本内容参考:Effective Python,有时间的同学可以购买原书籍阅读
一:关键词
- Python:多指 python3 版本,本人使用的是 Python3.6
二:编码风格
代码风格:PEP 8 – Style Guide for Python Code | peps.python.org
注释风格:PEP 257 – Docstring Conventions | peps.python.org
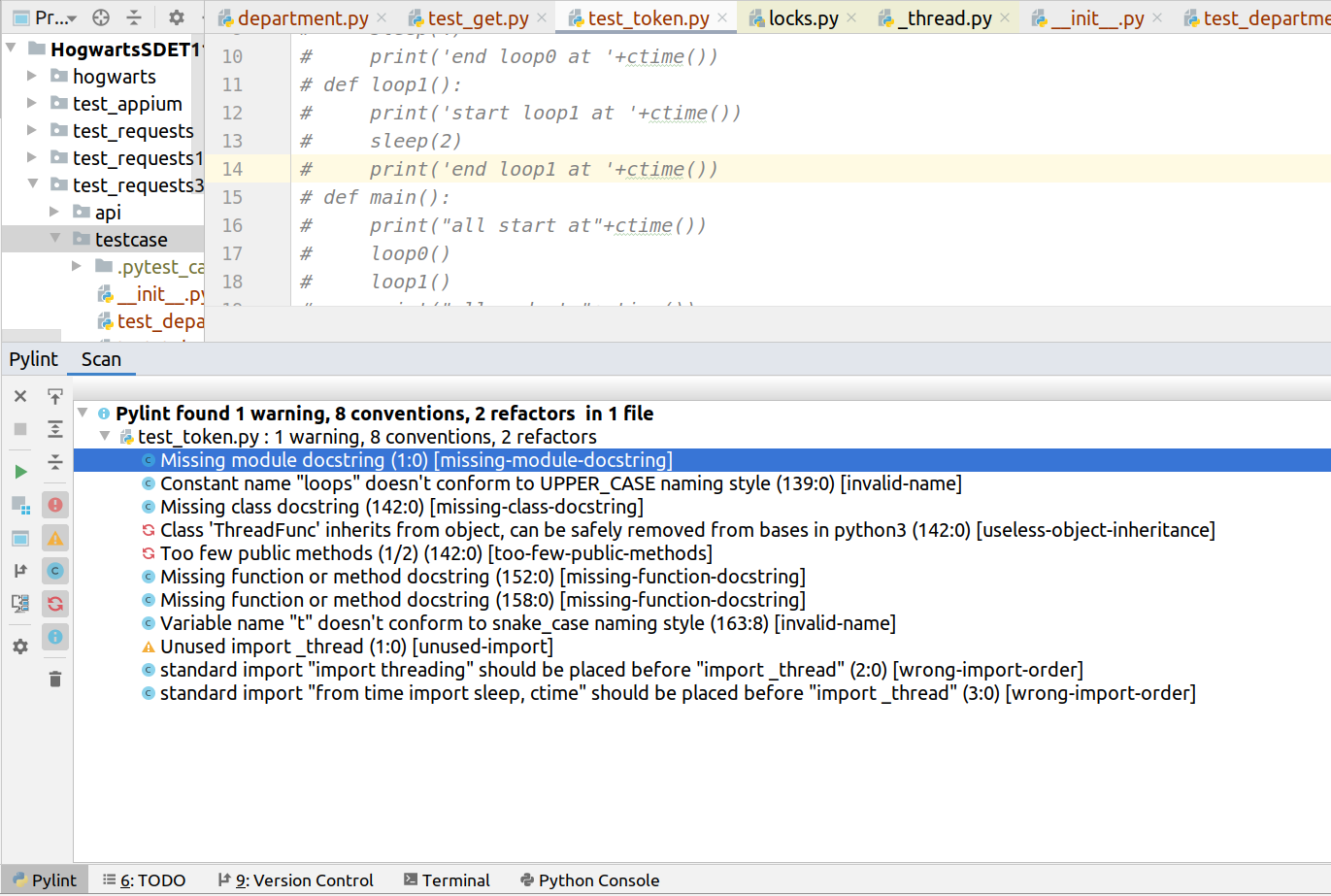
Pylint 是 Python 源码静态分析工具,可检查代码是否符合 PEP 8 风格指南
可在 pycharm 中下载 Pylint 插件,在左下角会标识出 Pylint 字样,点击浏览即可审查代码,Pylint 的检查非常严格:
三:编码
Python3 有两种字符序列类型: str 和 bytes ,其中 bytes 的实例是字节,其对应 8 位二进制数据, str 的实例包括 Unicode 字符,可以用 utf-8 编码方式把 Unicode 字符转为二进制数据,反之同理。Python3 使用 encode() 和 decode() 分别对应上述操作:
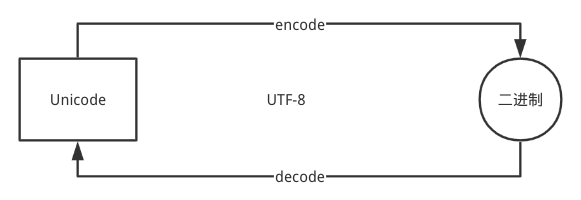
在程序内部,建议使用 Unicode ,把任何外部输入转换为 Unicode ,而对外输出则采用 bytes 。这样可以保证外部编码不影响内部使用,同时输出稳定(都是 bytes )。以下代码实现了 二进制 与 Unicode 格式互转:
def to_str(bytes_or_str):
if isinstance(bytes_or_str, bytes):
value = bytes_or_str.decode('utf-8')
else:
value = bytes_or_str
return value # Instance of bytes
def to_bytes(bytes_or_str):
if isinstance(bytes_or_str, str):
value = bytes_or_str.encode('utf-8')
else:
value = bytes_or_str
return value # Instance of str
Python 的 open() 方法默认使用 encoding() 方法,即要求传一个 Unicode 字符,它会帮你转成二进制,如果你传的是二进制数据,就会报错

参考以下代码及输出结果, os.urandom() 产生随机的 bytes 值,把它写入 random.bin 文件会报错:
def main():
with open('./random.bin', 'w') as f:
f.write(os.urandom(15))
if __name__ == '__main__':
main()

以下是官方源码给出的注释:
In text mode, if encoding is not specified the encoding used is platform dependent: locale.getpreferredencoding(False) is called to get the current locale encoding.
只需要将写入模式改为二进制写入即可:
```python
def main():
with open('./random.bin', 'wb') as f:
f.write(os.urandom(15))
if __name__ == '__main__':
main()
四:辅助函数
Python 有很多强大的特性,如果过度使用,会让代码晦涩难懂,考虑以下代码及返回结果:
from urllib.parse import parse_qs
my_values=parse_qs('red=5&blue=0&green=',
keep_blank_values=True)
print(repr(my_values))
>>>
{'red': ['5'], 'blue': ['0'], 'green': ['']}
三种颜色都有返回值,用 get() 方法获取内容时,会打出下面内容:
print('Red: ', my_values.get('red'))
print('Green: ', my_values.get('green'))
print('xxxx: ', my_values.get('xxxx'))
>>>
Red: ['5']
Green: ['']
xxxx: None
发现一个问题,当原 list 为空时, get 方法返回空,当原 key 不存在时(比如xxxx), get 方法返回 None ,现在利用 Python 的特性,将上述代码优化。 Python 中空字符串、空
列表及零值都是 False :
# 优化一
print('Red: ', my_values.get('red', [''])[0] or 0)
print('Green: ', my_values.get('green', [''])[0] or 0)
# 当字典没有这个值时, get 方法会返回第二个参数值 ['']
print('xxxx: ', my_values.get('xxxx', [''])[0] or 0)
>>>
Red: 5
Green: 0
xxxx: 0
# 优化二
read = my_values.get('red', [''])
print('Red: ', read[0] if read[0] else 0)
无论是优化一还是优化二,都让代码少,但复杂晦涩。此时不如向特性做出妥协,使用传统的 if/else 语法,把要实现的功能封装到函数中,称之为辅助函数:
def get_first_int(value: dict, key, default=0):
found = value.get(key, [''])
if found[0]:
found = found[0]
else:
found = default
return found
print('Red: ', get_first_int(my_values, 'red'))
五:切割序列
Python 可对序列进行切割,基本写法是 list[start:end] ,其中 start 所指元素会在切割后的范围内, 而 end 所指元素不会被包括在切割结果中。查看下面代码及输出结果:
a = ['a','b','c','d','e','f','g','h','i']
print('First four:',a[:4])
print('last four:',a[-4:])
print('Middle three:',a[3:-3])
>>>
First four: ['a', 'b', 'c', 'd']
last four: ['f', 'g', 'h', 'i']
Middle three: ['d', 'e', 'f']
start 和 end 可以越界使用,因此可以限定输入序列的最大长度,比如限定长度为 20 :
a=['a', 'v', 'c']
print(a[:20])
print(a[-20:])
>>>
['a', 'v', 'c']
['a', 'v', 'c']
对切割后的内容进行任何操作,都不会影响到原 list ,比如:
a=['a', 'v', 'c']
b=a[1:]
b[0]=10
print('a: ' , a)
print('b: ', b)
>>>
a: ['a', 'v', 'c']
b: [10, 'c']
可以对 list 中的值进行扩张,把列表中指定范围的值替换成新值,比如:
a1 = ['a', 'v', 'c', 'h']
a1[0:10]=['f','f']
print('a1: ', a1)
a2 = ['a', 'v', 'c', 'h']
a2[2:3]=['f','f']
print('a2: ', a2)
>>>
a1: ['f', 'f']
a2: ['a', 'v', 'f', 'f', 'h']
六:单次切片不同时指定 start、end 和 stride
Python 提供更激进的切片操作 somelist[start:end:stride] ,可以指定步进值 stride 实现取出奇索引和偶索引:
a = ['i','love','hogwarts','every','day']
odds = a[::2]
evens = a[1::2]
print(odds)
print(evens)
>>>
['i', 'hogwarts', 'day']
['love', 'every']
甚至可以进行反转操作:
a = ['i', 'love', 'hogwarts', 'every', 'day']
b = b'abcdefgh'
reverse_a = a[::-1]
reverse_b = b[::-1]
print(reverse_a)
print(reverse_b)
>>>
['day', 'every', 'hogwarts', 'love', 'i']
b'hgfedcba'
这个技巧适合字节串和 ASCII 字符,对于编码成 UTF-8 字节串的 Unicode ,会出问题:
a = '霍格沃兹测试学院'
b = a.encode('utf-8')
c = b[::-1]
d = c.decode('utf-8')
print(d)
>>>
Traceback (most recent call last):
File "xxx", line 5, in <module>
d = c.decode('utf-8')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa2 in position 0: invalid start byte
另外,2::2 , -2::-2 , -2:2:-2 和 2:2:-2 的意思同理,如果参数过多,意思会非常难以理解,不应该把 stride 与 start 和 end 写在一起。尽量采用正值 stride ,省略 start 和 end 索引。如果一定要配合 start 或 end 索引来使用 stride,可以先步进式切片,把切割结果赋给变量,然后在变量上再进行切割。也可以使用 islide ,它不允许 start , end 或 stride 有负值。
a = ['i','love','hogwarts','every','day']
b = a[::2]
c = b[1:-1]
print(c)
>>>
['hogwarts']
七:推导式
Python 可根据一份 list 来制作另一份,对 dict 也适用,参考以下代码及执行结果:
a = ['i','love','hogwarts','every','day']
b1 = [k+'ff' for k in a]
b2 = [k+'ff' for k in a if k == 'every']
print('b1: ',b1)
print('b2: ',b2)
>>>
b1: ['iff', 'loveff', 'hogwartsff', 'everyff', 'dayff']
b2: ['everyff']
当然, map 与 filter 也可以做到上述效果,但很难理解。字典(dict)和集合(set)也有类似的推导机制,参考以下执行结果:
a = {'a': 'i', 'b': 'love', 'c': 'hogwarts', 'd': 'every', 'e': 'day'}
b1 = {key:value+'ff' for key, value in a.items()}
b2 = {key:value+'ff' for key, value in a.items() if key == 'd' or key == 'a'}
print('b1: ', b1)
print('b2: ', b2)
>>>
b1: {'a': 'iff', 'b': 'loveff', 'c': 'hogwartsff', 'd': 'everyff', 'e': 'dayff'}
b2: {'a': 'iff', 'd': 'everyff'}
八:不要使用含有两个以上表达式的列表推导
todo
