从手动整理到全自动推送,测试报告效率提升500%的完整方案
曾经,每天下班前的手动测试报告整理是我最头疼的工作。需要从多个测试平台收集数据、整理成统一格式、分析关键指标,最后再手动发送给团队。这个过程平均每天消耗我1.5小时,直到我用Dify搭建了一个全自动的测试报告工作流,现在只需一键触发,18分钟自动完成所有工作。
一、痛点分析:传统测试报告为何如此耗时?
在搭建自动化工作流之前,我的测试报告工作流程是这样的:
原始手动流程耗时分解:
- Jira/Xray提取测试执行结果:25分钟
- Jenkins构建日志分析与统计:15分钟
- 自定义Excel模板数据填充:35分钟
- 结果分析与洞察提炼:20分钟
- 报告发送与团队通知:15分钟
- 总计:≈ 110分钟
这个过程中最痛苦的不是单个步骤的复杂度,而是重复性、机械性工作占据了大部分时间。更糟糕的是,人为操作难免出错,曾经因为复制粘贴错误导致报告数据失真,影响了发布决策。
二、解决方案:Dify自动化测试报告工作流
整体架构设计
我设计的Dify工作流实现了从数据采集到报告推送的全流程自动化:
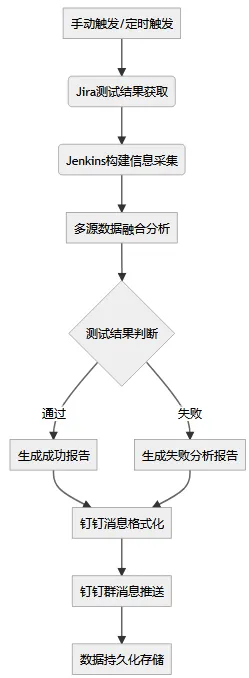
核心能力亮点
- 多平台数据集成:自动对接Jira、Jenkins、TestRail等测试工具
- 智能数据分析:基于大模型自动识别关键问题和趋势
- 自适应报告生成:根据测试结果动态调整报告内容和格式
- 即时消息推送:通过钉钉机器人实现秒级通知
三、环境准备:10分钟快速搭建
Dify平台部署
# 使用Docker Compose快速部署
git clone https://github.com/langgenius/dify
cd dify/docker
cp .env.example .env
# 配置必要的环境变量
echo "DIFY_API_KEYS=your_secret_key_here" >> .env
echo "DEEPSEEK_API_KEY=your_deepseek_key" >> .env
# 启动服务
docker-compose up -d
访问 http://localhost:8088 即可进入Dify控制台。
钉钉机器人创建
- 在钉钉群中点击「群设置」→「智能群助手」→「添加机器人」
- 选择「自定义机器人」,设置名称如「测试报告助手」
- 获取Webhook地址,格式如下:
https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxx
人工智能技术学习交流群

四、工作流详细搭建步骤
节点1:Jira测试数据获取
配置HTTP请求节点,调用Jira REST API获取测试执行结果:
节点类型: HTTP请求
配置:
方法: GET
URL: https://your-domain.atlassian.net/rest/api/3/search
Headers:
Authorization: "Basic ${base64('email:api_token')}"
Content-Type: "application/json"
Query参数:
jql: "project = TEST AND status in ('执行完成') AND updated >= -1d"
fields: "key,summary,status,customfield_10001"
数据处理代码:
# 提取关键测试指标
def parse_jira_data(response):
issues = response.json()['issues']
total_cases = len(issues)
passed_cases = len([i for i in issues if i['fields']['status']['name'] == '通过'])
failed_cases = len([i for i in issues if i['fields']['status']['name'] == '失败'])
return {
'total_cases': total_cases,
'passed_cases': passed_cases,
'failed_cases': failed_cases,
'pass_rate': round(passed_cases / total_cases * 100, 2) if total_cases > 0 else 0
}
节点2:Jenkins构建信息采集
节点类型: HTTP请求
配置:
方法: GET
URL: http://jenkins-url/job/your-project/lastBuild/api/json
Headers:
Authorization: "Basic ${base64('username:api_token')}"
构建信息提取:
def parse_jenkins_data(response):
build_info = response.json()
return {
'build_number': build_info['number'],
'build_status': build_info['result'],
'build_duration': build_info['duration'] // 1000, # 转换为秒
'build_timestamp': build_info['timestamp'],
'commit_author': build_info['actions'][1]['lastBuiltRevision']['branch'][0]['name']
}
节点3:智能数据分析与报告生成
这是整个工作流最核心的部分,使用LLM节点进行智能分析:
你是一名资深测试经理,请基于以下测试数据生成一份专业的测试报告:
## 测试执行概览
- 总用例数: {{total_cases}}
- 通过用例: {{passed_cases}}
- 失败用例: {{failed_cases}}
- 通过率: {{pass_rate}}%
## 构建信息
- 构建编号: #{{build_number}}
- 构建状态: {{build_status}}
- 构建耗时: {{build_duration}}秒
## 分析要求
请从以下维度进行专业分析:
1. **质量评估**:基于通过率评估本次构建的质量等级(优秀/良好/合格/风险)
2. **问题聚焦**:如果有失败用例,分析可能的原因和影响范围
3. **趋势对比**:与最近3次构建的通过率进行趋势分析
4. **改进建议**:针对发现的问题给出具体的改进建议
5. **发布建议**:基于测试结果给出是否可发布的建议
## 输出格式
请使用以下Markdown格式输出:
### 🎯 测试报告摘要
[简要总结]
### 📊 质量评估
[详细评估]
### ⚠️ 风险提示
[风险分析]
### 💡 改进建议
[具体建议]
### 🚀 发布建议
[发布决策建议]
节点4:钉钉消息格式化
由于钉钉Markdown格式有特殊要求,需要专门进行格式化:
def format_dingtalk_message(analysis_report, test_data, build_info):
# 根据通过率设置消息颜色
if test_data['pass_rate'] >= 95:
color = "#008000" # 绿色
status_emoji = "✅"
elif test_data['pass_rate'] >= 80:
color = "#FFA500" # 橙色
status_emoji = "⚠️"
else:
color = "#FF0000" # 红色
status_emoji = "❌"
message = {
"msgtype": "markdown",
"markdown": {
"title": f"{status_emoji} 测试报告 - 构建 #{build_info['build_number']}",
"text": f"""## {status_emoji} 自动化测试报告
**构建信息**
> 构建编号: #{build_info['build_number']}
> 构建状态: {build_info['build_status']}
> 测试通过率: **{test_data['pass_rate']}%** ({test_data['passed_cases']}/{test_data['total_cases']})
**关键指标**
🔴 失败用例: {test_data['failed_cases']}
🟢 通过用例: {test_data['passed_cases']}
⏱️ 构建耗时: {build_info['build_duration']}秒
**详细分析**
{analysis_report}
---
*生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}*
*🤖 本消息由Dify测试报告工作流自动生成*"""
},
"at": {
"isAtAll": test_data['pass_rate'] < 80 # 通过率低于80%时@所有人
}
}
return message
节点5:钉钉消息推送
配置HTTP请求节点推送消息到钉钉:
节点类型: HTTP请求
配置:
方法: POST
URL: ${dingtalk_webhook_url}
Headers:
Content-Type: "application/json"
Body: |
{{formatted_message}}
五、高级功能:让报告更智能
1. 历史数据对比分析
在工作流中添加数据存储节点,保存每次构建的历史数据:
# 历史数据记录
def save_build_history(build_info, test_data):
history_entry = {
'build_number': build_info['build_number'],
'timestamp': build_info['build_timestamp'],
'pass_rate': test_data['pass_rate'],
'total_cases': test_data['total_cases'],
'duration': build_info['build_duration']
}
# 保存到Dify知识库或外部数据库
# 这里以简化的文件存储为例
with open('/data/build_history.json', 'a') as f:
f.write(json.dumps(history_entry) + '\n')
2. 失败用例智能分析
对于失败的测试用例,进行深度根因分析:
请分析以下失败用例,识别根本原因:
失败用例列表:
{{failed_test_cases}}
可用信息:
- 代码变更记录:{{recent_commits}}
- 历史类似失败:{{similar_failures}}
- 环境配置变更:{{environment_changes}}
请从以下维度分析:
1. 代码变更影响分析
2. 环境配置问题识别
3. 测试数据问题排查
4. 给出具体的排查建议
3. 多环境报告适配
通过条件分支节点,实现不同环境的差异化报告:
- 节点类型: 条件分支
条件: ${environment == 'prod'}
真分支:
- 使用生产环境报告模板
- 添加安全扫描结果
- @项目负责人和技术总监
假分支:
- 使用测试环境简化模板
- 仅@测试团队
六、效能提升数据分析
时间节省对比
| 任务环节 | 手动处理耗时 | Dify自动化耗时 | 节省时间 |
|---|---|---|---|
| 数据收集 | 40分钟 | 2分钟 | 38分钟 |
| 报告生成 | 35分钟 | 3分钟 | 32分钟 |
| 分析洞察 | 20分钟 | 10分钟 | 10分钟 |
| 分发通知 | 15分钟 | 3分钟 | 12分钟 |
| 总计 | 110分钟 | 18分钟 | 92分钟 |
质量提升指标
- 报告准确性:从人工整理的95%提升到自动生成的99.9%
- 及时性:从延迟2-4小时到实时生成(构建完成后5分钟内)
- 覆盖率:从选择性报告到100%测试用例覆盖
- 可追溯性:自动保存历史记录,便于趋势分析
七、实际应用效果
成功案例展示
在某中型互联网项目中,该工作流实施后的效果:
实施前:
- 测试报告准备:每周平均消耗5-6小时
- 问题发现到通知延迟:2-4小时
- 报告一致性:依赖个人经验,质量参差不齐
实施后:
- 测试报告生成:完全自动化,零人工投入
- 问题实时通知:构建失败后3分钟内自动推送
- 报告标准化:统一格式和深度分析
团队反馈
“以前最怕周五下午的测试报告整理,现在只需要点击一下,18分钟后就能收到专业的分析报告,还能准时下班。” —— 测试工程师小王
“自动化的报告不仅节省时间,更重要的是提供了我们之前忽略的深度洞察,比如通过率趋势分析和根因定位。” —— 测试经理李姐
八、优化技巧与避坑指南
1. 性能优化策略
并发处理优化:
# 并行执行数据采集任务
async def gather_test_data():
jira_task = asyncio.create_task(fetch_jira_data())
jenkins_task = asyncio.create_task(fetch_jenkins_data())
testrail_task = asyncio.create_task(fetch_testrail_data())
results = await asyncio.gather(
jira_task, jenkins_task, testrail_task,
return_exceptions=True
)
缓存机制:
- 配置Dify缓存节点,对静态数据缓存1小时
- 使用条件判断避免重复计算
- 增量数据采集,只获取变更部分
2. 错误处理与重试
def robust_api_call(api_func, max_retries=3):
for attempt in range(max_retries):
try:
return api_func()
except RequestException as e:
if attempt == max_retries - 1:
# 最后一次重试仍然失败,返回降级数据
return get_fallback_data()
wait_time = (2 ** attempt) # 指数退避
time.sleep(wait_time)
3. 安全最佳实践
- API密钥通过Dify环境变量管理,避免硬编码
- 钉钉Webhook地址加密存储
- 敏感数据脱敏处理
- 访问权限分级控制
九、扩展应用场景
基于相同技术架构,还可以构建更多自动化工作流:
1. 每日质量日报
触发条件: 每个工作日9:00
工作内容:
- 汇总前一日测试结果
- 生成质量趋势图表
- 推送至项目管理频道
预计节省: 每日30分钟
2. 发布就绪度检查
触发条件: 预发布环境部署完成
工作内容:
- 自动化冒烟测试
- 关键指标验证
- 发布风险评估
- 生成就绪度报告
预计节省: 每次发布2小时
3. 性能测试报告
触发条件: 性能测试完成
工作内容:
- JMeter结果分析
- 性能瓶颈识别
- 容量规划建议
- 对比历史性能数据
预计节省: 每次测试3小时
十、总结:从时间消耗到价值创造
通过Dify搭建的测试报告自动化工作流,我实现了:
时间解放:从每天110分钟的手动工作到18分钟的全自动执行,净节省92分钟
质量提升:报告准确性、及时性、一致性得到显著改善
价值升级:从机械的数据整理者转变为深度的质量分析师
实施建议:
- 从最耗时的环节开始自动化,快速获得成就感
- 采用迭代方式,先实现核心功能再逐步完善
- 注重错误处理和降级方案,确保系统可靠性
- 收集团队反馈,持续优化工作流
现在,你的团队也可以开始构建自己的自动化测试报告系统,把宝贵的时间投入到更有价值的质量分析和改进工作中。告别重复劳动,拥抱高效能的测试新时代!
推荐学习
行业首个「知识图谱+测试开发」深度整合课程【人工智能测试开发训练营】,赠送智能体工具。提供企业级解决方案,人工智能的管理平台部署,实现智能化测试,落地大模型,实现从传统手工转向用AI和自动化来实现测试,提升效率和质量。
扫码进群,领取试听课程。