一、SeleniumIDE用例录制
1、SeleniumIDE的下载以及安装
①官网:https://www.selenium.dev/
②Chrome插件:
https://chrome.google.com/webstore/detail/selenium-ide/mooikfkahbdckldjjndioackbalphokd
③Firefox插件:
https://addons.mozilla.org/en-US/firefox/addon/selenium-ide/
④github release:
https://github.com/SeleniumHQ/selenium-ide/releases
⑤其它版本:
https://addons.mozilla.org/en-GB/firefox/addon/selenium-ide/versions/
⑥注意:Chrome插件在国内无法下载,Firefox可以直接下载。
2、启动
1)安装完成后,通过在浏览器的菜单栏中点击它的图标来启动它:
2)如果没看到图标,首先确保是否安装了Selenium IDE扩展插件
3)通过以下链接访问所有插件
Chrome: chrome://extensions
Firefox: about:addons
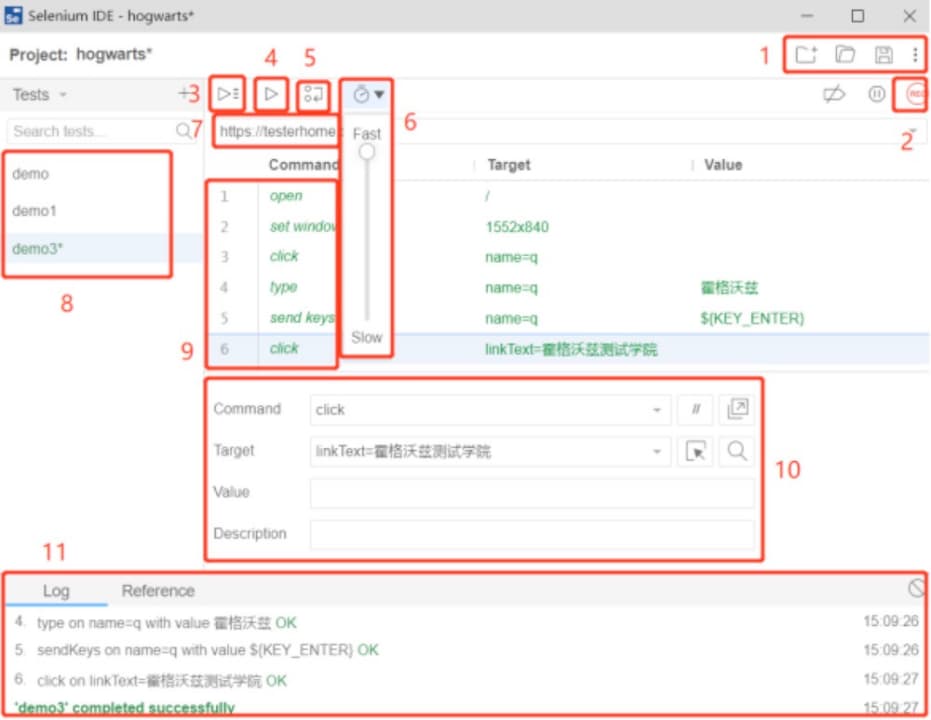
3、SeleniumIDE常用功能
1)新建、保存、打开
2)开始和停止录制
3)运行8中的所有的实例
4)运行单个实例
5)调试模式
6)调整案例的运行速度
7)要录制的网址
8)实例列表
9)动作、目标、值
10)对单条命令的解释
11)运行日志
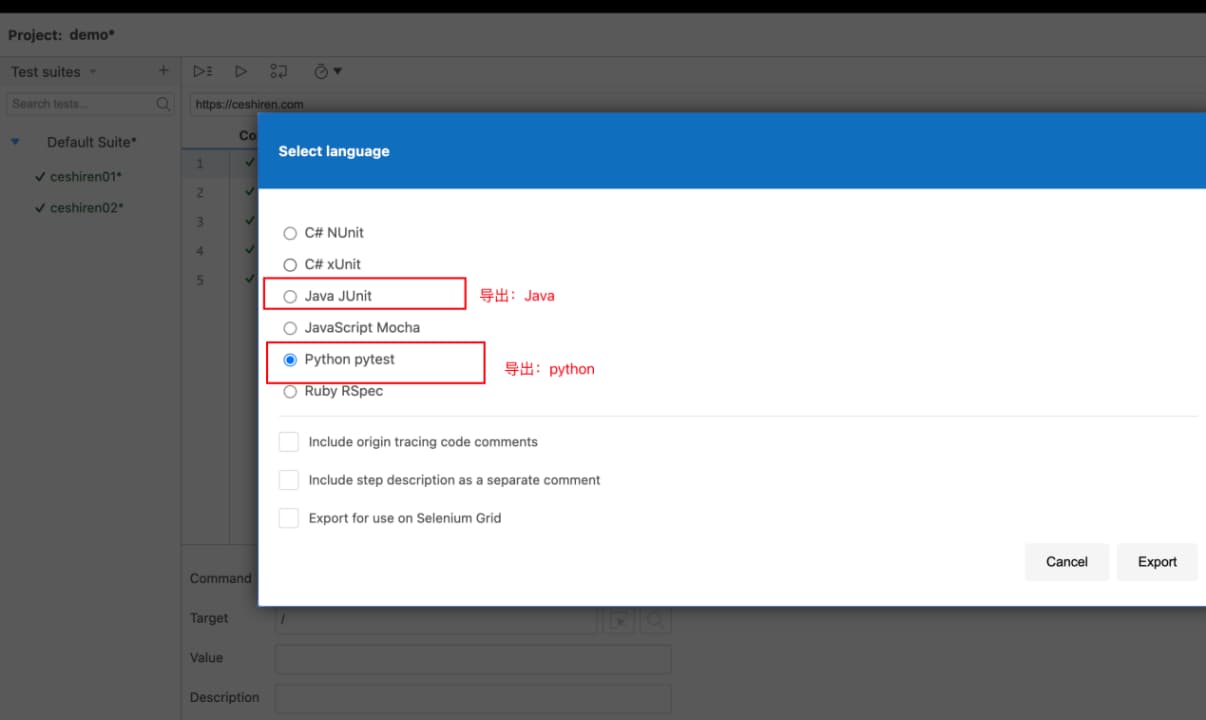
4、SeleniumIDE脚本导出:Java和Python
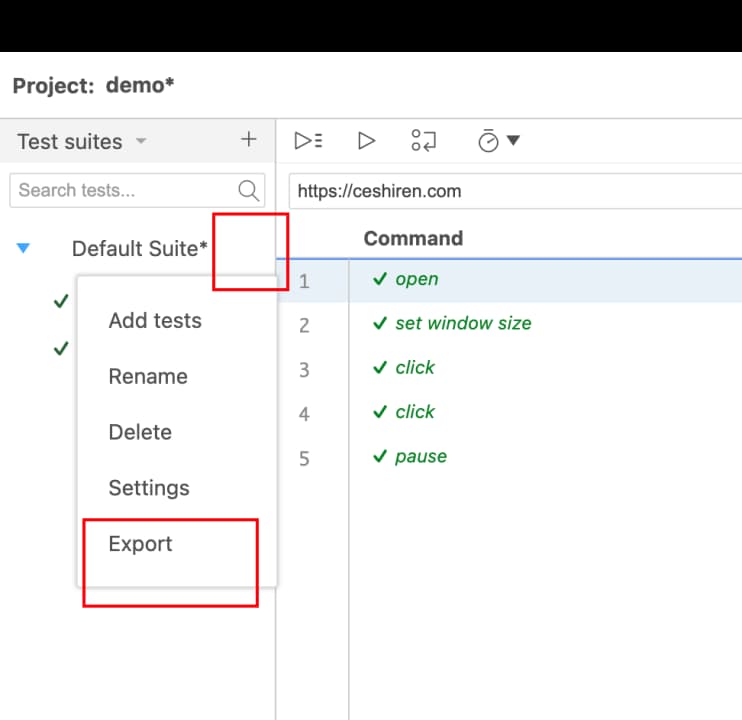
二、自动化测试用例结构分析
1、标准的用例结构(功能)
①用例标题
②前提条件
③用例步骤
④预期结果
⑤实际结果
2、自动化用例结构及作用
【结构:自动化测试用例:作用】
①用例标题:测试包、文件、类、方法名称:【用例的唯一标识】
②前提条件:setup、setup_class(Pytest;BeforeEach、BeforeAll(JUnit):【测试用例前的准备动作,比如读取数据或者driver的初始化】
③用例步骤:测试方法内的代码逻辑:【测试用例具体的步骤行为】
④预期结果:assert 实际结果 = 预期结果:【断言,印证用例是否执行成功】
⑤实际结果:assert 实际结果 = 预期结果:【断言,印证用例是否执行成功】
⑥后置动作:teardown、teardown_class(Pytest);@AfterEach、@AfterAll(JUnit):【脏数据清理、关闭driver进程】
3、IDE录制脚本
1)脚本步骤:
①访问百度网站
②搜索框输入“霍格沃兹测试开发”
③点击搜索按钮
# Generated by Selenium IDE
import pytest
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
class Test():
def setup_method(self, method):
self.driver = webdriver.Chrome()
self.vars = {}
def teardown_method(self, method):
self.driver.quit()
def test_sougou(self):
# 打开网页,设置窗口
self.driver.get("https://www.sogou.com/")
self.driver.set_window_size(1235, 693)
# 输入搜索信息
self.driver.find_element(By.ID, "query").click()
self.driver.find_element(By.ID, "query").send_keys("霍格沃兹测试开发")
# 点击搜索
self.driver.find_element(By.ID, "stb").click()
element = self.driver.find_element(By.ID, "stb")
actions = ActionChains(self.driver)
actions.move_to_element(element).perform()
#优化后的代码,添加断言判断用例是否成功
# Generated by Selenium IDE
import pytest
import time
import json
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
class Test(object):
# 前提条件,webdriver的初始化
def setup_method(self, method):
self.driver = webdriver.Chrome()
self.vars = {}
# 后置操作,关闭网站
def teardown_method(self, method):
self.driver.quit()
# 测试用例步骤
def test_sougou(self):
# 打开网页,设置窗口
self.driver.get("https://www.sogou.com/")
self.driver.set_window_size(1235, 693)
# 输入搜索信息
self.driver.find_element(By.ID, "query").click()
self.driver.find_element(By.ID, "query").send_keys("霍格沃兹测试开发")
# 点击搜索
self.driver.find_element(By.ID, "stb").click()
element = self.driver.find_element(By.ID, "stb")
actions = ActionChains(self.driver)
actions.move_to_element(element).perform()
# 问题:无法确定用例执行成功或失败
# 解决方案:添加断言信息,判断搜索列表中,是否会有"霍格沃兹测试开发"
res_element = self.driver.find_element(By.CSS_SELECTOR, "#sogou_vr_30000000_0 > em")
# 获取到定位的文本信息
# 判断实际获取到的搜索展示的列表和预期是否一致
assert res_element.text == "霍格沃兹测试开发"
三、web 浏览器控制
|
操作 |
使用场景 |
| get |
打开浏览器 |
web自动化测试第一步 |
| refresh |
浏览器刷新 |
模拟浏览器刷新 |
| back |
浏览器退回 |
模拟退回步骤 |
| maximize_window |
最大化浏览器 |
模拟浏览器最大化 |
| minimize_window |
最小化浏览器 |
模拟浏览器最小化 |
import time
from selenium import webdriver
# 打开网页
def open_browser():
# 实例化chromedriver
driver = webdriver.Chrome()
# 调用get方法时需要传递浏览器的URL
driver.get("https://ceshiren.com/")
# 添加等待1秒
time.sleep(2)
# # 刷新浏览器
# driver.refresh()
# # 通过get跳转到百度
# driver.get("https://www.baidu.com/")
# # 回退操作,退回到测试人网页
# driver.back()
# 最大化浏览器
driver.maximize_window()
time.sleep(2)
# 最小化浏览器
driver.minimize_window()
time.sleep(2)
if __name__ == '__main__':
open_browser()
四、常见控件定位方法
1、HTML铺垫
①标签:尖括号,如括起来的<a>、<html>、<title>等
②属性:a=b,如href
③类属性: class
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>测试人论坛</title>
</head>
<body>
<a href="https://ceshiren.com/" class="link">链接</a>
</body>
</html>
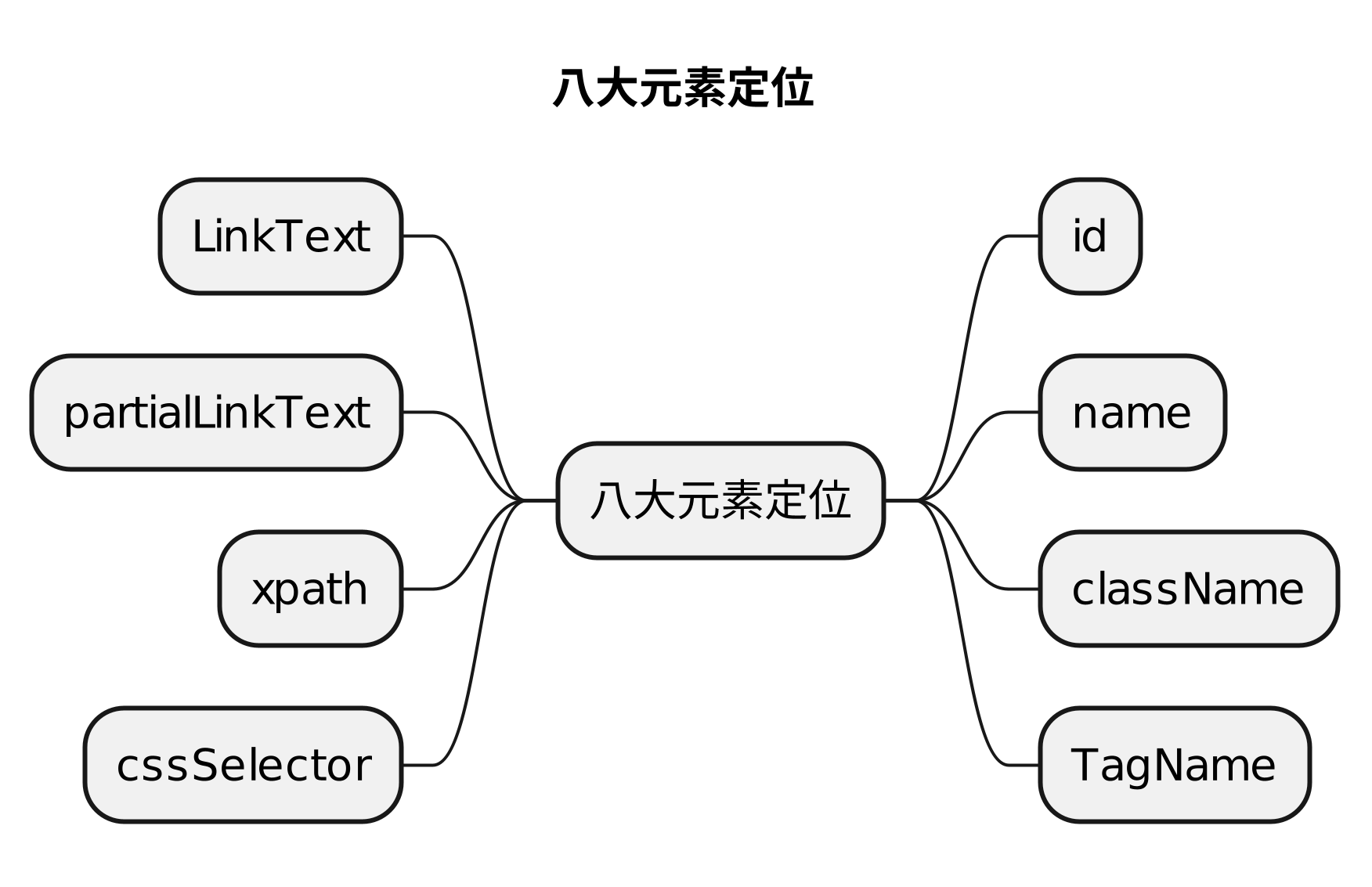
2、Selenium八大定位方式
1)selenium 常用定位方式
#格式:
driver.find_element_by_定位方式(定位元素)
driver.find_element(By.定位方式, 定位元素)
# 示例,两种方式作用一模一样
# 官方建议使用下面的方式
driver.find_element_by_id("su")
driver.find_element(By.ID, "su")
| 方式 |
描述 |
| class name |
class 属性对应的值 |
| css selector(重点) |
css 表达式 |
| id(重点) |
id 属性对应的值 |
| name(重点) |
name 属性对应的值 |
| link text |
查找其可见文本与搜索值匹配的锚元素 |
| partial link text |
查找其可见文本包含搜索值的锚元素。如果多个元素匹配,则只会选择第一个元素。 |
| tag name |
标签名称 |
| xpath(重点) |
xpath表达式 |
2)【方式:描述】
①class name:class 属性对应的值
②css selector(重点):css 表达式
a.格式: driver.find_element(By.CSS_SELECTOR, "css表达式")
b.复制绝对定位
c.编写 css selector 表达式
③id(重点):id 属性对应的值
格式: driver.find_element(By.ID, "ID属性对应的值")
④name(重点):name 属性对应的值
格式: driver.find_element(By.NAME, "Name属性对应的值")
⑤link text:查找其可见文本与搜索值匹配的锚元素
格式:driver.find_element(By.LINK_TEXT,"文本信息")
⑥partial link text:查找其可见文本包含搜索值的锚元素。如果多个元素匹配,则只会选择第一个元素。
⑦tag name:标签名称
⑧xpath(重点):xpath表达式
a.格式: driver.find_element(By.XPATH, "xpath表达式")
b.复制绝对定位
c.编写 xpath 表达式
from selenium import webdriver
from selenium.webdriver.common.by import By
def web_locate():
# 首先需要实例化driver对象,Chrome一定要加括号
driver = webdriver.Chrome()
# 打开一个网页
driver.get("https://vip.ceshiren.com/#/ui_study/frame")
# 1.ID定位,第一个参数传递定位方式,第二个参数传递定位元素,调用这个方法的返回值为WebElement
web_element = driver.find_element(By.ID, "locate_id")
print(web_element)
# 2.NAME定位,如果没有报错,证明元素找到了
# 如果报错no such element,代表元素定位可能出现错误
# driver.find_element(By.NAME, "locate123") # 错误示例
driver.find_element(By.NAME, "locate")
# 3.CSS选择器定位
driver.find_element(By.CSS_SELECTOR, "#locate_id > a > span")
# 4.xpath表达式定位
driver.find_element(By.XPATH, '//*[@id="locate_id"]/a/span') # 表达式里有双引号,建议用单引号
# 5.Link text,通过链接文本的方式,(1)元素一定是a标签;(2)输入的元素为标签内的文本
driver.find_element(By.LINK_TEXT, "元素定位") # 通常会带一个点击的操作,在最后面添加.click(),可加可不加
if __name__ == '__main__':
web_locate()
五、强制等待与隐式等待
1、为什么要添加等待
避免页面未渲染完成后操作,导致的报错
from selenium import webdriver
from selenium.webdriver.common.by import By
def wait_sleep():
"""
如果直接执行,不添加任何等待,可能会报错
"""
driver = webdriver.Chrome()
driver.get("https://vip.ceshiren.com/")
# 不加等待,可能会因为网速等原因产生报错
# 报错:no such element: Unable to locate element
# 原因:页面未加载完成,就去查找元素,此时这个元素还未加载出来
driver.find_element(By.XPATH, "//*[text()='个人中心']")
if __name__ == '__main__':
wait_sleep()
2、强制(直接)等待
(1)解决方案:在报错的元素操作之前添加等待
(2)原理:强制等待,线程休眠一定时间。time.sleep(3)
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
def wait_sleep():
"""
如果直接执行,不添加任何等待,可能会报错
"""
driver = webdriver.Chrome()
driver.get("https://vip.ceshiren.com/")
# 不加等待,可能会因为网速等原因产生报错
# 报错:no such element: Unable to locate element
# 原因:页面未加载完成,就去查找元素,此时这个元素还未加载出来
# 1.强制等待,让页面渲染完成,在报错的元素操作之前添加等待,没有报错,就证明是页面渲染速度导致,有报错则是其他问题,如定位错误等
time.sleep(3)
driver.find_element(By.XPATH, "//*[text()='个人中心']")
if __name__ == '__main__':
wait_sleep()
3、隐式等待
(1)问题:难以确定元素加载的具体等待时间。
(2)解决方案:针对于寻找元素的这个动作,使用隐式等待添加配置。
(3)原理:设置一个等待时间,轮询查找(默认0.5秒)元素是否出现,如果没出现就抛出异常
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
def wait_sleep():
"""
如果直接执行,不添加任何等待,可能会报错
"""
driver = webdriver.Chrome()
driver.get("https://vip.ceshiren.com/")
# 不加等待,可能会因为网速等原因产生报错
# 报错:no such element: Unable to locate element
# 原因:页面未加载完成,就去查找元素,此时这个元素还未加载出来
# 1.强制等待,让页面渲染完成,在报错的元素操作之前添加等待,没有报错,就证明是页面渲染速度导致,有报错则是其他问题,如定位错误等
# time.sleep(3)
# 强制等待的问题:(1)不确定页面加载时间,可能会因为等待时间过长,而影响用例的执行效率;(2)不确定页面加载时间,可能会因为等待时间过短,而导致代码依然报错
# 2.隐式等待
# 设置一个最长的等待时间,轮询查找(默认0.5秒)元素是否出现,如果没出现就抛出异常
# 注意:(1)在代码一开始运行时就添加隐式等待的配置,隐式等待是全局生效,即在所有find_element动作之前添加该配置即可;(2)隐式等待只能解决元素查找问题,不能解决元素交互问题
driver.implicitly_wait(3)
driver.find_element(By.XPATH, "//*[text()='个人中心']")
# driver.implicitly_wait(5) # 修改隐式等待的配置
driver.find_element(By.XPATH, "//*[text()='题库']")
4、隐式等待无法解决的问题
(1)问题:元素可以找到,使用点击等操作,出现报错
(2)原因:
①页面元素加载是异步加载过程,通常html会先加载完成,js、css其后
②元素存在与否是由HTML决定,元素的交互是由css或者js决定
③隐式等待只关注元素能不能找到,不关注元素能否点击或者进行其他的交互
(3)解决方案:使用显式等待
5、显式等待基本使用(初级)
(1)示例: WebDriverWait(driver实例, 最长等待时间, 轮询时间).until(结束条件)
(2)原理:在最长等待时间内,轮询,是否满足结束条件
注意:在初级时期,先关注使用
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
"""显示等待"""
def wait_show():
driver = webdriver.Chrome()
driver.get("https://vip.ceshiren.com/#/ui_study/frame")
# driver.implicitly_wait(3) # 问题:元素可以找到,但是点击效果没有触发
# 显示等待,第一个参数是driver,第二个参数是最长等待时间,轮询时间可加可不加,util方法内需要结合expected_conditions或者自己封装的方法进行使用
# expected_conditions的参数传入都是一个元组,即多一层小括号
WebDriverWait(driver, 10).until(expected_conditions.element_to_be_clickable((By.ID, "success_btn")))
driver.find_element(By.ID, "success_btn").click() # 添加点击操作.click(),点击"消息提示"
time.sleep(5)
if __name__ == '__main__':
wait_show()
6、总结
(1)直接等待:
1)使用方式:time.sleep(等待时间))
2)原理:强制线程等待
3)适用场景:调试代码,临时性添加
(2)隐式等待:
1)使用方式:driver.implicitly_wait(等待时间)
2)原理:在时间范围内,轮询查找元素
3)适用场景:解决找不到元素问题,无法解决交互问题
(3)显式等待:
1)使用方式:WebDriverWait(driver实例, 最长等待时间, 轮询时间).until(结束条件)
2)原理:设定特定的等待条件,轮询操作
3)适用场景:解决特定条件下的等待问题,比如点击等交互性行为
六、常见控件交互方法
1、元素操作
点击,输入,清空
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
def element_interaction():
"""
元素操作:点击、输入、清空
:return:
"""
# 1.实例化driver对象
driver = webdriver.Chrome()
# 2.打开一个网页
driver.get("https://www.sogou.com/")
# 3.定位到输入框进行输入操作,.send_keys()
driver.find_element(By.ID, "query").send_keys("霍格沃滋测试开发")
# 强制等待2秒
time.sleep(2)
# 4.对输入框进行清空操作.clear()
driver.find_element(By.ID, "query").clear()
time.sleep(2)
# 5.再次输入
driver.find_element(By.ID, "query").send_keys("霍格沃滋测试开发学社")
time.sleep(2)
# 6.点击搜索.click()
driver.find_element(By.ID, "stb").click()
time.sleep(2)
if __name__ == '__main__':
element_interaction()
2、获取元素属性信息
①原因:定位到元素后,获取元素的文本信息,属性信息等
②目的:根据这些信息进行断言或者调试
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 获取元素属性
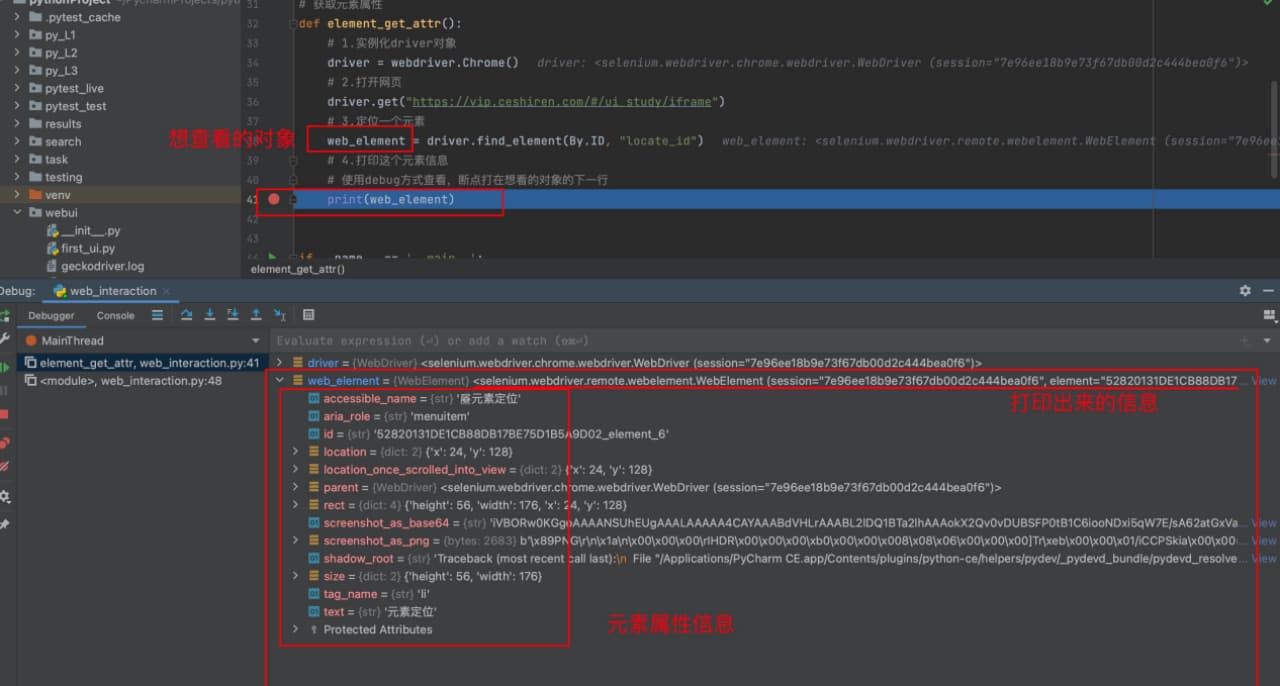
def element_get_attr():
# 1.实例化driver对象
driver = webdriver.Chrome()
# 2.打开网页
driver.get("https://vip.ceshiren.com/#/ui_study/iframe")
# 3.定位一个元素
web_element = driver.find_element(By.ID, "locate_id")
# 4.打印这个元素信息
# 使用debug方式查看,断点打在想看的对象的下一行
# print(web_element)
# 5.获取元素的文本信息,不是每个元素都有文本信息的
print(web_element.text)
# 6.获取元素的属性信息,如 id="locate_id", title="xxx"
res = web_element.get_attribute("class")
print(res)
if __name__ == '__main__':
# 获取元素属性
element_get_attr()
3、获取元素属性信息的方法
①获取元素文本
②获取元素的属性(html的属性值)
# 获取元素文本
driver.find_element(By.ID, "id").text
# 获取这个元素的name属性的值
driver.find_element(By.ID, "id").get_attribute("name")
七、自动化测试定位策略
1、定位方式
2、通用 Web 定位方式
| 定位策略 |
描述 |
| class name |
通过 class 属性定位元素 |
| css selector |
通过匹配 css selector 定位元素 |
| id |
通过 id 属性匹配元素 |
| name |
通过 name 属性定位元素 |
| link text |
通过 text 标签中间的 text 文本定位元素 |
| partial link text |
通过 text 标签中间的 text 文本的部分内容定位元素 |
| tag name |
通过 tag 名称定位元素 |
| xpath |
通过 xpath 表达式匹配元素 |
【定位策略:描述】
①class name:通过 class 属性定位元素
②css selector:通过匹配 css selector 定位元素
③id:通过 id 属性匹配元素
④name:通过 name 属性定位元素
⑤link text:通过 <a>text</a> 标签中间的 text 文本定位元素
⑥partial link text:通过 <a>text</a> 标签中间的 text 文本的部分内容定位元素
⑦tag name:通过 tag 名称定位元素
⑧xpath:通过 xpath 表达式匹配元素
3、选择定位器通用原则
1)与研发约定的属性优先(class属性: [name='locate'])
2)身份属性 id,name(web 定位)
3)复杂场景使用组合定位:
①xpath,css
②属性动态变化(id,text)
③重复元素属性(id,text,class)
④父子定位(子定位父)
4)js定位
4、Web 弹框定位
1)场景:web 页面 alert 弹框
2)解决:web 需要使用 driver.switchTo().alert() 处理
5、下拉框/日期控件定位
1)场景:
<input>标签组合的下拉框无法定位
<input>标签组合的日期控件无法定位
2)解决:面对这些元素,我们可以引入JS注入技术来解决问题。
6、文件上传定位
1)场景:input 标签文件上传
2)解决:input 标签直接使用 send_keys()方法
L1实战–测试人论坛搜索功能自动化测试
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestCeshiren01:
def setup(self):
"""
前提条件:进入测试人论坛的搜索页面
:return:
"""
# 实例化driver对象
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3) # 隐式等待
# 打开被测地址
self.driver.get("https://ceshiren.com/search?expanded=true")
def teardown(self):
# 每一次用例结束之后都会关闭chromedriver进程,也会关闭浏览器
self.driver.quit()
def test_search01(self):
"""
测试步骤:1.输入搜索关键词;2.点击搜索按钮
:return:
"""
# 定位搜索框,并输入搜索内容,如果是动态id,使用css
self.driver.find_element(By.CSS_SELECTOR, "[placeholder=搜索]").send_keys("appium")
# 定位到搜索按钮,并点击搜索
self.driver.find_element(By.CSS_SELECTOR, ".search-cta").click()
# 断言=预期结果与实际结果对比的结果
# 定位实际结果,即为获取搜索结果列表的标题内容
web_element = self.driver.find_element(By.CSS_SELECTOR, ".topic-title")
# 获取文本类的实际结果断言,appium关键字是否在获取的实际结果文本之中
assert "appium" in web_element.text
八、高级定位-css
1、css 选择器概念
①css 选择器有自己的语法规则和表达式
②css 定位通常分为绝对定位和相对定位
③和Xpath一起常用于UI自动化测试中的元素定位
2、css 相对定位使用场景
①支持web产品
②支持app端的webview
3、css 相对定位的优点
①可维护性更强
②语法更加简洁
③解决各种复杂的定位场景
4、css 定位的调试方法
1)进入浏览器的console
2)输入:$("css表达式")或者$$("css表达式"),如果表达式里有双引号,外面要单引号,如果表达式用的是单引号,外面就要用双引号,外双内单,外单内双
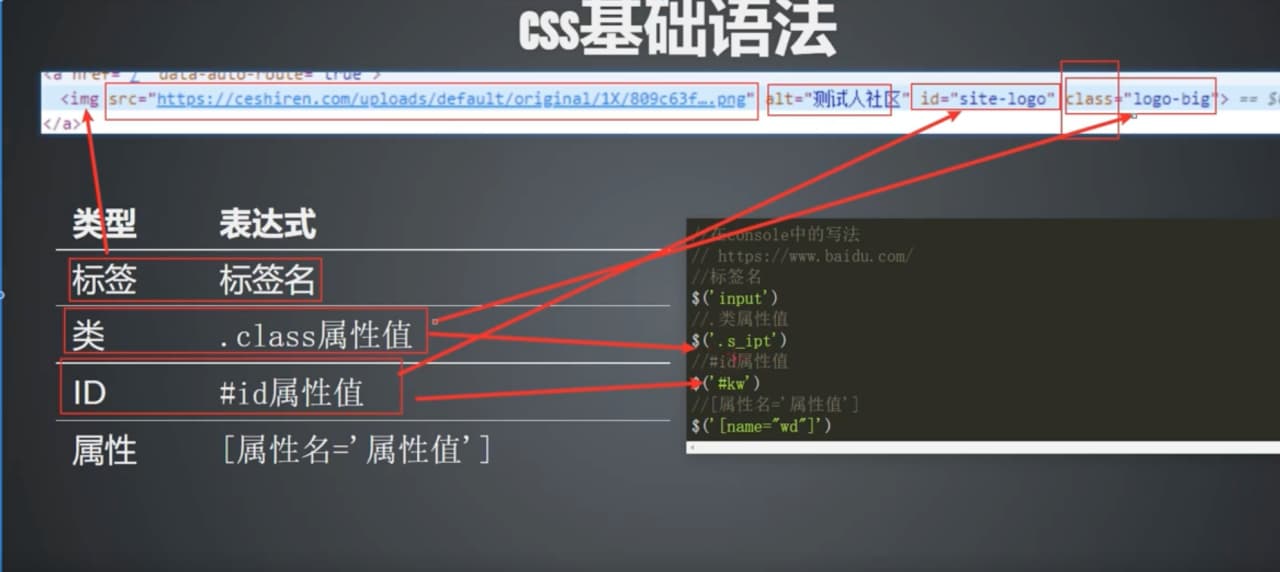
5、css基础语法
| 类型 |
表达式 |
| 标签 |
标签名 |
| 类 |
. (表示class属性值) |
| ID |
# (表示id属性值) |
| 属性 |
[属性名=‘属性值’] |
【类型:表达式】
①标签:标签名
$("div") # 获取所有的div标签
②类:.表示为class属性值,如果类里面有多个值(单词),就不能直接复制,将空格改为.即可
$(".logo-big")等同于$("[class='logo-big']")
③ID:#表示为id属性值
$("#site-logo")等同于$("[id='site-logo']")
④属性:[属性名='属性值']
$("[alt='测试人社区']")
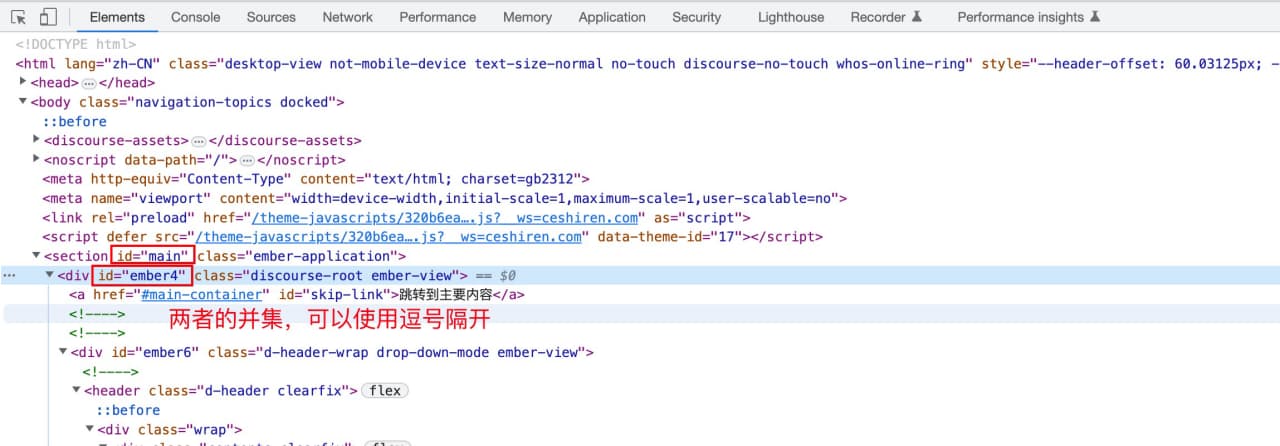
6、css关系定位
| 类型 |
格式 |
| 并集 |
元素,元素 |
| 邻近兄弟(了解即可) |
元素+元素 |
| 兄弟(了解即可) |
元素1~元素2 |
| 父子 |
元素>元素 |
| 后代 |
元素 元素 |
【类型:格式】
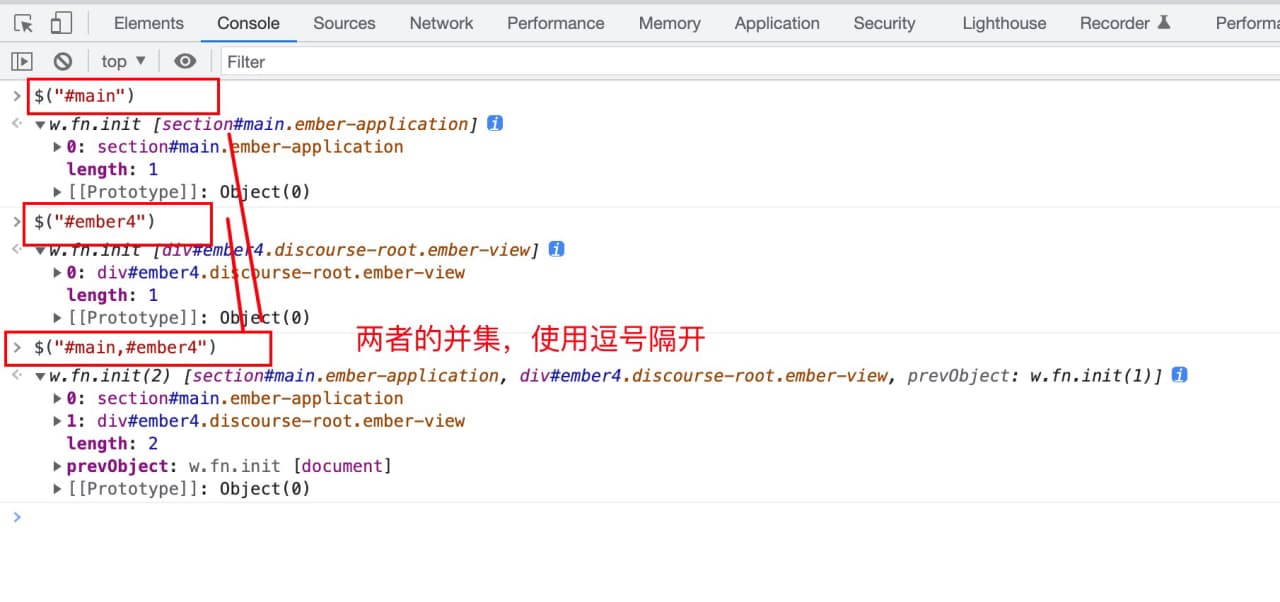
①并集:元素,元素
$("#main,#ember4")
②邻近兄弟(了解即可):元素+元素
$("#ember39+#ember40")
③兄弟(了解即可):元素1~元素2
$("#ember39~#ember41")
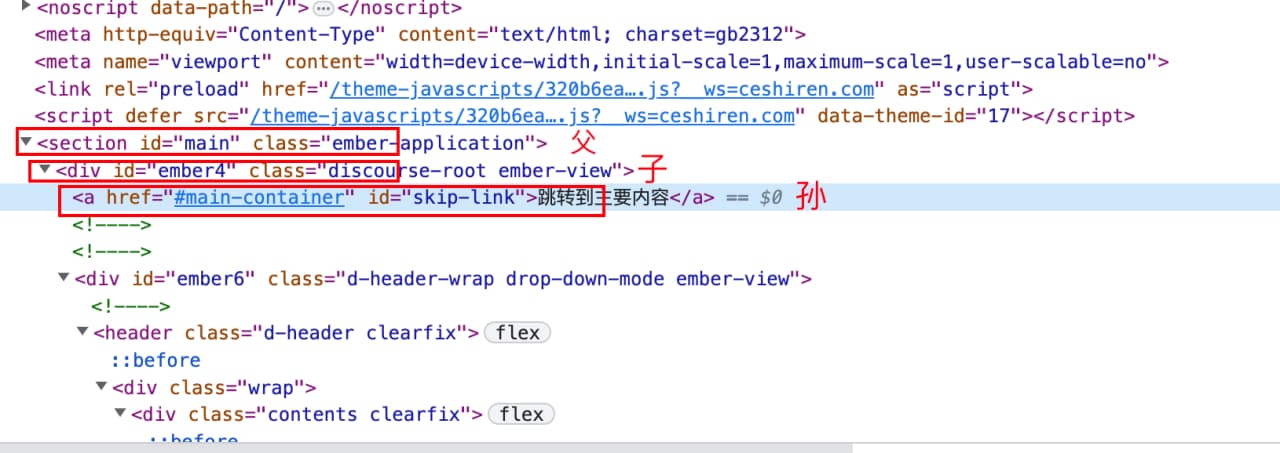
④父子:元素>元素
$("#main>#ember4")
⑤后代:元素 元素
$("#main #skip-link")
7、css 顺序关系
| 类型 |
格式 |
| 父子关系+顺序 |
元素 元素 |
| 父子关系+标签类型+顺序 |
元素 元素 |
【类型:格式】
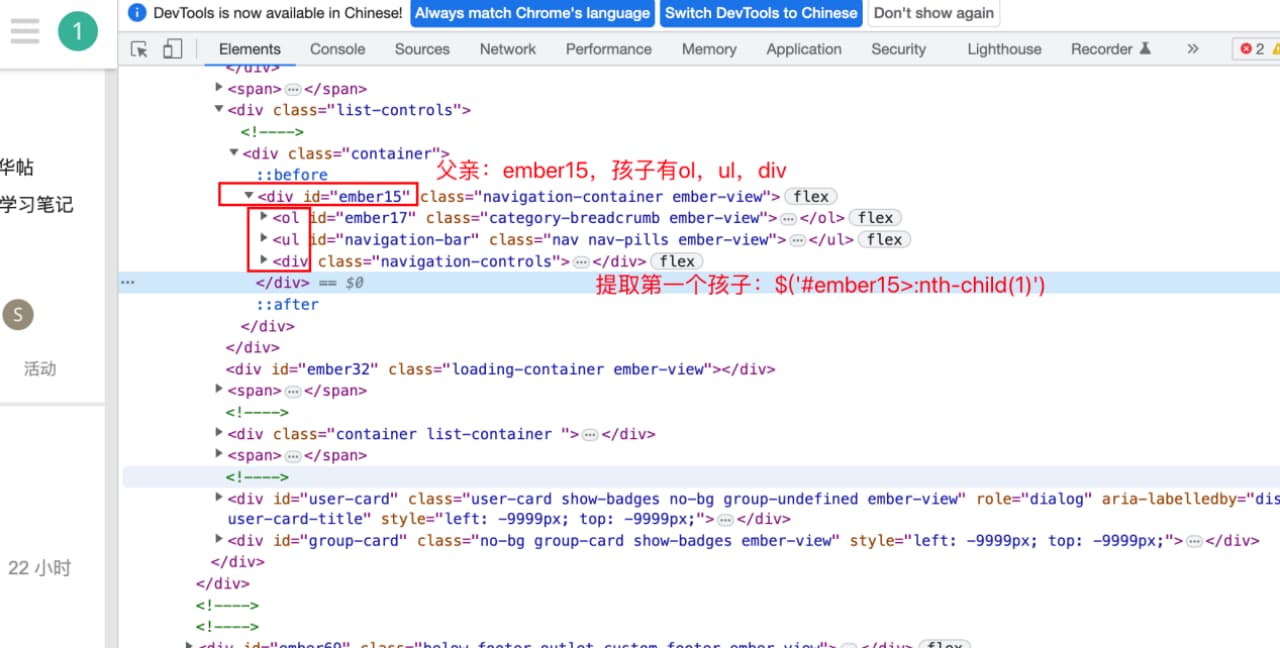
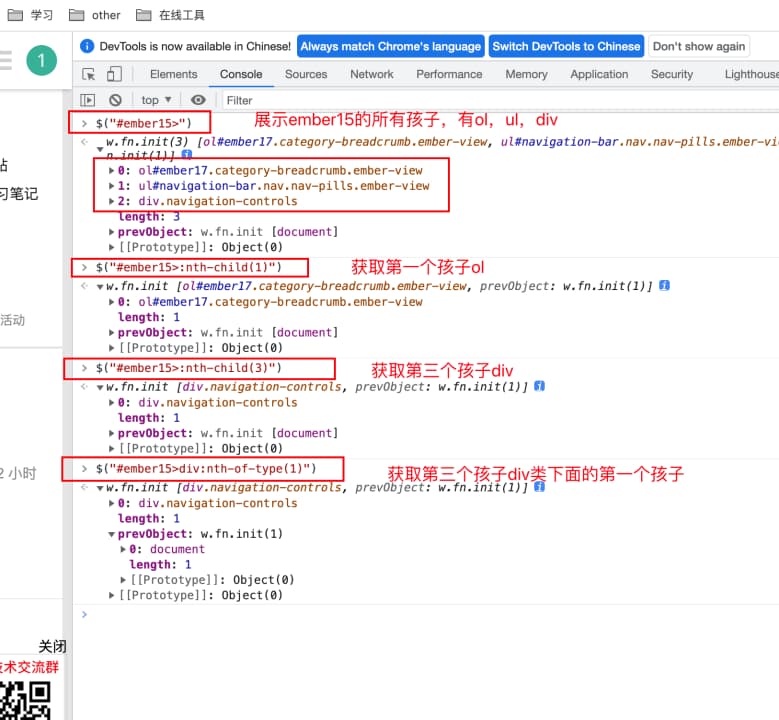
①父子关系+顺序:元素 元素(父亲有多个孩子,找到第一个孩子)
表达式://:nth-child(n)
$("#ember15>:nth-child(3)") ( #ember15为父亲,:nth-child(3)为第三个孩子)
②父子关系+标签类型+顺序:元素 元素(父亲的孩子有多个类型,想找其中一个类型里面的第一个孩子)
表达式://:nth-of-type(n)
$("#ember15>div:nth-of-type(1)")( #ember15为父亲,:nth-of-type(1)为第三个类型div的第一个孩子)
css表达式定位:
九、高级定位-xpath
1、xpath 基本概念
①XPath 是一门在 XML 文档中查找信息的语言
②XPath 使用路径表达式在 XML 文档中进行导航
③XPath 的应用非常广泛
④XPath 可以应用在UI自动化测试
2、xpath 使用场景
①web自动化测试
②app自动化测试
3、xpath 相对定位的优点
①可维护性更强
②语法更加简洁
③相比于css可以支持更多的方式
4、xpath 定位的调试方法
1)浏览器-console
$x("xpath表达式")
2)浏览器-elements
ctrl+f 输入xpath或者css
5、xpath 基础语法(包含关系)
| 表达式 |
结果 |
| / |
从该节点的子元素选取 |
| // |
从该节点的子孙元素选取 |
| * |
通配符 |
| nodename |
选取此节点的所有子节点 |
| … |
选取当前节点的父节点 |
| @ |
选取属性 |
【表达式:结果】
①/ :从该节点的子元素选取
②// :从该节点的子孙元素选取
③* :通配符
$x("//*[@id='ember61']"),匹配所有的[@id='ember61']
$x("//tr[@id='ember61']"),匹配tr标签下面的[@id='ember61']
④nodename :选取此节点的所有子节点,相当于标签名
⑤.. :选取当前节点的父节点,
如$x("//*[@id='ember61']/.."),寻找ember61的父节点
写法二:$x("//tr[@id='ember61']"),在某个标签下寻找
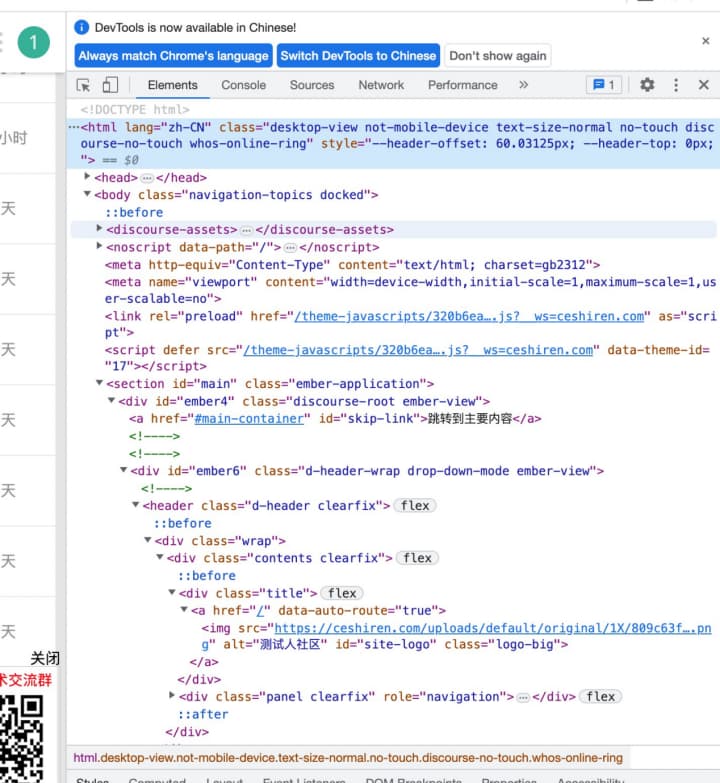
⑥@ :选取属性
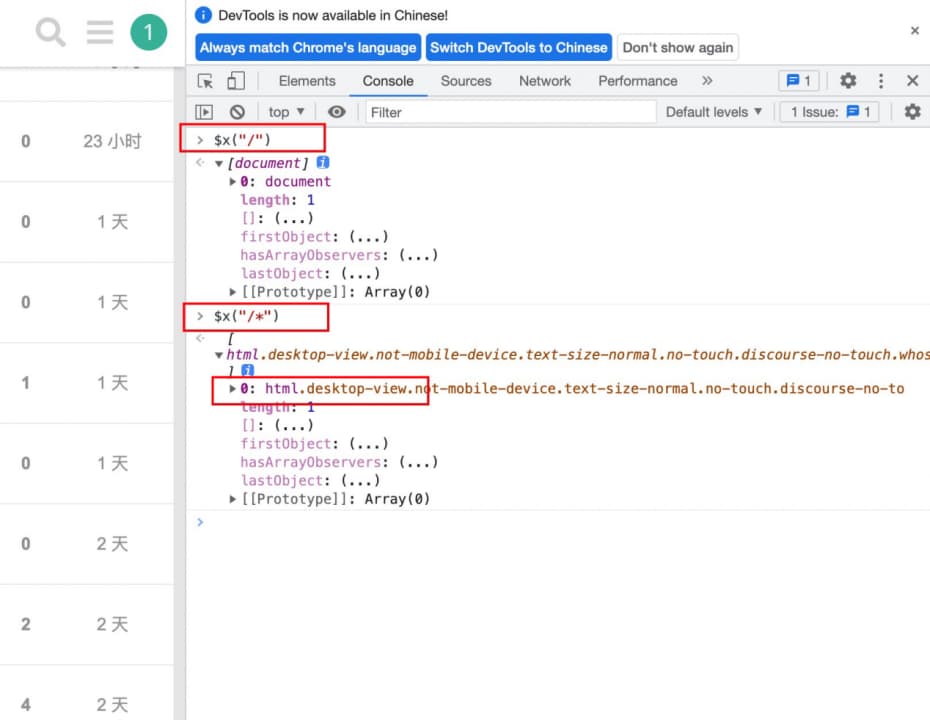
# 整个页面
$x("/")
# 页面中的所有的子元素,匹配/下面的所有节点,相当于是html
$x("/*")
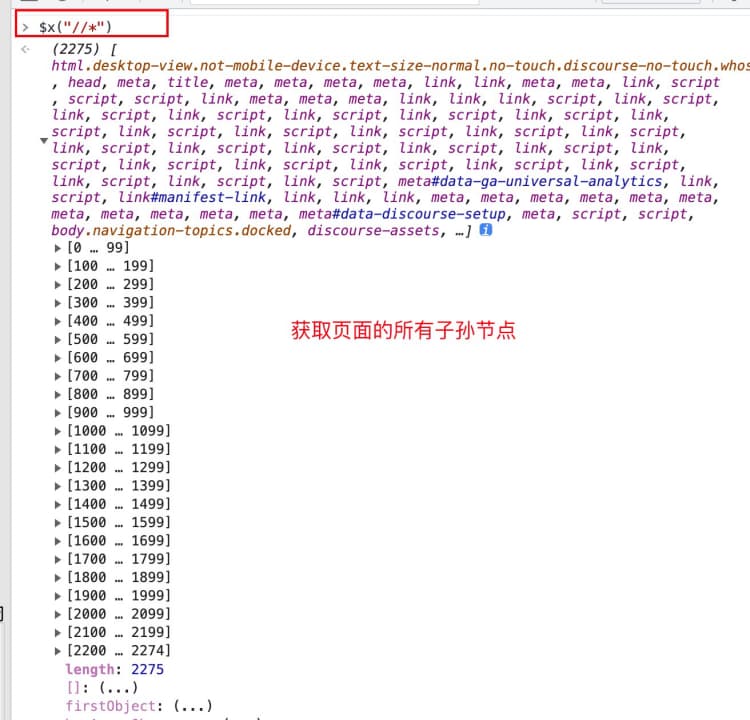
# 整个页面中的所有元素
$x("//*")
# 查找页面上面所有的div标签节点,标签不等于属性
$x("//div")
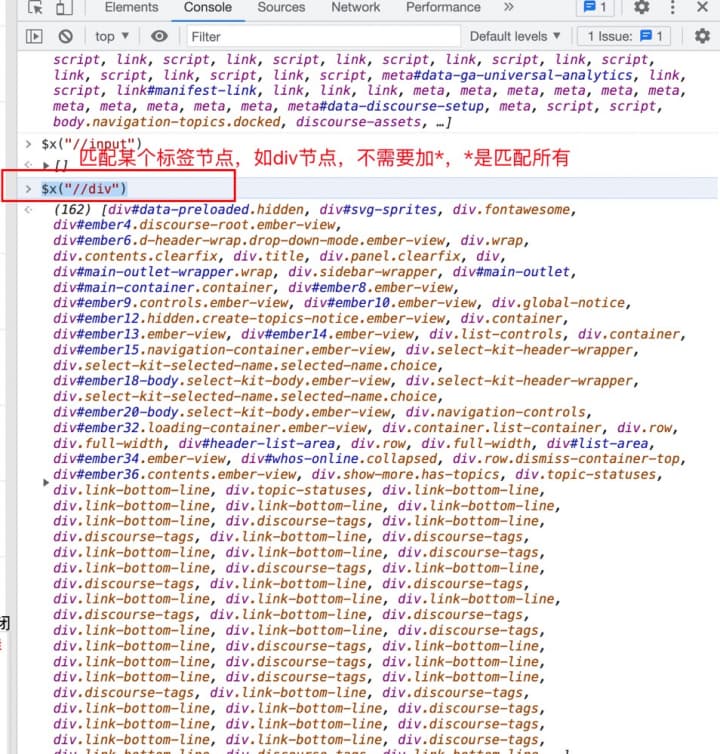
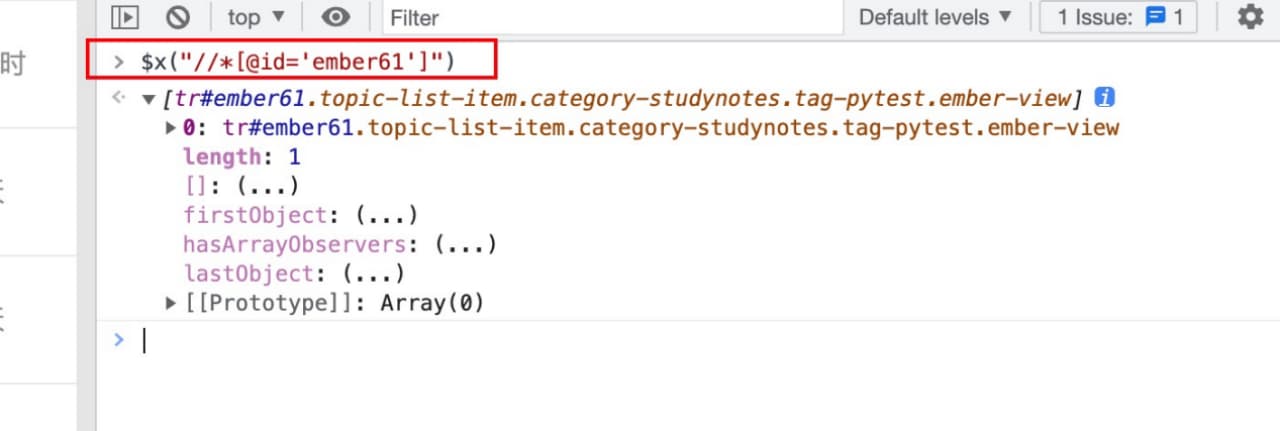
# 查找id属性为ember61的节点,*先匹配所有节点,再匹配某个属性
$x('//*[@id="ember61"]')
# 查找ember61节点的父节点
$x('//*[@id="ember61"]/..')
$x("//*[@id='ember61']/../..") # 再往上寻找父节点
6、xpath 顺序关系(索引)
xpath通过索引直接获取对应元素
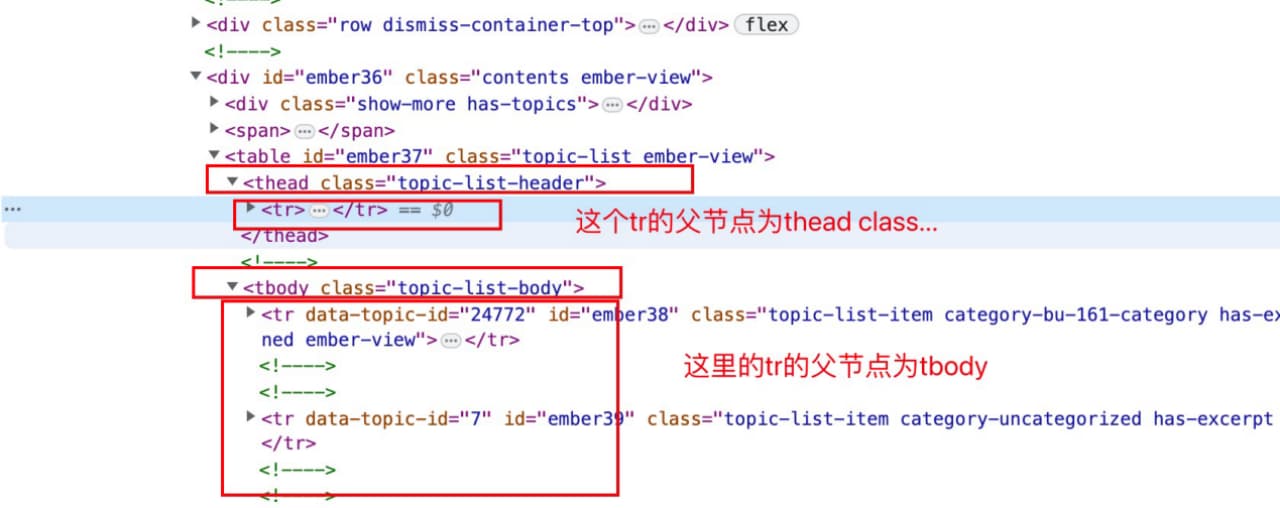
# 查找tbody下的所有tr
$x("//tbody//tr")
# 查找tbody下的第一个tr,下标从1开始
$x("//tbody//tr[1]")
# 获取所有的tr,注意这里的tr并不是都是同一个父节点
$x("//tr")
# 获取每个不同父节点下面的第一个tr
$x("//tr[1]")
7、xpath 高级用法
①[last()]: 选取最后一个
$x("//tr[last()]") # 获取每一个父节点下的最后一个tr
$x("//tbody//tr[last()]") # 获取tbody下面的最后一个tr
②[@属性名='属性值' and @属性名='属性值']: 与关系
$x("//*[@class='topic-list-item category-bu-161-category unseen-topic ember-view' and @id='ember44']")
③[@属性名='属性值' or @属性名='属性值']: 或关系
$x("//*[@class='topic-list-item category-bu-161-category unseen-topic ember-view' or @id='ember44']")
④[text()='文本信息']: 根据文本信息定位
$x("//*[text()='赏金任务']") # text不是属性,不需要加@,是一个方法,加括号
⑤[contains(text(),'文本信息')]: 根据文本信息包含定位;也可以contains(@id或@name等)
$x("//*[contains(text(),'赏金')]")
$x("//*[contains(@id,'site')]")
⑥注意:所有的表达式需要和[]结合
十、显式等待高级使用
1、显式等待原理
①在代码中定义等待一定条件发生后再进一步执行代码
②在最长等待时间内循环执行结束条件的函数,结合③一起查看
③源码:WebDriverWait(driver 实例, 最长等待时间, 轮询时间).until(结束条件函数)
2、常见 expected_conditions
| 类型 |
示例方法 |
说明 |
| element |
element_to_be_clickable();visibility_of_element_located() |
针对于元素,比如判断元素是否可以点击,或者元素是否可见 |
| url |
url_contains() |
针对于 url |
| title |
title_is() |
针对于标题 |
| frame |
frame_to_be_available_and_switch_to_it(locator) |
针对于 frame |
| alert |
alert_is_present() |
针对于弹窗 |
1)类型:element:
示例方法:
element_to_be_clickable()visibility_of_element_located()
说明:针对于元素,比如判断元素是否可以点击,或者元素是否可见
2)类型:url
示例方法:url_contains()
说明:针对于 url
3)类型:title
示例方法:title_is()
说明:针对于标题
4)类型:frame
示例方法:frame_to_be_available_and_switch_to_it(locator)
说明:针对于 frame
5)类型:alert
示例方法:alert_is_present()
说明:针对于弹窗
3、封装等待条件
1)官方的 excepted_conditions 不可能覆盖所有场景,如有些按钮需要点击两次或多次才会有反应
2)定制封装条件会更加灵活、可控
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.remote.webdriver import WebDriver
from selenium.webdriver.support.wait import WebDriverWait
class TestWebdriverWait:
driver = webdriver.Chrome()
driver.maximize_window()
driver.implicitly_wait(5)
driver.get("https://vip.ceshiren.com/#/ui_study/iframe")
def teardown(self):
self.driver.quit()
def test_webdriver_wait(self):
# 解决的问题:有的按钮点击一次没有反应,可能要点击多次,比如企业微信的添加成员
# 解决的方案:一直点击按钮,直到下个页面出现,封装成显式等待的一个条件
def muliti_click(button_element,until_ele):
# 函数封装
def inner(driver):
# 封装点击方法
driver.find_element(By.XPATH,button_element).click()
return driver.find_element(By.XPATH,until_ele)
return inner
time.sleep(5)
# 在限制时间内会一直点击按钮,直到展示弹框
WebDriverWait(self.driver,10).until(muliti_click("//*[text()='点击两次响应']","//*[text()='该弹框点击两次后才会弹出']"))
time.sleep(5)
十一、高级控件交互方法
1、使用场景
| 使用场景 |
对应事件 |
| 复制粘贴 |
键盘事件 |
| 拖动元素到某个位置 |
鼠标事件 |
| 鼠标悬停 |
鼠标事件 |
| 滚动到某个元素 |
滚动事件 |
| 使用触控笔点击 |
触控笔事件(了解即可) |
1)复制粘贴
对应事件:键盘事件
2)拖动元素到某个位置
对应事件:鼠标事件
3)鼠标悬停
对应事件:鼠标事件
4)滚动到某个元素
对应事件:滚动事件
5)使用触控笔点击
对应事件:触控笔事件(了解即可)
2、ActionChains解析
1)实例化类ActionChains,参数为driver实例。
2)中间可以有多个操作。
3).perform()代表确定执行。
3、键盘事件
1)按下、释放键盘键位
2)结合send_keys回车
3)键盘事件-使用shift实现大写
①ActionChains(self.driver): 实例化ActionChains类
②key_down(Keys.SHIFT, ele): 按下shift键实现大写
③send_keys("selenium"): 输入大写的selenium
④perform(): 确认执行
from selenium import webdriver
from selenium.webdriver import ActionChains, Keys
from selenium.webdriver.common.by import By
class TestKeyBoard:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3) # 隐式等待3秒
def teardown_class(self):
self.driver.quit()
def test_shift(self):
"""
键盘事件-使用shift实现大写
1.访问https://ceshiren.com/官方网站
2.点击搜索按钮
3.输入搜索的内容,输入的同时按着shift键
:return:
"""
self.driver.get("https://ceshiren.com/")
# 点击搜索按钮
self.driver.find_element(By.ID, "search-button").click()
# 目标元素,即为输入框
ele = self.driver.find_element(By.ID, "search-term")
# key_down代表按下某个键位,.send_keys输入内容,.perform()确认执行以上操作
ActionChains(self.driver).key_down(Keys.SHIFT, ele).send_keys("selenium").perform()
4)键盘事件-输入后回车
①直接输入回车: 元素.send_keys(Keys.ENTER)
②使用ActionChains: key_down(Keys.ENTER)
from selenium import webdriver
from selenium.webdriver import ActionChains, Keys
from selenium.webdriver.common.by import By
class TestKeyBoard:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3) # 隐式等待3秒
def teardown_class(self):
self.driver.quit()
def test_enter(self):
"""键盘事件-输入后回车"""
self.driver.get("https://www.sogou.com/")
self.driver.find_element(By.ID, "query").send_keys("python语言")
# 第一种回车方式,直接输入回车
self.driver.find_element(By.ID, "query").send_keys(Keys.ENTER)
# 第二种使用ActionChains,要记得加.perform()
ActionChains(self.driver).key_down(Keys.ENTER).perform()
5)键盘事件-复制粘贴
①多系统兼容
mac 的复制按钮为 COMMAND
windows 的复制按钮为 CONTROL
②左箭头:Keys.ARROW_LEFT
③按下COMMAND或者CONTROL: key_down(cmd_ctrl)
④按下剪切与粘贴按钮: send_keys("xvvvvv")
import sys
from selenium import webdriver
from selenium.webdriver import ActionChains, Keys
from selenium.webdriver.common.by import By
class TestKeyBoard:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3) # 隐式等待3秒
def teardown_class(self):
self.driver.quit()
def test_copy_and_paste(self):
"""键盘事件-复制粘贴"""
# 打开网页
self.driver.get("https://ceshiren.com/")
# 点击搜索按钮
self.driver.find_element(By.ID, "search-button").click()
# 目标元素,即为输入框
ele = self.driver.find_element(By.ID, "search-term")
# 判断操作系统是否为Mac(darwin),是mac返回command键位,windows返回control键位
command_control = Keys.COMMAND if sys.platform == "darwin" else Keys.CONTROL
# .key_down(Keys.SHIFT, ele)按下shift键,.send_keys("selenium")输入大写selenium,
# .key_down(Keys.ARROW_LEFT)按下左箭头,.key_down(command_control)按下command或control键位,
# .send_keys("xvv"),x表示为剪切,多少个v表示复制多少次,.key_up(command_control)表示松开command或control键位,.perform()执行
ActionChains(self.driver)\
.key_down(Keys.SHIFT, ele)\
.send_keys("selenium@")\
.key_down(Keys.ARROW_LEFT)\
.key_down(command_control).send_keys("xvvvvvv").key_up(command_control)\
.perform()
4、鼠标事件
1)双击
double_click(元素对象): 双击元素
2)拖动元素
drag_and_drop(起始元素对象, 结束元素对象): 拖动并放开元素
3)指定位置(悬浮)
move_to_element(元素对象): 移动到某个元素
import time
from selenium import webdriver
from selenium.webdriver import ActionChains, Keys
from selenium.webdriver.common.by import By
class TestKeyBoard:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(3) # 隐式等待3秒
def teardown_class(self):
self.driver.quit()
def test_double_click(self):
"""鼠标事件-双击"""
# 打开网页
self.driver.get("https://vip.ceshiren.com/#/ui_study/iframe")
# 获取点击按钮
ele = self.driver.find_element(By.ID, "primary_btn")
# .double_click(ele)调用双击方法,传入双击元素,.perform()执行
ActionChains(self.driver).double_click(ele).perform()
def test_drag_and_drop(self):
"""鼠标事件-拖动元素"""
# 打开网页
self.driver.get("https://vip.ceshiren.com/#/ui_study/action_chains")
# 获取需要拖动的元素,即起始元素的位置
item_left = self.driver.find_element(By.CSS_SELECTOR, '#item1') # #表示id标签
# 获取目标元素的位置
item_right = self.driver.find_element(By.CSS_SELECTOR, '#item3') # #表示id标签
# 实现拖拽操作,.drag_and_drop(item_left, item_right)
ActionChains(self.driver).drag_and_drop(item_left, item_right).perform()
def test_hover(self):
"""鼠标事件-悬浮"""
self.driver.get("https://vip.ceshiren.com/#/ui_study/action_chains2")
# 获取下拉框位置
ele = self.driver.find_element(By.CSS_SELECTOR, ".menu")
# 鼠标悬浮在下拉框
ActionChains(self.driver).move_to_element(ele).perform()
# 选择下拉选项
self.driver.find_element(By.XPATH, "//*[contains(text(),'测开班')]").click()
time.sleep(3)
5、滚轮/滚动操作
1)滚动到元素
scroll_to_element(WebElement对象):滚动到某个元素
2)根据坐标滚动
scroll_by_amount(横坐标, 纵坐标)
3)注意: selenium 版本需要在 4.2 之后
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
class TestScroll:
def setup_class(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(10) # 隐式等待
def teardown_class(self):
self.driver.quit()
def test_scoll_to_element(self):
"""滚轮/滚动操作-滚动到元素"""
# 打开网页
self.driver.get("https://ceshiren.com/")
# 获取页面底部某个标题
ele = self.driver.find_element(By.XPATH, "//*[text()='接口测试上线标准']")
# 页面滚动操作,找到"接口测试上线标准",selenium版本需要在 4.2 之后
ActionChains(self.driver).scroll_to_element(ele).perform()
time.sleep(5)
def test_scroll_to_xy(self):
"""滚轮/滚动操作-根据坐标滚动"""
self.driver.get("https://ceshiren.com/")
# 坐标滚动方式,.scroll_by_amount(0, 10000)纵向滚动
ActionChains(self.driver).scroll_by_amount(0, 3000).perform()
time.sleep(3)
十二、网页 frame 与多窗口处理
1、selenium⾥⾯如何处理多窗⼜场景
1) 多个窗口识别
2)多个窗口之间切换
2、selenium⾥⾯如何处理frame
1)多个frame识别
2)多个frame之间切换
3、多窗口处理
1)点击某些链接,会重新打开⼀个窗口,对于这种情况,想在新页⾯上操作,就
得先切换窗口了。
2)获取窗口的唯⼀标识⽤句柄表⽰,所以只需要切换句柄,就可以在多个页⾯灵
活操作了。
4、多窗口处理流程
1)先获取到当前的窗口句柄(driver.current_window_handle)
2)再获取到所有的窗口句柄(driver.window_handles)
3.)判断是否是想要操作的窗口,如果是,就可以对窗口进⾏操作,如果不是,
跳转到另外⼀个窗口,对另⼀个窗口进⾏操作 (driver.switch_to_window)
"""base.py文件,Base类有前置和后置操作"""
from selenium import webdriver
# 前置和后置操作,提供测试用例调用
class Base(object):
# 前置操作
def setup(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(5) # 隐式等待
# 后置操作
def teardown(self):
self.driver.quit()
"""测试用例文件test_window.py"""
import time
from selenium.webdriver.common.by import By
from webui.window_frame.base import Base
# 继承Base类,Base类里有前置和后置操作
class TestWindows(Base):
def test_window(self):
self.driver.get("https://www.baidu.com/")
# 找到登录按钮,并点击
self.driver.find_element(By.XPATH, "//*[@id='s-top-loginbtn']").click()
print(self.driver.current_window_handle) # 点击登录之后,打印当前窗口
# 点击弹窗里的立即注册按钮
self.driver.find_element(By.XPATH, "//*[text()='立即注册']").click()
# # 点击立即注册之后,打印当前窗口
# print(self.driver.current_window_handle)
# # 打印所有窗口的名字,列表形式,会有注册页面的窗口,
# print(self.driver.window_handles)
# 获取所有窗口列表,赋给window
window = self.driver.window_handles
# window[-1]获取注册页面的窗口,并切换到注册页面的窗口
self.driver.switch_to.window(window[-1])
# 注册页面,输入用户名username
self.driver.find_element(By.ID, "TANGRAM__PSP_4__userName").send_keys("username")
time.sleep(3)
# 切换回最初登录页面的窗口
self.driver.switch_to.window(window[0])
# # 登录页面,点击短信登录
# self.driver.find_element(By.XPATH, "//*[text()='短信登录']").click()
# 获取用户名输入框,并输入用户名
self.driver.find_element(By.ID, "TANGRAM__PSP_11__userName").send_keys("login_username")
# 获取密码输入框,并输入密码
self.driver.find_element(By.ID, "TANGRAM__PSP_11__password").send_keys("login_password")
# 点击登录
self.driver.find_element(By.ID, "TANGRAM__PSP_11__submit").click()
time.sleep(6)
5、frame处理
1)frame介绍
①在web⾃动化中,如果⼀个元素定位不到,那么很⼤可能是在iframe中。
②什么是frame?
a. frame是html中的框架,在html中,所谓的框架就是可以在同⼀个浏览器中显⽰不⽌⼀个页⾯。
b. 基于html的框架,又分为垂直框架和⽔平框架(cols,rows)
③Frame 分类
a. frame标签包含frameset、frame、iframe三种,
b. frameset和普通的标签⼀样,不会影响正常的定位,可以使⽤index、id、name 、webelement任意种⽅式定位frame。
c. ⽽frame与iframe对selenium定位⽽⾔是⼀样的。selenium有⼀组⽅法对frame进⾏操作
2)多frame切换
①frame存在两种:⼀种是嵌套的,⼀种是未嵌套的
②切换frame
❖ driver.switch_to.frame() # 根据元素id或者index切换切换frame
❖ driver.switch_to.default_content() # 切换到默认frame
❖ driver.switch_to.parent_frame() # 切换到⽗级frame
3)frame未嵌套
①处理未嵌套的iframe
❖ driver.switch_to_frame(“frame 的 id”)
❖ driver.switch_to_frame(“frame - index”) frame⽆ID的时候依据索引来处理,索引从0开始 driver.switch_to_frame(0)
4)frame嵌套
②处理嵌套的iframe
❖ 对于嵌套的先进⼊到iframe的⽗节点,再进到⼦节点,然后可以对⼦节点⾥⾯的对象进⾏处理和操作
❖ driver.switch_to.frame(“⽗节点”)
❖ driver.switch_to.frame(“⼦节点”)
import time
from selenium.webdriver.common.by import By
from webui.window_frame.base import Base
# 继承Base类,Base类里有前置和后置操作
class TestFrame(Base):
def test_frame(self):
self.driver.get("https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable")
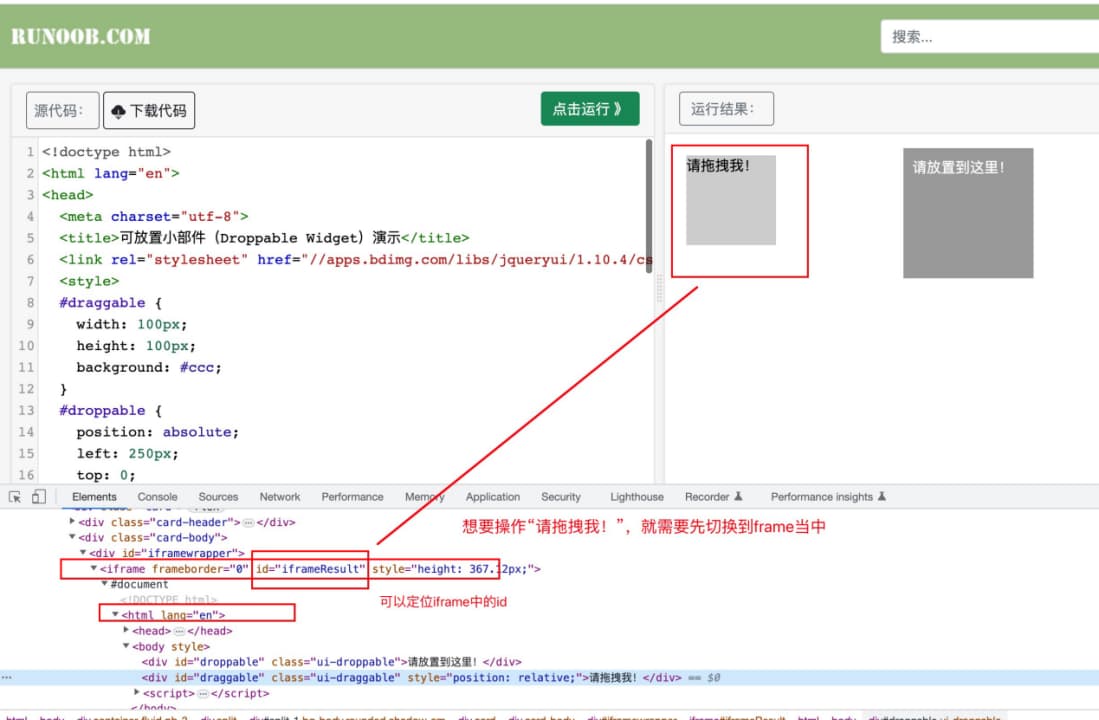
# 切换到frame中,根据frame的元素id
self.driver.switch_to.frame("iframeResult") # 写法一,常用
# self.driver.switch_to_frame("iframeResult") # 写法二
# 获取"请拖拽我!"的属性,获取文本内容
print(self.driver.find_element(By.ID, "draggable").text)
# 写法一:切回网页,即不在frame页面,即切回frame父节点
# self.driver.switch_to.parent_frame()
# 写法二:切换到默认frame节点,即刚打开的地址节点
self.driver.switch_to.default_content()
# 获取"点击运行"按钮,并点击
self.driver.find_element(By.ID, "submitBTN").click()
time.sleep(5)
十三、文件上传弹框处理
1、⽂件上传
1)input标签可以直接使⽤send_keys(⽂件地址)上传⽂件
2) ⽤法:
①el = driver.find_element_by_id('上传按钮id')
②el.send_keys(”⽂件路径+⽂件名")
import time
from selenium.webdriver.common.by import By
from webui.window_frame.base import Base
# 继承Base类,Base类里有前置和后置操作
class TestFile(Base):
def test_file_upload(self):
self.driver.get("https://www.baidu.com/")
# 找到百度的相机图标并点击
self.driver.find_element(By.XPATH, "//*[@class='soutu-btn']").click()
# 定位到选择文件,并选择文件
self.driver.find_element(By.XPATH, "//input[@class='upload-pic']").send_keys("/Users/jiyu/PycharmProjects/pythonProject/webui/img/12.png")
time.sleep(5)
2、chrome 开启 debug 模式
1)有时候登录⽅式⽐较繁琐,需要动态⼿机密码,⼆维码登录之类的。⾃动话实现⽐较⿇烦。⼿⼯登录后,
不想让selenium启动⼀个新浏览器。可以使⽤chrome的debug⽅式来执⾏测试。
2)启动chrome的时候需要先退出所有chrome进程。使⽤ps aux|grep chrome|grep -v 'grep'查看是否有
chrome进程存在。确保没有chrome进程被启动过。
3)正常启动chrome的debug模式
①# 默认macOS系统
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --remote-debuggingport=9222
②# Windows下找到chrome.exe位置执⾏下⾯的命令
chrome.exe --remote-debugging-port=9222
4)启动后的提⽰信息,代表chrome运⾏正常,不要关闭⾃动打开的chrome窗口。
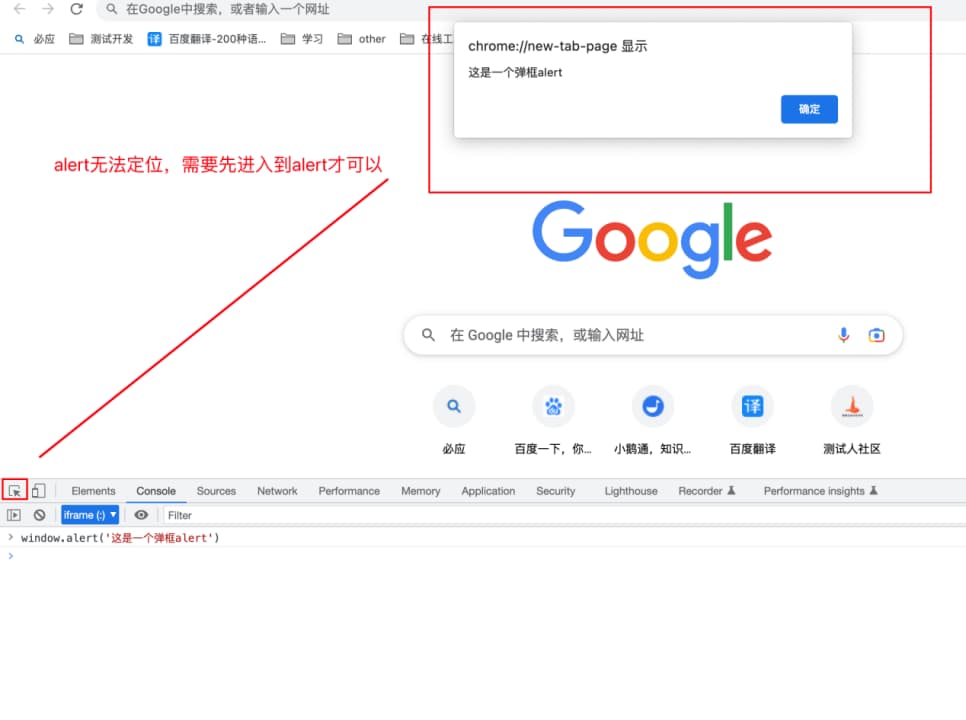
3、弹框处理机制
1)在页⾯操作中有时会遇到JavaScript所⽣成的alert、confirm以及prompt弹框,可以使⽤switch_to.alert()⽅法定位到。然后使⽤text/accept/dismiss/send_keys等⽅法进⾏操作。
2)操作alert常⽤的⽅法:
①switch_to.alert():获取当前页⾯上的警告框。
②text:返回alert/confirm/prompt 中的⽂字信息。
③accept():接受现有警告框。
④dismiss():解散现有警告框。
⑤send_keys(keysToSend):发送⽂本⾄警告框。keysToSend:将⽂本发送⾄警告框。
import time
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from webui.window_frame.base import Base
class TestAlert(Base):
def test_alert(self):
"""
❖ 打开⽹页
https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable
❖ 操作窗⼜右侧页⾯, 将元素1拖拽到元素2
❖ 这时候会有⼀个alert弹框,点击弹框中的’确定’
❖ 然后再按’点击运⾏’
❖ 关闭⽹页
:return:
"""
self.driver.get("https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable")
# 切换到frame中,根据frame的元素id
self.driver.switch_to.frame("iframeResult")
# 获取需要拖动的元素,即起始元素的位置
a1 = self.driver.find_element(By.CSS_SELECTOR, '#draggable')
# 获取目标元素的位置
a2 = self.driver.find_element(By.CSS_SELECTOR, '#droppable')
# 实现拖拽操作,.drag_and_drop(a1, a2):将a1拖拽到a2上,.perform()执行
action = ActionChains(self.driver)
action.drag_and_drop(a1, a2).perform()
time.sleep(2) # 强制等待2秒,查看效果
# 切换到alert页面,点击alert的确认按钮.accept()
self.driver.switch_to.alert.accept()
# 退出alert页面,返回到默认frame节点
self.driver.switch_to.default_content()
# 获取"点击运行"按钮,并点击
self.driver.find_element(By.ID, 'submitBTN').click()
time.sleep(3)
十四、自动化关键数据记录
1、什么是关键数据
①代码的执行日志
②代码执行的截图
③page source(页面源代码)
2、记录关键数据的作用
| 内容 |
作用 |
| 日志 |
1. 记录代码的执行记录,方便复现场景;2. 可以作为bug依据 |
| 截图 |
1. 断言失败或成功截图;2.异常截图达到丰富报告的作用;3. 可以作为bug依据 |
| page source |
1. 协助排查报错时元素当时是否存在页面上 |
1)日志:
①记录代码的执行记录,方便复现场景
②可以作为bug依据
2)截图
①断言失败或成功截图
②异常截图达到丰富报告的作用
③可以作为bug依据
3)page source
①协助排查报错时元素当时是否存在页面上
3、行为日志记录
1)日志配置
2)脚本日志级别
①debug记录步骤信息
②info记录关键信息,比如断言等
#日志配置文件log_utils.py
# 日志配置
import logging
# 创建logger实例
logger = logging.getLogger('simple_example')
# 设置日志级别
logger.setLevel(logging.DEBUG)
# 流处理器
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
# 日志打印格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 添加格式配置
ch.setFormatter(formatter)
# 添加日志配置
logger.addHandler(ch)
# 测试用例脚本文件test_data_record.py
# 日志与脚本结合
from selenium import webdriver
from selenium.webdriver.common.by import By
from webui.data_record.log_utils import logger
from webui.window_frame.base import Base
# 继承Base类,Base类里有前置和后置操作
class TestDataRecord(Base):
""""""
def test_data_record(self):
search_content = "python语言"
# 打开网页
self.driver.get("https://www.sogou.com/")
# 定位输入框,输入内容
self.driver.find_element(By.ID, "query").send_keys(search_content)
# 加入日志,步骤信息较多且琐碎,使用debug
logger.debug(f"搜索的信息为:{search_content}")
# 点击搜索
self.driver.find_element(By.ID, "stb").click()
# 获取搜索结果列表的标题,对应测试结果的实际结果
search_result = self.driver.find_element(By.CSS_SELECTOR, "em") # 多个em的情况下,默认拿第一个
# 添加日志,断言使用info,级别高于debug,断言实际结果与预期结果是否一致
logger.info(f"实际结果为:{search_result.text},预期结果为:{search_content}")
# 断言,search_result.text 获取搜索结果的文本信息,预期结果search_content
assert search_result.text == search_content
4、步骤截图记录
1)save_screenshot(截图路径+名称)
2)记录关键页面
①断言页面
②重要的业务场景页面
③容易出错的页面
from selenium.webdriver.common.by import By
from webui.data_record.log_utils import logger
from webui.window_frame.base import Base
# 继承Base类,Base类里有前置和后置操作
class TestDataRecord(Base):
def test_screen_shot_data_record(self):
search_content01 = "python语言"
# 打开网页
self.driver.get("https://www.sogou.com/")
# 定位输入框,输入内容
self.driver.find_element(By.ID, "query").send_keys(search_content01)
# 加入日志,步骤信息较多且琐碎,使用debug
logger.debug(f"搜索的信息为:{search_content01}")
# 点击搜索
self.driver.find_element(By.ID, "stb").click()
# 获取搜索结果列表的标题,对应测试结果的实际结果
search_result01 = self.driver.find_element(By.CSS_SELECTOR, "em") # 多个em的情况下,默认拿第一个
# 添加日志,断言使用info,级别高于debug,断言实际结果与预期结果是否一致
logger.info(f"实际结果为:{search_result01.text},预期结果为:{search_content01}")
# 截图记录,双重保障
self.driver.save_screenshot("search_result01.png")
# 断言,search_result01.text 获取搜索结果的文本信息,预期结果search_content01
assert search_result01.text == search_content01
5、page source记录
1)使用page_source属性获取页面源码
2)在调试过程中,如果有找不到元素的错误可以保存当时的page_source调试代码
from selenium.webdriver.common.by import By
from webui.window_frame.base import Base
# 继承Base类,Base类里有前置和后置操作
class TestDataRecord(Base):
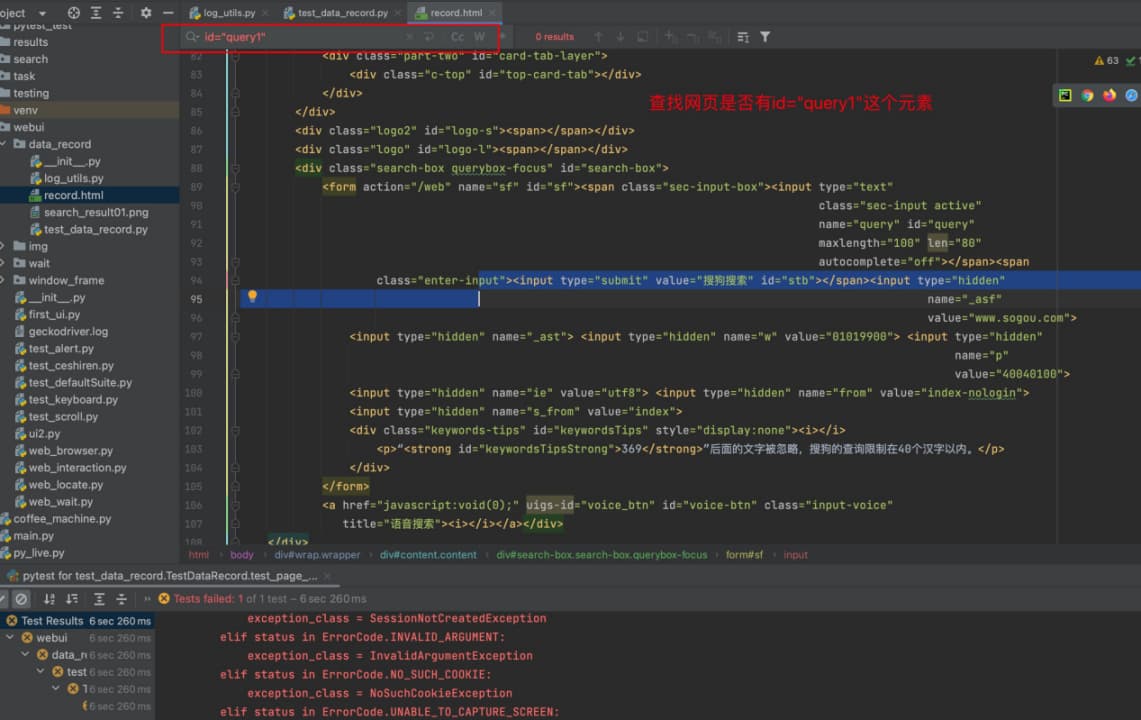
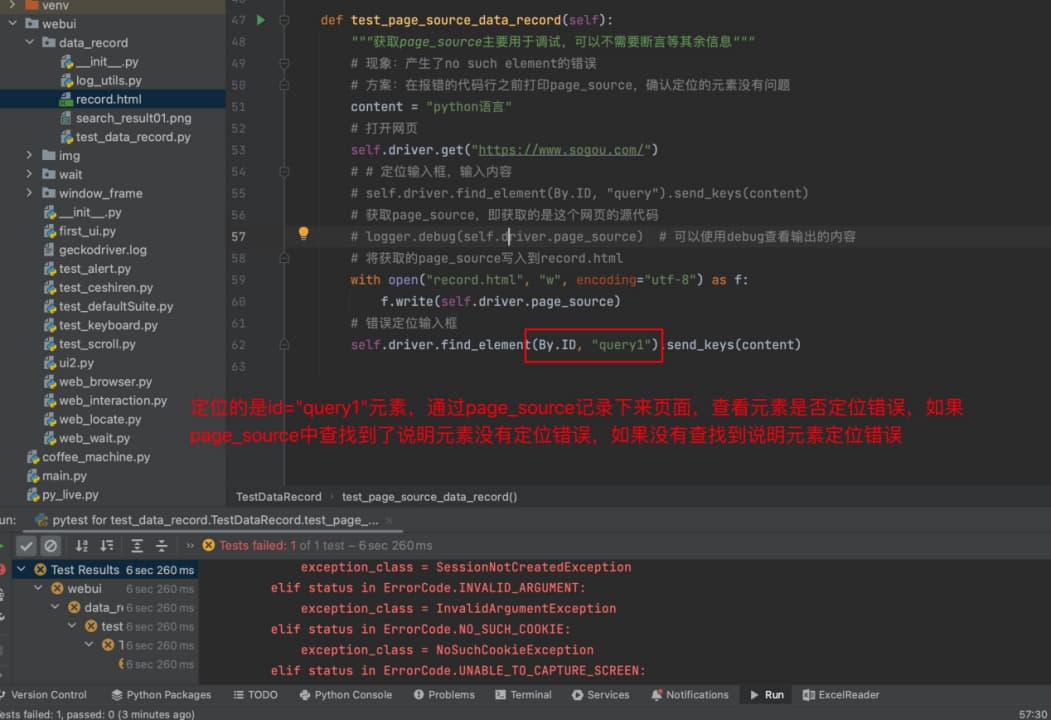
def test_page_source_data_record(self):
"""获取page_source主要用于调试,可以不需要断言等其余信息"""
# 现象:产生了no such element的错误
# 方案:在报错的代码行之前打印page_source,确认定位的元素没有问题
content = "python语言"
# 打开网页
self.driver.get("https://www.sogou.com/")
# # 定位输入框,输入内容
# self.driver.find_element(By.ID, "query").send_keys(content)
# 获取page_source,即获取的是这个网页的源代码
# logger.debug(self.driver.page_source) # 可以使用debug查看输出的内容
# 将获取的page_source写入到record.html
with open("record.html", "w", encoding="utf-8") as f:
f.write(self.driver.page_source)
# 错误定位输入框
self.driver.find_element(By.ID, "query1").send_keys(content)