感觉selenium还有一些问题没有解决:
-
用例的组织形式,有那么多链接,不能只给一个初始化的链接呀?
-
对于定位讲的太粗浅,变化的定位 和 一些下拉框等基础的都没有涉及到
-
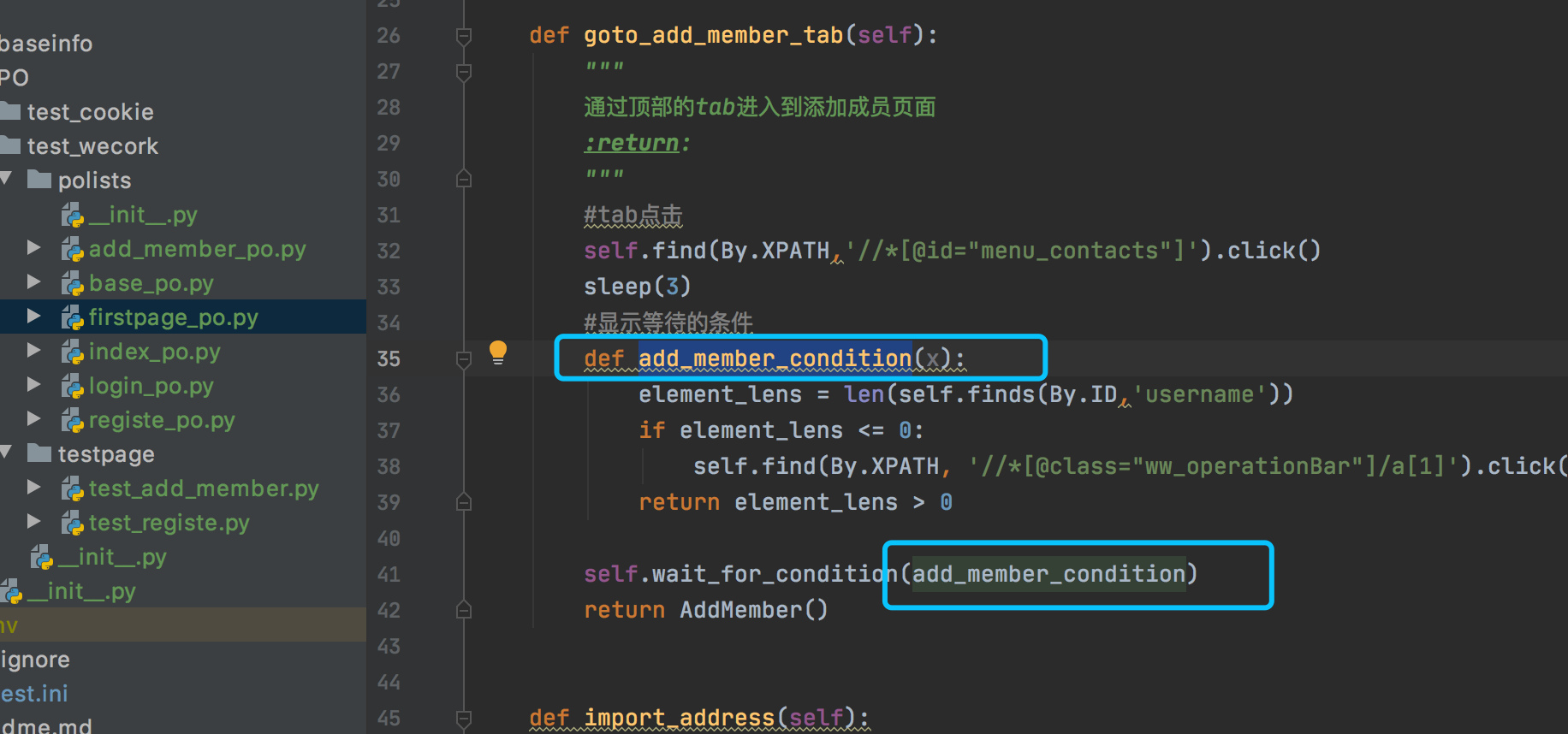
老师最后自己组装的显示等待中 ,参数x是干啥用的 也没有说明
-
断言也没有讲
-
也没有实现数据和框架分离
-
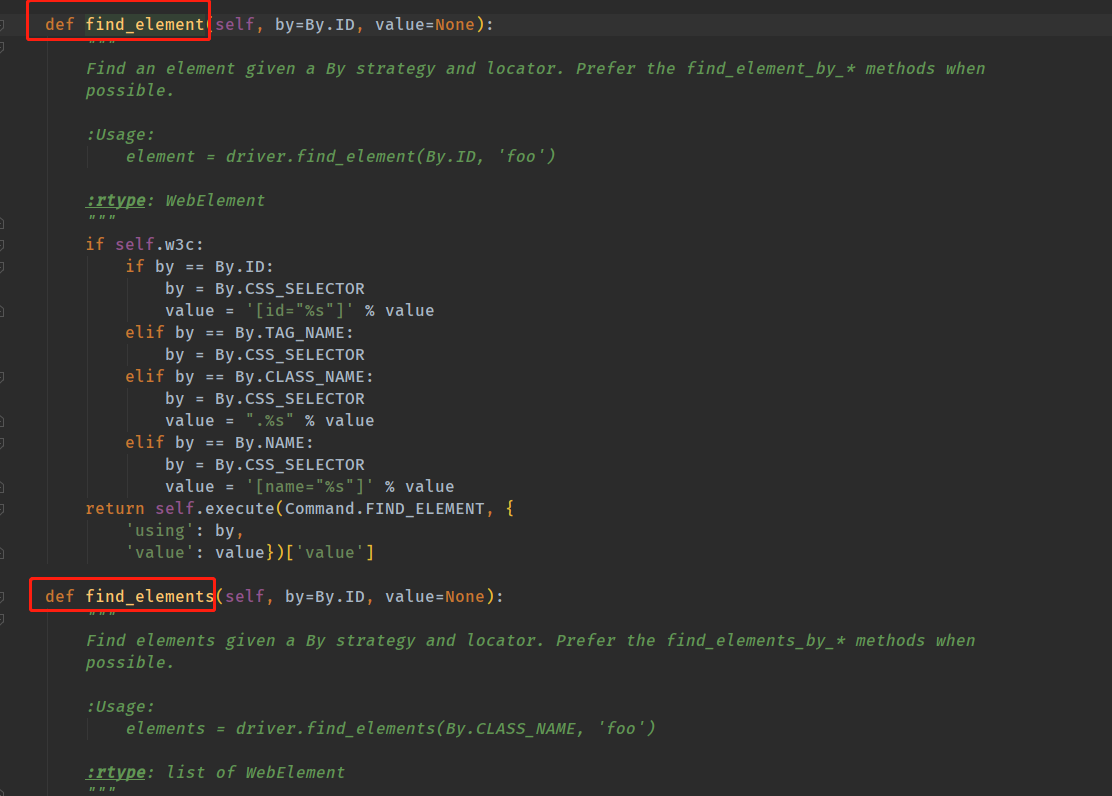
也没有解释,为啥在base_page中创建了 find finds 这个的区别是啥,为啥要这样做?
感觉selenium还有一些问题没有解决:
用例的组织形式,有那么多链接,不能只给一个初始化的链接呀?
对于定位讲的太粗浅,变化的定位 和 一些下拉框等基础的都没有涉及到
老师最后自己组装的显示等待中 ,参数x是干啥用的 也没有说明
断言也没有讲
也没有实现数据和框架分离
也没有解释,为啥在base_page中创建了 find finds 这个的区别是啥,为啥要这样做?
我只解答一些技术性问题哈,其他的我我也不是很清楚
现在的用的PageObject模式就是一种框架分层模式,那么用例层写在testcase层就可以了,那么用例的组织形式不清楚你的具体是啥?理论上setUp/tearDown模式解决了用例的前后关联,就是一个用例就可以成功运行了
变化的定位的解决方案都是显示等待+基础定位来解决的,只要你把显示定位掌握好了就可以解决这种“变化的定位”,下拉框这些定位应该录播课有讲或者自己去补一下就可以,就是很简单的内容
参数x是一个java 8的lambda表达式,x代表了一个形参
断言这部分应该再基础课里面就讲过了,selenium实战课应该就是直接用了,注意看下老师的源代码
数据和框架的分离指的是什么数据?你的输入数据?还是定位数据?
find finds 这两个方法其实差不多是一个类型的,猜测一个应该是找所有元素,一个是找一个元素吧,因为没有源代码,只能靠猜
第六点我知道,find_element和find_elements可以追踪源码,看返回值,前者只返回value,直到超时;后者返回value或者[],就是none
所以在判断显示等待条件代码那里用find_elements找姓名元素,没找到就返回[],无限点击添加成员,找到就返回value,就能执行else退出循环
有点不懂的是,为啥改了一下s就可以实现返回值类型不一样的问题:
#find只返回value,直到超时;
def find(self,by,locator):
return self._driver.find_element(by,locator)
#finds返回value或者[],就是none
def finds(self,by,locator):
return self._driver.find_elements(by,locator)
不知道这个为啥调用的时候也没有传参啊,在定义中也没有使用到这个参数,为啥就必须写呢??
但是断言需要整理的吧,需要存储的吧? 这些是怎么做的呢?
之前讲数据分离都很槽,随便建了一个文件,随便写了一些样式数据就完了,以为会在实际应用中重点使用,但是并没有
我没有问封装的好处,我想知道的是 find 和 finds 的区别??以及这样做的作用是啥,,为啥要两个
你可以追踪find_element和find_elements的源码进行查看
4.断言是属于测试用例部分的,基本写法就在之前pytest的课程,这部分内容不太建议封装,因为测试用例步骤做成数据驱动除非用来做测试平台,不然的话编写和维护难度其实是会变大的。
5.yaml文件的格式就是这样的,基本格式了解了之后,需要什么格式,按照规则去写就是了,怎么写主要取决于你测试数据是什么形式的。
6.find和finds对应的方法不是一个,功能也是不一样的,这个你直接追踪进去看封装的方法就知道了。
find是返回一个元素
finds是返回多个元素的列表,如果只找到一个就是一个元素的列表,需要加下标才能读取出来
首先声明,我不是python班的学员,可能有些上下文我无法联想,只能根据你贴的代码来回答!
第六个问题:加s返回的是个列表,也就是一组元素对象,如果找不到那就是空列表
不加s返回的是一个元素,如果找不到就是会抛异常