内置库 json
JSON
- JSON 是用于存储和交换数据的语法,是一种轻量级的数据交换格式。
- 使用场景
JSON 结构
{
"language": [
{
"name": "python",
"url": "https://www.python.org/"
},
{
"name": "java",
"url": "https://www.java.com/zh-CN/"
}
]
}
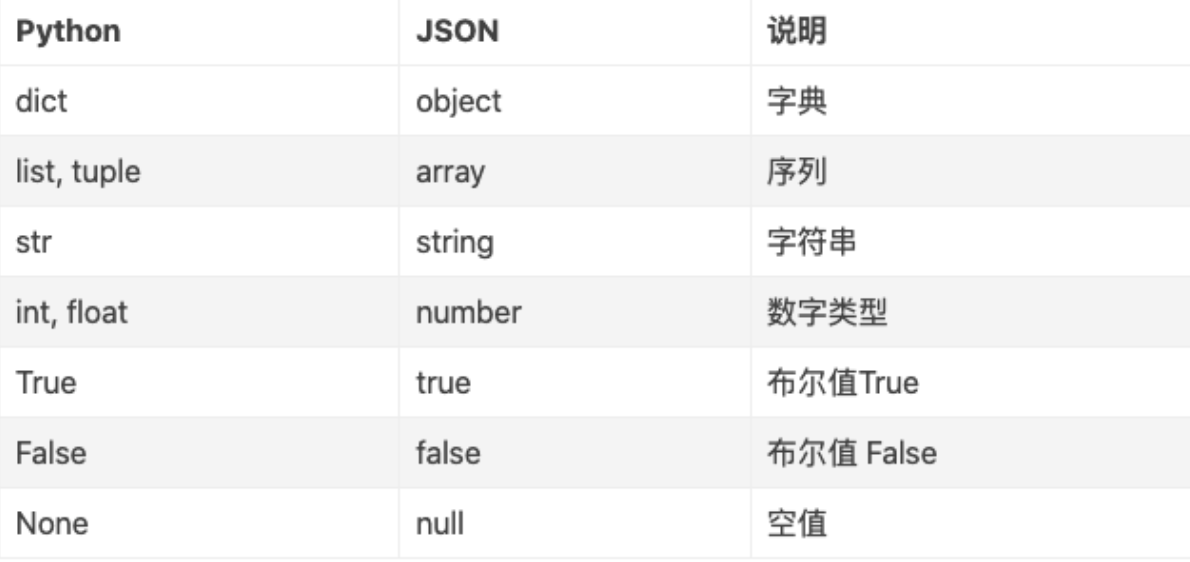
Python 与 JSON 数据类型对应
json 库
- 可以从字符串或文件中解析 JSON
- 该库解析 JSON 后将其转为 Python 字典或者列表
常用方法
-
dumps():将 Python 对象编码成 JSON 字符串
-
loads():解码 JSON 数据,该函数返回 Python 对象
-
dump(): Python 对象编码,并将数据写入 json 文件中
-
load():从 json 文件中读取数据并解码为 Python 对象
import json
# 定义 python 结构
data = [{'a': 1, 'b': '2', 'c': True, 'd': False, 'e': None }]
# 将 python 对象编码为 JSON 字符串
json_data = json.dumps(data)
# 将 JSON 字符串解码为 python 对象
python_data = json.loads(json_data)
# 写入 JSON 数据,在代码当前目录生成一个 data.json 的文件
with open('data.json', 'w') as f:
json.dump(data, f)
# 读取数据,读取 json 文件并解码成 python 对象
with open('data.json', 'r') as f:
data = json.load(f)
dumps 常用参数
-
indent:根据数据格式缩进显示,默认为 None,没有缩进
-
ensure_ascii:对中文使用 ASCII 编码,默认为 True
import json
data = {
'a': 1,
'b': '霍格沃兹',
'c': True,
'd': False,
'e': None }
python_data = json.dumps(data, indent=4, ensure_ascii=False)
print(python_data)
内置库 re
目录
正则表达式
什么是正则表达式
- 正则表达式就是记录文本规则的代码
- 可以查找操作符合某些复杂规则的字符串
使用场景
在 python 中使用正则表达式
- 把正则表达式作为模式字符串
- 正则表达式可以使用原生字符串来表示
- 原生字符串需要在字符串前方加上
r'string'
# 匹配字符串是否以 hogwarts_ 开头
r'hogwart_\w+'
使用 re 模块实现正则表达式操作
正则表达式对象转换
-
compile():将字符串转换为正则表达式对象
- 需要多次使用这个正则表达式的场景
import re
'''
prog:正则对象,可以直接调用匹配、替换、分割的方法,不需要再传入正则表达式
pattern:正则表达式
'''
prog = re.compile(pattern)
匹配字符串
-
match():从字符串的开始处进行匹配
-
search():在整个字符串中搜索第一个匹配的值
-
findall():在整个字符串中搜索所有符合正则表达式的字符串,返回列表
import re
'''
pattern: 正则表达式
string: 要匹配的字符串
flags: 可选,控制匹配方式
- A:只进行 ASCII 匹配
- I:不区分大小写
- M:将 ^ 和 $ 用于包括整个字符串的开始和结尾的每一行
- S:使用 (.) 字符匹配所有字符(包括换行符)
- X:忽略模式字符串中未转义的空格和注释
'''
re.match(pattern, string, [flags])
re.search(pattern, string, [flags])
re.findall(pattern, string, [flags])
替换字符串
import re
'''
pattern:正则表达式
repl:要替换的字符串
string:要被查找替换的原始字符串
count:可选,表示替换的最大次数,默认值为 0,表示替换所有匹配
flags:可选,控制匹配方式
'''
re.sub(pattern, repl, string, [count], [flags])
分割字符串
-
split():根据正则表达式分割字符串,返回列表
import re
'''
pattern:正则表达式
string:要匹配的字符串
maxsplit:可选,表示最大拆分次数
flags:可选,控制匹配方式
'''
re.split(pattern, string, [maxsplit], [flags])
# 匹配手机号码
pattern = r"1[34578]\d{9}"
s1 = "中奖号码 123456,联系电话 15611111111"
result = re.sub(pattern, '1xxxxxxxxxx', s1)
print(result)
p = r"[?|&]"
url = "https://www.baidu.com/s?wd=%E9%9C%8D%E6%A0%BC%E6%B2%83%E5%85%B9%E6%B5%8B%E8%AF%95%E5%BC%80%E5%8F%91&rsv_spt=1&rsv_iqid=0xdc2997e0000adc07&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_dl=tb&rsv_enter=1&rsv_sug2=0&rsv_btype=i&inputT=6346&rsv_sug4=6712"
r = re.split(p, url)
print(r)