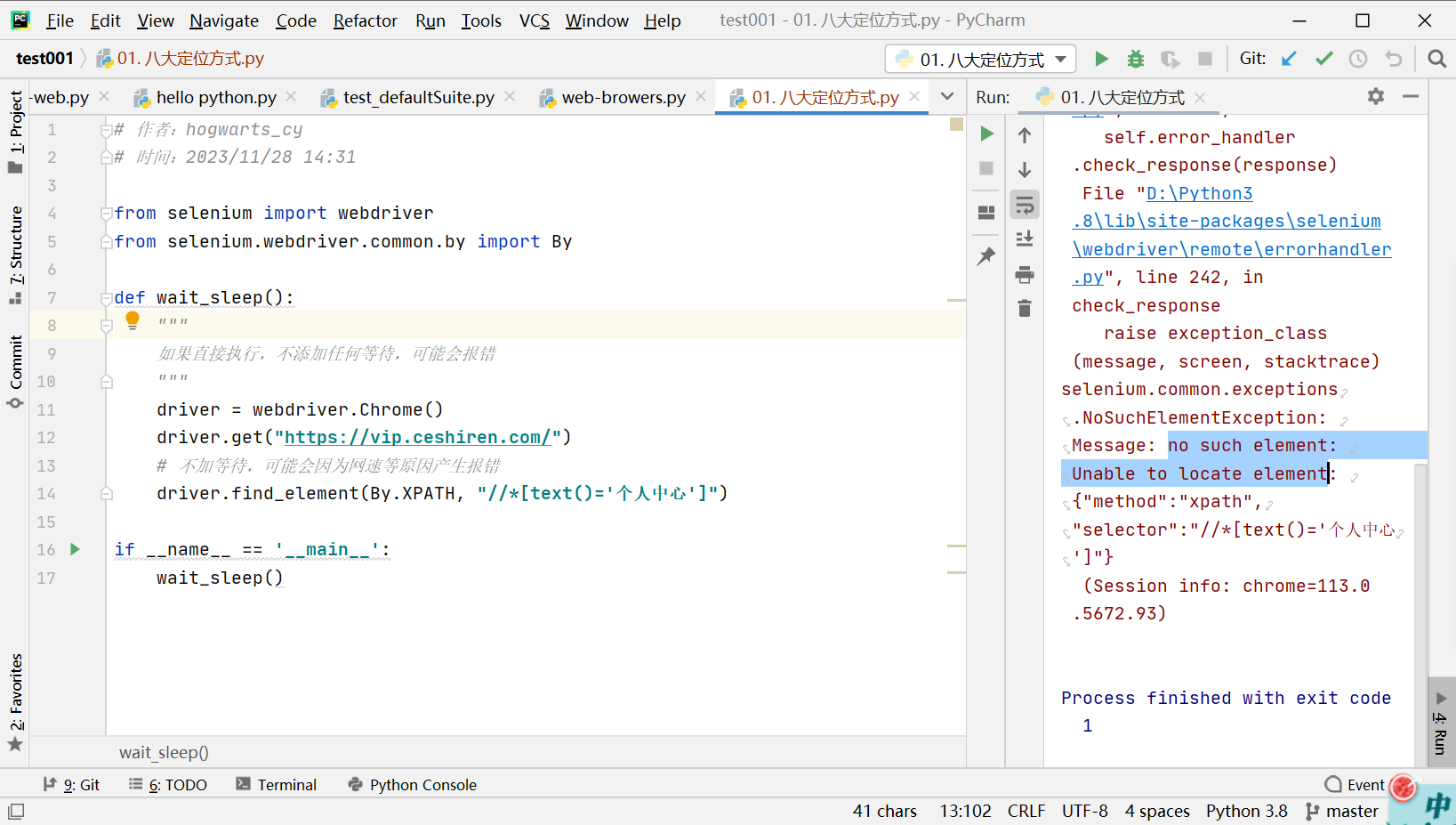
def wait_sleep():
"""
如果直接执行,不添加任何等待,可能会报错
"""
driver = webdriver.Chrome()
driver.get("https://vip.ceshiren.com/#/ui_study/frame")
# 不加等待,可能会因为网速等原因产生报错
driver.find_element(By.XPATH, '//*[@id="locate"]/span')
# 强制等待2秒
time.sleep(2)
if __name__ == '__main__':
wait_sleep()
强制等待的问题:
- 不确定页面的加载时间,可能会因为等待时间过长,而影响用例的执行效率;
- 不确定页面的加载时间,可能会因为等待时间过短,导致代码依然会报错。
3.1.2 隐式等待
-
问题:难以确定元素加载的具体等待时间。
-
解决方案:针对于寻找元素的这个动作,使用隐式等待添加配置。
-
适用场景:解决找不到元素的问题,无法解决交互问题。
-
原理:设置一个等待时间,轮询查找(默认0.5秒)元素是否出现,如果没出现就抛出异常。
-
格式:
driver.implicitly_wait(等待时间)
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
def wait_sleep():
"""
如果直接执行,不添加任何等待,可能会报错
"""
driver = webdriver.Chrome()
driver.get("https://vip.ceshiren.com/#/ui_study/")
driver.implicitly_wait(1)
driver.find_element(By.XPATH, '//*[@id="locate"]/span')
if __name__ == '__main__':
wait_sleep()
隐式等待的注意事项:
- 在代码一开始运行时就添加隐式等待的配置。因为隐式等待是全局生效,所以在所有的find_element动作之前就要执行此代码;
- 隐式等待只能解决元素查找的问题,不能解决元素交互的问题。
隐式等待无法解决的问题:
- 元素可以找到,使用点击等操作,出现报错。
- 原因:
- 页面元素加载是异步加载过程,通常html会先加载完成,js、css其后;
- 元素存在与否是由HTML决定,元素的交互是由css或者js决定;
- 隐式等待只关注元素能不能找到,不关注元素能否点击或者进行其他的交互;
- 解决方案:使用显式等待。
3.1.3 显示等待
- 原理:在最长等待时间内,轮询,是否满足结束条件。
- 适用场景:解决特定条件下的等待问题,比如点击等交互行为。
- 格式:
WebDriverWait(driver实例, 最长等待时间, 轮询时间).until(结束条件)- until需要结合expected_conditions或者自己封装的方法进行使用;
- expected_conditions的参数传入的都是一个元组,即多一层小括号。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
import time
def wait_sleep():
"""
如果直接执行,不添加任何等待,可能会报错
"""
driver = webdriver.Chrome()
driver.get("https://vip.ceshiren.com/#/ui_study/")
WebDriverWait(driver, 10).until(expected_conditions.element_to_be_clickable((By.ID, "success_btn")))
driver.find_element(By.ID, 'success_btn').click()
time.sleep(2)
if __name__ == '__main__':
wait_sleep()
四、常见控件交互方法
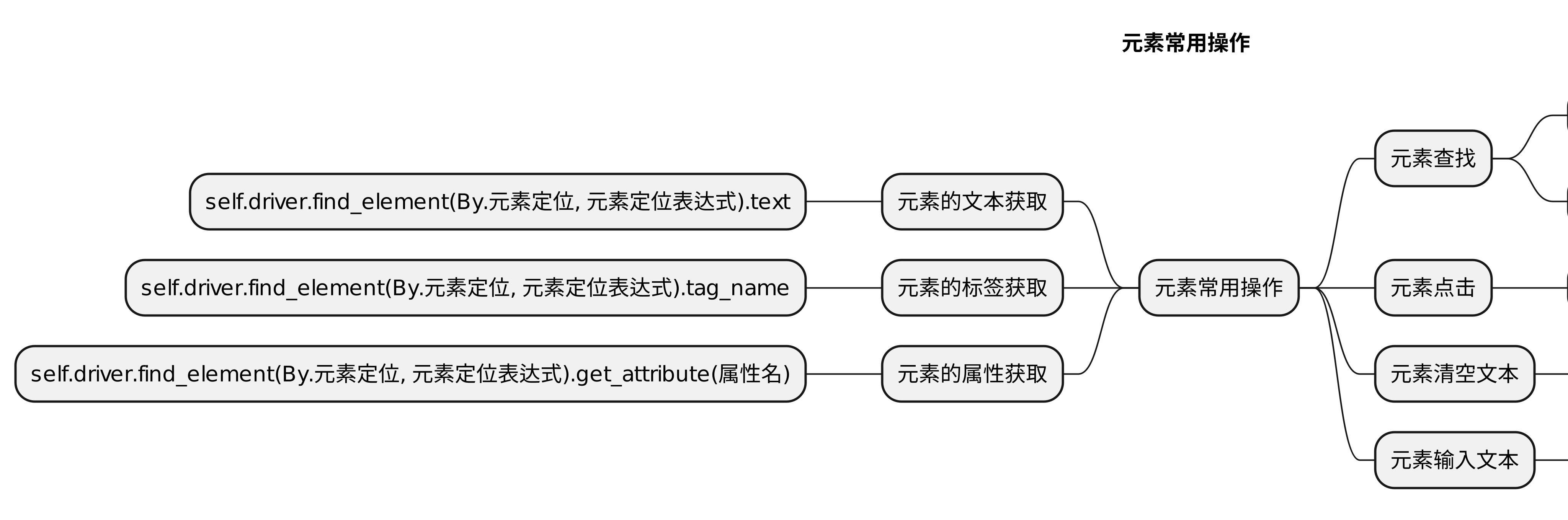
4.1 元素操作
- 点击、输入、清空。
- 点击百度搜索框;
- 输入”霍格沃兹测试开发”;
- 清空搜索框中信息。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
def element_interaction():
"""
元素的操作:点击、输入、清空
"""
# 1. 实例化driver方法
driver = webdriver.Chrome()
# 2. 打开一个网页
driver.get("https://www.sogou.com/")
# 3. 定位到输入框,进行输入操作
driver.find_element(By.ID, "query").send_keys("霍格沃兹测试开发")
# 强制等待
time.sleep(2)
# 4. 对输入框进行清空
driver.find_element(By.ID, "query").clear()
# 强制等待
time.sleep(2)
# 5. 再次输入
driver.find_element(By.ID, "query").send_keys("霍格沃兹测试开发啊")
# 强制等待
time.sleep(2)
# 6. 点击搜索
driver.find_element(By.ID, "stb").click()
if __name__ == '__main__':
element_interaction()
4.2 获取元素属性信息
- 原因:
- 定位到元素后,获取元素的文本信息,属性信息等。
- 目的:
- 根据这些信息进行断言或者调试。
- 方式:
- 获取元素文本;
- 获取元素的属性(html的属性值)。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
def element_get_attr():
# 1. 实例化driver
driver = webdriver.Chrome()
# 2. 打开网页
driver.get("https://vip.ceshiren.com/#/ui_study/")
# 3. 定位一个元素
web_element = driver.find_element(By.ID, "locate_id")
# 4. 打印这个元素对象
# 断点打在想看的对象的下一行
print(web_element)
# 5. 获取元素的文本信息
# 注意:不是每个元素都含有文本信息的
print(web_element.text)
# 6. 获取元素的属性信息
res = web_element.get_attribute("name")
print(res)
if __name__ == '__main__':
element_get_attr()
五、自动化测试定位策略
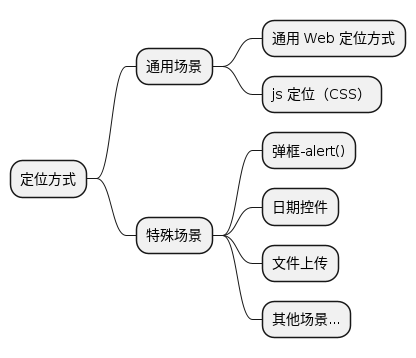
5.1 通用Web定位方式
| 定位策略 | 描述 |
|---|---|
| class name | 通过 class 属性定位元素 |
| css selector | 通过匹配 css selector 定位元素 |
| id | 通过 id 属性匹配元素 |
| name | 通过 name 属性定位元素 |
| link text | 通过 text 标签中间的 text 文本定位元素 |
| partial link text | 通过 text 标签中间的 text 文本的部分内容定位元素 |
| tag name | 通过 tag 名称定位元素 |
| xpath | 通过 xpath 表达式匹配元素 |
5.2 选择定位器通用原则
- 与研发约定的属性优先(class属性:[name=‘locate’]);
- 身份属性ID、NAME(web定位);
- 复杂场景使用组合定位;
①XPATH,CSS;
②属性动态变化(ID、TEXT);
③重复元素属性(ID、TEXT、CLASS);
④父子定位; - JS定位。
5.3 Web弹框定位
- 场景
- web 页面 alert 弹框;
- 解决:
- web 需要使用
driver.switchTo().alert()处理。
- web 需要使用
5.4 下拉框/日期控件定位
- 场景:
-
<input>标签组合的下拉框无法定位; -
<input>标签组合的日期控件无法定位;
-
- 解决:
- 面对这些元素,我们可以引入 JS 注入技术来解决问题。
5.5 文件上传定位
- 场景:
- input 标签文件上传;
- 解决:
- input 标签直接使用 send_keys()方法。
