基础
性能调优离应用程序越近越好,包括让应用程序充分利用系统资源,归纳应用程序使用系统资源的方式等。 在接手一个陌生应用程序时,可以无从下手,可以从以下几个问题来深入理解应用程序,以 AppCrawler为例:
- 功能:自动化遍历和操作 app ,可生成报告及操作截图
- 操作:开启 app ,对页面进行点击或其他 app 操作
- CPU 模式:以用户级软件实现,单进程
- 配置:可用 yaml 更改便利规则,配置中暂无性能参数
- 性能指标:无具体提供性能指标,可查看执行时间
- 日志:有标记每个步骤的执行时间
- 版本:是最新版本
- Bugs
- 社区:ceshiren.com
目标
要设定一个性能目标指明调优方向,以下是几个常用目标:
- 延时:低响应
- 吞吐量:高应用程序操作率或者数据传输率
- 资源使用率:高效的利用资源
在实际应用中,需要对目标进行量化:
- 应用程序平均延时 5ms
- 95% 的请求延时在 100ms 或以下
- 最大吞吐量为每台服务器至少 10000 次应用请求/秒
- 在每秒 1000 次应用请求的情况下,平均磁盘使用率在 50% 以下
优化方向
应用程序的代码行数轻松上万,不可能从头看起,如果该程序是 I/O 密集型,应该优先查看导致频繁 I/O 的代码路径,具体方法后面会介绍。
提高应用程序性能,可以从以下几个方向入手。
I/O 尺寸
每次执行 I/O 操作都会存在额外开销,包括,应该增加 I/O 的传输数据,减少传输次数,比如一次传输 128KB 要比 128 次传输 1KB 更高效。但是 I/O 容量过大也存在问题,比如执行 8KB 的数据读取按 128KB I/O 的尺寸运行会慢很多,因此,有必要选择一个合适的尺寸。
缓存
应用程序缓存与操作系统缓存类似,将经常操作的数据放入高速缓存区,用以备用,当计算机存在多个缓存时(多 CPU 下很常见,每个 CPU 都有自己的缓存),会出现对数据同时读写的情况,如果一边读一边写,必然会出现不一致的现象,保持缓存一致性就是保证缓存中的数据与主存储器中数据相同。
缓存提高了读操作的性能, 但对写操作有严格要求(要保证缓存一致性)。
缓冲区
与缓存不同,缓冲区可以提高写操作,数据在传递到下一层级之前,会放入缓冲区。比如 CPU 向磁盘写入内容,由于磁盘写入操作过慢, CPU 要等待上一块的写入操作完成才能传入下一块内容,如果加入缓冲区, CPU 可把数据一次性放入缓冲区即可,不必等待 I/O 操作完成。
但是当数据增多,缓冲区不能存储所有的数据,先处理先到的,然后把数据释放掉,再处理下一个,每次处理数据都要申请空间,释放空间,操作需要很多不必要的资源。
环形缓冲区开辟一个固定空间,利用这个环形区域处理数据。
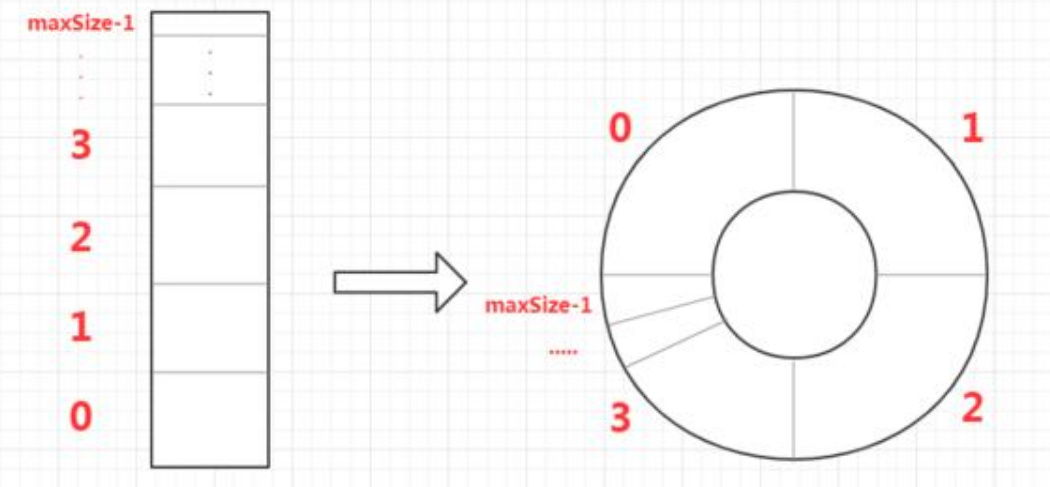
轮询
轮询是循环的检查某一个事件状态,它可能存在性能问题:
- 重复检查开销高昂
- 事件发生,不会立刻检查,每次检查间有一定的延时
系统调用 poll() 使用了轮询操作,比如下图是 select() ,底层使用 poll() 实现:

- 用户态创建了网络 IO 连接,假设一个 socket 连接就是一个 fd 文件描述符,那么将 fd 添加到 fd_set 集合中
- 将 fd_set 集合从用户态 copy 到内核态
- 遍历这个 fd_set 集合,找出所有已经就绪的 fd,执行对应 fd 的相关操作
- 将内核态的 fd_set 集合拷贝到用户态
可以看出,在整个处理过程,需要遍历 fd_set 集合,这个遍历操作需要 O(n) ,当文件描述符增多时,会产生性能问题, Linux 的最新工具 epoll(), epoll() 避免使用遍历,复杂度能达到 O(1) 。
并发和并行
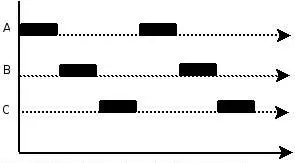
从 Unix 衍生的系统都是分时系统,支持程序的并发。无论是应用程序,还是程序内的函数都可以并发执行,可以装载和运行多个程序,但是,在某一瞬间只能有一个程序运行。可以对整个程序进行并发,也可以对程序中的某个函数并发。可用多线程,多进程,基于事件来实现并发。并发也可以用在 I/O 上,当一个线程阻塞在 I/O 等待时,可转身执行其他线程,如下图:
如果 CPU 数量变多,同一瞬间可以运行多个程序,这就是并行,可用多线程和多进程实现并行,但多线程更高效(共享同一进程内地址空间) ,如下图:
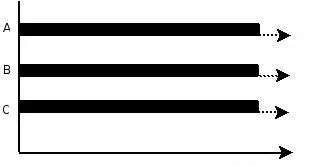
由于多线程共享地址空间,会造成数据读写问题,比如同时对数据进行读的过程中又进行写入,数据会不一致,此时需要同步原语操作,典型的同步原语操作引入了锁,下面是三种常见的锁:
- mutex 锁:假设双核 CPU,锁持有者在 Core0 进行操作,需要锁的线程在 Core1 会被阻塞,进行排队, Core1 会切换上下文去执行不需要锁的操作
- 自旋锁:只能锁持有者才能进行操作,其他的线程会循环检测锁是否被释放,不会被阻塞
- 读写锁:只允许一个写者和多个读者
- 自适应 mutex 锁(adaptive mutex lock):自旋锁和 mutex 锁的结合,安排一个合理的自旋时间,超时后进入阻塞
对锁的管理有多种方法:
- 所有数据结构只有一个锁:并发程序会引起锁的大量竞争
- 每个数据结构都有一个锁:锁太多,对锁的申请和释放会引起资源开销
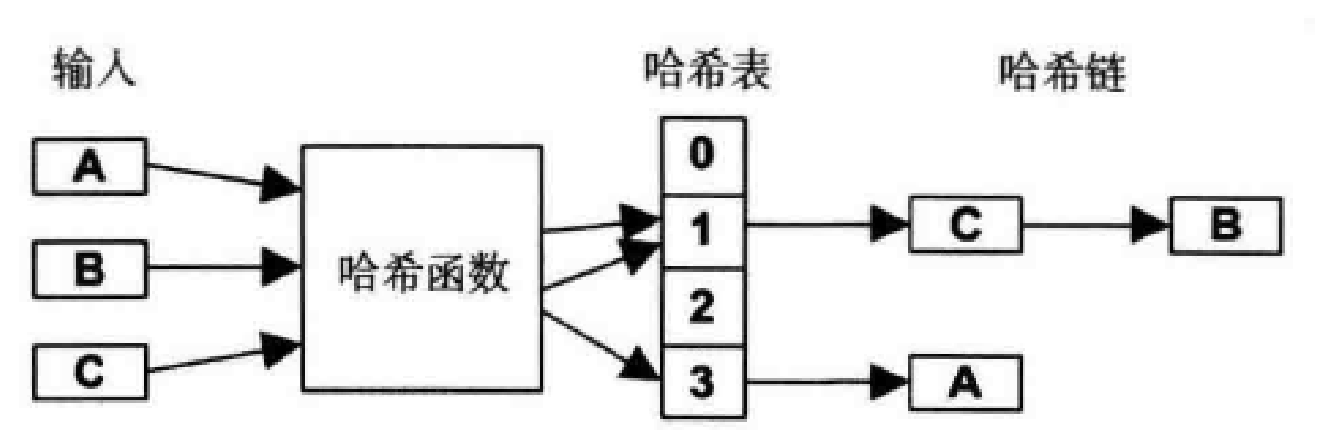
- 哈希表管理:使用固定数量的锁,不同的数据结构在哈希表中查找对应的锁,如果多个数据结构找到了一个锁,需要用链将数据结构串起来,比如下图的数据结构 C 和 B ,如果链条太长,需要进行遍历,也会造成资源消耗,因此,锁的数量和哈希函数的设计至关重要:
非阻塞 I/O
- 阻塞 I/O :请求读时,如果没有得到响应,会被阻塞,直到有响应为止。类似排除,一个一个来
- 非阻塞 I/O:请求读时,如果没有得到响应,会立刻返回一个 Error ,不会等待,避免多进程同时被阻塞,但需要轮询查看是否可以读取。类似排队取号,拿着号码不停的问“到我了吗”
- I/O 多路复用: 开启一个线程用来监控文件描述符状态(可用 select() 或者 poll() 实现),如果状态就绪,则在本线程或者新线程中执行 I/O 操作。类似黄牛,一人排除多人吃瓜
处理器绑定
现在流行一种架构 NUMA 环境(自行搜索扩展),这种架构下,线程或进程在单个 CPU 上运行是有益的,某些程序可以强制绑定到 CPU 上,这样会带来收益,但也有性能风险:
- 绑定间发生冲突
- 如果存在多用户,只会让绑定的 CPU 工作,其它空闲的 CPU 空闲
编程语言
编程语言有多种类型:
- 编译语言:运行之前将程序转换为机器指令(C和C++),性能强,调优简单,可通过调整编译器参数优化性能
- 解释语言:运行时翻译成行为(shell脚本),性能差调优难
- 虚拟机:将程序转换为虚拟机指令集,再由虚拟机解释执行,无法调优,除非虚拟机提供工具集
垃圾回发
很多语言都有自动内存管理,分配的内存不用手动释放,但这样做有风险:
- 释放不及时,造成内存使用增加
- GC 会间歇运行,消耗大量 CPU 资源
- GC 执行时,应用程序会中止执行
很多语言都提供 GC 调整参数,比如 java 虚拟机提供参数设置 GC 类型, GC 线程数等
方法
todo
