示例:"http://ceshiren.com/stde/courses" ,输出:"ceshiren""https://www.hogwarts.com" ,输出:"hogwarts"
题目难度:简单codewars
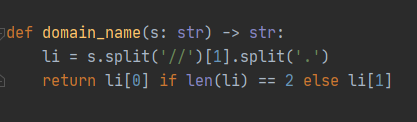
def domain_name(s:str) -> str:
pass
assert domain_name("http://ceshiren.com/stde/courses") == "ceshiren"
assert domain_name("https://www.hogwarts.com") == "hogwarts"
hua123
2021 年8 月 15 日 07:15
2
import tldextract # pip install tldextract
def domain_name(s: str) -> str:
return tldextract.extract(s).domain
assert domain_name("http://ceshiren.com/stde/courses") == "ceshiren"
assert domain_name("https://www.hogwarts.com") == "hogwarts"
import re
def domain_name(s: str) -> str:
res = re.findall(r'.*?://[w.]*\.?(.*?)\..*?', s)
return res[0]
assert domain_name("http://ceshiren.com/stde/courses") == "ceshiren"
assert domain_name("https://www.hogwarts.com") == "hogwarts"
def domain_name(s: str) -> str:
for i in urlparse(s).netloc.split("."):
if i == "www":
continue
else:
return i
assert domain_name("http://ceshiren.com/stde/courses") == "ceshiren"
assert domain_name("https://www.hogwarts.com") == "hogwarts"
fwj
2021 年8 月 16 日 06:49
5
def domain_name(s:str):
res=tldextract.extract(s)
return res.domain
def domain_name(s:str) -> str
return s.split("//")[-1].split("www.")[-1].split(".")[0]
思路:利用字符串内置的split方法进行分割解析,每次取分割后所需的部分。
import re
def domain_name(s:str):
return re.search('(https?://)?(www\d?\.)?(?P<name>[\w-]+)\.', s).group('name')
思路:利用正则表达式语法提取目标信息。
def domain_name(s: str) -> str:
return s.split('.com')[0].split('//')[1] if 'www' not in s else s.split('.com')[0].split('//')[1].split('www.')[1]
assert domain_name("http://ceshiren.com/stde/courses") == "ceshiren"
assert domain_name("https://www.hogwarts.com") == "hogwarts"
给定一个字符串格式的URL完整地址,请编写一个python函数,提取出其中的主域。