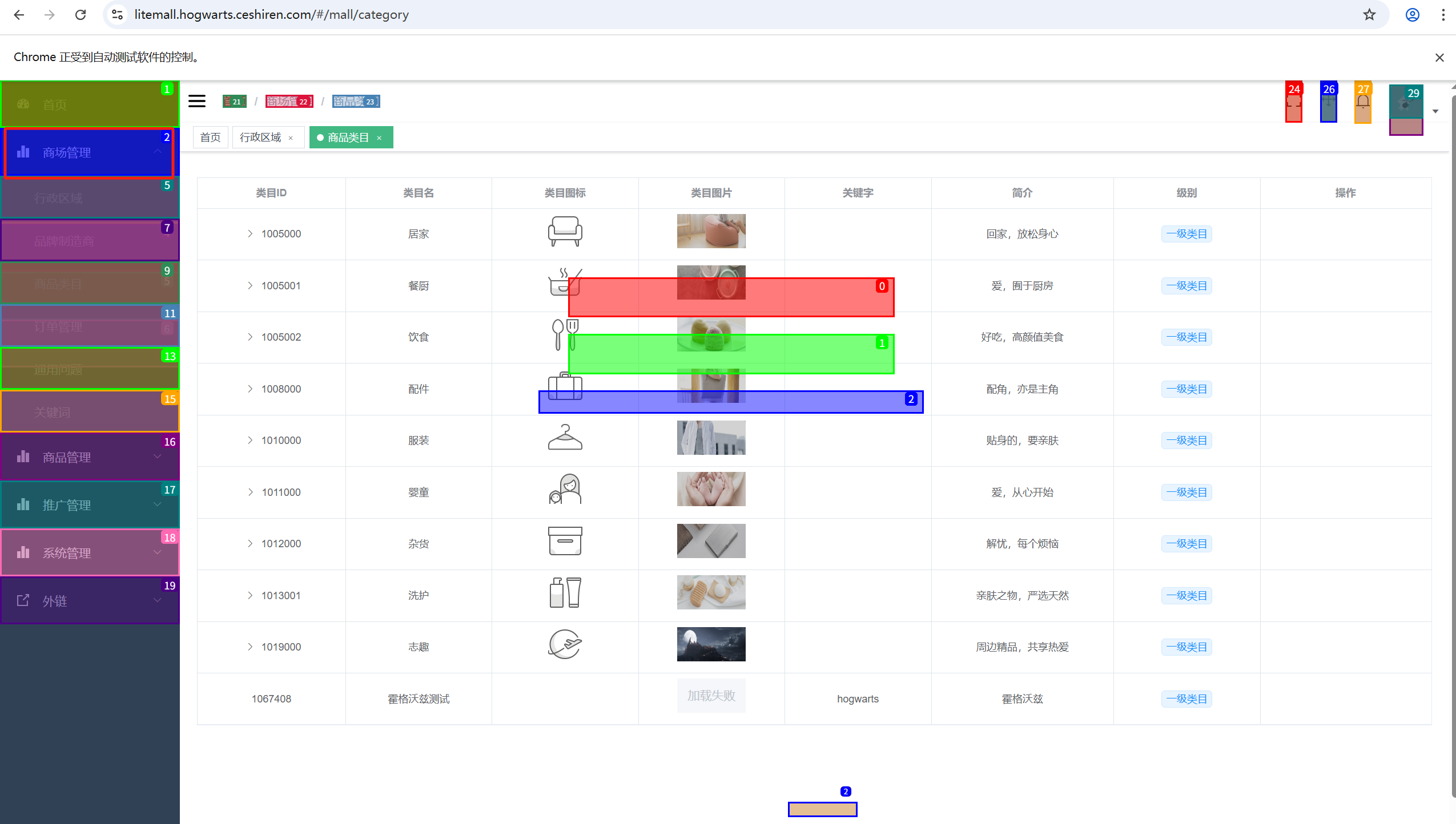
问题
使用browser user的js无法定位点击商品管理列表
看到已经页面识别出来了商品管理管理,但大模型无法定位
报错信息
browseruse.txt (1.0 MB)
环境
selenium_tool.py如下:
import json
from pathlib import Path
from typing import Optional, Dict, Any, Tuple
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.remote.webdriver import WebDriver
from selenium.common.exceptions import (
NoSuchElementException, ElementClickInterceptedException,
WebDriverException, TimeoutException
)
from selenium.webdriver.chrome.service import Service
# 读取JS文件内容并添加异常处理
try:
JS_PATH = Path(__file__).parent / 'buildDomTree.js'
with open(JS_PATH, 'r', encoding='utf-8') as f:
JS_CONTENT = f.read()
except FileNotFoundError:
raise RuntimeError(f"关键文件缺失: dom.js not found at {JS_PATH}")
except Exception as e:
raise RuntimeError(f"读取dom.js失败: {str(e)}")
class WebAutoFramework:
def __init__(self, headless: bool = False, max_token_length: int = 8000):
self.driver: Optional[WebDriver] = None
self.max_token_length = max_token_length
self.headless = headless
self._initialize_driver()
self.element = None
# 扩展需要收集的标签类型
self.target_tags = [
'button', 'input', 'select', 'textarea', # 表单元素
'a', 'span', 'p', 'h1', 'h2', 'h3', 'h4', 'h5', 'h6', # 文本与链接
'div', 'section', 'article', 'header', 'footer', # 布局元素
'table', 'tr', 'td', 'th', 'ul', 'ol', 'li', # 列表与表格
'img', 'video', 'audio' # 媒体元素
]
def _initialize_driver(self) -> None:
try:
options = webdriver.ChromeOptions()
if self.headless:
options.add_argument('--headless=new')
# 增强浏览器稳定性参数
options.add_argument('--no-sandbox')
options.add_argument('--disable-gpu')
options.add_argument('--ignore-certificate-errors')
options.add_argument('--disable-dev-shm-usage')
# 驱动路径(确保正确)
driver_path = r"D:\chrome_download\chrome_driver\chromedriver-win64\chromedriver.exe"
# 验证驱动存在性
if not Path(driver_path).exists():
raise FileNotFoundError(f"ChromeDriver不存在: {driver_path}")
service = Service(executable_path=driver_path)
self.driver = webdriver.Chrome(
service=service,
options=options
)
self.driver.set_page_load_timeout(30)
self.driver.implicitly_wait(10)
except WebDriverException as e:
raise RuntimeError(f"初始化浏览器失败: {str(e)}")
# def __init__(self):
# self.driver = None
# self.element = None
#
# def init(self):
# if not self.driver:
# self.driver = webdriver.Chrome()
# self.driver.implicitly_wait(5)
def open(self, url):
self.driver.get(url)
return self.source()
# def source(self):
# return self.driver.execute_script(
# """
# //var content="";
# //document.querySelectorAll('button').forEach(x=> content+=x.outerHTML);
# //document.querySelectorAll('input').forEach(x=> content+=x.outerHTML);
# //document.querySelectorAll('li').forEach(x=> content+=x.outerHTML);
# //document.querySelectorAll('table').forEach(x=> content+=x.outerHTML);
# return content;
# """
# )
def source(self) -> Dict[str, Any]:
if not self.driver:
return {"error": "浏览器未初始化"}
try:
raw_content = self.driver.execute_script(f"let f={JS_CONTENT};return f();")
#print(f"返回的page_source为{raw_content}")
return raw_content
except Exception as e:
return {"error": f"获取页面元素信息失败: {str(e)}"}
def click(self):
"""
点击当前的元素
:return:
"""
self.element.click()
return self.source()
def send_keys(self, text):
self.element.clear()
self.element.send_keys(text)
return self.source()
def find(self, locator):
print(f"find css = {locator}")
element = self.driver.find_element(by=By.CSS_SELECTOR, value=locator)
self.element = element
return self.source()
def maximizeWindow(self):
"""
浏览器最大化
:return:
"""
self.driver.maximize_window()
return self.source()
def quit(self):
# self.driver.quit()
pass
def get_current_url(self):
print(f"当前的url为{self.driver.current_url}")
return self.driver.current_url
web_agent.py如下:
import time
from hogwarts_logger import info
from langchain.globals import set_verbose
from langchain_core.globals import set_debug
from langgraph.prebuilt.chat_agent_executor import AgentState, create_react_agent
from testcase_gen.llm import model_chatpt, model_ollama
set_debug(True)
set_verbose(True)
from langchain_core.tools import tool
from langraph_agent.selenium_tools_ad import WebAutoFramework
web = WebAutoFramework()
@tool
def open(url: str):
"""
使用浏览器打开特定的url,并返回网页内容
"""
r = web.open(url)
return r
@tool
def find(css: str):
"""定位网页元素"""
return web.find(css)
@tool
def click(css: str = None):
"""以css的方式定位网页元素后点击"""
web.find(css)
return web.click()
@tool
def send_keys(css, text):
"""定位到css指定的元素,并输入text"""
web.find(css)
return web.send_keys(text)
@tool
def sleep(seconds: int):
"""等待指定的秒数"""
time.sleep(seconds)
@tool
def quit():
"""退出浏览器"""
web.quit()
@tool
def get_current_url():
"""获取当前的url"""
return web.get_current_url()
@tool
def maximizeWindow():
"""
浏览器最大化
:return:
"""
return web.maximizeWindow()
tools = [open, quit, get_current_url, find, click, send_keys,maximizeWindow]
# model=model_chatpt model_ollama
web_agent = create_react_agent(model=model_chatpt,
tools=tools,
prompt="你是一个测试工程师。"
"每次只返回包含一个action的工具调用。"
"每次只返回一个tool_call action。"
"每次只返回一个function_call action。")
def test_page_source_v3():
# 构建符合AgentState要求的输入
state = {
"messages": [{
"role": "user",
"content": "1. 浏览器最大化后打开 https://litemall.hogwarts.ceshiren.com/#/login?redirect=%2Fdashboard "
"2. 输入用户名 hogwarts"
" 3. 输入密码 test12345"
" 4. 点击登录按钮"
" 5. 进入首页后"
"6.点击商品管理,点击商品列表,点击添加按钮"
}],
"tools": tools,
"tool_names": [tool.name for tool in tools]
}
r = web_agent.invoke(state,config={"recursion_limit": 50})
info(r)
